REGISTRO DOI: 10.69849/revistaft/cl10202410021705

Renan Oliveira de Carvalho1
João Henrique Gião Borges2
André Luiz da Silva3
Fabiana Florian4
RESUMO
Este trabalho tem o objetivo de desenvolver um software que utiliza aprendizado de máquina e visão computacional para auxiliar no diagnóstico precoce de melanoma. O software foi desenvolvido em Python, utilizando bibliotecas de inteligência artificial e processamento de imagens, como o “TensorFlow” e o “OpenCV”, e a arquitetura de rede neural VGG16. O software comparou imagens suspeitas de lesões cutâneas com um banco de dados contendo imagens de lesões malignas e benignas, envolvendo o pré-processamento das imagens, a extração de características com o VGG16 e a análise de similaridade cosseno para a classificação das imagens. Os resultados indicaram que o sistema é eficaz na distinção entre lesões malignas e benignas, mas a acurácia depende da qualidade e diversidade das imagens. Futuros aprimoramentos poderiam incluir a ampliação do banco de dados e o uso de mais métodos de comparação de imagens.
Key-words: Câncer de pele, Diagnóstico precoce, Melanoma, Inteligência Artificial, Aprendizado de Máquina, Visão Computacional, Python.
1 INTRODUÇÃO
O câncer é uma das principais causas de morte no mundo, porém, se for detectado precocemente, as chances de cura aumentam. Segundo a Federação Brasileira das Entidades Beneficentes de Apoio à Saúde da Mama (FEMAMA), o diagnóstico precoce pode aumentar em até 95% as chances de tratamento. Enfatizando a importância da detecção rápida de células cancerígenas numa fase inicial é crucial para se evitar o agravamento da doença. Além disso, avanços tecnológicos, como a análise de imagens por meio de inteligência artificial, revolucionaram o campo do diagnóstico médico.
A aplicação da Inteligência Artificial (IA) à prática médica facilita a tarefa diagnóstica, possibilitando que os médicos tenham mais tempo para atender os pacientes. A IA, uma área da ciência da computação que é dedicada ao desenvolvimento de sistemas capazes de executar tarefas que normalmente exigiriam inteligência humana, como reconhecimento de fala, tomada de decisões e tradução de idiomas (DE SA; BORGES, 2023). Na medicina, esses algoritmos processam um volume imenso de dados para descobrir padrões e fornecem apoio em tempo real na tomada de decisões clínicas.
Além disso, a IA trilha um caminho para a tomada de decisão dos profissionais de saúde ao revelar características complexas que podem ser difíceis de ver a olho nu. Isto permite que médicos e enfermeiros façam escolhas mais estratégicas, que aliviam a sua carga de trabalho, com mais tempo livre esses profissionais podem realmente se dedicar ao apoio emocional e em como resolver o problema. Esta evolução sugere procedimentos cada vez menos invasivos, como uma biópsia, que representa uma mudança fundamental para um futuro em que o processo seja menos doloroso, mas também preventivo.
A análise de imagens orientada por IA facilita a intervenção profissional, produz relatórios médicos com rapidez e detecta anomalias que seriam quase impossíveis a olho nu. A precisão desses diagnósticos requer confiança que os métodos manuais tradicionais talvez não consigam fornecer devido aos melanomas serem na maioria das vezes visualmente parecidos com pintas ou manchas comuns.
Durante um exame de rotina, uma descoberta inesperada: uma lesão cutânea que não apresenta uma variação normal. Para muitos, esse momento marca o início de um período cheio de incertezas, com a questão: “Pode ser câncer ou não?”. Segundo o Instituto Nacional do Câncer (INCA, 2023), são esperados 2.175.000 novos casos de câncer até 2025, aproximadamente 725 mil casos por ano. Diante desse cenário, a precisão do diagnóstico é o mais importante. No entanto, o processo manual de análise dessas imagens é notoriamente lento, sujeito a erros e imprecisões, dificultado pela diversidade e complexidade das células cancerígenas, já que o câncer se caracteriza pela proliferação exacerbada das células.
O crescimento acelerado da inteligência artificial e do aprendizado de máquina acelera os métodos de diagnóstico médico, tornando-os mais inteligentes e precisos. Este artigo tem o objetivo de desenvolver um software utilizando a linguagem de programação em Python, que permitirá o auxílio no processo de diagnóstico. O programa analisa uma imagem de um suposto melanoma e compara com um banco de dados com imagens malignas e benignas, classificando o seu grau de similaridade com ambas, fornecendo um apoio para a detecção precoce do tumor. Esse avanço não só acelera diagnósticos e proporciona maior precisão, mas também proporciona orientação. Com a ajuda de algoritmos em constante melhoria, a IA aprimora hipóteses diagnósticas para se tornar cada vez mais precisa.
O software pode ser usado por dermatologistas durante consultas ao terem um pré-diagnóstico imediato e sanar todas as dúvidas do paciente em seu atendimento. Ao fornecer uma análise da probabilidade de uma lesão ser maligna ou benigna, auxiliando os médicos a tomarem decisões sobre a necessidade de biópsias ou encaminhamento para especialistas oncológicos. Sendo muito útil em regiões remotas onde a escassez ou a demanda de profissionais ou aparelhos de diagnósticos é alta.
O software inclui tecnologia avançadas como “Numpy”, “OpenCV” e “TensorFlow” essenciais no desenvolvimento do sistema. “Numpy” se destaca no desenvolvimento de sistemas científicos e de engenharia devido ao seu objeto, que representa arrays multidimensionais homogêneos de tamanho fixo, permitindo computação de alta velocidade crucial para manipulação eficaz de grandes conjuntos de dados (JINKU HU,2021). Esse recurso é crucial para processar e interpretar a complexidade das informações obtidas em imagens médicas. Por outro lado,” OpenCV”, que significa “Open Source Computer Vision Library”, concentra-se em algoritmos de “visão computacional” e “Machine Learning“. Ao fazer isso, o software não apenas captura e analisa imagens, mas também identifica padrões e características celulares que podem indicar a presença de câncer. Já o “TensorFlow” desempenha um papel fundamental ao fornecer a infraestrutura necessária para a construção e treinamento de modelos de aprendizado profundo, como a rede neural convolucional VGG16 utilizada neste projeto. Esse modelo pré-treinado permite a extração de características visuais complexas das imagens, facilitando a comparação e a classificação das lesões cutâneas, auxiliando assim no diagnóstico precoce do câncer.
Usando essas bibliotecas, o software poderá examinar imagens de células potencialmente cancerígenas e avaliar a probabilidade de ser câncer. Esta análise é importante para fornecer um apoio importante à detecção precoce do tumor e para fornecer orientação. As técnicas de “aprendizado de máquina” e “visão computacional” apoiadas em “Numpy” e “OpenCV”.
2 INTELIGÊNCIA ARTIFICIAL (IA) E MACHINE LEARNING
Esta seção apresenta uma base teórica dos principais conceitos em torno de Inteligência Artificial e Machine Learning proporcionando melhor compreensão deste trabalho.
IA é uma subárea da computação em que computadores executam tarefas de alto nível, igualando a inteligência dos humanos, que servem para vários mercados como melhoria da gestão de estoque ou até mesmo reconhecer padrões de características em imagens. Segundo Russell e Norvig (2016), a IA pode ser definida como o estudo de agentes que recebem percepções do ambiente e realizam ações que maximizam suas chances de sucesso. Ela desempenha um papel importante em várias etapas do tratamento e pesquisa do câncer, desde o diagnóstico precoce até a tomada de decisões sobre tratamentos complexos
Machine Learning é uma subárea da Inteligência Artificial focada no desenvolvimento de algoritmos a serem treinados a partir de vários dados, melhorando sua performance em tarefas específicas, sem serem explicitamente programados para isso. Segundo Bishop (2006), Machine Learning explora o estudo e construção de algoritmos que podem aprender de e fazer previsões sobre dados.
O aprendizado de máquina pode ser classificado em três categorias principais: o supervisionado, que é treinado com dados rotulados; o não supervisionado, em que, ao contrário do supervisionado, os dados não são rotulados e o objetivo é identificar padrões ocultos; e o aprendizado por reforço, que aprende interagindo com o ambiente. Murphy (2012) fornece uma abordagem probabilística para o aprendizado supervisionado e outros métodos em seu texto.
Existem muitas aplicações para Machine learning e áreas como perspectiva computacional, processamento de linguagem natural, e diagnósticos médicos. Jordan e Mitchell (2015) discutem como Machine learning tem impactado diversas áreas, transformando indústrias e profissões ao permitir análises mais profundas de grandes volumes de dados.
Python é uma linguagem de programação fácil e amplamente utilizada, projetada por Guido van Rossum e lançada em 1991. Foi criada com o objetivo de ser intuitiva e acessível, permitindo aos desenvolvedores criarem códigos em menos linhas em comparação com outras linguagens de nível mais baixo, como C++ ou Java, suportando múltiplos paradigmas de programação, incluindo programação orientada a objetos.
Python foi projetado com um foco em clareza e simplicidade, o que torna seu código mais legível e fácil de entender. Isso é evidenciado pelo uso de espaços em branco para definir blocos de código, ao invés de chaves ou palavras-chave específicas. É uma linguagem de tipagem dinâmica, o que significa que uma variável é determinada em tempo de execução e não precisa ser explicitamente declarada pelo programador. Isso facilita a escrita e reduz a quantidade de código necessário. Gerencia automaticamente a memória usada pelos programas. Isso inclui a alocação e liberação de memória, o que reduz a possibilidade de vazamentos de memória e outros problemas relacionados à gestão de memória.
3 DESENVOLVIMENTO
Esta seção apresenta as etapas para realizar a análise de imagens de câncer de pele, que emprega, bibliotecas avançadas para comparação de imagens e extração de suas variâncias e características.
O modelo VGG16 foi escolhido devido à sua eficácia comprovada em tarefas de classificação de imagens (SIMONYAN & ZISSERMAN, 2015). Este modelo é amplamente utilizado em problemas de visão computacional por sua capacidade de capturar características visuais e detalhadas. As camadas convolucionais profundas permitem a extração de recursos a nível alto, que é fundamental para identificar padrões complexos em imagens.
A) Redes Neurais Convolucionais (CNNs)
As redes neurais convolucionais são um tipo de rede neural artificial projetada para processar dados que têm uma estrutura de grelha, como imagens digitais (KRIZHEVSKY, SUTSKEVER, & HINTON, 2012). A CNN é uma sequência de camadas que estão em posição de fazer processamento e extração de informações diferentes de imagens digitais.
B) Camadas Convolucionais
As principais construções de CNNs são as camadas convolucionais. Elas usam convoluções, onde a entrada da imagem é varrida pelos filtros para extrair informações da imagem localmente, como texturas, bordas e padrões (LECUN, BENGIO, & HINTON, 2015). Cada um dos núcleos usados é projetado de uma forma que ele pegará um tipo de característica da imagem. Durante o treinamento, os valores dos filtros são atualizados de tal forma que mesmo a mais mínima informação da imagem seja destacada, para que a detecção de padrões possa ser feita corretamente.
C) Camadas de Pooling
Após as camadas convolucionais, geralmente surgem as camadas de pooling (ou camadas de subamostragem) em CNNs. É um processo no qual a dimensionalidade dos dados é reduzida de uma maneira que apenas as características mais dominantes permaneçam. Isso pode ser feito, por exemplo, por agrupamento máximo, onde o valor máximo em uma região é preservado, ou por agrupamento médio, onde o valor médio é preservado (SZEGEDY ET AL., 2015).
D) Camadas Totalmente Conectadas
A última camada da CNN é a camada totalmente conectada, à camada de neurônios em que um neurônio é conectado a cada neurônio da camada anterior (ESTEVA ET AL., 2017). O trabalho das camadas é essencialmente extrair características das camadas anteriores e fazer a última tarefa de classificação ou qualquer outra tarefa de aprendizado.
3.1 Aquisição dos dados
Para o desenvolvimento e teste do software, utiliza-se um conjunto de imagens composta por lesões cutâneas malignas, e uma imagem de lesão suspeita para a análise comparativa. As imagens foram obtidas de bancos de dados públicos especializados em imagens médicas de dermatologia, e todas foram organizadas em diretórios específicos separando cada uma por categoria para facilitar o processamento.
3.1.1 Pré-processamento de Imagens
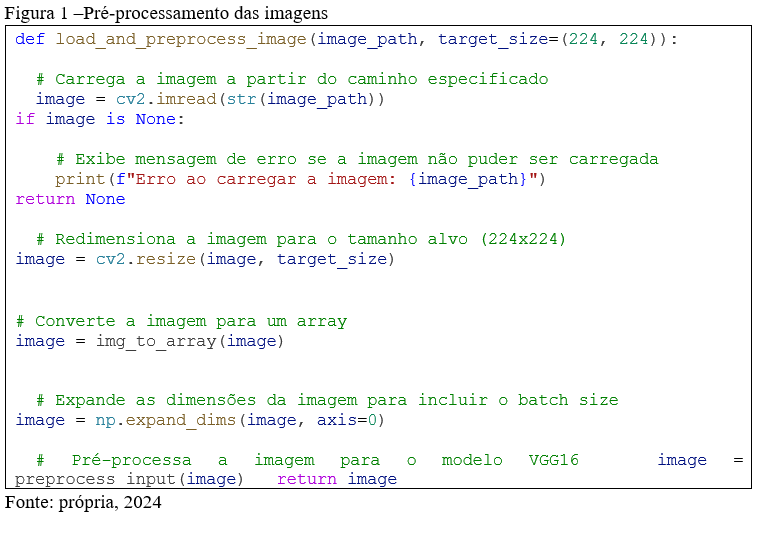
A figura 1 mostra o pré processamento das imagens que é uma etapa importante para a análise, garantindo que todas as imagens estejam em um formato adequado como 224×224 pixels , que é o tamanho de entrada padrão esperado pelo VGG16 .A normalização dos valores dos pixels é também importante para a faixa [-1,1] ,prática comum no treinamento de redes neurais, isso pode ajudar a acelerar o processo de treinamento, pois redes neurais tendem a treinar mais eficientemente quando os valores de entrada estão em uma faixa limitada e equilibrada. Utilizando a função ‘preprocess_input’ da biblioteca tensor ‘TensorFlow’, levando em conta que todos os processos têm uma mensagem de verificação de erro, onde se algo falhar, será exibido no console.
3.1.2 Extração de características
A figura 2 mostra uma função “extract_features” que extrai as características da imagem usando o modelo VGG16, com representações de alto nível, capturando informações essenciais que vão ser usadas para a comparação. A imagem é passada pelo modelo para obter uma previsão das variâncias e após isso, são achatadas em um vetor 1D para afim de facilitar o cálculo da similaridade.

3.1.3 Cálculo da similaridade
A figura 3 ilustra um método chamado “calculate_cosine_similarity”, que é uma métrica frequentemente utilizada para medir a similaridade entre dois vetores, avaliando o cosseno do ângulo entre dois vetores no espaço vetorial, indicando quão alinhados ou próximo estão em termos de direção. É muito usada em tarefas de processamento de linguagem natural e visão computacional, a ideia desse processo é avaliar o quão parecidos são ambos os vetores independentes de sua magnitude. Assim permite a comparação e a identificação de padrões semelhantes.
O cálculo do produto escalar entre os dois vetores de características é realizado através da linha dot_product = np.dot(feature1, feature2), que computa a soma dos produtos dos elementos correspondentes de cada vetor. Em seguida, as normas (ou magnitudes) dos vetores são determinadas pelas linhas norm1 = np.linalg.norm(feature1) e norm2 = np.linalg.norm(feature2), onde a norma é a raiz quadrada da soma dos quadrados de seus elementos. Finalmente, a similaridade cosseno é calculada dividindo o produto escalar pelo produto das normas dos vetores (similarity = dot_product / (norm1 * norm2)). O valor resultante indica o grau de similaridade entre os vetores, variando entre -1 e 1, onde 1 representa vetores idênticos em direção e -1 indica que eles são opostos.”

3.1.4 Carregamento e Pré-processamento de Imagens em Massa
A figura 4 mostra a função ‘load_images_from_folder’ que serve para carregar e pré-processar as todas as imagens de lesões contidas em um diretório especificado. Ela cria uma lista vazia chamada ‘Images’ para guardar as imagens carregadas, em seguida utiliza
‘os.listdir(folder_path)’ obtendo uma lista de todos os arquivos no diretório e iterar sobre cada arquivo. Para cada um, constrói o caminho completo da imagem (‘img_path’) e utiliza a função ‘load_and_preprocess_image’ para carregar e processar redimensionando-a para 224×224 pixels, convertendo-a para um array .Caso a imagem seja carregada com sucesso , ela é adicionada à lista de imagens carregadas e pré-processadas , sinalizando que estão prontas para serem usadas pelo modelo de rede neural.

3.1.5 Carregamento e Pré-processamento da imagem suspeita
A função load_and_preprocess_image apresentada na figura 5, é chamada para carregar e pré-processar a imagem da lesão suspeita. Este passo é muito importante para garantir que a imagem não esteja fora do formato correto para ser analisada pelo modelo de rede neural (VGG16). Caso a imagem não possa ser carregada, uma exceção é levantada interrompendo o processo e evitando possíveis erros na análise.

Em seguida, a figura 6 mostra o código carregando o modelo VGG16 pré-treinado para que as saídas desejadas sejam as mesmas extraídas da penúltima camada totalmente conectada(‘fc1’).Este ajuste é feito para que o modelo possa ser utilizado como um extrator de características, capturando informações visuais detalhadas. Após o carregamento do modelo, as características da imagem suspeita são extraídas usando a função extract_features. Esse vetor de características servirá como base para a comparação com as características extraídas das outras imagens (malignas e benignas).

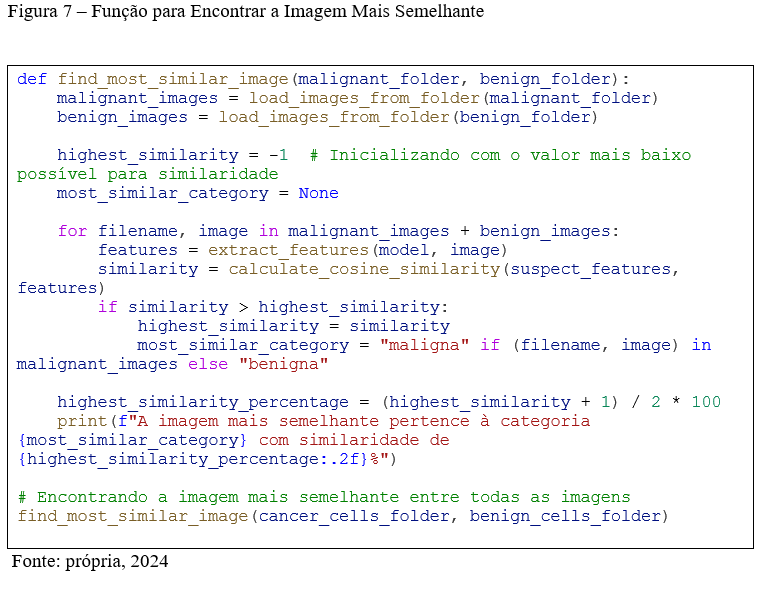
A função find_most_similar_image da figura 7 é o núcleo do processo de comparação. Ela começa carregando as imagens categorizadas como malignas e benignas, utilizando a função load_images_from_folder, e então itera sobre todas elas para calcular a similaridade entre cada imagem e a imagem suspeita. Durante essa interação, a função calcula a similaridade cosseno entre as características da imagem suspeita e cada imagem no banco de dados. A imagem com a maior similaridade é identificada, e a categoria dessa imagem (maligna ou benigna) é armazenada. Ao final da iteração, a função calcula a porcentagem de similaridade da imagem mais próxima e imprime o resultado, indicando se a imagem suspeita é mais semelhante a uma imagem maligna ou benigna.
4-RESULTADOS
Nesta seção, foram apresentados os resultados obtidos com a execução do código desenvolvido.
4.1 Resultados Obtidos com a Imagem Suspeita
Após a execução do código, o sistema processou a imagem suspeita (Imagem 9) e comparou-a com as imagens de referência, que estavam na pasta categorizadas como malignas ou benignas (Imagem 10). A imagem suspeita passou pelo processo de pré-processamento, onde foi redimensionada e normalizada, conforme descrito nas seções anteriores. Em seguida, o modelo VGG16 foi utilizado para extrair as características dessa imagem.
Imagem 9 – Melanoma suspeito
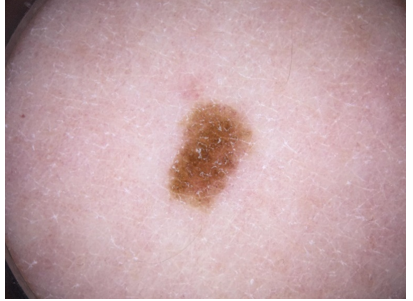
Imagem 10 – Pasta com imagens de treino malignas e benignas

Fonte: ISIC ARCHIVE, 2024
A fim de facilitar a compreensão, desenvolvi um código a parte que ilustra as comparações feitas pela Inteligência artificial. Como observamos (Imagem 11) cada pixel é analisado pela máquina, evidenciando as principais características similares e apontando-as através de uma linha horizontal. O resultado do código mostra também como a imagem fica após ser tratada pelos métodos citados na imagem 11, lembrando que as tratativas no código principal descrito neste trabalho são mais rigorosas e assertivas. Este modelo é apenas uma demonstração de como a IA faz a comparação.
Imagem 11 – Pontos de similaridade

Fonte: própria, 2024
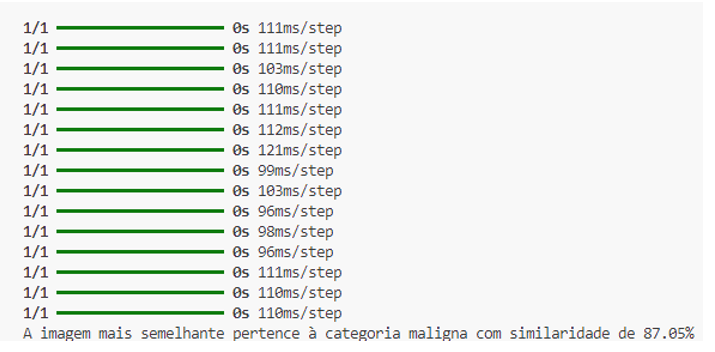
O código então comparou essas características com as características extraídas de cada imagem no banco de dados (malignas e benignas). O resultado mais relevante foi o cálculo da similaridade cosseno, que determinou a semelhança entre a imagem suspeita e as outras imagens. Durante a comparação, o sistema analisou todas as imagens nas pastas de lesões malignas e benignas evidenciando cada iteração com elas e o tempo de realização. A imagem mais semelhante pertencia à categoria de lesões malignas, sugerindo que a imagem suspeita possui características mais próximas de uma lesão maligna como podemos observar (imagem 12 ).
Imagem 12 – Resultado da comparação
Fonte: própria,2024
Esse resultado fornece uma indicação crucial sobre a natureza da lesão cutânea analisada. A precisão e a alta similaridade encontrada sugerem que o sistema desenvolvido pode ser uma ferramenta útil no auxílio ao diagnóstico precoce de câncer, permitindo que médicos e profissionais de saúde identifiquem rapidamente se uma lesão é potencialmente maligna ou benigna.
5 CONCLUSÃO
O objetivo desta pesquisa foi desenvolver um sistema para a detecção precoce de melanoma utilizando técnicas de aprendizado de máquina, especificamente por meio do modelo de rede neural convolucional VGG16. A ferramenta proposta visa auxiliar médicos e profissionais de saúde na identificação de lesões cutâneas malignas e benignas, comparando imagens suspeitas com um banco de dados previamente categorizado. A questão central da pesquisa é se o aprendizado profundo pode efetivamente contribuir para o diagnóstico precoce de melanoma e foi respondida de forma positiva, conforme demonstrado pelos resultados obtidos.
O trabalho mostrou que o sistema criado consegue diferenciar se a imagem em questão tem lesões malignas ou benignas, com base nas extrações das características visuais no modelo VGG16 que também podem ser usadas para classificações de vários tipos de imagens e não apenas de melanomas como é o seu foco. A utilização do cosseno de semelhança comprovada será útil na avaliação das características, permitindo uma análise confiável, onde a rapidez na detecção de melanomas pode ser garantida para o sucesso do tratamento e a sobrevivência dos pacientes.
O trabalho se destaca em um contexto de utilização de técnicas de aprendizado de máquina na área da saúde, contribuindo para aplicação redes neurais convolucionais pré-treinadas. Uma das principais vantagens do sistema criado, reside em sua habilidade de empregar uma máquina para executar de maneira ágil o planejamento de remoção de recursos, tarefa que seria demorada se realizada manualmente. Isso também torna uma opção econômica e viável para ser usada em ambientes clínicos com recursos limitados.
No entanto, uma desvantagem em relação a outros trabalhos existentes é a dependência do modelo VGG16 pré-treinado, que, embora eficaz, pode não capturar todas as nuances específicas de lesões cutâneas complexas que não estavam presentes no conjunto de dados original de treinamento. Além disso, a similaridade cosseno, enquanto útil, pode não ser a métrica ideal para todos os tipos de variações nas imagens, especialmente em casos em que as lesões apresentam características muito sutis e particulares.
O programa desenvolvido tem um potencial significativo para ser aplicado em ambientes clínicos como uma ferramenta de apoio ao diagnóstico. Ele pode ser integrado em fluxos de trabalho médicos para oferecer uma segunda opinião automatizada, ajudando médicos a tomar decisões mais estratégicas com base em análises. No entanto, para maximizar sua eficácia, recomenda-se um maior volume e variação do banco de dados de imagens ,incorporando uma quantidade maior de lesões e condições de pele para treinar e validar o modelo.
REFERÊNCIAS BIBLIOGRÁFICAS
ALPAYDIN, E. Machine Learning: The New AI. MIT Press, 2016. Acesso em: 17 abr. 2024.
BISHOP, C. M. Pattern Recognition and Machine Learning. Springer, 2006. Acesso em: 17 abr. 2024.
ESTEVA, A. et al. Dermatologist-level classification of skin cancer with deep neurais networks. Nature, v. 542, n. 7639, p. 115-118, 2017. https://doi.org/10.1038/nature21056 Acesso em: 25 maio. 2024.
FEMAMA. Diagnóstico precoce garante cura de 95% dos casos de câncer de mama. Disponível em:
https://www.febrasgo.org.br/pt/noticias/item/1511-diagnostico-precoce-garante-cura-de-95-dos-c asos-de-cancer-de-mama. Acesso em: 17 abr. 2024.
INCA. O crescimento dos casos de câncer no Brasil é preocupante. Disponível em:
https://www.dbmolecular.com.br/artigo/crescimento-dos-casos-de-cancer-no-brasil-e-preocupant e. Acesso em: 17 abr. 2024.
JINKU, Hu. Tutorial NumPy – Array Ndarray Multidimensional NumPy. DelftStack, 2021. Disponível em:https://www.delftstack.com/tutorial/python-numpy/numpy-ndarray/. Acesso em: 17 abr. 2024.
JORDAN, M. I.; MITCHELL, T. M. Machine learning: Trends, perspectives, and prospects. Science, v. 349, n. 6245, p. 255-260, 2015. Acesso em: 17 abr. 2024.
KRIZHEVSKY, A.; SUTSKEVER, I.; HINTON, G. E. ImageNet classification with deep convolutional neurais networks. Communications of the ACM, v. 60, n. 6, p. 84-90, 2012. https://doi.org/10.1145/3065386 Acesso em: 20 maio. 2024.
LeCUN, Y.; BENGIO, Y.; HINTON, G. Deep learning. Nature, v. 521, n. 7553, p. 436-444, 2015. https://doi.org/10.1038/nature14539 Acesso em: 25 maio. 2024.
MURPHY, K. P. Machine Learning: A Probabilistic Perspective. MIT Press, 2012. Acesso em: 17 abr. 2024.
RUSSELL, S.; NORVIG, P. Artificial Intelligence: A Modern Approach. 3rd ed. Pearson, 2016. Acesso em: 17 abr. 2024.
SIMONYAN, K.; ZISSERMAN, A. Very deep convolutional networks for large-scale image recognition. International Conference on Learning Representations (ICLR), 2015. Disponível em: http://arxiv.org/abs/1409.1556. Acesso em: 17 maio. 2024.
SZEGEDY, C. et al. Going deeper with convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), p. 1-9, 2015. https://doi.org/10.1109/CVPR.2015.7298594 Acesso em: 25 maio. 2024.
TURING, A. M. Computing machinery and intelligence. Mind, v. 59, n. 236, p. 433-460, 1950. Acesso em: 17 abr. 2024.
De Sa, J. R. C.; Borges, M. M. Inteligência Artificial: Aplicações e Impactos em Diversas Áreas. RSD Journal, v. 12, n. 5, p. 1-10, 2023. DOI: 10.33448/rsd.v12i5.40856. Acesso em: 26 set. 2024.
1Renan Oliveira de Carvalho. Graduando do Curso de Engenharia de computação da Universidade de Araraquara -UNIARA. Araraquara-SP. E-mail: renanocarvalho4@gmail.com ORCID : https://orcid.org/0009-0007-1299-0311
2João Henrique Gião Borges. Orientador. Docente do Curso de Engenharia de Computação e Sistemas de Informação da Universidade de Araraquara -UNIARA. Araraquara-SP. E-mail: jhgborges@uniara.edu.br ORCID : https://orcid.org/0000-0003-2909-7611
3André Luiz da Silva. Coorientador. Docente do Curso de Engenharia de Computação e Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: alsilva@uniara.edu.br ORCID: https://orcid.org/0000-0003-1646-1744
4Fabiana Florian. Coorientadora. Docente do Curso de Engenharia de Computação e Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: fflorian@uniara.edu.br ORCID: https://orcid.org/0000-0002-9341-0417