REGISTRO DOI: 10.69849/revistaft/fa10202511171501
Gabriel Felipe Baia Gentil1
Samuel Vinícius Pereira de Oliveira2
RESUMO
O avanço recente da Inteligência Artificial (IA) generativa impôs à administração pública o desafio de compreender e regular novas formas de interação homem–máquina. Nesse contexto, este trabalho propõe um protocolo metodológico comparativo entre duas abordagens emergentes de interação com modelos de linguagem de grande escala: a Engenharia de Prompt (EP) e a Engenharia de Contexto (EC). O objetivo é oferecer um modelo científico de referência que permita avaliar, de forma reprodutível e ética, o desempenho de diferentes arquiteturas de IA em tarefas típicas da gestão pública. A metodologia adotada caracteriza-se como qualitativa, exploratória e aplicada, estruturada em seis etapas: (i) levantamento teórico, (ii) seleção dos desafios empíricos de referência (Falconi et al., 2023), (iii) modelagem de casos simulados, (iv) elaboração de prompts controlados, (v) definição dos parâmetros experimentais e (vi) proposição de um plano analítico misto, combinando técnicas qualitativas (análise de conteúdo) e quantitativas (teste de Wilcoxon e métrica Cliff’s δ). O estudo não realiza a execução empírica do experimento, mas estabelece um framework metodológico completo e replicável, apto a orientar futuras pesquisas e aplicações práticas. Os resultados esperados incluem a padronização de critérios de avaliação, a mitigação de vieses de formulação e a criação de uma base conceitual para estudos comparativos sobre desempenho de LLMs na administração pública. A pesquisa encontra-se em conformidade com a Lei nº 13.709/2018 (LGPD) e com as diretrizes do Guia SERPRO/SGD (2025). Conclui-se que o protocolo proposto representa um avanço metodológico significativo, ao alinhar rigor técnico, transparência e aplicabilidade institucional no uso responsável da IA generativa pelo Estado.
Palavras-chave: Inteligência Artificial; Engenharia de Prompt; Engenharia de Contexto; Administração Pública; Metodologia de Pesquisa.
ABSTRACT
The recent advances in Generative Artificial Intelligence (AI) have posed new challenges for public administration, particularly regarding how humans interact with large-scale language models. In this context, this study proposes a comparative methodological protocol between two emerging approaches to human–AI interaction: Prompt Engineering (EP) and Context Engineering (EC). The objective is to establish a scientific and reproducible framework to evaluate the performance of different AI architectures in tasks typical of governmental management. The research is characterized as qualitative, exploratory, and applied, structured into six sequential stages: (i) theoretical review, (ii) selection of empirical challenges (Falconi et al., 2023), (iii) modeling of simulated cases, (iv) elaboration of controlled prompts, (v) definition of experimental parameters, and (vi) proposition of a mixed analytical plan combining qualitative (content analysis) and quantitative (Wilcoxon test and Cliff’s δ effect size) techniques. The study does not execute the experiment itself but instead establishes a comprehensive and replicable methodological framework to guide future applications and empirical validations. Expected outcomes include the standardization of evaluation criteria, mitigation of formulation biases, and the creation of a conceptual basis for comparative studies on the performance of large language models in public administration. The research complies with Brazil’s General Data Protection Law (Law No. 13.709/2018) and the SERPRO/SGD Guidelines (2025). It is concluded that the proposed protocol represents a significant methodological contribution, aligning technical rigor, transparency, and institutional applicability toward the responsible use of generative AI in the public sector.
Keywords: Artificial Intelligence; Prompt Engineering; Context Engineering; Public Administration; Research Methodology.
1 INTRODUÇÃO
O avanço dos modelos de Inteligência Artificial (IA) generativa tem proporcionado transformações expressivas na administração pública brasileira, sobretudo na automação, análise e otimização de processos administrativos e decisórios. Ferramentas como ChatGPT, Gemini, Claude, Copilot e Perplexity utilizam modelos de linguagem capazes de compreender o português natural e gerar relatórios, pareceres e recomendações de alta complexidade. Essas tecnologias, conhecidas como Modelos de Linguagem de Grande Escala (Large Language Models – LLMs), estão se tornando instrumentos estratégicos para a inovação governamental.
Segundo o Comitê Gestor da Internet no Brasil (CGI.br, 2022), aproximadamente metade das instituições públicas federais já utilizam soluções baseadas em IA, o que demonstra o avanço datransformaçãodigitaleacrescentedependênciadesistemasinteligentesparaapoiaraformulação de políticas e a tomada de decisões. Essa realidade evidencia a importância de compreender de que modo diferentes técnicas de interação com modelos de IA podem aprimorar a eficiência e a qualidade das respostas em contextos administrativos.
Entre as metodologias mais promissoras destacam-se a Engenharia de Prompt (EP) e a Engenharia de Contexto (EC). A primeira baseia-se na formulação de instruções diretas, claras e bem estruturadas para orientar o comportamento do modelo. A segunda representa uma evolução dessa lógica, ao ampliar o escopo para incluir elementos adicionais de contexto — como histórico institucional, metas, restrições normativas e perfis de usuários — durante a inferência. Conforme Anthropic (2025) e Liu et al. (2023), a Engenharia de Prompt (EP) foca na clareza das instruções, enquanto a Engenharia de Contexto (EC) fundamenta-se na curadoria das informações relevantes que condicionam a resposta.
Embora a literatura internacional apresente avanços significativos sobre interação homem– IA, como observado em estudos da OpenAI (2023) e Anthropic (2025), ainda existe lacuna de pesquisas empíricas aplicadas ao contexto administrativo brasileiro, especialmente considerando o impacto de restrições legais, como a LGPD, e de práticas institucionais específicas do serviço público.
Diante disso, o problema de pesquisa que orienta este trabalho é formulado da seguinte maneira: de que modo a Engenharia de Prompt e a Engenharia de Contexto diferem em termos de eficácia prática quando aplicadas a tarefas típicas do serviço público?
Parte-se da hipótese de que a Engenharia de Contexto tende a gerar respostas mais consistentes, contextualizadas e aplicáveis em cenários complexos, como a elaboração de relatórios de desempenho, notas técnicas e comunicações oficiais. A Engenharia de Prompt, por sua vez, mostra-se mais eficiente em demandas diretas e rotineiras, como instruções simples, redação padronizada e respostas rápidas.
O objetivo geral consiste em propor e validar conceitualmente uma metodologia comparativa entre EP e EC, identificando seus impactos sobre a qualidade das respostas e o potencial de uso dessas abordagens na administração pública. Como objetivos específicos, propõe-se:
i) descrever as principais características, técnicas e aplicações das engenharias de interação;
ii) aplicar ambas as abordagens a cenários simulados baseados em desafios reais do setor público;
iii) avaliar os resultados segundo critérios de clareza, coerência, aplicabilidade e profundi-dade;
iv) propor recomendações para uso ético e eficiente da IA generativa na gestão pública.
A relevância teórica e social deste estudo decorre de dois fatores principais. O primeiro é a necessidade de aprimorar a eficiência e a transparência da administração pública por meio da adoção responsável de tecnologias emergentes, conforme destacam Brynjolfsson e McAfee (2017) e DIO (2024). O segundo refere-se à urgência de estabelecer diretrizes que assegurem a conformidade das práticas de IA com os princípios da Lei nº 13.709/2018, Lei Geral de Proteção de Dados Pessoais (LGPD), e com o Guia SERPRO/SGD (2025), que recomenda transparência, rastreabilidade e supervisão humana no uso de modelos generativos pela administração pública.
A estrutura deste artigo organiza-se em quatro seções principais. A primeira apresenta os fundamentos teóricos sobre IA generativa e as engenharias de interação. A segunda descreve a metodologia aplicada à pesquisa comparativa. A terceira aborda a discussão e a análise dos resultados obtidos. Por fim, a quarta seção reúne considerações e recomendações para futuras pesquisas e aplicações no contexto governamental.
2 FUNDAMENTAÇÃO TEÓRICA
Esta seção apresenta os fundamentos conceituais e empíricos que sustentam o estudo, abordando a evolução dos modelos de Inteligência Artificial (IA) generativa, os princípios das engenharias de interação — Engenharia de Prompt (EP) e Engenharia de Contexto (EC) — e suas aplicações no setor público. A revisão também contempla trabalhos correlatos e lacunas da literatura que justificam a condução desta pesquisa.
2.1 Inteligência Artificial Generativa e Modelos de Linguagem
A IA generativa consiste em sistemas capazes de produzir novos conteúdos — textos, imagens, sons e códigos — com base em padrões aprendidos a partir de grandes volumes de dados. Goodfellow, Bengio e Courville (2016) apontam que os modelos de aprendizado profundo (deep learning) e as redes neurais transformadoras compõem a base das arquiteturas modernas de IA generativa, permitindo maior generalização e coerência contextual nas saídas.
De acordo com o relatório técnico da Open AÍ (2023), a eficácia dos modelos de linguagem de grande escala (Large Language Models, LLMs) depende diretamente da janela de contexto, ou seja, da quantidade de informações que o modelo consegue processar simultaneamente durante uma interação. Modelos com janelas mais amplas tendem a gerar respostas mais completas e consistentes, uma vez que consideram maior histórico de instruções e variáveis contextuais.
Os LLMs, como ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google DeepMind), Copilot (Microsoft) e Perplexity AI (Perplexity Labs), vêm expandindo suas capacidades multimodais, interpretando não apenas texto, mas também imagens, códigos e voz. No setor público, esses avanços possibilitam a automação de atividades antes restritas à intervenção humana, como elaboração de relatórios, análise de políticas e síntese de documentos administrativos.
2.2 Engenharia de Prompt: definição, técnicas e usos
A Engenharia de Prompt representa o estágio inicial de maturidade na interação entre humanos e modelos de IA, em que a precisão linguística e lógica das instruções define a qualidade das respostas geradas. De acordo com DIO (2024), a Engenharia de Prompt consiste na formulação de instruções diretas, precisas e bem estruturadas. Liu et al. (2023) complementam que a clareza semântica das instruções e a delimitação exata das metas comunicadas influenciam diretamente a qualidade das respostas..
No setor público, a Engenharia de Prompt mostra-se útil em processos como elaboração de ofícios, resumos executivos, minutas de documentos e atendimento automatizado ao cidadão. Segundo a Digital Innovation One (DIO, 2024), as principais estratégias de construção de prompts incluem:
- Role prompting: definição de papéis e níveis de autoridade(por exemplo, “aja como gestor público”);
- Few-shot prompting: apresentação de exemplos de entrada e saída;
- Chain-of-thought prompting: indução de raciocínio passo a passo;
- Restrições de formato (tabelas, relatórios, textos estruturados);
- Critérios de avaliação de qualidade (precisão, concisão, coerência e consistência).
Essas estratégias contribuem para acelerar fluxos de trabalho administrativos, padronizar comunicações e reduzir o tempo gasto em tarefas repetitivas. Entretanto, a ausência de contexto aprofundado (como normas, metas e histórico institucional) pode comprometer a adequação das respostas em situações reais.
2.3 Engenharia de Contexto: curadoria e alinhamento institucional
A Engenharia de Contexto caracteriza-se como uma evolução metodológica em relação à Engenharia de Prompt, pois amplia o escopo da interação ao incluir informações complementares que auxiliam o modelo na compreensão do ambiente e das restrições da tarefa. Conforme Anthropic (2025), a EC compreende o conjunto de estratégias voltadas à manutenção do conjunto ideal de tokens — dados, textos e instruções — durante a inferência do modelo, equilibrando completude e relevância contextual.
Enquanto a EP prioriza a clareza do comando, a EC enfatiza a curadoria das informações contextuais. Liu et al. (2023) destacam que a EC promove maior eficácia interpretativa, alinhando as respostas de IA aos objetivos, valores e políticas institucionais. Na prática, a EC envolve:
i) seleção e priorização de documentos e dados relevantes;
ii) normalização e síntese de informações (resumos e metadados);
iii) inserção de restrições legais (por exemplo, LGPD e normas internas);
iv) gerenciamento de versões e rastreabilidade das fontes utilizadas.
Essa abordagem apresenta relevância especial em ambientes governamentais, onde decisões exigem conformidade com legislação vigente, consideração de contexto histórico e avaliação de impactos sociais. Além disso, conforme Floridi e Cowls (2019), práticas éticas de IA requerem transparência, responsabilidade e rastreabilidade — princípios incorporados de forma mais robusta pela Engenharia de Contexto.
Enquanto estudos como Anthropic (2025) e HELM (2024) descrevem a Engenharia de Contexto como uma extensão da Engenharia de Prompt, outros autores a tratam como um paradigma autônomo, configurando uma “engenharia de segunda ordem”. Essa perspectiva enfatiza que a EC não apenas aprimora a estrutura do texto de entrada, mas também administra o ecossistema informacional em que o modelo opera, incluindo dados, histórico, restrições legais e metas organizacionais.
Essa distinção teórica reflete uma mudança epistemológica: enquanto a EP busca maximizar a clareza linguística, a EC visa otimizar o contexto cognitivo e institucional do modelo, reduzindo riscos de viés e aumentando a aderência semântica das respostas. Conforme Anthropic (2025), “a engenharia de contexto refere-se ao conjunto de estratégias para curadoria e manutenção do conjunto ideal de tokens (informações) durante a inferência de modelos de linguagem, incluindo todas as informações que podem ser incluídas além dos prompts.” (tradução livre).
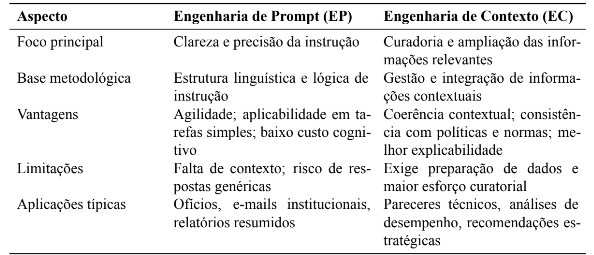
Tabela 1 – Relação conceitual entre Engenharia de Prompt e Engenharia de Contexto

2.4 IA Generativa no Setor Público: oportunidades e diretrizes
Relatórios internacionais destacam benefícios diretos da IA generativa na gestão pública, incluindo aumento da eficiência operacional, ampliação da transparência e aprimoramento dos serviços centrados no cidadão (OECD, 2023). No Brasil, o Guia SERPRO/SGD (2025) reforça esses princípios, recomendando o uso de IA sob supervisão humana e com rastreabilidade total das decisões automatizadas.
Conforme a Falconi et al. (2023), os principais desafios enfrentados pela administração pública envolvem o equilíbrio fiscal, a incorporação tecnológica, a gestão de pessoas, a reforma administrativa, a eficiência do Judiciário e o impacto direto das ações públicas na vida do cidadão. A IA generativa tem potencial para mitigar esses desafios, oferecendo automação de diagnósticos, predição de gargalos e suporte à comunicação interinstitucional.
Silva (2024) e Brynjolfsson e McAfee (2017) ressaltam, entretanto, que a adoção dessas tecnologias exige transformação cultural na gestão pública, centrada em dados, inovação e responsabilidade ética. O levantamento do CGI.br (2022) reforça essa visão ao apontar que a adoção de IA pelo setor público avança de forma desigual, destacando a necessidade de capacitação técnica e integração sistêmica. Falconi, Miranda e Eustáquio (2023) observam que o desafio da digitalização não se limita à infraestrutura, mas também à capacidade institucional de traduzir dados em políticas públicas eficazes e mensuráveis.
O setor público brasileiro enfrenta entraves estruturais que dificultam a plena incorporação da inteligência artificial: burocracia excessiva, lentidão decisória, baixa interoperabilidade entre sistemas, carência de cultura analítica e limitações orçamentárias. Além disso, a ausência de padrões unificados de governança de dados e de capacitação técnica cria barreiras à adoção de tecnologias emergentes. Esses fatores evidenciam que a simples implementação tecnológica não garante inovação efetiva, sendo necessário repensar o desenho institucional e as competências digitais dos servidores.
2.5 Comparativo entre Engenharia de Prompt e Engenharia de Contexto
A Tabela 2 sintetiza as principais diferenças entre as duas abordagens, considerando características, vantagens e limitações observadas na literatura.
Tabela 2 – Comparativo entre Engenharia de Prompt e Engenharia de Contexto
2.6 Considerações Parciais
Com base nos conceitos apresentados, constata-se que a Engenharia de Prompt e a Engenharia de Contexto representam etapas complementares na evolução da interação homem–IA. A EP privilegia eficiência e objetividade, enquanto a EC enfatiza coerência contextual e aderência institucional. Ambas demonstram potencial significativo para aprimorar a gestão pública, desde que aplicadas de forma ética, responsável e orientada a resultados.
Essas distinções fundamentam a análise comparativa proposta neste estudo, cujo foco é compreender a performance de ambas as abordagens em cenários simulados da administração pública brasileira. A próxima seção detalha o delineamento metodológico e as estratégias utilizadas para coleta e análise das respostas produzidas pelos modelos de IA.
3 METODOLOGIA
Esta seção descreve o delineamento metodológico adotado para o estudo comparativo entre a Engenharia de Prompt (EP) e a Engenharia de Contexto (EC), apresentando o tipo e a natureza da pesquisa, as etapas desenvolvidas, a base empírica utilizada, os critérios de coleta e análise dos dados, as limitações e os aspectos éticos e legais envolvidos. O propósito central é garantir transparência e reprodutibilidade, atendendo aos princípios de rigor científico indicados por Gil (2019) e Vergara (2020).
3.1 Tipo e natureza da pesquisa
A pesquisa caracteriza-se como qualitativa, exploratória e aplicada, com abordagem comparativaeprocedimentoexperimentalprevisto. A natureza qualitativa Justifica-se pelo interesse em compreender, de forma interpretativa, como diferentes estratégias de interação influenciam a qualidade das respostas geradas por modelos de IA. O caráter exploratório fundamenta-se na busca por novas perspectivas metodológicas aplicadas à administração pública, enquanto o viés aplicado visa gerar conhecimento com utilidade prática para gestores públicos e desenvolvedores de soluções baseadas em IA generativa.
Conforme Bardin (2016), esse tipo de abordagem é adequada quando o fenômeno estudado é recente, complexo e depende de variáveis contextuais de difícil mensuração. Dessa forma, o estudo adota um recorte comparativo entre duas técnicas emergentes (EP e EC), enfatizando as diferenças de desempenho quando aplicadas a desafios concretos do setor público.
3.2 Etapas metodológicas
O delineamento metodológico foi estruturado em seis etapas interdependentes, documentadas de forma sistemática para garantir rastreabilidade, replicabilidade e consistência analítica. Cada etapa foi concebida de acordo com princípios de pesquisa aplicada descritos por Vergara (2020) e Malhotra (2019).
(1) Levantamento teórico: revisão sistematizada da literatura sobre IA generativa, EP e EC, com ênfase em suas aplicações no setor público;
(2) Seleção dos desafios empíricos: escolha dos desafios propostos pela consultoria Falconi et al. (2023), representativos de problemas de gestão pública contemporâneos;
(3) Modelagem dos casos simulados: formulação de seis situações-problema inspiradas em cenários administrativos reais, contendo objetivos, restrições e indicadores de sucesso;
(4) Elaboração dos insumos de entrada: criação de pares de entradas textuais — prompts diretos (EP) e prompts contextualizados (EC) — redigidos de maneira controlada e padronizada;
(5) Execução experimental: submissão dos conjuntos de entradas a três modelos de IA, sob condições constantes de idioma, temperatura e formato de resposta;
(6) Coleta e análise: organização dos resultados em planilha de coleta padronizada, seguida de avaliação qualitativa e quantitativa segundo critérios de clareza, coerência, aplicabilidade e profundidade.
Tabela 3 – Etapas da pesquisa e objetivos correspondentes

Esse encadeamento metodológico busca assegurar coerência lógica entre a formulação teórica e a experimentação prática, alinhando-se ao modelo de pesquisa aplicada sugerido por Gil (2019).
3.3 Base teórico-empírica
A base teórico-empírica deste estudo fundamenta-se nos seis desafios prioritários do setor público brasileiro identificados pela consultoria Falconi et al. (2023). Esses desafios foram reinterpretados e adaptados como casos simulados para a modelagem dos cenários experimentais comparativos entre Engenharia de Prompt e Engenharia de Contexto, assegurando pertinência temática e coerência metodológica.
3.3.1 Os desafios da Falconi et al. (2023)
A base empírica do estudo fundamenta-se nos seis desafios prioritários do setor público brasileiro identificados pela consultoria Falconi et al. (2023), os quais representam gargalos estruturais e oportunidades de modernização administrativa. Cada desafio foi adaptado para um contexto realista e operacionalizável, garantindo pertinência e aplicabilidade prática.
Tabela 4 – Desafios Falconi et al. (2023) adaptados para o contexto da pesquisa

Cada um desses desafios foi convertido em um case empírico, com variáveis controladas e estrutura padronizada, servindo como base comparativa entre EP e EC.
3.4 Seleção dos modelos de IA
3.4.1 Critérios de seleção
A escolha dos modelos considerou dois critérios principais: (a) capacidade técnica global, medida pelo Epoch Capabilities Index (ECI); e (b) relevância social e adoção nacional, conforme Pacete (2025), que aponta ChatGPT, Gemini e Claude como as mais utilizadas no Brasil. O Epoch Capabilities Index (ECI) é um índice desenvolvido pela organização Epoch AÍ para comparar a capacidade geral de modelos de linguagem de grande escala, em uma escala de 0 a 150 pontos, na qual o modelo de referência (GPT-5) recebe a pontuação máxima. Esse índice agrega o desempenho dos modelos em múltiplas tarefas de raciocínio, compreensão e geração textual, funcionando como uma métrica sintética de maturidade técnica (EPOCHAI,2025). Neste Artigo, o ECI é utilizado apenas para caracterizar a capacidade técnica global dos modelos incluídos no experimento, com base nos valores disponíveis em 4 nov. 2025.
3.4.2 Modelos selecionados
Tabela 5 – Modelos de IA selecionados para o experimento comparativo
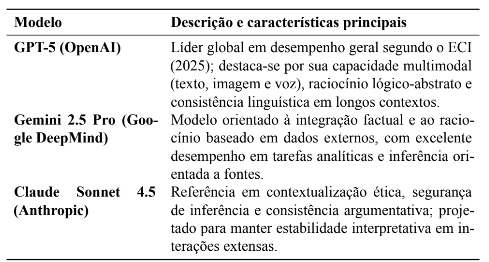
Tabela 6 – Desempenho dos modelos segundo o Epoch Capabilities Index (ECI, nov. 2025)
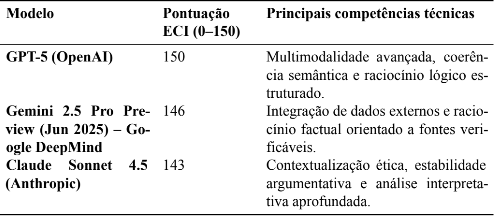
Nota metodológica: As pontuações correspondem aos valores reportados pelo Epoch Capabilities Index (EPOCH AI, 2025) na data da consulta (4 nov. 2025). No presente artigo, os dados são utilizados apenas para caracterizar a capacidade técnica global dos modelos, não constituindo objeto de análise comparativa aprofundada.
3.5 Modelagem dos casos simulados
Com base nos seis desafios propostos por Falconi et al. (2023), foram formulados seis casos simulados representativos de situações administrativas reais. Cada caso busca reproduzir um problema concreto de gestão pública, contendo três componentes essenciais: (i) objetivo operacional; (ii) restrições institucionais; e (iii) indicadores de sucesso.
Esses elementos definem o contexto necessário para aplicação das duas técnicas de interação (EP e EC) de forma padronizada e comparável. A Tabela 7 sintetiza as características de cada caso.
Tabela 7 – Matriz de casos simulados para experimentação com modelos de IA
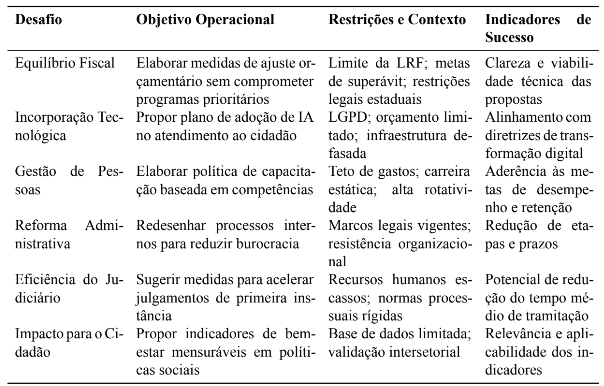
Esses casos simulados funcionam como unidades experimentais controladas, permitindo que os modelos de IA operem sob cenários comparáveis e que as diferenças de desempenho sejam atribuídas às técnicas de Engenharia de Prompt e Engenharia de Contexto, e não às variações temáticas.
3.6 Elaboração dos insumos de entrada (EP e EC)
Para cada caso simulado, foram elaborados dois tipos de insumo textual, denominado Engenharia de Prompt (EP) e Engenharia de Contexto (EC). Ambos partiram do mesmo problema de gestão pública, diferenciando-se pela estrutura e extensão da instrução fornecida ao modelo. A seguir, apresenta-se um exemplo ilustrativo referente ao Caso 1 – Equilíbrio Fiscal.
EP (Engenharia de Prompt):
Elabore três medidas de ajuste orçamentário que reduzam despesas sem afetar programas sociais prioritários.
EC (Engenharia de Contexto):
Você é um analista da Secretaria de Planejamento do Estado do Piauí. Elabore três medidas de ajuste orçamentário que reduzam despesas sem comprometer programas sociais prioritários, em conformidade com a Lei de Responsabilidade Fiscal (Lei Complementar nº 101/2000) e as metas de superávit fixadas na LDO 2025. Apresente as medidas em formato de relatório executivo, com justificativa técnica e impacto estimado.
Os pares completos de instruções textuais utilizados nos seis casos simulados encontram-se descritos integralmente no Apêndice A, com indicação de contagem de palavras e fundamentação teórica de cada instrumento.”
O mesmo procedimento foi aplicado aos demais casos simulados, garantindo padronização na estrutura e no nível de detalhamento das instruções.
3.7 Regras de construção dos instrumentos (EP e EC)
Para assegurar validade de construção na comparação entre Engenharia de Prompt (EP) e Engenharia de Contexto (EC), todos os instrumentos foram elaborados com mesma macroestrutura (i) objetivo da tarefa; (ii) formato exigido de saída; (iii) critérios de qualidade solicitados ao modelo. O contraste entre EP e EC é mantido exclusivamente no conteúdo contextual e na extensão.
3.7.1 Padrões formais e limites de extensão
- EP(EngenhariadePrompt): 80–120palavras; semreferênciasnormativas(LRF,LGPD, CF/88), sem metas (PPA/LDO), sem indicadores ou histórico institucional; foco em instruções claras e formato de saída.
- EC (Engenharia de Contexto): 280–350 palavras; inclui normas aplicáveis (por exemplo, LRF, LGPD, CF/88), metas institucionais (PPA/LDO), indicadores e contexto organizacional relevante.
A contagem aproximada de palavras e a macroestrutura aplicada a cada par de instrumentos constam do Apêndice A. A padronização acima evita pistas de condição por diferenças formais e preserva apenas a dimensão contextual como fator experimental.
3.7.2 Execução experimental prevista
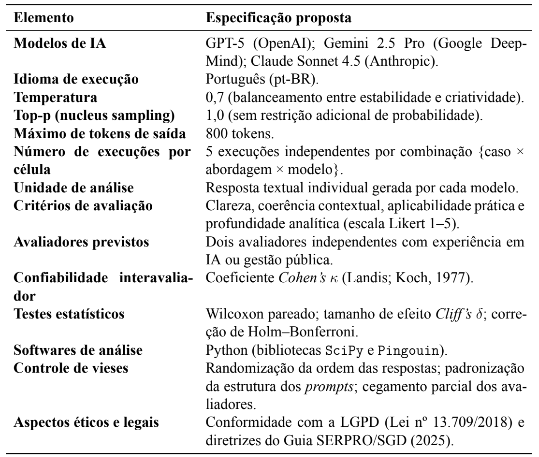
Propõe-se que os prompts elaborados nas modalidades de Engenharia de Prompt (EP) e Engenharia de Contexto (EC) sejam aplicados futuramente aos modelos de Inteligência Artificial (IA) selecionados — GPT-5 (OpenAI), Gemini 2.5 Pro (Google DeepMind) e Claude Sonnet 4.5 (Anthropic) — sob condições controladas e parâmetros padronizados. Cada combinação de caso, abordagem e modelo deverá ser executada em cinco rodadas independentes, mantendo os mesmos valores de temperatura (0,7), top-p (1,0), limite máximo de 800 tokens e idioma português.
Essas execuções comporão o conjunto empírico de respostas a ser avaliado em estudos posteriores. O presente trabalho, portanto, não realiza a geração prática das saídas, mas define de forma estruturada o protocolo metodológico para garantir reprodutibilidade, comparabilidade e rastreabilidade em aplicações futuras.
3.7.3 Coleta e organização dos dados previstos
As respostas geradas pelos modelos, quando o experimento for executado, deverão ser armazenadas em formato texto (.txt) e organizadas em diretórios por caso, modelo e abordagem, conforme estrutura padronizada previamente descrita. Sugere-se o registro sistemático dos seguintes metadados: data e hora da execução, parâmetros do modelo, comprimento da resposta (número de palavras) e número da repetição.
Esses dados deverão ser reunidos em planilha estruturada, contendo as colunas caso, modelo, abordagem, execução, resposta, avaliador A, avaliador B, média e observações. Essa padronização visa assegurar a rastreabilidade do experimento e facilitar análises estatísticas e de conteúdo em pesquisas subsequentes.
3.7.4 Plano de avaliação e análise futura
Propõe-se que as respostas obtidas sejam avaliadas por pelo menos dois especialistas independentes, com experiência em gestão pública e tecnologias de IA generativa. Cada avaliador deveráatribuirnotasde1a5paraosquatrocritériosdedesempenhodefinidos—clareza, coerência contextual, aplicabilidade prática e profundidade analítica — conforme escala Likert.
Para fins de confiabilidade interavaliador, recomenda-se a sobreposição parcial de amostras (10 a 15 respostas comuns) e cálculo do coeficiente de Cohen’s κ. A análise dos dados deverá empregar métodos não paramétricos, como o teste de Wilcoxon pareado (EP × EC) e cálculo do tamanho de efeito (Cliff’s δ), com correção de Holm–Bonferroni para múltiplas comparações.
A aplicação desses testes está prevista como parte do plano de validação empírica futura, enquanto este trabalho se limita à proposição e documentação do protocolo metodológico.
3.7.5 Número de execuções por combinação
Cada combinação {caso, abordagem (EP/EC), modelo} é projetada para ser executada em cinco rodadas independentes, sob parâmetros idênticos. Esse número foi definido como referência metodológica com base em benchmarks recentes de avaliação de modelos de linguagem (HELM Benchmark, 2024; Anthropic Eval Suite, 2024), que recomendam múltiplas repetições para mitigar a variância estocástica inerente a LLMs.
Embora o presente estudo não realize as execuções, essa definição serve como diretriz experimental para futuras replicações. Em aplicações práticas, recomenda-se manter as cinco execuções por célula, documentando eventuais restrições operacionais como limitação metodológica.
3.7.6 Aspectos éticos, legais e de validade
O protocolo experimental proposto está alinhado à Lei nº 13.709/2018 (Lei Geral de Proteção de Dados Pessoais – LGPD) e às diretrizes do Guia SERPRO/SGD (2025), garantindo que nenhuma informação sensível ou identificável seja processada nesta fase, uma vez que o estudo não envolve bases reais de cidadãos ou servidores.
A validade interna do protocolo decorre da padronização dos prompts, do controle dos parâmetros técnicos e da definição prévia dos critérios de avaliação. Já a validade externa dependerá da futura aplicação empírica em cenários administrativos reais, em conformidade com os princípios éticos e legais detalhados na Seção 3.9.
3.7.7 Ameaças à validade
A elaboração do protocolo metodológico permite antecipar possíveis ameaças à validade dos resultados que poderão ser obtidos em futuras execuções do experimento. Essas ameaças foram identificadas com base na literatura sobre avaliação de modelos de linguagem e controle experimental (Romano; Kromrey; Cor, 2006; Anthropic, 2025; Liu et al., 2023) e são classificadas em quatro categorias: interna, externa, de construção e estatística.
a) Validade interna. Refere-se à consistência do desenho experimental. As principais ameaças incluem a variância estocástica dos modelos de linguagem, que podem produzir respostas diferentes sob parâmetros idênticos, e a possibilidade de pistas residuais na formulação dos prompts, capazes de indicar implicitamente a condição (EP ou EC) ao avaliador. O protocolo mitiga esses riscos por meio de múltiplas execuções independentes (cinco por célula), controle de parâmetros técnicos e randomização da ordem de apresentação das respostas.
b) Validade externa. Diz respeito à capacidade de generalizar os achados para outros con-textos administrativos. Como os casos simulados são inspirados em desafios do setor público, mas não baseados em dados reais, reconhece-se que a extrapolação para ambientes institucionais efetivos deve ser realizada com cautela. A replicação do protocolo em diferentes órgãos e níveis de governo será essencial para testar sua robustez.
c) Validade de construção. Relaciona-se à fidelidade entre os conceitos teóricos e sua operacionalização. Eventuais sobreposições entre EP e EC podem ocorrer se um prompt de EP incluir informação contextual indevida ou se um de EC não contiver elementos suficientes de curadoria. Essa ameaça é mitigada pela manutenção de uma macroestrutura idêntica entre as abordagens e pela restrição do contraste ao conteúdo contextual e à extensão do texto (EP: 80–120 palavras; EC: 280–350 palavras).
d) Validade estatística e conclusão. Refere-se à adequação das análises quantitativas e ao controle de erros. O uso de múltiplas comparações entre critérios e casos eleva o risco de erro tipo I, mitigado pela aplicação da correção de Holm–Bonferroni. O número reduzido de execuções por célula (n=5) limita o poder estatístico e pode aumentar a variância amostral; esse fator será tratado em futuras aplicações como limitação metodológica inevitável no uso de LLMs.
3.8 Limitações do estudo
Nota de escopo metodológico. As etapas descritas a seguir correspondem a procedimentos previstos para execução futura, não realizados no presente estudo. Sua inclusão visa assegurar a completude e a reprodutibilidade do protocolo experimental, permitindo que futuras aplicações do método sigam parâmetros e critérios uniformes. O trabalho, portanto, descreve a estrutura conceitual e operacional do experimento, sem geração ou análise empírica de dados nesta fase. Reconhecem-se as seguintes limitações metodológicas: (i) ausência de base pública nacional consolidada sobre a adoção de IA no setor público; (ii) atualizações contínuas dos LLMs, que podem afetar a reprodutibilidade dos resultados; (iii) caráter simulado dos cenários; e (iv) subjetividade parcial da análise qualitativa, mitigada pela padronização dos critérios, presença de dois avaliadores independentes e cálculo de concordância interavaliador (Cohen’s κ).
3.9 Aspectos éticos e legais
Nota de escopo metodológico. As etapas descritas a seguir correspondem a procedimentos previstos para execução futura, não realizados no presente estudo. Sua inclusão visa assegurar a completude e a reprodutibilidade do protocolo experimental, permitindo que futuras aplicações do método sigam parâmetros e critérios uniformes. O trabalho, portanto, descreve a estrutura conceitual e operacional do experimento, sem geração ou análise empírica de dados nesta fase.
O estudo foi conduzido em conformidade com a Lei nº 13.709/2018 (Lei Geral de Proteção de Dados Pessoais – LGPD), observando os princípios de finalidade, adequação, necessidade, transparência e segurança. Além disso, seguem-se as diretrizes do Guia SERPRO/SGD (2025), que enfatiza o uso ético e responsável da IA generativa no setor público, incluindo supervisão humana, registro das decisões automatizadas e mitigação de vieses algorítmicos.
Os princípios de justiça, explicabilidade e rastreabilidade discutidos por Floridi e Cowls (2019) também orientam o protocolo, reforçando o compromisso com a ética, a governança digital e a prestação de contas no uso de modelos generativos em ambientes governamentais.
3.9.1 Delimitação experimental
Embora todos os instrumentos, parâmetros e critérios tenham sido definidos para execução prática, a presente pesquisa adota caráter metodológico e propositivo. Assim, o experimento completo — que envolve a execução dos prompts por múltiplos modelos de IA e a posterior avaliação humana — será conduzido em estudos futuros. Esta delimitação visa consolidar o desenho experimental, garantindo validade conceitual e viabilidade técnica antes da fase empírica. O trabalho, portanto, estabelece as bases metodológicas e os procedimentos padronizados que permitirão a replicação controlada em contextos institucionais reais.
Tabela 8 – Síntese dos parâmetros e condições experimentais previstas
4 PROPOSIÇÃO E ESTRUTURA DE ANÁLISE DE RESULTADOS
Esta seção apresenta a estrutura conceitual de análise proposta para futuras aplicações do protocolo experimental desenvolvido neste estudo. O objetivo não é relatar resultados empíricos, mas descrever os procedimentos analíticos, as métricas e os métodos estatísticos que deverão ser utilizados quando a metodologia for executada. Dessa forma, as subseções a seguir detalham o plano de interpretação dos dados previstos, os critérios de avaliação, o tratamento estatístico e as estratégias de validação dos achados, compondo o arcabouço analítico do modelo proposto.
4.1 Modelo conceitual de análise
A estrutura de análise de resultados delineada neste trabalho fundamenta-se em uma abordagem mista (mixed methods), que combina técnicas qualitativas e quantitativas de avaliação. Essa combinação busca assegurar uma compreensão ampla dos dados produzidos pelos modelos de Inteligência Artificial (IA) generativa sob as abordagens de Engenharia de Prompt (EP) e Engenharia de Contexto (EC).
O modelo conceitual proposto considera três dimensões analíticas principais:
i) Dimensão técnica, que avalia aspectos de clareza, coerência e consistência textual das respostas geradas;
ii) Dimensão aplicada, que considera a utilidade prática e a adequação das respostas a contextos administrativos reais;
iii) Dimensão interpretativa, que verifica a profundidade analítica e a capacidade do modelo de justificar, articular e contextualizar suas inferências.
A Tabela 9 sintetiza o fluxo conceitual de análise, integrando as etapas e respectivas finalidades do processo avaliativo.
Tabela 9 – Fluxo conceitual de análise dos resultados propostos

4.2 Critérios de avaliação qualitativa
Os resultados gerados pelos modelos deverão ser avaliados com base em quatro critérios centrais, definidos a partir da literatura sobre desempenho linguístico e contextual de LLMs (Bardin, 2016; Liu et al., 2023; Anthropic, 2025).
Tabela 10 – Critérios qualitativos propostos para avaliação das respostas

Cada critério deverá ser avaliado em escala Likert de 1 a 5 pontos, onde 1 representa desempenho insuficiente e desempenho excelente. Essa avaliação compõe base de dados qualitativa para a etapa quantitativa subsequente.
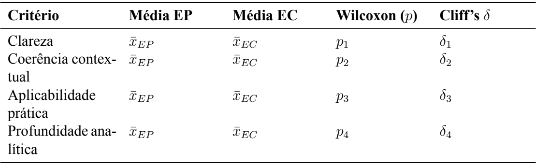
4.3 Estrutura de análise quantitativa proposta
Para mensurar diferenças de desempenho entre as abordagens (EP e EC) e entre os modelos de IA utilizados, propõe-se um conjunto de análises estatísticas não paramétricas, adequadas ao tamanho amostral reduzido e à natureza ordinal dos dados obtidos por meio da escala Likert.
O fluxo analítico quantitativo compreende quatro etapas principais:
(1) Cálculo de médias e dispersões por critério, abordagem e modelo;
(2) Aplicação do teste de Wilcoxon pareado para comparação entre EP e EC em cada critério e caso simulado;
(3) Cálculo do tamanho de efeito por meio da métrica Cliff’s δ, interpretado segundo Romano, Kromrey e Cor (2006);
(4) Correção para múltiplas comparações utilizando o método Holm–Bonferroni, a fim de controlar o erro tipo I.
Os dados deverão ser processados em ambiente Python, com o apoio das bibliotecas SciPy (VIRTANEN et al., 2020) e Pingouin (VALLAT, 2018), garantindo reprodutibilidade estatística. O formato conceitual dos resultados esperados é exemplificado na Tabela 11.
Tabela 11 – Estrutura conceitual de análise estatística proposta
4.4 Interpretação comparativa prevista
A interpretação dos resultados deverá ser conduzida de forma integrada, combinando as evidências quantitativas com a análise de conteúdo das respostas. O propósito é compreender não apenas se há diferença significativa entre EP e EC, mas também em que aspectos cada abordagem se destaca.
Tabela 12 – Síntese conceitual da interpretação comparativa esperada

A discussão deverá articular essas interpretações à literatura de base (particularmente às contribuições de Liu et al. (2023), HELM (2024) e Anthropic (2025)), ressaltando como as tendências observadas confirmam ou ampliam os referenciais teóricos existentes.
4.5 Validação e confiabilidade
A validade interna da análise estará fundamentada no controle de variáveis experimentais e na padronização dos prompts e parâmetros de execução. Recomenda-se o cálculo da confiabilidade interavaliador por meio do coeficiente Cohen’s κ, interpretado conforme Landis e Koch (1977), de modo a garantir consistência na aplicação dos critérios de avaliação.
A validade externa dependerá da replicação do protocolo em contextos administrativos distintos, envolvendo diferentes conjuntos de dados, órgãos públicos ou níveis de governo. O presente estudo estabelece as bases metodológicas para essas futuras replicações.
4.6 Síntese da estrutura analítica
A Tabela 13 apresenta uma visão consolidada do processo proposto de análise, integrando as dimensões qualitativa e quantitativa em um ciclo iterativo de avaliação, comparação e interpretação.
Tabela 13 – Síntese conceitual da estrutura analítica proposta
A estrutura consolidada reforça o caráter metodológico do estudo e permite que futuras pesquisas repliquem protocolos de forma sistemática, validando empiricamente suas premissas. Ao propor um modelo analítico completo, desde a definição dos instrumentos até o plano estatístico, este trabalho contribui para a construção de um referencial científico robusto sobre a aplicação das engenharias de interação (EP e EC) no contexto da administração pública brasileira.
5 CONSIDERAÇÕES FINAIS
O presente trabalho propôs e estruturou uma metodologia comparativa entre as abordagens de Engenharia de Prompt (EP) e Engenharia de Contexto (EC), com foco em sua aplicação à administração pública brasileira. A pesquisa apresentou o delineamento completo de um protocolo experimental reprodutível, capaz de orientar futuras investigações sobre o desempenho de modelos de Inteligência Artificial (IA) generativa em tarefas típicas do setor público, como elaboração de relatórios, pareceres técnicos e diagnósticos administrativos.
A contribuição central desta proposta consiste na formulação de um modelo metodológico robusto e escalável, baseado em princípios de controle experimental, padronização de parâmetros e avaliação multidimensional. Ao definir os instrumentos, as variáveis e os critérios de análise qualitativa e quantitativa, o estudo oferece uma estrutura de referência para pesquisadores e gestores que desejem aplicar metodologias de comparação entre modelos de linguagem em contextos institucionais.
Do ponto de vista teórico, o trabalho reforça o entendimento de que a Engenharia de Prompt e a Engenharia de Contexto representam estágios complementares na evolução da interação homem–IA. A primeira privilegia a precisão e a clareza das instruções, enquanto a segunda enfatiza a curadoria contextual e a coerência institucional das respostas. A consolidação conceitual dessas abordagens permite compreender seus potenciais e limitações, fornecendo subsídios para a formulação de diretrizes éticas e técnicas no uso da IA generativa no setor público.
Sob o ponto de vista metodológico, esta pesquisa se destaca por documentar de forma sistemática o protocolo experimental necessário para avaliar essas abordagens, abrangendo: (i) a elaboração dos prompts em conformidade com parâmetros linguísticos e estruturais; (ii) a definição dos critérios de avaliação humana e estatística; (iii) a proposição de métricas de confiabilidade e de controle de vieses; e (iv) o detalhamento dos instrumentos de análise previstos para futuras execuções. Esses elementos garantem reprodutibilidade, rastreabilidade e consistência científica, aspectos fundamentais em estudos que envolvem modelos probabilísticos complexos.
Reconhece-se, entretanto, que este trabalho se limita à proposição metodológica, não contemplando a execução empírica do experimento. Tal delimitação foi intencional e estratégica, permitindo consolidar uma base conceitual sólida antes da aplicação prática. A execução integral do protocolo (com geração, avaliação e análise das respostas dos modelos) representa o próximo passo natural da pesquisa, capaz de validar quantitativamente as hipóteses levantadas e de fornecer evidências empíricas sobre o desempenho comparativo entre EP e EC.
5.1 Trabalhos futuros
O presente estudo configura-se como uma proposição metodológica destinada à experimentação comparativa entre as abordagens de Engenharia de Prompt (EP) e Engenharia de Contexto (EC) no âmbito da administração pública brasileira. Dessa forma, recomenda-se que as próximas etapas de pesquisa envolvem a execução empírica controlada do protocolo aqui descrito, permitindo validar estatisticamente as hipóteses levantadas e ampliar a compreensão sobre a eficácia relativa de cada abordagem em tarefas típicas de gestão governamental.
As futuras aplicações poderão incluir a realização de experimentos com maior número de repetições por combinação caso, modelo, abordagem, análise estatística aprofundada com testes não paramétricos (Wilcoxon, Cliff’s δ) e avaliação interavaliador por meio de coeficiente de concordância (κ). Além disso, sugere-se a integração do protocolo a ambientes de teste automatizados baseados em frameworks de avaliação de LLMs, como o HELM Benchmark e a Anthropic Eval Suite, favorecendo reprodutibilidade e comparabilidade científica.
Recomenda-se também que as aplicações futuras sejam incorporadas a programas de capacitação e transformação digital na administração pública, contribuindo para o alinhamento institucional e o uso prático dos achados em contextos reais de gestão. Essa integração permitirá que servidores e gestores desenvolvam competências em interação homem–IA, ampliando a eficiência dos processos decisórios e a aderência às diretrizes de governo digital e inovação tecnológica no setor público.
Por fim, sugere-se o desdobramento da metodologia para outras áreas de política pública, como saúde, educação e finanças, a fim de avaliar a aplicabilidade da Engenharia de Contexto em domínios com variáveis altamente reguladas e sensíveis. O avanço dessa linha de pesquisa poderá contribuir para consolidar uma base nacional de boas práticas em IA generativa aplicada ao setor público, promovendo inovação responsável e alinhada à ética e à transparência administrativa.
REFERÊNCIAS
ANTHROPIC. Effective Context Engineering for AI Agents. San Francisco: Anthropic, 2025. Disponível em: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents. Acesso em: 4 nov. 2025.
ANTHROPIC.AnthropicEvalSuite: BenchmarkingResponsibleAISystems. SanFrancisco: Anthropic, 2024. Disponível em: https://www.anthropic.com/research/eval-suite. Acesso em: 3 nov. 2025.
BARDIN, L. Análise de conteúdo. Lisboa: Edições 70, 2016.
BRASIL. Constituição (1988). Constituição da República Federativa do Brasil. Art. 37. Brasília, DF: Presidência da República. Disponível em: https://www.planalto.gov.br/cc ivil_03/constituicao/constituicao.htm. Acesso em: 10 nov. 2025.
BRASIL. Lei Complementar nº 101, de 4 de maio de 2000. Estabelece normas de finanças públicas voltadas para a responsabilidade na gestão fiscal. Diário Oficial da União, Brasília, 5 mai. 2000. Disponível em: https://www.planalto.gov.br/ccivil_03/leis/lcp/lcp101.htm. Acesso em: 10 nov. 2025.
BRASIL. Lei nº 12.527, de 18 de novembro de 2011. Lei de Acesso à Informação (LAI). Diário Oficial da União, Brasília, 18 nov. 2011. Disponível em: https://www.planalto.gov.br/ccivil_03/ _ato2011-2014/2011/lei/l12527.htm. Acesso em: 11 nov. 2025.
BRASIL. Lei nº 13.709, de 14 de agosto de 2018. Lei Geral de Proteção de Dados Pessoais (LGPD). Diário Oficial da União, Brasília, 15 ago. 2018. Disponível em: https://www.planalto.gov. br/ccivil_03/_ato2015-2018/2018/lei/l13709.htm. Acesso em: 10 nov. 2025.
BRASIL. Decreto nº 9.991, de 28 de agosto de 2019. Institui a Política Nacional de Desenvolvimento de Pessoas (PNDP). Diário Oficial da União, Brasília, 29 ago. 2019. Disponível em: https://www.planalto.gov.br/ccivil_03/_ato2019-2022/2019/decreto/D9991.html. Acesso em: 9 nov. 2025.
BRASIL. Decreto nº 10.160, de 9 de dezembro de 2019. Institui a Política Nacional de Governo Aberto (PNGA) e o Comitê Interministerial de Governo Aberto. Diário Oficial da União, Brasília, 10 dez. 2019. Disponível em: https://www.planalto.gov.br/ccivil_0 3/_ato2019-2022/2019/ decreto/d10160.htm. Acesso em: 12 nov. 2025.
BRASIL. Decreto nº 10.332, de 28 de abril de 2020. Institui a Estratégia de Governo Digital 2020–2022. Diário Oficial da União, Brasília, 28 abr. 2020. Disponível em: https://www2.camara.leg.br/legin/fed/decret/2020/decreto-10332-28-abril-2020-7 90138-publicacaooriginal-160559-pe.html. Acesso em: 12 nov. 2025.
BRASIL. Lei nº 14.129, de 29 de março de 2021. Dispõe sobre princípios, regras e instrumentos para o Governo Digital. Diário Oficial da União, Brasília, 30 mar. 2021. Disponível em: https://www.planalto.gov.br/ccivil_03/_ato2019-2022/2021/lei/l14129.htm. Acesso em: 12 nov. 2025.
BRASIL. Lei nº 14.802, de 10 de janeiro de 2024. Institui o Plano Plurianual da União para o período de 2024–2027 (PPA 2024–2027). Diário Oficial da União, Brasília, 11 jan. 2024. Disponível em: https://www.gov.br/planalto/pt-br/acesso-a-informacao/acoe s-e-programas/programas-projetos-obras-acoes-e-atividades/ppa-2024-2027. Acesso em: 11 nov. 2025.
BRASIL. Decreto nº 12.066, de 18 de junho de 2024. Regulamenta a Lei nº 14.802/2024 (PPA 2024–2027). Diário Oficial da União, Brasília, 19 jun. 2024. Disponível em: https://www.planalto.gov.br/ccivil_03/_ato2023-2026/2024/decreto/d12066.htm. Acesso em: 9 nov. 2025.
BRASIL. Decreto nº 12.069, de 21 de junho de 2024. Dispõe sobre a Estratégia Nacional de Governo Digital 2024–2027 e a Rede Gov.br. Diário Oficial da União, Brasília, 24 jun. 2024. Disponível em: https://www.planalto.gov.br/ccivil_03/_ato2023-2026/2024/Dec reto/D12069.htm. Acesso em: 12 nov. 2025.
BRASIL. Decreto nº 12.198, de 24 de setembro de 2024. Institui a Estratégia Federal de Governo Digital 2024–2027 e a Infraestrutura Nacional de Dados. Diário Oficial da União, Brasília, 25 set. 2024. Disponível em: https://www2.camara.leg.br/legin/fed/decret/2024/decreto-12198-24-setembro-2024-796286-publicação original-173095-pe.html. Acesso em: 12 nov. 2025.
BRASIL. Lei nº 15.080, de 30 de dezembro de 2024. Dispõe sobre as diretrizes para a elaboração e a execução da Lei Orçamentária de 2025 (LDO 2025). Diário Oficial da União,
Brasília, 30 dez. 2024. Disponível em: https://www.planalto.gov.br/ccivil_03/_ato 2023-2026/2024/lei/L15080.htm. Acesso em: 9 nov. 2025.
BRYNJOLFSSON, E.; McAFEE, A. The Business of Artificial Intelligence. Harvard Business Review, Boston, 2017. Disponível em: https://hbr.org/cover-story/2017/07/the -business-of-artificial-intelligence. Acesso em: 23 out. 2025.
CGI.br – COMITÊ GESTOR DA INTERNET NO BRASIL. Pesquisa sobre tecnologias emergentes no setor público brasileiro: adoção da Inteligência Artificial. São Paulo: Cetic.br, 2022. Disponível em: https://cetic.br. Acesso em: 22 out. 2025.
CLIFF, N. Dominance statistics: Ordinal analyses to answer ordinal questions. Psychological Bulletin, v. 114, n. 3, p. 494–509, 1993. DOI: 10.1037/0033-2909.114.3.494.
CONSELHO NACIONAL DE JUSTIÇA (Brasil). Resolução nº 325, de 29 de junho de 2020. Dispõe sobre a Estratégia Nacional do Poder Judiciário 2021–2026. Brasília, DF: CNJ, 2020. Disponível em: https://atos.cnj.jus.br/files/original182343202006305efb 832f79875.pdf. Acesso em: 12 nov. 2025.
CONSELHO NACIONAL DE JUSTIÇA (Brasil). Relatório de acompanhamento da Estratégia 2021–2026: jan. — jun. 2025. Brasília, DF: CNJ, 2025. Disponível em: https: //www.cnj.jus.br/wp-content/uploads/2025/07/relatorio-acompanhamento-estrategia-jan-jun-2025. pdf. Acesso em: 12 nov. 2025.
DIO – DIGITAL INNOVATION ONE. Engenharia de Prompt: transformando a Administração Pública no Brasil com IA. São Paulo: DIO, 2024. Disponível em: https://web.dio. me. Acesso em: 25 out. 2025.
EPOCH AI. Epoch Capabilities Index (ECI). San Francisco: Epoch AI, 2025. Disponível em: https://epoch.ai/benchmarks/eci. Acesso em: 4 nov. 2025.
EPOCH AI. Models – Search and Rankings. San Francisco: Epoch AI, 2025. Disponível em: https://epoch.ai/models/search. Acesso em: 4 nov. 2025.
FALCONI, J.; MIRANDA, A.; EUSTÁQUIO, M. Os desafios e as principais tendências no setor público em 2024. São Paulo: Falconi Consultores de Resultado, 2023. Disponível em: https://falconi.com/insight/os-desafios-e-as-principais-tendencias-no-set or-publico-em-2024/. Acesso em: 10 nov. 2025.
FLORIDI, L.; COWLS, J. A unified framework of five principles for AI in society. Harvard Data Science Review, Cambridge, v. 1, n. 1, 2019. Disponível em: https://hdsr.mitpress.mit.edu/ pub/l0jsh9d1. Acesso em: 23 out. 2025.
GIL, A. C. Métodos e técnicas de pesquisa social. 7. ed. São Paulo: Atlas, 2019.
GOODFELLOW, I.; BENGIO, Y. ・ COURVILLE, A. Deep Learning. Cambridge: MIT Press, 2016.
HELM – Holistic Evaluation of Language Models. HELM Benchmark Report. Stanford: Center for Research on Foundation Models (CRFM), 2024. Disponível em: https://crfm.s tanford.edu/ helm/latest. Acesso em: 5 nov. 2025.
LIU, P. et al. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys, v. 55, n. 9, 2023. DOI: 10.1145/3560815. MALHOTRA, N. K. Marketing Research: An Applied Orientation. 7. ed. Harlow: Pearson, 2019.
OECD – ORGANISATION FOR ECONOMIC CO-OPERATION AND DEVELOPMENT. AI in the Public Sector: Principles and Case Studies. Paris: OECD Publishing, 2023. Disponível em: https://www.oecd.org/publications. Acesso em: 23 out. 2025.
OPENAI. GPT-4 Technical Report. San Francisco: Open AIR, 2023. Disponível em: https: //cdn.openai.com/papers/gpt-4.pdf. Acesso em: 25 out. 2025.
ORGANIZAÇÃO DAS NAÇÕES UNIDAS (ONU). Transformando nosso mundo: a Agenda 2030 para o Desenvolvimento Sustentável. Nova Iorque: ONU, 2015. Disponível em: https://brasil.un.org/sites/default/files/2020-09/agenda2030-pt-br.pdf. Acesso em: 12 nov. 2025.
ORGANIZAÇÃO DAS NAÇÕES UNIDAS (ONU). Objetivos de Desenvolvimento Sustentável (ODS): Portal ONU Brasil. Brasília, DF: ONU Brasil, [s.d.]. Disponível em: https: //brasil.un.org/pt-br/sdgs. Acesso em: 12 nov. 2025.
PACETE, L. G. IA já é hábito de 93% dos brasileiros conectados: veja quais são as ferramentas mais usadas. Forbes Tech, São Paulo, 12 jun. 2025. Disponível em: https://forbes .com.br/forbes-tech/2025/06/ia-ja-e-habito-de-93-dos-brasileiros-conecta dos-veja-quais-sao-as-ferramentas-mais-usadas/. Acesso em: 4 nov. 2025.
ROMANO, J.; KROMREY, J.; COR, K.; GRIEBEL, B. Appropriate statistics for ordinallevel data: Should we really be using t-tests and Cohen’s d for evaluating group differences on the NSSE and other surveys? Annual Meeting of the Florida Association of Institutional Research, 2006.
SERPRO – SERVIÇO FEDERAL DE PROCESSAMENTO DE DADOS; SECRETARIA DE GOVERNO DIGITAL (SGD). IA Generativa no Serviço Público: princípios e recomendações. Brasília, 2025. Disponível em: https://www.gov.br/governodigital. Acesso em: 4 Nov. 2025.
SILVA, M. Inteligência Artificial e inovação no setor público: desafios e oportunidades. São Paulo: Editora Tecnologia, 2024.
VALLAT, R. Pingouin: statistics in Python. 2018. Disponível em: https://pingouin-stats.org/. Acesso em: 5 nov. 2025.
VERGARA, S. C. Projetos e relatórios de pesquisa em administração. 18. ed. São Paulo: Atlas, 2020.
VIRTANEN, P. et al. SciPy 1.0: fundamental algorithms for scientific computing in Python. Nature Methods, v. 17, p. 261–272, 2020. DOI: 10.1038/s41592-019-0686-2.
APÊNDICE A – Instrumentos de Experimentação: Engenharia de Prompt (EP) e Engenharia de Contexto (EC)
Caso 1 – Equilíbrio Fiscal
Engenharia de Prompt (EP): Elabore uma proposta de ação para promover o equilíbrio entre receitas e despesas públicas, considerando formas de ampliar a eficiência na arrecadação e otimizar os gastos existentes. A resposta deve conter um título descritivo, até três medidas principais e justificativas breves para cada uma. Utilize linguagem técnica, objetiva e clara, priorizando resultados concretos e recomendações aplicáveis em diferentes contextos administrativos. Evite generalizações, repetições e termos subjetivos. O texto deve manter coesão, precisão terminológica e coerência lógica, limitando-se a aproximadamente 90 a 110 palavras, sem inserir qualquer referência normativa, metas ou contexto institucional.
Engenharia de Contexto (EC): Elabore um relatório técnico apresentando três propostas integradas para promover o equilíbrio entre receitas e despesas públicas, em conformidade com os princípios da eficiência, da transparência e da responsabilidade fiscal previstos na Lei Complementar nº 101/2000 (Lei de Responsabilidade Fiscal – LRF) e no artigo 37 da Constituição Federal. O relatório deve demonstrar como a gestão fiscal pode assegurar a sustentabilidade das contas públicas sem comprometer a continuidade dos serviços essenciais e a ampliação de programas sociais.
O texto deve adotar perspectiva intertemporal, articulando metas anuais do Plano Plurianual (PPA) e da Lei de Diretrizes Orçamentárias (LDO) com resultados de curto, médio e longo prazo. Cada proposta deve conter:
1 Descrição detalhada da medida, incluindo o órgão responsável pela execução e o instrumento normativo necessário (decreto, portaria ou alteração legislativa);
2 Justificativa técnica e fiscal, com base em indicadores como resultado primário, índice de comprometimento da receita corrente líquida e capacidade de investimento;
3 Avaliação de riscos fiscais e mitigadores, contemplando cenários de oscilação econômica, queda de arrecadação ou aumento de despesas obrigatórias.
Inclua ainda parâmetros de monitoramento e avaliação, como o acompanhamento do Resultado Nominal, do Índice de Despesas com Pessoal e dos limites de endividamento. Demonstre de que forma cada proposta contribui para o fortalecimento da governança orçamentária e para a credibilidade das contas públicas perante órgãos de controle e investidores.
O texto deve manter linguagem técnica, impessoal e formal, apresentar estrutura coerente com títulos e subtítulos internos, e conter até 350 palavras, assegurando coerência, rastreabilidade e aderência normativa.
Caso 2 – Incorporação e Aplicação de Tecnologia nos Processos
Engenharia de Prompt (EP): Elabore um plano de incorporação tecnológica destinado a modernizar processos administrativos que ainda dependem de tarefas manuais. Estruture o texto em formato de relatório técnico com um título descritivo, até três etapas principais e uma justificativa breve para cada uma. Indique os resultados esperados e os benefícios para a eficiência institucional. Utilize uma linguagem objetiva, padronizada e clara, priorizando aplicabilidade prática e consistência lógica. Evite qualquer menção a normas, leis ou contextos institucionais. Limite-se a aproximadamente 90 a 110 palavras, assegurando concisão, coesão e foco em resultados mensuráveis e replicáveis em diferentes órgãos públicos.
Engenharia de Contexto (EC):
Elabore um relatório técnico propondo estratégias para acelerar a incorporação e o uso de tecnologias digitais na administração pública, alinhadas às diretrizes da Estratégia de Governo Digital (Decreto nº 10.332/2020), da Lei Geral de Proteção de Dados (Lei nº 13.709/2018) e da Lei nº 14.129/2021 (Lei do Governo Digital). O relatório deve demonstrar como a transformação digital pode elevar a eficiência institucional, reduzir custos operacionais e aprimorar a qualidade dos serviços prestados ao cidadão, sem comprometer a segurança da informação nem a proteção dos dados pessoais.
Cada proposta deve contemplar:
1 Descrição técnica da medida, especificando o processo a ser digitalizado, a tecnologia a ser adotada (como RPA, IA, ou interoperabilidade de sistemas) e o cronograma de implantação;
2 Justificativa administrativa e econômica, evidenciando ganhos de produtividade, redução de retrabalho e otimização de fluxos;
3 Avaliação de conformidade e riscos, considerando aspectos de segurança da informação, aderência à LGPD e necessidade de capacitação dos servidores.
O texto deve incluir indicadores de desempenho, como tempo médio de execução de processos, percentual de automatização de tarefas e índice de satisfação do usuário, além de metas de interoperabilidade com os sistemas estruturantes da União, dos estados ou dos municípios. Demonstre como cada medida pode integrar-se ao PPA 2024–2027 e fortalecer a governança digital em diferentes níveis de governo.
Utilize linguagem técnica, impessoal e precisa, estruturando o relatório de modo coeso e rastreável, com até 350 palavras, assegurando clareza normativa, comparabilidade metodológica e aplicabilidade prática.
Caso 3 – Aperfeiçoamento da Gestão de Pessoas
Engenharia de Prompt (EP): Redija uma proposta de aperfeiçoamento da gestão de pessoas no setor público, enfatizando práticas de valorização profissional e de desenvolvimento de competências digitais. Estruture a resposta em formato de relatório técnico com um título descritivo, até três medidas estratégicas e justificativas curtas para cada uma. As recomendações devem priorizar clareza, aplicabilidade e objetividade, mostrando como podem acelerar a tomada de decisão baseada em dados. Utilize linguagem técnica, concisa e coerente, sem mencionar normas ou órgãos. O texto deve demonstrar consistência lógica e comunicativa, com extensão aproximada de 90 a 110 palavras, assegurando foco e comparabilidade metodológica.
Engenharia de Contexto (EC): Elabore um relatório técnico apresentando três medidas voltadas ao aperfeiçoamento da gestão de pessoas na administração pública, alinhadas à Política Nacional de Desenvolvimento de Pessoas (PNDP – Decreto nº 9.991/2019), à Estratégia Nacional de Governo Digital (Decreto nº 10.332/2020) e aos princípios da eficiência e impessoalidade previstos no artigo 37 da Constituição Federal. O relatório deve demonstrar como práticas de capacitação contínua, gestão por competências e valorização do servidor público podem fortalecer a cultura de inovação e o uso estratégico de dados nas decisões administrativas.
Cada proposta deve incluir:
1 Descrição da medida, especificando o público-alvo, as competências a serem desenvolvidas e o instrumento de gestão utilizado (plano de capacitação, trilhas de aprendizagem ou matriz de competências);
2 Justificativa técnica e institucional, evidenciando a relação entre o investimento em qualificação e a melhoria da eficiência organizacional;
3 Critérios de avaliação e acompanhamento, com indicadores como percentual de servidores capacitados, nível de satisfação funcional e impacto na produtividade administrativa.
O texto deve apresentar abordagem integrada entre desenvolvimento humano e transformação digital, incorporando o uso de plataformas de aprendizagem corporativa e metodologias de ensino baseadas em dados. Deve ainda indicar mecanismos de incentivo à inovação, estratégias de engajamento e práticas de reconhecimento profissional que contribuam para a retenção de talentos e a modernização da cultura organizacional.
Utilize linguagem formal, impessoal e técnica, assegurando precisão terminológica e coerência lógica. A extensão final deve limitar-se a aproximadamente 350 palavras, parâmetro definido para garantir comparabilidade metodológica entre os casos, consistência na densidade contextual e uniformidade analítica na experimentação.
Caso 4 – Reforma Administrativa
Engenharia de Prompt (EP): Elabore um plano resumido de reforma administrativa voltado à melhoria da eficiência e da transparência dos processos internos. O texto deve conter um título informativo, até três ações prioritárias e justificativas breves para cada medida, apresentadas de modo claro e estruturado. Utilize linguagem técnica e objetiva, enfatizando viabilidade e clareza operacional. Evite jargões, redundâncias e referências normativas. Priorize a simplificação de rotinas e o uso de indicadores de acompanhamento. O texto deve manter coesão, precisão e lógica, com aproximadamente 90 a 110 palavras, garantindo padronização metodológica e comparabilidade experimental.
Engenharia de Contexto (EC): Elabore um relatório técnico apresentando três medidas estruturais para promover uma reforma administrativa orientada à eficiência, à transparência e à responsabilização institucional na gestão pública. As propostas devem estar alinhadas aos princípios da Lei nº 14.129/2021 (Lei do Governo Digital), da Lei nº 12.527/2011 (Lei de Acesso à Informação) e do artigo 37 da Constituição Federal, enfatizando a simplificação de processos, a integração de sistemas e a criação de mecanismos de controle interno mais eficazes. O objetivo central é aperfeiçoar a estrutura administrativa, reduzir sobreposições de funções e ampliar a capacidade de entrega do Estado de forma sustentável.
Cada medida deve conter:
1 Descrição técnica da ação, especificando o processo ou setor-alvo, os recursos necessários e o impacto esperado na eficiência administrativa;
2 Justificativa e embasamento, demonstrando o problema identificado e as evidências empíricas que fundamentam a proposta de reestruturação;
3 Critérios de monitoramento, avaliação, com indicadores como tempo médio de tramitação de processos, índice de digitalização de serviços, graduação dos usuários e nível de transparência ativa.
O relatório deve também abordar aspectos de gestão de mudança organizacional, prevendo estratégias de capacitação, comunicação institucional e engajamento dos servidores. É essencial explicitar como as medidas propostas contribuem para o fortalecimento do controle social, o aprimoramento da governança e o alinhamento com os instrumentos de planejamento público, como o PPA 2024–2027 e a LDO.
A estrutura textual deve ser coesa, formal e padronizada, empregando linguagem técnica e impessoal, com foco na viabilidade e mensurabilidade das ações. A extensão final deve limitar aproximadamente 350 palavras, parâmetro definido para assegurar comparação metodológica entre os casos experimentais, equilíbrio na densidade contextual e coerência analítica no conjunto dos instrumentos avaliados.
Caso 5 – Aumento da Eficiência do Judiciário
Engenharia de Prompt (EP): Desenvolve um conjunto de ações destinadas a elevar a eficiência das atividades judiciais, com foco na redução do tempo de tramitação de processos. Estruture o texto em formato de relatório técnico, com um título descritivo, até três iniciativas principais e justificativas resumidas. Utilize linguagem formal e objetiva, destacando a importância da racionalização de fluxos e da adoção de ferramentas de apoio à gestão. Evite menção a órgãos, normas ou legislações. O texto deve apresentar consistência argumentativa, clareza textual e foco em resultados mensuráveis, limitando-se a aproximadamente 90 a 110 palavras, com padronização metodológica.
Engenharia de Contexto (EC): Elabore um relatório técnico propondo três medidas voltadas ao aumento da eficiência do sistema judiciário brasileiro, em consonância com as diretrizes do Planejamento Estratégico do Conselho Nacional de Justiça (CNJ 2021–2026), da Estratégia Nacional do Poder Judiciário e dos princípios da celeridade processual, da efetividade e da transparência previstos na Constituição Federal. O relatório deve demonstrar como a adoção de soluções tecnológicas, a racionalização de fluxos de trabalho e a valorização da gestão de desempenho podem contribuir para a redução do tempo de tramitação dos processos e para o fortalecimento da confiança pública no Poder Judiciário.
Cada medida deve abranger:
1 Descrição técnica e operacional, especificando o problema-alvo (como sobrecarga de demandas ou retrabalho processual), os recursos necessários e o potencial de automatização das tarefas;
2 Justificativa e impacto esperado, evidenciando ganhos de produtividade, qualidade das decisões e eficiência na alocação de recursos humanos e tecnológicos;
3 Indicadores e métricas de desempenho, incluindo parâmetros como tempo médio de tramitação, taxa de congestionamento processual, índice de conciliação e satisfação dos usuários internos e externos.
O texto deve também destacar ações complementares voltadas à capacitação de servidores e magistrados, à integração entre sistemas processuais eletrônicos e à ampliação do uso de inteligência artificial em tarefas de triagem, análise documental e priorização de demandas repetitivas. Deve-se explicitar a importância da governança de dados judiciais, do monitoramento contínuo dos resultados e da interoperabilidade entre tribunais, promovendo maior previsibilidade e eficiência no fluxo de informações.
Utilize linguagem formal, impessoal e técnica, com estrutura coesa e argumentação clara. A extensão final deve limitar-se a aproximadamente 350 palavras, parâmetro estabelecido para garantir comparabilidade metodológica entre os casos experimentais, uniformidade na densidade contextual e rigor analítico no processo de experimentação.
Caso 6 – Geração de Impacto para o Cidadão
Engenharia de Prompt (EP): Elabore uma proposta de gestão voltada para o aumento do impacto positivo das políticas públicas sobre a vida do cidadão. O texto deve apresentar um título objetivo, até três estratégias principais e justificativas curtas para cada uma. Escreva em formato de relatório sintético, com foco na entrega de valor público e na mensurabilidade dos resultados. Utilize Linguagem Técnica, clara e objetiva, evitando exemplos institucionais e menções anormais. O texto deve demonstrar coerência, progressão de ideias e precisão conceitual, limitando-se a aproximadamente 90 a 110 palavras, conforme parâmetros metodológicos definidos.
Engenharia de Contexto (EC): Elabore um relatório técnico apresentando três estratégias voltadas ao aumento do impacto positivo das políticas públicas na vida do cidadão, alinhadas às diretrizes da Política Nacional de Governo Aberto, da Agenda 2030 da Organização das Nações Unidas (ONU) e dos Objetivos de Desenvolvimento Sustentável (ODS). O relatório deve evidenciar como a administração pública pode aprimorar a entrega de valor público por meio de práticas de transparência ativa, participação social e uso intensivo de dados para formulação, monitoramento e avaliação de políticas.
Cada estratégia deve contemplar:
1 Descrição da iniciativa, indicando o público-alvo, a área de política pública envolvida (educação, saúde, mobilidade, etc.) e os mecanismos de atuação previstos;
2 Justificativa técnica e social, demonstrando o problema público a ser enfrentado e os impactos esperados em termos de equidade, eficiência e qualidade de vida;
3 Indicadores de mensuração e resultados, incluindo parâmetros como índice de satisfação do cidadão, nível de transparência de dados, percentual de execução orçamentária vinculada a resultados e grau de engajamento social.
O texto deve ainda demonstrar como a integração de plataformas digitais, dados abertos e mecanismos de escuta ativa pode fortalecer a governança participativa e promover maior alinhamento entre prioridades governamentais e necessidades reais da população. Recomenda-se evidenciar a importância do uso de ferramentas de inteligência artificial e análise de dados para antecipar demandas, otimizar recursos e aumentar a efetividade das ações públicas.
Empregue linguagem formal, técnica e impessoal, mantendo coesão, objetividade e clareza comunicativa. A extensão final deve limitar-se a aproximadamente 350 palavras, parâmetro definido para assegurar comparabilidade metodológica entre os casos experimentais, uniformidade na densidade contextual e consistência analítica na avaliação dos resultados.
Fonte: Elaborado pelo autor (2025). Todos os instrumentos seguiram macroestrutura comum e limites de extensão definidos na Seção 3.7.1, assegurando comparabilidade experimental.
1Graduando em Engenharia de Software, iCEV – Instituto de Ensino Superior, Teresina (PI) – Brasil. E-mail: gabriel_felipe.gentil@somosicev.com.
2Docente do iCEV – Instituto de Ensino Superior, Teresina (PI) – Brasil. E-mail: samuel.oliveira@grupocev.com