SCHOOL PERFORMANCE PREDICTION USING MULTILAYER PERCEPTRON
REGISTRO DOI: 10.5281/zenodo.12679995
Lucas Gabriel do Carmo Pereira1
Marcos César da Rocha Seruffo2
Resumo
Com a evolução e constante desenvolvimento da tecnologia ao passar dos anos, várias técnicas vêm sendo criadas e utilizadas com cada uma fazendo-se útil e proveitosa dependendo do contexto em que estiver empregada. Entre suas diversas áreas de atuação, no intuito de melhor prever e classificar sua competência no magistério de diversas instituições, a utilização de Redes Neurais Artificiais, em especial os modelos de previsão, vem apresentando potencial no meio acadêmico para identificação do desempenho de seus alunos ao longo do período letivo, dessa forma a mesma por consequência determina sua própria eficiência quanto a sua capacidade de ensino. Afim de obter o cenário mencionado anteriormente, foi utilizado neste estudo um modelo perceptron de multicamadas para prever e determinar o desempenho de 650 alunos de uma escola secundária em Portugal e assim classificar suas performances em “baixo”, “médio” e “alto”, determinando dessa forma, a competência da instituição de ensino ao todo quanto a sua qualidade de ensino e suporte a alunos dos grupos de risco. Os resultados apontaram uma acurácia de 86.08% para o desempenho dos alunos na matéria de matemática e 80.77% para a matéria de português, com os respectivos valores extraídos de uma matriz correspondente a cada matéria analisada, ao mesmo tempo, foi plotado dois gráficos de erro médio quadrático para analisar o comportamento do erro de treino e validação. Por fim, foi concluído que o modelo apresenta potencial para previsão e desempenho escolar com a base de dados utilizada apesar de apresentar espaço para futuras melhorias em sua arquitetura.
Palavras-Chave: Desempenho. Rede Perceptron Multicamadas. Previsão.
1. Introdução
A retenção de alunos em uma instituição, de acordo com Will et al. (2019), mostra-se diretamente relacionada com seu desempenho acadêmico. Neste contexto, identificar as variáveis responsáveis pela eficiência do estudante ajudam as instituições a prover o suporte assim como uma educação personalizada aos grupos docentes que fazem parte dessa zona de risco, a fim de otimizar o desempenho dos colegiais envolvidos. De um modo geral, as causas para uma queda na produtividade acadêmica são complexas, a qual são causadas por uma série de fatores econômicos e sociais que afetam diretamente a vida do estudante e o desempenho insatisfatório nas disciplinas cursadas(SOUZA; ARAUJO, 2021). Como foi destacado em Rodrigues et al 2024, a mineração de dados educacionais (Educational Data Mining, EDM) Lucas Gabriel do Carmo Pereira, Engenharia Elétrica, Faculdade Estácio, luccasg.pereira@gmail.com se preocupa no desenvolvimento, pesquisa e aplicação de técnicas de aprendizado de máquina para detectar padrões em grandes coleções de dados educacionais que ajudem a otimizar o processo de ensino nas escolas, entre estes trabalhos, vale destacar diversos estudos cujo intuito seja prever e melhorar o processo de aprendizagem nas instituições com baixa eficiência, tal como foi feito em Benevento et al. (2023) na qual foi feito uma pesquisa envolvendo a utilização de algoritmos de aprendizado de máquina em conjunto com ChatGPT para prever e melhorar o desempenho dos alunos do colégio estudado. A experiência em questão foi submetida a 900 alunos em 21 algoritmos com este estudo sendo de caráter quantitativo com base em técnicas variadas e experimentais, da mesma forma, em Pereira et al. (2020) foi feito um mapeamento sistemático de literaturas dos anos de 2009 a 2019 com objetivo de caracterizar estudos que propuseram métodos relacionados com previsão de desempenho em ambientes computacionais para turmas de computação, explorando técnicas de aprendizado de máquina e mineração de dados fazendo inferências por meio de modelagens dos perfis dos estudantes. Já em outros trabalhos como em Trombini et al. (2017) foi realizado um estudo sobre causas de evasão escolar, o qual foi constatado que o histórico escolar, as baixas expectativas para a conclusão do curso, as experiências sociais vividas em sala de aula assim como uma série de fatores externos e principalmente sociais são elementos essenciais que fazem parte do cenário de baixo desempenho construído. Por fim, em Souza et al. (2021) é feito o relacionamento a evasão escolar como comportamento reação natural a diversas mudanças e desafios enfrentados no âmbito escolar, com estes problemas presentes tanto dentro quanto fora das instituições.
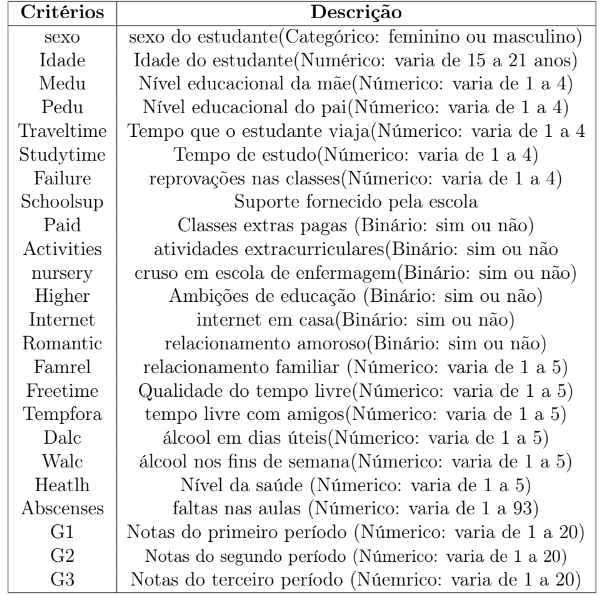
No caso deste estudo foi utilizado um repositório com dados de desempenho escolar de alunos de escola secundária em Portugal, com a base de dados dividida entre as matérias de português e matemática. As informações foram recolhidas de duas formas diferentes, com a primeira sendo questionários e a segunda respostas marcadas, devido a inicialmente o número de dados conter informações escassas, uma segunda coleta de dados foi realizada, o que permitiu o recolhimento de diversos aspectos demográficos, sociais e escolares do grupo de estudo alvo tais como, consumo de álcool em dias úteis, envolvimento em relacionamentos amorosos, nível de escolaridade dos pais, nível de suporte familiar e afins. O objetivo final baseia-se na ideia de, através da análise dos dados coletados e emprego de modelos Perceptron de multicamadas, prever as notas finais dos alunos estudados em cada matéria(matemática e português) e classificar seu desempenho final em 3 classes: “Baixo”, “Médio” e “Alto” com o objetivo de determinar a qualidade da instituição de ensino responsável pelo processo de aprendizagem de seus docentes assim como medir o nível de suporte necessário aos alunos com baixas classificações. Para tal, as duas matérias foram separadas em um total de 32 critérios, entretanto, com objetivo de consolidar uma maior estabilidade na classificação de dados numéricos, foram considerados 24 critérios a qual os modos de classificação foram:
i) classificação binária(obtidos por meio de questionários de “sim” ou “não”)
ii) Classificação por variação de níveis(geralmente variando de 0 ou I – Muito baixo a 4 ou 5 – Muito alto)
iii) Classificação com saída que varia com um percentual de 0% a 100%
Neste caso, os 24 critérios mencionados anteriormente foram distribuídos paras as três classes citadas acima, como, por exemplo, para a classificação i) foi atribuído o critério “você possui internet em casa?”, para a classificação ii) foi atribuído o critério “nível de relação com a família” que varia de 1 a 5 e para a classificação iii) foi atribuído o critério “Número de faltas” e assim sucessivamente para os outros dados empregados.
2. Materiais e Métodos
Conforme as informações de Corrtez et al. (2008), em Portugal, as escolas secundárias duram um período de 3 anos, precedendo os 9 anos de educação básica anteriores, seguido por um nível maior de ensino. Nesta etapa escolar, destacando a característica livre deste sistema educacional, os alunos são incentivados a se inscreverem em diversos cursos extracurriculares, tais como ciências da tecnologia e linguagens visuais, os quais possuem temas comuns com as matérias de português e matemática. Nestes cursos é utilizado, assim como em países como França e Venezuela, uma grade de notas que varia de 0 a 20 pontos, no qual 0 seria o desempenho mais baixo e 20 o desempenho mais alto, de modo semelhante, durante o período letivo a avaliação dos docentes ocorre em 3 séries, sendo estas G1, G2 e G3 com a última sendo influenciada pelos valores anteriores.
O estudo considerou dados coletados no período de 2005 a 2006 de duas escolas públicas da região de Alentejo em Portugal, vale notar-se que apesar dos avanços recentes ocorridos devido a investimentos do governo no âmbito da tecnologia da informação, grande parte das escolas apresentavam um sistema de informações muito defasado com algumas ainda fazendo uso de folhas de papel para coleta e armazenamento de dados. Dessa forma, a coleta de dados foi feita a partir de duas fontes: Relatos escolares o qual foram feitos com o uso de levantamentos escritos que incluíam uma série de perguntas e atributos dos docentes como, número de faltas, idade e notas nas séries cursadas; e questionários cujo intuito foi a complementação das informações coletadas anteriormente. Entre os questionamentos levantados foram feitas questões com resultados com variações pré-definidas e de caráter demográfico como, nível de escolaridade dos pais, consumo de álcool e relações familiares, assim como questões referentes à situação escolar do estudante questionado como por exemplo, número de reprovações, suporte fornecido pela escola e afins. Os questionários foram inicialmente revisados por uma série de professores e aplicados a um pequeno grupo de 15 estudantes no objetivo de analisar seus resultados, já para a versão final, foram criados inquerimentos contendo 37 questões em uma única folha de papel A4, a qual foram entregues e respondidas por 788 alunos. Posteriormente, durante a apuração dos resultados, 111 inquerimentos foram descartados devido a falta de identificação nos mesmos, devido à identificação ser essencial para cruzar os dados com as informações das escolas. Por fim, os dados analisados foram separados em dois databases: O primeiro para desempenho na matéria de matemática e o segundo para a matéria de português, com 395 exemplos e 650 registros respectivamente.
Ao longo do processamento dos dados utilizados no modelo, foram desconsiderados alguns critérios referentes a informações demográficas a qual possuíam certo grau de abstracionismo em seus dados, e por consequência, alta variação de seus dados numéricos, tais como, tipo de profissão dos pais, tamanho da família, endereço, guardiões e afins, referências essas que contribuem para instabilidade dos modelos, visto que este estudo busca analisar apenas os dados com certa estabilidade em sua linha de resultados. Dessa forma, os referenciais mencionados foram organizados na tabela abaixo:
2.1 Modelo Perceptron de multicamadas
No intuito de prever e classificar o desempenho dos alunos com base nos dados da tabela 1, foi empregado o modelo de classificação mediante o emprego de uma Rede Neural Perceptron de Múltiplas Camadas (MLP), este modelo é amplamente utilizado para solução de problemas mais complexos, fornecendo paradigmas de aprendizagem supervisionada em que uma informação prévia já seja apresentada a rede (SILVA, 2020), além de possuírem uma arquitetura simples que atende a estrutura do problema, visto que de acordo com Silva et al.2023: Redes Perceptron Multicamadas com uma ou duas camadas ocultas são suficientes para a resolução de qualquer problema não-linear. Entre suas características está o fato da natureza de seu processo ser de análise unidirecional, da qual dá-se início pelos neurônios de ativação da entrada e passando pelas camadas intermediárias até os valores de saída desejados (GONZÁLEZ; ARAÚJO; JUNIOR, ) além da mesma geralmente possuir, no mínimo, 3 camadas conectadas umas às outras, assim como neurônios com funções de ativação capazes de conceber relações não-lineares dos valores de saída com os valores de saída previstos(PEREIRA; COUTO, 2021).
Table 1: Dados de comportamento de onda da ilha de Mexiana.
Fonte: retirado de Cortez et al.2008
2.2 Setup do modelo
Tendo como base as informações anteriores, foi feito o uso de 3 camadas densas totalmente conectadas com cada uma contendo suas respectivas funções de ativação, nas quais as duas primeiras são as camadas ocultas que contém a função ReLu, cujo a qual seu encargo é prover a não-lineariedade do processo, e a última não menos importante, a camada de saída que contém a função softmax responsável por classificar e fornecer as probabilidades para as classes de saída, com cada uma das respectivas camadas citadas possuindo seus referentes números de neurônios, os quais 64 e 32 para as camadas ocultas e 3 neurônios na camada de saída para cada classe que o modelo está tentando prever. O modelo foi treinado por 50 épocas, porém a fim de evitar o overfitting, foi implementado um critério de parada cruzada caso o erro na base de validação não melhores após 5 épocas consecutivas, juntamente a essa medida, foi feita a separação dos dados em em 60% para o treinamento, 20% para validação e 20% para teste. Essas medidas visam evitar o overfitting da rede e prover melhor robustez para o modelo e impedir o mesmo de continuar treinando desnecessariamente após atingir seu melhor desempenho na base de validação. As classificações foram separadas em duas classes: A primeira para a matéria de matemática e a segunda para a matéria de português, da qual foram extraídas as matrizes de confusão com a devida acurácia de cada classe.
3. Resultados e discussões
O modelo empregado no estudo foi executado no Google Colab Notebook e contou 50 iterações para cada respectiva matéria, analisando seus valores de perda e acurácia ao longo do processo. Os resultados foram separados em dois conjuntos de dados, com um conjunto para português e outro para matemática, ambos foram analisados quanto aos seus desempenhos individuais e uma matriz de confusão e gráficos de erro médio quadrático foram gerados para cada conjunto.
3.1 Resultados de matemática
Para o acervo de resultados no que concerne a matéria de matemática, foi constatado inicialmente nos dados de treinamento, mais especificamente na época 1 uma perda inicial alta de 1,1135 e uma baixa acurácia de 0.3882, entretanto, ao longo do processo houve uma significativa redução da perda e um aumento na acurácia, culminando na época 17 os respectivos valores estabilizados de 0,0693 e 1,000 respectivamente para os dados de treino e uma perda de 0.9543 e acurácia de 0,6076 nos valores iniciais seguido por uma diminuição na perda para 0.4620 e estabilização de 0,8228 para acurácia nos valores de validação, ao fim, foi gerada uma matriz de confusão para a referente matéria.
Figure 1: Matriz de confusão de Matemática
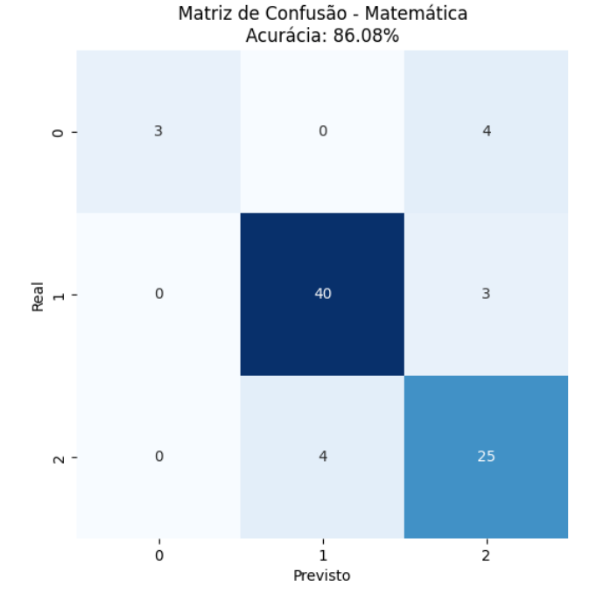
Fonte: Elaborado pelo autor
Na figura 1 acima é possível notar que entre as amostras de classe 0, 3 foram preditas corretamente com uma erroneamente classificada como 2, na classe 1 houve um desempenho bom com 43 das amostras analisadas obtendo 40 previsões corretas e por fim, na classe 2 houve um desempenho razoável com 25 das 29 amostras sendo previstas corretamente. Na parte que concerne o erro quadrático médio, um gráfico foi gerado.
Ao analisar-se a figura 2, nota-se uma consistente diminuição do erro ao longo das épocas, o que indica um bom progresso no processo de aprendizado do modelo, por outro lado, na curva de validação há uma diminuição da mesma seguida por sua estabilização e até mesmo uma ligeira elevação, o que sugere que o modelo pode estar sofrendo de overfitting, situação esta em que a rede está se adaptando demais as informações treinadas, o que causa uma errônea generalização de seus novos dados. No geral, após as informações anteriores terem sido avaliadas, foi apontado que o modelo possui boa capacidade de aprendizado com muitas previsões corretas para a classe “baixo” e “médio”, fato esse reforçado por sua alta acurácia de 86.09%, entretanto, o mesmo apresenta alguns equívocos entre as classificações de “médio” e “alto” assim como sinais de possível overfitting, especialmente nas épocas finais de treinamento, indicando que o modelo pode estar um pouco sobreajustado aos dados de treino.
Figure 2: Erro quadrático médio para matemática
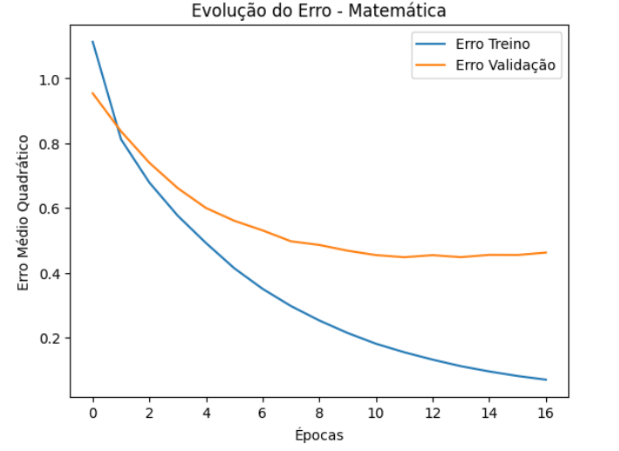
Fonte: Elaborado pelo autor
3.2 Resultados de Português
Para os resultados da matéria de Português foi verificado nas épocas iniciais uma perda de 0.9831 e acurácia de 0,5270 juntamente com uma baixa contínua resultando nas épocas finais em uma estabilização da perda em 0.0688 e acurácia máxima de 1.000 para os valores de treinamento, e valores de 0.9831 e 0.5270 nas épocas iniciais e 0.3816 e 0.8077 para os respectivos parâmetros mencionados para os números de validação, seguido pela geração de uma matriz de confusão e um gráfico de erro quadrático para a referente matéria.
Ao examinar-se a figura 3 é possível identificar um desempenho razoável para especificações de classe 0, com 22 de 28 amostras classificadas corretamente, competência boa para classificações de classe 1, na qual houve previsões semelhantes à classe 0, com 27 acertos de 33 resultados previstos e por fim a classe 2 com o maior número de erros quanto a categorização dos exemplares, de modo que houve 56 acertos em 69 previsões. Quanto ao que concerne o erro médio quadrático, o seguinte gráfico foi criado:
Estudando o gráfico da figura 4 acima, nota-se que o erro de treino diminui rapidamente no início e logo em seguida diminui constantemente com o passar das épocas, sugerindo uma boa taxa de aprendizado a partir dos dados de treinamento, já para a curva de validação há uma atenuação inicial de seus valores, mas logo após isso o modelo aparentemente atinge um ponto de saturação, no qual percebe-se que a rede não consegue melhorar seu desempenho. Essa saturação não apresenta sinais claros de overfitting mas é nítido que a rede esta pode não estar capturando todos os dados corretamente. Em uma visão geral o modelo apresenta uma boa melhoria em seu aprendizado ao longo das épocas, apresentando bons resultados de classificações para as classe “baixo” e “médio” e atingindo uma acurácia de 80.77%, valor esse que pode ser considerado aceitável, todavia, o mesmo manifesta confusões mais frequentes entre as classes “médio” e “baixo” e entre “alto” e “médio”, indicador claro que o modelo está com dificuldade em distinguir entre as classes e possivelmente subajustado para o problema apresentado.
Figure 3: Matriz de confusão de Português
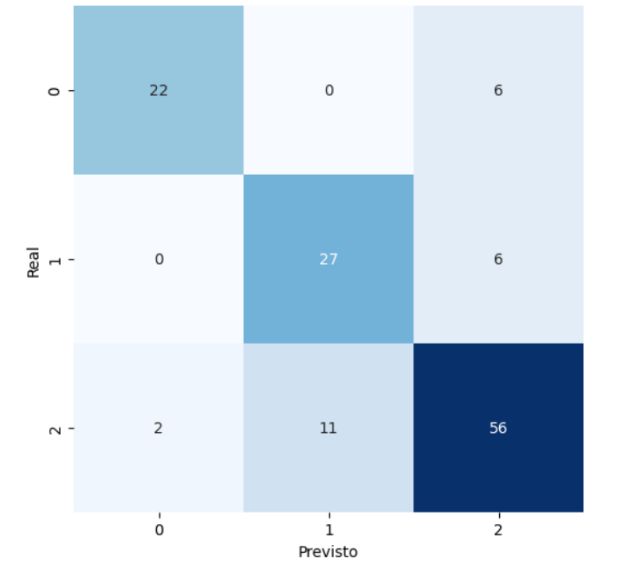
Fonte: Elaborado pelo autor
Figure 4: Erro quadrático médio para português
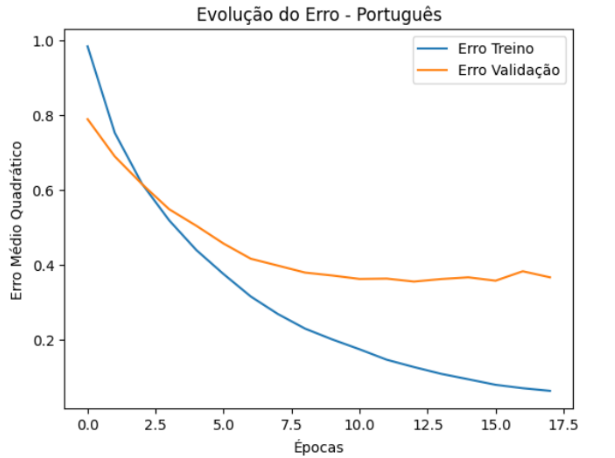
Fonte: Elaborado pelo autor
4. Conclusões
Visto que, no processo inicial de configuração dos parâmetros empregados houve a retirada de outras variáveis, concului-se que modelo utilizado apresenta resultados promissores para aplicações futuras quanto a classificação do desempenho dos alunos em classes distintas, apresentando taxas de acurácia aceitáveis, com acurácia de 86.08% para matemática e 80.77% para português, vale notar também o fato da rede neural utilizada, sendo essa a perceptron de multicamada, ter relativa aptidão para esses tipos de problema, con tribuindo para as performances citadas anteriormente, porém, a rede também apresenta problemas de quanto a seus dados de treinamento, como foi o caso de overfitting para o modelo referente a matéria de matemática e o subajuste para o modelo de português. Esses problemas podem ser corrigidos, em experimentos futuros, com a implementação de técnicas de regularização como dropout e L2 regularization a fim de combater o over fitting, aumento do dataset com o emprego de mais questionários em mais rede de escolas para dessa forma aumentar a robustez do modelo assim como o ajuste de alguns parâmetros de para melhorar a previsão das categorias, em especial as classes “médio” e “alto” que apresentaram o maior número de equívocos durante os treinamentos. Se essas configurações forem realizadas, certamente haverá um melhoramento significativo do modelo e por consequência mais espaço para a implementação do mesmo no âmbito acadêmico.
Referências
BENEVENTO, M.; MEIRELLES, F. de S. Prever e melhorar o desempenho dos alunos com o uso combinado de aprendizagem de máquina e gpt. Revista de Gestão e Avaliação Educacional, p. e74348–22, 2023.
CORTEZ, P.; SILVA, A. M. G. Using data mining to predict secondary school student performance. EUROSIS-ETI, 2008.
GONZÁLEZ, A. V.; ARAÚJO, G. L. S.; JUNIOR, F. E. Previsão do comportamento da resistência na interface areia/geomembrana mediante a aplicação de rede neural artificial.
PEREIRA, D. M.; COUTO, R. S. Predição de métricas em grafos temporais utilizando redes neurais. In: SBC. Anais do XX Workshop em Desempenho de Sistemas Computacionais e de Comunicação. [S.l.], 2021. p. 84–95.
PEREIRA, F. D. et al. Predição de desempenho em ambientes computacionais para turmas de programação: um mapeamento sistemático da literatura. Anais do XXXI Simpósio Brasileiro de Informática na Educação, SBC, p. 1673–1682, 2020.
RODRIGUES, L. S. et al. Transformers para previsão de desempenho acadêmico no ensino fundamental e médio. Revista Brasileira de Informática na Educação, v. 32, p. 213–241, 2024.
SILVA, A. T. Y. L. et al. Aplicação de redes neurais multicamadas associadas a algoritmos genéticos aplicados a operação de redes de distribuição de água com vistas à eficiência hidroenergética em cidades inteligentes. Universidade Federal de Itajubá, 2023.
SILVA, J. P. d. O. Aplicação de redes neurais artificiais do tipo perceptron para previsão da condutividade hidráulica em solos não saturados. 2020.
SOUZA, F. G. d. C. Previsão de evasão e retenção escolar no ensino médio profissional: uma abordagem baseada em redes neurais artificiais. 2021.
SOUZA, F. G. da C.; ARAUJO, R. de A. Previsão de evasão e retenção no ensino médio profissional: Uma abordagem baseada em redes neurais. Revista Semiárido De Visu, v. 9, n. 1, p. 53–64, 2021.
TROMBONI, J.; OLEGARIO, F.; LAROQUE, L. As políticas para o ensino médio na realidade brasileira: uma agenda em disputa. Revista Intersabes, v. 12, n. 25, p. 144–151, 2017.
WILL, N. N.; KEMCZINSKI, A.; PARPINELLI, R. Deep learning para previsão do desempenho do estudante: Um mapeamento sistemático da literatura. In: Brazilian Symposium on Computers in Education (Simpósio Brasileiro de Informática na Educação-SBIE). [S.l.: s.n.], 2019. v. 30, n. 1, p. 1798.
1Lucas Gabriel do Carmo Pereira Engenheiro Elétrico da Faculdade Estácio de Belém, email: luc casg.pereira@gmail.com
2Marcos César da Rocha Seruffo Docente e Pós-Doutorando do Curso Superior de Engenharia Elétrica da Universidade Federal do Pará, email: seruffo@ufpa.br