REGISTRO DOI: 10.69849/revistaft/fa10202408051918
Milton Garcia Monteiro,
Orientador: Prof. Dr. Mauro Sérgio Silva Pinto,
Co-orientador: Prof. Dr. Cícero Costa Quarto
RESUMO
Policiamento preditivo é um conceito baseado na premissa de que é possível prever quando e onde crimes ocorrerão novamente no futuro, usando análise computadorizada sofisticada com base em dados sobre crimes anteriormente cometidos (UCHIDA, como citado em NORTON, 2013, p. 32–33). O objetivo deste artigo é analisar a previsão espacial de crimes, destacando a importância de abordagens inovadoras no campo da gestão em segurança pública. Especialmente, o artigo explora aplicações práticas do uso da Inteligência Artificial (I.A) usando algoritmos de aprendizado de máquina supervisionado para classificação, utilizando como insumo a base de dados de registros de chamadas emergenciais (190) de roubo na região metropolitana de São Luís, comparando resultados por meio de técnicas de validação para o algoritmo Random Forest. Através da análise detalhada desses dados, procura-se ilustrar o potencial do policiamento preditivo para não apenas antecipar eventos criminais, mas também, o desenvolvimento de uma ferramenta computacional capaz de auxiliar e apoiar nas tomadas de decisões estratégicas, contribuindo significativamente no gerenciamento de alocação de tropas e, consequentemente, no aprimoramento dos serviços de patrulhamento urbano preventivo.
Palavras-chave: Inteligência Artificial, Policiamento Preditivo, Análise Criminal, Aprendizado de Máquina, Ciência de Dados, Roubo.
SUBSTRACT
Predictive policing is a concept based on the premise that it is possible to predict when and where crimes will occur again in the future by using sophisticated computer analysis based on data from previously committed crimes (UCHIDA, as cited in NORTON, 2013, pp. 32–33). The aim of this article is to analyze the spatial prediction of crimes, highlighting the importance of innovative approaches in the field of public safety management. Specifically, the article explores practical applications of using Artificial Intelligence (AI) through supervised machine learning algorithms for classification, using the emergency call records database (190) of robbery incidents in the metropolitan region of São Luís as input, and comparing results through validation techniques for the Random Forest algorithm. Through detailed analysis of these data, the potential of predictive policing is illustrated not only to anticipate criminal events but also to develop a computational tool capable of assisting and supporting strategic decision-making, significantly contributing to troop allocation management and, consequently, to the enhancement of preventive urban patrol services.
Keywords: Artificial Intelligence, Predictive Policing, Criminal Analysis, Machine Learning, Data Science, Robbery.
1. INTRODUÇÃO
O policiamento preditivo surgiu como uma das inovações mais prevalentes na aplicação da lei nos últimos anos, buscando “produzir previsões operacionais de curto prazo sobre a ocorrência futura de crime” através da identificação de padrões em dados relacionados ao crime e à sociedade (LEESE, 2023, p. 06). Este avanço reflete uma tentativa significativa de otimizar a eficácia do policiamento através da tecnologia. A evolução tecnológica do século XXI tem provocado transformações significativas em diversos setores da sociedade e da administração pública. Entre essas mudanças, o conceito de “policiamento preditivo” emergiu como um paradigma inovador, visando aprimorar a eficácia das operações policiais por meio da ciência de dados (EGBERT et al. 2021). Em Egbert et al. (2021) discutem esse fenômeno, destacando o uso de técnicas analíticas avançadas para prever e prevenir atividades criminais. Essa abordagem se fundamenta na coleta e análise de vastos volumes de dados, que podem variar desde registros criminais produzidos pelas próprias forças policiais até informações provenientes de fontes externas diversas e heterogêneas.
O policiamento preditivo se enraíza em práticas históricas de análise criminal e estratégias preventivas, empregando ciência de dados e Inteligência Artificial (I.A) para aprimorar a segurança pública (EGBERT et al. 2021). Longe de ser uma novidade absoluta, representa a evolução das metodologias policiais em direção a um enfoque mais científico e orientado por dados e evidências.
Halterlein (2021) aponta em sua pesquisa que geralmente o policiamento preditivo é caracterizado pelo uso de tecnologia da informação, dados e técnicas analíticas para identificar locais e horários com elevada probabilidade de ocorrência de crimes futuros. À vista disso, técnicas de Inteligência Artificial podem ser aplicadas para prever incidências de crimes (SALEH et al., 2019), permitindo que as autoridades atuem de forma preventiva e reduzam a incidência de crimes.
Dakalbab et al. (2022) buscam contribuir para o desenvolvimento dessa área, ao propor um modelo que analisa as correlações entre o tipo de roubo, o horário, o dia e o local onde eles ocorrem. Com isso, esses pesquisadores explicam seus pressupostos ao preverem áreas e horários com maior probabilidade de ocorrência de crime por meio de algoritmos, permitindo que os recursos da polícia sejam alocados de forma estratégica.
A modernização das estratégias de policiamento, conforme indicado pela literatura especializada, reflete uma transição paradigmática da reação para a prevenção no combate à criminalidade (CARTER et al., 2013). Este avanço direciona para a adoção de práticas que possam responder aos desafios contemporâneos de segurança pública de maneira efetiva, ultrapassando os modelos de policiamento que se mostram obsoletos frente às novas demandas sociais.
Em particular, o Policiamento Orientado para a Inteligência (POI), juntamente com o policiamento preditivo, pode representar uma disrupção nesse contexto, alinhando a coleta e análise de dados à tomada de decisões estratégicas (SCHAIBLE et al., 2012). O encontro no qual essas ideias são discutidas, o X Encontro Brasileiro de Administração Pública, fornece um fórum essencial para o desenvolvimento e aprimoramento dessas iniciativas inovadoras na administração pública (BRASIL et al., 2022).
A proposta da pesquisa apresentada envolve uma pesquisa do estado da arte e a aplicação dos algoritmos preditivos. Isso abrange a integração da IA e o POI para prever atividades criminosas com base em dados históricos de crimes.
2. ESTADO DA ARTE
A análise preditiva, fundamentada no estudo de vastos conjuntos de dados, têm demonstrado uma capacidade notável de prever futuras ocorrências criminais com base em locais de crimes anteriores, conforme identificado por Kadar et al. (2016). Esta metodologia não apenas promete melhorar a segurança pública, mas também traz benefícios abrangentes para a sociedade, como destacado por Dayara et al. (2022).
A implementação eficaz dessas técnicas preditivas exige que os profissionais de segurança adquiram novas competências e conhecimentos especializados, uma necessidade sublinhada por Alves (2021), que também enfatiza a importância da integração de tecnologias avançadas e métodos analíticos no policiamento.
A modernização das estratégias de policiamento, conforme indicado pela literatura especializada, reflete uma transição paradigmática da reação para a prevenção no combate à criminalidade (CARTER et al., 2013). Este avanço direciona para a adoção de práticas que possam responder aos desafios contemporâneos de segurança pública de maneira mais eficaz, ultrapassando os modelos de policiamento que se mostram obsoletos frente às novas demandas sociais.
A eficácia da análise preditiva na prevenção de crimes é corroborada por Lobato (2019) e Fiorot et al. (2021), que observam sua aplicação bem-sucedida nos Estados Unidos ao longo das duas últimas décadas. Este sucesso é evidenciado pelo uso de modelos de Árvore de Decisão, referenciando Quinlan (1993), e dados do UCI Machine Learning Repository (2012) por Iqbal e colaboradores (2013), conforme relatado em DAYARA et al. (2022). Estes modelos superaram o método Naive Bayes que resultou em 70,81% de precisão de classificação, delineado por Duda et al. (1973), demonstrando a superioridade das Árvores de Decisão que resultou precisão de 83,95% na análise preditiva de crimes.
Os resultados positivos comprovados dos modelos de Árvore de Decisão na análise preditiva de crimes estabelecem um robusto fundamento para a implementação de técnicas sofisticadas de aprendizado de máquina (machine learning) como auxílio nas tomadas de decisões para prevenção de delitos. Entretanto, uma metodologia possivelmente mais avançada e eficiente envolve a aplicação do algoritmo Random Forest, que representa uma evolução significativa do modelo de Árvore de Decisão.
O algoritmo Random Forest não somente preserva os benefícios do modelo de Árvore de Decisão, como elucidado por Ali et al. (2012), mas também, através do emprego de técnicas de bagging sobre amostras, de um esquema de votação para a tomada de decisões e da seleção aleatória de subconjuntos de variáveis, frequentemente supera o desempenho do modelo Árvore de Decisão.
Essa superioridade é particularmente relevante no contexto de predição de eventos criminais, onde a precisão e a robustez são cruciais para a eficácia das intervenções preventivas.
Alves (2021) discute que o cerne das técnicas preditivas baseadas em IA reside na habilidade de alocar dados temporalmente, considerando suas características multidimensionais. Esta abordagem não só facilita a construção de uma base temporal robusta para apresentação dos dados, mas também estabelece os modelos estatísticos como fundamentais na ciência da predição probabilística.
No estudo de Forradellas et al. (2021), a utilização de técnicas de Aprendizado de Máquina para a análise de dados de criminalidade em Buenos Aires, no período de 2016 a 2019, culminou no desenvolvimento de um modelo preditivo fundamentado em redes neurais. Esta metodologia guarda paralelismo com a estrutura de nosso projeto, que não só almeja a previsão de roubos em áreas urbanas, mas também se dedica à comparação da precisão entre diferentes modelos de aprendizado de máquina.
A adoção de modelos de Aprendizado de Máquina, utilizando dados de registros de chamadas (190) emergenciais, oferece uma fonte valiosa de dados para a análise preditiva de roubos, conforme exposto por Fiorot et al. (2021). Este estudo se propõe a testar e validar modelos de Aprendizagem de Máquina
Supervisionado para predizer incidentes de roubos na região metropolitana de São Luís, visando explorar seu potencial para detectar padrões e tendências úteis na prevenção e combate a crimes. Tal iniciativa busca contribuir não apenas para o desenvolvimento de cidades inteligentes, mas também para a implementação de políticas públicas preventivas eficazes.
3. ANÁLISE GERAL DA FONTE DE DADOS REAIS UTILIZADA
As fontes de dados utilizadas para a análise exploratória englobam um compilado dos dados do Centro Integrado de Operações de Segurança (CIOPS) da Secretaria de Segurança Pública do Maranhão (SSPMA). A base de dados se constituiu na concatenação de 4 arquivos no formato xlsx para cada ano.
Neste trabalho, os dados brutos provenientes do CIOPS passaram por limpeza de dados (identificação de dados incorretos ou ausentes, correção de erros, tratamento de valores ausentes, remoção de duplicatas, validação de consistência e conformidade, conversão de tipos de dados, padronização de dados), por transformação de dados (agregação de dados, integração de dados e redimensionamento de dados), mineração e modelagem de dados para os modelos de machine learning aplicados.
Como pesquisador, ao enfrentar um baixo índice de dados ausentes, especificamente 0.14% neste estudo, a decisão de eliminar os registros incompletos foi sustentada tanto pela conveniência e pesquisas, quanto pela justificativa estatística. Conforme Berglund e Heeringa (2014) discutem, a exclusão de linhas com dados ausentes em análises univariadas é improvável que produza viés significativo se a taxa de dados ausentes é baixa, tipicamente inferior a 5%. Esta abordagem é particularmente justificada em nosso caso, dado que o percentual de dados faltantes é substancialmente inferior a este limite, reforçando a premissa de que a eliminação desses casos terá um impacto mínimo na validade dos resultados.
O espaço amostral coletado para essa pesquisa (2019-2022) apresenta certa regularidade nas variáveis existentes, no total, 24 atributos compõem o banco de dados com total de 38.854 registros com uma variedade de tipos de dados, incluindo int641 e object2 prontos para o pré-processamento. Foram identificados 184 registros duplicados associados a valores únicos da variável “Ocorrência”. As variáveis do banco de dados incluem, mas não se limitam a, “Bairro”, “Endereço”, “Cidade”, e “Tipo” de ocorrência, juntamente com variáveis temporais como “Hora”, “Dia”, “Mês”, e “Ano”.
3.1 Tratamento da base dados
A integridade do banco de dados é sólida, com a maioria das variáveis apresentando 0% de valores nulos e desta forma não necessitando de tratamento especial de interpolação de dados. Contudo, algumas variáveis como “Bairro” e “Endereço” possuem um certo número de entradas ausentes, que podem impactar análises que dependem destes campos, para isso, buscou-se pesquisar boas práticas de interpolação de dados para não influenciar nos resultados desta pesquisa.
Para otimizar recurso computacional para o processamento, além de codificar as variáveis de interesse, foram convertidos todos os valores inteiros de 64 bits para 32 bits para uso de memória.
Na Figura 1, cada coluna representa uma variável específica do conjunto de dados, incluindo “Ocorrência” para um código gerado com valor único, “Tipo” para classificar a natureza da ocorrência gerada, “Subtipo” para subclassificar o natureza da ocorrência que foi gerada, a variável “Finalização” para atribuir uma classe representando o resultado da ocorrência gerada, as variáveis “Hora”, “Período”, “Dia”, “Semana”, “Mês”, “Trimestre” e “Ano” são atributo com valores temporais, as variáveis “Endereço”, “Bairro”, “Cidade” e “Zona” são do tipo nominal de lugar (espaço).
Após selecionar as variáveis de interesse e carregar o banco de dados, os atributos como Endereço, Bairro, Cidade, e Zona exibem níveis de dados ausentes, mostram incidência de nulidade, a Figura 2 apresenta uma matriz de nulidade executada em linguagem de programação Python.
Figura 1. Matriz de nulidade
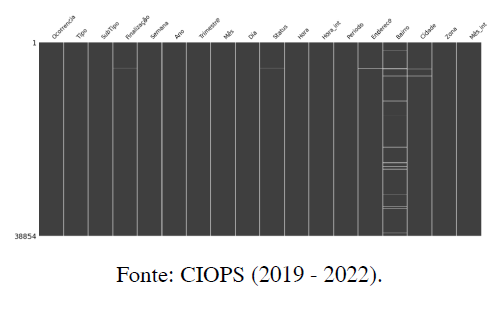
A coluna “Bairro” possui 982 valores únicos e uma porcentagem de dados faltantes de 1.67%, enquanto a coluna “Tipo” tem um único valor único, indicando uma categoria de ocorrência.
Esta matriz de nulidade (Figura 1) executada em linguagem de programação python, usando bibliotecas de visualização, é uma ferramenta visual empregada para identificar a presença de dados ausentes em conjunto de dados.
As linhas da matriz representam as observações (frequências) ou registros das chamadas de roubos, com 38.854 linhas, indicando o número total de registros do conjunto de dados. As áreas preenchidas de cinza escuro indicam a presença de dados para a respectiva variável naquele registro, enquanto que as áreas brancas representam a ausência de dados, ou seja, valores nulos.
Observa-se que a maioria das variáveis possui dados completos em quase todos os registros, com exceção de “Endereço”, “Bairro”, “Cidade” e “Zona”, que apresentam várias incidências de valores ausentes. A visualização destes padrões de nulidade é crucial para o pré-processamento de dados, permitindo que analistas identifiquem e decidam como tratar esses valores ausentes antes de realizar análises subsequentes ou treinar modelos de aprendizado de máquina.
Para assegurar a eficácia de modelos de machine learning, é imprescindível uma clara compreensão tanto do desafio a ser superado quanto dos dados a serem manipulados, visando à geração de resultados consistentes e relevantes para a aplicação pretendida. A acurácia na aplicação e o desempenho de um modelo estão intrinsecamente ligados à qualidade do entendimento do problema e à integridade do banco de dados utilizado (Vieira, 2021). Estes fatores são fundamentais para a obtenção de um modelo robusto e confiável em cenários reais.
4. METODOLOGIA
Nesta seção, é apresentada primeiramente uma análise exploratória dos dados prontos para processamento dos algoritmos preditivos. Esse material foi selecionado de modo a apresentar características relevantes a serem discutidas na próxima seção. Todo o estudo exploratório dos dados, desenvolvimento dos gráficos e processamento foi executado a partir de bibliotecas da linguagem de programação Python.
Marban et al. (2009) elucidam o Cross-Industry Standard Process for Data Mining (CRISP-DM), modelo de arquitetura de processamento de dados, conhecido por sua flexibilidade e diretrizes genéricas. Originado em 2000, o modelo é valorizado por sua abordagem iterativa e sua adaptabilidade às demandas que envolvem aprendizado de máquina (CHAPMAN, et al., 2000).
O modelo CRISP-DM foi a abordagem escolhida e utilizada neste trabalho, é recomendada para projetos de Ciência de Dados que buscam prever a probabilidade de ocorrência de eventos a partir de grandes conjuntos de dados, conforme descrito por Kutzias et al. (2021). Acompanhando a descrição na Figura 2, oferece uma visualização da arquitetura do processamento de ingestão e saída dos dados, fornecendo compreensão visual das etapas interconectadas do modelo CRISP-DM, reforçando o entendimento da metodologia e facilitando a implementação.
Embora a inconsistência seja uma característica comum na estrutura de grandes volumes de dados, a maioria das pesquisas utilizam técnicas de pré-processamento que consiste basicamente na limpeza e tratamento dos dados, do qual são capazes de afetar substancialmente o desempenho de algoritmos. Esse fenômeno reforça a importância do ajuste meticuloso em pesquisa e preparo, ressaltando o impacto direto que tais técnicas podem ter na acurácia dos resultados (KOUNADI et al., 2020).
Figura 2. Arquitetura de processamento de dados.
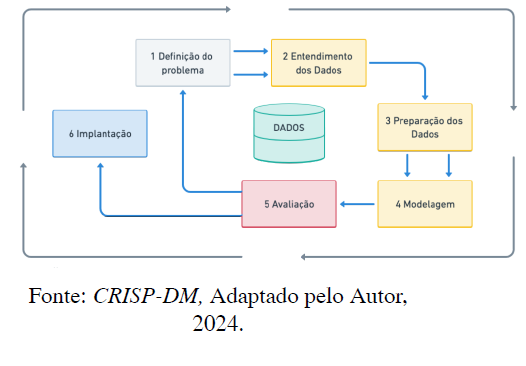
Como evidenciado por Kounadi et al. (2020), o entendimento do problema, a escolha criteriosa de variáveis, métodos e a precisão na parametrização são cruciais para o aprimoramento dos resultados em estudos de previsão espacial de crimes.
Berglund e Heeringa (2014) apontam que em situações onde os dados ausentes são poucos e assumidamente aleatórios (MCAR – Missing Completely at Random), a eliminação por lista pode ser uma escolha adequada sem comprometer significativamente a qualidade e a confiabilidade dos resultados estatísticos. A escolha de eliminar registros incompletos, ao invés de aplicar técnicas mais complexas de imputação, oferece uma solução pragmática e eficaz, permitindo-nos concentrar nossos esforços na análise de um conjunto de dados mais robusto e completo (BERGLUND, et al., 2014).
Ademais, reconhecendo a relevância de atributos temporais detalhados, procedemos com a engenharia de recursos com base em colunas já preexistentes, para facilitar e refinar as análises estatísticas e gráficas subsequentes.
O pré-processamento, a análise exploratória, preparação, modelagem e assim como todo processamento computacional do projeto, foram feitos via Python 3.11.5, tendo como IDE o JupyterLab. Nesse ambiente, é feita a conexão dos pacotes Python, as instalações das bibliotecas facilitam a análise exploratória, visualização, tratamento estatístico, e modelagem preditiva do projeto, abrangendo desde a preparação até a interpretação de dados, que foram essenciais para extrair insights e construir modelos eficientes contínuos.
5. RESULTADOS E DISCUSSÃO
O presente projeto visa analisar e avaliar o desempenho do algoritmo de aprendizado de máquina Random Forest na predição de ocorrências policiais de roubo, por meio de predições de chamadas telefônicas futuras para registros de ocorrência policiais de roubo na região metropolitana de São Luís, utilizando métricas e indicadores computacionais. A escolha do modelo baseado em algoritmos foi baseada no estudo da arte e nos recursos disponíveis.
A fase da análise de treino e validação dos resultados, por meio dos indicadores de performance do algoritmo Random Forest para o Policiamento Preditivo, desempenha como uma métrica de qualidade e validação do processamento da base de dados das ocorrências policiais dos registros das chamadas emergências do tipo roubo. O objetivo da fase da validação dos resultados é criar uma linha de base útil em cenários de classificação e nos ajustes ideias dos hiperparâmetros.
No entanto, ao dividir o conjunto de dados em amostras de treino, utilizando os registros de ligações de roubos ocorridos entre 2019 e 2021, e em amostras de teste, utilizando os registros de ligações de roubos de 2022, ocorreu uma limitação crítica de recursos computacionais, especialmente no que diz respeito à memória ao usar o modelo Random Forest.
Conforme ilustrado na imagem abaixo na Figura 3, o sistema de memória física de 16 GB está quase saturado, com 14,63 GB já utilizados, o que inclui 8,34 GB destinados a aplicativos e 3,52 GB de dados comprimidos. Adicionalmente, a memória de troca já atingiu 7,61 GB, indicando que o sistema está operando sob alta pressão de memória, com risco iminente de erros de alocação de memória durante a execução de processos intensivos.
Figura 3. Sistema de memória física.

Diante dessa restrição, foi inviável continuar a análise no nível de granularidade desejado. Para contornar essa limitação e possibilitar a realização do teste, optou-se por quantificar as ocorrências em termos de zonas geográficas mais amplas, ao invés de bairros individuais. Esta abordagem, embora menos precisa, permitiu a viabilidade computacional do estudo e assegurou a continuidade das análises preditivas.
Itzpatrick et al. (2019) ressaltam que, decisões como a especificação do modelo, a seleção de parâmetros e a seleção de dados de entrada têm impactos significativos sobre a capacidade de métodos de previsão para capturar crimes futuros com suas previsões mais bem classificadas e maximizar a eficácia das medidas de intervenção.
Os parâmetros de hiperparâmetros ilustrados a Figura 4 foram utilizados para quantificar as ocorrências tanto em termos de zonas geográficas mais amplas quanto em bairros individuais. Especificamente, a grade de hiperparâmetros definida inclui o número de estimadores (‘n_estimators’), a profundidade máxima das árvores (‘max_depth’), o número mínimo de amostras necessárias para dividir um nó (‘min_samples_split’), o número mínimo de amostras em uma folha terminal (‘min_samples_leaf’) e o número de recursos a serem considerados para a melhor divisão (‘max_features’).
Essas configurações foram aplicadas ao modelo de busca em grade (GridSearchCV) para otimizar a performance do modelo preditivo em ambas as abordagens de quantificação.
Figura 4. Algoritmo para curva de aprendizado

Shamsuddin et al. (2017) propõem métodos híbridos para resultados superiores. Essas perspectivas coletivas sugerem um caminho promissor para o avanço das estratégias de segurança pública, enfatizando a inovação contínua e o investimento tecnológico.
No Gráfico 1, é apresentado uma visualização da curva de aprendizado do modelo Random Forest, com objetivo de prever zonas de maior incidência de roubos a pessoas na região metropolitana por meio da divisão do conjunto de dados para treino e teste. Há insights3 significativos sobre o comportamento e a eficácia do modelo em relação ao volume de dados de treino.
Gráfico 1. Curva de aprendizado (Random Forest).
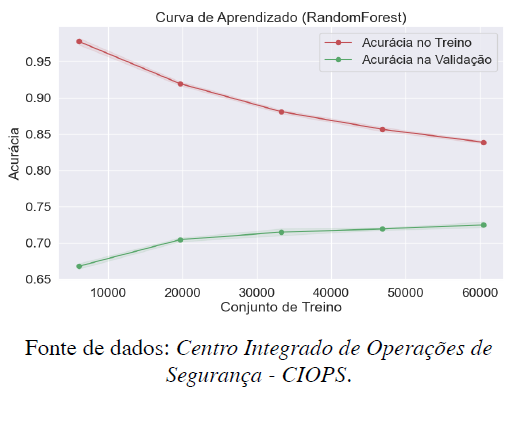
Na curva de aprendizado do modelo, é observado que há uma tendência de decréscimo na acurácia à medida que o tamanho do conjunto de treino aumenta. Inicialmente, com dados limitados (cerca de 10.000 instâncias), o modelo apresenta uma acurácia superior a 95%. Este alto desempenho pode ser atribuído ao sobreajuste (overfitting), onde o modelo aprende demais os detalhes e as peculiaridades do conjunto de treino, resultando em uma capacidade limitada de generalizar para novos dados.
Contrapondo à acurácia de treino, a acurácia na validação melhora progressivamente à medida que mais dados são fornecidos. Começando de um patamar abaixo de 70%, a acurácia de validação sobe gradualmente, estabilizando-se em torno de 75% com 60,000 instâncias. Isso indica que o modelo está começando a generalizar melhor e se tornar mais robusto devido à variabilidade dos dados não vistos durante o treino.
A lacuna significativa entre as curvas de treino e validação sugere que, apesar da melhoria na generalização, ainda há uma notável diferença de desempenho, o que pode ser um indicativo de que o modelo ainda sofre com algum grau de sobreajuste. O modelo está ajustado de forma demasiada aos dados de treino, prejudicando seu desempenho em dados novos.
6. CONCLUSÃO
A presente pesquisa evidenciou a eficácia e potencial do policiamento preditivo ao utilizar algoritmos de aprendizado de máquina para prever ocorrências criminais. Especificamente, a aplicação do algoritmo Random Forest na predição de chamadas telefônicas de crimes de roubo na Região Metropolitana de São Luís demonstrou resultados promissores na identificação de padrões e na antecipação de eventos criminais.
A metodologia foi fundamental para estruturar e gerenciar as fases do projeto, deste a definição do problema, pré-processamento, a análise exploratória, preparação, modelagem e assim como todo processamento computacional do projeto. Dentro da arquitetura desenvolvida, a etapa de pré-processamento exigiu maior esforço no projeto, pois contou com a limpeza, transformação e padronização de dados.
Ao apontar as limitações desta pesquisa acadêmica, é importante destacar que tinha sido proposto uma análise preditiva de bairros com maiores probabilidade de chamadas emergenciais de roubo, mas devido à falta de memória computacional adequada para o problema inicial proposto. Nesse sentido, para contornar essa limitação e viabilizar a realização do teste, optou-se por quantificar as ocorrências em termos de zonas geográficas mais amplas, em vez de bairros individuais. Embora essa abordagem seja menos precisa, ela permitiu a viabilidade computacional do estudo e garantiu a continuidade das análises preditivas.
Portanto, a continuidade do estudo e a implementação de mais recursos tanto computacionais, como outras fontes de dados, para análise de correlação de variáveis com outras fontes de dados (climáticos, fases da lua e etc.) podem ser alvo de novas pesquisas. Para estudos futuros, também pretende-se usar técnicas de georreferenciamento para otimizar a análise. A colaboração entre pesquisadores, profissionais de segurança pública e formuladores de políticas é essencial para o desenvolvimento e aprimoramento contínuo dessas ferramentas, garantindo que o policiamento preditivo se torne um componente integral e eficaz na estratégia de segurança pública.
Este trabalho contribui para o campo da gestão em segurança pública ao evidenciar o valor das abordagens inovadoras baseadas em dados e tecnologia, e sugere que futuras pesquisas explorem a aplicação de outros algoritmos e técnicas de aprendizado de máquina para fortalecer ainda mais a eficiência do policiamento preditivo.
1int64: Este tipo de dado representa números inteiros de 64 bits.
2object: Este tipo de dado é usado para armazenar dados de texto (strings) ou uma mistura de diferentes tipos de dados.
3Em análise de dados é uma compreensão clara e acionável extraída de padrões e tendências nos dados, que orienta decisões e estratégias eficazes.
REFERÊNCIAS
ALI, J.; KHAN, R.; AHMAD, N.; MAQSOOD, I. Random Forests and Decision Trees. I.J. Computer Science Issues, v. 9, n. 5, p. 272, set. 2012. Disponível em: www.IJCSI.org. Acesso em: 30 Abril. 2024.
ALVES, Marcos C. R. Inteligência Artificial na prevenção criminal pelas Polícias Militares do Brasil. In: HAMADA, Hélio Hiroshi; MOREIRA, Renato Pires (org.). Gestão do Conhecimento e boas práticas na área de segurança pública. Catu: Bordô-Grená, 2021.
BERGLUND, P.; HEERINGA, S. Multiple Imputation of Missing Data Using SAS. Cary, North Carolina: SAS Institute Inc., p. 05, 2014.
BRASIL, Daniel Alves; MAUERBERG JUNIOR, Arnaldo. A relação entre o policiamento orientado pela inteligência e o desempenho nas organizações policiais: um breve tour pela literatura recente sobre o tema. In: IX Encontro Brasileiro de Administração Pública, 2022, São Paulo. Anais… São Paulo: Sociedade Brasileira de Administração Pública, 2022. Disponível em: https://sbap.org.br. Acesso em: 20 mar. 2024
BRAYNE, Sarah; CHRISTIN, Angèle. Technologies of crime prediction: The reception of algorithms in policing and criminal courts. Social problems, v. 68, n. 3, p. 608-624, 2021. Disponível em: https://academic.oup.com/socpro/articl e/68/3/608/5782114?login=false. Acesso em: 27 mar. 2023.
CARTER, Jeremy G. Intelligence-led policing: a policing innovation. LFB Scholarly Publishing LLC, 2013.
CHAPMAN, et al. CRISP-DM 1.0: Step-by-step data mining guide. 9(13). SPSS Inc, p. 1–73. (2000).
CLYDE, Merlise A, et al. Bayesian adaptive sampling for variable selection and model averaging. Journal of Computational and Graphical Statistics, v. 20, n. 1, p. 80-101, 2011.
DAYARA, Thanu, et al. Crime analyses using data analytics. International Journal of Data Warehousing and Mining (IJDWM), v. 18, n. 1, p. 1-15, 2022. Disponível em: http://doi.org/10.4018/IJDWM.299014 . Acesso em: 27 mar. 2023.
DAKALBAB, Fatima, et al. Artificial intelligence & crime prediction: A systematic literature review. Social Sciences & Humanities Open, 2022, 6.1: 100342.
KOUNADI, O., Ristea, A., ARAUJO Jr., A., & LEITNER, M. (2020). A systematic review on spatial crime forecasting. *Crime Science, 9*(7). Disponível em: https://doi.org/10.1186/s40163-020-00 116-7. Acesso em: 20 nov. 2023. IQBAL, AZMI, & MUSTAPHA,
PANAHY, & KHANAHMADLIRAVI. (2013). An experimental study of classification algorithms for crime prediction. Indian Journal of Science and Technology, 6, 4219–4225.
QUINLAN. (1993). C4.5: Programs for machine learning. Morgan Kaufmann.
LEESE, Matthias. Staying in control of technology: predictive policing, democracy, and digital sovereignty. Democratization, 18 abr. 2023. Disponível em: https://doi.org/10.1080/13510347.2023 .2197217. Acesso em: 7 jan. 2024.
EGBERT, Simon. LEESE, Matthias. Criminal Futures: Predictive policing and everyday police work. Nova York. Editora Routledge, p. 20. 2021.
FONSECA, J.J.S. Metodologia da pesquisa científica. Fortaleza: UEC, 2002.
FÓRUM BRASILEIRO DE SEGURANÇA PÚBLICA. Anuário Brasileiro de Segurança Pública 2021. São Paulo: FBSP, 2021. Disponível em: https://forumseguranca.org.br/publicac oes/anuario-brasileiro-de-seguranca-pu blica-2021/. Acesso em: 13 mar. 2023.
FIOROT, Bruna Luchi, et al. A plausibilidade da utilização do Big Data para a predição de crimes no Brasil frente aos seus riscos e consequências. 2021. Disponível em: http://www.repositorio.fdv.br:8080/han dle/fdv/1203. Acesso em: 14 mar. 2023.
FURTADO, Vasco. Inteligência artificial na segurança pública: conceitos, perspectivas e desafios. In: DORIAM, Borges et al. Estatísticas de segurança pública [livro eletrônico]: produção e uso de dados criminais no Brasil. São Paulo, SP: Fórum Brasileiro de Segurança Pública. p. 178-189. 2022.
GABRIEL, Martha. Inteligencia Artificial: do zero ao metaverso. Atlas. p.20-21. 2022.
GERHARDT, Tatiana Engel, et al. Métodos de pesquisa. 1. ed. Porto Alegre: UFRGS, 2009.
GIL, Antonio Carlos. Como elaborar projetos de pesquisa. 6. ed. São Paulo: Atlas, 2019.
HALTERLEIN, J. Epistemologies of predictive policing: Mathematical social science, social physics and machine learning. Big Data and Society, p. 13. 2021.
HORROCKS, N. S. Novas e Novíssimas Guerras: O debate teórico-conceitual para pensar a violência urbana. p. 20, 2019. Disponível em: https://www.academia.edu/download/5 8867157/Novas_Novissimas_Guerras2 0190411-43888-e1ej7f.pdf. Acesso em: 23 mar. 2023.
ITZPATRICK, Dylan J, et al. Predictive analytics in policing. Annual Review of Criminology, 2019, 2: p. 473-491. Disponível em: https://www.annualreviews.org/doi/pdf /10.1146/annurev-criminol-011518-02 4534. Acesso em: 13 mar. 2023.
KADAR, Cristina; IRIA, José; CVIJIKJ, Irena Pletikosa. Exploring Foursquare-derived features for crime prediction in New York City. KDD-Urban Computing WS 16. 2016. 10-1145.
KUTZIAS, et al. Towards a Continuous Process Model for Data Science Projects. In LEITNER, et al., editor, Advances in the Human Side of Service Engineering, volume 266 of Lecture Notes in Networks and Systems, pag. 204–210. Springer International Publishing, Cham. 2021.
LEMUS-DELGADO, Daniel, et al. Ciencias de datos y estudios globales: aportaciones y desafíos metodológicos. Colombia Internacional. v. 1, n. 102, p. 41–62, 2020. Disponível em: https://revistas.uniandes.edu.co/index.p hp/colombia-int/article/view/2923. Acesso em: 29 mar. 2023
LOBATO, Fernanda Silva. Uso de softwares com função analítica preditiva aplicados à investigação criminal e atividade de inteligência: uma análise sobre o conflito de normas relativas ao direito constitucional à privacidade e à segurança pública. Belém, 2019. Disponível em: https://bdm.ufpa.br:8443/jspui/handle/ prefix/3260. Acesso em: 19 mar. 2023.
MARBAN, O., MARISCAL, G., et al. A data mining and knowledge discovery process model. In P. Julio & K. Adem (Eds.), Data mining and knowledge discovery in real life applications (p. 438–453). Paris, I-Tech. 2009.
MARISCAL, G., MARBAN, O. et al. A survey of data mining and knowledge discovery process models and methodologies. The Knowledge Engineering Review, 25, p. 137–166. 2010.
MORAES, F. O. Policiamento Preditivo e aspectos constitucionais. São Paulo: Editora Dialética, p. 07-08. 2022.
NORTON, A. A. (2013). Predictive policing: The future of law enforcement in the trinidad and tobago police service (TTPS). International Journal of Computer Applications, 62(4), 32–36. doi:10.5120/10070-4680
PINTO, Danielle Jacon Ayres; MEDEIROS, Sabrina Evangelista. Inteligência artificial e seu uso no contexto militar: desafios e dilemas éticos. In: Cadernos Adenauer, volume XXIII, nº 2, p. 99. 2022
SALEH. Khan. Crime data analysis in Python using K-means clustering. International Journal for Research in Applied Science and Engineering Technology, v. 7, n 4, p. 151–155, 2019.
SCHAIBLE, Lonnie M.; SHEFFIELD, James. Intelligence‐led policing and change in state law enforcement agencies. Policing: An International Journal of Police Strategies & Management, 2012.
VIEIRA, F. C. Análise exploratória de dados: limpeza, manipulação e pré-processamento aplicado a dataset de perfil de atendimento nas unidades de saúde da cidade de Curitiba. 2021. Monografia (Especialização em Ciência de Dados e suas Aplicações) – Universidade Tecnológica Federal do Paraná, Curitiba.