SUGAR CANE VARIETY RECOGNITION USING ARTIFICIAL INTELLIGENCE (AI)
REGISTRO DOI: 10.69849/revistaft/ra10202411122356
Lucas Machado da Costa1
Felipe Diniz Dallilo2
Fabiana Florian3
Resumo: Este trabalho descreve a criação de um modelo de rede neural convolucional para a classificação automática de diferentes variedades de cana-de-açúcar, nomeadamente CTC 04 e RB966928, com base em características morfológicas. A abordagem consistiu na coleta de imagens em campo, seguida por um procedimento de pré-processamento para uniformização dos dados e, em seguida, na aplicação de métodos de aprendizado profundo. O modelo obteve uma precisão de 98,7% na identificação das variedades, evidenciando grande eficácia e confiança. A utilização da inteligência artificial no reconhecimento das variedades de cana-de-açúcar complementa a análise manual especializada, economizando tempo e recursos na agricultura. Os resultados demonstram a capacidade da inteligência artificial para melhorar as práticas de manejo agrícola, contribuindo de maneira significativa para a inovação tecnológica no setor.
Palavras-chave: Aprendizado profundo. Cana-de-açúcar. Classificação automatizada. Inteligência artificial. Morfologia. Redes neurais convolucionais.
Abstract: This study outlines the development of a convolutional neural network model designed to automatically classify different sugarcane varieties specifically CTC 04 and RB966928 based on their morphological characteristics. The approach began with field image collection, followed by a preprocessing procedure to standardize the data, and culminated in the application of deep learning methods. Remarkably, the model achieved an accuracy of 98.7% in variety identification, showcasing its high effectiveness and reliability. The implementation of artificial intelligence in sugarcane variety recognition complements specialized manual analysis, conserving both time and resources in agriculture. These findings highlight the potential of artificial intelligence to enhance agricultural management practices, significantly contributing to technological innovation in the sector.
Key-words: Deep learning. Sugarcane. Automated classification. Artificial intelligence. Morphology. Convolutional neural networks.
INTRODUÇÃO
A inteligência artificial (IA) tem experimentado um crescimento acelerado nos últimos anos, tornando-se cada vez mais comum no cotidiano dia a dia das pessoas. Afinal, é extremamente benéfico ter algo que tome decisões e execute tarefas de forma semelhante ao ser humano. Isso é evidente em ferramentas como assistentes virtuais, sistemas de sugestão em plataformas de streaming e comércio eletrônico, e até mesmo em aplicativos de navegação que empregam Inteligência Artificial para aprimorar rotas em tempo real e customizar experiências com base no comportamento do usuário (ZENDESK, 2023).
Segundo Massruhá et al. (2014), um exemplo da utilização da IA pode ser visto na Embrapa Informática Agropecuária, desde os anos 2000. Por meio de uma gestão eficaz da informação e da utilização de padrões avançados em métodos de geoprocessamento e descoberta de dados, a agência se destaca no desenvolvimento de soluções para o setor agrícola.
A integração da inteligência artificial na agricultura tem trazido avanços significativos ao aprimorar os processos e aumentar a eficiência das atividades no campo. A IA é utilizada para monitorar o estado de saúde das plantações e prever condições climáticas futuras de forma mais precisa e também para gerenciar os recursos hídricos de maneira mais eficiente. Além disso, sistemas inteligentes ajudam na identificação precoce de pragas e doenças nas plantas, possibilitando intervenções mais precisas e reduzindo a necessidade de pesticidas.
Essas melhorias têm contribuído para promover uma agricultura mais sustentável e produtiva (CHEN et al., 2023).
Levando em consideração os impactos da IA apresentados no setor agrícola, o objetivo deste trabalho é identificar as variedades de cana-de-açúcar por meio de uma rede neural, rede neural convolucional com aprendizado supervisionado usando as características morfológicas da planta para definir a diferença entre elas.
Esse reconhecimento ajudará o agricultor a identificar de maneira mais simples diferentes tipos de cana-de-açúcar em um campo onde podem estar várias variedades plantadas ou alguma que se desenvolveu melhor.
Uma das formas de identificar variedades de cana-de-açúcar é por meio de suas características morfológicas. É possível distinguir as variedades observando aspectos como a cor do palmito, o comprimento, a quantidade de cera e o formato da gema, pois essas características variam conforme o estágio de maturação e a variedade da planta (VALDIR, 2015).
O reconhecimento de variedade de cana-de-açúcar é uma tarefa desafiadora, pois exige um vasto conhecimento das características morfológicas de cada de variedade, onde possui uma grande diversidade de detalhes. Na prática agrícola, os métodos para reconhecimento dependem da observação de um especialista, o que pode causar uma grande perda de tempo e está sujeito a erro na identificação.
Visando ter um ganho de tempo e uma maior taxa de assertividade, a proposta é treinar um algoritmo com um grande conjunto de dados de imagens das plantas o fazendo ser capaz de identificar as características morfológicas com uma alta precisão.
Foi realizada uma pesquisa de avaliação e levantamento bibliográfico para identificar variedades de cana-de-açúcar, estruturada em duas etapas. A primeira etapa envolveu a obtenção de imagens das variedades comerciais em parceria com produtores de cana, onde as fotos foram capturadas em campo com dispositivos fotográficos (smartphones) e acompanhadas de anotações sobre cada variedade. Na segunda etapa, destinada ao desenvolvimento do modelo de inteligência artificial, as imagens foram processadas para assegurar qualidade e consistência dos dados. Em seguida, aplicaram-se técnicas de aprendizado de máquina, incluindo redes neurais convolucionais, que permitem uma abordagem mais ampla e eficaz no reconhecimento das variedades de cana-de-açúcar, pois conseguem aprender padrões complexos em grandes volumes de dados.
2 REVISÃO BIBLIOGRÁFICA
Esta seção apresenta os conceitos referentes à inteligência artificial e morfologia da cana-de-açúcar.
2.1 INTELIGÊNCIA ARTIFICIAL
O principal propósito da Inteligência Artificial é imitar habilidades humanas, incluindo lógica, aquisição de conhecimento, identificação de padrões e processo decisório, possibilitando que máquinas realizem atividades de maneira independente e eficaz. De acordo com Teixeira (1990), há pesquisadores que acreditam que a mente humana funciona de forma semelhante a um computador, o que implica que processos cognitivos complexos podem ser vistos como operações de processamento de informações significando que, ao reproduzir essas tarefas, a inteligência artificial possibilita que sistemas informáticos aprendam com dados, se ajustem a novas informações e realizem ações com pouca intervenção humana, atingindo precisão e uniformidade.
2.1.1 DEEP LEARNING
O Deep Learning é uma subárea do aprendizado de máquina que utiliza redes neurais profundas, compostas por múltiplas camadas de neurônios artificiais. Essas redes são inspiradas no funcionamento do cérebro humano, ainda que de maneira simplificada. Conforme descrito pela IBM (2024), redes neurais profundas consistem em três ou mais camadas, o que permite que o modelo identifique padrões complexos e realize previsões de maneira altamente precisa. Apesar de não alcançar a complexidade do cérebro, essas redes são capazes de processar grandes volumes de dados com eficiência. A presença de camadas ocultas adicionais tem sido essencial para o sucesso das principais aplicações de inteligência artificial, permitindo a automação de processos analíticos e físicos sem a necessidade de intervenção humana.
2.2 MORFOLOGIA CANA-DE-AÇÚCAR
A cana-de-açúcar, pertencente à família Poaceae, apresenta características únicas em comparação com outras plantas. De acordo com Marafon (2012) e Diola e Santos (2010), as plantas dessa família, como a cana-de-açúcar, possuem inflorescências em forma de espiga, caule desenvolvido em colmos e folhas com bordas revestidas por lâminas de sílica. No seu habitat natural, a cana-de-açúcar é uma planta perene de crescimento ereto que, nas fases iniciais, pode apresentar um leve declive. Além disso, devido ao auto-sombreamento, ocorre uma seleção natural dos perfilhos, e o crescimento em altura é influenciado por fatores como água, temperatura e florescimento, variando de acordo com o genótipo.
As principais partes da cana-de-açúcar que serão úteis para o reconhecimento por IA podem ser organizadas da seguinte forma:
Colmo – Caule da cana-de-açúcar, responsável por sustentar as folhas, além de ser o local onde é armazenado o açúcar (Figura 1).
Figura 1 – Colmo cana-de-açúcar

Fonte: 3RLAB (2021)
Nós e entrenós – Parte onde contém elementos necessários para o reconhecimento de variedade (Figura 2).
Figura 2 – Nó e entrenó cana-de-açúcar
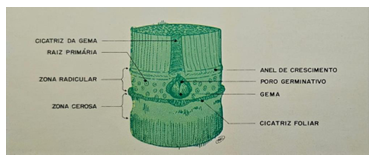
Fonte: (BOLETIM TÉCNICO COPERSUCAR EDIÇÃO ESPECIAL, 1991, p.26)
Gema – Existem diferentes tipos de gemas, onde cada variedade acaba tendo uma gema diferente, sendo assim ela um importante elemento para o reconhecimento de variedades (Figura 3).
Figura 3 – Tipos de gema
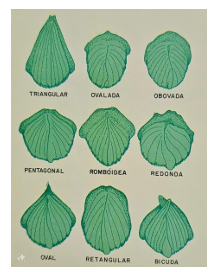
Fonte: (BOLETIM TÉCNICO COPERSUCAR EDIÇÃO ESPECIAL, 1991, p.26)
Tipos de entrenós – Da mesma forma que existem tipos diferentes de gemas, os entrenós possuem características diferentes para cada variedade (Figura 4).
Figura 4 – Tipos de entrenós

Fonte: (BOLETIM TÉCNICO COPERSUCAR EDIÇÃO ESPECIAL, 1991, p.26)
2.3 FERRAMENTAS PARA DESENVOLVIMENTO DA REDE NEURAL
A seção introduz as ferramentas de Python utilizadas para o desenvolvimento da rede neural convolucional.
2.3.1 PYTHON
A escolha do Python como principal ferramenta se deu, em grande parte, devido à sua vasta e ativa comunidade, que oferece suporte significativo em comparação a outras linguagens de programação. Python é uma linguagem de propósito geral que roda em praticamente qualquer sistema, possibilitando seu uso em diversas áreas, como desenvolvimento web e aprendizado de máquina. Sua versatilidade e acessibilidade tornam-na ideal tanto para iniciantes quanto para profissionais experientes, fatores que contribuem para que Python seja uma das linguagens de programação mais populares globalmente (SANTANA, 2024).
Além disso, Python é amplamente utilizado no desenvolvimento de inteligência artificial, especialmente em aprendizado de máquina e redes neurais, devido à sua extensa biblioteca de ferramentas e frameworks especializados, como TensorFlow e Keras. A linguagem possui uma estrutura que facilita o protótipo rápido e a experimentação, aspectos essenciais no campo da IA, o que a torna preferida por desenvolvedores dessa área (CHOLLET, 2018).
2.3.2 TENSORFLOW
TensorFlow é uma biblioteca de código aberto amplamente utilizada para criar redes neurais capazes de detectar padrões e correlações em imagens.
Trata-se de uma plataforma completa para desenvolvimento de aplicações de aprendizado de máquina, utilizando fluxo de dados e programação diferençável para treinar e realizar inferências em redes neurais profundas.
A biblioteca fornece aos desenvolvedores uma variedade de ferramentas, recursos e suporte da comunidade, sendo considerada uma das mais populares do mundo para aprendizado profundo (JOHNSON, 2023).
2.3.3 NUMPY
NumPy é uma biblioteca que facilita a manipulação de matrizes em Python, oferecendo um amplo conjunto de funções e operações específicas para esse propósito. NumPy, que significa Numerical Python, é uma biblioteca poderosa que trabalha com arrays multidimensionais, acompanhada de diversas rotinas para processamento desses arrays. No contexto do aprendizado de máquina, ela é extremamente útil para auxiliar o treinamento de redes neurais, pois permite realizar cálculos numéricos, como multiplicações, transposições e somas, de forma rápida e eficiente (SANTIAGO, 2018).
Os arrays do NumPy são amplamente utilizados para armazenar dados de treinamento e parâmetros dos modelos de aprendizado de máquina, facilitando o desenvolvimento de algoritmos com alta performance e simplicidade na escrita do código (SANTIAGO, 2018).
2.3.4 KERAS
Keras é uma biblioteca de código aberto baseada no TensorFlow, desenvolvida para facilitar o reconhecimento de padrões em imagens e outras tarefas de aprendizado profundo.
Também é amplamente utilizada na criação de redes neurais para resolver diversos problemas, como classificação de imagens, detecção de objetos e regressão. Sua interface simplificada permite que desenvolvedores criem redes neurais com uma estrutura de código similar à utilizada em Python, e, por ser de código aberto, está disponível gratuitamente para qualquer pessoa interessada em explorar e utilizar suas funcionalidades (DIDÁTICA TECH, S.D.).
2.3.4 OS
A biblioteca OS em Python é amplamente utilizada para manipular o sistema operacional de forma eficiente, permitindo a realização de tarefas como criação de diretórios e execução de comandos no terminal, o que garante maior dinamismo dependendo do ambiente de execução.
OS é uma biblioteca padrão essencial para a interação com o sistema operacional, oferecendo funcionalidades que possibilitam navegar e manipular diretórios, executar comandos e obter informações sobre o sistema. Essas informações são úteis para adaptar o comportamento do código de acordo com o sistema operacional em que está sendo executado (RAMOS, 2023).
2.3.5 OpenCV
A biblioteca OpenCV em Python é amplamente utilizada para processamento de imagens e visão computacional, fornecendo uma vasta gama de funções para análise e manipulação de imagens, o que permite o desenvolvimento de aplicações avançadas, como reconhecimento de padrões e rastreamento de objetos.
Segundo Bradski e Kaehler (2008), o OpenCV oferece uma plataforma poderosa e flexível, com diversas funcionalidades para captura, processamento e análise de imagens, que são aplicáveis em múltiplos contextos, desde tarefas simples até algoritmos complexos de aprendizado de máquina. Essa biblioteca é essencial para projetos que necessitam de uma interação robusta com dados visuais, adaptando seu comportamento conforme os requisitos específicos de cada aplicação.
2.3.6 Glob
A biblioteca glob em Python é amplamente utilizada para localizar arquivos e diretórios de maneira eficiente, oferecendo uma interface simples para busca de padrões em sistemas de arquivos.
O módulo glob fornece uma forma conveniente de encontrar arquivos com nomes específicos, permitindo a utilização de curingas como “ *, ? e []” para realizar buscas detalhadas. Essa funcionalidade é essencial para automatizar processos que envolvem grandes volumes de dados, possibilitando a seleção de arquivos conforme extensões, nomes e padrões definidos pelo usuário (LUTZ, 2013).
2.3.7 Scikit-learn
A biblioteca scikit-learn é uma ferramenta fundamental em Python para aprendizado de máquina e análise de dados, oferecendo uma ampla gama de algoritmos e métodos para modelagem preditiva. O scikit-learn disponibiliza implementações eficientes de algoritmos supervisionados e não supervisionados, incluindo métodos de classificação, regressão, clustering e redução de dimensionalidade. Projetada para interoperar com bibliotecas populares como NumPy e SciPy, scikit-learn se integra de maneira fluida em fluxos de trabalho de ciência de dados, tornando o desenvolvimento de modelos acessível e modular.
Suas ferramentas para validação cruzada e ajuste de hiperparâmetros permitem otimizar a precisão e o desempenho de modelos de forma sistemática. Assim, o scikit-learn é amplamente reconhecido por sua flexibilidade e precisão, sendo essencial para projetos que exigem análise e processamento de dados robustos (PEDREGOSA ET AL., 2011).
3 DESENVOLVIMENTO
Para o desenvolvimento da rede neural, foi conduzido um trabalho de campo para capturar imagens das características morfológicas da cana-de-açúcar, com foco em duas variedades específicas: RB966928 e CTC 4. Ao todo, foram obtidas 2.706 fotos, divididas igualmente entre as variedades, com 1.353 imagens de cada. As características detalhadas da variedade RB966928 estão descritas no Quadro 1.
Quadro 1 – Características morfológicas variedade RB966928
CARACTERÍSTICAS DESCRIÇÃO Porte Ereto Perfilhamento Bom perfilhamento Colmos Predominante verde Gema Oval
Fonte: (O autor, 2024)
O Quadro 2 apresenta as características da variedade CTC 04.
Quadro 2 – Características morfológicas variedade CTC 4
CARACTERÍSTICAS DESCRIÇÃO Porte Ereto Perfilhamento Bom perfilhamento Colmos Predominante verde com nós espaçados Gema Ovalada
Fonte: (O autor, 2024)
Para iniciar o desenvolvimento da rede neural, importam-se todas as bibliotecas que auxiliarão na construção do modelo (Figura 5).
Figura 5 – Importar bibliotecas
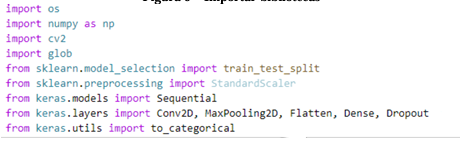
Fonte: (O autor, 2024)
Após a importação das bibliotecas necessárias, implementa-se uma função para o carregamento e pré-processamento das imagens, submetendo-as a uma formatação padronizada. Com o uso da biblioteca OpenCV, cada imagem é redimensionada para 128×128 pixels, garantindo uniformidade na entrada de dados. Em seguida, o resultado desse pré processamento é convertido em um array Numpy, facilitando o processamento subsequente pela rede neural (Figura 6).
Figura 6 – Pré-processamento das imagens.
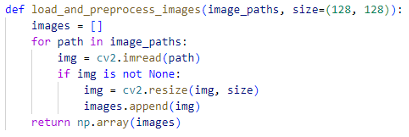
Fonte: (O autor, 2024)
Em seguida, as imagens são carregadas a partir de dois diretórios distintos, denominados CTC 04/TREINO e RB966928/TREINO. Com o auxílio da biblioteca glob, realiza-se uma busca nesses diretórios, selecionando todos os arquivos nos formatos .jpg e .png. Posteriormente, cada grupo de imagens é submetido a um pré-processamento, resultando em dois arrays de imagens (Figura 7).
Figura 7 – Carregamento das Imagens
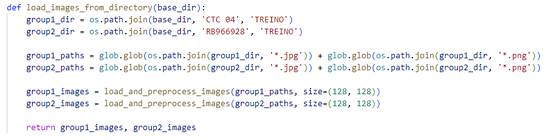
Fonte: (O autor, 2024)
Com as imagens carregadas, cria-se uma matriz x para armazenar todas as imagens previamente processadas, onde cada imagem é representada por uma matriz de pixels no formato 128×128 com três canais de cor (vermelho, verde e azul), resultando em uma matriz tridimensional de dimensão (128, 128, 3).
Na sequência, procede-se à normalização dos dados. Os valores dos pixels, inicialmente variando de 0 a 255, são divididos por 255, ajustando-os a um intervalo entre 0 e 1, esse procedimento é crucial para uniformizar os dados, acelerar a convergência no treinamento, evitar que determinadas características se sobreponham e, consequentemente, aprimorar o desempenho do modelo.
A etapa seguinte consiste na rotulagem dos dados. As imagens do grupo 1 (CTC 04) recebem o valor 0, enquanto as do grupo 2 (RB966928) são rotuladas com o valor 1. Os rótulos são armazenados na variável y, que é então convertida em um array Numpy, estrutura de dados recomendada para o uso em modelos de aprendizado de máquina.
Por fim, aplica-se o one-hot encoding à variável y, convertendo os rótulos numéricos em formato binário. Esta etapa é fundamental para possibilitar o uso da ativação softmax no modelo, sendo realizada com a função to_categorical (Figura 8).
Figura 8 – Rotulagem e normalização dos dados
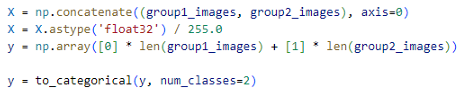
Fonte: (O autor, 2024)
Após a realização de todos os procedimentos de tratamento das imagens, o conjunto total foi dividido em duas partes: um conjunto de treino, contendo 80% das imagens, e um conjunto de teste, com os 20% restantes. Essa divisão foi feita utilizando o método train_test_split, que selecionou as imagens de forma aleatória. Com o argumento stratify=y, garantiu-se que o conjunto de treino e o conjunto de teste mantivessem a mesma proporção de imagens das variedades CTC 04 e RB966928 (Figura 9).
Figura 9 – Divisão das imagens para treino e teste

Fonte: (O autor, 2024)
Para a construção do modelo, utilizou-se o método Sequential() do Keras, permitindo a definição de uma arquitetura com dez camadas dispostas para maximizar a extração e representação das características das imagens. Inicialmente, uma camada convolucional (Conv2D) foi responsável pela extração de características básicas, como bordas e texturas, identificando padrões locais fundamentais. Em seguida, aplicou-se uma camada de MaxPooling para redução da dimensionalidade, mantendo apenas as informações mais relevantes e contribuindo para a mitigação de overfitting.
A estrutura prosseguiu com uma segunda camada Conv2D, configurada com o dobro de filtros, aprimorando a detecção de características mais complexas. Logo após, outra camada de MaxPooling, com 64 mapas de características, foi incorporada para reforçar a extração de padrões relevantes. Na etapa subsequente, uma terceira camada Conv2D com 128 filtros foi introduzida para identificar características mais refinadas e detalhadas, seguida por uma última camada de MaxPooling, que reduziu a resolução espacial de 32×32 para 16×16 pixels.
Para adaptar a saída convolucional a um formato compatível com a etapa de classificação, utilizou-se a camada Flatten, que converteu a saída das camadas anteriores em um vetor unidimensional composto por 128 mapas de 16×16 pixels. Posteriormente, uma camada densa com 128 neurônios atuou como classificador preliminar, integrando as características extraídas para gerar uma predição inicial. Para promover maior capacidade de generalização, foi incorporada uma camada de Dropout, a qual desativou aleatoriamente 50% dos neurônios durante o treinamento, reduzindo assim a possibilidade de overfitting.
A última camada, também densa, foi composta por dois neurônios correspondentes às classes CTC 04 e RB966928, fornecendo as probabilidades de classificação para cada imagem. Essa arquitetura, conforme ilustrado na Figura 10, foi projetada para capturar de forma eficiente as características das imagens e realizar a classificação com precisão (Figura 10).
Figura 10 – Criação das camadas do modelo

Fonte: (O autor, 2024)
Após concluir todos os procedimentos necessários, iniciou-se o treinamento do modelo, configurado para 10 épocas e utilizando um lote de 32 imagens. Durante o processo, o conjunto de teste foi empregado para validação, permitindo o monitoramento contínuo do desempenho do modelo e possibilitando ajustes nos hiperparâmetros (Figura 11).
Figura 11 – Treino do Modelo
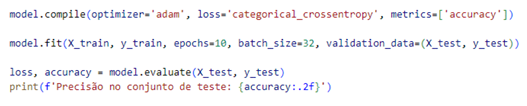
Fonte: (O autor, 2024)
4 RESULTADOS
Esta seção apresenta os resultados obtidos na classificação das variedades de cana-deaçúcar CTC 04 e RB966928, destacando as métricas de desempenho do modelo e sua eficácia na tarefa proposta.
4.1 DESEMPENHO GERAL DO MODELO
O modelo desenvolvido foi testado em um conjunto de dados independente, obtendo uma precisão geral de 98,7%. Essa avaliação foi feita com base na matriz de confusão, que evidenciou a alta capacidade do modelo em diferenciar corretamente as variedades de cana-de-açúcar CTC 04 e RB966928. A acurácia reflete a proporção de previsões corretas em relação ao total de amostras, demonstrando a eficácia do modelo na tarefa de classificação (Figura 12).
Figura 12 – Resultado pós treinamento – Matriz Confusão
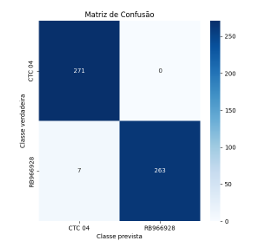
Fonte: (O autor, 2024)
A matriz de confusão (Figura 12) ilustra o desempenho do modelo em termos de previsões corretas e incorretas para cada classe, permitindo uma análise mais detalhada dos acertos e erros de classificação. O modelo classificou corretamente 271 amostras de CTC 04 como CTC 04 e 263 amostras de RB966928 como RB966928. Houve 7 erros de classificação, onde a classe CTC 04 foi incorretamente prevista como RB966928, resultando em uma taxa de erro de 2,5% para essa classe.
Esses resultados confirmam que o modelo é confiável para identificar variedades de cana-de-açúcar, reduzindo tanto os erros de falta de detecção quanto as classificações incorretas. Essa precisão é especialmente importante no contexto agrícola, onde uma identificação correta das variedades pode influenciar diretamente as decisões de manejo e melhorar a eficiência das operações no campo.
4.2 DESEMPENHO DO MODELO AO LONGO DAS ÉPOCAS
Os gráficos de Precisão e Perda ao longo das épocas são essenciais para analisar o progresso do aprendizado do modelo, oferecendo informações sobre como ele está se adaptando aos dados de treino e validação ao longo das iterações (épocas). Estes gráficos auxiliam na verificação se o modelo está aprendendo corretamente e conseguindo generalizar bem para dados que não foram vistos.
4.2.1 ACURÁCIA DE TREINAMENTO E VALIDAÇÃO POR ÉPOCA
O gráfico de Acurácia de Treinamento e Validação mostra a progressão da taxa de acerto do modelo durante as épocas. Nele, pode-se notar que a precisão de treinamento cresce rapidamente nas primeiras épocas, sugerindo que o modelo está assimilando os padrões dos dados. A precisão de validação aumenta de maneira similar, atingindo valores próximos a 100% e permanecendo estável nas últimas épocas (Figura 13).
Figura 13 – Precisão treinamento e Validação por Época
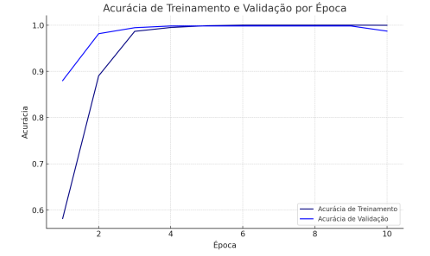
Fonte: (O autor, 2024)
Esse comportamento é um sinal encorajador, pois demonstra que o modelo está se generalizando adequadamente para o conjunto de validação. A constância da acurácia de validação em níveis altos indica que o modelo foi capaz de apreender as características das classes CTC 04 e RB966928 de forma eficiente, reduzindo a probabilidade de overfitting, que aconteceria se a acurácia de validação começasse a diminuir enquanto a acurácia de treinamento seguisse aumentando.
4.2.2 PERDA DE TREINAMENTO E VALIDAÇÃO POR ÉPOCA
O gráfico de Perda de Treinamento e Validação exibe a diminuição do erro do modelo ao longo das épocas. Nota-se que, a princípio, a perda é consideravelmente elevada, mas reduz-se rapidamente nas primeiras épocas, alcançando níveis baixos e estáveis nas últimas iterações. A perda de treinamento diminui continuamente até se estabilizar perto de zero, enquanto a perda de validação também mostra uma queda constante, permanecendo baixa e estável ao longo do tempo (Figura 14).
Figura 14 – Perda de Treinamento e Validação por Época
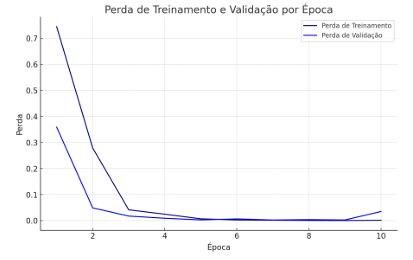
Fonte: (O autor, 2024)
Esse padrão sugere que o modelo está conseguindo reduzir o erro tanto no conjunto de treinamento quanto no de validação. A consistência da perda de validação durante as épocas indica que o modelo está bem ajustado aos dados, sem evidências de overfitting. A reduzida perda no conjunto de validação sugere que o modelo está realizando previsões corretas e constantes em dados desconhecidos, fortalecendo sua habilidade de generalização.
5 CONSIDERAÇÕES FINAIS
O modelo desenvolvido nesta pesquisa se mostrou uma ferramenta promissora para a identificação automatizada de variedades de cana-de-açúcar. A alta precisão e confiabilidade do modelo destacam seu potencial para atender demandas específicas do setor agrícola, onde a identificação rápida e correta de variedades é crucial para uma tomada de decisão eficiente.
A utilização de técnicas de aprendizado profundo na classificação de variedades de cana-de-açúcar oferece um avanço significativo em termos de precisão e eficiência, reduzindo o tempo gasto e auxiliando o laudo de especialistas. Esse tipo de tecnologia pode transformar práticas agrícolas tradicionais, automatizando um processo que antes demandava tempo e recursos humanos intensivos. A identificação por meio da IA possibilita o monitoramento contínuo das variedades em campo, facilitando intervenções mais rápidas e adequadas às necessidades específicas de cada tipo de cana-de-açúcar.
A expectativa é que, ao ser aplicada em escala, essa tecnologia contribua para o aumento da produtividade e otimização dos recursos nas plantações, tendo em vista que as características morfológicas variam de acordo com o solo plantado e a idade da planta. O reconhecimento automatizado pode auxiliar na implementação de práticas agrícolas mais sustentáveis, reduzindo o desperdício e melhorando o aproveitamento das colheitas. Além disso, ao fornecer uma forma eficiente de monitoramento, o modelo pode contribuir para o controle e planejamento do ciclo produtivo, identificando variedades mais adaptadas a condições ambientais específicas, o que é crucial em tempos de mudanças climáticas.
Portanto, o desenvolvimento de um modelo robusto e de fácil aplicabilidade como o proposto não só agrega valor à pesquisa científica, como também oferece benefícios práticos para agricultores e empresas do setor agrícola. A adoção de soluções baseadas em inteligência artificial pode ajudar a construir um setor agrícola mais inovador e preparado para os desafios futuros, promovendo uma produção mais sustentável e adaptada às demandas contemporâneas.
REFERÊNCIAS BIBLIOGRÁFICAS
BRADSKI, G.; KAEHLER, A. Learning OpenCV: Computer Vision with the OpenCV Library. 1. ed. Sebastopol: O’Reilly Media, 2008.
CANAONLINE. Conheça o Valdir, o identificador de variedades. São Paulo, 30 abr. 2015. Disponível em: https://www.canaonline.com.br/conteudo/conheca-valdir-o-identificador-devariedades.html. Acesso em: 22 abr. 2024.
CHEN, H. et al. Artificial Intelligence in Agro-Food Systems: A Review. arXiv preprint, 2023. Disponível em: https://arxiv.org/abs/2305.01899. Acesso em: 3 nov. 2024.
DIDÁTICA TECH. O que é Keras e para que serve?. Disponível em: https://didatica.tech/oque-e-keras-para-que-serve/. Acesso em: 1 jun. 2024.
FERNANDES, A. C.; VENDRAMINI, A.; LOURENCO, D. de M.; SANTOS FILHO, O. T. Boletim Técnico Copersucar: Edição Especial. São Paulo: Cooperativa de Produtores de Cana, Açúcar e Álcool do Estado de São Paulo Ltda. (COPERSUCAR), 1991. 26 p.
IBM. Deep Learning. Disponível em: https://www.ibm.com/br-pt/topics/deep-learning. Acesso em: 1 jun. 2024.
JOHNSON, D. What is TensorFlow? Atualizado em 26 dez. 2023. Disponível em: https://www.guru99.com/what-is-tensorflow.html. Acesso em: 22 abr. 2024.
LUTZ, M. Learning Python. Sebastopol: O’Reilly Media, 2013.
MARAFON, A. C. Análise quantitativa de crescimento em cana-de-açúcar: uma introdução ao procedimento prático. Aracaju: Embrapa Tabuleiros Costeiros, 2012. 29 p. (Documentos / Embrapa Tabuleiros Costeiros, ISSN 1678-1953; 168). Disponível em: http://www.cpatc.embrapa.br/publicacoes_2012/doc_168.pdf.
MASSRUHÁ, S. M. F. S.; LEITE, M. A. A.; LUCHIARI JUNIOR, A.; ROMANI, L. A. S. Tecnologias da informação e comunicação e suas relações com a agricultura. Brasília, DF: Embrapa, 2014.
PEDREGOSA, F. et al. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, v. 12, p. 2825–2830, 2011.
RAMOS, V. A biblioteca os do Python. Python Academy, 7 jul. 2023. Atualizado em: 7 jul. 2023. Disponível em: https://pythonacademy.com.br/blog/a-biblioteca-os-dopython#descobrindo-informa%C3%A7%C3%B5es-do-sistema. Acesso em: 1 jun. 2024.
SANTIAGO JR., L. Entendendo a biblioteca NumPy. Publicado em 30 set. 2018. Disponível em: https://medium.com/ensina-ai/entendendo-a-biblioteca-numpy-4858fde63355. Acesso em: 1 jun. 2024.
SANTANA, B. Python: O que é?. Publicado em 7 mar. 2024. Disponível em: https://www.hostinger.com.br/tutoriais/python-o-que-e. Acesso em: 22 abr. 2024.
SILVA, T. DA. Importância da análise foliar na cana-de-açúcar. 3RLAB, 2024. Disponível em: https://www.3rlab.com.br/importancia-da-analise-foliar-na-cana-de-acucar/. Acesso em: 1 jun. 2024.
TEIXEIRA, J. DE F. O que é Inteligência Artificial. São Paulo: Editora Brasiliense, 1990.
ZENDESK. Inteligência artificial no dia a dia. Atualizado em: 12 dez. 2023. Disponível em: https://www.zendesk.com.br/blog/inteligencia-artificial-no-dia-a-dia/. Acesso em: 3 nov. 2024.
1 Graduando do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. Email: lmdcosta@uniara.edu.br
2 Orientador. Docente Curso de Sistema de Informação da Universidade de Araraquara- UNIARA. AraraquaraSP. E-mail: fddallilo@uniara.edu.br
3 Coorientador. Docente Curso de Sistema de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP.E-mail: fflorian@uniara.edu.br