CUSTOM TRAINING OF LORA MODELS FOR VISUAL CONTENT GENERATION WITH AI
REGISTRO DOI: 10.69849/revistaft/ni10202511262101
Eduardo Ramos da Silva1
André Luiz da Silva2
Fabiana Florian3
Resumo: Este trabalho apresenta uma prova de conceito para a personalização do modelo generativo Stable Diffusion XL (SDXL) por meio da técnica LoRA (Low-Rank Adaptation), utilizando apenas uma captura de tela do jogo Ark: Survival Ascended. O objetivo é avaliar a capacidade do modelo de reproduzir a estética da cena original a partir de um conjunto mínimo de dados, caracterizando um cenário de one-shot learning. A metodologia foi estruturada em quatro etapas: seleção da imagem, curadoria e pré-processamento, treinamento com os LoRA Easy Training Scripts e avaliação qualitativa dos resultados. O treinamento foi conduzido em ambiente com GPU dedicada, com monitoramento de métricas de perda (loss) para identificar o ponto de estabilização do aprendizado e selecionar o checkpoint adequado. Os resultados indicam que, mesmo com apenas um exemplo, é possível reproduzir a cena-alvo com alta fidelidade, preservando a paleta de cores, a composição global e os elementos visuais centrais. Observou-se, contudo, limitação de generalização para outros cenários, coerente com a natureza do experimento. Como contribuição prática, o estudo demonstra um fluxo replicável e de baixo custo para personalização estilística em asset pipelines de jogos digitais, destacando a viabilidade de uso da IA generativa em tarefas de personalização visual com recursos restritos, bem como caminhos de melhoria para trabalhos futuros (p.ex., few-shot e métricas objetivas).
Palavras-chave: Inteligência Artificial; Jogos Digitais; Modelos Generativos; LoRA; one-shot Learning.
Abstract: This proof-of-concept investigates customizing the Stable Diffusion XL (SDXL) generative model via Low-Rank Adaptation (LoRA) using a single screenshot from the game Ark: Survival Ascended. The aim is to assess the model’s ability to reproduce the original scene’s aesthetics from a minimal dataset, characterizing a one-shot learning scenario. The workflow comprises four stages: image selection, curation and preprocessing, training with the LoRA Easy Training Scripts, and qualitative evaluation of outputs. Training was performed on a dedicated GPU, with loss curves monitored to identify stabilization and select an appropriate checkpoint. Results indicate that, even with only one example, the model can recreate the target scene with notable fidelity, preserving color palette, global composition, and key visual elements. Nonetheless, limited generalization to different scenes was observed, consistent with the experiment’s scope. In practice, the study delivers a replicable, low-cost pipeline for stylistic personalization in game asset workflows, highlighting the feasibility of generative AI for visual customization under tight resource constraints and pointing to improvements for future work (e.g., few-shot setups and objective metrics).
Keywords: Artificial Intelligence. Digital Games. Generative Models. LoRA. One-shot Learning.
1 INTRODUÇÃO
A geração de imagens por meio de modelos de difusão tem se consolidado como uma das inovações mais relevantes no campo da inteligência artificial aplicada à criação visual. Entre esses modelos, o Stable Diffusion XL (SDXL) destaca-se pela capacidade de produzir imagens de alta qualidade, com alto detalhamento e controle semântico. Contudo, apesar da robustez do modelo base, a adaptação de sua estética a contextos específicos geralmente requer procedimentos de personalização capazes de ajustar o comportamento do modelo a estilos, personagens, cenários ou identidades visuais particulares.
No desenvolvimento de jogos digitais, especialmente em equipes pequenas ou independentes, é comum haver pouca disponibilidade de material visual nas primeiras etapas de concepção. Muitas vezes, existe apenas uma única imagem de referência, como uma captura de tela inicial de cenário, interface ou ambiente de jogo. Essa limitação impõe desafios significativos para os métodos tradicionais de personalização, que normalmente dependem de conjuntos extensos de dados para evitar problemas de memorização e alcançar uma generalização adequada.
Nesse contexto, técnicas leves de adaptação, como Low-Rank Adaptation (LoRA), têm ganhado destaque por possibilitar ajustes rápidos e eficientes em modelos de difusão, demandando menos tempo de treinamento e menor custo computacional. Entretanto, a eficácia dessa abordagem quando aplicada em um regime extremo de dados, o one-shot learning, no qual apenas uma imagem está disponível, ainda é pouco documentada e permanece um tema de interesse científico e prático.
Embora LoRA permita personalizações rápidas e acessíveis, não está claro se o SDXL é capaz de aprender uma estética consistente com base em apenas uma imagem de referência, preservando a composição, a paleta e os elementos visuais sem causar distorções ou memorização excessiva. Assim, o problema investigado neste trabalho consiste em determinar até que ponto é viável personalizar o SDXL em um cenário de one-shot learning e quais são os limites técnicos dessa abordagem.
É possível personalizar o modelo SDXL, utilizando LoRA e apenas uma captura de tela, de forma que o modelo aprenda a estética essencial da imagem de referência e seja capaz de reproduzi-la de maneira consistente nas gerações subsequentes?
A pesquisa se justifica pela necessidade crescente de soluções rápidas e eficientes para a geração de conteúdo visual no desenvolvimento de jogos e em outras aplicações criativas. A possibilidade de adaptar um modelo de difusão inteiro com apenas uma imagem representa um avanço significativo em termos de custo, acessibilidade e velocidade de produção, especialmente para projetos independentes ou com recursos limitados.
Do ponto de vista científico, o estudo contribui para a compreensão dos limites inferenciais dos dados necessários para a personalização de modelos generativos, oferecendo evidências sobre o comportamento do SDXL em cenários de dados extremamente escassos. Ao explorar o potencial e as limitações da técnica LoRA em um ambiente tão restritivo, o trabalho busca ampliar o entendimento sobre a capacidade de generalização, o risco de memorização e a estabilidade do treinamento em regimes ultrarreduzidos.
Dessa forma, esta pesquisa investiga a viabilidade prática e teórica da personalização do SDXL por meio de LoRA em um contexto de one-shot learning, avaliando seus resultados, limitações e aplicações potenciais em pipelines de criação visual para jogos digitais.
2 REVISÃO BIBLIOGRÁFICA
A inteligência artificial (IA) generativa consolidou-se como tecnologia estratégica para a síntese de imagens de alta qualidade, influenciando indústrias criativas e, em particular, os jogos digitais. Nesta revisão, foi apresentado (I) um panorama dos modelos generativos; (II) fundamentos dos modelos de difusão; (III) a evolução do Stable Diffusion até o SDXL; (IV) tecnologias de aceleração (CUDA/Tensor Cores); (V) técnicas de personalização (DreamBooth, Textual Inversion e LoRA); (VI) princípios de one-shot/few-shot learning; (VII) aplicações em jogos; (VIII) ferramentas de treinamento local; e (IX) boas práticas de curadoria de dados para garantir qualidade.
Para compreender os fundamentos da técnica adotada neste estudo, é necessário, inicialmente, revisar as principais classes de modelos generativos e suas características.
2.1 Modelos generativos: panorama e fundamentos
Quatro famílias marcaram a evolução recente da IA generativa: Autoencoders Variacionais (VAEs), Redes Generativas Adversárias (GANs), Modelos Baseados em Fluxo e Modelos de Difusão. Enquanto as GANs produzem imagens realistas mas sofrem com instabilidade, e os VAEs são estáveis mas com menor nitidez, os Modelos de Difusão consolidaram-se por oferecer equilíbrio superior entre qualidade e estabilidade (ROMBACH et al., 2022), sendo a base tecnológica deste estudo.
2.2 Modelos de Difusão: do ruído ao controle
Os modelos de difusão operam com dois processos: (I) forward (adiciona ruído gaussiano até destruir a informação) e (II) reverse (uma rede aprende a remover ruído progressivamente). Na prática moderna, a rede aprende a prever ε (ruído) ou uma parametrização equivalente (v-prediction), o que melhora a estabilidade. Agendas de ruído (beta schedules) e arquiteturas U-Net com atenção cruzada (texto-imagem) são centrais.
2.2.1 Guidance e condicionamento textual
Para aumentar o controle do usuário sobre a imagem gerada, Ho e Salimans (2022) introduziram o Classifier-Free Guidance (CFG). A técnica consiste em “misturar predições condicionadas e não condicionadas para aumentar a fidelidade ao prompt, controlando o trade-off entre qualidade e diversidade”.
2.2.2 Difusão Latente (LDM)
Em vez de operar no custoso espaço de pixels, Rombach et al. (2022, p. 5) inovaram ao propor que o processo de difusão fosse realizado “em espaço latente comprimido, reduzindo custo e viabilizando alta resolução“. Nesta arquitetura, conhecida como Latent Diffusion Model (LDM), a decodificação final da imagem é realizada por um decodificador treinado (VAE).
Com os conceitos de difusão estabelecidos, torna-se possível examinar a evolução dos modelos Stable Diffusion até o SDXL.
2.3 Stable Diffusion e SDXL
O Stable Diffusion popularizou a difusão ao oferecer código aberto e um pipeline eficiente. O SDXL amplia capacidades:
- Resolução nativa de 1024×1024, com mais detalhes e melhor composição;
- Interpretação de prompts longos/complexos;
- Pipeline em duas etapas (Base + Refiner opcional) para realçar nitidez e texturas finas;
- Melhor alinhamento texto-imagem, útil na estética de jogos (LEE et al., 2024; ROMBACH et al., 2022).
Quadro 1 – Evolução do Stable Diffusion
| Versão | Resolução nativa | Principais melhorias | Observações |
| SD 1.4/1.5 | 512×512 | Acesso aberto; comunidade ampla | Limitações de detalhe/anatomia |
| SDXL Base | 1024×1024 | Melhor composição; prompts longos | Base pode ser usada sozinha |
| SDXL Refiner | 1024×1024+ | Nítidez/realce na etapa 2 | Aumenta tempo de geração |
| SDXL “Turbo” | Variável | Baixa latência | Tende a menor fidelidade |
2.4 Tecnologias de aceleração: CUDA, Tensor Cores e precisão mista
O treinamento eficiente de modelos de difusão exige paralelismo massivo, viabilizado pela plataforma CUDA e acelerado por Tensor Cores. O uso de precisão mista (fp16/bf16) foi fundamental neste trabalho para reduzir o consumo de VRAM e aumentar a velocidade de processamento sem degradar a qualidade final da geração (NVIDIA, 2020).
Além dos modelos base, é importante compreender os métodos existentes para personalizar, especialmente em cenários com poucos dados.
2.5 Personalização de modelos: Textual Inversion e LoRA
2.5.1 Textual Inversion
Aprende um novo token textual associado a um conceito ou estilo. Vantagens: barato e rápido (1–5 imagens); Limitações: menor capacidade para estilos complexos; forte dependência do modelo base (GAL et al., 2022).
2.5.2 LoRA (Low-Rank Adaptation)
Para solucionar o alto custo de fine-tuning, Hu et al. (2021) propuseram o Low-Rank Adaptation (LoRA), um método que “injeta adaptadores de baixo ranque […] nas camadas-alvo, mantendo [os] pesos originais congelados”. Segundo os autores, isso “reduz drasticamente os parâmetros treináveis e a VRAM, sem sacrificar muito a qualidade” (HU et al., 2021). Para SDXL, LORA é popular pela rapidez e por produzir checkpoints leves.
Quadro 2 – Técnicas de personalização
| Técnica | Vantagens | Limitações | Indicação |
| Textual Inversion | Leve, rápido (1–5 imgs) | Capta menos estilos complexos | Palavras/estilos simples |
| LoRA | Poucos parâmetros; rápido | Requer ajuste fino de r, LR | Estilização eficiente/SDXL |
Como este estudo opera em regime de dados mínimos, é fundamental apresentar os princípios de one-shot e few-shot learning.
2.6 One-shot e few-shot learning
One-shot (1 amostra) e few-shot (poucas amostras) testam a capacidade de memorizar e reproduzir padrões com dados mínimos. Isso inclui:
- Aumentos de dados (cortes, flips leves, variações de brilho) para robustez;
- Regularização (weight decay, dropout ou técnicas específicas como prior preservation) para mitigar overfitting;
- Parada precoce: observar loss por epoch e encerrar quando aparecer o “zig-zag” de estabilização;
- Ajuste cuidadoso do learning rate e do rank (no caso de LoRA) para não “distorcer” o estilo.
No presente trabalho, adota-se a abordagem one-shot, com uma captura do Ark: Survival Ascended, visando à reprodução fiel da cena (prova de conceito).
2.7 Aplicações em jogos digitais
A IA generativa impacta o pipeline de arte de jogos:
- Cenários e biomas: prototipagem rápida de variações (floresta, caverna, ruínas);
- Texturas e materiais: produção de superfícies coerentes em alta resolução;
- Personagens/NPCs: iterações de visual/estilo;Arte conceitual/marketing: materiais promocionais consistentes.
- Benefícios: redução de custos e tempo e ampliação criativa (WU et al., 2023).
- Desafios: consistência estilística, licenciamento de referências e ética no uso de dados.
2.8 Ferramentas de treinamento local
Neste trabalho, foi utilizado o LoRA Easy Training Scripts (suite em Python) para personalização do SDXL via LoRA. O fluxo típico inclui:
- Preparação do dataset (pastas/legendas);
- Definição de hiperparâmetros (learning rate, batch size, epochs, precisão mista);
- Carga do SDXL base (pesos congelados) e injeção dos adaptadores;
- Treinamento com logging do loss;
- Exportação dos checkpoints (.safetensors) para uso em toolkits de geração.
2.9 Boas práticas de curadoria e preparo de dados Mesmo com uma imagem, recomenda-se:
Qualidade técnica: foco, ausência de artefatos, compressão mínima, iluminação equilibrada;
Padronização: correção de cor/contraste leve;
Documentação: registrar fonte, parâmetros de captura (horário, clima no jogo) e justificativa da escolha;
Pré-visualização: inspecionar a imagem após os ajustes para evitar viés indesejado no treino.
2.10 Síntese da revisão
A literatura indica que a difusão latente (LDM) oferece um trade-off ótimo entre custo e qualidade (ROMBACH et al., 2022); o SDXL amplia a resolução e a fidelidade; CUDA/Tensor Cores viabilizam o processamento; e LoRA permite personalização leve com dados mínimos. No contexto de jogos, isso permite provas de conceito rápidas e replicáveis, como a reprodução de uma cena específica de Ark: Survival Ascended em cenário one-shot.
3 TREINAMENTO
Esta seção apresenta as etapas do treinamento do SDXL com LoRA em cenário one-shot, que foi desenvolvido a partir de uma única captura do Ark: Survival Ascended, cobrindo (i) coleta, curadoria e pré-processamento da imagem; (ii) descrição técnica da cena-referência; (iii) ferramentas e organização do projeto com LoRA Easy Training Scripts; (iv) ambiente computacional utilizado; (v) configuração efetiva do treino (hiperparâmetros e critérios operacionais); e (vi) riscos e limitações do procedimento. O objetivo é contextualizar o pipeline adotado e preparar o leitor para os resultados e análises subsequentes.
3.1 Coleta e Curadoria do Dataset
O dataset deste estudo é unitário: compõe-se de uma única captura de tela do jogo Ark: Survival Ascended, escolhida pela qualidade técnica e pela representatividade estética do cenário. A opção por um conjunto mínimo tem caráter de prova de conceito (one-shot), com foco em verificar a capacidade do adaptador LoRA, sobre o SDXL, de reproduzir a cena-alvo com alta fidelidade.
3.1.1 Critérios de seleção
- Nitidez e foco global: ausência de motion blur perceptível e de ruído cromático evidente.
- Iluminação equilibrada: sombras definidas, sem subexposição; luzes altas controladas, evitando clipping.
- Complexidade visual moderada: presença de texturas ricas (gelo, rocha, cristais), linhas predominantes (paredões, formas espiculares) e paleta coerente (tons frios contrastando com acentos quentes).
- Composição clara: linhas de horizonte e camadas de profundidade (primeiro plano gelado, médio plano com formações rochosas, fundo com cristas verticais e céu limpo).
3.1.2 Pré-processamento e padronização
A resolução da captura permaneceu em 2560 × 1440 px, compatível com a resolução nativa do SDXL, preservando da proporção por letterboxing, quando necessário, e aplicando ajustes sutis.
- Balanço de branco (neutralização de dominantes excessivas);
- Curva de tons (recuperação sutil de microcontraste em médios);
- Nitidez de saída (apenas para compensar o reamostramento).
Observação: qualquer alteração agressiva (sharpen forte, saturação extrema) foi evitada para não introduzir vieses que o modelo “aprenda” como estilo obrigatório.
3.2 Descrição técnica do cenário de referência (imagem-alvo)
A Figura 1 ilustra um ambiente glacial amplo e aberto, com superfície congelada ocupando grande parte do primeiro plano. O médio plano é dominado por afloramentos rochosos de coloração esbranquiçada/esverdeada e por rochas rosadas com veios horizontais, sugerindo estratificação ou oxidação. Dispostas verticalmente no fundo, surgem estruturas espiculares de tom marrom-escuro, lembrando cristas cristalinas ou formações lignificadas, que acrescentam direcionalidade vertical e profundidade ao enquadramento. Há emissões luminosas magenta pontuais (cristais/rachaduras energizadas) que funcionam como acentos cromáticos quentes, rompendo a paleta fria dominante (azuis, cianos, brancos).
Figura 1 – Cena de referência do Ark: Survival Ascended: Imagem capturada de dentro do jogo Ark: Survival Ascended na arena do Rei Titã no mapa Extinção

O céu é claro e limpo, com tonalidade azul-pálida, gerando luz difusa que suaviza as sombras duras. As sombras projetadas sobre o gelo indicam angulação solar média (não zênite), o que contribui para a leitura volumétrica de saliências e relevos. Pequenos arbustos outonais (laranja/amarelos) aparecem esparsos, criando microcontrastes de cor e de escala.
3.2.1 Elementos formais e texturais relevantes
- Texturas de gelo: áreas lisas com specular suave e regiões com microfissuras; variações sutis de albedo.
- Rochas frias (esverdeadas): de aparência metamórfica/mineral, com transições suaves e veios sutis.
- Rochas rosadas: estrias horizontais que marcam o ritmo e sugerem sedimentação; bom contraste com o gelo.
- Espículas escuras: formas verticais e pontiagudas, introduzem ritmo direcional (leitmotif formal).
- Cristais/rachaduras luminosas (magenta): focos de atenção; úteis para avaliar a conservação de cor e brilho no resultado gerado.
3.2.2 Justificativa estética e técnica da escolha
- Riqueza de materiais (gelo, rocha, cristal) → diversidade de BRDFs (funções de distribuição de refletância bidirecionais) e de microtexturas para o modelo aprender.
- Paleta fria com acentos quentes → teste de conservação de paleta na geração.
- Composição clara (planos e linhas verticais) → referência sólida para avaliar a estrutura global em relação às variações do modelo.
3.3 Ferramentas e Configuração de Treinamento
Neste trabalho utilizou-se o LoRA Easy Training Scripts para a personalização do SDXL. O modelo base foi o sd_xl_base_1.0.safetensors com um VAE externo compatível para estabilidade.
O treinamento foi realizado em um ambiente com 64 GB de RAM e uma GPU NVIDIA RTX 4090 (24 GB VRAM).
A configuração one-shot utilizou a imagem única com 150 repetições, executada por 20 épocas, totalizando 3000 passos de otimização. Para equilibrar a fidelidade estética e a estabilidade, definiram-se os hiperparâmetros essenciais: learning rate (UNet) de 1.0e-4, scheduler cosine com warmup de 5%, rank (Network Dimension) 16 e Network Alpha 16.
Otimizações como o otimizador AdamW8bit e a precisão mista bf16 foram ativadas para reduzir o uso de VRAM e acelerar o processo.
As especificações completas do ambiente computacional, a lista detalhada de hiperparâmetros (Quadro 4), o resumo de execução (Figura 6 e Quadro 5) e as telas de configuração da ferramenta (Figuras 2, 3, 4 e 5) foram movidos para o Apêndice A para preservar a fluidez do texto principal.
O treinamento foi executado por 20 épocas. Não se utilizou early stopping automático; a seleção do modelo ideal foi realizada a posteriori mediante a análise da curva de perda, conforme detalhado na Seção 4.2.
3.4 Riscos, limitações e contornos de validade
O processo de treinamento em cenário one-shot apresenta riscos e limitações inerentes que devem ser reconhecidos para a correta interpretação dos resultados.
Memorização (overfitting): a probabilidade de memorização é inevitavelmente alta, uma vez que o modelo é exposto repetidas vezes a um único exemplo. Apesar das augmentations e da regularização implícita do LoRA, uma parte significativa do aprendizado tende a reproduzir padrões específicos da imagem de referência.
Sensibilidade a hiperparâmetros: pequenas variações em parâmetros como o learning rate e o rank influenciam diretamente a quantidade de detalhes copiados ou derivados. Valores muito altos podem gerar perda de fidelidade ou distorções; valores muito baixos, por outro lado, resultam em aprendizado insuficiente e baixa expressividade da LoRA.
Ruído de aquisição: qualquer artefato presente na captura de tela, como compressão, aliasing, reflexos ou distorções de iluminação, é interpretado como sinal de treinamento. Por isso, a etapa de curadoria, ainda que mínima, foi conduzida com cuidado para reduzir interferências e preservar a integridade do conteúdo visual.
Transferência limitada: a generalização para contextos fora do domínio original (como outros biomas, ângulos de câmera ou condições de iluminação) é restrita. A LoRA tende a reproduzir com maior precisão apenas o cenário específico em que foi treinada, o que limita seu uso a variações controladas no mesmo estilo visual.
O treinamento foi conduzido com o modelo sd_xl_base_1.0, utilizando VAE externo, resolução de 1344 × 768, precisão bf16, atenção SDPA e repetição da imagem única por 150 vezes por epoch. O processo contou com 20 epochs, totalizando 3000 passos de otimização com learning rate de 1e-4, LoRA com rank 16 e network alpha 16, além de flip augment. Essa configuração foi selecionada para equilibrar a fidelidade estética, a estabilidade do aprendizado e o risco controlado de memorização.
4 RESULTADOS
Os resultados obtidos corroboram a hipótese inicial do estudo, indicando que mesmo um único exemplo é suficiente para reproduzir fielmente a estética do cenário. As amostras geradas preservam a composição, a paleta e os elementos estruturais da imagem de referência, demonstrando que a LoRA treinada em regime one-shot é capaz de capturar padrões essenciais sem depender de múltiplas vistas do ambiente.
4.1 Procedimento de avaliação
A avaliação foi realizada com base no checkpoint selecionado pelo critério de oscilação do loss (Seção 3.3). No experimento, a oscilação inicia no epoch 13; portanto, o checkpoint adotado foi o do epoch 15.
4.2 Curva de loss por epoch
A Figura 7 ilustra a evolução da métrica de perda (loss) durante o treinamento. Observa-se uma convergência acentuada até a 12ª epoch, quando os valores atingem aproximadamente 0,0075. A partir da 13ª epoch, a curva entra em um platô oscilatório (efeito “zigue-zague”), indicando a estabilização do aprendizado e o início do risco de memorização excessiva (overfitting). Com base nessa leitura, selecionou-se o checkpoint da época 15, que apresentou o equilíbrio ideal entre estabilidade numérica e a fidelidade visual desejada. Os dados numéricos detalhados desta evolução encontram-se no Quadro 6, no Apêndice A.
Figura 7 – Gráfico Loss × Epoch
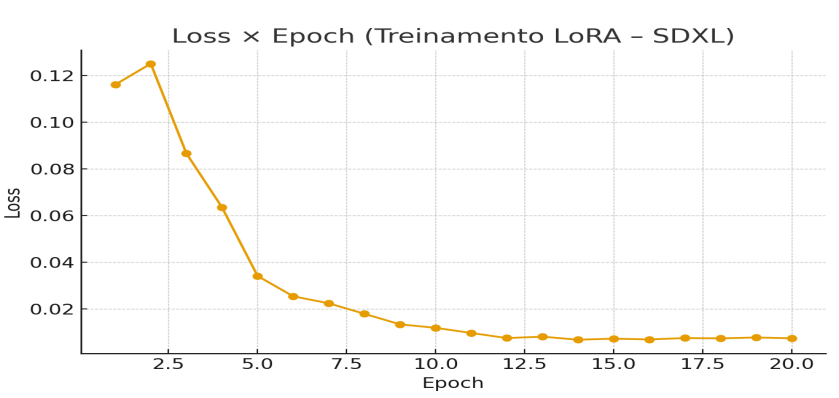
Fonte: Autoria própria.
Tempo total do treino: 1h 58min 23s (3000 steps, ≈2,37 s/step).
4.3 Comparação qualitativa
A análise qualitativa foi estruturada para avaliar a capacidade do modelo de reproduzir os elementos visuais essenciais presentes na imagem de referência utilizada no treinamento. Essa etapa é necessária para verificar se o modelo internalizou corretamente a composição, a paleta de cores e os padrões estruturais do ambiente, antes mesmo de se considerar métricas quantitativas ou avaliações mais específicas. A partir dessa contextualização, a subseção seguinte detalha os critérios empregados para avaliar a fidelidade da cena gerada.
4.3.1 Avaliação qualitativa (reprodução da cena)
A avaliação neste estudo concentra-se na fidelidade visual à Figura 1 (paleta fria com acentos magenta, estruturas verticais espiculares, planos de profundidade e texturas de gelo/rocha). Os critérios observados:
- Paleta e acentos: manutenção de azuis/cianos/brancos com magenta nos pontos energizados;
- Composição global: presença de primeiro plano gelado, médio plano rochoso e fundo com espículas verticais;
- Texturas: coerência de especular do gelo (brilho amplo) vs. difuso das rochas;
- Detalhes salientes: fendas luminosas e arbustos quentes esparsos como microcontrastes.
A avaliação qualitativa desempenha um papel central na análise de modelos generativos, especialmente em experimentos de personalização com LoRA, nos quais se busca medir o quanto o modelo é capaz de incorporar características visuais específicas a partir de um conjunto extremamente reduzido de amostras. Antes de recorrer a métricas quantitativas ou subjetivas, é essencial observar visualmente se a estrutura global da cena, sua paleta de cores e os padrões texturais são preservados após o processo de ajuste fino. Nesse contexto, a Figura 9 permite uma verificação inicial da fidelidade e da estabilidade do modelo na reprodução de elementos essenciais do ambiente original.
Após verificar a correspondência geral entre a imagem de referência e a amostra gerada (Figura 8), torna-se relevante analisar como esse nível de fidelidade se desenvolve ao longo do processo de treinamento. Diferentes epochs podem apresentar variações significativas na nitidez, no posicionamento de estruturas e na coerência cromática, o que permite identificar em que momento o modelo começa a estabilizar suas representações internas. Essa observação progressiva ajuda a compreender a dinâmica de aprendizado do LoRA, evidenciando tanto a evolução do refinamento quanto a redução de artefatos típicos das primeiras iterações.
Figura 8 – Comparação qualitativa: referência vs. amostra gerada (fidelidade de paleta, estrutura e texturas).

A Figura 9 ilustra a progressão do processo de aprendizagem do modelo LoRA, evidenciando como a fidelidade estrutural, a nitidez das texturas e a estabilidade da paleta de cores se aprimoram à medida que as epochs avançam. A comparação sequencial demonstra a redução gradual de artefatos, a melhora na definição de contornos e o aumento da coerência visual em relação ao cenário de referência.
Figura 9 – Comparação entre as epochs 1, 5, 10, 15, e 20

4.3.2 Análise da progressão temporal
As amostras geradas preservam a paleta fria (gelo/rochas) e os acentos magenta das emissões. A composição em planos (gelo no primeiro plano, afloramentos no médio plano e espículas verticais no fundo) é mantida, assim como o ritmo direcional das cristas. Em termos de materialidade, observa-se o specular suave do gelo e o difuso mineral nas rochas esverdeadas/rosadas, com microveios plausíveis.
Pequenas variações surgem na posição e escala das espículas e no brilho das emissões, o que indica uma recomposição coerente da cena, sem cópia pixel a pixel. Entre os epochs comparados, o epoch 15 apresenta bom equilíbrio entre fidelidade e suavidade; epochs mais tardios podem evidenciar sinais de memorização.
4.4 Ameaças à validade
- Dataset unitário: forte viés para a composição específica da cena.
- Métrica única (loss): não captura percepção humana.
- Augment limitado (flip): ajuda na robustez, mas não substitui variedade de vistas/iluminação.
4.5 Discussão
Os resultados obtidos demonstram que a abordagem one-shot com LoRA sobre o SDXL é capaz de reproduzir de forma convincente a estética da imagem de referência, mesmo em um contexto de dados extremamente reduzidos. A consistência observada, especialmente na manutenção da paleta, das texturas e da organização espacial da cena, reforça a literatura que aponta os modelos de difusão latente como altamente expressivos e capazes de absorver padrões visuais complexos a partir de poucos exemplos.
A curva de loss observada ao longo das épocas evidencia o comportamento esperado em cenários de memorização: queda acentuada nas primeiras iterações, seguida de estabilização, com oscilações que sugerem o início do sobreajuste. A identificação desse ponto de inflexão, utilizada para selecionar o checkpoint final, mostrou-se um critério prático e replicável, eficiente para aplicações que exigem fidelidade visual e não generalização semântica.
Outro aspecto relevante diz respeito às pequenas variações identificadas nas amostras geradas, como variações sutis na escala ou na posição de estruturas verticais, no brilho das emissões e nos microdetalhes das rochas. Essas variações, longe de indicar falhas, sugerem que o modelo recompõe a cena a partir de padrões aprendidos, sem copiar diretamente a imagem de entrada, o que é sinal positivo para preservar a criatividade do modelo dentro dos limites da referência.
Do ponto de vista prático, o experimento demonstra que a LoRA pode ser empregada como ferramenta leve e rápida para personalização artística em pipelines de produção de jogos e de arte digital. A possibilidade de reproduzir biomas, cenários ou estilos visuais específicos a partir de poucas imagens abre oportunidades para prototipagem, documentação visual, mockups e apoio a workflows criativos. No entanto, o viés decorrente do dataset unitário e o foco estrito na aparência da cena limitam o uso a contextos de memorização controlada, e não à generalização ou à criação de variantes amplas.
Expandindo as aplicações práticas na indústria, a metodologia one-shot demonstra valor significativo para estúdios independentes na prototipagem rápida de assets (como biomas ou texturas), na geração ágil de material de marketing e na exploração estilística geral com custo computacional e de tempo reduzidos.
Contudo, essa facilidade de replicação levanta considerações éticas relevantes. O treinamento, mesmo em datasets mínimos, utiliza assets (como os de Ark: Survival Ascended) que são propriedades intelectuais protegidas, gerando um debate necessário sobre os limites do uso justo e da obra derivada. Adicionalmente, a capacidade de replicar estilos visuais específicos com alta fidelidade pode ser usada para falsificações (deepfakes) ou para a apropriação indevida da identidade artística de criadores. Futuros trabalhos devem considerar não apenas a métrica técnica de fidelidade, mas também o licenciamento dos dados de origem e os potenciais impactos negativos da replicação visual facilitada pela IA generativa.
Portanto, a discussão evidencia que o método é tecnicamente sólido para o propósito delimitado nesta pesquisa, reprodução fiel de uma cena específica, mas carece de extensões metodológicas para aplicações mais amplas, como avaliações quantitativas e conjuntos de treinamento mais diversos.
5 CONCLUSÃO
Este trabalho investigou a capacidade do Stable Diffusion XL (SDXL), adaptado por meio de um módulo LoRA, de reproduzir com alta fidelidade visual uma cena específica do jogo Ark: Survival Ascended, utilizando apenas uma imagem de referência (cenário one-shot). A partir de um pipeline controlado, que incluiu curadoria rigorosa da imagem, definição explícita de hiperparâmetros e monitoramento sistemático do loss, demonstrou-se que o modelo é capaz de memorizar a estética global da cena-alvo, mantendo coerência estrutural, cromática e textural.
Os resultados indicaram que a combinação de rank 16, learning rate da U-Net de 1e-4 e 20 épocas de treino foi suficiente para capturar os elementos principais da composição: paleta fria com acentos magenta, planos de profundidade, padrões de gelo e rochas e as estruturas verticais características do cenário. A análise qualitativa também revelou que checkpoints próximos ao início da oscilação do loss (como o epoch 15) produzem um equilíbrio adequado entre fidelidade e suavidade, evitando tanto subtreinamento quanto sinais iniciais de memorização excessiva.
Entretanto, algumas limitações permanecem. O uso de um dataset unitário implica um forte viés na composição específica da cena, restringindo a capacidade de generalização do modelo. Além disso, a avaliação depende majoritariamente de análise visual e de comparação qualitativa, sem incorporar métricas automáticas complementares.
Como desdobramentos futuros, recomenda-se:
(i) expandir o dataset para um cenário few-shot (3–10 imagens), possibilitando maior robustez;
(ii) integrar métricas objetivas, como CLIPScore ou FID, combinadas à avaliação humana;
(iii) investigar faixas ampliadas de rank e learning rates para identificar regimes mais estáveis; e
(iv) explorar o uso do LoRA personalizado em pipelines de arte e de prototipagem de biomas para fins de desenvolvimento e marketing.
Assim, conclui-se que a personalização leve via LoRA é uma estratégia viável e eficiente para a reprodução fiel de cenas específicas em contextos de dados extremamente limitados.
REFERÊNCIAS BIBLIOGRÁFICAS
CLEANLAB. How to Filter Unsafe and Low-Quality Images from any Dataset. Cleanlab Blog, 2023. Disponível em: https://cleanlab.ai/blog/image-issues/. Acesso em: 25 set. 2025.
DODGE, S.; KARAM, L. Understanding How Image Quality Affects Deep Neural Networks. arXiv preprint, arXiv:1604.04004, 2016. Disponível em: https://arxiv.org/abs/1604.04004. Acesso em: 25 set. 2025.
DUTRA, P. V. M.; VILLELA, S. M.; NETO, R. F. Procedural Content Generation using Reinforcement Learning and Entropy Measure as Feedback. IEEE, 2023. Disponível em: https://www.researchgate.net/publication/365829051. Acesso em: 06 mar. 2025.
FORGEUI. Forge UI – Stable Diffusion Web Interface. s.l.: GitHub, 2024–2025. Disponível em: https://github.com/lllyasviel/stable-diffusion-webui-forge. Acesso em: 28 fev. 2025.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. Cambridge: MIT, 2016. Disponível em: https://www.deeplearningbook.org. Acesso em: 15 mar. 2025.
HO, J.; SALIMANS, T. Classifier-Free Diffusion Guidance. arXiv preprint, arXiv:2207.12598, 2022. Disponível em: https://arxiv.org/abs/2207.12598. Acesso em: 25 set. 2025.
HU, E. J. et al. LoRA: Low-Rank Adaptation of Large Language Models. arXiv preprint arXiv:2106.09685, 2021. Disponível em: https://arxiv.org/pdf/2106.09685. Acesso em: 03 nov. 2025
KOHYA. kohya-ss/sd-scripts: Stable Diffusion fine-tuning. s.l.: GitHub, 2024. Disponível em: https://github.com/bmaltais/kohya_ss. Acesso em: 11 mar. 2025.
LEE, S. et al. Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion. IEEE, 2024. Disponível em: https://ieeexplore.ieee.org/abstract/document/10771097. Acesso em: 25 set. 2025.
67372A. LoRA Easy Training Scripts. s.l.: GitHub, 2024–2025. Disponível em: https://github.com/67372a/LoRA_Easy_Training_Scripts. Acesso em: 14 abr. 2025.
MIMICPC. Kohya_ss LoRA Training Guide: A Step-by-Step Tutorial. MimicPC, 2025. Disponível em: https://www.mimicpc.com/ja/learn/kohya-ss-lora-training-guide. Acesso em: 25 set. 2025.
NICKOLLS, J.; BUCK, I.; GARLAND, M.; SKADRON, K. Scalable Parallel Programming with CUDA. Queue, v. 6, n. 2, p. 40–53, 2008. Disponível em: https://doi.org/10.1145/1365490.1365500. Acesso em: 25 set. 2025.
NICKOLLS, J. et al. CUDA: Enabling Scalable Parallel Computing for High-Performance Applications [white paper]. Santa Clara: NVIDIA, 2008. Disponível em: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/cud a-enabled-applications-whitepaper.pdf. Acesso em: 25 set. 2025.
NVIDIA. NVIDIA Ampere Architecture In-Depth. Santa Clara: NVIDIA, 2020. Disponível em: https://developer.nvidia.com/ampere-architecture. Acesso em: 12 mai. 2025.
ROMBACH, P.; BLATTMANN, A.; LORENZ, D.; ESSER, P.; OMMER, B. High-Resolution Image Synthesis with Latent Diffusion Models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. Disponível em: https://openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_Image_S ynthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.html. Acesso em: 25 set. 2025.
STABILITY AI. Stable Diffusion XL 1.0 (SDXL). s.l.: Stability AI, 2023. Disponível em: https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0. Acesso em: 18 abr. 2025.
STABILITY AI. SDXL VAE. s.l.: Stability AI, 2023. Disponível em: https://huggingface.co/stabilityai/sdxl-vae. Acesso em: 25 jun. 2025.
STUDIO WILDCARD; GROVE STREET GAMES. Ark: Survival Ascended. EUA: Studio Wildcard, 2023–2025.
WU, Y.; YI, A.; MA, C.; CHEN, L. Artificial Intelligence for Video Game Visualization: Advancements, Benefits and Challenges. Mathematical Biosciences & Engineering, v. 20, n. 8, p. 15345–15373, 2023. DOI: https://doi.org/10.3934/mbe.2023686. Disponível em: https://www.researchgate.net/publication/372564528. Acesso em: 25 set. 2025.
XIE, Y. AI-driven Automatic Generation and Rendering of Game Characters. Applied and Computational Engineering, v. 82, n. 1, p. 137–141, 2024. DOI: https://doi.org/10.54254/2755-2721/82/20241022. Disponível em: https://www.researchgate.net/publication/385708286. Acesso em: 11 jul. 2025.
YADAV, P. A Super Simple Guide to LoRA Training on Kohya. Medium, 2024. Disponível em: https://medium.com/@pankaj2376y/a-super-simple-guide-to-lora-training-on-kohya-75e9a72 577a9. Acesso em: 20 mai. 2025.
APÊNDICE A – DETALHAMENTO TÉCNICO DO TREINAMENTO
Esta seção agrupa os detalhes operacionais, hiperparâmetros e configurações de software/hardware utilizados no experimento (Seção 3), que foram movidos para melhorar a fluidez da leitura principal.
A.1 Ambiente Computacional
A configuração de hardware utilizada para o treinamento foi:
- CPU: Intel Core i5 14400F
- RAM: 64 GB DDR4 3200mhz
- Armazenamento: SSD NVMe 2 TB
- GPU: NVIDIA RTX 4090 (24 GB VRAM)
A.2 Hiperparâmetros Efetivamente Utilizados
O Quadro 4 sintetiza os hiperparâmetros utilizados no treinamento one-shot do LoRA.
Quadro 4 – Hiperparâmetros efetivamente utilizados
| Parâmetro | Valor adotado | Observação técnica |
| Modelo base | sd_xl_base_1.0 | Pesos congelados; LoRA injeta deltas |
| VAE externo | sdxlVAE | Melhor estabilidade de cor/textura |
| Resolução | 1344 × 768 | compatível com SDXL; preserva detalhe |
| Batch size | 1 | Coerente com dataset unitário |
| Epochs | 20 | Verificação da oscilação |
| Precisão | bf16 | Equilíbrio entre estabilidade e VRAM |
| Atenção eficiente | SDPA | Reduz memória e acelera steps |
| Learning rate (UNet/global) | 1.0e-4 | Scheduler cosine com warmup 0,05 |
| Learning rate (Text Encoder) | 0 | TE desativado |
| Otimizador | AdamW8bit | Variante 8-bit (reduz VRAM) |
| Perda | L2 | Estável em one-shot |
| LoRA rank (Network Dimension) | 16 | Capacidade moderada-alta (mais detalhe) |
| Network Alpha | 16 | Escala dos deltas consistente com rank |
| Repetições da imagem | 150 | Gera passos suficientes com 1 exemplo |
| Flip augment | Ativo | Robustece composição sem alterar paleta |
| Save Freq | 1 epoch | Seleção do melhor checkpoint |
A.3 Configuração da Ferramenta (LoRA Easy Training Scripts)
As figuras a seguir detalham as telas de configuração da ferramenta LoRA Easy Training Scripts utilizadas no estudo.
Figura 2 – Tela principal do LoRA Easy Training Scripts: Parâmetros essenciais (modelo base SDXL, VAE, resolução, precisão, gradiente, seed, batch size, epochs).
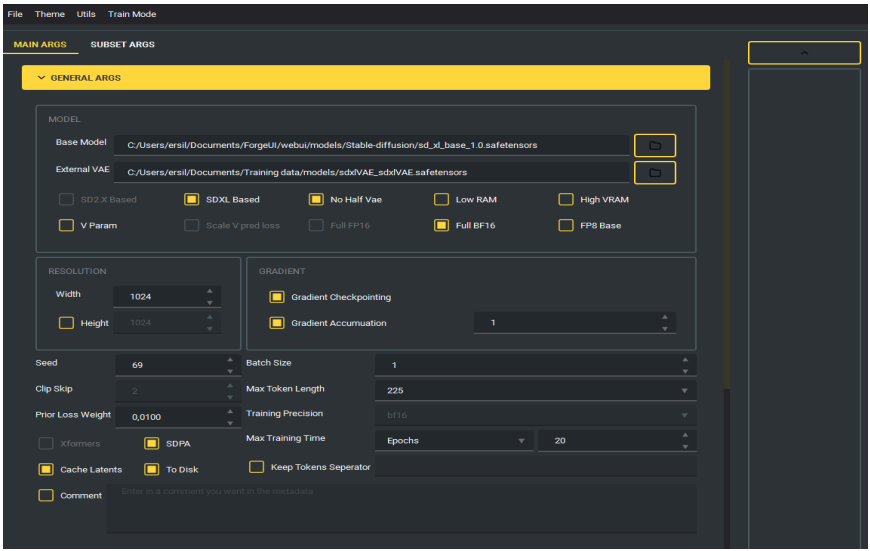
Figura 3 – SUBSET ARGS: Pasta da imagem (Input Image Dir), repeats e augmentations.
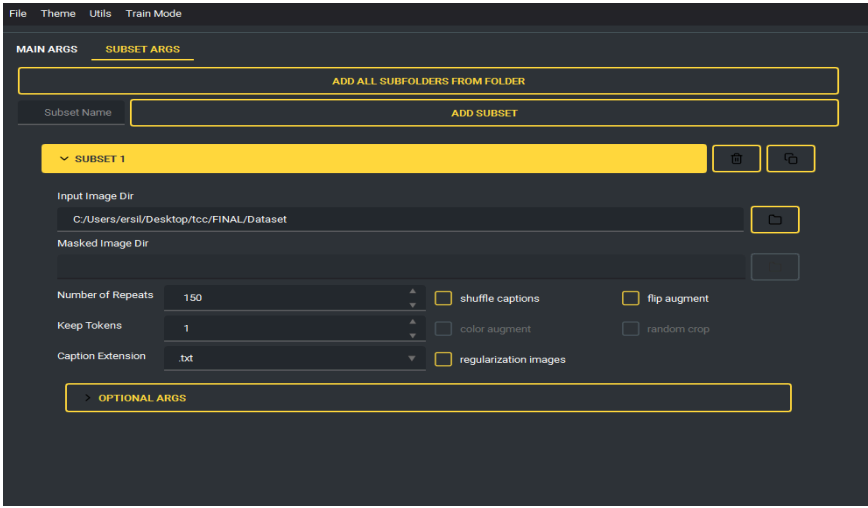
Figura 4 – Parâmetros de salvamento (SAVING ARGS): Pasta de saída (Output Folder), bf16, safetensors, Save Freq = 1 epoch, Save Toml File.
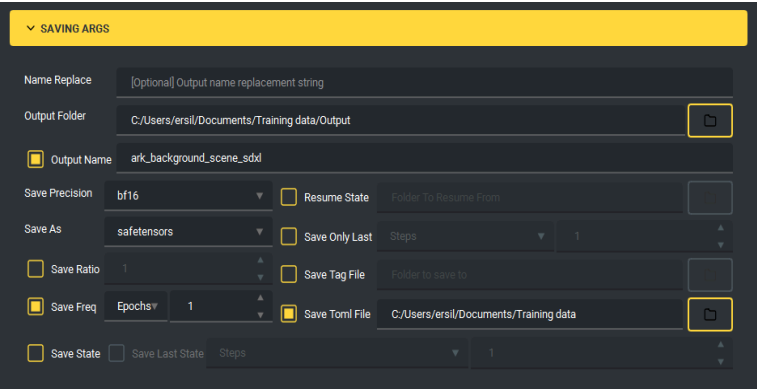
Figura 5 – Parâmetros avançados (NETWORK/OPTIMIZER): Rank (Network Dimension), Network Alpha, scheduler cosine, AdamW8bit, warmup.
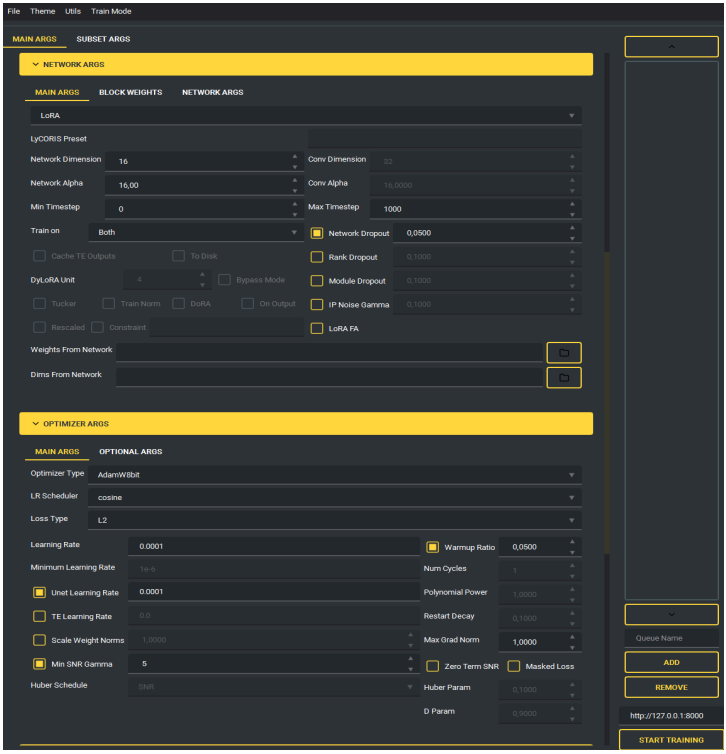
A.4 Resumo de Execução e Contagem de Passos
Figura 6 apresenta o log de execução do script e o Quadro 5 detalha a contagem de passos. Com 1 imagem e 150 repetições, cada epoch contém 150 batches (batch size = 1). Em 20 epochs, totaliza 3000 passos de otimização.
Figura 6 – Resumo da execução
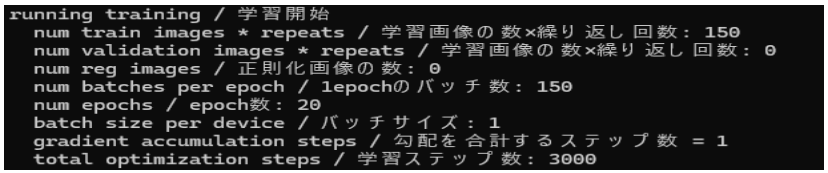
Quadro 5 – Resumo de execução e contagem de passos
| Item | Valor | Observação |
| Imagem(es) no dataset | 1 | Cenário one-shot |
| Repetições por epoch | 150 | Gera passos suficientes a partir de 1 exemplo |
| Batches por epoch | 150 | Batch size = 1 ⇒ 1 imagem por batch |
| Batch size | 1 | Reduz VRAM e evita gradientes redundantes |
| Gradient accumulation steps | 1 | Sem acumulação (passo padrão) |
| Número de epochs | 20 | Com parada precoce ao aparecer o “zig-zag” no loss |
| Total de optimization steps | 3000 | 150 batches/epoch × 20 epochs |
| Augment ativo | flip | Robustece pose/composição sem alterar paleta |
| Frequência de salvamento | 1/epoch | Facilita selecionar o melhor checkpoint próximo ao início do platô |
A.5 Dados Brutos do Treinamento
Quadro 6 – Loss médio por epoch
| Ep. | Loss | Ep. | Loss | Ep. | Loss | Ep. | Loss |
| 1 | 0,1160 | 6 | 0,0254 | 11 | 0,00970 | 16 | 0,00694 |
| 2 | 0,1250 | 7 | 0,0224 | 12 | 0,00752 | 17 | 0,00752 |
| 3 | 0,0866 | 8 | 0,0179 | 13 | 0,00811 | 18 | 0,00738 |
| 4 | 0,0635 | 9 | 0,0134 | 14 | 0,00682 | 19 | 0,00778 |
| 5 | 0,0341 | 10 | 0,0119 | 15 | 0,00727 | 20 | 0,00742 |
1Graduando do Curso de Sistemas de Informação Eduardo Ramos da Silva da Universidade de Araraquara-UNIARA. Araraquara-SP. E-mail: ersilva1@uniara.edu.br
2Orientador. Docente Curso de Sistemas de Informação André Luiz da Silva da Universidade de Araraquara-UNIARA. Araraquara-SP. E-mail: alsilva@uniara.edu.br
3Coorientador. Docente Curso de Sistemas de Informação Fabiana Florian da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: fflorian@uniara.edu.br