PROBLEMATIC OF CUSTOMER SUPPORT SERVICE BY CHATBOTS: AN EMPIRICAL STUDY OF GPT-4
REGISTRO DOI: 10.69849/revistaft/ch10202412100535
Gustavo Mendes Xavier
Orientadora: Leandra Cristina Cavina Piovesan Soares
Resumo
O presente artigo é um estudo empírico da base de dados do Banco Inter e um estudo de caso da startup de software Phibo, focado na sua capacidade de resolução de problemas, avaliando suas funcionalidades em comparação com as capacidades de chatbots e robôs de serviço existentes no cenário do atendimento ao cliente. A metodologia empregada neste estudo, foi de abordagem mista quantitativa e qualitativa, conduzida por meio do estudo de caso da empresa Phibo e Banco Inter. O estudo mostrou um desempenho significativamente superior em várias métricas-chave em comparação com seus predecessores e com outros sistemas de Inteligência Artificial (IA) comumente utilizados para suporte ao cliente. Além disso, a pesquisa identificou que embora o GPT-4 tenha alcançado um desempenho impressionante, questões como ética na IA, transparência nos processos de tomada de decisão e a necessidade contínua de treinamento e atualização dos modelos permanecem como desafios críticos a serem abordados no futuro.
Palavras-chave: Atendimento ao Cliente, Transformador Preditivo Pré-treinado 4 (GPT-4), Inteligência Artificial, Satisfação do Cliente.
Abstract
The present article is an empirical study of Banco Inter’s database and a case study of a software startup called Phibo, focused on its problem-solving capacity. It evaluates its functionalities in comparison with the capabilities of existing chatbots and service robots in the customer service scenario. The methodology employed in this study was a mixed quantitative and qualitative approach, conducted through case studies of the companies Phibo and Banco Inter. The study showed significantly superior performance in various key metrics compared to its predecessors and other Artificial Intelligence (AI) systems commonly used for customer support. Furthermore, the research identified that although GPT-4 has achieved impressive performance, issues such as AI ethics, transparency in decision-making processes, and the continuous need for training and updating the models remain critical challenges to be addressed in the future.
Keywords: Customer Service, Generative Pretrained Transformer 4 (GPT-4), Artificial Intelligence, Customer Satisfaction.
1. INTRODUÇÃO
A inteligência artificial (IA) está revolucionando o atendimento ao cliente, prometendo maior eficiência e suporte 24/7 (MAKRIDAKIS, 2017; SHARMA et al., 2023). Entretanto, muitas empresas enfrentam dificuldades em equilibrar a eficiência operacional com a satisfação do cliente (RASUL et al., 2023). Modelos avançados de linguagem natural, como o GPT-4, superam IA anteriores na compreensão e resposta às necessidades dos clientes (ARORA, 2023; CRIBBEN & ZEINALI, 2023; LUND & WANG, 2023; KASNECI et al., 2023). Contudo, a adoção dessas tecnologias levanta preocupações sobre a substituição de empregos humanos e implicações éticas (SALLAM, 2023; BRYNJOLFSSON & MCAFEE, 2014). Dreyfus (1972, 1986) argumenta que a IA não pode substituir completamente o julgamento humano em situações que exigem intuição e empatia.
Este estudo explora o impacto do GPT-4 no atendimento ao cliente, com a hipótese de que sua implementação aumentará a eficiência operacional e a satisfação dos clientes em comparação com IA anteriores e o atendimento humano. Realizado na startup Phibo, em Belo Horizonte, Brasil, o estudo utiliza métodos experimentais e abordagens mistas de pesquisa. Foca em três pilares: a engenharia de prompt, a implementação prática na Phibo e as razões técnicas que diferenciam a IA generativa (IAG) das soluções tradicionais, destacando a personalização e eficiência que aprimoram a experiência do usuário.
Ao fornecer uma visão abrangente sobre o papel transformador do GPT-4 no atendimento ao cliente, este trabalho contribui com insights valiosos para pesquisas futuras.
2. INTELIGÊNCIA ARTIFICIAL GENERATIVA
A Inteligência Artificial Generativa (IAG) utiliza Redes Neurais Profundas (DNNs) e Redes Generativas Adversárias (GANs) para gerar dados que imitam conjuntos de treinamento (GOODFELLOW et al., 2014; CARLEO et al., 2019). Um exemplo notável é o GPT-4 da OpenAI, que sucedeu o GPT-3, com 175 bilhões de parâmetros, embora o número exato do GPT-4 não tenha sido divulgado (BROWN et al., 2020).
A IAG possui aplicações significativas na educação, com assistentes de ensino personalizados (RASUL et al., 2023; RUDOLPH; TAN; TAN, 2023; SALLAM, 2023); na saúde, para análise de dados e personalização de tratamentos (ARORA, 2023; SALLAM, 2023; TANG et al., 2023; QI; ZHU; WU, 2023); e na ciência da informação, para análise de grandes volumes de dados (LUND; WANG, 2023).
Seus diferenciais técnicos incluem (1) o uso de GANs para geração de conteúdo (GOODFELLOW et al., 2014); (2) avanços em hardware computacional, como GPUs (BRYNJOLFSSON; MCAFEE, 2014); (3) acesso a grandes volumes de dados para treinamento (BROWN et al., 2020); e (4) integração de métodos supervisionados e não supervisionados (DOSHI-VELEZ; KIM, 2017).
Apesar do potencial transformador em diversos setores, o desenvolvimento da IAG exige atenção a desafios éticos e técnicos para assegurar sua implementação responsável e benéfica.
3. RAZÕES TÉCNICAS PELAS QUAIS A IAG ESTÁ SE DIFERENCIANDO DAS DEMAIS
A Inteligência Artificial Generativa (IAG) distingue-se de outras formas de IA por empregar redes neurais profundas, como GANs e VAEs, para modelar a distribuição conjunta dos dados e gerar novos conteúdos semelhantes (GOODFELLOW et al., 2014; GÓMEZ-BOMBARELLI et al., 2018; CARLEO et al., 2019). Em contraste, a IA supervisionada foca na previsão de variáveis alvo (BURLINA et al., 2018), a IA não supervisionada busca padrões ocultos em dados não rotulados (DOSHI-VELEZ; KIM, 2017), e o aprendizado por reforço opera por tentativa e erro para maximizar recompensas (BRYNJOLFSSON; MCAFEE, 2014).
A IAG enfrenta seis desafios principais: (1) viés de dados que reflete preconceitos nos dados de treinamento (ZHAO et al., 2017); (2) questões éticas, especialmente no contexto de deepfakes (CHESNEY; CITRON, 2019); (3) problemas de direitos autorais relacionados a conteúdo gerado por IA (ABBOTT, 2016); (4) preocupações sobre a substituição de empregos (BRYNJOLFSSON; MCAFEE, 2014); (5) falta de transparência e explicabilidade nos modelos (DOSHI-VELEZ; KIM, 2017); e (6) limitações na compreensão semântica e na experiência humana (Dreyfus, 1992).
Esses desafios e distinções possuem implicações significativas para as aplicações específicas de cada tipo de IA, ressaltando a importância de considerar tanto o potencial quanto às limitações da IAG em seu desenvolvimento e implementação (MAKRIDAKIS, 2017).
4. ESTUDO DE CASO DA EMPRESA PHIBO
A Phibo, startup de software de gestão em Belo Horizonte, implementou um chatbot baseado no GPT-4 para otimizar seu atendimento ao cliente (PHIBO, 2024). Chatbots têm melhorado a satisfação dos usuários no atendimento ao cliente (BRANDTZAEG; FØLSTAD, 2017). O chatbot da Phibo resolve problemas simples autonomamente e direciona casos complexos a atendentes humanos, ajustando-se e melhorando com cada interação (CHUNG et al., 2020). Isso aprimora a personalização e a experiência do usuário (VAN ESCH; BLACK; FEROLIE, 2019), refletindo a tendência crescente do uso de inteligência artificial para interações mais naturais e eficazes no atendimento ao cliente (SHAWAR; ATWELL, 2007).
5. METODOLOGIA
Este estudo adota uma abordagem mista, combinando métodos quantitativos e qualitativos, para analisar a implementação do GPT-4 no atendimento ao cliente, com foco em dois estudos de caso: a startup Phibo e o Banco Inter. Para fundamentação teórica, foram realizados levantamentos bibliográficos que subsidiaram a definição das metodologias e a aplicação prática das técnicas (GIL, 2008).
Na primeira etapa, o estudo comparou o GPT-4 com outras ferramentas de IA, analisando interações reais entre clientes, o modelo e representantes humanos. Foram coletados dados sobre tempo de resposta, resolução no primeiro contato e satisfação dos clientes, comparando os resultados antes e depois da implementação do GPT-4.
No caso do Banco Inter, o estudo envolveu testes com o chatbot do banco (“Babi”), simulando interações reais para avaliar a usabilidade, eficiência no processamento de demandas e adequação das respostas. As Figuras 4, 5 e 6 ilustram interações problemáticas, evidenciando falhas de personalização e compreensão de solicitações complexas. Esses testes foram comparados às respostas do GPT-4, focando em tempo de resposta, clareza na comunicação e a frustração do cliente.
Além disso, a conformidade regulatória e a segurança dos dados foram avaliadas para garantir que as soluções respeitassem as exigências do setor financeiro. Os dados foram coletados com rigor e a privacidade dos participantes foi assegurada, permitindo uma análise detalhada do potencial e das limitações do GPT-4 no atendimento ao cliente.
6. IMPLEMENTAÇÃO PRÁTICA DA TECNOLOGIA NA STARTUP PHIBO
A implementação prática da tecnologia na startup Phibo começou com a configuração do GPT-4 para buscar respostas apenas na base de conhecimento disponível no sistema da empresa, hospedado em Ajuda (2024). Para isso, foi utilizado o processo de web crawling, uma técnica que automatiza a coleta de informações de páginas da web, descrita por Olston e Najork (2010) como essencial para a extração de dados estruturados.
O crawling funciona por meio de agentes de software, chamados “crawlers” ou “spiders”, que navegam automaticamente entre URLs para capturar informações relevantes. Essa técnica permitiu que o GPT-4 acessasse dados do site da Phibo de forma estruturada e contextualizada, garantindo que as respostas fornecidas aos usuários fossem precisas e alinhadas ao sistema da empresa.
Para desenvolver um crawler eficaz, é necessário seguir uma sequência estruturada de etapas, conforme descrito por Olston e Najork (2010):
1. Identificação de URLs e Semeação: O processo inicia-se com a definição de um conjunto de URLs de partida, conhecidas como “seeds“. Essas seeds agem como pontos iniciais de onde o crawler começa sua jornada. A escolha dessas URLs iniciais é crítica, pois define o escopo e a relevância do conteúdo a ser extraído.
2. Requisições HTTP e Acesso ao Conteúdo: Após a definição das seeds, o crawler faz requisições HTTP para acessar o conteúdo dessas páginas. Este passo envolve lidar com aspectos técnicos como gestão de tempo de espera (timeout), tratamento de erros, e respeito às regras definidas no arquivo robots.txt das páginas web, que especificam as diretrizes de crawling para cada site.
3. Análise de Conteúdo: Uma vez que o conteúdo é acessado, o crawler necessita analisar o HTML retornado. Esta análise envolve a interpretação da estrutura do documento, identificando onde a informação desejada está localizada na página. Ferramentas como Beautiful Soup e Selenium em Python são frequentemente utilizadas para essa tarefa, permitindo a navegação pela estrutura DOM (Document Object Model) da página e a extração de dados específicos.
4. Extração e Armazenamento de Informações: Finalmente, os dados de interesse são extraídos do conteúdo da página. A natureza desses dados pode variar amplamente, desde textos simples até informações estruturadas como tabelas e listas. Os dados coletados são então armazenados em um formato adequado para análise posterior, comumente em bancos de dados ou sistemas de arquivos.
Uma abordagem eficaz para alcançar respostas mais pertinentes é o uso de técnicas de embedding para a seleção da resposta mais adequada a partir de um conjunto de dados previamente coletados.
Ao integrar o modelo GPT-4 para auxiliar no suporte ao cliente da startup Phibo, foi identificada a necessidade de recorrer a uma técnica avançada de inteligência artificial chamada “embedding“. No cenário do atendimento ao cliente, os embeddings são essenciais para compreender e selecionar as respostas mais relevantes em relação às consultas dos usuários, garantindo que as interações sejam tanto precisas quanto contextualmente adequadas.
Figura 1. Retrata o processo de embeddings vetoriais
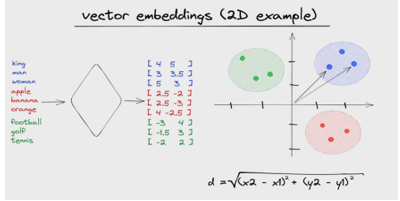
Fonte: (ASSEMBLYAI, 2023)
A Figura 1 apresenta representações vetoriais de dados que capturam a semântica e os contextos intrínsecos em um espaço de dimensões reduzidas. No domínio da linguagem natural, os embeddings transformam palavras ou frases em vetores numéricos, mantendo, na medida do possível, as relações semânticas entre elas.
Para a seleção ótima de respostas, o processo pode ser conceituado da seguinte maneira:
Figura 2. Modelagem do fluxo
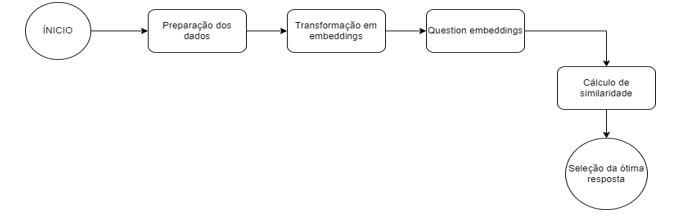
O fluxograma demonstrado na figura 2, apresenta as etapas para a escolha da seleção ótima das respostas que compreendeu:
- Preparação dos Dados: Primeiramente, é preciso coletar um conjunto de possíveis respostas, oriundas de interações prévias ou de bases de conhecimento da empresa. Este conjunto, após ser crawlado, serve como base de treinamento e validação.
- Transformação em Embeddings: Cada resposta no conjunto de dados é transformada em um vetor numérico utilizando um modelo de embedding, como Word2Vec, FastText ou BERT. Isso resulta em uma representação densa que capta a semântica das respostas.
- Question Embedding: Quando uma consulta é feita pelo cliente via WhatsApp, essa pergunta é imediatamente transformada em seu respectivo vetor (embedding) usando o mesmo modelo.
- Cálculo de Similaridade: Com o vetor da pergunta e os vetores das respostas em mãos, calcula-se a similaridade (por exemplo, através da similaridade de cosseno) entre a pergunta e todas as respostas possíveis. Isso gera uma lista de respostas classificadas pela sua relevância.
- Seleção da Resposta Ótima: A resposta com a maior similaridade é então escolhida como a mais adequada para ser enviada ao cliente. Dependendo do grau de confiança exigido, pode-se optar por uma revisão humana ou ajustes subsequentes.
- Feedback e Ajustes: Com base nas interações subsequentes do cliente ou feedbacks explícitos, o sistema pode aprender e ajustar seus embeddings e métodos de seleção, tornando-se cada vez mais preciso com o tempo.
O uso de embeddings, portanto, fornece uma metodologia robusta para navegar pelo vasto espaço de possíveis respostas e selecionar aquelas que são mais relevantes para as consultas dos clientes.
7. ENGENHARIA DE PROMPT E O PAPEL DE AFUNILAR A ATUAÇÃO DO GPT-4
A engenharia de prompt consiste na criação cuidadosa de comandos para direcionar modelos de linguagem como o GPT-4 a gerar respostas específicas e desejadas. Devido à sua capacidade de compreender e gerar linguagem natural, o GPT-4 é uma solução promissora para o atendimento ao cliente (BROWN et al., 2020).
O primeiro passo é definir um contexto claro para o modelo, garantindo que suas respostas estejam alinhadas ao domínio específico. A qualidade da resposta depende da natureza e especificidade do prompt; por exemplo, prompts vagos como “Ajude o usuário” podem resultar em respostas genéricas. Prompts mais detalhados que solicitam racionalizações das respostas podem oferecer maior clareza e uma camada extra de verificação, permitindo avaliar a precisão das respostas (DOSHI-VELEZ; KIM, 2017).
Outro aspecto importante é o “prompt base”, que cria um contexto adequado para o modelo e influencia a abordagem do GPT-4. Ao configurar o modelo como um assistente técnico especializado, ele é direcionado a responder dentro desse contexto específico. Técnicas de engenharia de prompt podem refinar as interações, ajustando a profundidade e o estilo das respostas.
Em contextos de atendimento ao cliente onde o histórico de interações está disponível, os prompts podem ser configurados para considerar essas informações, garantindo respostas mais personalizadas e contextualizadas. Assim, a engenharia de prompt é essencial para otimizar o GPT-4 em tarefas específicas, como o suporte ao cliente.
8. RESULTADOS
A promessa de utilizar chatbots e inteligência artificial (IA) no suporte ao cliente é atraente como respostas rápidas, disponibilidade 24/7 e redução de custos operacionais. No entanto, em alguns casos, essa promessa não se concretiza totalmente, resultando em experiências frustrantes para os usuários.
Um exemplo claro disso é o uso de chatbots em instituições bancárias, onde as expectativas de eficiência e personalização do atendimento frequentemente não são atendidas. Estudos como os de Buhalis e Law (2008) mostram que os chatbots ainda enfrentam dificuldades em lidar com consultas complexas e fornecer um atendimento realmente personalizado. O principal desafio é a falta de capacidade desses sistemas em entender as nuances e especificidades das solicitações dos clientes. Em muitos casos, os usuários são forçados a escolher entre opções pré-definidas e limitadas, como “1”, “2” ou “3”, o que nem sempre corresponde às suas necessidades reais. Isso resulta em um ciclo frustrante, no qual o cliente não consegue ser atendido de forma eficaz.
Além disso, quando os chatbots não conseguem identificar corretamente o problema do cliente, eles frequentemente repetem as mesmas opções, o que agrava ainda mais a insatisfação. Essa repetição não apenas reflete a ineficiência do sistema, mas também a falta de personalização e empatia, essenciais no atendimento ao cliente, especialmente em setores sensíveis como o bancário. A Figura 3, apresenta exemplos reais de atendimentos do Banco Inter, ilustrando essas falhas e a ineficiência do processo.
Figura 3. Caso 1:Interação com o chatbot “Babi”
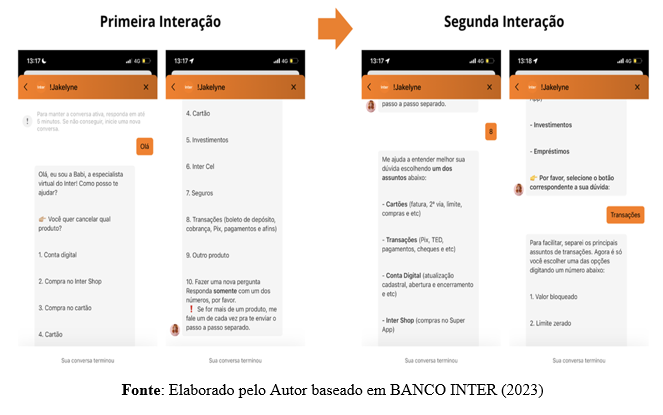
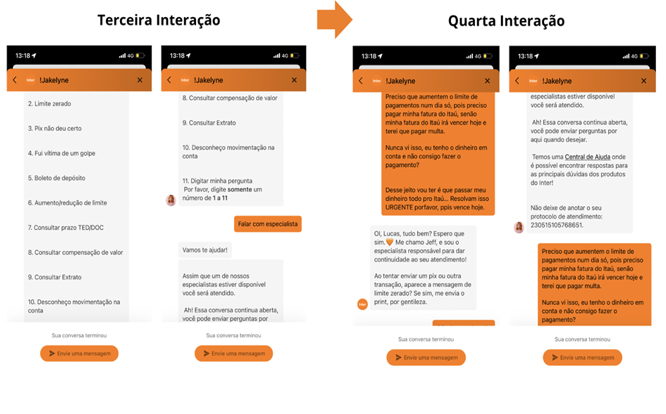
A Figura 4 retrata a continuação do atendimento Caso 1 via chatbot do Banco Inter da Figura 3. Nesta continuação do diálogo percebe-se que, quando repassado a um especialista humano, o usuário de fato expõe toda sua situação problema, que realmente representa algo extremamente mais complexo do que era retratado pelas opções pré-fixadas em 1, 2, 3 […], 8.
Figura 4. Continuação do atendimento com o chatbot “Babi”
Fonte: Elaborado pelo Autor baseado em BANCO INTER (2023)
Como pode-se perceber na Figura 5, tem-se um diálogo em que a IA do banco chamada “Babi” inicia o atendimento e faz uma pergunta ao usuário solicitando qual a dúvida, em seguida o usuário expõe, e de imediato a Babi responde que não conseguiu entender e solicita uma nova tentativa.
Figura 5. Caso 2: Retrata um atendimento via chatbot do Banco Inter
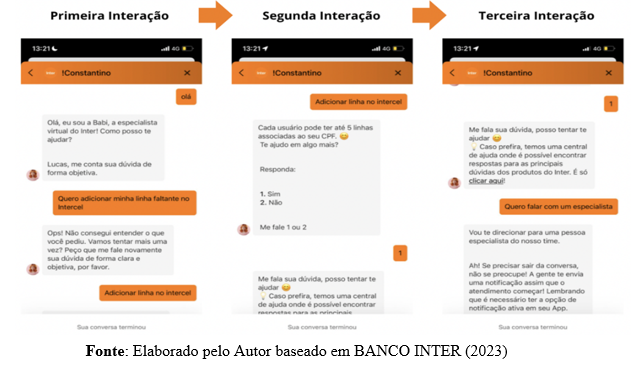
Fonte: Elaborado pelo Autor baseado em BANCO INTER (2023)
Hubert Dreyfus (1992) argumenta que, apesar de modelos como o GPT-4 gerarem textos coerentes, eles carecem de uma compreensão profunda e experiência vivida. Embora o GPT-4 possa simular compreensão, ele não possui a capacidade de entender o mundo de forma contextualizada. Por exemplo, ao ser solicitado a descrever a sensação de caminhar sob a chuva, o modelo respondeu de forma coerente, mas sem uma verdadeira compreensão da experiência, como mostrado na Figura 6.
Figura 6. Resposta do GPT ao prompt

Fonte: Elaborado pelo Autor baseado em OpenAI (2023)
No processo de adaptar o modelo GPT-4 para fornecer suporte autônomo aos clientes, identificou-se a necessidade de ajustar a linguagem, o tratamento e as estruturas de resposta para torná-las mais humanizadas. A engenharia de prompt desempenhou um papel essencial nesse aspecto.
Um elemento crucial nesse contexto é o “prompt base”, que atua como uma lente direcionadora para o vasto conhecimento e capacidades do modelo. Seu poder reside em criar um contexto apropriado, influenciando a abordagem e a perspectiva adotadas pelo GPT-4 nas respostas. Por exemplo, ao definir o modelo como um assistente especializado em suporte técnico para eletrônicos, ele se concentra nesse domínio específico. A partir disso, técnicas de engenharia de prompt podem refinar ainda mais as interações, ajustando a especificidade, profundidade e estilo das respostas. No caso da Phibo, uma startup de software de gestão, o prompt base foi adaptado para direcionar o modelo conforme suas necessidades específicas.
Figura 7. Teste de Prompt para configurar um chatbot de atendimento

Fonte: Elaborado pelo Autor baseado em OpenAI (2023)
O texto apresenta um exemplo de prompt (Figura 7) utilizado para configurar um chatbot de atendimento, instruindo o modelo a agir como um agente de suporte de uma startup de software de gestão. O chatbot deve fornecer respostas baseadas exclusivamente nas informações fornecidas pelo sistema e, caso não possua a resposta, deve dizer: “Certo, entendi! Vou te repassar para o departamento responsável, aguarde um instante.” Além disso, é enfatizado que o modelo não deve inventar informações nem responder a perguntas fora das fontes de conhecimento fornecidas.
A natureza iterativa da engenharia de prompt é destacada como fundamentalmente experimental, exigindo ajustes e refinamentos para alcançar a eficácia desejada. Instruções como “Responda de forma concisa e direta” podem ser incorporadas para manter as respostas focadas e objetivas.
O texto enfatiza as diferenças entre o comportamento do GPT-4 e dos bots tradicionais. Enquanto o ChatGPT busca resolver as demandas de forma direta e objetiva, bots convencionais tendem a seguir fluxos pré-determinados, limitando a resolução eficiente de problemas complexos, conforme demonstrado nas Figuras 3 e 4. Esse contraste evidencia a vantagem da abordagem baseada em inteligência artificial, onde a combinação de prompts bem projetados e um modelo robusto resulta em uma experiência mais fluida e eficiente para o usuário.
Testes de interação demonstraram que o GPT-4 apresenta um comportamento mais dinâmico e adaptável, permitindo que as respostas evoluam conforme o contexto da conversa e as necessidades específicas do cliente. Essa característica é especialmente relevante no cenário da Phibo, onde personalização e agilidade são fatores críticos para o sucesso. Os testes realizados ilustram como o GPT-4, com base no prompt adaptado, consegue atender às demandas de forma mais eficiente e personalizada, proporcionando uma experiência superior no suporte aos clientes.
Figura 8: Testes Práticos com Chatbot Configurado para o Sistema Phibo

Fonte: Elaborado pelo autor baseado em ChatGPT (2024)
Figura 9: Testes Práticos com Chatbot Configurado para o Sistema Phibo
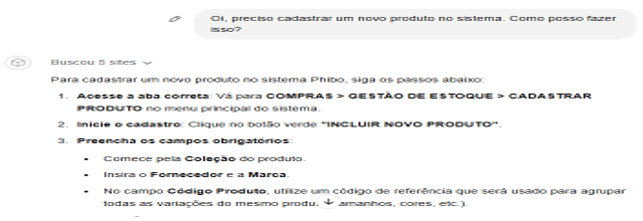
Fonte: Elaborado pelo autor baseado em ChatGPT (2024)
O texto destaca como o GPT-4 se diferencia de bots tradicionais ao fornecer instruções claras, objetivas e adaptadas ao contexto do sistema Phibo. Enquanto soluções convencionais se limitam a fluxos predefinidos, o GPT-4 demonstra flexibilidade ao abordar diversas demandas, oferecendo respostas detalhadas e organizadas passo a passo em tarefas como consulta de vendas, importação de notas fiscais XML e cadastro de produtos.
Essa capacidade de personalização e agilidade na entrega de informações reforça a experiência superior proporcionada pelo GPT-4. No ambiente da Phibo, onde eficiência no suporte e clareza nos processos são essenciais, o modelo se destaca por oferecer um atendimento dinâmico e focado nas necessidades específicas do usuário, garantindo maior assertividade na resolução de problemas e interações mais fluidas.
Além disso, em cenários de atendimento ao cliente com acesso ao histórico de interações, os prompts podem ser configurados para considerar essas informações, garantindo respostas contextualizadas e personalizadas. Em conclusão, a engenharia de prompt é uma ferramenta essencial para configurar o GPT-4 em tarefas específicas como suporte ao cliente, permitindo moldar as respostas do modelo e assegurando eficiência, relevância e precisão em aplicações práticas.
9. CONCLUSÃO
Este estudo empírico comparou a eficácia do GPT-4 com outros chatbots no atendimento ao cliente, constatando que o GPT-4 apresenta desempenho significativamente superior em métricas-chave. Destacou-se na compreensão de contextos complexos e no fornecimento de respostas mais precisas e relevantes, resultando em interações mais fluidas e satisfatórias e minimizando a necessidade de intervenção humana. Sua capacidade de personalização e adaptação ao estilo de comunicação do cliente contribuiu para maior satisfação e menor taxa de abandono de conversas.
Enquanto chatbots anteriores ofereceram contribuições valiosas, eles enfrentaram desafios significativos, como falta de compreensão contextual e respostas pouco personalizadas, o que impactou negativamente sua eficácia e gerou frustração nos usuários. O estudo também identificou que, apesar do desempenho impressionante do GPT-4, persistem desafios relacionados à ética na IA, transparência nos processos de tomada de decisão e necessidade contínua de treinamento e atualização dos modelos. A integração de feedback humano é apontada como uma área promissora para melhorar ainda mais a precisão das respostas do GPT-4 em pesquisas futuras.
Conclui-se que o GPT-4 reforça seu papel transformador no atendimento ao cliente, destacando suas capacidades avançadas em relação aos predecessores. Embora existam desafios a serem enfrentados, o futuro da IA no suporte ao cliente parece cada vez mais promissor com o desenvolvimento contínuo dessas tecnologias.
REFERÊNCIAS
ABBOTT, R. I think, therefore I invent: creative computers and the future of patent law. BCL Rev., HeinOnline, v. 57, p. 1079, 2016.
ARORA, A. The promise of large language models in health care. The Lancet, Elsevier, v. 401, n. 10377, p. 641, 2023.
Asaro, P. (2020). AI Ethics. In The Stanford Encyclopedia of Philosophy.
ASSEMBLYAI. Vector Embeddings. [S.l.]: YouTube, 2023. Disponível em: https://www.youtube.com/watch?v=dN0lsF2cvm4. Acesso em: 31 ago. 2024.
BROWN, T. et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, v. 33, p. 1877–1901, 2020.
BRYNJOLFSSON, E.; MCAFEE, A. The second machine age: Work, progress, and prosperity in a time of brilliant technologies. [S.l.]: WW Norton & Company, 2014.
BURLINA, P. M. et al. Use of deep learning for detailed severity characterization and estimation of 5-year risk among patients with age-related macular degeneration. JAMA Ophthalmology, American Medical Association, v. 136, n. 12, p. 1359–1366, 2018.
BRANDTZAEG, P. B.; FØLSTAD, A. Why people use chatbots. In: International Conference on Internet Science. Springer, Cham, 2017. p. 377-392.
BANCO INTER. Banco Inter. Disponível em: <https://www.bancointer.com.br/\>. Acesso em: 20 nov. 2023.
CARLEO, G. et al. Machine learning and the physical sciences. Reviews of Modern Physics, APS, v. 91, n. 4, p. 045002, 2019.
Central de Ajuda | Phibo. Disponível em: <https://ajuda.phibo.site/>. Acesso em: 5 dez. 2024.
ChatGPT. Disponível em: <https://chatgpt.com/g/g-674e6112bd348191a0b6078a687d210e-phibo-chat> Acesso em: 3 dez. 2024
CHESNEY, B.; CITRON, D. Deep fakes: A looming challenge for privacy, democracy, and national security. Calif. L. Rev., HeinOnline, v. 107, p. 1753, 2019.
CHUNG, M.; KO, E.; JOUNG, H.; KIM, S. J. Chatbot e-service and customer satisfaction regarding luxury brands. Journal of Business Research, v. 117, p. 587-595, 2020.
Crawford, K. (2017). The Trouble with Bias, NIPS Keynote.
Cribben, I., & Zeinali, Y. (2023). The Benefits and Limitations of GPT-4 in Business Education and Research: A Focus on Management Science, Operations Management and Data Analytics. SSRN.
Davenport, T., Guha, A., Grewal, D., & Bressgott, T. (2020). How AI Will Change the Way We Make Decisions. Harvard Business Review.
DOSHI-VELEZ, F.; KIM, B. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608, 2017.
Dreyfus, H. L. (1991). Being-in-the-World: A Commentary on Heidegger’s Being and Time, Division I. MIT Press.
Dreyfus, H. L. (1992). What Computers Still Can’t Do: A Critique of Artificial Reason. MIT Press.
DREYFUS, H. L. Mind over machine: The power of human intuition and expertise in the era of the computer. 1986.
DREYFUS, H. L. What computers can’t do: The limits of artificial intelligence. 1972.
GÓMEZ-BOMBARELLI, R. et al. Automatic chemical design using a data-driven continuous representation of molecules. ACS Central Science, ACS Publications, v. 4, n. 2, p. 268–276, 2018.
GIL, Antônio Carlos. Métodos e técnicas de pesquisa social. [S.l: s.n.], 2008.
GOODFELLOW, I. et al. Generative adversarial nets. Advances in Neural Information Processing Systems, v. 27, 2014.
KARRAS, T. et al. A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S.l.: s.n.], 2019. p. 4401–4410.
Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., … & Kasneci, G. (2023). GPT-4 for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274.
LUND, B. D.; WANG, T. Chatting about ChatGPT: how may AI and GPT impact academia and libraries? Library Hi Tech News, Emerald Publishing Limited, v. 40, n. 3, p. 26–29, 2023.
MAKRIDAKIS, S. The forthcoming artificial intelligence (AI) revolution: Its impact on society and firms. Futures, Elsevier, v. 90, p. 46–60, 2017.
OORD, A. v. d. et al. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
OpenAI. (2023). GPT-4: An Advanced Language Model by OpenAI. OpenAI Blog. Retrieved from https://openai.com/blog/gpt-4.
PHIBO. Phibo. Disponível em: <https://phibo.com.br/\>. Acesso em: 4 dez. 2024.
QI, X. et al. The promise and peril of ChatGPT in geriatric nursing education: What we know and do not know. [S.l.]: Elsevier, 2023. 100136 p.
RASUL, T. et al. The role of ChatGPT in higher education: Benefits, challenges, and future research directions. Journal of Applied Learning and Teaching, v. 6, n. 1, 2023.
RUDOLPH, J. et al. ChatGPT: Bullshit spewer or the end of traditional assessments in higher education? Journal of Applied Learning and Teaching, v. 6, n. 1, 2023.
SALLAM, M. ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. In: MDPI. Healthcare. [S.l.], 2023. v. 11, n. 6, p. 887.
SHARMA, P. K. et al. An era of ChatGPT: Systematic analysis of utility and challenges. In: IEEE. 2023 2nd International Conference on Edge Computing and Applications (ICECAA). [S.l.: s.n.], 2023. p. 897–902.
Shum, H., He, X., & Li, D. (2018). From Eliza to XiaoIce: Challenges and Opportunities with Social Chatbots. Frontiers of Information Technology & Electronic Engineering.
SHUM, H.; HE, X.; LI, D. From Eliza to XiaoIce: Challenges and Opportunities with Social Chatbots. Frontiers of Information Technology & Electronic Engineering, v. 19, n. 1, p. 10-26, 2018.
SHAWAR, B. A.; ATWELL, E. Chatbots: are they really useful? LDV Forum, v. 22, n. 1, p. 29-49, 2007.
Shum, H., He, X., & Li, D. (2018). From Eliza to XiaoIce: Challenges and Opportunities with Social Chatbots. Frontiers of Information Technology & Electronic Engineering.
TANG, R. et al. Does synthetic data generation of LLMs help clinical text mining? arXiv preprint arXiv:2303.04360, 2023.
VAN ESCH, P.; BLACK, J. S.; FEROLIE, J. Marketing AI recruitment: The next phase in job application and selection. Computers in Human Behavior, v. 90, p. 215-222, 2019.
ZHANG, H. et al. Self-attention generative adversarial networks. In: PMLR. International Conference on Machine Learning. [S.l.: s.n.], 2019. p. 7354–7363.
ZHAO, J. et al. Men also like shopping: Reducing gender bias amplification using corpus-level constraints. arXiv preprint arXiv:1707.09457, 2017.