REGISTRO DOI: 10.69849/revistaft/ni10202501121241

Renato A. Terezan de Moura1
Cidoval Morais de Sousa2
Articulando métodos etnográficos virtuais e Ciência de Dados Sociais, investiga-se as dinâmicas de difusão e divulgação científica de uma faculdade pública em amostras de conteúdos de seus acervos em redes sociais e mídias digitais na internet. Problematiza-se a hipótese de comprovar a efetividade dessas dinâmicas de cultura científica através de análises descritivas e estatísticas de acesso articuladas com a modelagem de dados de interação (linguagem escrita e emojis) coletados nos chats, comentários e transcrição das transmissões dos eventos acadêmicos. Esses dados são modelados e analisados por técnicas de Processamento de Linguagem Natural (PLN) em framework Python NLTK, no software Maxqda, no Gemini Advanced e publicados em um site WordPress (HTML e PHP). Esta abordagem híbrida classifica dados sociais, assuntos e palavras nas atividades de difusão e comunicação científica ao realizar análises lexicais, de conteúdo, sentimento e discurso, além de inferências qualitativas com validação empírica.
Palavras-chave: Cultura Científica, Etnografia Virtual, Ciência de Dados Sociais, Redes Complexas
Introdução
O aumento do interesse em conteúdos e letramento científico no Brasil atende demandas da sociedade aos desafios de formação eficiente e atualizada de seus membros (CGEE, 2024) que, visando obter sucesso na economia informacional globalizada de enorme complexidade científica e tecnológica, precisam ser fluentes nas interfaces e linguagens da chamada, inteligência coletiva (LÉVY, 2010). As redes sociais, aplicativos de mensagens e plataformas digitais são os meios mais utilizados (39,8%) para obter os conteúdos (CGEE, 2024).
Porém, mais de 62% dos brasileiros não obteve em seu letramento, conhecimentos científicos suficientes para compreender dados e resolver problemas cotidianos, como analisar o consumo e tarifação de energia elétrica, interpretar dados dos rótulos dos alimentos ou compreender manuais técnicos de aparelhos domésticos (IBLC, 2017, pág.19)
Dados coletados nas plataformas de divulgação, repositórios audiovisuais e sites da Instituição de Ensino Superior (IES) objeto deste estudo, já indicam números expressivos de alcance dos conteúdos pelos métodos e processos desenvolvidos atualmente. Os conteúdos nos serviços de transmissão (streaming) e acervo audiovisual (on demand) de audiovisuais, palestras, conferências e eventos científicos atingem milhares de acessos mensais através da plataforma Eduplay na Rede Nacional de Ensino e Pesquisa (RNP), site WordPress e canais de Youtube dos projetos de extensão estudados.
Não existe ciência sem comunicação ou conhecimento científico não publicado, porque permanecendo irrelevante, não alcança sua função social. A difusão dos trabalhos científicos no contexto da cibercultura, oferece oportunidades lúdicas de letramento e podem ser reinventadas com o intuito de democratizar a ciência. (PORTO, 2018).
As redes sociais e de mídias digitais da IES neste estudo se tornaram essenciais como ferramenta institucional de comunicação com os alunos, ex-alunos e toda a comunidade interna e externa, pois são ativos de comunicação social e científica que cumprem a missão de comunicação de eventos e atividades de ensino, divulgação da produção científico-cultural da unidade e difusão científica dos resultados e dinâmicas das atividades de ensino, pesquisa e extensão.
Discussão teórica
A nova realidade imposta pelas modalidades virtuais de atendimento presencial remoto e sua flexibilização nas relações interpessoais e interinstitucionais, que se acentuaram após a pandemia, resultaram no que podemos inferir como prova empírica da emergência da cultura algorítmica ( ZUIN e ZUIN, 2018) , ( BEZERRA, 2017) , ao concebermos que algoritmos rodando em redes informacionais se envolvem ou dominam tarefas consideradas tradicionalmente culturais que incluem escolhas, buscas, classificação e hierarquização de objetos, pessoas, ideias e lugares. A migração do espaço vivencial para a virtualidade das redes informacionais acelerou a circulação de desinformação e a transformou em uma camada do modelo de negócios das big techs, através de algoritmos de publicações de anúncios que remuneram páginas e sites que produzem e difundem desinformação (ORESKES e CONWAY, 2017).
Segundo o relatório Índice Global de Desinformação, as empresas Google (70%), Taboola (4 %), Revcontent (3 %), Content Ad (2 %), Teads (1 %) e Monetizer (1%), dominam juntas 81% do mercado de anúncios e remuneram valores significativamente maiores aos sites e páginas de desinformação quando comparados com os todos os outros sites classificados na comparação, conforme o Índice Global de Desinformação da UNESCO (GDI).
Podemos inferir a emergência de uma face da cultura algorítmica que cria e mantém bolhas de desinformação em nível global, com empresas que atuam em mercados bem definidos e atende instituições públicas e particulares, governos democraticamente eleitos, partidos políticos e grupos religiosos que fazem uso efetivo e frequente de notícias falsas, desinformação e manipulação algorítmica (EMPOLI, 2022), (O´NEIL, 2020), (D’ANCONA, 2018), (O’NEIL, 2021) , (CASSINO et al, 2021).
O letramento científico rudimentar da população brasileira colabora, em alguma medida (IBLC, 2017; CGEE, 2024), para o êxito da desinformação em praticamente todos os segmentos da sociedade. Isso pode acentuar a manipulação algorítmica de bolhas de desinformação que articulam pautas identitárias conservadoras com viéses racistas, homofóbicos e misóginos com as quais algumas pessoas se identificam e a coerção direta exercida em grupos religiosos, políticos, ideológicos, armamentistas ou mesmo familiares.
Fica evidente diante desses fatos e proposições que a comunicação, o letramento e a difusão de conteúdos e conhecimentos científicos podem colaborar com o fortalecimento da cultura científica na sociedade e fazer frente aos desafios cognitivos na era das redes informacionais, na qual, ironicamente, estamos imersos em muita desinformação.
O conhecimento e a cultura científica podem estar presentes cotidianamente na vida das pessoas (VOGT, 2016) agregando ferramentas de difusão, divulgação e letramento científicos, entendendo-as como necessariamente complementares e desenvolvendo um olhar crítico, ao mesmo tempo, para a ciência e para a mídia. (PEZZO, in VOGT, GOMES, MUNIZ, 2018, p. 87 a 95).
A cultura científica (VOGT, 2016) disseminada como tecnociência (LATOUR, 2000) nas redes complexas de produção e difusão científica analisada nesta tese, busca dinamizar a mesma em sites e aplicativos de mídias digitais em dispositivos multiplataforma, visando aproximar as instituições científicas e universidades da sociedade brasileira, que admira e confia nos cientistas e professores em níveis superiores a jornalistas, líderes religiosos e escritores (IBLC, 2017; CGEE, 2024).
A visibilidade da produção científica e sua difusão pelos canais institucionais de comunicação social das universidades se torna essencialmente estratégico na aproximação com a população e enfrentamento do negacionismo científico. A cultura científica desmitifica a ciência infalível e culturalmente distante da era mertoniana (ZIMAN, 2000), que passa a ser compreendida como atividade socioeconômica com dinâmicas e idiossincrasias naturais e humanas, sujeitas a reveses, crises, eleições, políticas e extrema competitividade, características das sociedades industrializadas e democracias capitalistas.
Metodologia
A metodologia adotada é a da pesquisa-ação (LEWIN, 1965), que tem como uma de suas principais características, a ausência inicial de todos os elementos necessários para a delimitação do objetivo e gradual formulação dos meios adequados para obter resultados satisfatórios. Associando os dados coletados aos conceitos articulados na observação do modelo experimental em suas dinâmicas, busca-se articular as seis fases específicas da metodologia (CHIZZOTTI, 2018), visando a superação gradativa e sequencial daquilo que se pretende resolver.
Na metodologia de Ciência de Dados, são mapeados os problemas a resolver ou apoiar a solução, analisados os dados e propondo um modelo de compreensão que possibilite observar padrões, obter insights, fazer inferências e até mesmo prever resultados, numa abordagem chamada top-down (de cima para baixo). (AMARAL, 2016). A metodologia também deve permitir a análise contínua dos dados em qualquer período de tempo em cinco etapas, não se limitando à sazonalidade de demandas (CASTRO e FERRARI, 2016).
1) Os dados são coletados em formato CSV nas plataformas e exportados para o Google Planilhas, onde são analisados e limpos , rotulados e validados também no Maxqda quanto aos dados dos conteúdos (Preparação de Dados).
2) Na segunda etapa, na Análise Exploratória dos Dados são descobertos padrões, distribuições e suas correlações para obter uma compreensão abrangente, propondo inferências quantitativas e/ou qualitativas que formulam hipóteses.
3) A terceira etapa consiste em utilizar métodos estatísticos como análises de variância, regressão linear e/ou logística, séries temporais e tabelas de frequências para testar as hipóteses formuladas na etapa anterior e criar tabelas dinâmicas que permitam implementar a Modelagem de Dados.
4) Após a modelagem estatística, os chats, comentários e vídeos são transcritos e analisados no Maxqda e submetidos a um treinamento de aprendizado de máquina em framework Python-NLTK de Processamento de Linguagem Natural ( PLN) por um método Naive-Bayes ou de Máquinas de Boltzmann Restritas (RMB) de probabilidades, tais como lematização, gerenciamento de derivações e redução de flexões.
5) Na última etapa são gerados os gráficos das análises descritivas e os conteúdos submetidos à janelas de contexto no Gemini Advanced (mais de 1.5 milhão de tokens) e de 100.000 mil caracteres no Maxqda através de comandos diretamente no chat dessas ferramentas, quando são gerados os resumos, comentários e análises de sentimento e discurso. Os gráficos e tabelas são organizados em um site WordPress.
Análise
Além da análises das redes sociais e suas estruturas relacionais, também são investigados projetos e instâncias que demandam serviços de comunicação, difusão e letramento científico multiplataforma através de sites multimídia e canais de streaming.
Projeto do canal de streaming Ciências Sociais em Diálogo
Após o início do isolamento imposto pela pandemia de Covid-19, o Departamento de Ciências Sociais da FCLAr Unesp demandou a criação de um canal de streaming que iniciou suas atividades em abril de 2020 e se dedica, segundo dados do projeto, a compartilhar com a comunidade universitária e a sociedade em geral, debates semanais e abertos sobre temas atuais e que interessa a todos, permitindo a interação do público com os expositores.
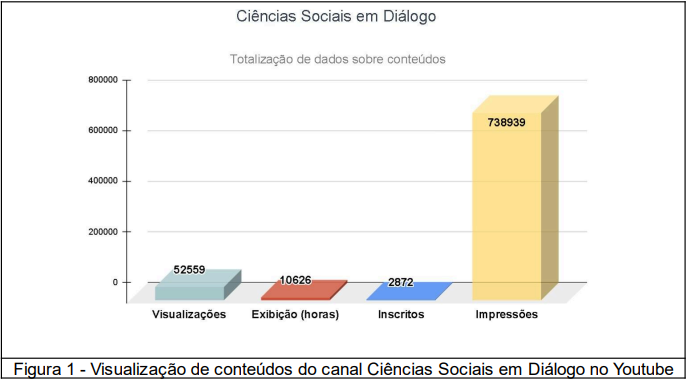
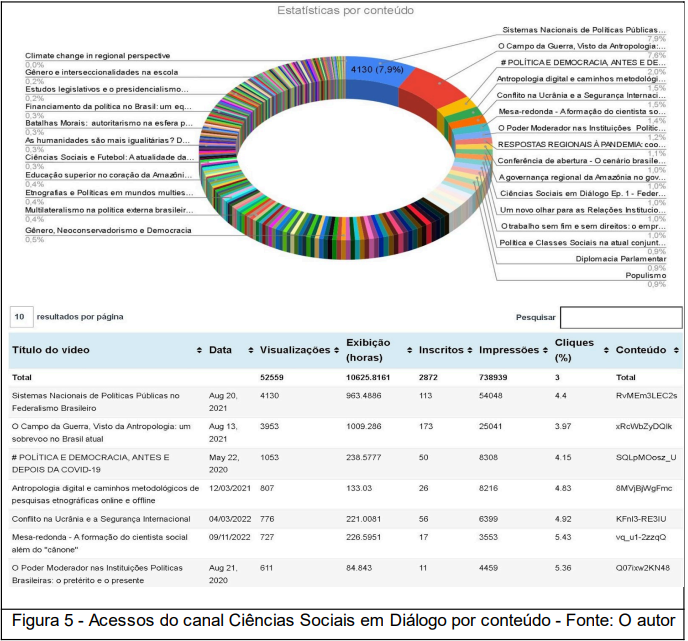
Foram produzidas vinhetas de abertura e encerramento, a programação visual e criação do canal, que já realizou 241 transmissões de conteúdos que alcançaram mais de 52.500 visualizações, possuindo 2872 inscritos e totalizou 10.626 horas de exibição de conteúdos.
Para demonstrar o modelo de análises descritivas, seguem gráficos e inferências rápidas sobre dados coletados desde a criação do canal em abril de 2020 até maio de 2024.
Para exemplificar e demonstrar a análise de conteúdos do canal articulando etnografia virtual e ciência de dados sociais, utilizamos o vídeo com o segundo maior número de acessos on-line e on demand do acervo.
O site da tese, com todas as análises, terá o acesso liberado após a defesa em agosto de 2024.
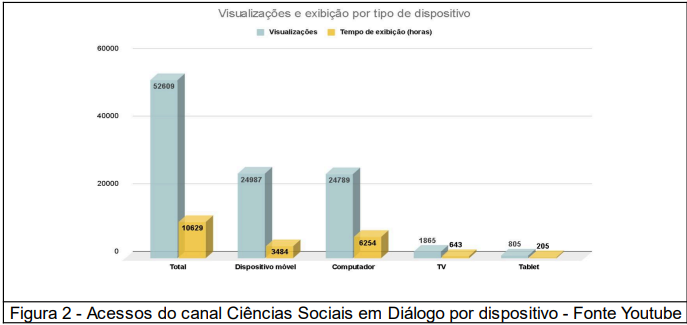
O canal multiplataforma é acessado por dispositivos móveis (47,5%), computadores (47,11%), televisores (3,54%) e tablets (1,53%), sendo praticamente equivalente ao percentual em relação aos dois primeiros.
A maior duração média de visualizações é nas TVs (20m41s), Tablets (15m19s), computadores (15m08s) e a menor em dispositivos móveis (8m35s), possivelmente pelo alto consumo de franquia de dados móveis e fadiga visual ocasionado pela pequena tela dos mesmos.
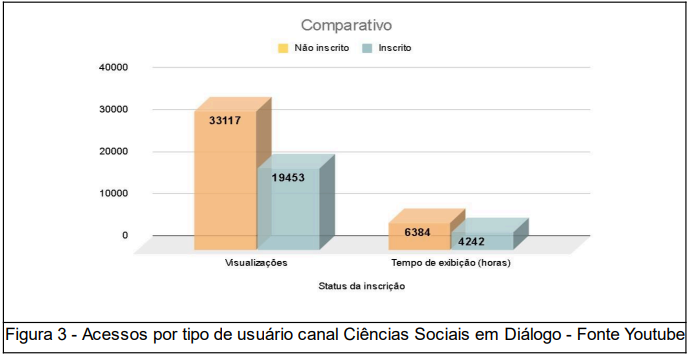
As visualizações por não inscritos no canal é maior (58,5%) em relação aos que se inscreveram (41,5%), sendo que a duração média de visualização é maior entre os inscritos (13m55s) em relação aos não inscritos (12m28s). O engajamento pode ser avaliado e otimizado.
Em relação ao alcance dos conteúdos por idade, predomina a quantidade de acessos dos usuários (78,95%) e maior tempo de exibição entre 18 e 44 anos (78,95%), porém o percentual médio de visualizações é maior pelos usuários entre 45 e mais de 65 anos.
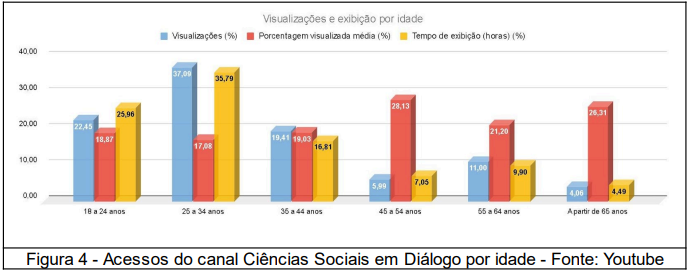
As estatísticas por conteúdo em relação ao total e percentual de cada um deles é acessível por gráfico interativo e planilha de dados dinâmica em HTML, que permite classificar e filtrar os dados para avaliações por assunto ou palavra chave, visualizações, horas de exibição, número de inscritos, impressões e cliques.
Análises netnográficas e de conteúdos auxiliado por Aprendizado de Máquina
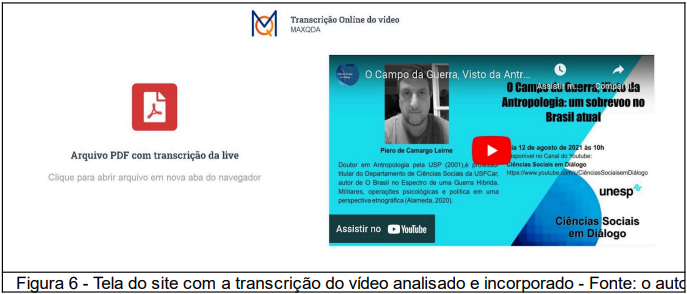
Os vídeos transmitidos e armazenados no Youtube, seus comentários e chats são os conteúdos analisados qualitativamente, iniciando pela transcrição do mesmo em arquivo de texto PDF pela ferramenta Maxqda e disponibilizado juntamente com acesso ao audiovisual incorporado no site. Qualquer pessoa pode ler a transcrição e acessar o trecho do conteúdo no contexto da transmissão.
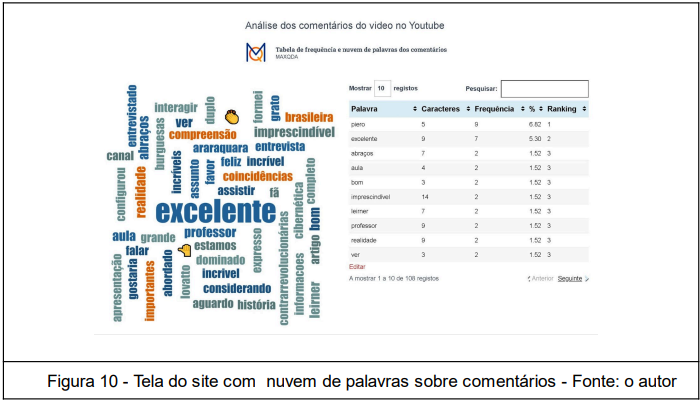
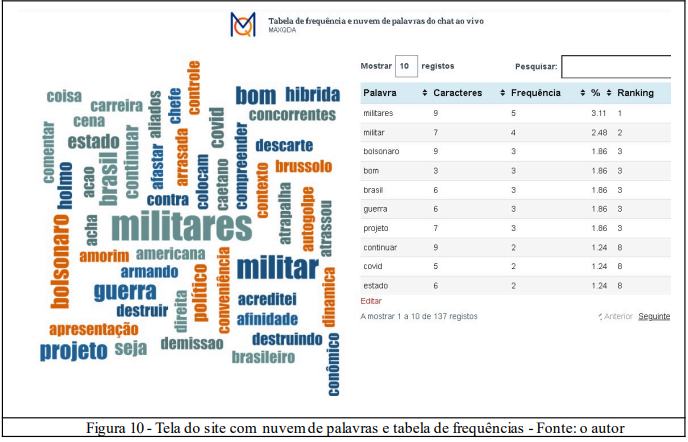
Após a transcrição, são gerados a tabela de frequência e a nuvem de palavras usadas na live, além do gráfico de tendência de palavras gerados pela análise no Maxqda. A nuvem permite uma visualização dinâmica da predominância dos assuntos pela classificação das 1631 palavras desta live5.
A transcrição, a nuvem e a tabela de frequência de palavras são submetidos a um treinamento de aprendizado de máquina em framework Python, além de uma janela de contexto de milhões de tokens no Gemini Advanced e no Maxqda através de comandos diretamente no chat das ferramentas.

Os chats de IA generativa oferecem recursos avançados em Processamento de Linguagem Natural (PLN) que superaram as análises pela biblioteca NLTK no Python. Os recursos de PLN foram muito eficazes em tarefas que as IAs generativas sequer realizam de forma simples, como remover stopwords, gerenciar derivações (stemming) ou reduzir as flexões.
A NLTK permite realizar o treinamento do modelo de linguagem por um método Naive-Bayes de probabilidades, porém o resultado não entrega muita coisa, além de classificações descrevendo sentimentos muito simplórios como raiva, alegria, medo e tristeza, que não contemplariam a complexidade dos conteúdos analisados.
O software Maxqda possibilitou realizar com certa facilidade, essas mesmas tarefas de preparação e lematização que foram inicialmente feitas via programação Python diretamente no framework PyCharm usando NLTK, que entrega resultados apenas numéricos no console ou no Google Collab.
O AI Assist do Maxqda e o Gemini Advanced do Google forneceram análises de sentimento e discurso bem específicos e claros através de comandos específicos e sequenciais no chat. Entregaram resumos com boa redação e sínteses pertinentes, além de gerar inferências sequer notadas via NLTK/Python.

Um link com acesso ao contexto do chat no Gemini Advanced é disponibilizado para que qualquer usuário com o mesmo nível de conta Google possa prosseguir com novas perguntas ao modelo, cujo recurso não existe no Maxqda, que mostra as linhas onde estão as palavras que orientam sua análise. Após processar os dados da transcrição e filtragem, são geradas tabela, nuvem de palavras e relatório curto de análise de sentimentos nos comentários do vídeo no canal (on demand).
Após processar os dados da transcrição, são gerados resumos, análises de sentimentos e de discurso dos diálogos nos comentários conteúdo (On demand).
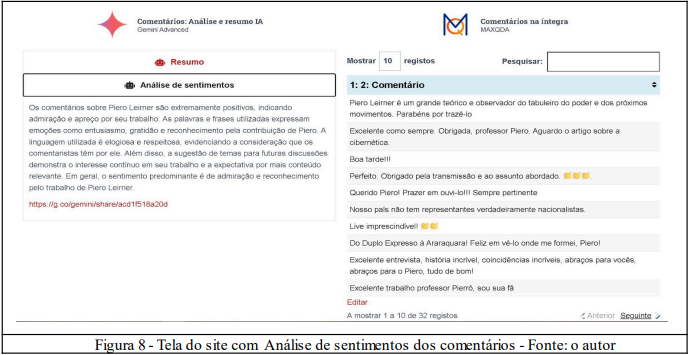
Este modelo não restringe as análises de sentimento ao reducionismo da tripla polaridade (positivo, negativo ou neutro), mas possibilita a análise semântica ou mesmo linguística simultaneamente aos estudos estatísticos transversais. Também foram analisados os emoticons presentes nos diálogos, coletando e analisando importantes recursos de comunicação já incorporados à realidade linguística e dinâmicas conversacionais online.
Os “Comentários” ocorrem após a transmissão e disponibilização pelo Youtube da versão “Por demanda”, nos quais surgem novos questionamentos e manifestações que podem se desdobrar em um diálogo entre os espectadores, ou mesmo entre eles e os palestrantes. É possível inferir que os comentários sejam estratégicos no relacionamento com os inscritos no canal, afinal, após a live, é o único espaço conversacional disponível, tendo um caráter mais informal e reflexivo que o chat, que acontece em tempo real.
O chat oferece recursos muito relevantes para análise de conteúdos e compreensão geral da atmosfera da transmissão, porém nem sempre há profissionais ou mesmo voluntários para realizarem a mediação e moderação. Isso acaba sendo realizado pela equipe de transmissão e em inúmeros casos, pelos próprios entrevistadores que assumem ambos os papeis.
Ambos os recursos “Chat” e “Comentários” são ferramentas que apoiam as narrativas audiovisuais dos conteúdos, conferindo uma legitimidade única de manifestações que podem ser analisadas em seu contexto, no qual o lugar de fala é descorporificado e desterritorializado, mas ao mesmo tempo politizado e ideológico.
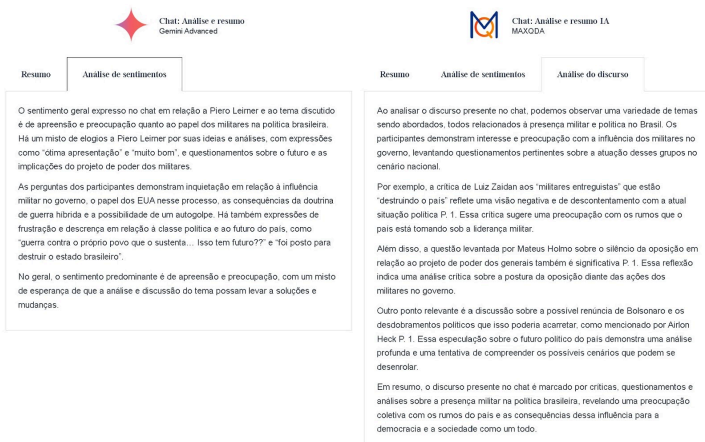
As análises de sentimento de ambos os modelos de IA generativa (Gemini e MaxQDA) permitem contextualizar sua própria base de conhecimento, ao agregar sites, pdfs, planilhas, tabelas, infográficos, manuais, documentos e qualquer conjunto de dados, estruturados ou não.
Este recurso possibilita que seu chatbot ou agente de análise não precise acessar conteúdos externos da internet, caso isso seja relevante, como é o caso desta tese, ou seja, somente dados e informações da base de conhecimento que você mesmo cria, atualiza e realimenta, treinando o modelo continuamente.
Se o canal dispuser de suporte adequado, além dos dados implícitos nas conversas, pode-se estabelecer diálogos com os espectadores e se relacionar com seus inscritos, estimular novas inscrições e oferecer recursos que aumentem o engajamento. O acesso a novos conteúdos do canal e redes sociais pode gerar oportunidades de aumentar o consumo e compartilhamento de mais conteúdos por meio dessas plataformas.
Considerações Finais
Além dos resultados descritivos e estatísticos demonstrados, os dados etnográficos virtuais coletados permitem analisar fenômenos relacionais, linguísticos e comunicacionais que ocorrem em determinado tempo (períodos analisados), local ( redes complexas) e cultura científica (divulgação, difusão e letramento) .
Através dos resultados encontrados até o momento, corrobora-se a hipótese de comprovar a eficácia das dinâmicas de cultura científica (divulgação, difusão e letramento) em redes informacionais através da amostragem de conteúdos dos acervos em redes sociais e mídias digitais da Instituição de Ensino Superior objeto deste estudo.
Esta pesquisa desenvolveu e implementou um modelo de chatbot integrado à base de conhecimento armazenada vetorialmente em uma aplicação no AWS Bedrock (LLMs/GraphRAGs). O desenvolvimento obteve sucesso ao alimentar a base de conhecimento com os conteúdos da tese de forma estruturada por menus e treinar o modelo com os textos do site.
Uma amostra de 99 codificações entre todos os títulos das transmissões foi criada para exemplificar o livro de códigos, aqui neste capítulo e que estará integralmente disponível no site da tese (tecnociencia.net) com dezenas de páginas.
A amostra inicia com uma lista seguida das três codificações propostas para cada título e seus códigos, oferecendo maior flexibilidade e efetividade aos buscadores e eficiência nas buscas por IA generativa e Aprendizado de Máquina (AM).
Através da codificação dos títulos dos conteúdos, que por si só já carregam informações sobre o escopo e finalidade do debate, foi possível realizar análises das modalidades de abordagem para cada assunto. Além do livro de códigos e lista de categorias, as palavras também são avaliadas pela frequência delas nos enunciados e referenciados visualmente nas nuvens de palavras.
A nuvem de palavras a seguir resultou da frequência de códigos de todos os títulos das transmissões e apresenta uma distribuição diagonal das palavras em 45 graus, além das horizontais e verticais, diferenciando estas nuvens cujos dados se originaram de agregações de conteúdos.


Para concluir, a título de exemplo, apresentamos um resumo sobre os temas abordados nas transmissões do canal Ciências Sociais em Diálogo, baseado nos títulos dos conteúdos, códigos e categorias pela metodologia híbrida proposta nesta tese e que referenciam 244 temas de cada live do canal.

3O termo “letramento científico” neste estudo refere-se mais propriamente ao uso e compreensão da linguagem técnico-científica, mediante a utilização de conhecimentos específicos previamente adquiridos para lidar com situações cotidianas, do que apenas oferecer aulas de ciência ou cursos tecnológicos.
4https://www.disinformationindex.org/research/2019-9-1-the-quarter-billion-dollar-question-how-is-disinformation-gaming-ad-tech/
5https://tecnociencia.net.br/piero-leirner/
Referências
AMARAL, Fernando. Introdução à ciência de dados: mineração de dados e big data. Rio de Janeiro: Alta Books, 2016.
BEZERRA, Arthur Coelho. 2017. “Vigilância E Cultura algorítmica No Novo Regime De mediação Da informação”. Perspectivas Em Ciência Da Informação 22 (4):68-81. https://periodicos.ufmg.br/index.php/pci/article/view/22537 .
CASSINO, João Francisco, Joyce Souza, e Sérgio Amadeu Silveira, eds. Colonialismo de dados: como opera a trincheira algorítmica na guerra liberal. Autonomia Literária, 2021.
CASTRO, L. N. de; FERRARI, D. G. Introdução à mineração de dados: conceitos básicos, algoritmos e aplicações. São Paulo: Saraiva, 2016.
CHIZZOTTI, Antonio. Pesquisa qualitativa em ciências humanas e sociais.. 6ª ed. – Petrópolis, RJ: Vozes, 2014 (4ª reimpressão, 2018).
D’ANCONA, Matthew. Pós-verdade: a nova guerra contra os fatos em tempos de fake news. Barueri: Faro Editorial, 2018
EMPOLI, G. Os engenheiros do caos: como as fake news, as teorias da conspiração e os algoritmos estão sendo utilizados para disseminar ódio, medo e influenciar eleições. 3. ed. São Paulo: Vestígio, 2019.
IBLC, Indicadores de Letramento Científico: Relatório Técnico, Instituto Brasileiro de Letramento Científico. São Paulo (SP): IBLC, 2017 http://iblc.org.br/wp-content/uploads/2018/01/2-relatorio-tecnico-ilc.pdf
CGEE, Percepção pública da C&T no Brasil – 2023. Resumo Executivo. Brasília, DF: Centro de Gestão e Estudos Estratégicos, 2024. https://www.cgee.org.br/documents/10195/4686075/CGEE_OCTI_Resumo_Executivo-Perc_Pub_CT_Br_2023.pdf
LATOUR, Bruno. Ciência em ação: como seguir cientistas e engenheiros sociedade afora. São. Paulo: UNESP, 2000
LÉVY, Pierre, A inteligência coletiva: por uma antropologia do ciberespaço, 3. ed. São Paulo: Loyola, 2000.
LEWIN, K. Teoria de campo em ciência social. São Paulo: Pioneira, 1965
O’NEIL, Cathy. Algoritmos de destruição de massa: como o Big Data aumenta a desigualdade e ameaça a democracia. Santo André, SP: Editora Rua do Sabão, 2020.
ORESKES, Naomi & CONWAY, Erik M. (2010). Merchants of Doubt: How a Handful of Scientists Obscured the Truth on Issues From Tobacco Smoke to Global Warming. Bloomsbury Press. – https://philpapers.org/rec/OREMOD
PORTO, Cristiane Produção e difusão de ciência na cibercultura: narrativas em múltiplos olhares / Cristiane Porto, Kaio Eduardo Oliveira, Flávia Rosa (organizadores). Editus, 2018. Acessado em 12/08/2018 em http://www.labi.ufscar.br/wp-content/uploads/2019/01/Anexo-9.pdf
VOGT, C. A espiral da cultura científica. In: CONGRESSO TÉCNICO CIENTÍFICO DA ENGENHARIA E DA AGRONOMIA, 2016, Foz do Iguaçu. [Trabalhos apresentados]. Brasília, DF: Confea, 2016. http://www.confea.org.br/media/contecccarlosvogt_Trilha.pdf
VOGT, Carlos, Marina Gomes, Ricardo Muniz (Organizadores). – Campinas, SP: BCCL/ UNICAMP, 2018. 274 p. ISBN: 978-85-85783-90-7
ZIMAN, John M. (2000). Real science: what it is, and what it means. New York: Cambridge University Press.
1Doutorando em Ciência, Tecnologia e Sociedade (UFSCAr), Mestre em Mídia e Tecnologia (UNESP), Cientista Social (UNESP), Cientista de Dados (UNIVESP) e Especialista em EAD (UFF)
e-mail: renato.terezan@gmail.com
2Professor de Sociologia da Ciência na Universidade Estadual da Paraíba (UEPB), Doutor em Geociências (UNICAMP), Bacharel em Comunicação Social pela UEPB
e-mail : cidoval@gmail.com