REGISTRO DOI: 10.69849/revistaft/ch10202511261358
Caique Michel de Aquino Elias
Guilherme dos Santos Valentim de Oliveira
Jean Acêdo Silva
Orientador(a): Micaella Garcia Fontes Gatti
RESUMO
Este estudo apresenta uma avaliação da disponibilidade e qualidade dos dados do Sistema de Informação em Saúde e Ambiente da Web (SISAWEB) para vigilância de arboviroses no estado de São Paulo. Foram analisadas as coberturas e dos dados fornecidos pelas Application Programming Interfaces – APIs do sistema, incluindo 681.120 consultas realizadas em 645 municípios paulistas ao longo de 66 meses (2020-2025), abrangendo 16 APIs distintas do sistema. Os resultados revelam que apenas 36,16% das consultas retornaram dados com sucesso, enquanto 63,74% apresentaram ausência de dados e 0,10% resultaram em erros. Através de análise de clusterização utilizando K-means (k=4), identificou-se que apenas 6 municípios (0,9%) demonstram excelência em dados de vigilância, com média de 2.331 linhas de dados por cidade e taxa de sucesso de 68,21%. Em contraste, 354 municípios (54,9%) apresentam volume mínimo de dados (média de 12,68 linhas) e baixa disponibilidade (30,49% de sucesso). A análise temporal semestral evidenciou melhora gradual na taxa de sucesso, passando de 32,74% no primeiro semestre de 2020 para 39,38% no primeiro semestre de 2025, representando um aumento de 6,64 pontos percentuais. A comparação entre os 6 melhores e 6 piores municípios revelou uma distância de 64,11 pontos percentuais na taxa de sucesso, indicando significativas desigualdades regionais na capacidade de produção e gestão de dados de vigilância epidemiológica. Os achados evidenciam a necessidade urgente de investimentos em infraestrutura, capacitação técnica e políticas de qualidade de dados para fortalecer os sistemas de vigilância em saúde, especialmente em municípios de menor porte.
Palavras-chave: SISAWEB. Vigilância Epidemiológica. Arboviroses. Qualidade de Dados. Sistemas de Informação em Saúde. Análise de Clusters. Políticas Públicas. Controle de Vetores.
1 INTRODUÇÃO
As arboviroses representam um desafio significativo para a saúde pública no Brasil, especialmente no estado de São Paulo, que abriga a maior população urbana do país. O Sistema de Informação em Saúde e Ambiente da Web (SISAWEB) foi desenvolvido para auxiliar na vigilância e controle dessas doenças, fornecendo dados essenciais para o planejamento e execução de ações de prevenção e controle.
A disponibilidade e qualidade dos dados de vigilância epidemiológica são fundamentais para a tomada de decisões baseadas em evidências. Sistemas de informação robustos e confiáveis permitem identificar tendências, detectar surtos precocemente e avaliar a efetividade das intervenções em saúde pública. No entanto, a efetividade desses sistemas depende não apenas de sua implementação técnica, mas também da capacidade local de coleta, processamento e disponibilização de dados.
Este estudo apresenta uma análise abrangente da disponibilidade e qualidade dos dados do SISAWEB, abrangendo 645 municípios paulistas ao longo de 66 meses (janeiro de 2020 a junho de 2025). Foram realizadas 681.120 consultas em 16 APIs distintas do sistema, permitindo uma avaliação detalhada dos padrões de disponibilidade de dados, disparidades regionais e evolução temporal do sistema.
Os objetivos específicos deste trabalho incluem: (1) quantificar as taxas de sucesso, ausência de dados e erros nas consultas ao SISAWEB; (2) identificar padrões de disponibilidade de dados através de análise de clusterização; (3) avaliar a evolução temporal da qualidade dos dados; (4) comparar o desempenho entre municípios com melhores e piores indicadores; e (5) identificar APIs com maior e menor disponibilidade de dados.
2 REFERENCIAL TEÓRICO
2.1 Vigilância Epidemiológica de Arboviroses no Brasil
As arboviroses, doenças transmitidas por artrópodes vetores, constituem importante problema de saúde pública no Brasil. Dengue, Zika e Chikungunya são as principais arboviroses urbanas, transmitidas pelo mosquito Aedes aegypti. A vigilância epidemiológica dessas doenças requer sistemas de informação eficientes que permitam o monitoramento contínuo da situação epidemiológica e a detecção precoce de surtos.
2.2 Sistemas de Informação em Saúde
Os sistemas de informação em saúde desempenham papel fundamental na gestão dos serviços e na vigilância epidemiológica. A qualidade desses sistemas depende de múltiplos fatores, incluindo infraestrutura tecnológica, capacitação de recursos humanos, processos de trabalho adequados e governança de dados. A literatura enfatiza a importância da completude, consistência e oportunidade dos dados para a efetividade dos sistemas de vigilância.
2.3 O Sistema SISAWEB
O SISAWEB é um sistema de informação desenvolvido pelo estado de São Paulo para apoiar as ações de vigilância e controle de vetores de arboviroses. O sistema disponibiliza 16 APIs (Application Programming Interfaces) distintas que fornecem dados sobre diferentes aspectos da vigilância entomológica e epidemiológica, incluindo levantamentos de índices larvários, controle vetorial, notificações de casos e caracterização ambiental.
2.4 Os Endpoints do Sistema SISAWEB
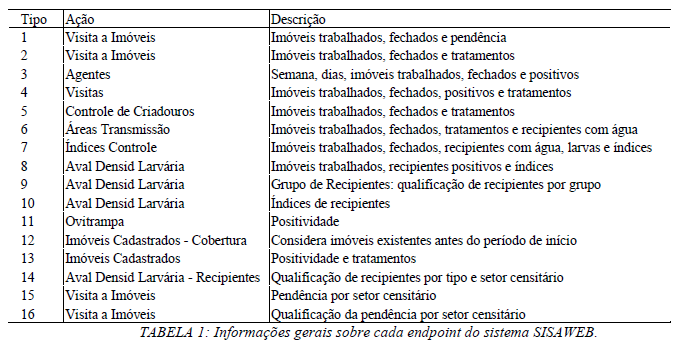
O SISAWEB é um sistema que contém uma estrutura de requisição dividida em 16 endpoints (endereços web) determinados tipos. Cada endpoint possui um tema retratado dentro das informações disseminadas sobre o vetor. Para facilitar a compreensão, foi criada a tabela a seguir contendo todos os 16 endpoints em ordem:
3 METODOLOGIA
3.1 Coleta de Dados
A coleta de dados foi realizada mediante consultas sistemáticas às 16 APIs do SISAWEB, abrangendo todos os 645 municípios do estado de São Paulo. O período de análise compreendeu 66 meses, de janeiro de 2020 a junho de 2025. Para cada município e mês, foram realizadas consultas a todas as APIs disponíveis, totalizando 681.120 consultas. As consultas foram realizadas de forma automatizada através de scripts Python, registrando-se o status de cada resposta (sucesso, sem dados, ou erro), o código de resposta HTTP e o volume de dados retornados (quantidade de linhas).
3.2 Análise de Dados
A análise dos dados foi conduzida em múltiplas etapas. Primeiramente, realizou-se uma análise descritiva geral das taxas de sucesso, ausência de dados e erros. Em seguida, aplicou-se o algoritmo K-means para clusterização dos municípios com base em 8 features: taxa de sucesso, taxa de sem dados, taxa de erro, diversidade de respostas HTTP, média de linhas, mediana de linhas, máximo de linhas e total de linhas acumuladas. O método do cotovelo foi utilizado para determinar o número ideal de clusters (k=4). Todas as features foram normalizadas utilizando StandardScaler antes da clusterização. A análise temporal foi conduzida em granularidade semestral para identificar tendências e variações sazonais. Por fim, realizou-se análise comparativa entre os 6 municípios com melhor e pior desempenho geral. Todas as análises e visualizações foram realizadas utilizando Python com as bibliotecas pandas, scikit-learn e plotly.
4 RESULTADOS E DISCUSSÃO
4.1 Panorama Geral da Disponibilidade de Dados
Das 681.120 consultas realizadas ao SISAWEB, apenas 246.303 (36,16%) retornaram dados com sucesso, enquanto 434.144 (63,74%) apresentaram ausência de dados e 673 (0,10%) resultaram em erros técnicos. Esses números revelam que a maioria das consultas não retornam dados, indicando tanto lacunas na cobertura do sistema quanto possíveis deficiências na alimentação de dados pelos municípios.
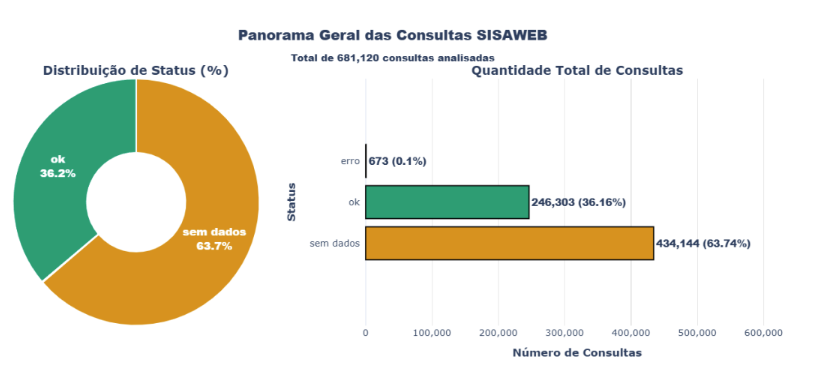
FIGURA 1: Panorama Geral das Consultas SISAWEB – Gráfico de pizza mostrando distribuição de status (ok, sem dados, erro) e gráfico de barras com quantidade total de consultas.
A baixa taxa de retorno de dados (36,16%) é particularmente preocupante considerando a importância desses dados para a vigilância epidemiológica. A predominância de consultas sem dados (63,74%) pode refletir diferentes cenários: ausência real de atividades de vigilância nos municípios, dados coletados mas não digitados no sistema, problemas de integração entre sistemas locais e o SISAWEB, ou municípios que utilizam sistemas alternativos. A baixa taxa de erros (0,10%) sugere que o sistema possui boa estabilidade técnica, e que o problema principal não é de infraestrutura tecnológica, mas sim de alimentação de dados. Contudo dados os testes seguidos nas APIs com erro, e suas respectivas falhas consecutivas, indica também a persistência e consistência do erro de requisição para as consultas em questão.
4.2 Padrões de Disponibilidade: Análise de Clusters
A análise de clusterização a partir do método da curva do cotovelo identificou quatro grupos distintos de municípios com padrões de disponibilidade de dados significativamente diferentes:
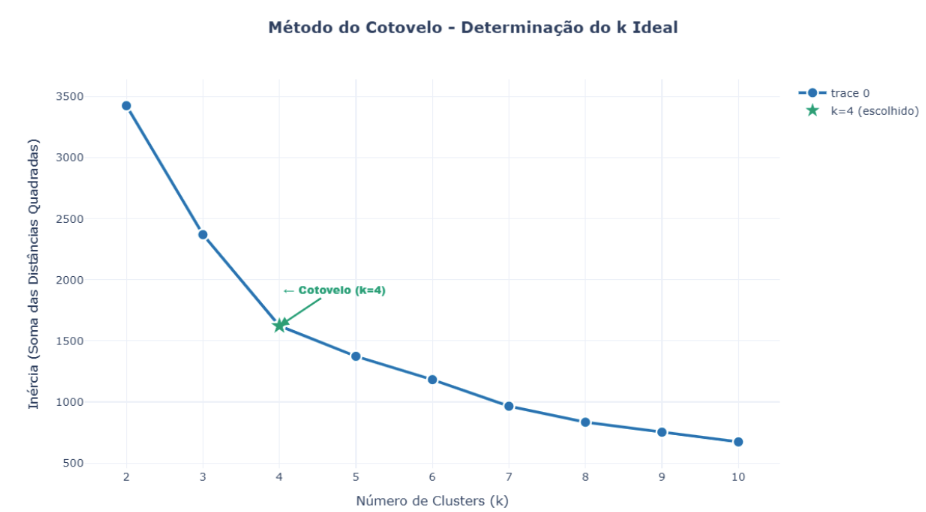
FIGURA 2: Método do Cotovelo – Gráfico mostrando inércia vs número de clusters com destaque para k=4
Cluster 0 (354 municípios – 54,9%): “Baixa Disponibilidade – Volume Mínimo”. Este grupo, que representa mais da metade dos municípios paulistas, apresenta baixa taxa de sucesso (30,49%), alta taxa de sem dados (69,51%) e volume mínimo de registros (média de 12,68 linhas por cidade). Com total acumulado de 4.739.350 linhas, esses municípios caracterizam-se por dados muito escassos, sugerindo limitações estruturais nos sistemas locais de vigilância.
Cluster 1 (108 municípios – 16,7%): “Boa Disponibilidade – Volume Médio-Alto”. Com taxa de sucesso de 59,82%, taxa moderada de sem dados (40,09%) e média de 343,78 linhas por cidade, este grupo demonstra estrutura consolidada de vigilância. Notavelmente, este cluster concentra o maior volume total de dados (39.207.299 linhas), indicando que esses municípios são responsáveis pela maior parte da produção de dados do sistema, apesar de representarem apenas 16,7% do total de municípios.
Cluster 2 (177 municípios – 27,4%): “Baixa Disponibilidade – Volume Baixo com Erros”. Este grupo apresenta baixa taxa de sucesso (31,99%), alta taxa de sem dados (67,71%) e a maior taxa de erros entre todos os clusters (0,31%). Com média de apenas 19,31 linhas e total acumulado de 3.608.520 linhas, esses municípios enfrentam tanto problemas técnicos quanto baixo volume de dados, sugerindo infraestrutura problemática ou dados inconsistentes.
Cluster 3 (6 municípios – 0,9%): “Excelência – Altíssima Disponibilidade e Volume Massivo”. Este grupo de elite apresenta o melhor desempenho em todos os indicadores: taxa de sucesso de 68,21%, baixa taxa de sem dados (31,71%) e média excepcional de 2.331,05 linhas por cidade – 185 vezes superior ao Cluster 0. Os municípios deste cluster (Itu, São Bernardo do Campo, Presidente Prudente, Votuporanga, Lençóis Paulista e Santa Bárbara d’Oeste) acumulam 14.769.521 linhas e representam referência de excelência em sistemas de vigilância epidemiológica.
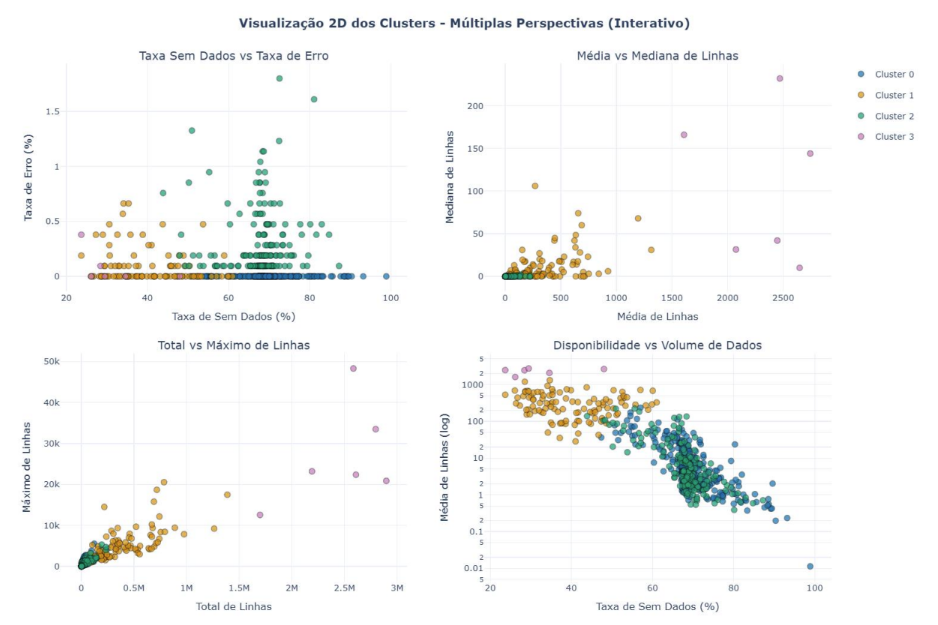
FIGURA 3: Visualização 2D dos Clusters – 4 subplots mostrando diferentes perspectivas dos clusters (Taxa Sem Dados vs Taxa de Erro; Média vs Mediana de Linhas; Total vs Máximo de Linhas; Disponibilidade vs Volume)
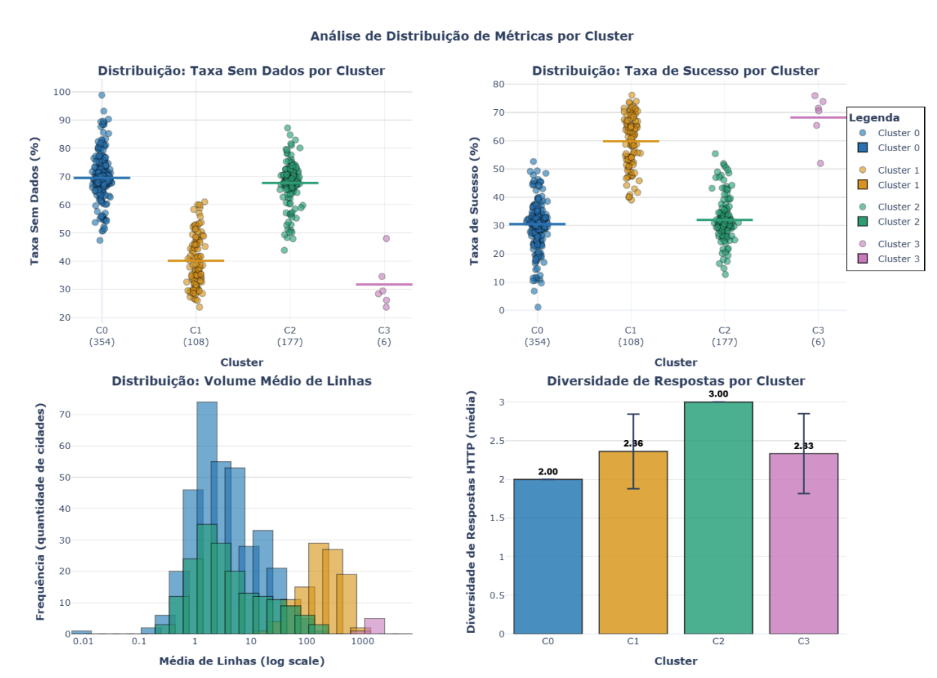
FIGURA 4: Análise de Distribuição de Métricas por Cluster – 4 painéis: (1) Strip plot de Taxa Sem Dados, (2) Strip plot de Taxa de Sucesso, (3) Histograma de Média de Linhas em escala log, (4) Barras de Diversidade de Respostas
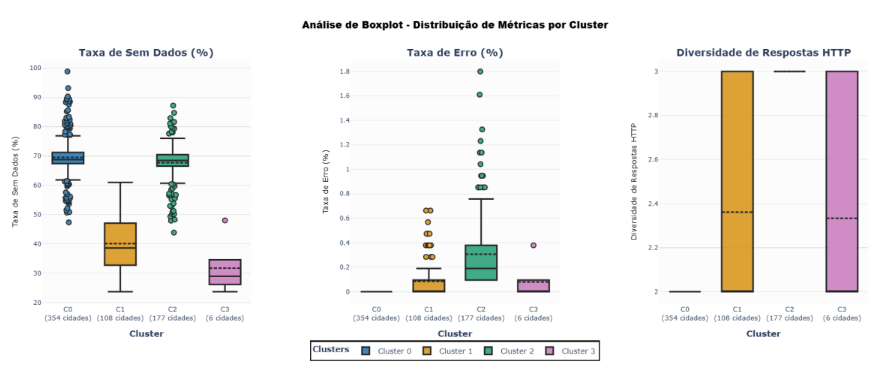
FIGURA 5: Boxplots das Features por Cluster – 3 boxplots mostrando distribuição de Taxa de Sem Dados, Taxa de Erro e Diversidade de Respostas HTTP por cluster
A análise de clusters revela desigualdades substanciais na capacidade de produção e gestão de dados de vigilância epidemiológica entre os municípios paulistas. Enquanto apenas 0,9% dos municípios (Cluster 3) demonstram excelência, mais da metade (54,9% – Cluster 0) apresenta volume mínimo de dados. Esta disparidade sugere que fatores como porte populacional, recursos financeiros, capacitação técnica e estrutura de vigilância desempenham papel determinante na qualidade dos dados produzidos.
4.3 Análise de Disponibilidade por API
A análise individual das 16 APIs do SISAWEB revela variações significativas na disponibilidade de dados. As APIs 8 e 9 apresentam as maiores taxas de sucesso (26,66% e 26,69%, respectivamente), seguidas pelas APIs 4 e 7 (ambas com 19,33%). Em contraste, a API 11 apresenta a menor taxa de sucesso (0,73%), com 99,27% de consultas sem dados, indicando baixíssima utilização ou cobertura. As APIs 1, 2 e 3 apresentam taxas idênticas (16,27% de sucesso), sugerindo possível correlação entre esses sistemas. A taxa média de sucesso entre todas as APIs é de 36,16%, consistente com o panorama geral.
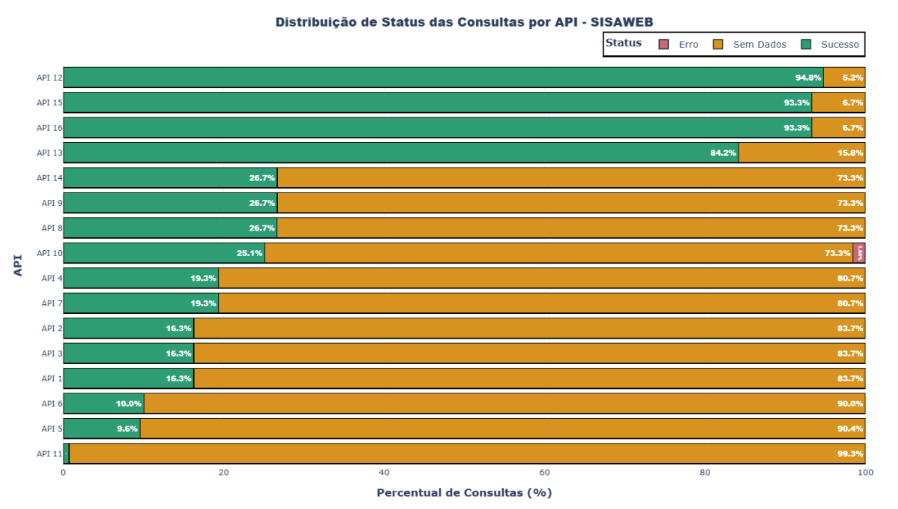
FIGURA 6: Distribuição de Status das Consultas por API – Gráfico de barras horizontais empilhadas mostrando percentual de Sucesso/Sem Dados/Erro para cada uma das 16 APIs, ordenadas por taxa de sucesso
A baixa taxa de erros em todas as APIs (variando de 0% a 1,56%) confirma que o sistema possui boa estabilidade técnica. A API 10 apresenta a maior taxa de erros (1,56%), mas ainda assim mantém taxa de sucesso de 25,13%. Esses resultados sugerem que diferentes APIs apresentam diferentes níveis de adesão pelos municípios, possivelmente refletindo a relevância de cada sistema para as atividades locais de vigilância, a facilidade de uso, a natureza do tema de cada uma das APIs individuais, ou a obrigatoriedade de alimentação de dados.
4.4 Evolução Temporal da Disponibilidade de Dados
A análise temporal semestral revela tendência de melhora gradual na disponibilidade de dados ao longo do período estudado. A taxa de sucesso evoluiu de 32,74% no primeiro semestre de 2020 (2020-S1) para 39,38% no primeiro semestre de 2025 (2025-S1), representando aumento de 6,64 pontos percentuais (20,3% de melhora relativa). O melhor desempenho foi observado em 2024- S1, com taxa de sucesso de 40,49%, enquanto o pior desempenho ocorreu em 2020-S2, com apenas 29,65% de sucesso.
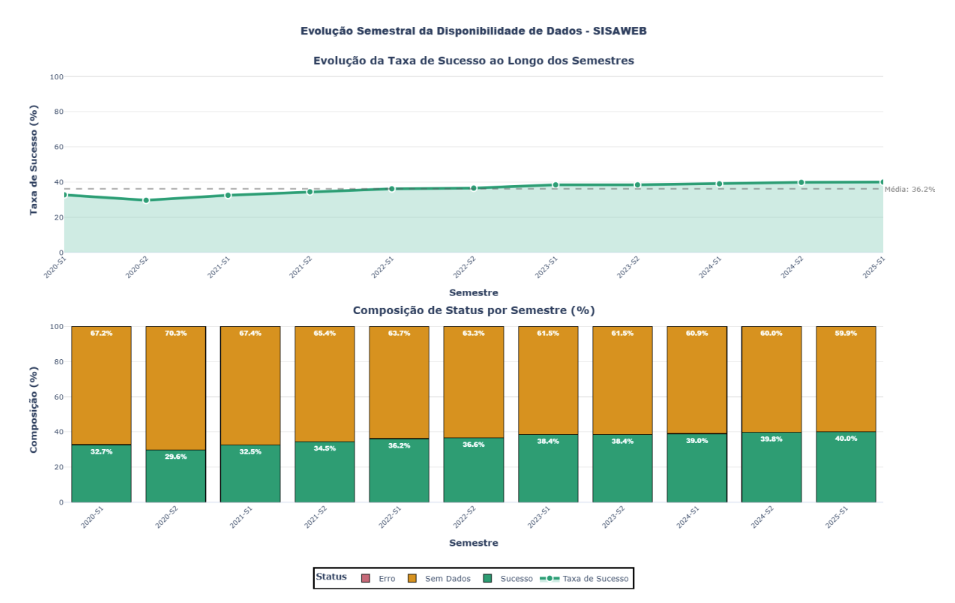
FIGURA 7: Evolução Semestral da Disponibilidade de Dados – 2 painéis: (1) Gráfico de linha mostrando evolução da taxa de sucesso com área preenchida e linha de média geral, (2) Barras empilhadas mostrando composição de status (Sucesso/Sem Dados/Erro) por semestre
A análise semestral permite identificar variações sazonais e períodos críticos. Observa-se melhora consistente entre 2020 e 2024, com destaque para os anos de 2022 e 2023, que apresentaram as maiores taxas de crescimento. Em 2025-S1, observa-se pequena redução em relação a 2024-S2, mas ainda assim mantendo-se acima da média histórica. Esta melhora gradual pode refletir investimentos em infraestrutura, capacitação de equipes municipais, aprimoramentos no sistema ou maior conscientização sobre a importância da qualidade de dados.
4.5 Análise Comparativa: Melhores vs Piores Municípios
A comparação detalhada entre os 6 municípios com melhor desempenho (Taciba, Presidente Prudente, Itararé, Santa Bárbara d’Oeste, Pindorama e Tambaú) e os 6 com pior desempenho (Piracaia, Salesópolis, Pinhalzinho, Iporanga, Rafard e Pedra Bela) revela disparidades marcantes. Os municípios do TOP 6 apresentam taxa média de sucesso de 74,55%, enquanto os do BOTTOM 6 apresentam apenas 10,45%, resultando em uma distância de 64,11 pontos percentuais.
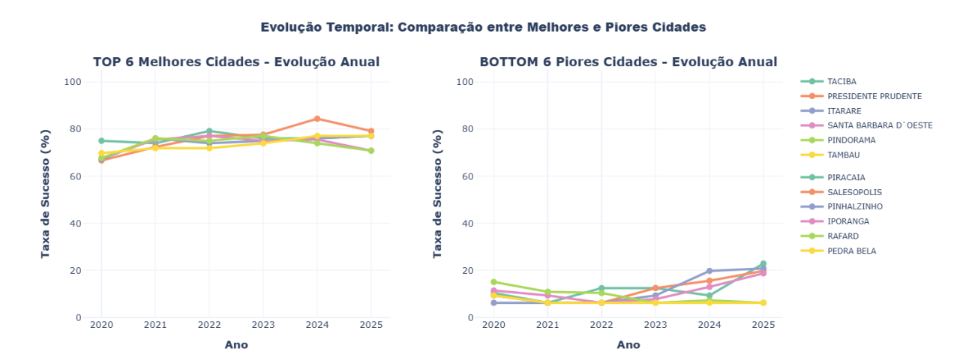
FIGURA 8: Evolução Temporal TOP 6 vs BOTTOM 6 – 2 painéis lado a lado mostrando evolução anual da taxa de sucesso dos 6 melhores municípios (esquerda) e 6 piores municípios (direita)
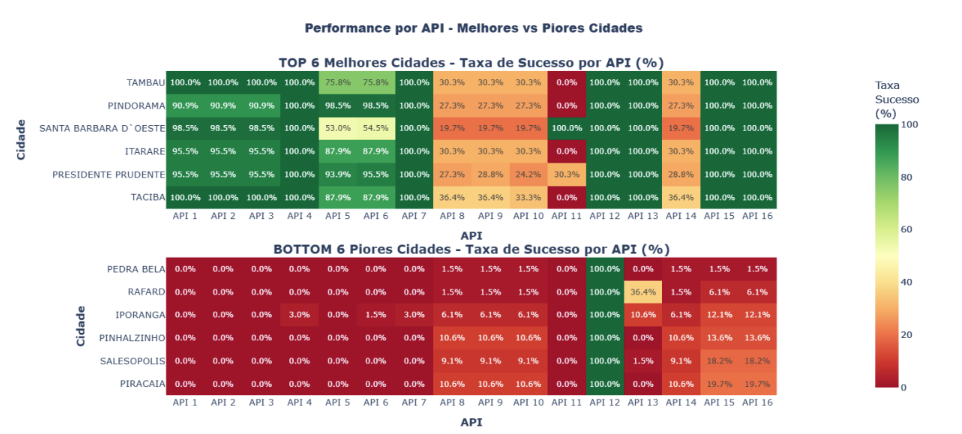
FIGURA 9: Heatmap de Performance por API – 2 heatmaps empilhados verticalmente mostrando taxa de sucesso por API para TOP 6 (acima) e BOTTOM 6 (abaixo), com escala de cores verde (alta) a vermelho (baixa)
A análise por API revela que a distância entre os grupos varia conforme a API analisada. APIs com grande distância (>50 pontos percentuais) indicam forte dependência de infraestrutura e capacitação local, em que municípios bem estruturados obtêm sucesso mas municípios menores enfrentam dificuldades. APIs com distância média (20-50 pp) apresentam disparidades moderadas, sugerindo problemas mistos (local + sistêmico). APIs com distância baixa (<20 pp) e taxas baixas em ambos os grupos indicam problemas sistêmicos que afetam todos os municípios independentemente de seu porte ou capacidade.
A evolução temporal demonstra que ambos os grupos apresentaram melhora ao longo do período, mas o gap permanece substancial, evidenciando que as desigualdades estruturais persistem. Os municípios do TOP 6 mantêm consistência temporal em seu desempenho, enquanto os do BOTTOM 6 apresentam maior variabilidade, sugerindo instabilidade nos sistemas locais de vigilância.
5 CONSIDERAÇÕES FINAIS
Este estudo apresentou uma avaliação abrangente da disponibilidade e qualidade dos dados do SISAWEB para vigilância de arboviroses no estado de São Paulo. Os resultados evidenciam cenário preocupante: apenas 36,16% das consultas retornam dados com sucesso, e mais da metade dos municípios (54,9%) apresenta volume mínimo de dados. Apenas 6 municípios (0,9%) demonstram excelência em dados de vigilância, revelando profundas desigualdades regionais na capacidade de produção e gestão de dados epidemiológicos.
A análise de clusterização identificou quatro perfis distintos de municípios, permitindo caracterizar padrões de disponibilidade e direcionar intervenções específicas para cada grupo. A evolução temporal demonstra melhora gradual (6,64 pontos percentuais entre 2020 e 2025), mas insuficiente para alcançar níveis adequados de cobertura. A análise comparativa entre melhores e piores municípios revelou uma distância de 64,11 pontos percentuais, evidenciando que fatores locais (infraestrutura, recursos, capacitação) desempenham papel determinante na qualidade dos dados.
Com base nos achados, recomendam-se investigações como próximos passos das seguintes ações prioritárias: (1) investimento em infraestrutura tecnológica e capacitação técnica para municípios dos Clusters 0 e 2, que concentram 531 municípios (82,3%) com baixa disponibilidade de dados; (2) implementação de programa de benchmarking utilizando os 6 municípios de excelência (Cluster 3) como referência de boas práticas; (3) revisão das APIs com baixíssima utilização (especialmente API 11 com 0,73% de sucesso) para identificar barreiras técnicas ou operacionais; (4) estabelecimento de políticas de governança de dados com metas de qualidade e completude; (5) criação de sistema de monitoramento contínuo da qualidade dos dados com alertas automáticos para municípios com deterioração de indicadores.
Este trabalho contribui para a literatura ao fornecer análise sistemática da qualidade de dados de sistemas de vigilância epidemiológica em larga escala, aplicando técnicas de machine learning (K-means) para identificação de padrões e segmentação de municípios. Limitações do estudo incluem a impossibilidade de análise de conteúdo dos dados retornados (apenas disponibilidade foi avaliada) e ausência de análise de fatores contextuais (socioeconômicos, demográficos) que possam explicar as disparidades observadas. Estudos futuros devem investigar determinantes das desigualdades identificadas e avaliar o impacto de intervenções direcionadas para melhoria da qualidade de dados.
A qualidade dos dados de vigilância epidemiológica é fundamental para ações efetivas de saúde pública. Os achados deste estudo evidenciam a urgência de investimentos e políticas voltadas ao fortalecimento dos sistemas de informação em saúde, especialmente em municípios de menor porte e capacidade técnica, para assegurar vigilância epidemiológica equitativa e eficaz em todo o estado de São Paulo.
REFERÊNCIAS
BARBOSA, GERSON LAURINDO, ANTÔNIO HENRIQUE ALVES GOMES, AND VERA LUCIA FONSECA DE CAMARGO-NEVES. 2023. “The SisaMob Information System: Implementation of Digital Data Collection as a Tool for Surveillance and Vector Control in the State of São Paulo.” Insects 14(4). doi:10.3390/insects14040380.
CHIAPPETTA, ESTELA CARDOSO, GIOVANNA GUALBERTO PERPÉTUO, REBECA VITÓRIA NOGUEIRA, JÚLIA APARECIDA LINTZ, DALCIANE RODRIGUES DE SOUZA, ROMEU RODRIGUES DE SOUZA, ÉRIC EDMRU ARRUDA. 2024. “ep-096 – Análise da distribuição mensal de casos de dengue no estado de São Paulo de janeiro de 2014 a abril de 2024.” The Brazilian Journal of Infectious Diseases 28(2): 104021. doi:10.1016/j.bjid.2024.104021.
GOMES, ANTONIO HENRIQUE ALVES, GERSON LAURINDO BARBOSA. 2019. “O Uso de Sistemas de Informação Para a Tomada de Decisões.” In Boletim Epidemiológico Paulista, , 29–30. doi:10.13140/RG.2.2.14730.31683.
MACHADO RABELO, CAMILA, AMANDA FREITAS POMPEU DOS SANTOS, MATHEUS BARROS CARVALHO, RAFAEL RODRIGUES DA CUNHA VIEGAS. 2024. “Dengue Em Território Brasileiro: Análise Das Taxas e Do Perfil de Morbidade.” Brazilian Journal of Implantology and Health Sciences 6(3): 566–74. doi:10.36557/2674- 8169.2024v6n3p566-574.
PEREIRA, MARIZA I, AKEMI SUZIKI, MICHELE HIGA FRÓES III, ADRIANA II YURIKA MAEDA, MARIÂNGELA IV GUANAES BORTOLO DA CRUZ, SILVIO V AUGUSTO MARGARIDO, RACHEL V HIDALGO SECCO, ANTONIO I HENRIQUE ALVES GOMES, DALVA I MARLI VALÉRIO WANDERLEY. 2013. “Dengue No Estado de São Paulo: Situação Epidemiológica e Ações Desenvolvidas Em 2013 Dengue in the State of São Paulo: Epidemiological Situation and Activities Developed in 2013.” Bepa 10(119): 3–14. http://periodicos.ses.sp.bvs.br/pdf/bepa/v10n119/v10n119a01.pdf.
CELEBI, M. E.; KINGRAVI, H. A.; VELA, P. A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Systems with Applications, v. 40, n. 1, p. 200-210, 2013. DOI: 10.1016/j.eswa.2012.07.021.
IKOTUN, A. M. et al. K-means clustering algorithms: a comprehensive review, variants analysis, and advances in the era of big data. Information Sciences, v. 622, p. 178-210, 2023. DOI: 10.1016/j.ins.2022.11.139.
SINAGA, K. P.; YANG, M. S. Unsupervised K-means clustering algorithm. IEEE Access, v. 8, p. 80716-80727, 2020. DOI: 10.1109/ACCESS.2020.2988796.
MCKINNEY, W. Python for data analysis: data wrangling with pandas, NumPy, and Jupyter. 3rd ed. Sebastopol: O’Reilly Media, 2022. 579 p.
PEDREGOSA, F. et al. Scikit-learn: machine learning in Python. Journal of Machine Learning Research, v. 12, p. 2825-2830, 2011.
PLOTLY TECHNOLOGIES INC. Collaborative data science. Montreal: Plotly Technologies Inc., 2015. Disponível em: https://plot.ly.
VANDERPLAS, J. Python data science handbook: essential tools for working with data. Sebastopol: O’Reilly Media, 2016. 541 p.
XU, D.; TIAN, Y. A comprehensive survey of clustering algorithms. Annals of Data Science, v. 2, n. 2, p. 165-193, 2015. DOI: 10.1007/s40745-015-0040-1.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 6022: informação e documentação: artigo em publicação periódica científica impressa: apresentação. Rio de Janeiro: ABNT, 2018.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 6023: informação e documentação: referências: elaboração. Rio de Janeiro: ABNT, 2018.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. NBR 10520: informação e documentação: citações em documentos: apresentação. Rio de Janeiro: ABNT, 2023.
ARTS, D. G. T.; DE KEIZER, N. F.; SCHEFFER, G. J. Defining and improving data quality in medical registries: a literature review, case study, and generic framework. Journal of the American Medical Informatics Association, v. 9, n. 6, p. 600-611, 2002. DOI: 10.1197/jamia.M1087.
CHAN, K. S. et al. Review of use of electronic health records for public health surveillance of infectious diseases. Current Epidemiology Reports, v. 4, n. 2, p. 163-170, 2017. DOI: 10.1007/s40471-017-0106-1.
LIMA, C. R. A. et al. Revisão das dimensões de qualidade dos dados e métodos aplicados na avaliação dos sistemas de informação em saúde. Cadernos de Saúde Pública, Rio de Janeiro, v. 25, n. 10, p. 2095-2109, 2009. DOI: 10.1590/S0102-311X2009001000002.
MILINOVICH, G. J. et al. Internet-based surveillance systems for monitoring emerging infectious diseases. The Lancet Infectious Diseases, v. 14, n. 2, p. 160-168, 2014. DOI: 10.1016/S1473-3099(13)70244-5.
OLIVEIRA, G. L. et al. Avaliação da completude dos dados de notificação de dengue no sistema de informação de agravos de notificação, Brasil, 2014. Epidemiologia e Serviços de Saúde,
Brasília, v. 27, n. 1, e201616120, 2018. DOI: 10.5epidemiol. Serv. Saúde, Brasília, 27(1):e201616120, 2018.
ROMERO, D. E.; CUNHA, C. B. Avaliação da qualidade das variáveis epidemiológicas e demográficas do Sistema de Informações sobre Nascidos Vivos, 2002. Cadernos de Saúde Pública, Rio de Janeiro, v. 23, n. 3, p. 701-714, 2007. DOI: 10.1590/S0102- 311X2007000300028.
WORLD HEALTH ORGANIZATION. Data quality review: a toolkit for facility data quality assessment. Geneva: WHO, 2017. (Module 1: Framework and metrics).
BRASIL. Ministério da Saúde. Secretaria de Vigilância em Saúde. Guia de vigilância em saúde. 5. ed. Brasília: Ministério da Saúde, 2022. 1126 p.
BRASIL. Ministério da Saúde. Secretaria de Vigilância em Saúde. Levantamento rápido de índices para Aedes aegypti (LIRAa) para vigilância entomológica do Aedes aegypti no Brasil: metodologia para avaliação dos índices de Breteau e Predial e tipo de recipientes. Brasília: Ministério da Saúde, 2013.
CHIAPPETTA, E. C. et al. Análise espacial da dengue e o contexto socioeconômico no município do Rio de Janeiro, RJ. Revista de Saúde Pública, São Paulo, v. 43, n. 4, p. 666-673, 2009. DOI: 10.1590/S0034-89102009005000037.
DONALISIO, M. R.; FREITAS, A. R. R.; ZUBEN, A. P. B. V. Arboviroses emergentes no Brasil: desafios para a clínica e implicações para a saúde pública. Revista de Saúde Pública, São Paulo, v. 51, art. 30, 2017. DOI: 10.1590/S1518-8787.2017051006889.
GUSMÃO, C. M. G.; PATRIOTA, A. C. L. S.; CARVALHO, I. L. Aedes aegypti e arboviroses no Brasil: uma revisão bibliográfica focada no zika vírus. Revista Brasileira de Inovação Tecnológica em Saúde, Natal, v. 8, n. 3, p. 33-48, 2019. DOI: 10.18816/r-bits.v8i3.16340.
LOPES, N.; LINHARES, R. E. C.; NOZAWA, C. Características gerais e epidemiologia dos arbovírus emergentes no Brasil. Revista Pan-Amazônica de Saúde, Ananindeua, v. 5, n. 3, p. 55- 64, 2014. DOI: 10.5123/S2176-62232014000300007.
MACHADO, L. A. et al. Arboviroses no Brasil: padrões epidemiológicos, impactos em saúde pública e desafios contemporâneos. Revista Ibero-Americana de Humanidades, Ciências e Educação, São Paulo, v. 11, n. 10, p. 3767-3774, 2025. DOI: 10.51891/rease.v11i10.21375.
PEREIRA, A. C. S. et al. Análise de dados sobre as arboviroses dengue, zika e chikungunya no sudeste brasileiro. ARACÊ – Direitos Humanos em Revista, São Paulo, v. 6, n. 3, p. 6786-6798, 2024. DOI: 10.56238/arev6n3-149.
SÃO PAULO (Estado). Secretaria de Estado da Saúde. Centro de Vigilância Epidemiológica “Prof. Alexandre Vranjac”. Manual de vigilância acarológica. São Paulo: CVE, 2004. 62 p.
SOUZA, E. R. M. et al. Epidemiological study of evaluation of increased incidence of arboviroses as a result of dam breaking in Minas Gerais, Brazil. Research, Society and Development, Vargem Grande Paulista, v. 10, n. 1, e18210111529, 2021. DOI: 10.33448/rsd v10i1.11529.
TAUIL, P. L. Urbanização e ecologia do dengue. Cadernos de Saúde Pública, Rio de Janeiro, v. 17, supl., p. 99-102, 2001. DOI: 10.1590/S0102-311X2001000700018.
LIMA, C. R. A.; SCHRAMM, J. M. A.; COELI, C. M.; SILVA, M. E. M. Revisão das dimensões de qualidade dos dados e métodos aplicados na avaliação dos sistemas de informação em saúde. Cadernos de Saúde Pública, Rio de Janeiro, v. 25, n. 10, p. 2095-2109, 2009.
MARIN, H. F. Sistemas de informação em saúde: considerações gerais. Journal of Health Informatics, São Paulo, v. 2, n. 1, p. 20-24, 2010.
MORAES, I. H. S. Informações em saúde: da prática fragmentada ao exercício da cidadania. São Paulo: Hucitec; Rio de Janeiro: Abrasco, 1994.
PINTO, L. F.; ROCHA, C. M. F. Inovações na Atenção Primária em Saúde: o uso de dados em tempo real como estratégia para a gestão e avaliação do cuidado. Ciência & Saúde Coletiva, Rio de Janeiro, v. 21, n. 5, p. 1421-1430, 2016. DOI: 10.1590/1413-81232015215.07702015.