REGISTRO DOI:10.5281/zenodo.10050647
Jean Carlo Albuquerque¹
Thágore Arthur Dourado Silvestrim2
Ronnie Shida Marinho³
RESUMO
Com o objetivo de auxiliar os usuários a encontrar produtos de seu interesse, plataformas online, como sistemas web, incorporam módulos de recomendação de itens que, de maneira automatizada, selecionam o conteúdo adequado com base nas preferências de cada indivíduo. Entretanto, existem várias maneiras e abordagens para realizar esse processo de recomendação de acordo com as interações disponíveis no sistema; no entanto, a maioria delas sofre com a escassez de informações utilizadas para caracterizar as preferências dos usuários e as descrições dos itens. Trabalhos recentes relacionados a esse tema validam a possibilidade de utilizar revisões de usuários como fontes de metadados, considerando que essas revisões são criadas de forma colaborativa entre os indivíduos. Diante disso, este trabalho tem como objetivo desenvolver uma técnica de extração e representação de termos referentes a revisões de usuários sobre filmes analisados, com a finalidade de favorecer de forma mais eficiente o cálculo da recomendação, levando em consideração as preferências obtidas por meio da caracterização extraída dos itens.
Palavras chave: Sistema de Recomendação; Revisões de Filmes; Extração de termos;
ABSTRACT
In order to assist users in finding products of their interest, online platforms, such as web systems, incorporate item recommendation modules that automatically select appropriate content based on each individual’s preferences. However, there are several ways and approaches to perform this recommendation process according to the interactions available in the system; nevertheless, most of them suffer from a lack of information used to characterize user preferences and item descriptions. Recent works related to this topic validate the possibility of using user reviews as sources of metadata, considering that these reviews are collaboratively created by individuals. Therefore, this work aims to develop a technique for extracting and representing terms related to user reviews of analyzed films, with the purpose of more efficiently facilitating the recommendation calculation, taking into account the preferences obtained through the extracted characterization of the items.
Keywords: Recommendation System; Film Reviews; Term extraction.
1 INTRODUÇÃO
Com a constante evolução tecnológica, aumentando exponencialmente o uso da internet e a disponibilização de informações na Web, surgiu a necessidade de prever a relevância de determinados itens aos usuários. Em resposta a essa situação, emergiram os sistemas de recomendação, os quais auxiliam usuários na procura e escolha de itens de seu interesse dentre a vasta quantidade disponível. Para isso, tais sistemas utilizam previamente a coleta de informações, tanto dos itens quanto dos usuários em questão, com a finalidade de criar diversas associações e processos de decisões, como sugestões de filmes a serem assistidos, produtos a serem adquiridos, músicas a serem acessadas, entre outras situações.
Em linhas gerais, os sistemas de recomendações podem ser categorizados em dois paradigmas fundamentais: filtragem baseada em conteúdo e a filtragem colaborativa. Resumidamente a filtragem baseada em conteúdo gera recomendação de um item a um usuário baseando-se na semelhança com itens adquiridos ou vistos por este usuário no passado (ADOMAVICIUS; TUZHILIN, 2005),e a filtragem colaborativa possui como característica principal o fato de que as sugestões fornecidas a um usuário derivam dos itens que são desconhecidos por ele, porém, levando em consideração que esses mesmos itens foram apreciados por outros usuários de preferências similares.(RESNICK et al., 1994).
A maioria dos modelos de sistema de recomendação utiliza como fonte de informação textos de natureza estática, como sinopses, revisões e notas para validar a satisfação de determinados produtos, anonimizando informações de cunho pessoal e sensível dos usuários de criação. Em especial, as revisões de usuários possuem certa relevância para serem analisadas pois permeiam as descrições dos itens, levando em consideração as opiniões dos usuários referentes ao produto.
1.1 OBJETIVOS
Este trabalho tem como objetivo exemplificar de maneira prática a construção de representações de itens com base em revisões de usuários, a serem aplicadas em um sistema de recomendação. A partir desse propósito, propõe-se uma técnica de pré-processamento dos dados, de modo que eles possam ser analisados com o intuito de elaborar uma extração de termos essenciais em relação aos itens que compõem o sistema.
O mecanismo disposto neste estudo possui a capacidade de construir representações, utilizando-se de métodos de extração de termos, que utiliza o processo de feature extraction (extração de características) referente às diversas revisões dos itens.
Por fim, o procedimento mencionado para a construção de representações é integrado à etapa de recomendação propriamente dita, estabelecendo relações entre os itens e as preferências compartilhadas pelos usuários. Neste trabalho, o método proposto é avaliado no contexto das notas e de suas descrições, sendo aplicado no domínio da recomendação de filmes.
2. FUNDAMENTAÇÃO TEÓRICA
Nesta seção, será desempenhado um papel crucial no embasamento e compreensão do contexto em que o estudo se insere. O qual, sucintamente refere-se a examinar os princípios de processamento de linguagem natural, suas aplicações práticas, tornando possível compreender como essa abordagem pode enriquecer a precisão e a análise de sistemas de recomendações. Apresentando os principais conceitos e teorias utilizadas, que fornecerão a base sólida para a análise e interpretação dos resultados obtidos.
2.1 PLN (Processamento de Linguagem Natural).
PLN pode ser situado como uma subárea da computação e da linguística (McShane e Nirenburg 2021), onde o objetivo principal é desenvolver modelos computacionais e recursos linguísticos úteis para a automatização do processamento das línguas humanas.
Nos últimos tempos, houve um crescimento notável na quantidade de dados que são processados, armazenados e acessados por meio de documentos, especialmente aqueles disponibilizados em plataformas digitais. Devido a esse aumento substancial na quantidade de informações, a tarefa de manipular esses dados manualmente se torna impraticável, levando à necessidade de empregar mecanismos e ferramentas que viabilizem a automatização do processamento de informações.(BENIN et al)
Processamento de Linguagem Natural (PLN) é uma área de Ciência da Computação que estuda o desenvolvimento para programas de computador que analisam, reconhecem e/ou geram textos em linguagens humanas, ou linguagens naturais, é uma tarefa trivial devido à rica ambiguidade da linguagem. Essa ambiguidade torna esse processo diferente do processamento das linguagens de programação de computador, as quais são formalmente definidas evitando, justamente, a ambiguidade. (VIEIRA RENATA; LOPES LUCELENE)
É uma abordagem predominante para analisar e compreender textos e linguagens utilizando tecnologia computacional. Em sistemas de recomendação, o PLN desempenha um papel crucial ao permitir que informações contextuais, muitas vezes presentes em descrições de filmes, resenhas e comentários, sejam analisadas e utilizadas para aprimorar a qualidade das recomendações. Segundo (Liddy, 2003), alguns objetivos usuais em PLN são: recuperação de informação a partir de textos, tradução automática, interpretação de textos e realização de inferências a partir de textos.
Diante disso, nota-se que é de suma relevância do ponto de vista linguístico, possibilitando se concentrar em níveis de diferentes análises: aspectos fonéticos e fonológicos, aspectos morfológicos, aspectos sintáticos, aspectos semânticos ou aspectos pragmáticos. Cada um desses níveis apresenta suas próprias características e desafios específicos. No entanto, dependendo do contexto da aplicação de PLN, a ênfase pode ser direcionada a um desses subconjuntos de níveis linguísticos.
A mineração de textos é um paradigma de programação criado para resolver este problema, sendo capaz de entender a linguagem natural dos documentos de texto e conseguindo lidar com a sua imprecisão e incerteza. A mineração de textos envolve várias áreas da informática, como mineração de dados, aprendizado de máquina, recuperação de informação, estatística e linguagem computacional, para conseguir transformar o texto em algo que um computador consiga entender (MACHADOet al., 2010).
O principal objetivo da mineração de textos é encontrar termos relevantes em documentos de texto com grande volume de dados e estabelecer padrões e relacionamentos entre eles com base na frequência e temática dos termos encontrados. Perante ao exposto, podemos incluir métodos e procedimentos específicos, comumente chamado de pré-processamento, que abrangem de forma computacional, essas segmentações, auxiliando a análise e mineração de dados para seus devidos objetivos. (PEZZINI)
No pré-processamento os documentos adquiridos, escritos em linguagem natural, passam por uma formatação para estruturá-los de maneira padronizada, mas sem perder suas características naturais, para que os algoritmos que serão utilizados nas próximas etapas sejam capazes de manipular todos os documentos da mesma maneira. Ao final deste processo obtém-se uma estrutura que representa o grupo de documentos fonte, geralmente uma tabela atributo-valor (MARTINS et al., 2003).
Tendo em vista essa finalidade, ao decorrer desse estado de pré-processamento dos dados, são frequentemente empregados termos computacionais específicos, dentre eles, podemos mencionar a tokenização¹ e stopwords²,com a finalidade de tornar a tarefa de análise de linguagem natural mais gerenciável, no ponto de vista da engenharia de software.
A tokenização, também conhecida como segmentação de palavras, quebra a sequência de caracteres em um texto localizando o limite de cada palavra, ou seja, os pontos onde uma palavra termina e outra começa [Palmer, 2010]. Para fins de linguística computacional, as palavras assim identificadas são frequentemente chamadas de tokens.
Segundo SANTOS (2002) stopwords são palavras que ocorrem frequentemente em textos. Uma vez que elas são muito comuns, sua presença não contribui significativamente para a determinação do conteúdo do documento. Podemos então concluir que elas podem ser descartadas do documento, para fins de mineração. As stopwords podem ser: artigos, preposições, pronomes e demais palavras utilizadas para auxiliar na construção sintática das orações.
2.2 Sistemas de Recomendação.
Com o advento da internet a produção e distribuição massiva de informações se tornou comum e crescente a cada dia. Atualmente essa geração excede nossa capacidade de processamento, dificultando frequentemente que os usuários encontrem conteúdo de seu interesse e relevante para si, como notícias, livros, filmes, vídeos ou produtos.
Como resposta a esse desafio, surgiram os sistemas de recomendações, com o intuito de fornecer aos usuários um conteúdo mais assertivo e personalizado com base em suas preferências. Esses sistemas utilizam algoritmos e técnicas que analisam o comportamento passado do usuário e suas interações com o conteúdo, a fim de oferecer sugestões relevantes, melhorando a experiência geral do usuário.
2.2.1 Tipos de Sistemas de Recomendação.
Dentre os mais referenciados na literatura (GOLDBERG et al., 1992) (BALABANOVIĆ; SHOHAM, 1997) (BURKE, 2002) e (ADOMAVICIUS; TUZHILIN,
2005), estão: filtragem colaborativa, filtragem baseada em conteúdos e filtragem híbrida.
Filtragem colaborativa (FC) – O termo FC foi criado por (GOLDBERG et al., 1992), que foi um dos pioneiros no uso desta técnica. A principal característica da FC é de que as recomendações feitas a um usuário são baseadas nos itens que lhe são desconhecidos, mas que foram relevantes para usuários com gostos semelhantes. Consiste no princípio de que os usuários que concordaram sobre certos itens anteriormente irão concordar no futuro (RESNICK et al., 1994) (CACHEDA et al., 2011).
Algumas das desvantagens deste tipo de filtragem, segundo (BALABANOVIĆ; SHOHAM, 1997) (BURKE, 2002) e (ADOMAVICIUS; TUZHILIN, 2005) são: novos itens, pois são regularmente adicionados aos SR. Os sistemas que utilizam a FC dependem unicamente da avaliação dos usuários para que possam fazer recomendações, ou seja, enquanto um novo item não for avaliado por um número considerável de usuários, o sistema não o recomendará. Novo usuário: este problema é similar ao que ocorre nos sistemas que utilizam a FBC. Para fazer recomendações precisas, o SR deve primeiramente aprender as preferências do usuário, a partir de suas avaliações.
Filtragem Baseada em Conteúdo (FBC) – Na FBC, a recomendação de um item a um usuário baseia-se na semelhança com itens adquiridos ou vistos por este usuário no passado (ADOMAVICIUS; TUZHILIN, 2005).Um livro, por exemplo, pode ser caracterizado pelo tema, autor, editora, título etc. Já em um texto, geralmente, as próprias palavras que o compõem são consideradas como suas características. É com base nessas características que os itens podem ser comparados e a semelhança entre eles estabelecida.
Contudo, um problema com esse tipo de abordagem é que o sistema tende a ser muito especializado, recomendando apenas itens similares aos itens já avaliados pelo usuário.Por exemplo, um usuário que gostou do livro “Harry Potter e a pedra filosofal“ pode receber apenas recomendações de filmes de fantasia mesmo que o usuário goste de outros gêneros.
Algumas das desvantagens deste tipo de filtragem, segundo (ADOMAVICIUS; TUZHILIN, 2005) e (BURKE, 2002) são:
Novo usuário: para que o sistema possa realmente compreender as preferências e apresentar recomendações confiáveis, o usuário deve avaliar um número suficiente de itens. Um novo usuário, que avaliou poucos itens, consequentemente, receberá recomendações pouco confiáveis.Criação do perfil: para que seja realizada a recomendação, essa técnica cria um perfil para cada item e usuário. No entanto, geralmente, as bases de dados reais não possuem informações disponíveis sobre todos os itens, podendo gerar perfis incompletos e recomendações imprecisas.
Filtragem Híbrida (FH) –O caso mais comum da FH é a junção da FBC com a FC
(MELVILLE; SINDHWANI, 2010) (ADOMAVICIUS; TUZHILIN, 2005) e (BALABANOVIĆ; SHOHAM, 1997). Existem diferentes formas de agregar esses dois tipos de filtragem:
Incorporar algumas características da FBC na FC: o sistema pode manter os perfis dos usuários, comparar diretamente os perfis para determinar os usuários semelhantes com a FBC e então utilizar a FC. Esta estratégia permite reduzir os problemas da escassez de itens comuns e dos novos itens, pois podem ser sugeridos com base no perfil do usuário. Assim, o usuário alvo recebe não só as recomendações de itens que foram bem avaliados por usuários com perfis semelhantes, mas também itens que sejam semelhantes àqueles já avaliados positivamente por ele.
Incorporar algumas características da FC na FBC: o mais comum nessa categoria é a utilização de uma técnica de redução da dimensionalidade aplicada ao grupo de perfis com FBC. Para isso, o Indexação Semântica Latente – Latent Semantic Indexing (LSI) é usado para criar perfis de usuários tipo FC. Neste caso, LSI é aplicada sobre o conjunto de perfis (tanto de FC como de FBC) em vez de ser aplicado no conjunto de documentos, com o objetivo de obter semelhanças entre os perfis (ADOMAVICIUS; TUZHILIN, 2005).
Desenvolvimento de um modelo unificado de recomendação: um modelo unificado que incorpora características das abordagens baseada em conteúdo e colaborativa. Um exemplo é a junção de um sistema de FBC com um classificador baseado em regras, objetivando a obtenção de recomendações confiáveis.
Implementar os métodos FBC e FC separadamente e combinar suas recomendações: nesta forma, existem dois cenários: combinar as avaliações obtidas individualmente em cada um dos métodos para oferecer uma recomendação final; avaliar em cada recomendação qual dos sistemas gera recomendações mais exatas, determinando o grau de confiança de cada uma e escolher o mais consistente com as avaliações realizadas pelo usuário no passado.
3 TRABALHOS RELACIONADOS
Aqui são apresentados trabalhos recentes e similares a este artigo. Inicialmente apresentam-se estudos que utilizam revisões de usuários para realizar a recomendação. Em seguida é apresentado um trabalho de revisões da literatura sobre algoritmos de filtragem colaborativa.
Nguyen propôs o ExtKNNCF um modelo adaptativo de filtragem colaborativa baseado em KNN que incorpora parâmetros de cognição do usuário. Os parâmetros de cognição do usuário permitiram capturar as preferências do usuário com mais precisão, melhorando assim a qualidade das recomendações. Nos experimentos foram utilizados os conjuntos de dados MovieLens, incluindo MovieLens-100 K e MovieLens-1 M.
Em DHARMIK foi proposto um novo sistema de modelo de recomendação híbrido para recomendação de filmes utilizando o método de mineração CF & Rule. A base de dados utilizada foi a MovieLens-1 M. Os autores propuseram 5 medidas de similaridade distintas, a Cityblock, Medidas de correlação de Cosine, Braycurtis, Chevyshev e Spearman para alcançar similaridade item-item
Em DELGADO foi proposto a implementação e análise de alguns algoritmos clássicos de filtragem colaborativa: filtragem colaborativa baseada em usuários, em itens e passeios aleatórios. Foram utilizados dados do MovieLens para gerar recomendações de filmes para usuários e avaliar os algoritmos implementados: filtragem colaborativa baseada em itens, baseada em usuários, passeio aleatório e passeio aleatório enviesado as medidas de similaridade foram Pearson e Cosseno
4 ARQUITETURA METODOLÓGICA
Nesta seção, são detalhados os experimentos conduzidos para comprovar a eficácia desta abordagem. Inicialmente, são fornecidos detalhes pertinentes sobre a fonte de dados empregada. Em seguida, as configurações específicas dos experimentos são delineadas e, por fim, os resultados obtidos são expostos. Para isso, será demonstrado como que as técnicas de tratamento e processamento de texto apresentadas na Seção 2 se integram ao sistema
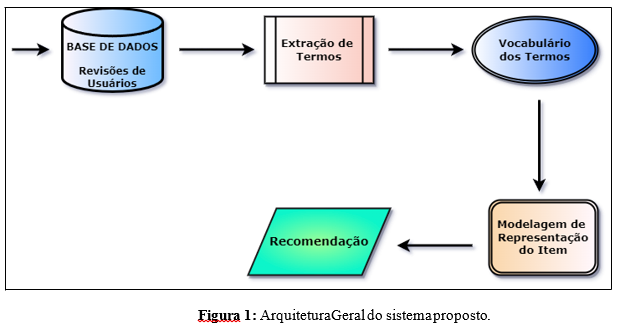
De maneira sucinta, a arquitetura desse processo envolve a transformação das revisões de usuários em uma forma em que os algoritmos de análise de texto e de recomendação possam entender. A extração de termos é uma etapa fundamental para capturar as informações-chave presentes nas revisões, permitindo que os algoritmos identifiquem padrões, semelhanças e preferências dos usuários de maneira mais eficaz.
4.1 Base de Dados
Nas análises conduzidas, a fonte de dados empregada compreendeu o conjunto MovieLens ML-100k, disponibilizado pelo Grupo de Pesquisa GroupLens[4]. Essa coleção contempla 943 utilizadores e 1682 filmes, com cada indivíduo avaliando ao menos 20 obras cinematográficas. Adicionalmente, a base de dados contém metadados relativos aos filmes, incluindo gêneros, autores e diretores. Além desse aspecto, para a elaboração da estratégia proposta, foram extraídas análises de usuários do website IMDb[5]. Em média, as dez primeiras avaliações de cada obra foram coletadas, sendo ordenadas conforme seu nível de relevância.
4.2 Extração de Termos
O módulo de extração de termos é responsável pela realização de diversas tarefas que visam a estruturação de revisões de usuários, de modo que as informações contidas nelas sejam aproveitadas pelo sistema. Diante disso, as seguintes tarefas são realizadas: processo de tokenização, remoção de ruído, análise morfossintática.
- Tokenização:é o processo de dividir um texto em unidades individuais, chamadas de tokens. Tokens podem ser palavras, frases, símbolos ou qualquer outra unidade significativa.
- Remoção de Ruído:é o procedimento de eliminar informações indesejadas ou irrelevantes de um conjunto de dados, melhorando sua qualidade e clareza, as stopwords, além de palavras com caracteres especiais, datas e caracteres numéricos, além de transformar os termos com letras minúsculos criando um padrão para análise.
- Análise Morfossintática:é o procedimento de examinar a estrutura gramatical e as características linguísticas das palavras e frases em um conjunto de dados linguísticos.
Envolve identificar as partes de fala (substantivos, verbos, adjetivos, etc.).
4.3 Criação de Vocabulário
O processo de criação de um vocabulário de termos envolve a identificação e coleta de elementos relevantes presentes em um conjunto de textos ou documentos. Esse vocabulário consiste em uma lista de palavras distintas que ocorrem no corpus de texto e é frequentemente utilizado em análises linguísticas, processamento de linguagem natural e outras aplicações.
Para que essa etapa ocorra da melhor maneira possível, foram aplicados conceitos de extração de termos, conforme descrito na seção anterior. Após concluir a estruturação e análise dos reviews, uma ampla variedade de termos foi caracterizada, pertencentes a todas as classes gramaticais. No entanto, uma vez que o objetivo deste trabalho é recomendação, optou-se por selecionar apenas os termos da classe gramatical ‘substantivo’.
Os termos ‘substantivos’ são frequentemente utilizados em análises linguísticas e processamento de linguagem natural para se referir a palavras que desempenham um papel fundamental na comunicação e na estruturação das sentenças. Isso se deve a várias razões e características dessa classe gramatical. Dentre elas, destacam-se a representação central nas sentenças e a capacidade de extração de informações, além de sua responsabilidade em nomear seres, objetos, ações e lugares.
4.4 Modelagem e Representação do Item
Diante desse critério, foi desenvolvido um vocabulário de termos contendo apenas os substantivos, sem repetições, provenientes da análise das avaliações (reviews) dos filmes presentes na base de dados.
Após a extração desse vocabulário, o módulo subsequente do sistema assume a responsabilidade de utilizá-lo para criar representações dos itens. Essas representações são modeladas em um espaço vetorial por meio da criação de uma Matriz Binária. Em uma visão geral, esse vocabulário construído encontra-se registrado em um arquivo ‘txt’, contendo um total de 53.645 termos obtidos a partir da análise de 15.863 avaliações (reviews).
Neste trabalho, investiga-se o uso dos termos presentes nos itens para influenciar a escolha destes. Dessa forma, são selecionados apenas os conceitos da classe substantivos, conforme explicado no capítulo anterior 4.3, porque conceitos dessa classe geralmente representam características (Liu; Zhang, 2012).
Nesse contexto, faz-se uso da técnica de Part-of-speech tagging (POS), que consiste basicamente no processo de categorização de cada palavra em uma sentença de acordo com sua classe morfossintática (verbo, substantivo, adjetivo, etc.). O POS tagging é considerado uma atividade fundamental no desenvolvimento de aplicações de processamento de linguagem natural (PLN), já que muitas dessas aplicações necessitam dessa informação em algum momento.(César Rômulo, 2019)
Considera-se que cada substantivo representa uma dimensão no modelo de espaço vetorial, de modo que cada item é descrito por um vetor cujas posições são representadas por cada substantivo existente no vocabulário. Com base nisso, este trabalho utiliza a técnica já mencionada do POS para construir uma matriz binária que indica se um determinado termo existe no corpus de um item. Nessa matriz, o valor 1 representa a presença do termo, enquanto o valor 0 indica a ausência do termo. Essa abordagem facilita o processamento computacional, como exemplificado na Tabela 1, que apresenta de forma concisa o processo relacionado ao item/filme “Toy Story”.
Filme Vocabulário POSSUI TERMO? Toy Story play 1 terrible 0 fun 1 toy 1 fire 0
Tabela 1- Representação pela Matriz Binária do Item (Toy Story)
4.5 Recomendação
Concluída a criação das representações dos itens, estas são encaminhadas para o módulo de recomendação. Neste módulo, elas são analisadas em conjunto com as avaliações fornecidas pelos usuários. Como algoritmo de recomendação, a escolha recaiu sobre a utilização de um método de vizinhança baseado em item (item k-NN).
O qual, leva em consideração o viés dos usuários e itens, e isso foi modificado para empregar os vetores de características em vez dos convencionais vetores de avaliação de usuários no processo de obtenção de vizinhos. Os vieses associados aos itens e aos usuários são incorporados nas chamadas estimativas de referência, que são representadas como bui. Essa estimativa reflete a previsão de que um usuário u atribuiria a um item i. O cálculo dessa estimativa é feito da seguinte forma:
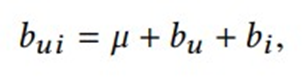
Onde µ corresponde à média de todas as avaliações conhecidas, bu e bi indicam o desvio observado do usuário u e do item i em relação à média das avaliações, e esse desvio pode ser obtido ao resolver um problema de quadrados mínimos(Yehuda Koren). O algoritmo item-kNN tem como finalidade prever as avaliações de itens que o usuário ainda não avaliou, com base nas avaliações de outros itens semelhantes que ele já avaliou. Para realizar isso, utiliza-se uma medida de semelhança (i, j) entre as representações de itens. A métrica de semelhança escolhida para este estudo é o coeficiente de correlação de Pearson, que é definido como:
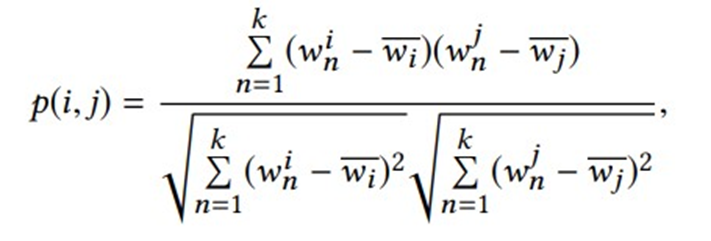
Na mesma linha, onde w i n e w j n denotam o valor da enésima característica nas representações dos itens i e j, e wi e wj representam a média dos valores das características de i e j, respectivamente. A métrica de similaridade resultante é um coeficiente de correlação retraído, sij (Yehuda Koren):

Nesse contexto, nij representa o número de características que descrevem tanto os itens i quanto j, enquanto λ é uma constante de regularização. Com base nas similaridades calculadas, o algoritmo identifica os k itens avaliados por u que são mais semelhantes a i, ou seja, os k-vizinhos mais próximos. Esse conjunto é representado como S k (i;u). Utilizando esse conjunto, a nota prevista final é calculada como a média das notas dos k itens mais similares, ajustadas às suas estimativas de referência (Yehuda Koren):
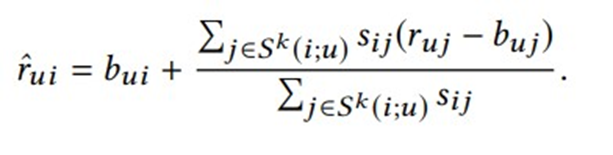
5 RESULTADOS
Para a construção dos resultados e a validação da proposta, foi conduzido um experimento. Este experimento envolveu a comparação da técnica de recomendação, avaliando a qualidade da sua execução em diferentes abordagens que também se baseiam na vizinhança com previsão de notas. Dessa forma, a representação desenvolvida foi comparada com as seguintes representações de referência:
- Gêneros: essa representação faz uso dos metadados de gêneros dos filmes, e é construída de forma que cada ´posição dos vetores se refere a um gênero que o item pode conter(valor 1) ou não (valor 0)
- Termos Heurísticos: essa representação faz uso de heurísticas para extração de termos a partir das revisões de usuários. Tal técnica seleciona termos lematizados da classe morfossintática de substantivos,e aplica também o IF(com limiar 30) para filtragem de termos menos frequentes, Considera-se aqui também o peso para o termo conforme a utilização do TF-IDF. Adota-se a terminologia TH-TFIDF.
A ponto de avaliar a qualidade da representação, independentemente do tamanho do seu vocabulário, e viabilizar a abordagem proposta, foram conduzidos experimentos com o mesmo número de conceitos apresentados nas duas representações basais..
Na Tabela 2 e nas Figuras 2 e 3, são apresentados os valores médios obtidos pelas abordagens mencionadas anteriormente, juntamente com os resultados de suas respectivas representações. Estas são exibidas de forma comparativa com a abordagem original proposta por este estudo, que é a matriz binária.
Tabela 2: Valores obtidos de RMSE para as representações propostas e basais. Valores
em negrito indicam melhores resultados
Algoritmo k=20 k=40 k=60 k=80 k=100 TH-TFIDF 0,9435 0,9407 0,9402 0,9403 0,9404 Binária 0,93403 0,9336 0,9352 0,9367 0,9381 Gêneros 0,9404 0,9401 0,9401 0,9401 0,9401 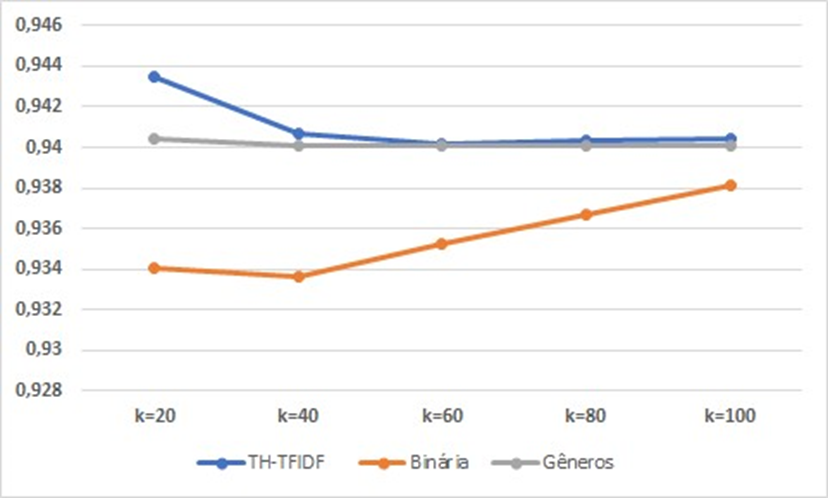
Figura 2: Gráfico comparativo contendo os resultados de RMSE das representações
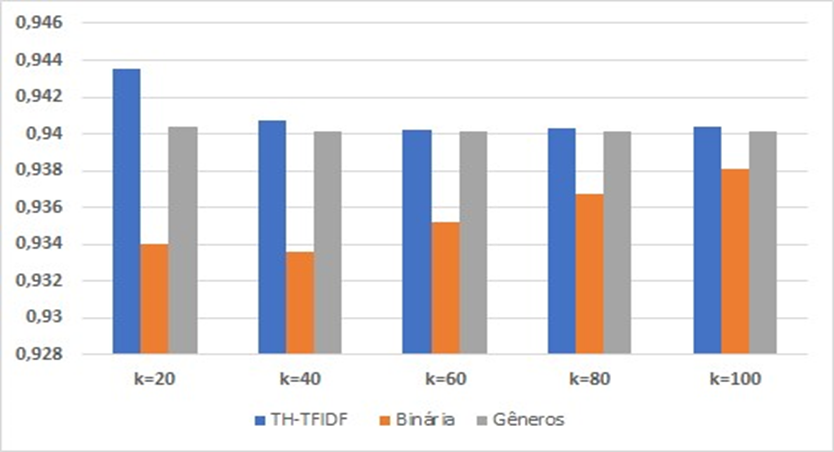
Figura 3: Comparação de resultados de RMSE entre a abordagem proposta e as representações basais
Observe-se que, dentre as três abordagens analisadas, é evidente a superioridade dos resultados obtidos a partir da matriz binária em comparação com as demais. Além disso, nota-se que para os valores de k igual a 40, 60, 80 e 100, os resultados de TH-TFDF e Gêneros são bastante semelhantes, mantendo uma certa estabilidade ao longo da análise,mesmo com o aumento do valor de k, o que pode ser facilmente compreendido através das Figuras 2 e 3.
Podemos igualmente inferir, a partir da Tabela 2 e da Figura 2, que o melhor resultado dentre todas as abordagens analisadas foi obtido para o valor de k igual a 40 na matriz binária, apresentando uma erro quadrático médio (RMSE)de 0,9336. No entanto, após o aumento do valor de k, essa acurácia diminui progressivamente.
Em resumo, o Erro Quadrático Médio (RMSE) é o desvio padrão dos valores residuais (erros de previsão). Os valores residuais são uma medida da distância entre a linha de regressão e os pontos de dados. O RMSE é uma medida da dispersão desses valores residuais. Em outras palavras, ele informa o quão concentrados os dados estão em torno da linha de melhor ajuste.
6 CONCLUSÃO:
Este artigo apresenta um sistema de recomendação baseado em revisões de usuários para uma base de filmes, utilizando a técnica de extração de características dos itens, com o objetivo de estruturar os dados de forma vetorizada para análise. Os resultados demonstram que, em comparação com outras abordagens já utilizadas nesse campo de estudo, foram obtidos valores superiores, melhorando a eficácia de um sistema de recomendação.
Por fim, pretende-se estender a aplicação dessa técnica a outros algoritmos de recomendação que façam uso de representações de itens, incluindo a possibilidade de incorporar, em futuros trabalhos, a análise de sentimentos à proposta atual, a fim de comparar os resultados obtidos com aqueles produzidos neste estudo.
REFERÊNCIAS:
ADOMAVICIUS, G.; TUZHILIN, A. Rumo à próxima geração de sistemas de
recomendação: Um levantamento do estado da arte e possíveis extensões. Conhecimento e Engenharia de Dados, IEEE Transactions on, IEEE, v. 6, pág. 734–749, 2005.
BALABANOVIC, Marko e SHOHAM, Yoav. (1997). Fab: recomendação colaborativa baseada em conteúdo. Comunicações da ACM. 40. 66-72. 10.1145/245108.245124.
BENIN, Keli Rodrigues do Amaral. Processamento de linguagem natural e Ciência da Informação: inter-relações e contribuições. Disponível em: https://repositorio.utfpr.edu.br/jspui/handle/1/32098 . Acesso em: 19 ago. 2023.
BURKE, R. Sistemas de recomendação híbridos: pesquisas e experimentos. Modelagem de usuário e interação adaptada ao usuário, Springer, v. 12, n. 4, pág. 331–370, 2002.
CACHEDA, F.; CARNEIRO, V.; FERNÁNDEZ, D.; FORMOSO, V. Comparação de
algoritmos de filtragem colaborativa: Limitações das técnicas atuais e propostas para sistemas de recomendação escaláveis e de alto desempenho. ACM Trans. Web, ACM, Nova York, NY, EUA, v. 1, pág. 2:1-2:33, fev. 2011. ISSN 1559-1131. Disponível em: < http://doi.acm.org/10.1 145/19215911921593>.
GOLDBERG, D. et al. Usando filtragem colaborativa para tecer uma tapeçaria de informações. Comunicações da ACM, ACM, v. 35, n. 12, pág. 61–70, 1992.
GrupoLens. Conjunto de dados MovieLens 100K. Disponível em: https://grouplens.org/datasets/movielens/100k/ . Acesso em: 31 mar. 2023.
Banco de dados de filmes da Internet (IMDb). Disponível em: https://www.imdb.com/ . Acesso em 31 mar. 2023.
Liu, B., Zhang, L. (2012). Uma Pesquisa de Mineração de Opinião e Análise de Sentimento. In: Aggarwal, C., Zhai, C. (orgs.) Mineração de Dados de Texto. Springer, Boston, MA. https://doi.org/10.1007/978-1-4614-3223-4_13 .
MARINHO, Ronnie Shida. Desambiguação lexical de revisões de itens aplicados em sistemas de recomendação. 2018. Tese de Doutorado. Universidade de São Paulo.
MELVILLE, P.; SINDHWANI, V. Sistemas de recomendação. In: Enciclopédia de aprendizado de máquina. [Sl]: Springer, 2010. p. 829–838.
NGUYEN, LV; VO, Q.-T.; NGUYEN, T.-H. Serviços de recomendação de filtragem colaborativa estendida adaptativa baseada em KNN. Big Data e Computação Cognitiva, v. 7, n. 2, pág. 106, 1º de junho. 2023.
PEZZINI, A. Mineração de textos: conceito, processo e aplicações. Revista Brasileira de
Contabilidade e Gestão, Ibirama, v. 10, pág. 58-61, 2023. DOI: 10.5965/2764747105102016058. Disponível em: https://revistas.udesc.br/index.php/reavi/article/view/6750 . Acesso em: 20 atrás. 2023.
RESNICK, P: IACOVOU, N.; SUCHAK, M.; BERGSTROM, P; RIEDL, J. Grouplens: Uma
arquitetura aberta para filtragem colaborativa de netnews. In: Anais da Conferência
ACM de 1994 sobre Trabalho Cooperativo Apoiado por Computador. Nova York, NY, EUA: ACM, 1994 (CSCW 94), p. 175-186. ISBN 0-89791-689-1. Disponível em: < http://doi.acm.org/10.1 145/192844.192905>.
SANTOS, M. Extraindo regras de associação a partir de textos. Dissertação (Mestrado em Informática Aplicada) – Pontifícia Universidade Católica do Paraná, Curitiba, [Sl], 2002.
VIEIRA, Renata; LOPES, Lucelene. Processamento de linguagem natural e tratamento computacional de linguagens científicas. Corpora, pág. 183, 2010.
Yehuda Koren. 2010. Fator nos vizinhos: filtragem colaborativa escalonável e precisa. Transações ACM sobre descoberta de conhecimento a partir de dados (TKDD) 4, 1
(janeiro de 2010), 1–24.
¹Discente do curso de Tecnólogo em Ciência de Dados da instituição FATEC Adamantina SPe-mail jean975335@gmail.com
²Discente do curso de Tecnólogo em Ciência de Dados da instituição FATEC Adamantina SPe-mail thagoredourado@gmail.com
³Docente do curso de Tecnólogo em Ciência de Dados da instituição FATEC Adamantina SPOrientador, e-mail ronnieshida@gmail.com