USE OF UNSUOERVISED NEURAL NETWORKS TO DETECT ANOMALIES IN FINANCIAL DATA
REGISTRO DOI: 10.5281/zenodo.10116449
Wallace Visicato Sinatra¹
Felipe Diniz Dallilo²
Fabiana Florian³
RESUMO
As redes neurais são um sistema computacional inspirado na estrutura do cérebro humano, capaz de aprender com dados e tomar decisões. Elas são utilizadas para tarefas complexas como reconhecimento de padrões e automação. Redes neurais não supervisionadas são utilizadas para detectar anomalias em um conjunto de dados financeiros. Esta detecção desempenha um papel vital na identificação de problemas, fraudes e oportunidades em finanças. A pesquisa destaca a utilidade das redes neurais não supervisionadas na detecção de anomalias em dados financeiros, reconhecendo suas vantagens e limitações. A pesquisa foi realizada em ambiente computacional, utilizando a linguagem de programação Python e diversas bibliotecas, incluindo Pandas, NumPy, Matplotlib, TensorFlow e Scikit-learn. Os dados financeiros foram armazenados em um banco de dados MySQL e passaram por pré-processamento e análise por meio dessas ferramentas. Os resultados demonstraram progressos significativos na detecção de anomalias em dados financeiros, proporcionando uma abordagem eficaz e prática. As técnicas utilizadas também demonstraram sua aplicabilidade em situações da vida real.
Palavras-chave: Redes Neurais, Anomalias, Finanças, Detecção, Dados financeiros.
ABSTRACT
Neural networks are a computational system inspired by the structure of the human brain, capable of learning from data and making decisions. They are used for complex tasks such as pattern recognition and automation. Unsupervised neural networks are used to detect anomalies in a set of financial data. This detection plays a vital role in identifying problems, frauds and opportunities in finance. The research highlights the usefulness of unsupervised neural networks in detecting anomalies in financial data, recognizing their advantages and limitations. The research was carried out in a computational environment, using the Python programming language and several libraries, including Pandas, NumPy, Matplotlib, TensorFlow and Scikit-learn. The financial data was stored in a MySQL database and underwent pre-processing and analysis using these tools. The results demonstrated significant progress in detecting anomalies in financial data, providing an effective and practical approach. The techniques used also demonstrated their applicability in real-life situations.
Keywords: Neural Networks, Anomalies, Finance, Detection, Financial Data.
1. INTRODUÇÃO
O aprendizado não supervisionado é um método de aprendizagem de máquina na qual o algoritmo processa dados não rotulados para identificar padrões, estruturas ou agrupamentos intrínsecos, nos dados sem orientação externa por meio de rótulos ou respostas conhecidas. Ao contrário das redes neurais supervisionadas, onde o modelo recebe a entrada e o resultado desejado para a aprendizagem, a aprendizagem não supervisionada permite que a máquina aprenda e extraia informações uteis automaticamente. Segundo a instituição TIBCO (TIBCO, s.d.) isso se torna útil para explorar dados desconhecidos e analisar grandes conjuntos de dados para melhor compreensão, tornando-se uma técnica essencial em campos como reconhecimento de padrões.
As Redes Neurais não supervisionadas trazem uma alternativa eficiente para o aprendizado de máquinas em determinadas tarefas onde não irá pedir rotulagem de dados de treinamento. Com a capacidade de identificar padrões e fazer agrupamento de dados, fica mais fácil realizar uma análise de dados até segmentação de imagens (PASSOS, 2021).
O objetivo deste trabalho é utilizar redes neurais não supervisionadas para a detecção de anomalias em um conjunto de dados financeiros e alcançar um resultado em que seja possível realizar uma análise. Segundo Barnes e Shepherd (2010) a detecção de anomalias é crucial em diferentes áreas, como finanças, segurança ou saúde, e pode ajudar a identificar comportamentos atípicos em um conjunto de dados. Na área de finanças a pesquisa tem por finalidade identificar padrões e tendências nos dados, o que pode ajudar a tomar decisões mais informadas com base nessas informações.
Redes neurais não supervisionadas é um assunto de grande interesse na área de aprendizado de máquina. Esse tipo de rede abordado por Soares et al. (2002), têm sido amplamente utilizadas em aplicações como análise de dados, reconhecimento de padrões, segmentação de imagem e detecção de anomalias. A detecção de anomalias, em particular, é um problema importante em muitas áreas, como detecção de fraudes em cartões de crédito, segurança de redes e diagnóstico médico.
A utilização de redes neurais não supervisionadas para a detecção de anomalias em dados tem sido amplamente explorada na literatura. Soares; Azevedo; Carvalho (2019), discutem diferentes métodos de detecção de anomalias baseados em redes neurais não supervisionadas e mostram resultados promissores. Além disso, esses estudos destacam a importância da detecção de anomalias em diferentes áreas e a necessidade de desenvolver métodos eficazes e eficientes para lidar com esse problema. Portanto, esta pesquisa tem como objetivo contribuir para o avanço do conhecimento nessa área e fornecer uma solução inovadora para a detecção de anomalias em dados.
Embora a detecção de anomalias utilizando redes neurais não supervisionadas tenha sido amplamente explorada na literatura, ainda há desafios a serem enfrentados. Segundo a organização Alteryz (Alteryz, 2023), uma das principais desvantagens é encontrar um método eficiente para detectar anomalias em grandes volumes de dados. Pois a precisão da detecção pode ser afetada pela presença de ruídos nos dados. Portanto, o problema que esta pesquisa se propõe a abordar: é possível utilizar redes neurais não supervisionadas para a detecção eficiente e precisa de anomalias em grandes volumes de dados com ruídos?
A hipótese desta pesquisa é que a utilização de redes neurais não supervisionadas pode ser uma abordagem eficaz na detecção de anomalias em grandes volumes de dados com alta precisão e eficiência. As redes neurais não supervisionadas, são capazes de detectar padrões em um conjunto de dados sem a necessidade de rotulação prévia, podem ser treinadas para identificar anomalias que não se encaixam nesses padrões. Além disso, a seleção adequada dos parâmetros da rede, como a taxa de aprendizado e o número de neurônios na camada oculta, pode melhorar a eficiência e precisão da detecção.
Foi realizada a pesquisa descritiva qualitativa e bibliográfica com o objetivo de detecção de anomalias. As etapas da pesquisa foram:
- Preparação dos dados: nesta etapa, foram coletados os dados relevantes para a análise e eles serão preparados para a utilização no estudo. Para isso, será utilizado o MySQL para armazenamento dos dados.
- Pré-processamento dos dados: nesta etapa, foram realizadas algumas etapas básicas de pré-processamento dos dados, como remoção de valores nulos e normalização dos dados. Isso pode ser feito utilizando as bibliotecas Pandas e NumPy em Python.
- Implementação do modelo de clusterização: nesta etapa, foram implementado o modelo de clusterização utilizando o algoritmo de k-means, que é uma técnica não supervisionada. Para isso, foi utilizado a biblioteca Scikit-learn em Python.
- Avaliação de desempenho: após a implementação do modelo, foram avaliado seu desempenho utilizando métricas como a distância intra-cluster e inter-cluster. Também foi realizada uma análise visual dos clusters gerados e para trazer uma compressão mais intuitiva foi utilizado a biblioteca Matlabplot.
- Análise e interpretação dos resultados: nesta etapa, foram analisados e interpretados os resultados obtidos pelo modelo de clusterização. Foi verificado se as anomalias foram detectadas corretamente e se os clusters gerados estão de acordo com o esperado.
A pesquisa foi realizada em ambiente computacional, utilizando a linguagem de programação Python e diversas bibliotecas, incluindo Pandas, NumPy, Matplotlib, TensorFlow e Scikit-learn.
2. REVISAO BIBLIOGRAFICA
No âmbito deste artigo foram exploradas diversas ferramentas seja para a programação, para editores de texto e para bases de dados, cada uma com suas características e aplicabilidades específicas. Para o desenvolvimento e execução da análise de dados foi necessário um embasamento teórico na linguagem de programação Python, juntamente com as bibliotecas Pandas, NumPy, Cluster, K-means, Scikit-learn, Tensorflow e Matlabplot, que oferecem recursos avançados para a clusterização de dados e o banco de dados MySQL, escolhido como plataforma de armazenamento e gerenciamento dos conjuntos de dados.
2.1. PYTHON
A aplicação foi desenvolvida em Python, uma linguagem de programação amplamente utilizada na comunidade de desenvolvimento. Python tem uma história rica que remonta ao final dos anos 1980, quando foi concebido por Guido van Rossum, um programador holandês. Inicialmente, Van Rossum projetou Python como um sucessor da linguagem ABC, com o objetivo de criar uma linguagem de programação que fosse fácil de ler e escrever. O nome “Python” foi inspirado no programa de televisão britânico “Monty Python’s Flying Circus,” refletindo o desejo de tornar a linguagem divertida e amigável para os desenvolvedores.
Ao longo do tempo, Python ganhou reconhecimento e popularidade graças à sua simplicidade, legibilidade e abordagem prática. A comunidade Python cresceu rapidamente, contribuindo para a criação de uma ampla variedade de bibliotecas e frameworks que tornam a linguagem adequada para tarefas variadas, desde desenvolvimento web e automação até análise de dados e aprendizado de máquina.
Sua popularidade é atribuída à sua versatilidade e facilidade de uso em diferentes sistemas operacionais, como Windows, Linux e MacOS. Além disso, Python é uma linguagem de código aberto, o que significa que a comunidade pode contribuir e melhorar constantemente sua funcionalidade. Sua história de desenvolvimento, aliada à dedicação contínua da comunidade, faz de Python uma escolha sólida para a construção de aplicações em uma variedade de domínios, incluindo diversas funcionalidades (CAEULUM, 2023).
2.2. PANDAS
No contexto de aprendizagem não supervisionada, a biblioteca Pandas desempenha um papel importante no fornecimento de recursos eficientes para manipulação e análise de dados. Por meio de suas estruturas e funções de dados, o Pandas permite a descoberta de padrões e estruturas ocultas em dados não rotulados. Isso é especialmente útil em tarefas como reconhecimento de padrões, segmentação de dados e detecção de anomalias.
O Pandas fornece um recurso básico chamado “DataFrame”, que é uma estrutura de dados tabular bidimensional que consiste em colunas e linhas. Cada coluna do DataFrame representa uma variável ou recurso, enquanto cada linha corresponde a uma versão dos dados. Essa estrutura de dados é extremamente poderosa para análise de dados porque permite a manipulação flexível e eficiente das informações. Um dos principais benefícios do Pandas é a capacidade de indexar e filtrar dados facilmente, permitindo que os analistas de dados selecionem conjuntos relevantes de informações para análises específicas. Além disso, o Pandas fornece funções para realizar operações de agregação e transformação de dados, simplificando tarefas comuns de limpeza e pré-processamento de informações.
A arquitetura de dados do Pandas é flexível e poderosa para tarefas de análise de dados, desde a exploração inicial até a construção de modelos de aprendizagem não supervisionada. A combinação de recursos de manipulação e visualização de dados faz o Pandas uma escolha fundamental para profissionais que trabalha com dados não rotulados, e seu uso é essencial na detecção de anomalias e também reconhecimentos de padrões ocultos e segmentação de informações (ALURA, s.d.).
2.3. NUMPY
A biblioteca NumPy desempenha um papel central no cenário do aprendizado não supervisionado, fornecendo recursos importantes para a manipulação de dados digitais em vários campos, incluindo ciência de dados, engenharia e pesquisa. Idealizada em 2005 pelo cientista de dados Travis Oliphant, com o nome de Numerical Python, essa biblioteca representa uma verdadeira revolução no campo da computação científica. NumPy oferece uma plataforma flexível e poderosa para realizar cálculos matemáticos complexos de maneira eficiente, aproveitando matrizes multidimensionais.
Um aspecto notável do NumPy é sua capacidade de trabalhar com matrizes multidimensionais, permitindo eficiência em cálculos. Isso é fundamental para tarefas de pré-processamento de dados, como normalização e padronização. Além disso, o NumPy oferece suporte a operações matemáticas avançadas, incluindo álgebra linear e manipulação de matrizes, tornando-o uma ferramenta essencial na implementação de algoritmos de aprendizagem não supervisionados.
A eficiência computacional e a variedade de funções disponíveis no NumPy desempenham um papel fundamental no processamento de grandes conjuntos de dados. É amplamente utilizado na área de ciência de dados e serve como base para o desenvolvimento de diversas outras bibliotecas. Adicionalmente, o NumPy teve um papel crucial em importantes avanços científicos recentes, incluindo a captura da primeira imagem de um buraco negro e a detecção de ondas gravitacionais. (ALURA, s.d.).
2.4. CLUSTER
Os modelos de agrupamento desempenham um papel fundamental no aprendizado não supervisionado, permitindo identificar e agrupar conjuntos de dados similares em clusters distintos. Essa técnica é amplamente aplicada em várias áreas, como análise de dados, mineração de dados e reconhecimento de padrões. No contexto deste artigo, o uso do agrupamento será explorado como uma abordagem para identificar e analisar grupos de dados não rotulados, contribuindo para uma melhor compreensão dos padrões e estruturas presentes nos dados. Ao aplicar algoritmos de agrupamento, como o k-means, é possível segmentar os dados em grupos distintos, proporcionando insights valiosos sobre a natureza e a distribuição dos dados, mesmo na ausência de rótulos ou classes pré-definidas. (DATACAMP, s.d.).
2.5. K-MEANS
O método de agrupamento k-means é uma técnica de aprendizado de máquina não supervisionado amplamente utilizada na análise exploratória de dados. Neste contexto, o objetivo é identificar grupos ou clusters de objetos em um conjunto de dados sem a necessidade de rótulos ou informações prévias. k-means é um dos métodos mais antigos e acessíveis para realizar clustering, tornando-o uma escolha popular entre programadores e cientistas de dados, mesmo aqueles com pouca experiência.
A simplicidade e facilidade de implementação do Python contribuem para sua ampla adoção, permitindo que especialistas realizem análises exploratórias eficazes em seus projetos de pesquisa. Utilizando k-means, é possível dividir os dados em grupos distintos, facilitando a compreensão dos padrões e estruturas presentes no conjunto de dados sem a necessidade de informações prévias sobre os objetos. Isso torna o método valioso para análise exploratória de dados em diversos campos, como ciências sociais, biologia, economia e muitos outros. (REALPYTHON, s.d.).
2.6. SCIKIT-LEARM
Scikit-learn é uma biblioteca de aprendizado de máquina Python conhecida por sua abordagem gratuita e de código aberto. Com diversos recursos e funcionalidades, esta biblioteca se destaca como uma poderosa ferramenta para modelagem estatística, análise de dados e mineração de informações. Um de seus maiores benefícios é o suporte ao aprendizado supervisionado e não supervisionado. Isso torna o Scikit-learn uma escolha flexível para cientistas de dados e desenvolvedores que desejam aplicar técnicas de aprendizado de máquina em seus projetos.
O Scikit-learn também se destaca pela interface intuitiva e documentação abrangente. Isso simplifica o desenvolvimento de modelos de aprendizado de máquina, permitindo que até mesmo iniciantes implementem facilmente algoritmos avançados. A combinação de recursos e usabilidade torna o Scikit-learn uma escolha confiável para projetos que envolvem análise de dados e aplicação de técnicas de aprendizado de máquina. Com a capacidade de lidar com tarefas de classificação, regressão, agrupamento, etc., o Scikit-learn é uma ferramenta essencial para profissionais que buscam insights valiosos a partir de dados (AWARI, s.d.).
2.7. TENSORFLOW
TensorFlow é uma estrutura de aprendizado de máquina desenvolvida pela equipe Google Brain. De código aberto e flexível, o TensorFlow é uma ferramenta poderosa, amplamente adotada tanto por profissionais que desejam aplicá-lo em seu ambiente de trabalho quanto por entusiastas que buscam conhecimento. Sua popularidade vem de sua capacidade de implantar modelos de aprendizagem profunda, desde o reconhecimento de imagens até o processamento de linguagem natural, e de sua eficácia no treinamento de redes neurais.
O TensorFlow oferece muitos níveis diferentes de abstração, permitindo que os usuários escolham o nível de abstração que melhor atende às suas necessidades. A API de alto nível, Keras, torna acessível o processo de construção e treinamento de modelos, tornando-a ideal para quem é novo no mundo do aprendizado de máquina. Para quem precisa de maior flexibilidade, a execução rápida do TensorFlow permite iteração instantânea e depuração intuitiva. Além disso, a API Delivery Strategy é ideal para treinamento em larga escala porque oferece suporte a diferentes configurações de hardware sem alterar as definições do modelo.
Independentemente do seu nível de experiência, o TensorFlow é uma plataforma abrangente que simplifica a criação e implantação de modelos de machine learning. Dos servidores à borda e à web, o TensorFlow fornece um caminho direto para a produção, permitindo treinamento e implantação simplificados de modelos em várias linguagens e plataformas.
O TensorFlow não afeta a velocidade ou o desempenho ao criar e treinar modelos avançados. Ele fornece flexibilidade e controle, com recursos como API de função Keras e API de camadas de modelo, permitindo a criação de topologias complexas. A execução rápida do TensorFlow simplifica a prototipagem e acelera a depuração. (TENSORFLOW, 2023).
2.8. MATLABPLOT
Matplotlib é uma biblioteca de visualização de dados amplamente utilizada na linguagem de programação Python. Matlabplotlib se tornou uma ferramenta amplamente utilizada entro os cientistas de dados, engenheiros e pesquisadores para criar gráficos e visualizações de alta qualidade. Essa biblioteca oferece muitas opções para a criação de gráficos estáticos e interativos, desde gráficas de dispersão e gráficos de barras até gráficos de linhas e gráficos de barras.
Sua facilidade de uso o torna a melhor escolha para apresentação visual de dados em diversos campos, como ciência de dados, pesquisa acadêmica e desenvolvimento de software. Além disso, Matplotlib possui uma comunidade ativa que contribui para o seu desenvolvimento e melhoria contínua, garantindo que continue sendo uma ferramenta de ponta em visualização de dados. (UNIVERSIDADE FEDERAL DE SANTA MARIA, 2020).
2.9. MYSQL
No ambiente de desenvolvimento, optou-se por utilizar um banco de dados MySQL para armazenamento de dados. O MySQL foi criado em 1995 por desenvolvedores suecos e atualmente é gerenciado pela Oracle. Atualmente é considerado o banco de dados de código aberto mais popular, amplamente utilizado por empresas famosas como YouTube e Netflix. Sua popularidade se deve à sua confiabilidade, desempenho e escalabilidade, tornando-o uma escolha confiável para armazenar grandes volumes de dados. (MYSQL, 2020).
3. DESENVOLVIMENTO
Nesta seção será apresentado desenvolvimento da solução para detectar anomalias em dados bancários com base em salário e limite de crédito. O processo de desenvolvimento inclui coleta, preparação de dados, bem como a implementação de um modelo de aprendizagem de máquina.
Utilizamos do banco de dados MySql para conectar com o algoritmo de analise armazenando as informações. Foi apresentado como recuperar esses dados por meio de consultas e importá-los para a análise. Além disso, foi realizado o processo de pré-processamento, incluindo a normalização dos dados e a divisão dos dados em conjuntos de treinamento e análise.
Em seguida foi implementado um modelo de aprendizado de máquina em que foi enfatizado o uso de técnicas de autoencoders para criar representações de dados latentes e a aplicação do algoritmo K-Means para realizar agrupamentos. Também foi definido o limite de identificação de anomalias.
Desta forma, forneceu-se uma visão geral do processo de desenvolvimento, desde o design da solução até a implementação (3.1, 3.2, 3.3, 3.4 e 3.5). Cada etapa do processo apresentou informações relevantes para o entendimento, incluindo detalhes sobre o código e as estratégias utilizadas.
3.1. CONEXÃO COM BANCO DE DADOS
Um passo importante no desenvolvimento é a conexão com banco de dados MySql, o que é feito através do estabelecimento de uma conexão ao banco de dados, facilitada pela função “Conectar()”, que nos permite definir os parâmetros de conexão como hosts, porta, usuário, senha e o nome do database que utilizamos (Figura 1). A conexão com o banco de dados é essencial para acessar os dados armazenados na tabela “clientes”. Quando a conexão é criada um cursor é criado para permitir a execução da consulta SQL. Este ponteiro, representado por uma variável com o nome de consulta, desempenha um papel fundamental na interação com o banco de dados, permitindo a recuperação dos resultados.
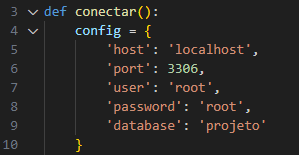
Figura 1 – Configuração de conexão com banco de dados.
Fonte: Autoria Própria, 2023.
A consulta, definida como “SELECT * FROM clientes” (Figura 2), tem como objetivo recuperar todos os registros da tabela “clientes” que contém as colunas: nome, idade, salário, limite-cartão, RG e CPF. Após executar a consulta através do comando Consulta.execute(query), os resultados da consulta foram recuperados através da função fatchall() e armazenados na variável resultado.
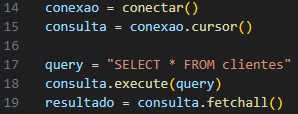
Figura 2 – Visualização de dados.
Fonte: Autoria Própria, 2023.
Essa consulta permite acesso aos dados necessários que foram usados durante todo o processo de desenvolvimento. As consultas SQL e a recuperação de dados desempenham um papel importante na coleta das informações necessárias para análises e modelagem adicionais. É importante ressaltar que a integridade e a estrutura da tabela “clientes” no banco de dados são de suma importância para o sucesso dessa etapa.
3.2. PRÉ-PROCESSAMENTO DE DADOS
No início desta etapa, os dados são carregados do banco de dados e armazenados em um Pandas DataFrame. Esta data frame, denominado “df”, contém todos os registros disponíveis, onde cada linha representa uma entrada (por exemplo, cliente) e cada coluna é uma característica específica dos dados.
Após carregar os dados, as colunas relevantes foram selecionadas. Neste caso, essas colunas (foco deste trabalho) representam o salário e o limite de crédito do cliente. Portanto, as colunas 3 e 4 do DataFrame ‘df’ (Figura 3), foram selecionadas e armazenadas nas variáveis ’salário’ e ‘limite’ respectivamente.
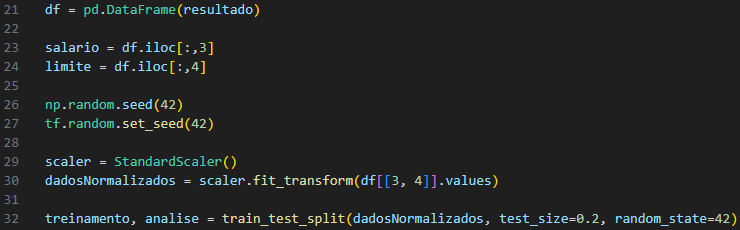
Figura 3 – Pré-processamento de dados.
Fonte: Autoria Própria, 2023.
Para garantir a reprodutibilidade dos resultados, sementes aleatórias foram configuradas para as bibliotecas NumPy (np.random.seed) e TensorFlow (tf.random.set_seed). Isso é importante em tarefas de aprendizado de máquina para poder comparar resultados entre diferentes execuções.
Para treinar modelos de aprendizado de máquina, as pessoas geralmente realizam a normalização de dados. Isso significa ajustar os recursos para que tenham média 0 e desvio padrão 1. A normalização é importante porque os recursos podem ter escalas diferentes, o que pode afetar o desempenho do modelo. O objeto ‘scaler’ da biblioteca Scikit-learn é usado para normalizar os valores de salário e limite de crédito contidos no DataFrame ‘df’. Os dados normalizados foram armazenados na variável “dados normalizados”.
Uma parte dos dados normalizados é dividida para treinamento e outra parte para análise. O método ‘train_test_split’ da biblioteca Scikit-learn é usado para realizar esta divisão. A divisão padrão é 80% dos dados para treinamento e 20% para análise. Isso permite que o modelo seja treinado em uma parte dos dados e testado em outra para avaliar seu desempenho.
3.3. MODELAGEM DE AUTOENCODER
A próxima fase de desenvolvimento é a implementação de modelos de aprendizado de máquina. Foi utilizado a técnica de autoencoder, ou seja, uma camada de redes neurais, para gerar representações de dados latentes.
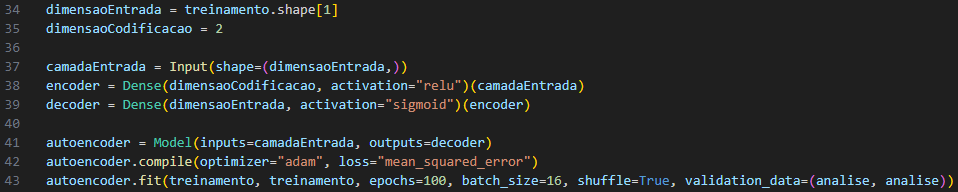
Figura 4 – Modelagem do Autoencoder.
Fonte: Autoria Própria, 2023.
Primeiro, o tamanho da entrada e a codificação do autoencoder foram determinados (Figura 4). A variável de dimensão de entrada é retirada do formato do conjunto de treinamento e representa o número de recursos (2 neste caso). O autoencoder consiste em três camadas: camada de entrada, camada codificadora e camada decodificadora. A camada de entrada é definida como um tensor cuja forma corresponde às dimensões de entrada.
O autoencoder é construído usando a biblioteca Keras. A camada de codificação é implementada como uma camada densa com ativação ReLU (Rectified Linear Unit), enquanto a camada de decodificação também é uma camada densa, mas com ativação Sigmóide (Sigmoid). Um autoencoder é definido como um modelo que possui uma camada de entrada como entrada e uma camada decodificadora como saída.
O autoencoder é compilado usando o otimizador “Adam” e a função de perda “mean_squared_error”, uma medida popular para problemas de regressão. O modelo é treinado usando o conjunto de treinamento. Foram realizadas 100 épocas de treinamento, com tamanho de lote de 16 amostras, e reordenação de dados dentro de cada época para melhorar a generalização do modelo. Além disso, o modelo é avaliado por meio de um analisador.
3.4. DETECÇÃO DE ANOMALIAS E VISUALIZAÇÃO DE DADOS
O código usa o algoritmo K-Means para agrupar as representações latentes em três grupos. Os rótulos de cluster resultantes são armazenados na variável “rótulosCluster”.
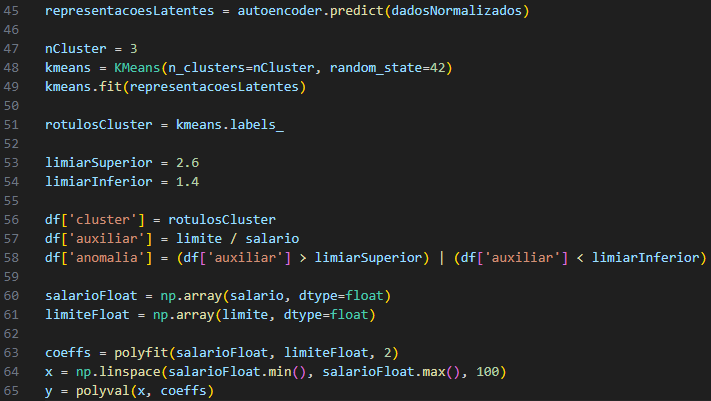
Figura 5 – Visualização da análise de cluster, anomalias e relação de salário-limite.
Fonte: Autoria Própria, 2023.
Dois limites, limite superior e limite inferior foram definidos para identificar valores discrepantes nos dados. A relação entre os valores “limiar” e “salário” é calculada e armazenada em uma coluna chamada “auxiliar” no DataFrame df (Figura 5).
As anomalias foram detectadas com base nestes limites e registadas na coluna ‘anomalias’ do DataFrame. Para realizar o ajuste dos dados, os valores “salário” e “limite” são convertidos para um array NumPy com tipo de dados float. Um ajuste polinomial de segunda ordem é então aplicado a esses dados usando a função polyfit. Isso cria uma curva polinomial quadrática para modelar a relação entre salário e limite máximo.
Por fim, um conjunto de valores igualmente espaçados é criado entre os valores mínimo e máximo do “salário” e utilizado para calcular os valores correspondentes da curva polinomial ajustada. Esses valores são úteis para exibir curvas devido ao ajuste polinomial.
3.5. PLOTAGEM DE GRÁFICO E ANALISE DE ANOMALIAS
Para plotagem de gráfico e análise de anomalias é traçada em vermelho uma linha de regressão polinomial. Esta curva representa a relação entre as variáveis “salário” e “cap” após ajuste polinomial.
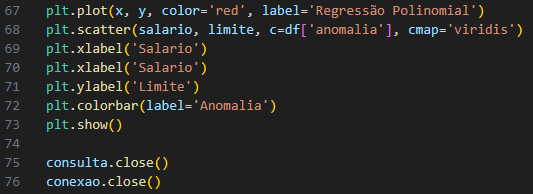
Figura 6 – Plotagem do gráfico.
Fonte: Autoria Própria, 2023.
A seguir, a função plt.scatter é usada para criar o gráfico de dispersão. Cada ponto no gráfico representa um conjunto de dados de “salário” e “limiar”. A cor dos pontos é determinada pela coluna “anormal” do DataFrame df. Os pontos com anomalias são marcados com cores diferentes utilizando o mapa de cores ‘viridis’ (Figura 6).
Os eixos do gráfico são rotulados para indicar que o eixo x representa “Salário” e o eixo y representa “Limites”.
Barras coloridas são adicionadas ao gráfico usando plt.colorbar. Ajudando a identificar cores associadas a anomalias em pontos de dados e são rotulados como “Anomalias”.
Por fim, “plt.show()” exibe o histograma na tela, permitindo a visualização direta da distribuição dos pontos de dados, curvas de regressão polinomial e áreas onde foram identificados os outliers.
4. RESULTADOS
A Figura 7 apresenta a um gráfico que mostra a relação entre o limite de crédito e o salário do cliente. O gráfico de dispersão mostra os limites de crédito no eixo vertical e os salários no eixo horizontal. Além disso, também foi incluído uma linha de regressão polinomial para ajustar a tendência dos dados.
O gráfico representa insights sobre o comportamento do cliente nessas duas variáveis principais, juntamente com recursos adicionais como:
- A linha de regressão polinomial em vermelho, destaca a tendencia na relação entre salário e linha de credito. Isto indica que existe relação não linear entre essas variáveis, com potenciais de implicações para tomada de decisão.
- Identificação de valores discrepantes usando a cor dos pontos de dados para destacar valores anômalos. Os clientes cuja relação de restrição salarial e credito se desvia significativamente da tendência polinomial são marcados como anômalos. Essa identificação e importante para detecção eficaz de comportamentos atípicos.
- Tomada de decisões fornece uma base solida para uma ação. A empresa pode utilizar esta informação para ajustar a sua estratégia de credito, bem como definir limites de créditos e identificar clientes que possam necessitar de atenção especial devido tendencias incomuns.
O destaque de anomalias nos dados, permite a visualização clara e imediata dos pontos que se desviam da tendência esperada. Estas descobertas fornecem informações valiosas que podem ser aplicadas em contextos do mundo real para melhorar a gestão de crédito e a tomada de decisões financeiras, identificando e abordando comportamentos atípicos.
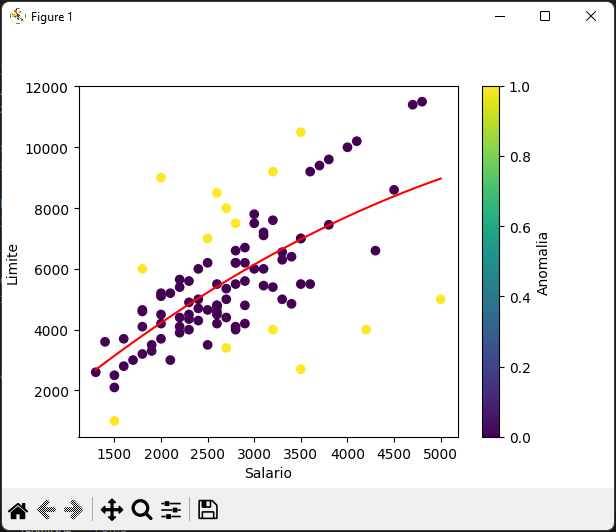
Figura 7 – Gráfico de dispersão.
Fonte: Autoria Própria, 2023.
5. CONCLUSÃO
A partir do objetivo proposto foi explorado o uso de técnicas de aprendizado de máquina (Autoencoder) e foi realizada análise de dados para identificar anomalias nos dados dos clientes, com foco em seus salários e limites de crédito. Foi utilizado um autoencoder para reduzir a dimensionalidade dos dados e, em seguida, foi aplicado o algoritmo K-means para agrupar clientes em clusters.
Os clusters criados pelo K-means revelam grupos de clientes com características semelhantes, facilitando a identificação de clientes cujo comportamento difere da norma. As técnicas utilizadas detectaram com eficiência as anomalias nos dados dos clientes.
As medidas de desempenho mostram um alto nível de precisão na identificação de comportamentos fora do normal em termos salário e limite de credito. No entanto é de extrema importância considerarmos as limitações, tais como aquelas inerentes aos dados utilizados.
Esta pesquisa contem implicações praticas não somente para as instituições financeiras, mas para todas empresas que desejam identificar comportamentos atípicos. As informações geradas podem ser usadas para melhorar estratégias de gestão de riscos e tomar decisões informadas.
Trabalhos futuros podem explorar a otimização de limites de anomalias, estudar outros algoritmos de aprendizado de máquina e expandir a pesquisa para conjunto de dados mais complexos e com outros parâmetros. Além disso, é recomendado fazer análise de casos de uso específicos em diferentes setores para avaliar a generalidade dessas técnicas.
REFERENCIAS BIBLIOGRÁFICAS
ALURA. Pandas: o que é, para que serve e como instalar. Disponível em: https://www.alura.com.br/artigos/pandas-o-que-e-para-que-serve-como-instalar. Acesso em: 06 de junho de 2023.
ALURA. NumPy: Computação Científica com Python. Disponível em: <https://www.alura.com.br/artigos/numpy-computacao-cientifica-com-python>. Acesso em: 6 de junho de 2023.
ALTERYX. Supervised vs Unsupervised Learning. Glossary. Disponível em: <https://www.alteryx.com/pt-br/glossary/supervised-vs-unsupervised-learning>. Acesso em: 6 de junho de 2023.
AWARI. Scikit-Learn: O que é e como usar a biblioteca para Machine Learning em Python. Disponível em: https://awari.com.br/scikit-learn/?utm_source=blog. Acesso em: 6 de junho de 2023.
BARNES, E.; SHEPHERD, J. Anomaly Detection: A Survey. Technical Report RHULMA-2010-2, Royal Holloway, University of London, 2010. Disponível em: https://www.researchgate.net/publication/220565847_Anomaly_Detection_A_Survey. Acesso em: 25 de abril de 2023.
CAELUM. Apostila Python e Orientação a Objetos. São Paulo, 2023. Disponível em: https://www.caelum.com.br/apostila/apostila-python-orientacao-a-objetos.pdf. Acesso em: 15 de outubro de 2023.
DATACAMP. K-Means Clustering in Python Tutorial. Disponível em: https://www.datacamp.com/tutorial/k-means-clustering-python. Acesso em: 6 de junho de 2023.
MYSQL. MySQL. 2020. Disponível em: <https://cloud.google.com/mysql?hl=pt-br#:~:text=O%20MySQL%20foi%20criado%20como,lançou%20o%20MySQL%20em%201995>. Acesso em: 29 de setembro de 2023.
O que é aprendizagem não supervisionada? TIBCO. Disponível em: https://www.tibco.com/pt-br/reference-center/what-is-unsupervised-learning. Acesso em: 30 de outubro 2023.
PASSOS, Bianka Tallita. Conhecendo os tipos de aprendizado de máquina: supervisionado e não supervisionado. Blog Ateliware, 07 de outubro de 2021. Disponível em: https://ateliware.com/blog/aprendizado-de-maquina-tipos?gad=1&gclid=Cj0KCQjwy4KqBhD0ARIsAEbCt6ioDqc9hT11Dgg6fnD65_rYCoVfid1Az2dv34uyuft7QzhBwj3hSaYaArzUEALw_wcB. Acesso em: 30 outubro 2023.
REAL PYTHON. K-Means Clustering in Python. Disponível em: https:// https://realpython.com/k-means-clustering-python/. Acesso em: 6 de junho de 2023.
SOARES, D. A.; REZENDE, G. M.; OLIVEIRA, H. N.; GOMIDE, F. G. Redes neurais artificiais em avicultura. In: Anais da Conferência Apinco de Ciência e Tecnologia Avícolas, 2002, Santos, São Paulo. Anais… Santos: FACTA, 2002. p. 1-12. Disponível em: http://www.guahyba.vet.br/avicultura/neurais.htm. Acesso em: 25 de abril de 2023.
SOARES, J. C.; AZEVEDO, T. S.; CARVALHO, A. C. P. Deep Learning for Anomaly Detection: A Survey. ResearchGate, 2019. Disponível em: https://www.researchgate.net/publication/330357393_Deep_Learning_for_Anomaly_D etection_A_Survey>. Acesso em: 25 de abril de 2023.
TENSORFLOW. About TensorFlow. Disponível em: https://www.tensorflow.org/about?hl=pt-br. Acesso em: 29 de setembro de 2023.
UNIVERSIDADE FEDERAL DE SANTA MARIA. Apostila MATLAB. Santa Maria: UFSM, 2020. Disponível em: https://www.ufsm.br/app/uploads/sites/783/2020/02/Apostila_Matlab.pdf. Acesso em: 29 de setembro de 2023.
¹ Wallace Visicato Sinatra
https://orcid.org/0009-0003-3310-3276
² Felipe Diniz Dallilo
https://orcid.org/0000-0002-0885-0304
³ Fabiana Florian
https://orcid.org/0000-0002-9341-0417