REGISTRO DOI: 10.69849/revistaft/fa10202502272228
Abdon de Paula, PhD
Osvaldo Fonseca, PhD
RESUMO
Na vida moderna, cada vez mais estão presentes índices compostos amplamente utilizados para sintetizar dados multidimensionais em métricas simplificadas, buscando facilitar comparações e tomadas de decisão em áreas como políticas públicas, saúde e sustentabilidade. Contudo, sua construção enfrenta desafios metodológicos significativos, como subjetividade na seleção e ponderação de indicadores, perda de informações durante a agregação e aumento da variância, comprometendo a diferenciação estatística. Este artigo examina criticamente essas limitações, com foco especial na robustez dos índices compostos. A revisão da literatura destaca contribuições que evidenciam os riscos de pesos implícitos e vieses decorrentes das fórmulas de agregação. Para mitigar esses problemas, o artigo propõe refinamentos metodológicos, incluindo maior transparência na ponderação, testes de sensibilidade e o uso de técnicas estatísticas avançadas, como a análise de componentes principais. Ao abordar as limitações e as alternativas à construção de índices complexos, este artigo busca contribuir para o desenvolvimento de índices compostos mais robustos e confiáveis, revendo recomendações presentes na literatura e oferecendo sugestões para aprimorar suas bases metodológicas e sua validade interpretativa.
Palavras-chave: Índices compostos, Dados multidimensionais, Desafios metodológicos, Ponderação de indicadores, Robustez.
ABSTRACT
In modern life, composite indices are increasingly utilized to synthesize multidimensional data into simplified metrics, aiming to facilitate comparisons and decision-making in areas such as public policy, health, and sustainability. However, their construction faces significant methodological challenges, such as subjectivity in selecting and weighting indicators, information loss during aggregation, and increased variance, compromising statistical differentiation. This article critically examines these limitations, with a special focus on the robustness of composite indices. The literature review highlights contributions that underscore the risks of implicit weights and biases resulting from aggregation formulas. To mitigate these issues, the article proposes methodological refinements, including greater transparency in weighting, sensitivity testing, and the use of advanced statistical techniques such as principal component analysis. By addressing the limitations and alternatives to the construction of complex indices, this article aims to contribute to the development of more robust and reliable composite indices, reviewing recommendations present in the literature and offering suggestions to enhance their methodological foundations and interpretative validity.
Keywords: Composite indices, Multidimensional data, Methodological challenges, Indicator weighting, Robustness.
INTRODUÇÃO
Os índices compostos são formados a partir da combinação de múltiplos indicadores em uma única métrica, visando possibilitar a avaliação de fenômenos complexos. Sua utilidade reside na possibilidade de sintetizar grandes volumes de informações em formatos compreensíveis, facilitando análises e decisões estratégicas.
Tais índices são amplamente utilizados em campos como economia, saúde e sustentabilidade, sintetizando informações complexas em métricas únicas para facilitar análises comparativas e formulação de políticas públicas. Exemplos conhecidos incluem o Índice de Desenvolvimento Humano (IDH) e o Índice de Sustentabilidade Ambiental (ISA).
Índices são amplamente utilizados em áreas como economia, saúde e sustentabilidade para transformar informações complexas em métricas únicas, facilitando análises comparativas e formulação de políticas públicas. Exemplos notáveis incluem o Índice de Desenvolvimento Humano (IDH) e o Índice de Sustentabilidade Ambiental (ISA). No entanto, a construção desses índices enfrenta desafios metodológicos significativos. A escolha de indicadores, a normalização, a atribuição de pesos e a agregação de dados podem introduzir subjetividades e vieses, afetando a confiabilidade e a interpretação dos resultados. Além disso, a variância dos índices é raramente apresentada, o que pode comprometer ainda mais sua significância.
Entre as principais críticas aos índices compostos, incluem-se: a amplificação da variância decorrente da composição de múltiplos indicadores estatísticos, que dificulta a discriminação estatística; a atribuição de pesos implícitos oriundos das fórmulas de composição do índice, que influencia os resultados de maneira pouco transparente; e, além disso, a combinação de múltiplos indicadores em uma métrica única frequentemente resulta na perda de informações relevantes.
Este artigo pretende realizar uma análise crítica da construção de índices compostos, com foco nas limitações metodológicas que comprometem sua robustez. Busca-se também explorar alternativas que aumentem a confiabilidade e a utilidade prática desses instrumentos, discutindo limitações e sugerindo estratégias para melhorar sua robustez e aplicabilidade.
Fundamentação teórica
Índices compostos são ferramentas estatísticas projetadas para sintetizar múltiplas dimensões de um fenômeno em uma única métrica, permitindo comparações diretas entre diferentes contextos. A construção desses índices precisa seguir etapas metodológicas rigorosas, aplicadas com o devido cuidado (Nardo et al., 2008; Saisana e Tarantola, 2002; Feil e Schreiber, 2017a e 1017b; Saltelli, 2007; Bentes, 2017; Michalos, 2011):
- Seleção de Indicadores: Envolve a escolha das variáveis que comporão o índice. Essa etapa deve ser fundamentada em critérios teóricos e empíricos para garantir representatividade.
- Normalização: Indicadores com escalas diferentes precisam ser transformados para uma base comum. Métodos como padronização (z-scores) ou escalas normalizadas de 0 a 1 são amplamente utilizados, mas podem alterar propriedades estatísticas importantes, como variância.
- Ponderação: Pesos são atribuídos aos indicadores para refletir sua relevância. Eles podem ser definidos de maneira explícita (especialistas) ou implícita (técnicas estatísticas ou fórmulas de agregação), mas muitas vezes carecem de transparência.
- Agregação: Indicadores normalizados e ponderados são combinados em uma métrica única. Fórmulas não lineares, como somas de quadrados ou produtos, podem amplificar a variância e atribuir pesos implícitos, resultando em vieses na interpretação.
Revisão da literatura
Saisana e Tarantola (2002) abordam a inconsistência interna de índices como o Índice de Sustentabilidade Ambiental (ISA), enfatizando que a integração de dimensões heterogêneas compromete sua robustez. Complementando essas críticas.
Estudos sobre índices compostos destacam tanto suas potencialidades quanto suas limitações. Autores como Saltelli (2007) e Nardo et al. (2008) alertam que a simplificação excessiva e escolhas metodológicas subjetivas podem comprometer a confiabilidade e a transparência.
Ravallion (2010), em sua análise do IDH, argumenta que a atribuição arbitrária de pesos e a falta de validação empírica são fatores que distorcem os resultados.
Michalos (2011a) sugere a adoção de análises estatísticas, como componentes principais, para reduzir a dimensionalidade sem perda significativa de informação.
Gileá Souza e Dantaslé Spinola (2017) discutem o papel de índices compostos na mensuração do desenvolvimento econômico. O estudo enfatiza a integração de dimensões sociais e econômicas em um único indicador, ressaltando a importância de captar desigualdades regionais e setoriais. Os autores também alertam para os riscos de simplificação excessiva na agregação dos dados.
Feil e Schreiber (2017a) abordam a estrutura e os critérios utilizados na construção de índices de sustentabilidade, enfatizando as etapas de seleção, ponderação e agregação de variáveis. Os autores destacam as vantagens desses índices na simplificação da análise de dados complexos, mas também apontam as limitações associadas às decisões metodológicas, como a perda de informação e os riscos de subjetividade. O estudo sugere estratégias para melhorar a confiabilidade dos índices, com recomendações para maior transparência e validação.
Em um segundo estudo, Feil e Schreiber (2017b) apresentam uma crítica aprofundada aos índices compostos, discutindo seus desafios teóricos e práticos. Eles enfatizam problemas relacionados à normalização de variáveis, à atribuição de pesos arbitrários e à escolha de métodos de agregação. O estudo chama a atenção para o impacto dessas escolhas na interpretação dos resultados e na comparabilidade entre diferentes contextos, propondo abordagens mais rigorosas para minimizar vieses e aumentar a robustez dos índices.
Feil e Schreiber (2017c) exploram as especificidades da elaboração de índices compostos aplicados à sustentabilidade, com foco nos aspectos práticos e metodológicos. Os autores discutem como as escolhas feitas ao longo do processo afetam a relevância e a aplicabilidade dos índices. Além disso, o estudo destaca a necessidade de integrar análises multivariadas e de realizar testes de sensibilidade para garantir maior validade e replicabilidade, reforçando a importância de índices confiáveis para análises ambientais.
De acordo com Souza e Spinola (2017), a simplificação de fenômenos complexos por meio de índices pode levar à perda de nuances importantes.
Pfeiffer (2017) investiga o uso de indicadores educacionais compostos para mensurar o desempenho escolar em diferentes contextos. O autor argumenta que a normalização dos dados pode causar distorções significativas, especialmente quando se busca comparar sistemas educacionais heterogêneos. Ele sugere uma abordagem mais cuidadosa na construção desses índices para evitar interpretações equivocadas.
O artigo de Bentes (2017) explora as aplicações de índices compostos no contexto de análises de mercado, destacando seu papel em sintetizar grandes volumes de dados econômicos para apoiar decisões estratégicas. O autor discute etapas essenciais da construção desses índices, como a seleção de variáveis, normalização, ponderação e agregação, e avalia os impactos das escolhas metodológicas na validade e utilidade dos indicadores. Além de abordar vantagens como a simplificação da complexidade dos dados, o estudo enfatiza desafios como a subjetividade e a comparabilidade dos índices, sugerindo melhorias para torná-los mais robustos e aplicáveis no cenário econômico.
De Paula (2024), ao analisar o INFORM Risk Index, destaca que a fórmula de agregação amplifica a variância e atribui pesos implícitos aos indicadores, afetando a estabilidade dos resultados. De Paula reforça a necessidade de maior transparência e de análises detalhadas das escolhas metodológicas para garantir que o índice reflita com precisão as condições reais.
O estudo de Bonnet, Coll-Martínez e Renou-Maissant (2021) utilizou PCA (Principal Component Analysis) para sintetizar dimensões relacionadas ao desenvolvimento sustentável, permitindo a criação de índices regionais para departamentos franceses e análise de padrões sustentáveis ao nível regional. Esse processo também envolveu a eliminação de redundâncias e combinações lineares entre variáveis, reduzindo a dimensionalidade da matriz original.
Essas contribuições reforçam a complexidade inerente à construção de índices compostos e a importância de metodologias mais robustas e transparentes.
Debate sobre a robustez
A busca por robustez nos índices compostos está relacionada à sua capacidade de gerar resultados consistentes e confiáveis, mesmo diante de variações metodológicas. O contido na revisão apresenta que, entre os desafios mais evidentes, estão (Feil e Schreiber, 2017b; Nardo et al., 2008; Saltelli, 2007; Saisana e Tarantola, 2002, de Paula, 2023):
- Amplificação da Variância: Fórmulas de agregação podem aumentar artificialmente a variabilidade, dificultando a diferenciação estatística entre unidades de análise.
- Subjetividade e Ponderação: Pesos explícitos baseados em julgamento de especialistas e pesos implícitos oriundos de fórmulas muitas vezes não refletem adequadamente a relevância dos indicadores.
- Perda de Informação: A síntese de múltiplos indicadores em uma única métrica frequentemente dilui especificidades importantes. Índices compostos frequentemente simplificam fenômenos complexos, resultando em perda de informações detalhadas sobre as variáveis individuais. A agregação pode ocultar dinâmicas específicas de subgrupos ou de indicadores individuais, comprometendo análises mais profundas.
- Sensibilidade Metodológica: Mudanças nas etapas de construção podem levar a resultados significativamente diferentes, comprometendo a replicabilidade e a interpretação.
Para mitigar essas questões, a literatura propõe alternativas como testes de sensibilidade, métodos estatísticos avançados (e.g., PCA1), maior transparência na ponderação e validação cruzada. No presente artigo, concentram-se esforços em ampliar análises e sugestões para minimizar a variância do índice a ser composto.
A Metodologia e a simplificação metodológica
A estratégia envolve a decomposição dos índices em suas etapas principais (seleção de indicadores, normalização, ponderação e agregação), seguida por uma avaliação sistemática de cada etapa com base na literatura existente. A estratégia também prioriza a comparação de diferentes métodos para identificar possíveis vieses e limitações, garantindo uma análise rigorosa e fundamentada (Feil e Schreiber, 2017a; Bentes, 2017; Nardo et al., 2008).
As fontes de dados incluem artigos acadêmicos, relatórios institucionais e índices previamente publicados, como o INFORM Risk Index. A seleção dos dados é baseada em critérios como relevância ao tema, rigor metodológico e aplicabilidade prática. Além disso, os critérios incluem a diversidade de setores abordados pelos índices (econômico, ambiental, social), a disponibilidade de documentação sobre a construção do índice e sua replicabilidade em diferentes contextos.
Os procedimentos analíticos compreendem técnicas específicas para avaliar a qualidade e a robustez dos índices compostos:
- Avaliação da variância: esta etapa analisa a contribuição de cada variável para a variância total do índice. O objetivo é identificar variáveis redundantes ou irrelevantes, além de avaliar o impacto das escolhas de normalização e ponderação sobre a variabilidade dos resultados. Técnicas estatísticas como a análise de componentes principais (ACP) são frequentemente empregadas nesse processo.
- Testes de sensibilidade: os testes de sensibilidade verificam como mudanças nos parâmetros (por exemplo, pesos atribuídos às variáveis ou métodos de normalização) afetam os resultados. Isso é essencial para avaliar a estabilidade do índice e identificar potenciais fragilidades. Métodos como simulações de Monte Carlo ou variações nos pesos de variáveis são frequentemente usados para validar a robustez do índice.
- Validação cruzada: A validação cruzada compara os resultados do índice com outros indicadores ou benchmarks conhecidos. Essa etapa verifica a consistência dos resultados e sua capacidade de capturar os fenômenos que se pretende medir. Pode incluir comparações intertemporais, geográficas ou setoriais, além de análises de correlação com índices estabelecidos.
Esses procedimentos, realizados de forma integrada, garantem que a análise metodológica seja abrangente, detalhada e capaz de identificar os pontos fortes e as limitações dos índices compostos.
A contribuição do presente trabalho, entretanto, vai focar especificamente a problemática da variância porque grande parte dos índices são publicados e suas variâncias são omitidas.
A Variância dos Índices Complexos
Para o estudo da variância de índice complexo, montou-se um conjunto de indicadores estatísticos que seguem a função gaussiana na distribuição de probabilidade. Embora, na prática, ponderável parte dos indicadores[OF1] [Ad2] não seguem tal distribuição, pelo Teorema do Limite Central da Estatística (DeGroot e Schervish, 2012), a função de um índice composto por muitos indicadores, independentemente da função de distribuição individual desses indicadores, tenderá a uma função gaussiana.
Assim, analisa-se o caso de um índice (I) composto por uma média ponderada de indicadores que segue a distribuição normal. A média é dada por:
(Eq. 1)
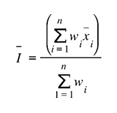
Onde wi representa o peso de cada um dos n indicadores na composição do índice I, cada xi nessa fórmula é representado por sua média.
Com essa composição, a variância do índice é dada por:
(Eq. 2)
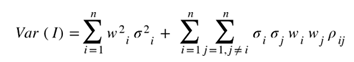
Onde, em acréscimo às variáveis já mostradas na equação de média, aparecem as variáveis σi, que representam os desvios padrão das distribuições dos indicadores considerados, e as variáveis ρij, que representam a correlação entre cada dupla de indicadores.
Um exemplo de aplicação dessas fórmulas é na composição de carteiras de investimento. Zentgraf (2001), em seus estudos de matemática financeira, aborda a composição de carteiras de ações com foco na minimização de risco, destacando a importância de ferramentas quantitativas, como variância e covariância, para avaliar e balancear risco e retorno. O autor enfatiza o uso da teoria moderna de portfólios, que busca diversificar os ativos eficientemente ao considerar a correlação entre eles. A diversificação estratégica reduz o impacto de flutuações individuais, maximizando o retorno ajustado ao risco. A ideia é maximizar o retorno da carteira, representado pela média, e, ao mesmo tempo, minimizar a variância. Essa minimização é obtida pela seleção de ativos com correlação negativa, o que diminuiria a variância que representa o risco da carteira.
A seleção de ações com correlação negativa busca aproveitar a diversificação, já que quando um ativo tem desempenho ruim, outro pode ter desempenho positivo, suavizando a variação geral da carteira. O processo de construção da carteira, portanto, envolve a identificação de ativos cujos movimentos de preço não sejam diretamente correlacionados, ou melhor ainda, que tenham correlação negativa.
Se os indicadores são altamente correlacionados (r próximo de 1), a variância do índice composto aumenta, indicando redundância entre os indicadores. Se os indicadores são independentemente distribuídos (r = 0), a variância do índice depende apenas das variâncias individuais. Indicadores com correlação negativa (r < 0) podem reduzir a variância do índice, aumentando sua estabilidade.
A estratégia se alinha com as abordagens descritas em teorias de portfólio, como a teoria moderna de portfólios de Markowitz (1952), que advoga pela seleção cuidadosa de ativos para alcançar uma fronteira eficiente, onde se encontra o risco mínimo para um dado nível de retorno.
Entretanto, essa técnica de minimização de variância dificilmente conseguiria ser aplicada na montagem de índices diversos. A escolha dos indicadores pertinentes não é adequada, em geral, para a busca de correlações negativas. Entretanto, se existirem na seleção dos indicadores, alguns com tal correlação, podem ser considerados, como critério secundário, na minimização de valores de variância de índices resultantes, mas dificilmente o processo seria adequado para a busca de indicadores com tais características, como objetivo na criação do índice.
Num índice composto por 3 indicadores, a variância implica em se somar 9 termos de variâncias e covariância. Se for composto por 25 indicadores, vai se somar 625 termos e, se for composto por 50 indicadores, teria que se somar 2500 termos. Esse crescimento na quantidade de parcelas indica uma forte possibilidade no crescimento da variância do índice em função da quantidade de indicadores utilizada.
A elevada variância de um índice composto por muitos indicadores, como no caso de 50 indicadores (com 2500 termos na matriz de covariância), pode influenciar significativamente a interpretação dos resultados em análises comparativas, obtendo-se impactos no teste de hipóteses sobre os valores medidos:
- Maior variabilidade afeta precisão: uma alta variância aumenta o erro padrão do índice composto. Isso reduz a precisão estatística e dificulta a detecção de diferenças significativas entre grupos ou condições nos testes de hipóteses.
- Redução do poder estatístico: o poder estatístico depende do tamanho do efeito em relação à variabilidade dos dados. Uma variância alta pode mascarar diferenças reais, aumentando a probabilidade de um erro do tipo II (não rejeitar a hipótese nula quando ela é falsa).
- Problemas de comparação entre grupos ou séries temporais: a alta variância dificulta identificar se as diferenças observadas entre valores medidos (em diferentes grupos ou momentos) são significativas ou resultado de ruído estatístico.
- Necessidade de ajustar o tamanho amostral: com alta variância, as análises exigem amostras maiores para garantir robustez estatística. Para estimar médias confiáveis do índice, seria necessário coletar mais dados para reduzir o impacto da variabilidade.
Vejam-se algumas estratégias iniciais para lidar com alta variância:
- Ajuste no peso dos indicadores: reduzir o peso de indicadores com variâncias muito altas ou correlações inconsistentes.
- Redução de redundâncias: eliminar variáveis redundantes ou altamente correlacionadas, diminuindo a amplificação da variância na agregação.
- Normalização adequada: garantir que os indicadores estejam escalados consistentemente para evitar que os de maior amplitude dominem a variância.
- Testes robustos: utilizar testes estatísticos que considerem a variância elevada, como análise de variância (ANOVA) ponderada ou modelos de erro heteroscedástico2.
Assim, a variância elevada pode afetar a confiabilidade de comparações e a significância estatística dos testes de hipóteses. Para análises confiáveis, ajustes metodológicos e estatísticos devem ser feitos para minimizar esse impacto.
Até aqui, concentrou-se em mostrar o efeito de uma variância aumentada e as tentativas que podem ser feitas para, ao manter a quantidade de indicadores, diminuir o efeito de alguns deles por intermédio de pesos. Resta analisar as possibilidades e critérios para redução de indicadores desnecessários na composição do índice.
Critérios de Seleção de Indicadores para Composição de Índice
Uma menor quantidade de indicadores implica, de modo geral, em um índice com menor variância, como já explanado. Agora, vejam-se critérios para inclusão de indicadores visando o uso de uma menor quantidade deles.
Para reduzir a quantidade ou o peso de indicadores em um índice composto para minimizar sua variância, existem diversas técnicas que podem ser aplicadas. Seguem algumas das mais relevantes:
- Análise de Componentes Principais (PCA): Esta técnica transforma um conjunto de variáveis correlacionadas em um menor número de variáveis não correlacionadas (componentes principais) que explicam a maioria da variabilidade dos dados. Em vez de incluir todos os indicadores originais no índice, apenas os componentes principais mais relevantes são utilizados; essa técnica reduz a dimensionalidade e, consequentemente, a variância, sem perder muito da informação inicial (Jolliffe e Cadima, 2016).
- Seleção de Indicadores com Base em Correlações: Indicadores altamente correlacionados são redundantes. A seleção elimina os indicadores que fornecem informações duplicadas. Essa técnica implica em analisar a matriz de correlação e remover indicadores com altas correlações positivas ou negativas. Ela reduz a variância ao minimizar a redundância entre indicadores (Everitt et al., 2011; Nardo et al., 2008).
- Atribuição de Pesos Otimizados: Os pesos podem ser ajustados com base na variância individual de cada indicador ou em métodos de otimização que minimizam a variância total do índice. Aqui se utilizam técnicas como a otimização de Markowitz para atribuir pesos menores a indicadores com maior variância. Nessa técnica se diminui o peso de indicadores instáveis, reduzindo a variância geral (Markowitz, 1952; Ravallion, 2010).
- Análise de Cluster: Aqui se agrupam indicadores semelhantes em clusters e se seleciona apenas um representante de cada cluster, por meio de métodos como k-means ou hierárquico, para identificar clusters e escolher indicadores mais representativos. Aqui também se reduz a quantidade de indicadores, eliminando-se aqueles que contribuem de forma redundante (Kaufman, Rousseeuw, 2005; Saisana, Tarantola, 2002).
- Normalização por Variância: Indicadores com maior variância podem ser normalizados ou padronizados para reduzir sua influência desproporcional no índice. A ideia é aplicar normalização (z-score) para ajustar os dados em uma escala uniforme, reduzindo o impacto de indicadores com alta variância, equilibrando sua contribuição no índice (Saltelli et al., 2008; OECD & JRC., 2008).
- Eliminação de Indicadores com Baixa Relevância: Identificar indicadores que tenham pouca contribuição para a variância total ou que não sejam fortemente relacionados ao objetivo do índice. Usar medidas de relevância, como testes de significância estatística ou análise de relevância prática, diminuindo a quantidade de indicadores, reduzindo a complexidade e a variância (Michalos, 2011b).
- Técnicas de Regularização: Penalizando-se indicadores menos relevantes em modelos de otimização, por intermédio de aplicação de métodos como LASSO (Least Absolute Shrinkage and Selection Operator) podem ser aplicados para selecionar os indicadores mais importantes. A ideia é reduzir a complexidade ao eliminar indicadores que têm pesos muito baixos no modelo (Tibshirani, 1996).
- Métodos de Agrupamento de Variáveis: Indicadores podem ser combinados em um único indicador composto em subgrupos temáticos. Em seguida, criar subíndices a partir de grupos de indicadores e, posteriormente, agregá-los a um índice principal. O impacto é simplificar o cálculo do índice, reduzindo a variância (Hair et al., 2010).
- Revisão e Simplificação Teórica: Reavaliar a justificativa teórica para incluir cada indicador no índice, eliminando indicadores que não tenham suporte empírico ou relevância teórica direta. Essa técnica enxuga o índice sem comprometer sua validade (Feil e Schreiber, 2017c).
- Métodos de Simulação para Testar Impacto: Realizar simulações para verificar a sensibilidade do índice à inclusão ou exclusão de indicadores. A aplicação visa testar combinações de indicadores e eliminar aqueles que não impactam significativamente os resultados, garantindo que os indicadores selecionados sejam robustos e necessários (Saltelli et al., 2004).
Essas técnicas, usadas isoladamente ou em combinação, permitem reduzir a quantidade ou peso de indicadores no índice, contribuindo para diminuir sua variância e aumentar sua eficiência e interpretabilidade.
Aplicação da Álgebra Linear Evidenciando Critérios e Objetivos
Por mais que se busque a objetividade no estabelecimento de critérios de aceitação (ou de recusa) de indicadores para compor um índice, o formalismo matemático envolto nos critérios de seleção pode obscurecer a pretendida transparência. Deste modo, vão-se montar processos com base na Álgebra Linear que, mantendo o nível adequado de rigor, permitam o acesso a resultados sobre os quais a decisão de recusa ou incorporação de um indicador na composição de um índice fique enfatizada, minimizando a subjetividade das escolhas e aumentando a transparência do processo seletivo.
Duas situações são aqui apresentadas:
- Caso A–Seleção Prévia de Indicadores para Compor um Índice: A escolha preliminar de indicadores estatísticos para montagem de um índice; e
- Caso B–Redução de Indicadores em um Índice: O estudo de índice existente visando reduzir a quantidade de indicadores.
Em ambos os casos, o objetivo maior é, mantendo as características do índice, minimizar sua variância, pelas razões retro explanadas.
Ressalte-se que uma matriz (um índice) pode representar um espaço n-dimensional, que possui um conjunto de vetores unitários (indicadores) para cada direção de forma que eles sejam ortogonais entre si. Acrescentar vetores que sejam combinações lineares dos outros ortogonais não aumenta o poder descritivo do espaço (o índice como espaço é composto por indicadores na qualidade de vetores direcionais). Assim, indicadores que sejam fortemente correlacionados com outros (ou combinação linear de outros indicadores) podem ser substituídos pelos outros sem grande perda de sua influência na participação no índice (função do valor de sua correlação ou da combinação linear de outros indicadores). Esse é o conceito elementar dos processos que serão a seguir apresentados.
Caso A–Seleção prévia de indicadores para compor um índice
A equação 2 pode ser escrita em termos de pesos, autovalores e autovetores, como segue (Bonnet, Coll-Martínez, Renou-Maissant, 2021):
(Eq. 3)

É interessante se iniciar o desenvolvimento do índice considerando-se todos os pesos iguais. A equação 3 se reduz a:
(Eq. 4)
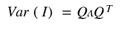
Iniciar o desenvolvimento de um índice composto atribuindo pesos iguais a 1 para todos os indicadores apresenta diversas vantagens, especialmente quando o objetivo é selecionar os indicadores mais relevantes visando à minimização da variância do índice composto. Essas vantagens incluem:
- Simplicidade inicial: atribuir pesos iguais elimina a necessidade de justificativas iniciais para escolhas subjetivas ou arbitrárias de pesos. Isso cria um ponto de partida neutro para a análise, permitindo que a relevância de cada indicador seja avaliada objetivamente.
- Facilitação da análise estatística: com pesos iguais, o índice composto inicial reflete diretamente as características estatísticas dos indicadores. Isso facilita a identificação de variâncias individuais, correlações entre os indicadores e sua contribuição total para a variância do índice.
- Decomposição baseada em autovalores e autovetores: partir de pesos iguais possibilita que a matriz de covariância do índice seja analisada diretamente com técnicas de decomposição espectral. Os autovalores indicam a magnitude da variância explicada por cada componente principal, ajudando a identificar os indicadores que contribuem menos para a variância total.
- Critério objetivo para seleção de indicadores: indicadores com baixa variância ou alta correlação com outros podem ser identificados e eliminados. Pesos iguais fornecem uma base uniforme para decidir quais indicadores são menos relevantes ou redundantes.
- Redução da complexidade do índice: A minimização da variância do índice composto pode levar a uma redução na quantidade de indicadores incluídos. Isso gera um índice mais robusto, interpretável e menos sensível a ruídos ou redundâncias nos dados.
- Evita vieses iniciais: pesos iguais evitam que indicadores sejam subestimados ou superestimados antes que sua relevância seja analisada. Isso é particularmente importante em contextos em que não há consenso ou informação prévia suficiente para determinar pesos iniciais.
- Comparabilidade com métodos alternativos: começar com pesos iguais cria uma linha de base para comparar os resultados de métodos mais complexos de ponderação, como análise fatorial, regressão ou métodos baseados em heurística.
Portanto, essa abordagem permite construir um processo metodológico claro e transparente, em que os indicadores são selecionados e os pesos ajustados com base em critérios objetivos. Assim, para utilizar o processo de redução da quantidade de indicadores, com base na matriz de covariância, deve-se seguir os seguintes passos:
- Obtenha a matriz de covariância: a matriz quadrada de covariância entre os indicadores reflete as variâncias na diagonal e as covariâncias fora da diagonal.
- Determine os autovalores e autovetores: decomponha a matriz em seus autovalores e autovetores. Os autovalores indicam a importância de cada componente em termos da variância explicada.
- Elimine componentes redundantes: avalie quais autovalores são próximos de zero. Isso identifica dimensões que contribuem muito pouco para a variância total.
- Reduza a dimensão: retenha apenas os autovetores associados aos maiores autovalores, criando uma matriz reduzida que conserva a maioria da variância explicada pelos indicadores. Aqui, a eliminação de indicadores é em si imediata por ser baseada nos autovalores. Também é possível, ao invés de eliminar, apenas se minimizar o efeito de indicadores por intermédio de manipulação de pesos. Entretanto, como se considera aqui que o indicador já tem seu efeito computado por intermédio de outros, simplesmente vai-se eliminar o indicador.
- Reconstrua a matriz: use os autovetores selecionados para construir uma nova matriz que represente o índice reduzido com menos indicadores.
Essa técnica é essencialmente a Análise de Componentes Principais (PCA), agora, aplicada à matriz de covariância. Autores que estudam índices compostos, como Saltelli (2007) e Nardo et al. (2008), utilizam PCA ou técnicas semelhantes para reduzir a dimensionalidade dos dados e eliminar redundâncias.
Para não macular a transparência por intermédio de formalismo excessivo, vai-se desenvolver o processo já citado em um exemplo numérico simples.
Considere a seguinte matriz inicial de covariância:

Os autovalores e autovetores são:
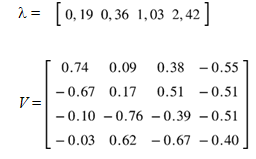
Observe-se que 2 autovalores predominam em relação aos dois outros:

E os autovetores associados [V3 V4 ]:

Desta forma, a matriz reduzida de covariância fica:
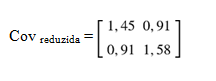
Observe-se que a matriz de covariância foi reduzida refletindo apenas ambos os indicadores selecionados. Essa matriz 2 x 2 pode ser usada para calcular a variância do índice composto ou para análises estatísticas posteriores. A redução dimensional garante que estamos considerando apenas os componentes mais significativos em termos de variância explicada. Observe-se que, ao invés de eliminar indicadores, poder-se-ia considerar atenuar seus efeitos por intermédio de pesos.
Caso B–Redução de indicadores de um índice
Numa situação em que o índice já tenha sido criado com vários indicadores, ele ainda carece de ser atualizado. Assim, pode-se pensar na redução de dimensões não apenas para reduzir a variância do índice, mas como para facilitar o seu cálculo futuro. A ideia, uma vez mais, é eliminar vetores que sejam uma combinação linear de outros. O objetivo é reduzir a matriz ao conjunto de vetores linearmente independentes por uma das seguintes técnicas (Strang, 2016; Lay, Lay e McDonald, 2016; Golub, e Van Loan, 2013):
- Redução por decomposição QR: O processo de redução se inicia por decomposição QR para identificar vetores linearmente independentes. A decomposição A = QR, onde Q contém vetores ortogonais e R é a matriz triangular superior, separa os componentes da matriz. Vetores cuja norma seja muito próxima de zero em R indicam dependência linear e podem ser descartados.
- Eliminação com determinante ou posto: O posto de uma matriz A mede o número máximo de vetores linearmente independentes. Para identificar e remover vetores dependentes: calcule o posto de A, que pode ser obtido pela decomposição LU ou SVD. Identifique as colunas que contribuem para o posto (por meio de pivotamento ou valores singulares diferentes de zero). Remova as colunas que não contribuem.
- Ortogonalização de Gram-Schmidt: O processo de Gram-Schmidt transforma um conjunto de vetores em um conjunto ortogonal equivalente. Escolha um vetor u1 = v1. Para cada vetor vj, projete-o em relação aos vetores já ortogonalizados u1, u2, …, e subtraia a projeção. Vetores com norma zero após o processo são combinações lineares e podem ser removidos.
- Transformação via decomposição SDV (Singular Value Decomposition). A SDV descompõe A como U D VT, onde D é diagonal com valores singulares. Linhas ou colunas associadas a valores singulares nulos correspondem a dependências lineares. Retenha apenas os vetores correspondentes a valores singulares positivos.
Consideremos um exemplo numérico para aplicar uma destas técnicas:
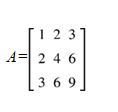
O determinante de A é zero, indicando dependência linear. Aplicando SVD ou Gran- Schmidt identifica-se que apenas dois vetores são linearmente dependentes.
A Precisão Indicada do Índice Composto
A questão da montagem do índice, segundo Burden e Faires (2022), está também relacionada a princípios do cálculo numérico e propagação de erro. Processar matematicamente as entradas não cria precisão para o resultado. Em geral, diminui. A soma, por exemplo, não altera a precisão do resultado em relação às parcelas. Já a divisão diminui a precisão.
Não há um único “teorema” específico que defina a precisão da saída com base nas entradas, mas existem diretrizes matemáticas amplamente aceitas:
1. Propagação de Erro e Precisão Significativa: a precisão da saída de um cálculo depende da menor precisão das entradas. Isso é fundamentado em:
- Propagação de erro em operações matemáticas → Pequenas imprecisões nas entradas se acumulam ao longo dos cálculos.
- Regras de algarismos significativos → O resultado não pode ter mais precisão do que os dados iniciais.
Por exemplo, ao multiplicar números, o resultado deve ter no máximo o mesmo número de algarismos significativos que o fator menos preciso.
2. Princípio da Conservação da Precisão (ou Regra dos Algarismos Significativos): este princípio estabelece que a precisão da saída deve ser limitada pela menor precisão da entrada. Ele é amplamente aplicado em engenharia, física e estatística para evitar falsas precisões.
3. Propagação de Incerteza (Análise de Erro Numérico): na análise numérica, especialmente quando se trabalha com medições e cálculos estatísticos, há métodos para estimar a incerteza da saída. Um dos principais conceitos é:
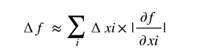

Vejamos um exemplo dessa verificação sobre o índice de desenvolvimento humano (IDH), que é um índice derivado de variáveis medidas com precisão limitada, deve seguir a regra dos algarismos significativos e a propagação de erro. Isso justifica que o IDH seja apresentado com no máximo 1 casa decimal, já que é uma saída e os dados de entrada não têm mais de 1 casa decimal.
Conclusão
A construção de índices compostos é uma ferramenta poderosa para sintetizar informações multidimensionais em um único indicador, facilitando análises e comparações. No entanto, esse processo envolve desafios significativos que demandam atenção rigorosa em cada etapa metodológica, desde a seleção de indicadores até a análise de resultados. Este estudo destacou a importância de considerar cuidadosamente critérios como redundância, correlação e peso dos indicadores para minimizar problemas de distorção e perda de informações.
A análise detalhada das variâncias e covariâncias mostrou que o impacto da correlação entre indicadores pode aumentar a variabilidade do índice, tornando essencial a aplicação de técnicas robustas, como a decomposição em autovalores e autovetores. Esse processo não apenas ajuda a identificar os indicadores mais relevantes, mas também possibilita a redução da dimensão dos dados sem comprometer significativamente a representatividade do índice, como ilustrado neste trabalho.
Além disso, a utilização inicial de pesos iguais para os indicadores foi apresentada como uma estratégia eficiente para facilitar análises exploratórias e diagnósticos preliminares. A partir disso, ajustes podem ser realizados com base em critérios empíricos e teóricos, otimizando a composição final do índice e garantindo maior robustez e interpretabilidade.
Conclui-se que a aplicação de ferramentas matemáticas, como a análise de componentes principais e a minimização de variância, são indispensáveis para a construção de índices compostos robustos e confiáveis. Para estudos futuros, sugere-se investigar métodos automatizados de seleção de indicadores, bem como a avaliação do impacto de diferentes métodos de ponderação na interpretação e utilização prática dos índices. Dessa forma, é possível avançar na construção de índices que representem com maior precisão as complexidades dos fenômenos a serem medidos. Entretanto, é preciso sempre estar atento à variância do índice.
1 Principal Component Analysis
2 O termo heteroscedástico refere-se a uma característica de conjuntos de dados ou modelos estatísticos onde a variância dos erros, ou resíduos, não é constante em diferentes níveis de uma variável independente. Isso contrasta com o conceito de homoscedasticidade, em que a variância dos erros é uniforme em todo o intervalo dos dados.
REFERÊNCIAS
Bentes, R. S. (2017). Aplicações de índices complexos em análises de mercado. Revista de Análise Econômica, 14(3), 34–50.
Bonnet, J., Coll-Martínez, E., & Renou-Maissant, P. (2021). Evaluating Sustainable Development by Composite Index. Sustainability, 13(2), 761. https://doi.org/10.3390/su13020761.
Burden, R. L., & Faires, J. D. (2022). Numerical analysis (10th ed.). Cengage Learning.
de Paula, A. (2023). INFORM Risk: uma análise crítica de um instrumento de prevenção de crises humanitárias na União Europeia. Tempo Exterior, 46(XXIV), 47–60.
DeGroot, M. H., & Schervish, M. J. (2012). Probability and statistics (4th ed.). Pearson.
Everitt, B., Landau, S., Leese, M., & Stahl, D. (2011). Cluster Analysis. Wiley.
Feil, A., & Schreiber, D. (2017a). Análise da estrutura e dos critérios na elaboração do índice de sustentabilidade. Revista Brasileira de Estatística, 39(2), 47–60.
Feil, A., & Schreiber, D. (2017b). Crítica sobre índices compostos: reflexões e desafios. Revista de Ciências Sociais Aplicadas, 28(1), 79–94.
Feil, A., & Schreiber, D. (2017c). Reflexões sobre a elaboração de índices compostos para análise de sustentabilidade. Revista de Estudos Ambientais, 14(2), 110–127.
Gileá Souza, J., & Dantaslé Spinola, N. (2017). Medidas do Desenvolvimento Econômico: construção e aplicação de indicadores. Revista de Desenvolvimento Econômico, 22(1), 15–32.
Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins University Press.
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2010). Multivariate data analysis (7th ed.). Pearson.
Jolliffe, I. T., & Cadima, J. (2016). Principal component analysis: A review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 374(2065), 20150202. https://doi.org/10.1098/rsta.2015.0202
Kaufman, L., & Rousseeuw, P. J. (2005). Finding groups in data: An introduction to cluster analysis. Wiley. https://doi.org/10.1002/9780470316801
Lay, D. C., Lay, S. R., & McDonald, J. J. (2016). Linear Algebra and Its Applications (5th ed.). Pearson.
Markowitz, H. M. (1952). Portfolio selection. Journal of Finance, 7(1), 77–91. https://doi.org/10.1111/j.1540-6261.1952.tb01525.x
Maricato, J. de M., & Lopes Martins, D. (2017). Altmetrics: complexities, challenges and new forms of measurement and understanding of scientific communication in the social web. Revista de Estudos de Comunicação, 19(2), 203–220.
Michalos, A. C. (2011a). Criteria and indicators of quality of life: Theory and application. Springer Science & Business Media.
Michalos, A. C. (2011b). What did Stiglitz, Sen and Fitoussi get right and what did they get wrong? Social Indicators Research, 102, 117–129. https://doi.org/10.1007/s11205-010-9734-7
Nardo, M., Saisana, M., Saltelli, A., Tarantola, S., & Hoffmann, A. (2008). Handbook on constructing composite indicators: Methodology and user guide. OECD Statistics Working Papers.
OECD & JRC. (2008). Handbook on constructing composite indicators: Methodology and user guide. OECD Publishing.
Pfeiffer, D. K. (2017). As medidas da educação: Medição e gestão mediante indicadores. Revista Brasileira de Educação, 22(3), 85–101.
Ravallion, M. (2010). How to measure inequality. World Bank Research Observer, 25(1), 35–67.
Saisana, M., & Tarantola, S. (2002). State-of-the-art report on current methodologies and practices for composite indicator development. European Commission Joint Research Centre.
Saltelli, A., Tarantola, S., Campolongo, F., & Ratto, M. (2004). Sensitivity analysis in practice: A guide to assessing scientific models. Wiley.
Saltelli, A. (2007). Composite indicators between analysis and advocacy. Social Indicators Research, 81(1), 65–77.
Saltelli, A., Ratto, M., Andres, T., Campolongo, F., Cariboni, J., Gatelli, D., & Tarantola, S. (2008). Global sensitivity analysis: The primer. Wiley.
Strang, G. (2016). Introduction to Linear Algebra (5th ed.). Wellesley-Cambridge Press.
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1), 267–288. https://doi.org/10.1111/j.2517-6161.1996.tb02080.x
Zentgraf, R. (2001). Estatística objetiva. Rio de Janeiro, ZTG.