REGISTRO DOI: 10.69849/revistaft/ra10202511300622
Kawan Ribeiro Dias Barros¹
Mauro Jose Araujo de Melo²
Resumo:
A baixa qualidade de dados públicos tabulares representa um dos principais desafios para a aplicação de modelos clássicos de Machine Learning, especialmente devido à recorrência de valores ausentes. Este trabalho realiza uma análise teórica e matematicamente fundamentada acerca do impacto de dois métodos simples e amplamente utilizados para a imputação de dados: média e mediana. A partir da avaliação das propriedades estatísticas desses métodos e de seu comportamento dentro das funções dos modelos de Regressão Linear, Regressão Logística, K-Nearest Neighbors (KNN) e Árvores de Decisão, demonstra-se que a imputação pela média é sensível à presença de valores extremos, afetando coeficientes, probabilidades, distâncias e medidas de impureza. Em contrapartida, a mediana se mostra robusta, por depender apenas da posição central dos dados, preservando a integridade estatística do conjunto analisado. Os resultados teóricos indicam que a imputação pela mediana tende a produzir maior estabilidade estrutural e, consequentemente, melhor desempenho preditivo nesses modelos quando aplicada a bases públicas tabulares. Conclui-se que, em cenários onde há maior probabilidade de inconsistências e valores distorcidos, a mediana representa uma estratégia mais adequada para preparação de dados voltados à aprendizagem supervisionada.
Palavras-chave: qualidade de dados; valores ausentes; Machine Learning.
Abstract:
Low-quality public tabular data is one of the main challenges for the application of classical Machine Learning models, particularly due to the frequent presence of missing values. This study provides a theoretical and mathematically grounded analysis of the impact of two simple and widely adopted imputation methods: mean and median. By examining the statistical properties of each method and their behavior within the functional structure of Linear Regression, Logistic Regression, K-Nearest Neighbors (KNN), and Decision Trees, it is shown that mean imputation is highly sensitive to outliers, which distorts coefficients, probabilities, distances, and impurity measures. In contrast, the median proves to be more robust, as it depends solely on the central position of the data, preserving statistical integrity. Theoretical results indicate that median imputation tends to produce greater structural stability and, consequently, improved predictive performance when applied to public tabular datasets. Therefore, in contexts where inconsistencies and distorted values are likely to occur, the median represents a more suitable data preparation strategy for supervised learning.
Keywords: data quality; missing values; Machine Learning.
INTRODUÇÃO
O presente trabalho propõe-se a investigar, do ponto de vista teórico e matemático, o impacto de diferentes estratégias de imputação de valores ausentes em bases de dados sobre o desempenho funcional de modelos clássicos de Machine Learning. Em bases tabulares, é comum a presença de dados faltantes, o que pode comprometer a qualidade do treinamento e a eficácia da previsão. Valores ausentes podem surgir em bases públicas devido a falhas de coleta, inconsistências entre sistemas, erros de preenchimento, limitações operacionais ou pela própria complexidade do armazenamento e atualização das informações.
A partir de uma análise conceitual, este estudo avalia como métodos simples de imputação — especificamente, a média e a mediana — podem modificar as funções internas dos modelos e, consequentemente, sua performance. Além disso, considerando o grande volume de dados abertos atualmente disponíveis, como os quase 13 mil conjuntos de dados catalogados no Portal Brasileiro de Dados Abertos, este trabalho ganha relevância prática: dados públicos amplamente utilizados em pesquisas podem conter valores ausentes, o que ressalta a importância de entender teoricamente como diferentes imputações influenciam os resultados.
A hipótese central deste estudo é que a imputação por mediana apresenta maior robustez frente a valores extremos e, por isso, tende a preservar melhor a estrutura matemática dos dados, gerando modelos mais estáveis e com menor tendência a erro. A abordagem adotada é inteiramente teórica e analítica, com demonstrações matemáticas para diferentes algoritmos clássicos de Machine Learning — Regressão Linear, Regressão Logística, Árvores de Decisão e K Vizinhos Mais Próximos (KNN).
Objetivo Geral
Analisar teoricamente o impacto de diferentes métodos de imputação de valores ausentes em bases tabulares sobre o comportamento funcional de modelos clássicos de Machine Learning.
- Objetivos Específicos
- 1. Demonstrar matematicamente como a imputação por média e mediana altera o conjunto de dados original.
- 2. Avaliar teoricamente como tais alterações influenciam as funções internas de modelos clássicos de Machine Learning (Regressão Linear, Regressão Logística, Árvores de Decisão e KNN).
- 3. Inferir a estabilidade e tendência de desempenho de cada modelo quando treinado com dados imputados por média e por mediana.
- 4. Relacionar a influência dos métodos de imputação com a relevância prática no uso de dados públicos tabulares brasileiros.
2. FUNDAMENTAÇÃO TEÓRICA
2.1 INTELIGÊNCIA ARTIFICIAL
2.1.1 Breve História
O termo “Inteligência Artificial” foi formalmente apresentado em 1956 por John McCarthy, durante a Conferência de Dartmouth, considerada o marco fundador da área (DARTMOUTH COLLEGE, 2024). Nesse evento, McCarthy, juntamente com Marvin Minsky, Nathaniel Rochester e Claude Shannon, propôs que aspectos da inteligência humana poderiam ser descritos matematicamente de modo que máquinas fossem capazes de realizá-los.
A partir desse marco inicial, a área evoluiu acompanhando o avanço do poder computacional e a crescente disponibilidade de dados digitais. O desenvolvimento de algoritmos mais robustos, especialmente a partir das décadas de 1990 e 2000, possibilitou novas vertentes, como Machine Learning e Deep Learning, que permitiram que sistemas computacionais aprendessem diretamente a partir de grandes volumes de dados, adaptando-se a novas situações e contextos.
2.1.2 Conceito Geral
A Inteligência Artificial (IA) é uma área da computação dedicada ao desenvolvimento de sistemas capazes de realizar tarefas que normalmente exigiriam capacidades humanas, como reconhecimento de padrões, tomada de decisão e previsões. Esses sistemas utilizam algoritmos e modelos matemáticos que permitem aprender a partir de dados, adaptar-se a novas informações e melhorar seu desempenho ao longo do tempo, simulando aspectos do raciocínio humano (IBM, 2024).
Além da capacidade de aprendizado, a IA também se destaca por sua habilidade de generalizar padrões e aplicar o conhecimento adquirido a novos contextos. Isso ocorre por meio de técnicas que permitem interpretar dados, identificar relações e tomar decisões com maior precisão, tornando a IA uma ferramenta essencial em aplicações que envolvem automação, previsão e suporte à análise de grandes volumes de informação (RUSSELL; NORVIG, 2022).
A eficácia dos algoritmos de IA depende diretamente da qualidade dos dados de entrada, sendo que valores ausentes, inconsistências ou outliers podem impactar significativamente o desempenho preditivo dos modelos. Essa observação reforça a relevância do estudo da qualidade de dados públicos tabulares no contexto do Machine Learning, tema central deste trabalho.
2.1.3 Tipos de Modelos de IA
A Inteligência Artificial (IA) engloba diferentes tipos de modelos que buscam reproduzir aspectos da inteligência humana, podendo ser classificados de acordo com a forma como processam informações e aprendem com os dados (RUSSELL; NORVIG, 2022). Entre os principais modelos estão os sistemas baseados em regras, que executam tarefas conforme instruções explícitas programadas pelo usuário; os métodos estatísticos, que identificam padrões por meio de análises matemáticas; e as redes neurais artificiais, inspiradas no funcionamento do cérebro humano, capazes de aprender a partir de grandes volumes de dados. Cada abordagem possui características próprias, vantagens e limitações, sendo aplicada conforme o tipo de problema e a disponibilidade de informações (GOODFELLOW; BENGIO; COURVILLE, 2016).
Dentre essas abordagens, o Machine Learning (ML) se destaca por sua capacidade de aprender diretamente a partir dos dados, ajustando seus parâmetros para melhorar o desempenho do modelo conforme novas informações são processadas, sem depender exclusivamente de regras pré-definidas. Essa característica torna o ML especialmente adequado para o tipo de análise utilizada neste trabalho, em que dados tabulares públicos brasileiros apresentam variabilidade, inconsistências e lacunas, exigindo algoritmos capazes de identificar padrões e realizar previsões confiáveis, com precisão e consistência (ZHOU; ZHOU; ZHOU, 2021).
Dessa forma, entre as diversas abordagens de IA, o Machine Learning surge como o foco central do estudo, uma vez que a qualidade dos dados influencia diretamente o desempenho dos modelos e, consequentemente, a confiabilidade das previsões.
2.2 MACHINE LEARNING (APRENDIZADO DE MÁQUINA)
2.2.1 Conceitos Gerais
O Machine Learning (ML), ou Aprendizado de Máquina, é uma subárea da Inteligência Artificial dedicada à construção de algoritmos capazes de aprender padrões a partir de dados e utilizá-los para realizar previsões ou tomar decisões de forma automatizada. Diferentemente de sistemas baseados em regras fixas, os modelos de ML ajustam seus parâmetros internos conforme processam exemplos, permitindo que o desempenho melhore progressivamente a partir da experiência (MITCHELL, 1997).
O processo de aprendizado no ML envolve a análise de relações matemáticas existentes entre variáveis, de modo que o modelo seja capaz de generalizar essas relações e aplicá-las a novos dados. Para isso, os algoritmos passam por etapas de treinamento, validação e teste, onde aprendem padrões, avaliam a eficiência das previsões e são ajustados para minimizar erros (JAMES et al., 2021).
Essa capacidade de generalização é uma das principais características que diferencia o ML de abordagens tradicionais de programação. Modelos de aprendizado de máquina não apenas executam tarefas previamente programadas, mas também se adaptam a novas informações e situações, simulando aspectos do raciocínio humano por meio da identificação e interpretação de padrões complexos nos dados.
2.2.2 Tipos de Aprendizado
Os algoritmos de Machine Learning podem ser classificados de acordo com a forma como aprendem a partir dos dados. As principais categorias são: aprendizado supervisionado, não supervisionado e por reforço. No aprendizado supervisionado, o modelo é treinado com dados rotulados, ou seja, cada entrada possui uma saída conhecida, permitindo que o algoritmo aprenda a relação entre variáveis e preveja resultados para novos dados (ALPAYDIN, 2020). Essa abordagem é particularmente adequada para dados estruturados, como tabelas, em que cada coluna representa uma variável e cada linha um registro, facilitando a análise das relações entre os atributos.
O aprendizado não supervisionado, por sua vez, trabalha com dados sem rótulos, buscando identificar padrões, agrupamentos ou estruturas internas nos dados. Já o aprendizado por reforço envolve a interação de um agente com um ambiente, aprendendo estratégias a partir de recompensas ou penalidades recebidas. Dentre essas abordagens, o aprendizado supervisionado se destaca por sua capacidade de processar e extrair informações de conjuntos de dados tabulares, tornando-se uma ferramenta essencial para problemas que envolvem previsões ou classificações baseadas em variáveis conhecidas (HASTIE; TIBSHIRANI; FRIEDMAN, 2009).
2.3 MODELOS CLÁSSICOS DE MACHINE LEARNING PARA DADOS TABULARES
Quando trabalhamos com dados públicos tabulares, como registros de saúde, educação ou estatísticas demográficas, alguns modelos de Machine Learning se destacam por sua eficácia, interpretabilidade e facilidade de aplicação.
2.3.1 Regressão Linear
A regressão linear é utilizada para prever valores contínuos, como renda média por município ou número de atendimentos de saúde. Ela identifica a relação entre variáveis explicativas e a variável que se deseja prever. Por exemplo, podemos estimar o número de consultas médicas considerando o número de médicos disponíveis e a população de uma cidade. Este modelo é intuitivo e fácil de interpretar, oferecendo uma base confiável para análises iniciais (NEVES, 2003).
2.3.2 Regressão Logística
Além da regressão linear, a regressão logística é indicada quando o objetivo é classificação binária, ou seja, prever categorias como “sim” ou “não”. Por exemplo, pode-se estimar se uma escola atingirá ou não uma meta de desempenho com base em indicadores de infraestrutura e número de alunos. O modelo calcula a probabilidade de ocorrência de um evento e classifica o resultado na categoria mais provável (ICHI.PRO, 2025).
2.3.3 Árvores de Decisão
Outro modelo importante são as árvores de decisão, que funcionam como um jogo de perguntas e respostas. Em cada etapa, o modelo faz uma pergunta sobre os dados (por exemplo, “a escola possui biblioteca?”) e segue por um caminho de acordo com a resposta até chegar a uma decisão final. São visuais, intuitivas e adaptáveis, capazes de lidar com diferentes tipos de dados tabulares e capturar relações complexas entre variáveis (DIO, 2024).
2.3.4 K‑Nearest Neighbors (KNN)
Por fim, o KNN classifica ou prevê valores observando os vizinhos mais próximos de um registro. Por exemplo, para estimar se um município terá alto risco de mortalidade infantil, o modelo compara suas características com municípios semelhantes e decide com base na maioria dos vizinhos. Este método é simples de aplicar, mas sensível à escolha do número de vizinhos e à métrica de distância utilizada (SURYA PRASATH, 2017).
2.4 Formalização Matemática dos Modelos Clássicos
Nesta seção, apresentamos uma visão simplificada da forma como os modelos clássicos de Machine Learning processam dados, usando representações intuitivas. O objetivo é mostrar como cada modelo transforma entradas em saídas.
2.4.1 Regressão Linear
A regressão linear pode ser pensada como uma linha reta que se ajusta aos dados. Cada variável de entrada contribui com um “peso” para prever o resultado.
Representação conceitual:
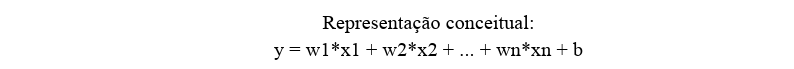
Intuição: o modelo aprende quais variáveis impactam mais o resultado e ajusta os pesos para que a previsão fique próxima aos valores reais.
2.4.2 Regressão Logística
A regressão logística transforma o resultado da regressão linear em uma probabilidade entre 0 e 1, permitindo fazer decisões de classificação.
Representação conceitual:
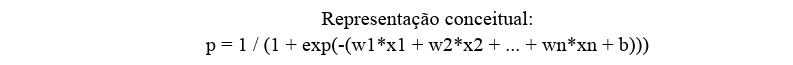
Intuição: o modelo calcula a chance de um evento acontecer com base nas variáveis, e classifica o registro de acordo com a probabilidade mais alta.
2.4.3 Árvores de Decisão
Árvores de decisão dividem os dados em blocos ou regiões usando regras simples de “sim” ou “não”.
Representação conceitual:

Intuição: cada pergunta sobre uma variável leva a um caminho diferente, até chegar a uma previsão ou classificação. É como seguir um “fluxograma” de decisões.
2.4.4 K‑Nearest Neighbors (KNN)
O KNN não cria uma função explícita, mas olha para os vizinhos mais próximos de um novo registro e decide o resultado com base no que é mais comum.
Representação conceitual:

Intuição: o modelo consulta os exemplos mais similares e “segue a tendência” encontrada entre eles para prever ou classificar.
2.5 Dados Públicos
O conceito de dados públicos refere-se a informações produzidas ou custeadas por órgãos governamentais, que são disponibilizadas de forma aberta, estruturada e acessível à sociedade. No Brasil, o acesso a esses dados é regulamentado pela Lei de Acesso à Informação (Lei nº 12.527/2011), que garante o direito de qualquer cidadão solicitar informações a órgãos públicos, promovendo transparência, fiscalização e participação social (BRASIL, 2011).
2.5.1 Conceito e Definição
Dados públicos são registros produzidos, coletados ou administrados por entidades governamentais que podem ser utilizados para análise, pesquisa e formulação de políticas públicas. Eles englobam informações sobre saúde, educação, segurança, finanças e estatísticas demográficas, entre outros. A disponibilização desses dados em formatos estruturados permite que sejam processados sistematicamente, possibilitando estudos comparativos, análises históricas e acompanhamento de indicadores (BATINI; SCANNAPIECO, 2016).
Além disso, dados públicos são caracterizados por sua transparência e abertura, podendo ser compartilhados em portais oficiais ou plataformas de dados abertos. Essa característica favorece a confiabilidade das análises, uma vez que os registros podem ser auditados e replicados, fortalecendo a integridade da informação (KITCHIN, 2014).
2.5.2 Características de Dados Públicos Tabulares
Entre as diversas formas de dados públicos, os dados tabulares são especialmente relevantes para análises quantitativas. Eles apresentam informações organizadas em linhas e colunas, facilitando a leitura, interpretação e aplicação de métodos estatísticos. Algumas características principais incluem:
1. Estruturação: cada coluna representa uma variável, e cada linha corresponde a uma observação ou registro.
2. Volume elevado: dados públicos podem englobar milhões de registros, permitindo análises em grande escala e representatividade estatística.
3. Heterogeneidade: os registros podem conter diferentes tipos de variáveis (numéricas, categóricas, temporais), refletindo a complexidade da realidade observada.
4. Transparência: todas as etapas de coleta e produção dos dados estão, em princípio, documentadas, permitindo rastreabilidade e auditoria.
Essas características tornam os dados tabulares públicos particularmente úteis para análises quantitativas e comparações entre diferentes regiões, períodos ou grupos populacionais (JASON et al., 2020).
2.5.3 Disponibilidade e Acessibilidade
A Lei nº 12.527/2011 estabelece que órgãos públicos devem disponibilizar informações de forma proativa, preferencialmente em formatos digitais abertos, como CSV, XLS ou JSON. Além disso, o governo brasileiro mantém portais de dados abertos, como o Portal Brasileiro de Dados Abertos, que reúne informações provenientes de diferentes ministérios e agências, permitindo que pesquisadores, empresas e cidadãos acessem os registros livremente.
A acessibilidade dos dados, aliada à padronização de formatos, facilita o tratamento e integração de múltiplas bases, permitindo análises mais robustas e confiáveis. Por exemplo, dados de saúde do DataSUS podem ser combinados com dados demográficos do IBGE, criando um conjunto mais completo para análise regional ou temporal (BRASIL, 2011; IBGE, 2024).
2.5.4 Exemplos de Bases Públicas Brasileiras
Entre os principais repositórios de dados públicos tabulares no Brasil destacam-se:
1. IBGE (Instituto Brasileiro de Geografia e Estatística): fornece informações sobre população, economia, educação e outros indicadores demográficos e sociais.
2. DataSUS: disponibiliza registros de saúde pública, atendimentos hospitalares, vacinação, mortalidade e morbidade.
3. INEP (Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira): fornece dados sobre escolas, desempenho educacional e avaliações nacionais.
4. Portais de Transparência: mantidos por diferentes órgãos governamentais, reúnem informações sobre execução orçamentária, licitações e despesas públicas.
Essas bases públicas oferecem registros extensivos e detalhados, que, quando tratados corretamente, possibilita análises precisas, comparações históricas e estudos estatísticos em larga escala, sendo fundamentais para a pesquisa aplicada em ciências sociais, economia, saúde e educação (KITCHIN, 2014; IBGE, 2024).
2.6 Problemas de Qualidade em Dados Públicos Tabulares
Embora os dados públicos sejam disponibilizados de forma estruturada e acessível, eles frequentemente apresentam problemas de qualidade que podem comprometer a análise estatística e a utilização em modelos de Machine Learning. A qualidade dos dados é determinada por atributos como completude, consistência, precisão, padronização e confiabilidade, sendo essencial identificar e tratar deficiências antes de realizar qualquer processamento analítico (BATINI; SCANNAPIECO, 2016).
No contexto de dados públicos tabulares brasileiros, os problemas mais recorrentes incluem valores ausentes, duplicidades, inconsistências semânticas e falta de padronização, que impactam diretamente a interpretação e o uso de informações em larga escala.
2.6.1 Valores Ausentes
Valores ausentes ocorrem quando determinados campos em registros não contêm informação, podendo derivar de falhas na coleta, preenchimento incorreto ou restrições de acesso. Em bases públicas tabulares, essa ocorrência é comum em registros de saúde, educação ou finanças, especialmente em variáveis opcionais ou historicamente subnotificadas. A presença de valores ausentes altera a distribuição estatística dos dados, podendo enviesar análises e prejudicar o desempenho de algoritmos de Machine Learning que dependem de informações completas (CHEN et al., 2020).
2.6.2 Duplicidades
Duplicidades são registros repetidos ou parcialmente redundantes que representam o mesmo evento ou unidade observacional. Elas podem surgir devido a processos de integração de múltiplas fontes, erros humanos ou falhas na atualização de sistemas. A duplicidade gera distorções estatísticas, como contagem incorreta de ocorrências, e pode influenciar negativamente métricas de aprendizado de máquina, especialmente em modelos sensíveis à frequência de eventos (BATINI; SCANNAPIECO, 2016).
2.6.3 Inconsistências Semânticas
Inconsistências semânticas ocorrem quando valores em uma variável apresentam significados divergentes, por exemplo, diferenças de nomenclatura, abreviações distintas ou categorização heterogênea. Em bases públicas, isso é frequente em registros provenientes de diferentes órgãos ou períodos. Tais inconsistências dificultam a agregação e análise comparativa, e podem induzir erros na interpretação dos resultados de modelos preditivos (WANG et al., 1998).
2.6.4 Falta de Padronização
A falta de padronização refere-se à ausência de uniformidade em formatos, unidades de medida, escalas ou regras de codificação. Por exemplo, uma variável de datas pode apresentar formatos diferentes (DD/MM/AAAA ou AAAA-MM-DD) ou uma variável de valor financeiro pode ser registrada em reais, centavos ou milhares de reais sem padronização. Esse problema exige tratamento prévio, como normalização e padronização, para permitir comparações consistentes e evitar interpretações incorretas em análises estatísticas e modelos de Machine Learning (BATINI; SCANNAPIECO, 2016).
A identificação e o tratamento desses problemas são etapas críticas na preparação de bases públicas para análise quantitativa, permitindo que os algoritmos interpretem corretamente os dados e reduzindo o risco de viés ou erro em predições.
2.7 Relação entre Dados Públicos e Modelos de Machine Learning
A aplicação de modelos de Machine Learning em bases públicas tabulares requer atenção à qualidade e à estrutura dos dados. Dados públicos possuem características específicas, como volume elevado, heterogeneidade e potencial de inconsistências, que impactam diretamente o desempenho dos modelos clássicos de aprendizado de máquina. Esta seção apresenta a correlação entre esses dados e o comportamento dos modelos, destacando como problemas de qualidade podem influenciar os resultados das análises.
2.7.1 Comportamento dos Dados Tabulares em Modelos Clássicos
Os dados tabulares públicos, organizados em linhas e colunas, são particularmente adequados para modelos de regressão, árvores de decisão e KNN. Cada registro (linha) representa uma observação, enquanto cada variável (coluna) fornece informações que alimentam o modelo.
1. Regressão Linear e Logística: sensíveis à distribuição estatística dos dados, sendo impactadas por outliers e valores ausentes.
2. Árvores de Decisão: relativamente robustas a valores ausentes e heterogeneidade, mas ainda dependem de consistência na categorização das variáveis.
3. K-Nearest Neighbors (KNN): altamente sensível a escalas e métricas de distância; valores extremos ou inconsistentes podem distorcer a identificação de vizinhos mais próximos. Essa interação mostra que, mesmo sem intervenção computacional, a estrutura e a qualidade dos dados públicos determinam o comportamento dos modelos, influenciando previsões, classificações e a generalização das relações aprendidas (HASTIE; TIBSHIRANI; FRIEDMAN, 2009).
2.7.2 Impacto da Qualidade dos Dados no Desempenho
Problemas de qualidade em dados públicos podem gerar efeitos significativos nos modelos de Machine Learning:
1. Valores ausentes: reduzem o tamanho efetivo da amostra ou requerem imputação, podendo alterar a distribuição das variáveis.
2. Duplicidades: introduzem vieses, pois registros repetidos afetam médias, probabilidades e métricas de distância.
3. Inconsistências semânticas: dificultam a categorização correta, prejudicando algoritmos de classificação.
4. Falta de padronização: dificulta a integração entre múltiplas bases, aumentando erros de interpretação.
O impacto se traduz em redução da precisão, aumento da variância e, em alguns casos, resultados contraditórios, reforçando a necessidade de estratégias adequadas de preparação e tratamento dos dados antes da aplicação de qualquer modelo (BATINI; SCANNAPIECO, 2016).
2.7.3 Técnicas de Tratamento de Dados Aplicadas à ML
Para mitigar os problemas de qualidade, é possível aplicar abordagens teóricas de tratamento de dados sem necessariamente programar:
1. Imputação de valores ausentes: métodos simples, como média ou mediana, podem restaurar a integridade da distribuição das variáveis.
2. Remoção de duplicidades: aplicação de regras lógicas para identificar e eliminar registros repetidos.
3. Padronização de categorias: uniformização de nomes, códigos ou classes de variáveis categóricas.
4. Normalização e escalonamento: ajusta variáveis numéricas para faixas compatíveis, especialmente relevante para KNN.
5. Detecção de outliers: análise de desvio padrão ou desvio absoluto, permitindo identificar valores que possam distorcer os modelos.
Essas técnicas, mesmo apresentadas conceitualmente, permitem demonstrar que a preparação adequada de dados públicos influencia diretamente o desempenho dos modelos
3. Metodologia (Teórica e Matematicamente Fundamentada)
Este estudo adota uma abordagem inteiramente teórica, com demonstrações matemáticas simples e aplicadas a modelos clássicos de Machine Learning, visando inferir o impacto que diferentes tratamentos para valores ausentes exercem sobre o comportamento funcional desses modelos.
3.1 Etapas da Análise Teórica
A análise segue quatro etapas conceituais:
1. Seleção do problema específico de qualidade dos dados: problema escolhido = valores ausentes
2. Aplicação teórica de dois métodos de imputação:
método 1 = média método 2 = mediana
3. Observação do efeito do valor imputado sobre as funções matemáticas dos modelos.
4. Inferência teórica da tendência de desempenho (não empírico).
3.2 Imputação Matemática
Para um conjunto de valores incompletos representado por:
conjunto = {valores válidos, valores faltantes} A imputação pela média será:
imputação media = soma(valores válidos) / quantidade(valores válidos
Enquanto a imputação pela mediana será:
imputação mediana = valor central ordenado(valores válidos)
A média depende de todos os valores. A mediana depende apenas da posição.
3.3 Análise do Impacto na Função dos Modelos
O impacto será observado avaliando como o valor imputado modifica cada função:


4. Resultados (Teóricos)
4.1 Regressão Linear
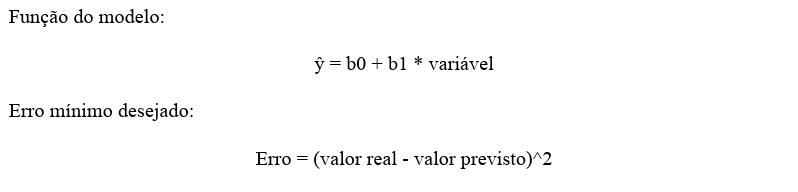
Quando a imputação é feita por média, valores extremos alteram variável, deslocando o coeficiente b1.
Com mediana, o valor permanece mais estável, e b1 sofre menor variação. Inferência teórica: menor erro médio quando imputado pela mediana.
4.2 Regressão Logística

pode crescer exageradamente, modificando a probabilidade prevista sem necessidade. Inferência teórica: menor perturbação das probabilidades quando usada mediana.
4.3 Árvores de Decisão
As divisões são escolhidas buscando mínima impureza:
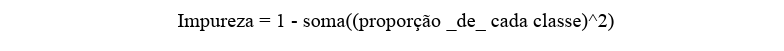
A média altera grupos ao adicionar valores influenciados por extremos, modificando proporções. A mediana mantém grupos mais estáveis.
Inferência teórica: mediana leva a cortes mais “puros”.
4.4 KNN (K Vizinhos Mais Próximos)

Isso causa classificação incorreta de vizinhos, aumentando erros. Com mediana, a diferença é menor, logo:
Inferência teórica: mediana reduz risco de vizinho errado.
5. Discussão
A imputação pela média aumenta o impacto de termos quadráticos e exponenciais nos modelos, como:

Assim, a mediana preserva uma estrutura matemática estável para aprendizado.
6. Conclusão
Com base em toda a análise teórica desenvolvida:
1. A média é instável diante de valores extremos, alterando coeficientes, probabilidades, distâncias e impurezas.
2. A mediana é robusta, pois depende da posição e não da magnitude dos valores.
3. Logo, a imputação por mediana tende teoricamente a produzir maior precisão e estabilidade, especialmente em bases públicas com alta presença de inconsistências.
Conclusão Final:
A mediana preserva melhor a integridade estatística dos dados e, consequentemente, conduz a modelos clássicos de Machine Learning teoricamente mais precisos e estáveis quando aplicada a bases tabulares públicas brasileiras.
7. Referências
ALPAYDIN, E. Introduction to Machine Learning. 4. ed. Cambridge: MIT Press, 2020.
BATINI, C.; SCANNAPIECO, M. Data Quality: Concepts, Methodologies and Techniques. Cham: Springer, 2016.
BISHOP, C. M. Pattern Recognition and Machine Learning. New York: Springer, 2006.
BRASIL. Lei nº 12.527, de 18 de novembro de 2011. Dispõe sobre o acesso a informações e altera a Lei nº 11.111, de 5 de maio de 2005. Disponível em: http://www.planalto.gov.br/ccivil_03/_ato2011-2014/2011/lei/l12527.htm. Acesso em: 25 nov. 2025.
BRASIL. Portal Brasileiro de Dados Abertos. Disponível em: https://dados.gov.br/. Acesso em: 25 nov. 2025.
CHEN, H. et al. Data Preprocessing for Machine Learning: A Review. IEEE Access, v. 8, p. 54776-54794, 2020.
DARTMOUTH COLLEGE. Birthplace of Artificial Intelligence. Dartmouth News, 2024. Disponível em: https://home.dartmouth.edu/about/artificial-intelligence-ai-coined-dartmouth. Acesso em: 25 nov. 2025.
DIO. Árvores de decisão, regressão logística e SVM: qual escolher e quando? 2024. Disponível em: https://www.dio.me/articles/arvores-de-decisao-regressao-logistica-e-svm-qual-escolher-e-quand o. Acesso em: 25 nov. 2025.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. Cambridge: MIT Press, 2016.
HASTIE, T.; TIBSHIRANI, R.; FRIEDMAN, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2. ed. New York: Springer, 2009.
IBGE. Estatísticas e bases de dados. Instituto Brasileiro de Geografia e Estatística, 2024. Disponível em: https://www.ibge.gov.br/. Acesso em: 25 nov. 2025.
IBM. What is Artificial Intelligence (AI)? IBM Knowledge Center, 2024. Disponível em: https://www.ibm.com/topics/artificial-intelligence. Acesso em: 25 nov. 2025.
ICHI.PRO. Regressão Logística: a matemática por trás disso, como funciona e um exemplo. 2025. Disponível em: https://ichi.pro/pt/regressao-logistica-a-matematica-por-tras-disso-como-funciona-e-um-exemplo -8611601809795. Acesso em: 25 nov. 2025.
JASON, H.; SMITH, A.; JOHNSON, R. Open Government Data and Data Quality: Implications for Analysis. Journal of Data Science, v. 18, n. 2, p. 115-132, 2020.
KITCHIN, R. The Data Revolution: Big Data, Open Data, Data Infrastructures & Their Consequences. London: Sage, 2014.
MITCHELL, T. M. Machine Learning. New York: McGraw-Hill, 1997.
NEVES, R. C. Introdução à regressão linear em estatística aplicada. Porto Alegre: UFRGS, 2003. Disponível em: https://repositorio.ufrgs.br/bitstream/handle/10183/2701/000375412.pdf. Acesso em: 25 nov. 2025.
RUSSELL, S.; NORVIG, P. Artificial Intelligence: A Modern Approach. 4. ed. New York: Pearson, 2022.
SURYA PRASATH, V. B.; RAJ, S.; KUMAR, P. K-Nearest Neighbors: A Study and Application. 2017. Disponível em: https://arxiv.org/abs/1708.04321. Acesso em: 25 nov. 2025.
WANG, R. Y.; PIETERS, C. M.; STRONG, D. M. Beyond Accuracy: What Data Quality Means to Data Consumers. Journal of Management Information Systems, v. 12, n. 4, p. 5-34, 1998.
ZHOU, Z.; ZHOU, X.; ZHOU, L. Machine Learning Applications in Data Science. Singapore: Springer, 2021.
¹Graduando em Engenharia de Software, 8º período, Instituto de Ensino Superior iCEV, Teresina – PI. E-mail:
kawan.barros@somosicev.com
²Mauro José Araujo de Melo – Mestre em Engenharia Elétrica, Universidade Federal do Maranhão – UFMA. E-mail:
mauro.melo@somosicev.com