STUDY OF THE INTEGRATION OF ARTIFICIAL INTELLIGENCE (AI) IN RECOMMENDATION SYSTEMS (SR): BIBLIOGRAPHICAL REVIEW
REGISTRO DOI: 10.69849/revistaft/fa10202411101906
Pedro Henrique Do Amaral Santos1,
João Henrique Gião Borges2,
Fabiana Florian3
RESUMO
Este estudo investiga a integração de Inteligência Artificial (IA) em Sistemas de Recomendação (SRs), destacando seu impacto na personalização e eficiência das recomendações em ambientes digitais diversificados. Através de uma revisão bibliográfica, foram analisadas as principais técnicas de IA aplicadas aos SRs, como aprendizado de máquina e redes neurais, e seus efeitos na melhoria da precisão e adaptação em tempo real às preferências dos usuários. Além disso, foram explorados os desafios éticos associados à implementação de IA, como privacidade, viés algorítmico e transparência, com o objetivo de promover uma abordagem mais responsável e inclusiva. Os resultados indicam que, embora a IA tenha o potencial de aumentar significativamente a eficácia dos SRs, é fundamental que o desenvolvimento dessas tecnologias seja equilibrado com práticas éticas que garantam equidade e diversidade nas recomendações. Este estudo oferece insights valiosos para pesquisadores e desenvolvedores interessados em aprimorar os SRs e abordar as complexidades éticas da personalização em massa.
Palavras-chave: Inteligência Artificial, Sistemas de Recomendação, Aprendizado de Máquina, Desafios Éticos, Personalização.
ABSTRACT
This study investigates the integration of Artificial Intelligence (AI) in Recommendation Systems (RSs), highlighting its impact on the personalization and efficiency of recommendations in diverse digital environments. Through a literature review, the main AI techniques applied to RSs, such as machine learning and neural networks, were analyzed, along with their effects on improving accuracy and real-time adaptation to user preferences. Additionally, ethical challenges associated with AI implementation, such as privacy, algorithmic bias, and transparency, were explored to promote a more responsible and inclusive approach. The results indicate that while AI has the potential to significantly enhance the effectiveness of RSs, it is essential that the development of these technologies is balanced with ethical practices that ensure fairness and diversity in recommendations. This study provides valuable insights for researchers and developers aiming to improve RSs and address the ethical complexities of mass personalization.
Keywords: Artificial Intelligence, Recommendation Systems, Machine Learning, Ethical Challenges, Personalization
1 INTRODUÇÃO
Este estudo visa fornecer insights valiosos para pesquisadores, profissionais e desenvolvedores interessados em aprimorar os Sistemas de Recomendação (SRs) e avançar na criação de recomendações personalizadas em ambientes digitais diversificados. Esses sistemas têm como principal função sugerir itens de interesse de maneira personalizada aos usuários, e hoje são essenciais em setores como comércio eletrônico, mídia digital e redes sociais, impactando diretamente a experiência de quem os utiliza. A Inteligência Artificial (IA) surgiu como uma ferramenta poderosa para aprimorar a eficiência e a eficácia desses sistemas. O aprendizado de máquina, em particular, tem sido amplamente adotado para analisar grandes volumes de dados e identificar padrões sutis, permitindo a geração de recomendações personalizadas e precisas.
Apesar dos avanços, um dos principais problemas enfrentados pelos SRs está na necessidade de equilibrar a personalização das recomendações com questões éticas e técnicas, como privacidade, transparência e viés algorítmico. A falta de clareza nos processos de recomendação pode gerar desconfiança por parte dos usuários, enquanto a coleta massiva de dados pessoais levanta preocupações quanto à proteção da privacidade. Além disso, algoritmos de IA podem perpetuar preconceitos existentes, reforçando estereótipos e limitando a diversidade de opções oferecidas aos usuários.
O objetivo deste trabalho é analisar como a integração de IA nos SRs pode melhorar a personalização e a eficiência das recomendações, promovendo ao mesmo tempo uma abordagem ética e transparente. A hipótese deste trabalho é que a integração de técnicas avançadas de IA em SRs resultará em recomendações mais precisas e personalizadas, enquanto mitiga problemas relacionados à privacidade, viés algorítmico e falta de transparência, promovendo uma abordagem mais ética e responsável.
Foi realizada uma pesquisa bibliográfica com o objetivo de explorar as técnicas mais relevantes de IA aplicadas a SRs e investigar os desafios éticos associados à sua implementação. A busca foi conduzida nas bases de dados ACM Digital Library, IEEE Xplore e Google Scholar, além de livros e artigos de referência na área, utilizando as palavras-chave ‘Inteligência Artificial’, ‘Sistemas de Recomendação’, ‘Desafios Éticos’ e ‘Personalização’. O período de análise abrangeu publicações de janeiro a dezembro de 2024, garantindo uma visão atualizada sobre as práticas e desafios na área. Este trabalho busca responder à seguinte questão: de que maneira a aplicação de técnicas avançadas de IA pode aprimorar a precisão das recomendações em SRs, ao mesmo tempo em que aborda os desafios éticos e técnicos?
2 REVISÃO BIBLIOGRÁFICA
A crescente complexidade dos ambientes digitais exige soluções tecnológicas capazes de lidar com grandes volumes de dados e proporcionar experiências personalizadas aos usuários. Nesse contexto, os Sistemas de Recomendação (SRs) têm se destacado como uma ferramenta essencial, oferecendo sugestões de itens e conteúdos relevantes com base em comportamentos e preferências dos usuários. Com a evolução da Inteligência Artificial (IA), esses sistemas têm passado por avanços significativos, integrando técnicas de aprendizado de máquina para aumentar a precisão e personalização das recomendações. Esta revisão bibliográfica tem como objetivo apresentar as principais abordagens utilizadas na implementação de SRs, bem como os desafios éticos e técnicos relacionados à privacidade e ao viés algorítmico, além de discutir como a IA tem impulsionado inovações nesses sistemas.
2.1 SISTEMAS DE RECOMENDAÇÃO (SRs)
Um sistema de recomendação (SR) é um software utilizado em contextos em que existem usuários e itens. Seu objetivo é estimar quais são os itens que cada usuário tem maior possibilidade de consumir. Algumas aplicações são: Netflix, YouTube, Spotify, Deezer, Globo, Terra, Americanas, Amazon, X (antigo Twitter), Facebook e Instagram. Esses sistemas desempenham um papel importante na atração e retenção de clientes.
Goldberg et al. (1992), descrito por Resnick e Varian (1997) como o primeiro estudo sobre sistemas de recomendação, é apresentada a solução Tapestry. Tapestry foi um sistema experimental de envio de e-mails que permitia a personalização dos e-mails recebidos pelos usuários através da aplicação de filtros baseados não apenas no conteúdo dos documentos, mas também nas avaliações dos leitores sobre esses documentos. Por exemplo, um usuário poderia filtrar documentos usando uma query que indicasse nomes de outros usuários que tivessem avaliado positivamente notícias de um newsletter.
Resnick e Varian (1997) discutem cinco exemplos de aplicações práticas em sistemas de recomendação, abordando a forma de avaliação, a origem dos dados de feedback dos usuários, a possibilidade de anonimato dos usuários, os critérios para avaliação dos itens recomendados e o método de envio das recomendações aos usuários. Esses aspectos foram fundamentais para a diversificação dos estudos na área de sistemas de recomendação.
Exemplos de pesquisas subsequentes incluem Balabanovic (1998), que investigou o equilíbrio entre recomendar itens com base no histórico de avaliações dos usuários e a introdução de novos documentos, e Lawrence et al. (2001), que descreveram um sistema de recomendação de produtos para clientes de supermercados usando PDAs (Personal Digital Assistant). Cohen et al. (1999) abordaram aspectos relacionados à ordenação de itens recomendados.
Adomavicius e Tuzhilin (2005) categorizam os sistemas de recomendação em três tipos principais: filtragem colaborativa, filtragem baseada em conteúdo e sistemas híbridos. Eles detalham as técnicas comuns para implementar cada tipo, bem como suas vantagens e desvantagens. Adicionalmente, os autores propõem extensões aos sistemas de recomendação existentes, como técnicas para uma compreensão mais detalhada dos perfis de usuários e itens, uso de informações contextuais, avaliações de usuários baseadas em múltiplos critérios, coleta de avaliações não explícitas, flexibilidade para personalização de recomendações e aplicação de métricas mais apropriadas para avaliação de sistemas de recomendação, além da acurácia e cobertura tradicionalmente usadas.
Duas publicações de Jannach et al. (2010) e Lops et al. (2011) expandem a classificação dos sistemas de recomendação para seis tipos: demográficos, baseados em conhecimento, baseados em comunidade, além dos três já mencionados (colaborativo, baseado em conteúdo e híbrido). Esses trabalhos exploram questões como confiança (níveis de relacionamento entre usuários), explicações (motivos detalhados para cada recomendação), persuasão (convencimento de usuários a consumir itens), recomendações para grupos e segurança (diferenciação entre avaliações genuínas e manipuladas).
Conforme indicado por Bobadilla et al. (2013), o número de publicações em conferências e periódicos sobre sistemas de recomendação quadruplicou entre 2006 e 2012. Este aumento é atribuído à crescente geração de dados por diversas aplicações, ao interesse da indústria e ao Prêmio Netflix, que em 2006 ofereceu um milhão de dólares para o desenvolvimento de um algoritmo capaz de melhorar em 10% a acurácia do sistema de recomendação da empresa, medida pelo RMSE (Root Mean Squared Error). Os métodos de avaliação para sistemas de recomendação serão discutidos na Seção 3.
Os Srs são um tipo de sistema de aprendizado computacional e fazem uso de algoritmos que são divididos em três grupos de acordo com Sindhwani e Melville (2010): filtragem colaborativa, filtragem baseada em conteúdo e sistemas híbridos.
2.1.1 Filtragem Colaborativa (Collaborative Filtering)
Utilizado no comércio eletrônico, especialmente no formato “Quem comprou X também comprou Y”, essas recomendações sugerem itens que usuários semelhantes compraram ou com os quais interagiram. Através dos itens já comprados ou interagidos pelo usuário A, o sistema busca por usuários com comportamentos semelhantes (que interagiram com os mesmos itens) e seleciona itens com os quais o usuário A ainda não interagiu. Em seguida, recomenda aqueles itens que receberam as maiores avaliações entre os usuários semelhantes (Terveen et al., 2004).
Esse tipo de recomendação, baseado exclusivamente nos dados de vendas (quem comprou qual produto), é amplamente utilizado em sites de comércio eletrônico devido à sua implementação simples e rápida.
Na Figura1, o Usuário 3 comprou maçã como os outros usuários e então procura-se uma fruta que os outros Usuários compraram e o Usuário 3 ainda não comprou. Pelo exemplo pode-se ver que esta fruta é a laranja e então ela é recomendada.
Figura 1: Ciência de dados: mecanismos de recomendação com filtragem colaborativa
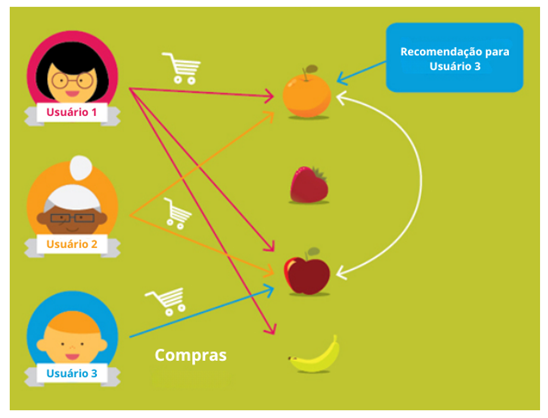
Disponível em: http://blog.operasolutions.com/bid/387700/Data-Science-Recommender-Engines-with- Collaborative-Filtering. Acesso em: 29 maio 2024.
2.1.2 Filtragem Baseada em Conteúdo (Content-based Filtering)
As recomendações baseadas em conteúdo (Content-based) sugerem itens semelhantes àqueles com os quais o usuário já interagiu ou comprou no passado. De acordo com De Gemmis, Lops e Semeraro (2012), o processo básico consiste em cruzar os atributos do perfil do usuário (interesses e preferências) com os atributos dos itens, para recomendar novos itens ao usuário.
O sistema analisa os documentos, descrições e características dos itens previamente interagidos pelo usuário e, com isso, cria um perfil dos interesses do usuário. Com base nesse perfil, o sistema recomenda novos itens que possuam atributos semelhantes.
A maioria dos sistemas baseados em conteúdo utiliza o texto ou a descrição dos itens, onde os atributos são normalmente representados por um conjunto de palavras.
Através dos itens avaliados pelo usuário, cria-se o perfil do mesmo e recomenda itens similares ao perfil.
Figura 2: Filtragem baseada em conteúdo.
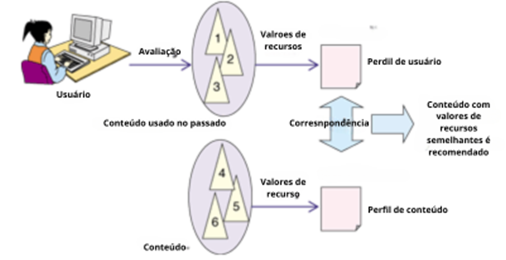
Disponível em: http://findoutyourfavorite.blogspot.com.br/2012/04/content-based-filtering.html. Acesso em: 29 maio 2024.
2.1.3 Sistemas de Recomendação Híbridos (Hybrid Recommender Systems)
Os algoritmos de recomendação híbridos combinam abordagens de Filtragem Colaborativa e Filtragem Baseada em Conteúdo, podem ser implementados de várias maneiras diferentes: aplicando os dois métodos separadamente e combinando os resultados posteriormente, adicionando capacidades Baseado em Conteúdo a um algoritmo de Filtragem Colaborativa (ou vice-versa), ou unificando ambas as abordagens em um único modelo.
De acordo com Burke (2002), existem diversos exemplos de combinações entre esses algoritmos, demonstrando os ganhos de desempenho obtidos com essas abordagens híbridas.
2.1.4 Sistema de Recomendação Sensíveis ao Contexto (Context-aware Recommender Systems)
Ao contrário dos algoritmos tradicionais, os algoritmos de recomendação contextual incorporam não apenas informações do item e do usuário, mas também dados do contexto que envolvem o evento, como tempo, clima, local e pessoas presentes, entre outros. Existem muitos casos em que as recomendações não podem se basear apenas nos dados do item ou do usuário, como em sites de filmes personalizados, sites de viagens e até sites de notícias. Por exemplo, considere uma pessoa assistindo televisão: seu comportamento pode variar durante a semana, quando assiste ao noticiário à noite, e nos finais de semana, quando assiste a jogos de futebol ou filmes (exemplo extraído de Adomavicius e Tuzhilin, 2010).
A incorporação do contexto permite uma personalização ainda mais precisa das recomendações, criando experiências verdadeiramente relevantes para o usuário. Como expressado por Prahalad (2004), “atingir e impactar clientes em qualquer lugar e a qualquer momento significa que as empresas precisam oferecer não apenas produtos competitivos, mas também experiências únicas e autênticas moldadas pelo contexto do cliente.”
A formulação da recomendação é realizada por meio da seguinte função:
f:User×Item×Context→Rating
Onde User e Item representam os domínios de usuário e item, respectivamente. Rating é o domínio das classificações (notas atribuídas aos itens), e Context são as informações de contexto associadas ao evento.
2.2 INTELIGÊNCIA ARTIFICIAL (IA)
Segundo Fernandes (2003), a expressão “inteligência artificial” deriva do latim, onde “inter” significa “entre” e “legere” significa “escolher”. Portanto, inteligência é a capacidade de escolher entre diferentes opções, sendo uma forma de resolver problemas e realizar tarefas. A inteligência artificial (IA) é, uma inteligência criada pelo homem para dotar as máquinas de habilidades que simulam a inteligência humana. No entanto, existem diversas definições de inteligência artificial entre os estudiosos da área.
Feigenbaum (1981, conforme citado por Fernandes, 2003) define inteligência artificial como uma área da ciência da computação dedicada ao desenvolvimento de sistemas computacionais inteligentes, ou seja, sistemas que exibem características associadas à inteligência humana. Exemplos dessas características incluem a compreensão da linguagem, aprendizado, raciocínio e resolução de problemas.
2.2.1 Aprendizagem Computacional
A Aprendizagem Computacional (Machine Learning) é uma subárea da Ciência da Computação e da Estatística que se concentra no estudo e desenvolvimento de algoritmos e técnicas que melhoram seu desempenho e precisão com base em uma medida de erro e na experiência adquirida através de conjuntos de dados de treinamento. Esses algoritmos integram diversos conceitos e técnicas de Inteligência Artificial e Otimização, o que frequentemente leva a uma sobreposição de temas na literatura (Mitchell, 1997).
As aplicações de aprendizagem computacional são variadas e incluem ferramentas de busca, detecção de fraudes em cartões de crédito e segmentação de clientes, entre outras. Em geral, essa tecnologia pode ser empregada em qualquer contexto em que algoritmos estáticos baseados em regras não são suficientes para atender às necessidades.
As tarefas de aprendizagem computacional podem ser categorizadas em:
- Aprendizagem Supervisionada: O algoritmo recebe exemplos de entradas e saídas, a partir dos quais “aprende” uma regra que mapeia as entradas nas saídas.
- Aprendizagem Não Supervisionada: Apenas exemplos de entrada são fornecidos, e o algoritmo é responsável por identificar agrupamentos e determinar os tipos de saída.
Existem diversos tipos de algoritmos de aprendizagem computacional, cada um com metodologias e finalidades distintas, como a Aprendizagem por Árvore de Decisão, Redes Bayesianas e Análise de Agrupamentos.
2.2.2 Aprendizado por Árvore de Decisão
Uma árvore de decisão é um algoritmo de aprendizagem supervisionada que utiliza um modelo preditivo para mapear as observações de um item e determinar o valor desejado desse item. As árvores de decisão recebem um conjunto de atributos como entrada e retornam uma decisão que é o valor predito para essa entrada. Sua estrutura é composta por nós e ramos: cada nó representa um teste em um atributo, e cada ramo representa um possível valor do atributo. Os nós terminais, que não têm ramos saindo deles, são chamadas folhas e especificam o valor de retorno se a folha for atingida (Maimon e Rokach, 2008).
Como exemplo de aplicação de uma árvore de decisão, podemos considerar o problema de decidir se deve esperar ou não para jantar em um restaurante. Neste caso, o objetivo é determinar se vale a pena esperar, considerando os seguintes atributos: alternar de restaurante, ir para um bar, dia da semana, estar com fome, número de fregueses, preço da comida, clima, se foi feita reserva, tipo do restaurante e estimativa de tempo de espera.
Figura 3: LIMA, Edirlei Soares. INF 1771 – Inteligência
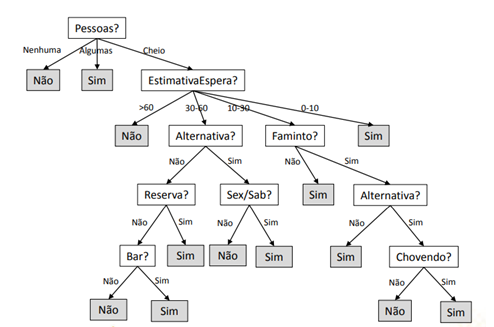
Disponível em: https://edirlei.com/aulas/ia_2012_2/IA_Aula_14_Arvores_de_Decisao_2012.pdf. Acesso em: 29 maio 2024.
2.2.3 Redes Bayesianas
Redes Bayesianas são modelos baseados em grafos utilizados para tomada de decisão em situações de incerteza. Nessas redes, os nós representam variáveis (que podem ser discretas ou contínuas) e os arcos indicam conexões diretas entre essas variáveis. O nome “Redes Bayesianas” deriva do uso da probabilidade bayesiana para determinar as chances de ocorrência de diversas possibilidades (Faltin, Ruggeri e Kennett, 2007).
Cada nó em uma rede bayesiana é associado a uma função de probabilidade que, ao receber um conjunto de valores das variáveis pais do nó, retorna à probabilidade (ou a distribuição de probabilidade) das variáveis representadas pelo nó.
Um exemplo de aplicação de uma rede bayesiana é a relação de probabilidade entre doenças e sintomas. Diante de sintomas específicos, a rede pode ser utilizada para calcular as probabilidades da presença de diferentes doenças.
2.2.4 Análise de Agrupamento
A Análise de Agrupamentos, também conhecida como Clustering, é a tarefa de organizar um conjunto de dados de forma que os objetos pertencentes ao mesmo grupo (cluster) sejam mais semelhantes entre si, de acordo com determinados critérios, do que aos objetos de outros grupos (Bailey, 1994).
Existem diversos algoritmos para realizar o agrupamento dos objetos, baseados em diferentes métodos, como a distância entre os pontos ou a aproximação dos centróides. Cada algoritmo pode produzir resultados distintos dependendo da natureza dos dados e dos critérios utilizados.
Um exemplo de aplicação de Clustering é a divisão de usuários de uma rede social em grupos, identificando assim comunidades baseadas em interesses ou temas específicos.
3 DESENVOLVIMENTO
Nesta seção, são discutidas as principais abordagens e técnicas que integram a Inteligência Artificial (IA) nos Sistemas de Recomendação (SRs). A evolução da IA tem desempenhado um papel fundamental no aprimoramento desses sistemas, permitindo maior precisão e personalização das recomendações. São analisadas as diferentes técnicas de aprendizado computacional, como Aprendizado de Máquina (Machine Learning), redes neurais e outros métodos que vêm transformando a forma como SRs operam em plataformas de streaming, e-commerce e redes sociais. Além disso, são abordados os desafios e resultados práticos da aplicação dessas tecnologias, bem como as tendências futuras no campo.
3.1 Evolução da Integração de IA em Sistemas de Recomendação
A integração da Inteligência Artificial (IA) em Sistemas de Recomendação (SRs) tem avançado rapidamente, impulsionada pelo aumento da disponibilidade de dados e da capacidade computacional. Diferente das abordagens tradicionais, que se baseavam apenas em técnicas de filtragem colaborativa e baseada em conteúdo, os algoritmos modernos de IA oferecem a capacidade de capturar padrões mais complexos e oferecer recomendações mais personalizadas e dinâmicas. O uso de aprendizado profundo (deep learning) é um dos exemplos mais significativos, pois permite o processamento de grandes volumes de dados não estruturados, como imagens, vídeos e textos, e melhora a acurácia das recomendações.
3.2 Casos Práticos de IA em SRs
Um exemplo prático da integração de IA em SRs é a plataforma Netflix, que utiliza redes neurais profundas para analisar não apenas o histórico de visualização dos usuários, mas também dados contextuais, como o momento do dia, os dispositivos usados e as interações recentes. O algoritmo da Netflix combina diferentes técnicas, como filtragem colaborativa e processamento de linguagem natural (NLP), para sugerir conteúdos com alta probabilidade de serem consumidos pelos usuários, aumentando significativamente a retenção e o tempo de uso da plataforma (Gomez-Uribe & Hunt, 2016).
Outro caso relevante é o sistema de recomendação da Amazon, que utiliza aprendizado de máquina supervisionado para prever os produtos que os usuários têm maior chance de comprar. Através da análise de dados de comportamento de compra, buscas e interações com o site, a IA da Amazon consegue fazer sugestões altamente personalizadas, aumentando o valor médio das compras e melhorando a experiência do usuário (Smith & Linden, 2017). Além disso, a Amazon é pioneira no uso de técnicas híbridas que combinam a filtragem colaborativa com o aprendizado profundo para otimizar suas recomendações.
3.3 Benefícios da IA para Personalização e Eficiência
Os benefícios da IA em SRs vão além da personalização das recomendações. A aplicação de algoritmos de IA permite que os sistemas de recomendação sejam capazes de se adaptar em tempo real ao comportamento do usuário, garantindo uma experiência mais fluida e relevante. Além disso, as técnicas de IA ajudam a otimizar a eficiência operacional, pois permitem identificar itens que não estão sendo explorados pelos usuários, sugerindo-os de forma estratégica para maximizar as interações (Ricci, Rokach, & Shapira, 2015).
Além da personalização, um dos maiores avanços da IA em SRs está na capacidade de “aprender” com feedbacks implícitos, ou seja, ações que os usuários realizam, como tempo gasto em uma página, cliques em produtos, ou até mesmo a velocidade de rolagem de uma tela. Esses dados, antes ignorados pelos sistemas tradicionais, agora são processados por algoritmos de IA que ajustam as recomendações de forma automática e precisa (Zhang et al., 2019).
3.4 Desafios e Limitações da Integração de IA em SRs
Apesar de todo o potencial da IA em aprimorar os SRs, sua implementação levanta uma série de desafios éticos e práticos que precisam ser considerados. Um dos principais problemas é a questão da privacidade dos dados. Para que os SRs sejam eficazes, eles dependem da coleta e análise de grandes volumes de informações pessoais dos usuários, como histórico de navegação, preferências e padrões de comportamento. Isso pode ser problemático, especialmente em um ambiente onde os regulamentos de privacidade estão se tornando mais rigorosos, como a Lei Geral de Proteção de Dados (LGPD) no Brasil e o Regulamento Geral sobre a Proteção de Dados (GDPR) na Europa (Tene & Polonetsky, 2012).
Outro grande desafio está relacionado ao viés algorítmico. Os algoritmos de IA são treinados com dados históricos e, se esses dados contiverem preconceitos ou padrões discriminatórios, os SRs podem acabar perpetuando essas distorções. Por exemplo, sistemas de recomendação em plataformas de e-commerce podem sugerir produtos baseados em estereótipos de gênero ou de classe, limitando as opções oferecidas a diferentes grupos de usuários (Friedman & Nissenbaum, 1996). Além disso, a criação de “bolhas de filtro” (filter bubbles), onde os usuários são expostos apenas a conteúdos que reforçam suas opiniões ou preferências anteriores, é um problema que afeta a diversidade das recomendações, especialmente em plataformas de redes sociais (Pariser, 2011).
3.4.1 Transparência e Responsabilidade
Com o crescente uso de IA, a transparência nos algoritmos de recomendação tornou-se uma necessidade. O funcionamento interno de muitos sistemas de recomendação é opaco para os usuários, o que pode gerar desconfiança, especialmente quando as recomendações parecem inadequadas ou enviesadas. A falta de transparência não só afeta a confiança dos usuários, mas também levanta questões sobre responsabilidade: quem deve ser responsabilizado quando um sistema de recomendação faz uma sugestão prejudicial ou errada?
A introdução da IA explicável (Explainable AI) está sendo considerada como uma solução para melhorar a transparência dos SRs. Essa abordagem visa criar algoritmos que possam justificar suas recomendações de forma compreensível para os usuários, explicando como e por que determinado item foi sugerido. Essa maior clareza permite que os usuários questionem as recomendações e possibilita que os desenvolvedores ajustem e aprimorem os sistemas para torná-los mais justos e éticos.
3.4.2 Questões Éticas na Personalização Excessiva
Outro desafio ético envolve a personalização excessiva. Embora a personalização seja o ponto central dos SRs, ela pode se tornar problemática quando usada para manipular comportamentos de consumo ou influenciar de maneira negativa as decisões dos usuários. Um exemplo disso é o “dark pattern“, no qual sistemas de recomendação exageram as sugestões de produtos, influenciando usuários a realizar compras desnecessárias. Além disso, em redes sociais, há preocupações de que SRs excessivamente personalizados possam alimentar a polarização de opiniões, expondo os usuários apenas a conteúdos que confirmam suas crenças, em vez de promover uma experiência diversificada.
3.4.3 Desafios na Equidade e Inclusão
A equidade na recomendação de itens é um ponto crítico, especialmente em um mundo cada vez mais conectado e diverso. Sistemas de Recomendação (SRs) que não levam em conta fatores de diversidade podem resultar em experiências desiguais para diferentes grupos de usuários, reforçando desigualdades e limitando o acesso a uma maior variedade de produtos, serviços e conteúdo.
Um exemplo disso é observado em plataformas de streaming de música ou vídeo. Se o algoritmo de recomendação de uma plataforma como o Spotify ou Netflix se basear exclusivamente no comportamento anterior do usuário, ele pode acabar “aprisionando” o usuário em um ciclo de recomendações que reforçam um único gênero musical ou cinematográfico. Isso pode levar à criação de “bolhas culturais”, nas quais os usuários não são expostos a diferentes estilos, gêneros ou culturas, perdendo a oportunidade de expandir seus horizontes.
Outro exemplo ocorre em plataformas de e-commerce, como Amazon. Se um sistema de recomendação for treinado com dados históricos que refletem preferências de consumidores de grupos majoritários, ele pode falhar em recomendar produtos que atendam às necessidades e preferências de minorias ou grupos sub-representados. Isso não só afeta negativamente a experiência de compra de usuários desses grupos, como também limita o acesso de pequenas empresas que produzem bens culturais ou produtos de nicho a um público mais amplo.
Além disso, os SRs em redes sociais, como o Facebook e o Instagram, enfrentam desafios semelhantes. Esses sistemas tendem a mostrar conteúdo baseados em interações anteriores, o que pode reforçar vieses e criar “bolhas de informações” (filter bubbles), expondo os usuários apenas a opiniões e conteúdo que correspondem ao seu círculo social ou ideológico. Isso pode perpetuar a polarização de opiniões e limitar o acesso a uma variedade mais ampla de perspectivas e informações.
Garantir que os SRs promovam a inclusão e a diversidade requer atenção em dois aspectos principais: treinamento dos algoritmos e análise dos dados usados. Para promover a equidade, os algoritmos de recomendação precisam ser treinados com dados que representem adequadamente a diversidade de usuários e seus interesses. Além disso, as métricas de sucesso de SRs devem incluir critérios que incentivem a diversidade nas recomendações, em vez de priorizar exclusivamente o engajamento ou o número de cliques.
Por fim, a implementação de técnicas de equidade algorítmica (algorithmic fairness), como o uso de algoritmos que ajustam as recomendações para maximizar a diversidade de conteúdo, pode ser uma solução promissora. Empresas como YouTube e Spotify já estão explorando maneiras de aumentar a variedade das recomendações, expondo os usuários a uma maior diversidade de culturas, gêneros e ideias, garantindo que todos os usuários possam ter uma experiência mais inclusiva e enriquecedora.
3.5 Futuras Tendências e Inovações
Com o avanço da IA, novas abordagens estão surgindo para resolver alguns dos desafios atuais dos SRs. Uma das inovações mais promissoras é o uso de IA explicável (Explainable AI), que visa aumentar a transparência dos sistemas de recomendação, permitindo que os usuários entendam por que um determinado item foi recomendado. Isso não apenas aumenta a confiança no sistema, mas também ajuda a reduzir o viés algorítmico (Doshi-Velez & Kim, 2017). A IA explicável permite que os desenvolvedores de sistemas criem recomendações mais justas e transparentes, ao mesmo tempo em que possibilita a verificação e ajustamento de decisões algorítmicas (Miller, 2019).
4 DISCUSSÃO E ANÁLISE DOS RESULTADOS
Na integração da Inteligência Artificial (IA) e Sistemas de Recomendação (SRs) demostrou avanços significativos em termos de personalização e eficiência, conforme analisado. Será discutido os resultados obtidos com base nas principais abordagens apresentadas, incluindo os impactos práticos, desafios identificados e as implicações éticas decorrentes da utilização de algoritmos de IA e SRs. A análise visa também explorar como essas tecnologias estão moldando a experiência do usuário, a retenção de clientes e as intenções com plataformas de streaming, e-commerce e redes sociais.
4.1 Personalização e a exatidão nos SRs
Um dos principais resultados da integração da IA em SRs é a significativa melhoria na personalização das recomendações. Os casos práticos analisados, como o Netflix e Amazon, evidenciam que o uso de técnicas de aprendizado profundo (deep learning) e aprendizado de máquina supervisionado (supervised machine learning) não apenas aumenta a precisão das recomendações, mas também permite que os sistemas se adaptem ao comportamento dos usuários em tempo real. Essa adaptabilidade é crucial para manter os usuários engajados, conforme observado no aumento do tempo de uso nas plataformas.
No caso da Netflix, por exemplo, a combinação de filtragem colaborativa com processamento de linguagem natural (NLP) e redes neurais profundas demonstrou uma capacidade sem precedentes de analisar grandes volumes de dados contextuais. Isso inclui fatores como o momento do dia em que o usuário assiste a conteúdo e o tipo de dispositivo utilizado, resultando em uma experiência personalizada que vai além das preferências explícitas do usuário. Os resultados indicam que a acurácia na recomendação foi amplamente melhorada, reduzindo a taxa de abandono de conteúdo e aumentando a retenção de assinantes [Gomez-Uribe & Hunt, 2016].
4.2 Impactos no E-commerce e Aumento da receita
Os SRs baseados em IA também têm um impacto significativo em plataformas de e-commerce. Como observado no sistema da Amazon, o uso de algoritmos de aprendizado supervisionado para prever os produtos que os usuários têm maior chance de comprar trouxe não apenas uma experiência de compra mais fluida, mas também aumentou o valor médio de compras por usuário [Smith & Linden, 2017]. A aplicação de técnicas híbridas que combinam filtragem colaborativa com aprendizado profundo mostrou-se eficaz ao sugerir produtos de nicho ou que os usuários não haviam considerado anteriormente, ampliando a diversidade de itens comprados.
Esse resultado revela a capacidade dos SRs baseados em IA de influenciar o comportamento de compra e maximizar a receita das plataformas. Além disso, os sistemas são capazes de sugerir produtos em tempo real com base no comportamento de navegação, o que tem o potencial de aumentar significativamente as vendas impulsivas e o ticket médio.
4.3 Transparência e Responsabilidade
A análise dos SRs também revelou a necessidade de maior transparência nas recomendações feitas por algoritmos de IA. Embora a personalização seja um ponto forte, a opacidade do funcionamento interno desses sistemas pode gerar desconfiança entre os usuários. Muitos usuários não entendem como ou por que certos itens lhes são recomendados, o que pode levar a percepções negativas, principalmente quando as recomendações parecem inadequadas ou enviesadas.
A introdução de IA explicável (Explainable AI) surge como uma solução promissora para lidar com essa questão [Doshi-Velez & Kim, 2017]. A capacidade de justificar as recomendações, explicando como e por que determinado item foi sugerido, aumenta a transparência e permite que os usuários confiem mais no sistema. Além disso, possibilita que os desenvolvedores ajustem os sistemas de recomendação, aprimorando sua precisão e equidade.
4.4 Diversidade e Inclusão nas Recomendações
Outro ponto crucial levantado na análise dos SRs foi a questão da diversidade nas recomendações. Como destacado, os algoritmos que não levam em consideração a diversidade cultural, social e comportamental podem limitar as opções oferecidas aos usuários, criando “bolhas” de recomendação que reforçam comportamentos já estabelecidos. Isso é particularmente relevante em plataformas de streaming e redes sociais, onde o conteúdo recomendado tende a ser baseado em interações anteriores, excluindo novas perspectivas ou estilos [Pariser, 2011].
Plataformas como YouTube e Spotify estão começando a explorar soluções para esse problema, ajustando seus algoritmos para maximizar a diversidade de conteúdo. A equidade algorítmica (algorithmic fairness) é um campo em crescimento, e a análise sugere que o desenvolvimento de algoritmos que promovam maior inclusão será uma tendência futura para combater a criação dessas “bolhas”.
5 CONCLUSÃO
Este estudo analisou a integração da Inteligência Artificial (IA) em Sistemas de Recomendação (SRs), destacando os avanços proporcionados por técnicas como aprendizado de máquina, redes neurais e processamento de linguagem natural (NLP). A aplicação dessas técnicas permite que os SRs ofereçam recomendações mais precisas, personalizadas e dinâmicas, transformando a forma como os usuários interagem com plataformas de streaming, e-commerce e redes sociais. Os exemplos práticos de grandes empresas, como Netflix e Amazon, mostraram como a IA pode aumentar a retenção de usuários e o valor médio das compras, respectivamente, ao adaptar-se ao comportamento do consumidor em tempo real.
Entretanto, o sucesso da implementação dessas tecnologias não se resume apenas aos avanços técnicos. O estudo revelou que, para garantir que os SRs ofereçam valor tanto para os usuários quanto para as empresas, é fundamental equilibrar a eficácia das recomendações com uma abordagem ética. Apesar dos benefícios proporcionados pela personalização, há desafios significativos relacionados à privacidade dos dados e ao viés algorítmico. A personalização excessiva, quando não controlada, pode levar à criação de “bolhas de filtro”, limitando a diversidade de opções apresentadas aos usuários e reforçando comportamentos e crenças pré-existentes. Além disso, sistemas de recomendação que não consideram a diversidade cultural e social correm o risco de reforçar desigualdades, em vez de promover a inclusão.
Nesse sentido, a transparência nos algoritmos, por meio da IA explicável, emerge como uma solução importante para garantir que os usuários compreendam como as recomendações são feitas e sintam confiança nos sistemas. Assim, o futuro sucesso dos SRs dependerá de um equilíbrio contínuo entre a eficiência técnica e a responsabilidade ética. A busca por equidade algorítmica e inclusão é uma tendência crescente, com algoritmos sendo ajustados para promover maior diversidade de conteúdo e experiências.
Por fim, este estudo oferece insights valiosos tanto para futuros pesquisadores quanto para profissionais da área, indicando que o sucesso da integração da IA em SRs dependerá não apenas da aplicação de técnicas avançadas, mas também da consideração cuidadosa dos desafios éticos envolvidos. Futuros trabalhos podem se aprofundar no desenvolvimento de novos modelos de IA que combinem eficácia com responsabilidade, oferecendo soluções que atendam tanto às demandas técnicas quanto às sociais e éticas.
REFERÊNCIAS BIBLIOGRÁFICAS
ADOMAVICIUS, Gediminas; TUZHILIN, Alexander. Context-aware recommender systems. Disponível em: http://ids.csom.umn.edu/faculty/gedas/nsfcareer/CARS-chapter-2010.pdf. Acesso em: 29 maio 2024.
BAILEY, Kenneth. Numerical Taxonomy and Cluster Analysis. SAGE, 1994.
BALABANOVIĆ, M. Exploring Versus Exploiting when Learning User Models for Text Recommendation. User Modeling and User-Adapted Interaction, v. 8, n. 1-2, p. 71–102, mar. 1998.
BOBADILLA, J.; ORTEGA, F.; HERNANDO, A.; GUTIÉRREZ, A. Recommender Systems Survey. Knowledge-Based Systems, v. 46, p. 109–132, jul. 2013.
BURKE, Robin. Hybrid recommender systems: Survey and experiments. Disponível em: http://josquin.cs.depaul.edu/~rburke/pubs/burke-umuai02.pdf. Acesso em: 29 maio 2024.
COHEN, W. W.; SCHAPIRE, R. E.; SINGER, Y. Learning to Order Things. Journal of Artificial Intelligence Research, v. 10, n. 1, p. 243–270, maio 1999.
Data science: Recommender engines with collaborative filtering. Disponível em: http://blog.operasolutions.com/bid/387700/Data-Science-Recommender-Engines-with-Collaborative-Filtering. Acesso em: 29 maio 2024.
DE GEMMIS, Marco; LOPS, Pasquale; SEMERARO, Giovanni. Content-based recommender systems: State of the art and trends. Disponível em: http://www.ics.uci.edu/~welling/teaching/CS77Bwinter12/handbook/ContentBasedRS.pdf. Acesso em: 29 maio 2024.
FERNANDES, Anita Maria da Rocha. Inteligência artificial: noções gerais. Florianópolis: Visual Books, 2003.
FEIGENBAUM, E. A.; FELDMAN, J. Computers and Thought: A Collection of Articles. New York: McGraw Hill, 1963.
FALTIN, Frederick; RUGGERI, Fabrizio; KENNETT, Ron. Bayesian networks. Disponível em: http://www.eng.tau.ac.il/~bengal/BN.pdf. Acesso em: 29 maio 2024.
GOLDBERG, D.; NICHOLS, D.; OKI, B. M.; TERRY, D. Using Collaborative Filtering to Weave an Information Tapestry. Communications of the ACM, v. 35, n. 12, p. 61–70, dez. 1992.
JANNACH, D.; ZANKER, M.; FELFERNIG, A.; FRIEDRICH, G. Recommender Systems: An Introduction. New York: Cambridge University Press, 2010.
LAWRENCE, R. D.; ALMASI, G. S.; KOTLYAR, V.; VIVEROS, M. S.; DURI, S. S. Personalization of Supermarket Product Recommendations. Data Mining and Knowledge Discovery, v. 5, n. 1-2, p. 11–32, jan. 2001.
LIMA, Edirlei Soares. INF 1771 – Inteligência Artificial. Disponível em: https://edirlei.com/aulas/ia_2012_2/IA_Aula_14_Arvores_de_Decisao_2012.pdf. Acesso em: 29 maio 2024.
LOPS, P.; DE GEMMIS, M.; SEMERARO, G. Content-based recommender systems: State of the art and trends. In: RICCI, F.; ROKACH, L.; SHAPIRA, B.; KANTOR, P. B. (Ed.). Recommender Systems Handbook. Springer, 2011. cap. 3, p. 73–105.
MAIMON, Oded; ROKACH, Lior. Data mining with decision trees: theory and applications. World Scientific Pub Co Inc, 2008.
MITCHELL, Tom. Machine Learning. McGraw Hill, 1997.
NORVIG, Peter; RUSSELL, Stuart. Artificial Intelligence: A Modern Approach. Prentice Hall, 2009.
PRAHALAD, C. K. Beyond CRM: C. K. Prahalad predicts customer context is the next big thing. American Management Association MwWorld, 2004.
RESNICK, P.; VARIAN, H. R. Recommender Systems. Communications of the ACM, v. 40, n. 3, p. 56–58, mar. 1997.
SINDHWANI, Vikas; MELVILLE, Prem. Recommender systems. Disponível em: http://www.prem-melville.com/publications/recommender-systems-eml2010.pdf. Acesso em: 29 maio 2024.
TERVEEN, Loren; RIEDL, John; HERLOCKER, Jonathan; KONSTAN, Joseph. Evaluating collaborative filtering recommender systems. Disponível em: http://dl.acm.org/citation.cfm?id=963772. Acesso em: 29 maio 2024.
GOMEZ-URIBE, C. A.; HUNT, N. The Netflix Recommender System: Algorithms, Business Value, and Innovation. ACM Transactions on Management Information Systems (TMIS), v. 6, n. 4, p. 1-19, 2016.
SMITH, B.; LINDEN, G. Two Decades of Recommender Systems at Amazon.com. IEEE Internet Computing, v. 21, n. 3, p. 12-18, 2017.
RICCI, F.; ROKACH, L.; SHAPIRA, B. Recommender Systems Handbook. Springer, 2015.
ZHANG, S.; YAO, L.; SUN, A.; TAY, Y. Deep Learning Based Recommender System: A Survey and New Perspectives. ACM Computing Surveys (CSUR), v. 52, n. 1, p. 1-38, 2019.
TENE, O.; POLONETSKY, J. Privacy in the Age of Big Data: A Time for Big Decisions. Stanford Law Review Online, v. 64, p. 63-69, 2012.
FRIEDMAN, B.; NISSENBAUM, H. Bias in Computer Systems. ACM Transactions on Information Systems (TOIS), v. 14, n. 3, p. 330-347, 1996.
PARISER, E. The Filter Bubble: What the Internet is Hiding from You. Penguin Press, 2011.
DOSHI-VELEZ, F.; KIM, B. Towards a Rigorous Science of Interpretable Machine Learning. arXiv preprint, arXiv:1702.08608, 2017.
MILLER, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. Artificial Intelligence, v. 267, p. 1-38, 2019.
1Graduando do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: phasantos@uniara.edu.br
2Orientador. Docente Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: jhgborges@uniara.edu.br