REGISTRO DOI: 10.5281/zenodo.7301944
Francisco Gabriel de Souza Ferreira, Gabriel da Mota Silva, Luiz Henrique Alves.
Orientador: Prof. Dr. Rogério Lobo
Resumo: O mercado financeiro está em constante evolução no quesito de técnicas de previsão. Com a popularização dos computadores, não tardou para que novas técnicas fossem desenvolvidas para auxiliar os analistas do mercado. Estudos recentes propõem que modelos de inteligência artificial aliados a técnicas já consolidadas de análise, como a análise fundamentalista de ações, podem trazer resultados consistentes para previsão de preço dos ativos. Desse modo, o presente trabalho busca desenvolver um modelo de inteligência artificial utilizando indicadores financeiros trimestrais de 2013 à 2022 de empresas brasileiras listadas na bolsa com parâmetro de comparação o índice Ibovespa. No âmbito de resultados, a carteira recomendada pelo modelo de Random Forest apresenta resultados ligeiramente melhores que o Ibovespa nos dois primeiros trimestres de 2022, com espaço para melhoria de performance na esfera de distribuição de ações na carteira.
Palavras-chave: Machine Learning. Random Forest. Ibovespa.
Stock buy or sell forecast using Machine Learning based on fundamental analysis
Abstract: The financial market is constantly evolving in terms of forecasting techniques. With the popularization of computers, it was not long before new techniques were developed to help market analysts. Recent studies propose that artificial intelligence models combined with already consolidated techniques of analysis, such as the fundamental analysis of shares, can bring consistent results for forecasting asset prices. Thus, the present work seeks to develop an artificial intelligence model using quarterly financial indicators from 2013 to 2022 of Brazilian companies listed on the stock exchange with the Ibovespa index as a benchmark. In terms of results, the portfolio recommended by the Random Forest model presents slightly better results than the Ibovespa in the first two quarters of 2022, with room for improvement in performance in the sphere of distribution of shares in the portfolio.
Keywords: Machine Learning. Random Forest. Ibovespa.
- Introdução
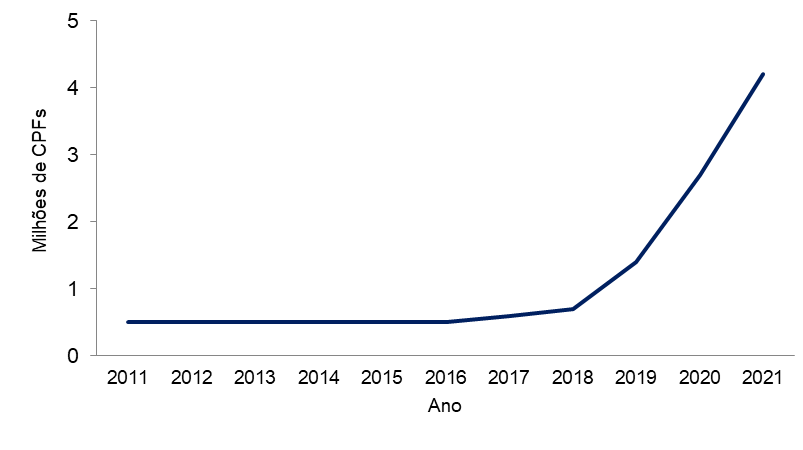
Nos últimos anos a quantidade de brasileiros que buscam ingressar no mercado de ações vem crescendo consideravelmente. Segundo dados da bolsa de valores brasileira, o número de CPFs registrados na B3 passou de 500 mil em 2011 para 4,2 milhões em 2021, um crescimento expressivo de 740% em 10 anos.
Entretanto, por mais que a procura tenha aumentado, investir não é uma tarefa fácil, de acordo com SANTOS (2020) os movimentos do mercado são dinâmicos e caóticos, envolvendo inúmeras variáveis. A alta volatilidade do mercado acionário torna a tarefa de investir muito ariscada devido as suas constantes oscilações de preços. Aspectos como conjuntura macroeconômica e microeconômica, cenário político, situação do mercado de atuação e desempenho operacional das companhias influenciam diretamente nos movimentos dos ativos. A junção desses fatores torna a procura por melhores rentabilidades no mercado um grande desafio.
Para se sobressair no mercado, os investidores necessitam realizar análises criteriosas antes de tomarem suas decisões. Por meio dessas análises, os investidores podem estimar e projetar como serão os desempenhos futuros dos ativos e se anteciparem na compra ou venda para poder alcançar melhores lucros e reduzir riscos.
Todavia, a grande quantidade e variedade de informações acabam por gerar uma dificuldade em conciliar todas essas variáveis, necessitando do poder computacional para processar todas essas informações no intuito de otimizar e automatizar o processo de análise de investimentos, traçando projeções mais assertivas.
Este estudo tem o objetivo de mostrar a importância do uso da tecnologia de nos investimentos, desenvolvendo um modelo de Machine Learning que realizará recomendações de compra e venda de ações a cada trimestre, com base na projeção de crescimento de 61 empresas listadas no índice Ibovespa, utilizando indicadores das demonstrações financeiras dessas empresas com a congregação de métodos estatísticos e algoritmos inteligentes.
A elaboração deste estudo se deu pela revisão bibliográfica de estudos, livros e artigos de autores voltados para inteligência artificial aplicada ao mercado financeiro, bem como sites confiáveis relacionados ao mercado para a obtenção dos dados a serem analisados.
A metodologia deste modelo se deu pela mineração de dados e coleta de indicadores financeiros, seguindo pelo do processamento e transformação dos dados no objetivo de quantificar suas correlações com os preços e desempenho das ações ao longo do tempo. Dados que foram submetidos à algoritmos de Machine Learning.
Definido o algoritmo a ser utilizado, o modelo analisará os indicadores selecionados no processo de mineração de dados, trimestre a trimestre e informará quais ações comprar e vender de acordo com padrões de desempenho históricos.
1.1 Justificativa e problemática
Considerando a intensa dinâmica dos mercados e os inúmeros fatores econômicos que impactam diretamente nos títulos, os investidores estão suscetíveis a sofrerem os efeitos ocasionados pela incerteza dos retornos em suas aplicações.
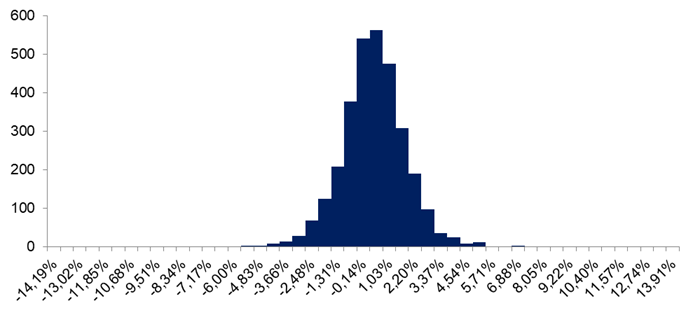
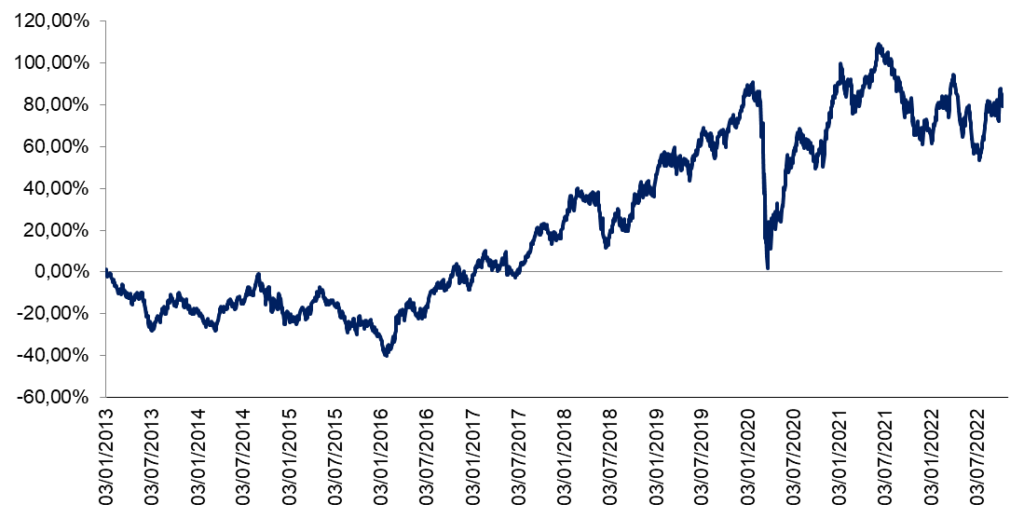
Para Assaf Neto (2018), o risco se caracteriza como a incerteza gerada pela probabilidade do resultado de um investimento se afastar do valor esperado. Abaixo é possível visualizar o histórico de variação percentual do índice Ibovespa de 2013 a outubro de 2022, bem como sua distribuição de frequência de retornos.
Gráfico 1 – Variação semestral do índice IBOVESPA entre os anos de 2013 a 2022.
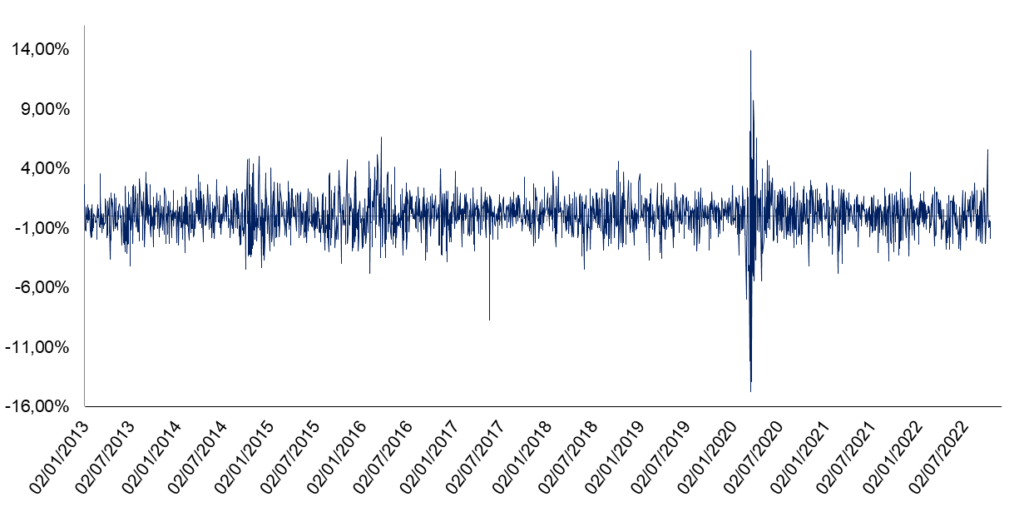
Gráfico 2 – Histograma de frequência das variações percentuais nos retornos do índice IBOVESPA entre 2013 e outubro de 2022
Fonte: Elaboração própria
Apesar dos riscos associados, a entrada de novos investidores no mercado vem crescendo nos últimos anos, desse modo a necessidade de softwares automatizados para auxiliar o processo de avaliação também cresce.
Gráfico 3 – Crescimento no número de novos CPFs na Bolsa de valores, em milhões
Fonte: Elaboração própria, com base em dados da B3
Segundo Buchanan (2019), o uso da tecnologia de Machine Learning está sendo cada vez mais adotada no mercado financeiro para poder prever essas tendências. Este movimento aliado ao ganho operacional da automação de processos justifica a realização deste trabalho.
1.2 Objetivos
O objetivo geral deste trabalho é desenvolver e descrever os conceitos técnicos de um modelo de Machine Learning. Tal modelo será selecionado a partir da comparação entre diversos algoritmos de aprendizado supervisionados e fornecerá recomendações de compra e venda de ações listadas no índice Ibovespa de acordo com seus indicadores financeiros, buscando o melhor resultado possível no horizonte trimestral.
Os objetivos específicos do trabalho são:
- Identificar os indicadores financeiros que possuem maior correlação com a cotação de uma ação.
- Avaliar métricas de desempenho do algoritmo e aprimorá-lo conforme os resultados.
- Comparar resultados previstos para o ano de 2022 com o índice Ibovespa.
- Revisão Bibliográfica
2.1 Análise Fundamentalista
De acordo com Assaf Neto (2018), uma decisão de investimento em ações deve ser realizada após uma profunda análise das expectativas visando alcançar retornos no longo prazo, e uma estratégia ideal para esse objetivo é a análise fundamentalista.
A análise fundamentalista é uma estratégia inicialmente proposta em 1934 por Benjamin Graham e David L. Dodd na publicação do livro Security Analysis. Sua premissa se dá pela avaliação do desempenho das empresas por meio de seus fundamentos utilizando indicadores financeiros, econômicos e mercadológicos provenientes de suas demonstrações financeiras. Desde então essa técnica vem sendo aprimorada.
Segundo Walter (1974), A análise fundamentalista tem como objetivo a identificação de títulos que estão sendo vendidos a preços abaixo dos seus preços de equilíbrio.
Por meio da análise dos indicadores é possível traçar cenários de como será o desempenho de uma determinada empresa e, consequentemente, avaliar quais são as probabilidades dessa organização gerar lucros e com isso aferir o impacto na valorização de seus títulos negociados no mercado acionário.
2.2 Machine Learning
Antes dos computadores essas análises eram feitas de maneira manual, sendo necessário muito tempo e recursos para poder realiza-las, mas com o aumento expressivo no número de informações e a complexidade dos indicadores, esse procedimento manual foi se tornando inviável, sendo assim, necessária uma nova abordagem.
Segundo GOMBOSKI (2018), os métodos tradicionais não traziam assertividade quando o assunto se tratava de modelos preditivos. Por isso, a utilização de Machine Learning começou a ser considerada para análises preditivas no setor financeiro.
Um dos primeiros registros do uso do Machine Learning foi de Arthur Samuel, um engenheiro do Massachusetts Institute of Technology, que criou um programa que podia aprender sem intervenção humana, sendo autossuficiente em seu próprio aprendizado daquilo que foi programado para aprender, um jogo de damas, detalhado em seu próprio livro “Some Studies in Machine Learning Using the Game of Checkers” (SAMUEL, 1959).
Graças ao importante pontapé inicial dado por Samuel em 1959, a melhoria dos modelos de Machine Learning e o advento de diversos estudos sobre o assunto, esta tecnologia foi se aperfeiçoando com o tempo, sendo possível desenvolver aplicações que poderiam contabilizar diversas variáveis em suas previsões. Ciclos econômicos, eventos políticos e a recepção dos investidores são exemplos de variáveis. Portanto com o crescimento dos mercados e suas variáveis, cálculos e modelos que pudessem prever essas alterações e possíveis resultados foram cada vez mais realizados por meio da computação.
Com o avanço da tecnologia, diferentes modelos de aprendizado de máquina caíram em desuso e outros tiveram sua ascensão. Tanto no mercado financeiro, quanto na academia, é constante este debate de qual modelo seria o mais adequado. Nogueira (2019) apresentou a comparação entre algoritmos de Machine Learning como decision tree e logistic regression, utilizando um banco de dados baseado em fatores de risco e o índice IBRX, com o objetivo de verificar a previsibilidade do mercado acionário brasileiro. Os resultados obtidos foram ligeiramente favoráveis para o algoritmo decision tree, com 37 de 71 empresas analisadas tendo previsão acima de 50%. A autora indica que o uso de modelos mais robustos pode favorecer a acurácia do algoritmo.
Leandro (2021) fez isso aplicando o modelo LSTM (Long Short Term Memory). Seu objetivo principal era verificar se o modelo em questão poderia ser eficaz quando aplicado ao mercado de ações na previsão de preços futuros de ativos. No final do estudo, o autor obteve um resultado de 61% com dados de entrada baseados no gráfico Renko. O autor sugere que uma abordagem multivariada utilizando outros fatores além do preço de fechamento pode contribuir para trabalhos futuros.
2.3 Aprendizagem supervisionada em Machine Learning
Graças ao Machine Learning, máquinas podem aprender através de dados a executar tarefas como os seres humanos. A execução é feita através da identificação de padrões encontrados nos dados. Conforme explicam Muller e Guido (2017), quando um algoritmo é treinado utilizando dados que apresentam um resultado explicito em sua composição, o chamamos de aprendizagem supervisionada.
Dentro desse nicho existem diversos modelos possíveis, alguns exemplos são: AdaBoost, Decision Tree, Naive Bays, SVM, KNN e Redes Neurais, etc. (GÉRON, 2019). Cada algoritmo possui suas particularidades, por isso, para este estudo foi utilizada a métrica f1-score testada em uma série de algoritmos para verificar qual deles performará melhor baseado na média de 5 execuções com cross validation. O algoritmo com melhor resultado será tunado e utilizado no trabalho.
2.4 Regressão Linear Simples
Segundo GUJARATI (2011), regressão é um modelo estatístico linear que tem o objetivo de estimar e prever os valores de um determinado espaço populacional levando em consideração a dependência de uma variável (variável dependente) em relação a uma variável explanatória. Esta ferramenta é muito útil para remover atributos que possuem grande interdependência.
A equação que expressa à regressão é:
Y = α + βx (1)
Onde:
y = variável dependente. Trata-se do resultado a ser previsto.
α = interseção entre a reta com o eixo vertical, representado por uma constante.
β = coeficiente angular
x = variável explanatória
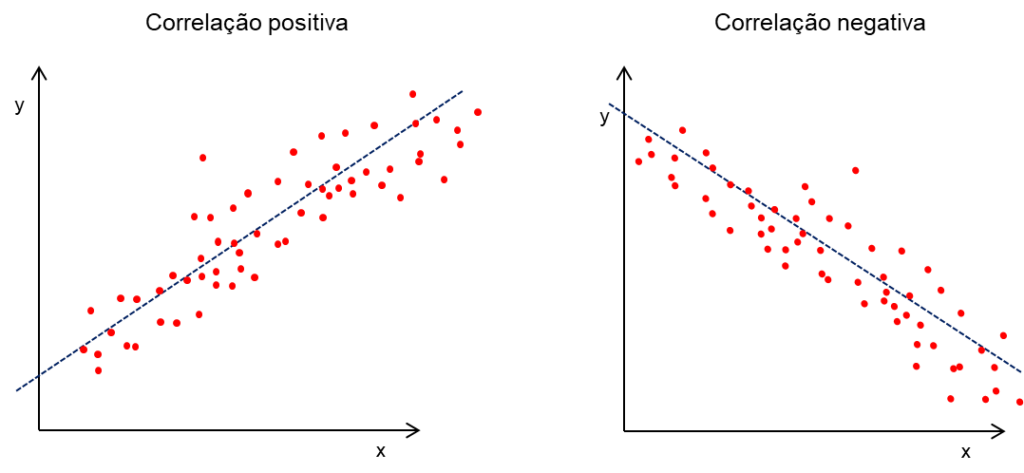
Dependendo do valor do coeficiente angular a inclinação da reta indicará se uma correlação é positiva ou negativa.
Gráfico 4 – Representação gráfica da regressão linear
2.5 Coeficiente de correlação
O coeficiente de correlação mede o nível de relação linear entre as variáveis. Seu valor varia entre -1 e 1.
Quanto mais próximo o valor for de -1, indica forte correlação negativa, bem como quanto mais próximo o valor for de 1 é indicativo de forte correlação positiva. Quanto mais o valor se aproxima de 0, menor é a correlação.
2.6 Random Forest
Random forest é um método de aprendizado de máquina composto por uma combinação de árvores de decisão, de tal forma que cada árvore ramifica seus dados em subconjuntos melhorados. Cada árvore é aprimorada com base em um vetor aleatório amostrado independentemente e com a mesma distribuição para todas as árvores da floresta (BREIMAN, 2001).
Figura 1 – Ilustração do funcionamento do modelo de Random Forest
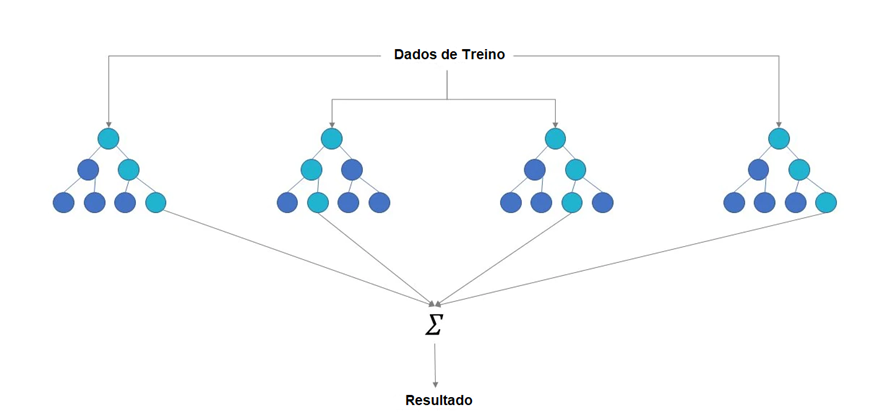
Marreti (2018) já apresentou a utilização desse modelo com dados de 2 anos da bolsa de valores de São Paulo, com objetivo de apresentar os principais componentes de Machine Learning na análise de ativos com a tecnologia, obtendo retornos acumulados em ações específicas de até 20%. O autor explica que a evolução do mercado financeiro, em conjunto com a automatização dos processos, justifica a utilização de técnicas de Machine Learning e ainda incita que a flexibilidade de escolher diferentes indicadores financeiros pode auxiliar em trabalhos futuros, bem como a utilização de uma base de dados com um período maior.
- Metodologia
3.1 Estratégia de investimentos adotada
Levando em consideração de que o valor de uma ação tende a se valorizar ao longo do tempo de acordo com os desempenhos de seus fundamentos, a premissa do projeto parte do princípio de que as cotações futuras das ações serão afetadas negativa ou positivamente de acordo com os resultados divulgados pelas companhias.
Entretanto, alguns pontos são necessários:
O crescimento do valor absoluto dos indicadores não se mostra um parâmetro eficiente, uma vez que as empresas listadas possuem proporções totalmente distintas. Empresas com maior valor de mercado e maiores receitas, naturalmente irão movimentar uma quantidade monetária muito superior em comparação com empresas de portes menores. Alguns tickers como Vale, Itaú e Petrobrás movimentam quantias bilionárias. Com isso, em um cenário onde cada uma delas alcançassem R$100 milhões de faturamento, não seria necessariamente algo positivo, visto que as mesmas geram volumes muito maiores, ao passo que para empresas menores essa quantia seria um desempenho extremamente positivo.
Para ter uma dimensão dessas disparidades, a composição da carteira do Ibovespa no dia 18/10/22 indicou que 42% do índice é formado apenas pelos 6 maiores papéis.
Gráfico 5 – Composição da carteira teoria do índice Ibovespa
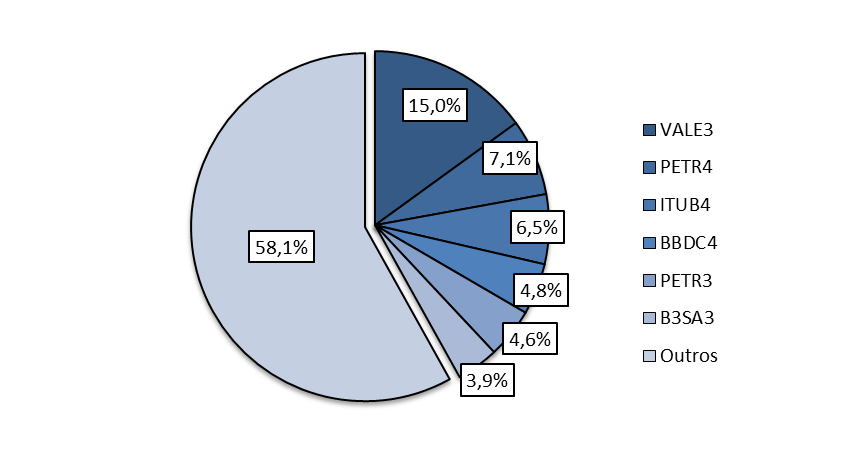
Fonte: Elaboração própria, com base em dados da B3
Tendo isso em mente, a maneira mais eficaz de comparar os desempenhos será pela variação percentual de cada indicador por trimestre, assim gerando igualdade de comparação entre o desempenho das empresas para análise.
Ainda assim é necessário definir mais uma condição. Não há como saber exatamente se uma variação percentual é boa ou ruim sem ter um referencial para comparação. No mercado financeiro este referencial chama-se benchmark e o benchmark para este projeto será o Ibovespa.
Gráfico 6 – Variação histórica do IBOVESPA de 2013 a outubro de 2022
Fonte: Elaboração própria
Basicamente a lógica partirá do seguinte princípio:
- Se uma ação performou mais que o IBOV em um determinado período, é positivo, por isso será classificado como comprar.
- Se uma ação se desvalorizou menos do que a desvalorização do IBOV no período, é positivo, por isso será classificado como comprar.
- Se uma ação se valorizou menos que o IBOV, é negativo, por isso será classificado como vender.
- Se uma ação se desvalorizou mais que o IBOV, é positivo, por isso será classificado como vender.
O objetivo do modelo será prever o rótulo dos ativos de acordo com essa estratégia.
Portanto, para utilizar a técnica de aprendizado supervisionado, será necessário um conjunto de dados bem estruturado para o algoritmo processar e iniciar o aprendizado.
3.2 Processo de mineração de dados
Figura 2 – Topologia do KDD
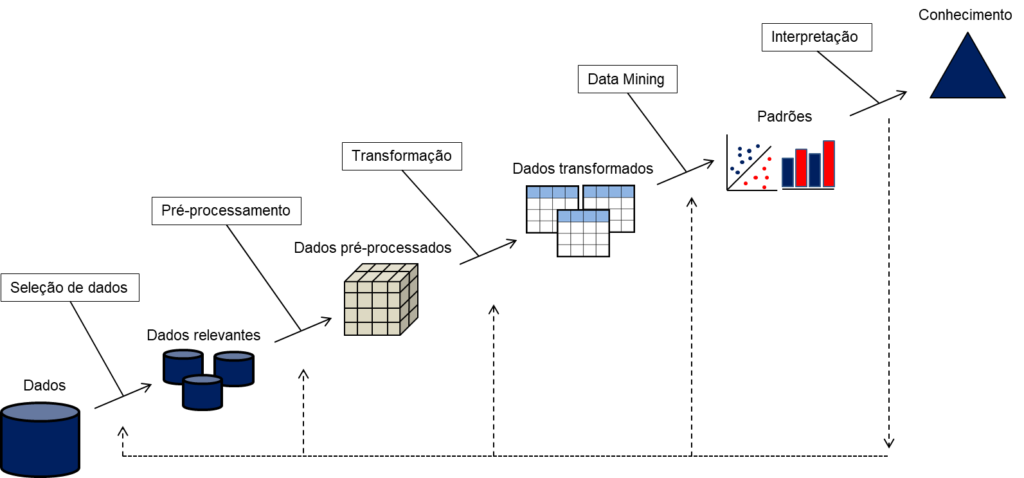
Fonte: Elaboração própria, baseado na metodologia do Fayyad et al (1996)
A qualidade dos dados é essencial para que um algoritmo de Machine Learning tenha sucesso em sua tarefa. Para obter insights úteis é necessário obter dados apropriados e limpá-los da forma adequada (SARKER, 2021). Pensando nisso, o KDD foi utilizado para sustentar o ciclo de vida dos dados no projeto. O foco inicial foi garantir que o escopo dos dados estava bem definido e por isso, a base de dados foi pensada com três atributos principais: indicadores financeiros que formam o balanço patrimonial, os preços de fechamento das ações e o valor do índice Ibovespa. Essas três informações seriam posteriormente condensadas para refletir o preço das ações com os indicadores financeiros em um determinado período, tendo o Ibovespa como comparativo.
Desse modo, foram obtidos dados de indicadores financeiros de 61 empresas da bolsa brasileira do período de 2013 a 2022, separados em trimestres, reservando o ano de 2022 para o teste final do algoritmo. O site “fundamentus” permite coletar estes balanços de forma fácil e armazená-los no formato.xls, propício para manipulação dos dados.
Quadro 1 – Exemplo de balanço extraído do site “fundamentus”
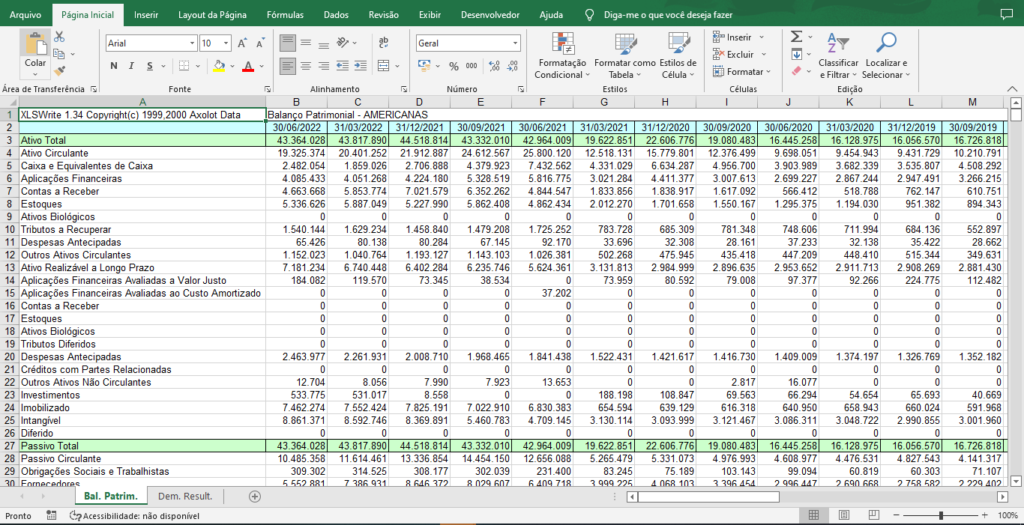
Fonte: Elaboração própria
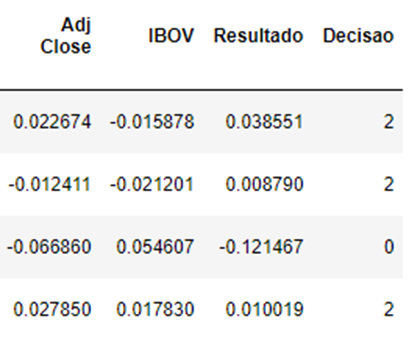
Utilizando a biblioteca pandas datareader é possível obter através da base de dados do Yahoo Finance o preço de fechamento das ações, bem como a pontuação do Ibovespa. Unindo o preço das ações, identificado como Adj. Close, com os indicadores financeiros temos como resultado a Figura 2. Esta atividade deu fim à etapa de pré-processamento dos dados.
É importante notar que não é necessário identificar as empresas individualmente, visto que o único parâmetro relevante são seus indicadores financeiros e o resultado que aqueles indicadores trouxeram para o preço da ação.
Tabela 1 – Amostra da tabela de indicadores financeiros com resultado
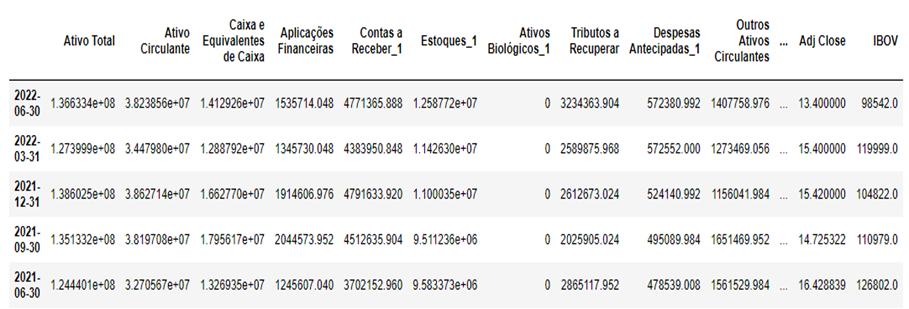
Fonte: Elaboração própria
Para o estudo ser relevante, é necessário considerar a disparidade entre grandes e pequenas empresas. Um exemplo claro é que uma empresa pode ter um ativo total de 100 milhões, mas performar mal em um trimestre por ter perdido 10% dessa métrica em comparação ao trimestre anterior, enquanto uma empresa com 1 milhão de ativo total pode ter uma alavancagem no preço da sua ação por ter aumentado esta métrica em 10% em relação ao trimestre anterior. Desse modo, o método correto de tratar esses valores são transformá-los em porcentagem considerando o preço do trimestre anterior, assim dá-se início a etapa de tratamento de dados. Note que nesse cenário a primeira linha do dataset de informações financeiras vai ficar vazia e por isso não será utilizada para treino.
Tabela 2 – Amostra da tabela de indicadores financeiros com resultado
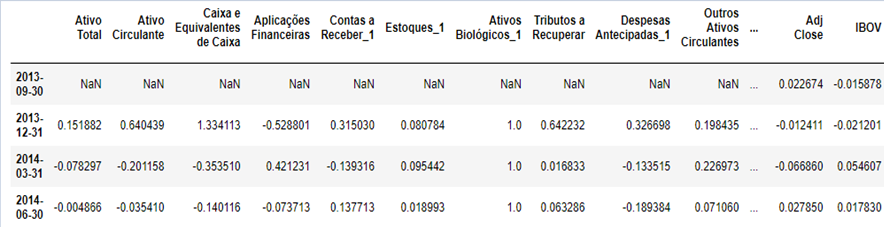
Fonte: Elaboração própria
Por fim, é necessário atribuir o resultado para cada ocorrência da tabela, isto é, dizer se devemos comprar ou vender naquele cenário. Para isto utilizamos o índice IBOV comparado à variação de preço daquela ação, se a ação performou melhor que o IBOV atribuiremos o rótulo de comprar para aquela ação, identificado como “2” no banco de dados, caso o resultado seja menor ou igual atribuiremos o rótulo “0” que significa vender a ação ou não a comprar.
Desse modo, o banco de dados está pronto para ser utilizado e interpretado pelo algoritmo.
Tabela 3 – Amostra da tabela de indicadores financeiros com resultado
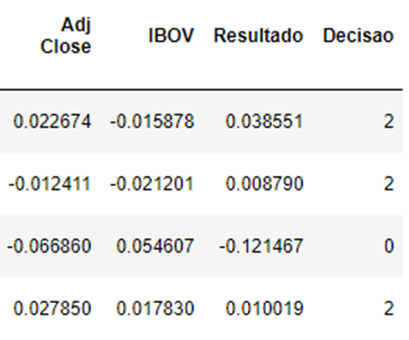
Fonte: Elaboração própria
- Feature selection
A escolha e remoção de atributos é essencial para um modelo de Machine Learning. Pensando nisso, o primeiro passo é identificar variáveis com maiores graus de interdependência, tanto negativa quanto positiva, e remover uma delas. Isso deve ocorrer pois variáveis duplicadas podem causar inconsistências no processo de decisão do algoritmo.
A primeira etapa foi verificar quais variáveis tinham forte correlação entre si, para isso foi utilizada a matriz de correlação. Essa ferramenta consiste na geração de uma tabela indicando os coeficientes de determinação entre as variáveis a fim de visualizar quais são as associações entre elas, foram removidas todas as correlações maiores que 0,8 e menores que -0,8.
Figura 3 – Matriz Total de correções
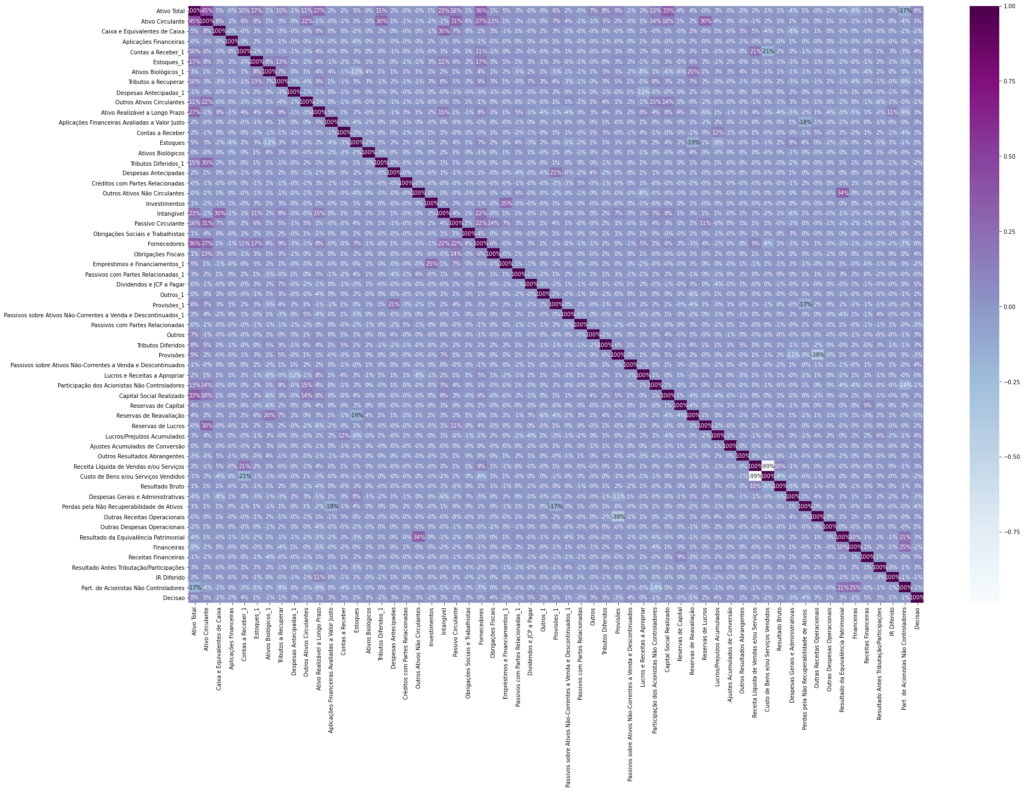
Fonte: Elaboração própria
Seguindo, foi treinado um modelo básico, o Extra tree classifier, para verificar quais atributos este modelo considerava mais importante para o resultado final de compra ou venda. No resultado, foram escolhidos os 10 indicadores que o algoritmo julgou importantes, baseado no gini inportance, que indica a probabilidade de classificarmos uma instância aleatória incorretamente. Este índice varia de 0 a 1, onde um valor de 0 indica pureza máxima para a variável, ou seja, um grupo de itens com resultado positivo no algoritmo certamente teriam essa variável em sua composição. Para melhor visualizar os atributos, os resultados do gini index foram normalizados e apresentados na tabela 4.
Tabela 4 – Impacto dos indicadores escolhidos no resultado do modelo inicial
Indicador Impacto no resultado Ativo Total 2,44% Ativo Circulante 2,31% Fornecedores 2,19% Contas a Receber_1 2,19% Dividendos e JCP a Pagar 2,16% Outros Ativos Circulantes 2,14% Obrigações Fiscais 2,13% Tributos a Recuperar 2,11% Ativo Realizável a Longo Prazo 2,10% Resultado Antes Tributação/Participações 2,08%
Fonte: Elaboração própria
Os indicadores parecem ter um impacto pequeno à primeira vista, mas isso ocorre pois o modelo inicial possuía muitos atributos, uma vez que o modelo será afunilado com os principais indicadores, eles serão melhor utilizados.
Além dos indicadores escolhidos pelo algoritmo, foram adicionados mais três: Passivo Circulante, Investimentos e Lucros/Prejuízos Acumulados. A seleção desses atributos complementares vai ser justificada no seguinte tópico.
3.4 Importância dos indicadores selecionados
Além da relação de gini, a seleção destes indicadores é reforçada devido à importância contábil para análise fundamentalista de uma empresa.
3.4.1 Ativo Total
Indicador que consiste na somatória de todos os bens e direitos de uma entidade, bens esses que irão gerar benefícios para a companhia no futuro. A importância deste indicador é estimar qual será a geração de capital da empresa.
3.4.2 Ativo Circulante
São os bens e direitos que serão liquidados em um período máximo de 12 meses. O Ativo circulante indica a capacidade financeira e operacional de uma empresa no curto prazo
3.4.3 Ativo Realizável a Longo Prazo
Ao contrário do circulante, este ativo só será convertido em dinheiro em períodos superiores a 12 meses. Este indicador possibilita identificar como será a geração financeira de uma empresa no futuro.
3.4.4 Passivo circulante
São as obrigações e deveres que as empresas deverão honrar em um período máximo de 12 meses. O passivo circulante afeta diretamente no resultado de uma empresa pois representa aspectos como dívidas e contas a pagar.
3.4.5 Investimentos
Investimentos integram tanto ativo circulante, quanto realizável a longo prazo. De acordo com (SALOTTI at. Al) um investimento é feito no intuito de obter retornos financeiros futuros. O impacto dos investimentos são fortemente sentidos em uma organização, sejam positivos ou negativos. Em uma visão de longo prazo, as operações de investimentos de uma empresa influenciam significativamente no seu desempenho, sendo assim, um indicador crucial para o modelo.
3.4.6 Contas a Receber
Direitos que as empresas irão receber de terceiros no curto, médio e longo prazo. Sua importância se dá pela previsão e detalhamento das receitas de uma companhia
3.4.7 Dividendos e JCP a Pagar
Dividendos e JCP são os proventos nos quais empresas distribuem para seus acionistas proporcionalmente as participações societárias de cada um. É um dos indicadores mais importantes para os investidores, pois é basicamente uma das formas de retorno financeiro sobre as aplicações. Sendo assim, esse indicador exerce grande impacto nos preços das ações dependendo do seu desempenho.
3.4.8 Lucro/prejuízo acumulado
É o resultado final do exercício de uma empresa. Por meio dele é possível medir para onde estão levando os esforços de uma companhia. O resultado de lucro ou prejuízo impacta diretamente nas cotações das ações.
3.4.9 Resultado Antes Tributação/Participações
Este indicador mede a eficiência de uma empresa na geração financeira antes do abatimento dos impostos. Sua importância se dá pela visibilidade do desempenho operacional da organização na geração de resultado
3.4.10 Obrigações Fiscais
Indicador que representa os impostos que uma empresa deverá pagar. A carga tributária brasileira para as empresas é bastante significativa, influenciando diretamente no resultado em um determinado período.
3.4.11 Tributos a Recuperar
Assim como existem as obrigações tributárias, as empresas também possuem impostos a serem recuperados. Dependendo da ocasião, essas quantias recuperadas podem representar uma parte significativa do resultado de uma empresa durante um determinado período.
3.4.12 Fornecedores
Este indicador representa as obrigações que as empresas têm em pagar seus fornecedores. Em um cenário onde a alta demanda por produtos e rápida rotatividade dos estoques exigem muito da capacidade operacional de uma organização, gastos com matérias primas representam uma grande parte do resultado.
3.5 Métricas de precisão na escolha do modelo
Para definir qual o melhor algoritmo foi utilizado o F1-score. Definido por Tharwat (2020) como o cálculo da eficiência da média harmônica entre a precisão e o recall, esta métrica de avaliação permite ponderar de forma mais eficiente falsos negativos e positivos se comparado à precisão.
Tabela 5 – Tabela com o F1-Score da eficiência média
Fonte: Elaboração própria
Para realizar o cálculo da métrica principal, foi levada em consideração a relação de se um objeto foi classificado da maneira correta e se, caso haja algum erro, qual classificação foi atribuída a ele. Considerando à possibilidade de compra ou venda a tabela 1 apresenta a nomenclatura utilizada:
Tabela 6 – Exemplificação entre resultado do algoritmo X output de compra ou venda
Nomenclatura Resultado Real Output do algoritmo Falso Positivo Vender Comprar Positivo verdadeiro Comprar Comprar Falso negativo Comprar Vender Negativo verdadeiro Vender Vender
Fonte: Elaboração própria
Com estas informações é possível calcular as métricas que irão compor o F1-score, começando pela precisão:

Seguindo para orecall:

Após obter os valores relativos ao recall e à precisão é possível calcular o f1-score:

- Resultados e Discussão
4.1 Modelo com melhor desempenho
Após a comparação de 9 modelos utilizando a métrica do f1-score, chegou-se ao resultado de que o Random Forest é o melhor modelo, com um resultado de 53,96% de acertos em média de 5 testes. O modelo apresentou erro maior na previsão de valores quando devia-se vender uma ação ao invés de comprá-la, por outro lado, performou bem quando realmente devia-se vender uma ação, vide figura 5.
Gráfico 7 – Amostra de Matriz de confusão inicial do Random Forest
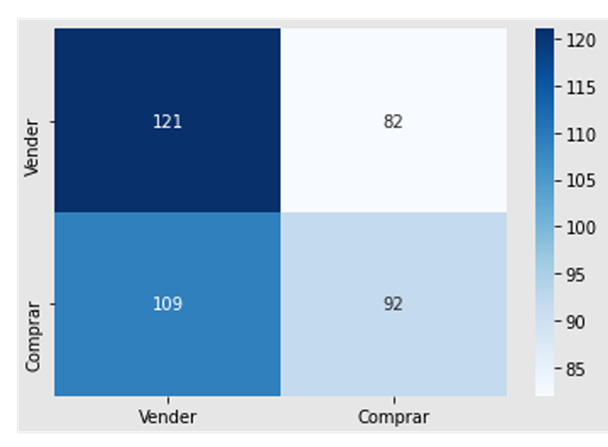
Fonte: Elaboração própria
Uma vez definido o modelo foi possível tunar seus hiper parâmetros, obtendo um resultado um pouco melhor de 54,90% de acertos na média de 5 testes.
Gráfico 8 – Amostra de Matriz de confusão do modelo final
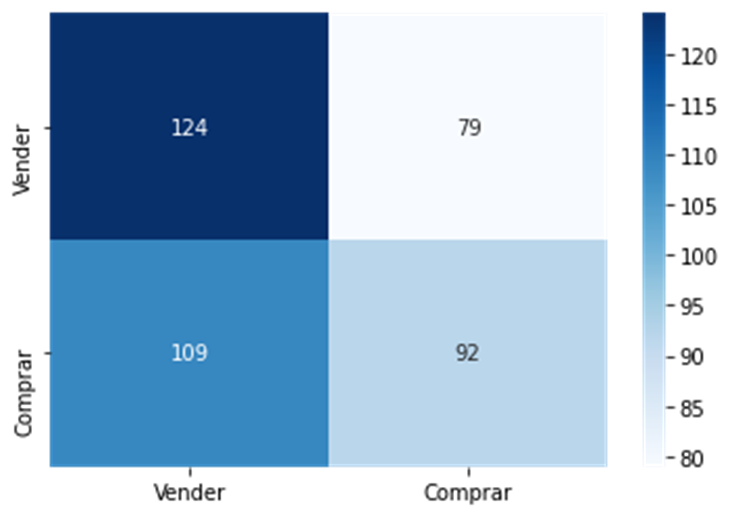
Fonte: Elaboração própria
4.2 Resultados do modelo com o ano de 2022
O modelo final foi submetido à base do primeiro e segundo trimestre de 2022 com um total de 61 empresas. Para o primeiro trimestre de 2022, o modelo recomendou a compra de 14 ações e a venda de 47. Para verificar se o modelo performou bem, foi elaborada uma carteira fictícia e atribuídos mil reais para cada ação que o modelo recomendou a compra, simulando o começo do trimestre, e comparou-se com o preço da ação no final do trimestre.
Figura 4 – Resultado final do modelo para o primeiro trimestre de 2022
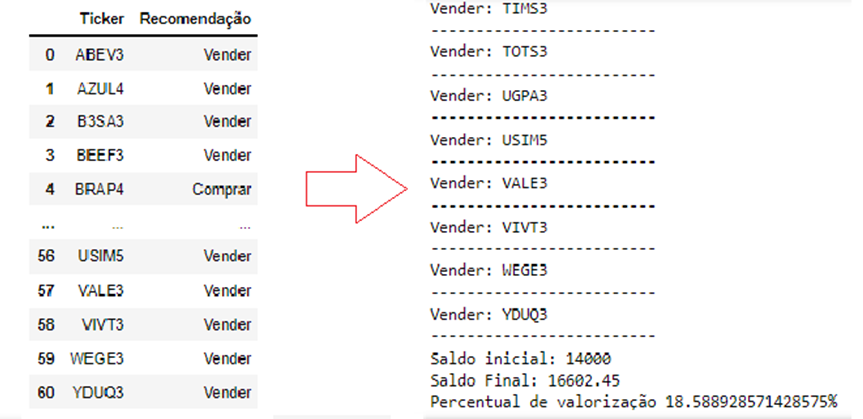
Fonte: Elaboração própria
O resultado final do modelo para o primeiro trimestre de 2022 foi de 18,58% de valorização com lucro de R$ 2.602,45, batendo o IBOV que apresentou no mesmo período variação de 15,47%, ou seja, teria lucro de apenas R$ 2.165,8.
Dentre as 14 ações escolhidas pelo modelo apenas uma não apresentou lucro, a KBLN11, isso pode ser justificado pelos resultados dos indicadores financeiros da empresa do terceiro para o quarto trimestre de 2021, onde a empresa aumentou atributos que são considerados importantes para o modelo, como ativo total (aumento de R$ 1.239.650) e contas a receber (aumento de R$ 151.876), mas mesmo assim não correspondeu no preço final.
Por outro lado, as ações que mais apresentaram lucro com o modelo foram a CFB3, com R$ 572, e a HYPE3, com R$ 421. Ambas juntas representam 38,15% do lucro total da carteira. Isso pode indicar que a distribuição de ativos de maneira ponderada na carteira poderia ser interessante para alavancar o lucro do algoritmo.
O segundo trimestre de 2022 foi marcado por uma variação negativa no IBOV e isso também refletiu nos ativos escolhidos pelo algoritmo. Novamente 14 ativos foram escolhidos para o período, com uma variação negativa de -18,37% contra -18,94% do IBOV. O prejuízo para o período foi de R$ 2.572,98 contra um prejuízo de 2.651,6 do IBOV.
Figura 5 – Resultado final do modelo para o segundo trimestre de 2022
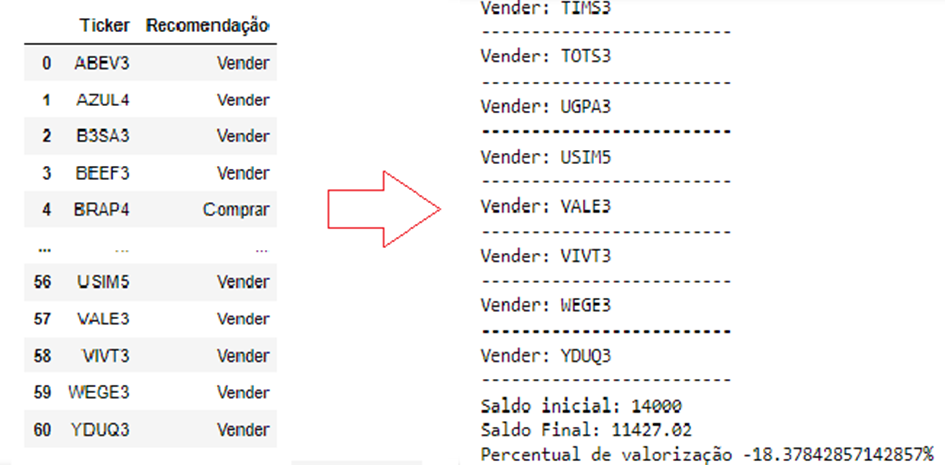
Fonte: Elaboração própria
O resultado do segundo trimestre acompanha o resultado geral das empresas no segundo trimestre no Brasil. Apenas uma empresa escolhida conseguiu oferecer lucro, a CPFE3, com R$ 17.
Gráfico 9 – Comparativo das valorizações do IBOV e da carteira recomendada pelo modelo
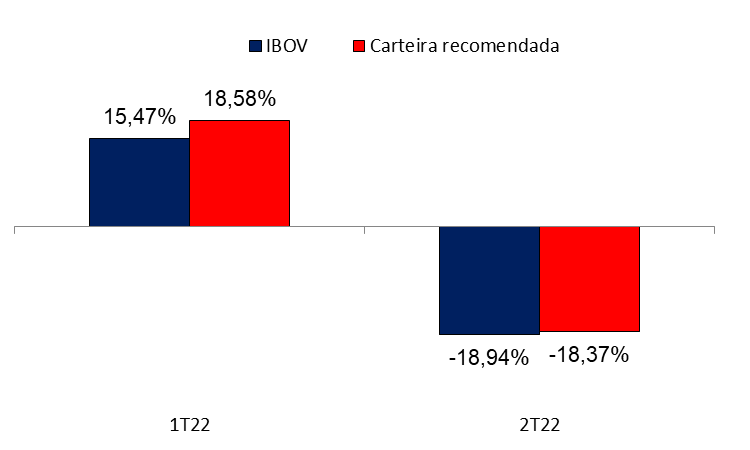
Fonte: Elaboração própria
- Considerações Finais
Ao fazer a análise de estudos anteriores como o de Marreti (2019) no mercado financeiro, foi possível constatar que o modelo Random Forest apresenta um resultado satisfatório quando alimentado por uma base de dados consistente e com indicadores relevantes.
Os resultados do modelo desenvolvido foram consistentes quando comparados com o indicador do Ibovespa, entretanto, apresentam uma disparidade no quesito de balanceamento do portfólio, onde poucas ações influenciam o resultado geral da carteira. Isso indica que o modelo poderia se beneficiar de um sistema de peso para cada ação, atrelado à probabilidade de que o modelo realmente acertou o resultado futuro. Desse modo, quanto maior a probabilidade de acerto, mais dinheiro deveria ser aplicado à uma ação.
Os indicadores financeiros escolhidos apresentaram boa relação com o resultado final da ação para cada trimestre. A variedade dos indicadores na análise fundamentalista proporciona uma boa visão geral da saúde de uma empresa, que está diretamente ligada com sua capacidade de lucro. Neste tipo de análise muitas vezes não é possível ver de prontidão, isto é, de um trimestre para o outro, bons resultados. Esse fato pode prejudicar a confiabilidade do algoritmo final, que necessitaria de mais testes no futuro em um horizonte maior para ser aplicável em um cenário real.
Referências
ASSAF NETO, Alexandre. Mercado Financeiro. 14. ed. São Paulo: Atlas Editora, 2018.
BREIMAN, L. Random Forests. Machine Learning, Springer v.45, p. 5–32, 2001.
BUCHANAN, Bonnie G.. Artificial intelligence in finance. Washington, Estados Unidos: Zenodo, 2019.
FAYYAD, Usama; PIATETSKY-SHAPIRO, Gregory; SMYTH, Padhraic. Knowledge Discovery and Data Mining: Towards a Unifying Framework. KDD-96 Proceedings fromAssociation for the Advancement of Artificial Intelligence, California, 1996.
GÉRON, Aurélien. Hands-On Machine Learning with Scikit-Learn and TensorFlow: concepts, tools, and techniques to build intelligent systems. 2. ed: O’reilly Media, 2019.
GOMBOSKI, Matheus. A UTILIZAÇÃO DE ALGORITMOS DE MACHINE LEARNING NA ANÁLISE ECONÔMICA. Porto Alegre: Universidade Federal do Rio Grande do Sul, 2019.
GRAHAM, Benjamin; DAVID, Dodd. Security Analysis: sixth edition, foreword by warren buffett: principles and technique. 6. ed. New York: McGraw-Hill, 2008.
GUJARATI, Damodar N.; PORTER, Dawn C.. ECONOMETRIA BÁSICA. 5. ed. Porto Alegre: Amgh, 2011. 920 p https://www.b3.com.br/pt_br/market-data-e-indices/indices/indices-amplos/indice-ibovespa-ibovespa-composicao-da-carteira.htm
LEANDRO, Jhonatan Correa. Aplicação de Redes Neurais LSTM para Previsão de Séries Temporais Financeiras. 2021. 14 f. TCC (Graduação) – Curso de Engenharia da Computação, Universidade Federal da Grande Dourados, Mato Grosso do Sul, 2021.
MALTA, Tanira Lessa; CAMARGOS, Marcos Antônio de. Variáveis da análise fundamentalista e dinâmica e o retorno acionário de empresas brasileiras entre 2007 e 2014. Belo Horizonte: Rege – Revista de Gestão, v. 23, 2016.
Marretti, Roberto Bruno Lemes. Simulação de negociações em instrumentos do índice IBOVESPA utilizando Machine Learning. Mestrado (Mestrado em Engenharia Elétrica e Computação) – Universidade Presbiteriana Mackenzie – São Paulo, 2019.
Nogueira, Carolina Calió. Previsibilidade no mercado acionário utilizando Machine Learning. Dissertação (mestrado profissional MPFE) – Fundação Getulio Vargas, Escola de Economia de São Paulo – São Paulo, 2019.
SANTOS, Gustavo Carvalho. ALGORITMOS DE MACHINE LEARNING PARA PREVISÃO DE AÇÕES DA B3. Uberlândia: Faculdade de Engenharia Elétrica da Universidade Federal de Uberlândia, 2020.
WALTER, Richard G.. Análise fundamentalista e avaliação de títulos: aspectos teóricos. Rio de Janeiro: Departamento de Contabilidade, Finanças e Controle da Escola de Administração de Empresas de São Paulo da Fundação Getulio Vargas,1974.