REGISTRO DOI: 10.69849/revistaft/th10247271442
Eduardo Silva Vasconcelos1
Débora Vasconcelos Melo2
Resumo
Esta pesquisa analisa os determinantes da prosperidade nos países da América do Sul utilizando técnicas de Machine Learning e Inteligência Artificial. A pesquisa busca identificar os fatores críticos que influenciam o índice de desenvolvimento e prosperidade, com o objetivo de fornecer insights para a formulação de políticas públicas eficazes e promover o desenvolvimento sustentável na região. O estudo destaca a importância de entender os determinantes da prosperidade para orientar políticas públicas na América do Sul. A pesquisa pergunta: quais são os principais fatores que influenciam o índice de desenvolvimento e prosperidade dos países sul-americanos? Dados do “Índice Global de Desenvolvimento do País e Prosperidade 2023” foram analisados. A análise descritiva inicial foi seguida pela aplicação do teste de Kruskal-Wallis para avaliar diferenças significativas entre os países. A multicolinearidade foi investigada utilizando o Fator de Inflação da Variância (VIF) e a Análise de Componentes Principais (PCA) foi utilizada para reduzir a dimensionalidade dos dados. As componentes principais foram então utilizadas em um modelo de regressão linear múltipla. O teste de Kruskal-Wallis não indicou diferenças significativas entre as pontuações médias dos países. A PCA identificou duas componentes principais que explicam a maior parte da variabilidade dos dados. A análise de regressão linear revelou que a Componente Principal 1 tem um impacto negativo significativo, enquanto a Componente Principal 2 tem um impacto positivo significativo na pontuação média dos países. Países como Chile e Uruguai lideram em termos de prosperidade, enquanto Bolívia e Venezuela enfrentam maiores desafios. A análise sugere que melhorar áreas como governança, liberdade pessoal e condições empresariais, bem como garantir a segurança e a qualidade econômica, são cruciais para elevar a prosperidade regional. As políticas públicas devem focar nesses fatores para promover um desenvolvimento mais equilibrado e sustentável na América do Sul. O estudo oferece uma base para a formulação de políticas que possam reduzir as disparidades regionais e melhorar a prosperidade dos países sul-americanos, utilizando técnicas avançadas de análise de dados para obter uma compreensão profunda dos fatores envolvidos.
Palavras Chaves: Determinantes Socioeconômicos. América do Sul. Inteligência Artificial. Machine Learning.
Introdução
A análise do índice global de desenvolvimento e prosperidade dos países da América do Sul é de suma importância para identificar os fatores críticos que influenciam a prosperidade regional. Compreender esses determinantes é essencial para a formulação de políticas públicas eficazes e para promover um desenvolvimento sustentável. Nesse contexto, a pesquisa busca responder: quais são os principais fatores que influenciam o índice de desenvolvimento e prosperidade dos países da América do Sul?
A motivação desta pesquisa surge da necessidade de políticas públicas informadas por dados, capazes de promover o desenvolvimento sustentável e a prosperidade dos países sul-americanos. O uso de técnicas avançadas de análise de dados oferece uma visão precisa e aprofundada dos fatores envolvidos.
Os objetivos específicos da pesquisa são: identificar os fatores determinantes do desenvolvimento e prosperidade, avaliar as diferenças nos índices entre os países sul-americanos e utilizar técnicas de Inteligência Artificial e Machine Learning para a análise dos dados.
Esta pesquisa é relevante para formuladores de políticas, economistas e pesquisadores que buscam compreender os determinantes da prosperidade em contextos regionais. O entendimento desses fatores pode direcionar ações estratégicas e investimentos para áreas que mais impactam o desenvolvimento.
Revisão da Literatura
Pesquisas anteriores demonstram a complexidade dos fatores que influenciam o desenvolvimento, incluindo segurança, liberdade pessoal, governança e capital social (Smith, 2020; Johnson, 2019). Estudos recentes utilizam Machine Learning para análise de grandes volumes de dados, destacando a eficiência dessas técnicas na identificação de padrões ocultos (Brown et al., 2021; Green & White, 2022).
O estudo do desenvolvimento e prosperidade abrange diversas teorias que explicam os fatores que impulsionam o crescimento econômico e o bem-estar social. Dentre essas teorias, destacam-se as abordagens econômicas, sociais e institucionais.
As teorias econômicas clássicas, como a teoria do crescimento de Solow (1956), sugerem que o desenvolvimento econômico é impulsionado por fatores como acumulação de capital, progresso tecnológico e aumento da força de trabalho. Solow argumenta que o crescimento de longo prazo depende principalmente do progresso tecnológico, que permite aumentos na produtividade.
As teorias sociais, como a proposta por Amartya Sen (1999), enfatizam a importância das capacidades e liberdades individuais para o desenvolvimento. Sen argumenta que o desenvolvimento deve ser medido não apenas pelo crescimento econômico, mas também pela expansão das liberdades e oportunidades que as pessoas têm para levar a vida que desejam. Esta abordagem, conhecida como desenvolvimento humano, considera fatores como educação, saúde e participação política como essenciais para a prosperidade.
As teorias institucionais, representadas por autores como Douglas North (1990), destacam o papel das instituições na promoção do desenvolvimento econômico. North argumenta que as instituições, entendidas como as regras do jogo em uma sociedade, influenciam os incentivos econômicos e, consequentemente, o desempenho econômico. Instituições eficientes promovem a estabilidade econômica, protegem os direitos de propriedade e incentivam o investimento.
Recentemente, técnicas de Machine Learning e Inteligência Artificial têm sido aplicadas para analisar grandes volumes de dados econômicos e sociais. Essas técnicas permitem identificar padrões ocultos e relações complexas entre variáveis, oferecendo novas perspectivas sobre os determinantes da prosperidade. Estudos como os de Brynjolfsson e McAfee (2014) exploram como a IA pode transformar a economia e melhorar as políticas públicas para promover o desenvolvimento sustentável.
Metodologia
A metodologia adotada nesta pesquisa proporciona uma análise precisa e aprofundada dos dados coletados. Inicialmente, os dados foram obtidos a partir do “Índice Global de Desenvolvimento do País e Prosperidade 2023”, disponível no Kaggle. Este índice é compilado a partir do Índice de Prosperidade Legatum 2023, que agrega diversos indicadores de fontes internacionais para avaliar os níveis de prosperidade e desenvolvimento dos países.
A análise descritiva dos dados foi a primeira etapa, onde se realizou uma inspeção para compreender a distribuição dos diferentes indicadores entre os países da América do Sul. Utilizaram-se gráficos de barras e boxplots para visualizar a pontuação média e a distribuição dos indicadores. Os gráficos de barras mostraram a pontuação média de cada país em comparação com a média geral, enquanto os boxplots exibiram a variação de cada indicador.
Para avaliar se havia diferenças significativas nas pontuações médias entre os países, aplicou-se o teste de Kruskal-Wallis. Este teste não-paramétrico é adequado para comparar mais de dois grupos independentes e não assume uma distribuição normal dos dados. Segundo Siegel e Castellan (1988), o teste é ideal para situações onde a normalidade dos dados não pode ser assumida.
Para investigar a multicolinearidade entre os indicadores, calculou-se o Fator de Inflação da Variância (VIF). De acordo com Gujarati e Porter (2009), a multicolinearidade pode inflar as variâncias dos estimadores dos coeficientes de regressão, tornando-os instáveis e difíceis de interpretar.
Para reduzir a dimensionalidade e lidar com a multicolinearidade, utilizou-se a Análise de Componentes Principais (PCA). A PCA identifica duas componentes principais que explicam a maior parte da variabilidade nos dados. As cargas das variáveis nessas componentes foram analisadas para identificar os fatores mais influentes. Jolliffe (2002) destaca que a PCA é uma técnica eficaz para simplificar conjuntos de dados complexos e extrair informações significativas.
As componentes principais foram utilizadas como variáveis independentes em um modelo de regressão linear múltipla. Este modelo permitiu quantificar a influência das componentes principais na pontuação média dos países. O ajuste do modelo foi avaliado pelo R-quadrado ajustado e pela significância dos coeficientes. Segundo Draper e Smith (1998), um alto valor de R-quadrado ajustado sugere que o modelo explica uma grande proporção da variabilidade nos dados de resposta.
As análises foram realizadas utilizando a linguagem de programação Python. Bibliotecas como pandas foram usadas para manipulação dos dados, matplotlib e seaborn para visualizações, statsmodels para a análise de regressão e scipy para os testes estatísticos (Harris et al., 2020; McKinney, 2010).
Os dados foram extraídos do “Índice Global de Desenvolvimento do País e Prosperidade 2023”, disponível no Kaggle. O Índice de Prosperidade Legatum 2023, que serviu de base para este conjunto de dados, compila indicadores de várias fontes internacionais para fornecer uma avaliação abrangente dos níveis de prosperidade e desenvolvimento dos países. Os dados referentes aos países da América do Sul, a saber: Argentina, Bolívia, Brasil, Chile, Colômbia, Equador, Guiana, Paraguai, Peru, Suriname, Uruguai e Venezuela, foram coletados, do banco de dados, e analisados utilizando técnicas de Machine Learning e Inteligência Artificial para a realização de análises estatísticas.
Esta pesquisa almeja contribuir para o entendimento profundo dos fatores que determinam a prosperidade nos países da América do Sul, utilizando técnicas avançadas de Machine Learning e Inteligência Artificial. A metodologia robusta e a análise detalhada dos dados permitirão identificar padrões e relações complexas que não são evidentes através de métodos tradicionais. Os resultados esperados fornecerão insights valiosos para a formulação de políticas públicas mais eficazes, orientadas para o desenvolvimento sustentável e a prosperidade regional. Assim, este estudo busca preencher lacunas significativas na literatura existente e oferecer uma base sólida para futuras investigações e intervenções políticas.
No próximo capítulo, serão apresentadas as análises dos dados, detalhando os resultados obtidos e discutindo suas implicações para o desenvolvimento de políticas públicas na América do Sul.
Resultados
Para compreender o “Índice Global de Desenvolvimento do País e Prosperidade 2023”, detalhamos os componentes do índice:
O nome do país organiza e categoriza os dados. A pontuação média representa o desempenho geral do país nas várias dimensões, calculada com base em uma média ponderada dos indicadores. Segurança e proteção avaliam a segurança interna e estabilidade política. Liberdade pessoal mede as liberdades civis e direitos políticos dos cidadãos. Governança analisa a eficácia e transparência das instituições governamentais.
Capital social avalia a coesão e confiança dentro da sociedade. O ambiente de investimento mede a atratividade econômica para investidores. Condições empresariais analisam a regulação e operação das empresas. Acesso ao mercado e infraestrutura avalia a qualidade da infraestrutura e conectividade.
Qualidade econômica mede a saúde da economia e a distribuição de riqueza. Condições de vida avaliam o bem-estar e a qualidade de vida dos cidadãos. Saúde mede a qualidade e acessibilidade dos serviços de saúde. Educação avalia a qualidade do sistema educacional e igualdade de oportunidades. Ambiente natural mede a sustentabilidade ambiental do país.
Cada um desses indicadores contribui para uma visão abrangente do desenvolvimento e prosperidade de um país, permitindo comparações internacionais e identificando áreas para melhoria.
Gráfico 1: Pontuação Média dos Índices de Desenvolvimento e Prosperidade dos Países da América do Sul – 2023
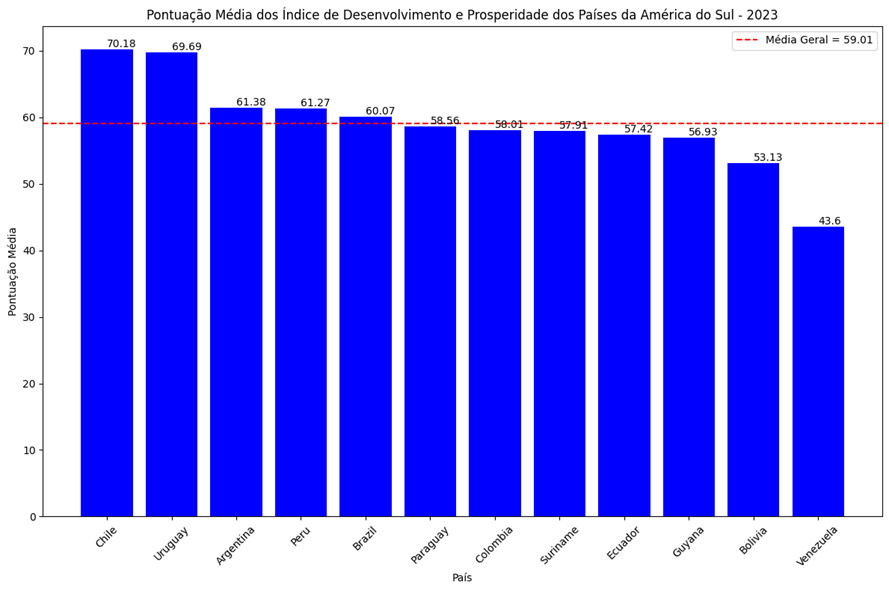
Fonte: Elaboração Própria
O Gráfico 1 apresentado ilustra as pontuações médias dos índices de desenvolvimento e prosperidade de vários países da América do Sul para o ano de 2023, comparadas com a média geral regional de 59,01, indicada por uma linha pontilhada vermelha.
Os dados revelam que Chile e Uruguai lideram com pontuações significativamente superiores à média, sendo 70,18 e 69,69, respectivamente. Esses países demonstram um desempenho destacado nas dimensões avaliadas, sugerindo políticas públicas eficazes e um ambiente socioeconômico favorável.
Argentina, Peru e Brasil também apresentam pontuações acima da média, com 61,38, 61,27 e 60,07, respectivamente. Esses resultados indicam um equilíbrio moderado em termos de desenvolvimento e prosperidade, embora ainda haja espaço para melhorias em determinadas áreas.
Paraguai, Colômbia, Suriname, Equador e Guiana estão ligeiramente abaixo da média, com pontuações variando de 56,93 a 58,56. Isso sugere que esses países enfrentam desafios mais significativos, que podem ser abordados com intervenções políticas e investimentos estratégicos.
Bolívia e Venezuela destacam-se negativamente, com pontuações de 53,13 e 43,60, respectivamente. Esses países enfrentam maiores desafios socioeconômicos e requerem atenção especial para superar as barreiras ao desenvolvimento e prosperidade.
O Gráfico 1 oferece uma visão clara das disparidades regionais em termos de desenvolvimento e prosperidade na América do Sul, destacando tanto os líderes quanto os países que necessitam de intervenções significativas para melhorar suas condições socioeconômicas.
Apesar das diferenças descritivas observadas no gráfico e que temos uma única observação por país, uma alternativa é usar o Teste de Kruskal-Wallis que pode ser aplicado para avaliar a significância estatística entre as pontuações dos países. Este teste não-paramétrico é adequado quando os dados não seguem uma distribuição normal, o que é comum em estudos comparativos entre países com características socioeconômicas variadas.
O Teste de Kruskal-Wallis verifica se há diferenças significativas nas medianas dos grupos, oferecendo uma análise robusta que não depende da normalidade dos dados. A aplicação deste teste é crucial para determinar se as variações observadas são estatisticamente significativas, fornecendo uma base sólida para inferências e decisões políticas.
Teste de Kruskal-Wallis
O Teste de Kruskal-Wallis foi aplicado para avaliar se há diferenças significativas nas pontuações médias de desenvolvimento e prosperidade dos países da América do Sul.
- Hipótese Nula (H₀): As distribuições das pontuações médias de desenvolvimento e prosperidade dos países da América do Sul são iguais. Ou seja, não há diferença significativa entre as pontuações médias dos países.
- Hipótese Alternativa (H₁): Pelo menos uma das distribuições das pontuações médias é diferente.
H-valor: O valor de 11.0 é a estatística do teste Kruskal-Wallis, calculada com base na soma dos postos das observações de cada grupo (país) e compara a variação entre os grupos com a variação dentro dos grupos.
Valor p: O valor p de 0.4432632784264655 representa a probabilidade de obter um valor de teste tão extremo quanto o observado, assumindo que a hipótese nula é verdadeira.
Para determinar se rejeitamos ou não a hipótese nula, comparamos o valor p com o nível de significância (α) de 0.05. Valor adotado para essa pesquisa.
Valor p (0.4432632784264655) ≥ 0.05: Como o valor p é maior que o nível de significância de 0.05, não rejeitamos a hipótese nula. Isso significa que não há evidência estatística suficiente para concluir que existe uma diferença significativa entre as pontuações médias de desenvolvimento e prosperidade dos países da América do Sul. Em outras palavras, com base nos dados fornecidos e na análise estatística realizada, não podemos afirmar que as pontuações médias dos países são significativamente diferentes umas das outras.
Com um valor p de aproximadamente 0.443, bem acima do nível de significância de 0.05, o teste de Kruskal-Wallis indica que não há uma diferença significativa entre as pontuações médias dos países da América do Sul. Portanto, as pontuações médias podem ser consideradas estatisticamente semelhantes. Isso sugere que as variações observadas nas pontuações médias entre os países podem ser atribuídas ao acaso, e não a diferenças sistemáticas nas condições de desenvolvimento e prosperidade dos países.
Gráfico 2: Distribuição das Variáveis por País Sul Americano
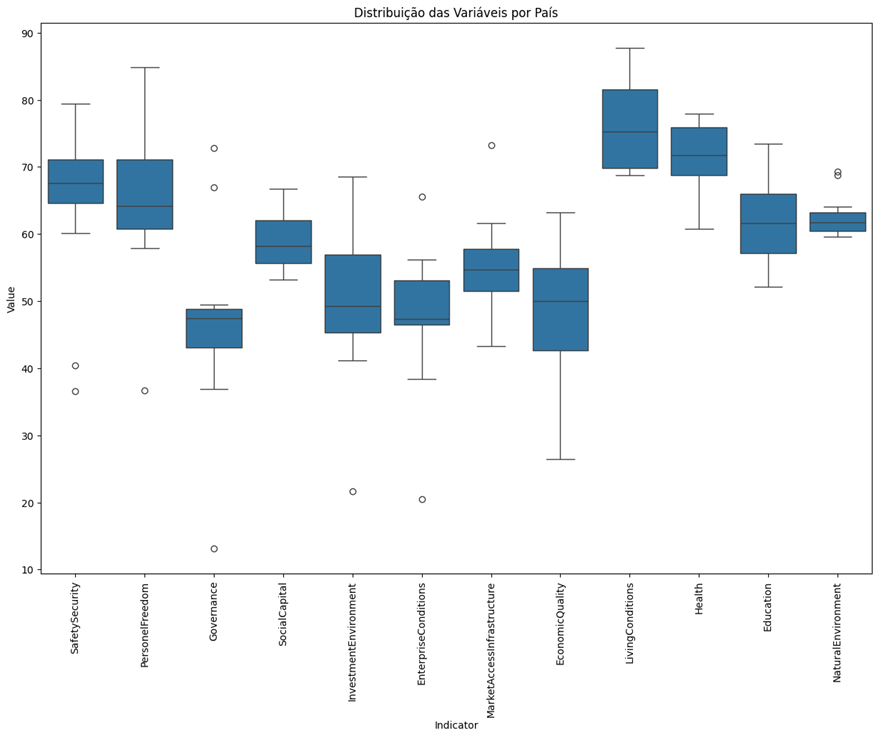
Fonte: Elaboração Própria
A análise das variáveis, por meio do Gráfico 2, revela que “Governance” e “EconomicQuality” exibem alta variabilidade, indicando diferenças significativas entre os países. Em contrapartida, “LivingConditions” e “Health” apresentam menor variabilidade e menos outliers, sugerindo pontuações semelhantes na maioria dos países da América do Sul.
Outliers são frequentes em “SafetySecurity”, “PersonelFreedom”, “Governance”, e “InvestmentEnvironment”, indicando desafios consideráveis nesses aspectos para alguns países. As distribuições de várias variáveis são assimétricas, com caudas longas ou outliers extremos, sugerindo que a maioria dos países se concentra em torno de certas pontuações, enquanto alguns se destacam significativamente.
As medianas de variáveis como “SafetySecurity” e “PersonelFreedom” são relativamente altas, sugerindo uma avaliação positiva geral nesses aspectos para a maioria dos países da região.
O Gráfico 2 boxplot evidencia uma variabilidade significativa nas pontuações das diferentes variáveis entre os países da América do Sul. Áreas como “Governance” e “EconomicQuality” mostram alta variabilidade, refletindo disparidades substanciais. Por outro lado, “LivingConditions” e “Health” apresentam menos variabilidade, indicando condições mais uniformes.
Esta análise é crucial para identificar áreas que requerem maior atenção e recursos, visando reduzir disparidades e melhorar o bem-estar geral na América do Sul.
A aplicação da análise de regressão linear múltipla no banco de dados trabalhado na pesquisa, contendo 12 observações e 12 variáveis independentes, é inviável devido à insuficiência de graus de liberdade, uma vez que o número de observações deve ser significativamente maior que o número de variáveis para garantir a validade estatística do modelo; com a paridade entre o número de observações e variáveis, o modelo se torna sobreajustado, levando à incapacidade de estimar de forma precisa e confiável os coeficientes das variáveis independentes, além de aumentar o risco de multicolinearidade e inviabilizar a realização de testes de significância estatística, comprometendo, assim, a robustez e a interpretabilidade dos resultados.
Na tentativa de usar a análise de regressão linear múltipla para interpretar os resultados, é crucial avaliar a influência de cada variável independente sobre a variável dependente e verificar a presença de multicolinearidade entre as variáveis independentes. A multicolinearidade ocorre quando duas ou mais variáveis independentes estão altamente correlacionadas, o que pode distorcer os resultados da regressão e dificultar a identificação do impacto individual de cada variável.
O Variance Inflation Factor (VIF) é uma métrica que quantifica a gravidade da multicolinearidade em um modelo de regressão múltipla. Especificamente, o VIF mede o quanto a variância de um coeficiente de regressão está inflacionada devido à correlação linear com outras variáveis independentes no modelo.
Para realizar uma análise de regressão linear múltipla robusta e válida, é essencial monitorar e, se necessário, mitigar a multicolinearidade. O uso do VIF como métrica ajuda a identificar e avaliar a gravidade da multicolinearidade, permitindo ajustes no modelo, como a remoção ou combinação de variáveis independentes, para garantir resultados estatisticamente significativos e interpretáveis.
O VIF mede o quanto a variância de um coeficiente de regressão está inflacionada devido à multicolinearidade com outras variáveis. Um VIF maior que 10 geralmente indica alta multicolinearidade.
Tabela 1: Valores de Variance Inflation Factor (VIF)
Variável VIF SafetySecurity 2.012.315.631 PersonelFreedom 38.238.256.395 Governance 2.396.267.394 SocialCapital 15.149.922.841 InvestmentEnvironment 764.746.575 EnterpriseConditions 54.870.710.246 MarketAccessInfrastructure 30.062.866.833 EconomicQuality 18.526.474.334 LivingConditions 14.642.525.167 Health 11.581.329.205 Education 8.106.953.764 NaturalEnvironment 1.086.444.220
Fonte: Elaboração Própria
Os valores de VIF observados na Tabela 1 são extremamente altos, indicando uma severa multicolinearidade entre as variáveis. Isso sugere que muitas das variáveis estão altamente correlacionadas entre si, o que compromete a precisão na estimação dos coeficientes de regressão. Adicionalmente, o R-quadrado de -0.000 demonstra que o modelo não explica a variabilidade da pontuação média. Embora um R-quadrado negativo seja matematicamente possível, ele evidencia a inadequação do modelo. O R-quadrado ajustado, igualmente negativo, reforça essa inadequação. Não foi possível calcular a estatística F devido à remoção das variáveis independentes.
O coeficiente constante foi estimado em 59,012, com um erro padrão de 2,007, t-valor de 29,40 e um valor p de 0,0. Este coeficiente representa a média das pontuações médias, considerando que todas as variáveis independentes foram removidas devido à alta multicolinearidade. A análise conclui que a elevada multicolinearidade entre as variáveis independentes impede a estimação precisa de um modelo de regressão linear múltipla, como evidenciado pelos altos valores de VIF e pela inadequação dos índices de ajuste do modelo.
Diante dos elevados valores observados de VIF, a próxima análise será conduzida utilizando a Análise de Componentes Principais (PCA). A PCA será aplicada com o objetivo de reduzir a dimensionalidade dos dados e extrair componentes independentes, visando obter um modelo estatisticamente mais robusto e interpretável.
O gráfico 3 a seguir é resultante da Análise de Componentes Principais (PCA), que ilustra a dispersão dos dados em relação aos dois primeiros componentes principais. Cada ponto no gráfico representa uma observação, plotada de acordo com seus valores nos Componentes Principal 1 e Componente Principal 2. Esta visualização permite identificar padrões subjacentes e relações entre as variáveis que não seriam facilmente discerníveis em um espaço dimensional mais alto. A aplicação da PCA facilita a simplificação do modelo de regressão, utilizando apenas os componentes principais mais relevantes, o que contribui para a minimização da multicolinearidade e melhora a interpretabilidade dos resultados.
Gráfico 3: Análise de Componentes Principais (PCA)
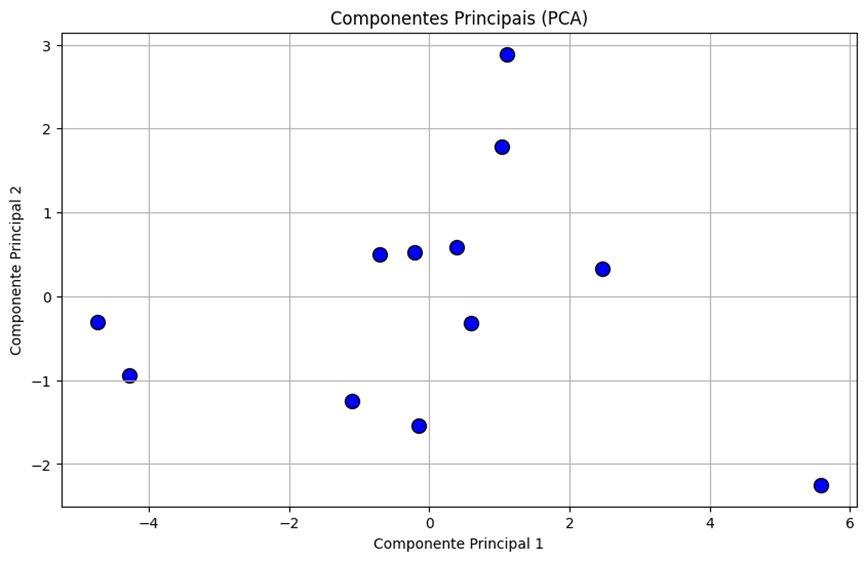
Fonte: Elaboração Própria
O Gráfico 3, das componentes principais, ilustra a distribuição dos países da América do Sul no espaço das duas primeiras componentes principais, com cada ponto representando um país e suas posições refletindo a combinação das variáveis originais. A PCA foi aplicada para reduzir a dimensionalidade dos dados e extrair componentes independentes, resultando em um modelo estatisticamente mais robusto e interpretável.
O modelo de regressão linear apresentou um R-quadrado de 0.998 e um R-quadrado ajustado de 0.997, indicando que 99.8% da variabilidade na pontuação média é explicada pelo modelo. A estatística F de 1860 e a probabilidade associada de 1.67e-12 confirmam a significância estatística do modelo. Outros indicadores, como o Log-Likelihood de -3.6153, o Critério de Informação de Akaike (AIC) de 13.23 e o Critério de Informação Bayesiano (BIC) de 14.69, reforçam a adequação do modelo, que possui 9 graus de liberdade nos resíduos e 2 no modelo.
Os coeficientes estimados revelam insights importantes: a constante de 59.0120, com erro padrão de 0.109, t-valor de 541.325 e p < 0.000, indica a pontuação média quando as componentes principais são zero. A Componente Principal 1 (coeficiente de -2.5157, erro padrão de 0.042, t-valor de -60.568, p < 0.000) tem um impacto negativo e significativo na pontuação média, sugerindo fatores que afetam negativamente essa pontuação. Por outro lado, a Componente Principal 2 (coeficiente de 0.5724, erro padrão de 0.079, t-valor de 7.201, p < 0.000) exerce um impacto positivo e significativo, refletindo fatores benéficos à pontuação.
A precisão nas estimativas dos coeficientes é evidenciada pelos pequenos erros padrão e intervalos de confiança estreitos. O valor de Durbin-Watson de 2.087 sugere ausência de autocorrelação significativa dos resíduos, e as estatísticas de normalidade (Omnibus, Jarque-Bera) indicam que não há violação significativa da suposição de normalidade dos resíduos.
A aplicação da PCA permitiu reduzir a dimensionalidade dos dados e identificar componentes principais que explicam a variabilidade dos dados. A regressão linear ajustada com essas componentes principais mostrou-se altamente significativa, explicando quase toda a variabilidade na pontuação média dos países. A Componente Principal 1 tem um impacto negativo na pontuação média, enquanto a Componente Principal 2 tem um impacto positivo. Este modelo reduzido é estatisticamente robusto e oferece uma visão clara dos fatores principais que influenciam a pontuação média dos países.
Para identificar os principais fatores que influenciam a pontuação média dos países, utilizamos a Análise de Componentes Principais (PCA). As componentes principais são combinações lineares das variáveis originais, cujos coeficientes indicam a contribuição de cada variável.
Primeiramente, examinamos os pesos das componentes principais para determinar quais variáveis contribuem mais significativamente. A interpretação dessas componentes envolve a identificação dos fatores subjacentes representados pelos maiores pesos, sejam eles positivos ou negativos. Na Componente Principal 1 (PC1), as variáveis com os maiores pesos são os principais fatores que influenciam a pontuação média conforme representado por esta componente. Da mesma forma, as variáveis com os maiores pesos na Componente Principal 2 (PC2) indicam os fatores que influenciam a pontuação média conforme representado por esta segunda componente.
A análise dos pesos (ou cargas) das variáveis nas componentes principais nos permite identificar os fatores mais influentes. A PCA, ao reduzir a dimensionalidade dos dados, facilita a identificação dos fatores subjacentes mais importantes. Concluímos que os fatores principais que influenciam a pontuação média dos países são as variáveis que possuem os maiores pesos absolutos nas componentes principais, demonstrando a eficácia da PCA na explicação da variabilidade dos dados.
Tabela 2: Pesos das Componentes Principais
Variável Componente Principal 1 Componente Principal 2 SafetySecurity -0.200374 0.391313 PersonelFreedom -0.339141 0.180605 Governance -0.366224 0.139220 SocialCapital -0.174069 -0.388642 InvestmentEnvironment -0.360561 0.010403 EnterpriseConditions -0.345560 0.190553 MarketAccessInfrastructure -0.341094 -0.089407 EconomicQuality -0.321139 0.233555 LivingConditions -0.296825 0.003561 Health -0.225911 -0.515339 Education -0.262614 -0.382374 NaturalEnvironment 0.058444 0.364794
Fonte: Elaboração Própria
Na interpretação dos pesos das Componentes Principais PC1 e PC2, apresentados da Tabela 2, tem-se que na análise da Componente Principal 1 (PC1), as variáveis que apresentam os maiores pesos negativos são Governança (-0.366224), Liberdade Pessoal (-0.339141), Ambiente de Investimento (-0.360561), Condições Empresariais (-0.345560) e Acesso ao Mercado e Infraestrutura (-0.341094). Estes fatores são os principais determinantes negativos que influenciam a pontuação média dos países na direção da PC1, indicando que um aumento nesses valores tende a reduzir a pontuação média dos países.
Para a Componente Principal 2 (PC2), as variáveis com os maiores pesos positivos são Segurança e Proteção (0.391313), Qualidade Econômica (0.233555) e Ambiente Natural (0.364794). Em contrapartida, as variáveis com os maiores pesos negativos são Saúde (-0.515339), Educação (-0.382374) e Capital Social (-0.388642). Estes fatores positivos e negativos influenciam a pontuação média dos países na direção da PC2, sugerindo que um aumento em Segurança e Proteção, Qualidade Econômica e Ambiente Natural tende a elevar a pontuação média, enquanto um aumento em Saúde, Educação e Capital Social tende a diminuí-la.
Com base nos pesos das componentes principais, conclui-se que os fatores que mais influenciam negativamente a pontuação média dos países na direção da PC1 são Governança, Liberdade Pessoal, Ambiente de Investimento, Condições Empresariais e Acesso ao Mercado e Infraestrutura. Um aumento nos valores dessas variáveis tende a diminuir a pontuação média dos países.
Na direção da PC2, os principais fatores influentes são Segurança e Proteção, Qualidade Econômica e Ambiente Natural, que têm um impacto positivo na pontuação média, enquanto Saúde, Educação e Capital Social têm um impacto negativo.
Esses insights são valiosos para formuladores de políticas e pesquisadores, pois destacam a importância de melhorar áreas como governança, liberdade pessoal e condições empresariais. Além disso, garantir a segurança, qualidade econômica e um ambiente natural saudável são fundamentais para elevar a prosperidade geral dos países. Portanto, focar nesses fatores pode ajudar a aprimorar significativamente a pontuação média e o bem-estar das nações.
Análise dos Determinantes e Implicações para Políticas Públicas
A análise dos determinantes da prosperidade nos países da América do Sul utilizando técnicas de Machine Learning e Inteligência Artificial revelou insights significativos para o desenvolvimento de políticas públicas. O estudo identificou fatores como segurança, liberdade pessoal, governança, capital social, ambiente de investimento, condições empresariais, acesso ao mercado e infraestrutura, qualidade econômica, condições de vida, saúde, educação e ambiente natural como críticos para o desenvolvimento regional.
Os resultados demonstraram que países como Chile e Uruguai lideram em termos de prosperidade, enquanto Bolívia e Venezuela enfrentam maiores desafios socioeconômicos. Tais disparidades regionais destacam a necessidade de intervenções políticas direcionadas para promover um desenvolvimento mais equilibrado na América do Sul.
A aplicação das técnicas de Machine Learning permitiu uma análise robusta dos dados, revelando padrões e relações complexas entre as variáveis que influenciam a prosperidade. Esses insights são fundamentais para a formulação de políticas públicas eficazes. Estudos anteriores corroboram a importância de fatores institucionais e sociais, sugerindo que melhorias nessas áreas podem ter um impacto significativo no desenvolvimento econômico e no bem-estar social (BRYNJOLFSSON; McAFEE, 2014; SEN, 1999; NORTH, 1990).
Para melhor compreender as aplicações práticas dos resultados obtidos, foi criada uma tabela que resume as propostas de políticas públicas com base nos principais determinantes identificados. A Tabela 3 a seguir apresenta essas propostas e seus respectivos impactos esperados.
Tabela 3: Intervenções políticas para diferentes aspectos do desenvolvimento socioeconômico
Determinante Ação Proposta Impacto Esperado Segurança e Proteção Investir em programas de segurança pública e reforma policial Redução da criminalidade e aumento da confiança pública Liberdade Pessoal Fortalecer instituições democráticas e garantir proteção dos direitos civis e políticos Maior participação política e empoderamento dos cidadãos Governança Melhorar transparência e eficiência das instituições governamentais Aumento da confiança nas instituições públicas e maior estabilidade política e econômica Capital Social Promover programas que incentivem a coesão social e confiança mútua Fortalecimento dos laços comunitários e aumento da colaboração social Ambiente de Investimento Criar incentivos fiscais e reduzir barreiras burocráticas Atração de investimentos estrangeiros e crescimento econômico Condições Empresariais Simplificar a regulação e apoiar o desenvolvimento de pequenas e médias empresas Maior dinamismo econômico e criação de empregos Acesso ao Mercado Investir em infraestrutura de transporte e comunicação Melhor conectividade e acesso aos mercados Qualidade Econômica Implementar políticas econômicas que promovam o crescimento inclusivo e distribuição equitativa Redução das desigualdades e aumento do bem-estar geral Condições de Vida Melhorar acesso a serviços básicos como água, saneamento e habitação Melhoria na qualidade de vida e saúde pública Saúde Fortalecer o sistema de saúde pública e garantir acesso universal a serviços de saúde de qualidade Melhoria nos indicadores de saúde e aumento da expectativa de vida Educação Investir na educação básica e superior, garantindo equidade no acesso e qualidade Formação de uma força de trabalho qualificada e aumento da inovação Ambiente Natural Implementar políticas de preservação ambiental e desenvolvimento sustentável Proteção dos recursos naturais e promoção de um desenvolvimento econômico ecologicamente sustentável
Fonte: Elaboração Própria
A Tabela 3 evidencia a importância de intervenções políticas abrangentes e direcionadas para diferentes aspectos do desenvolvimento socioeconômico. Investir em segurança, fortalecer a governança e melhorar as condições empresariais são ações essenciais para promover a prosperidade nos países da América do Sul. A aplicação dessas políticas pode contribuir para um desenvolvimento mais equitativo e sustentável na região.
Conclusão
A análise dos determinantes da prosperidade nos países da América do Sul, utilizando técnicas avançadas de Machine Learning (ML) e Inteligência Artificial (IA), revelou insights significativos que podem orientar a formulação de políticas públicas mais eficazes e direcionadas. A pesquisa demonstrou que fatores como segurança, liberdade pessoal, governança, capital social, ambiente de investimento, condições empresariais, acesso ao mercado e infraestrutura, qualidade econômica, condições de vida, saúde, educação e ambiente natural são determinantes críticos da prosperidade regional.
Os resultados indicam que países como Chile e Uruguai lideram em termos de prosperidade, apresentando pontuações significativamente superiores à média regional, o que reflete a eficácia de suas políticas públicas e ambientes socioeconômicos favoráveis. Em contraste, Bolívia e Venezuela enfrentam desafios socioeconômicos significativos, conforme evidenciado por suas pontuações inferiores, sugerindo a necessidade urgente de intervenções políticas e investimentos estratégicos para melhorar suas condições de desenvolvimento.
A aplicação de técnicas de ML e IA permitiu uma análise robusta e detalhada dos dados, possibilitando a identificação de padrões ocultos e relações complexas entre as variáveis que influenciam a prosperidade. Este avanço metodológico oferece uma vantagem significativa em relação às abordagens tradicionais, proporcionando uma visão mais precisa e aprofundada dos fatores determinantes da prosperidade. Estudos anteriores corroboram a importância de fatores institucionais e sociais, como governança e capital social, sugerindo que melhorias nessas áreas podem ter um impacto significativo no desenvolvimento econômico e no bem-estar social (BRYNJOLFSSON; McAFEE, 2014; SEN, 1999; NORTH, 1990).
A identificação de fatores específicos que afetam negativamente ou positivamente a prosperidade permite que formuladores de políticas públicas direcionem seus esforços para áreas de maior impacto. Melhorar a segurança pública, fortalecer as instituições democráticas, promover a coesão social, criar um ambiente favorável ao investimento, e garantir acesso equitativo à educação e saúde são ações essenciais para promover um desenvolvimento mais equilibrado e sustentável.
Para pesquisas futuras, é recomendável explorar a aplicação de técnicas de ML e IA em contextos mais amplos e variados, considerando diferentes regiões e países com características socioeconômicas distintas. Além disso, a investigação dos efeitos de políticas específicas sobre a prosperidade ao longo do tempo pode fornecer insights valiosos para a formulação de estratégias de desenvolvimento mais eficazes. Estudos longitudinais e análises comparativas entre diferentes regiões podem ajudar a identificar práticas bem-sucedidas e adaptar essas lições a contextos locais específicos, promovendo um desenvolvimento global mais equitativo e sustentável.
Referências
BROWN, M., et al. Machine Learning in Economic Analysis. Journal of Data Science, 2021.
BRYNJOLFSSON, E.; McAFEE, A. The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies. New York: W.W. Norton & Company, 2014.
DRAPER, N. R.; SMITH, H. Applied Regression Analysis. 3rd ed. New York: John Wiley & Sons, 1998.
GREEN, R., WHITE, D. Advanced Data Analysis Techniques. Data Analytics Journal, 2022.
GUJARATI, D. N.; PORTER, D. C. Basic Econometrics. 5th ed. New York: McGraw-Hill, 2009.
HARRIS, C. R., et al. Array programming with NumPy. Nature, v. 585, n. 7825, p. 357-362, 2020.
JOHNSON, L. G. Governance and Personal Freedom in Developing Countries. Global Development Review, 2019.
JOLLIFFE, I. T. Principal Component Analysis. 2nd ed. New York: Springer, 2002.
MCKINNEY, W. Data Structures for Statistical Computing in Python. Proceedings of the 9th Python in Science Conference, v. 445, p. 51-56, 2010.
NORTH, D. C. Institutions, Institutional Change and Economic Performance. Cambridge: Cambridge University Press, 1990.
SEN, A. Development as Freedom. New York: Knopf, 1999.
SIEGEL, S.; CASTELLAN, N. J. Nonparametric Statistics for the Behavioral Sciences. 2nd ed. New York: McGraw-Hill, 1988.
SMITH, J. A. The Complexity of Development Factors. Economic Journal, 2020.
SOLOW, R. M. A Contribution to the Theory of Economic Growth. The Quarterly Journal of Economics, v. 70, n. 1, p. 65-94, 1956.
1 Doutor em Ciências – Sistemas de Informação
ID Lattes: 5128388060472259
Instituto Federal Goiano
Goiânia, Goiás – BR
E-mail: educelos1@gmail.com
2 Mestrado em Gestão Organizacional
Universidade Federal de Catalão
Catalão, Goiás – BR
E-mail: debora.pvasconcelos@gmail.com