MACHINE LEARNING-BASED PREDICTIVE MODELS FOR OPTIMIZING STRATEGIES IN SPORTS BETTING ON SOCCER
REGISTRO DOI: 10.69849/revistaft/fa10202410211435
Leonardo Zavarize Bergo1,
Orientador: Felipe Diniz Dallilo2,
Coorientador: Fabiana Florian3
RESUMO
Este trabalho apresenta uma investigação sobre a aplicação de modelos preditivos baseados em Machine Learning para otimizar estratégias de apostas esportivas no futebol. A pesquisa foi realizada utilizando uma combinação de métodos quantitativos e qualitativos, incluindo a análise de dados históricos de partidas de futebol e a implementação de algoritmos de aprendizado de máquina. Os resultados indicam que os modelos preditivos podem ser eficazes na previsão de resultados de partidas de futebol, o que pode ser útil para otimizar estratégias de apostas esportivas. A aplicação prática desses modelos pode fornecer aos apostadores uma vantagem competitiva, permitindo-lhes tomar decisões mais informadas e, potencialmente, melhorar seus resultados financeiros. Conclui-se que, enquanto os modelos preditivos oferecem uma ferramenta valiosa para o aprimoramento das estratégias de apostas, uma abordagem cuidadosa e uma contínua avaliação dos modelos são essenciais para maximizar sua eficácia. A pesquisa sugere que futuras investigações podem explorar a integração de dados adicionais e a melhoria dos algoritmos para aumentar a precisão das previsões.
Palavras-chave: Apostas esportivas. Futebol. Machine Learning. Modelos preditivos. Otimização de estratégias. Previsão de resultados.
ABSTRACT
This study presents an investigation into the application of predictive models based on Machine Learning to optimize sports betting strategies in football. The research was conducted using a combination of quantitative and qualitative methods, including the analysis of historical football match data and the implementation of machine learning algorithms. The results indicate that predictive models can be effective in forecasting football match outcomes, which can be useful for optimizing sports betting strategies. The practical application of these models can provide bettors with a competitive advantage, allowing them to make more informed decisions and potentially improve their financial outcomes. It is concluded that while predictive models offer a valuable tool for enhancing betting strategies, a careful approach and ongoing evaluation of the models are essential to maximize their effectiveness. The research suggests that future investigations could explore the integration of additional data and the improvement of algorithms to increase prediction accuracy.
Key-words: Sports Betting. Football. Machine Learning. Predictive Models. Strategy Optimization. Outcome Prediction.
1 INTRODUÇÃO
O futebol é um dos esportes mais populares do mundo, com milhões de pessoas assistindo e apostando em partidas todos os dias. No entanto, fazer apostas bem-sucedidas em partidas de futebol pode ser um desafio, devido à natureza imprevisível do esporte. Este trabalho tem como objetivo explorar o uso de modelos preditivos baseados em Machine Learning (ML) para otimizar estratégias de apostas esportivas no futebol.
Os modelos preditivos são ferramentas estatísticas ou de ML que utilizam dados históricos para fazer previsões sobre eventos futuros (Filatro, 2021). Esses modelos analisam padrões e relações nos dados passados para estimar a probabilidade de diferentes resultados (McCabe; Trevathan, 2008). No contexto do futebol, os modelos preditivos são amplamente utilizados para prever o resultado de partidas (vitória, empate, derrota), o desempenho de jogadores, e outras métricas relevantes (Baio; Blangiardo, 2010; Tax; Joustra, 2015).
Os modelos preditivos são implementados e testados em ambientes de pesquisa acadêmica utilizando ferramentas como Python, Scikit–learn e TensorFlow. O processo de avaliação envolve a divisão dos dados em conjuntos de treinamento e teste, aplicação de validação cruzada e uso de métricas de desempenho como precisão, recall, e F1-score para avaliar a eficácia dos modelos (Awari by Fluency, 2023).
Acredita-se que a realização desta pesquisa possa contribuir para a compreensão de como o ML pode ser aplicado no campo das apostas.
A justificativa para a realização deste trabalho é a crescente popularidade das apostas esportivas e o potencial do ML para melhorar a precisão das previsões de resultados de partidas de futebol. Estudos de ML e de apostas esportivas é uma área de estudo relativamente nova, e acredita-se que este trabalho possa disseminar conhecimento.
Há a dificuldade em fazer previsões precisas sobre os resultados das partidas de futebol. A hipótese é que, ao aplicar técnicas de ML aos dados históricos das partidas, é possível desenvolver modelos preditivos que possam prever com maior precisão os resultados das partidas.
A metodologia do estudo é de revisão bibliográfica, tem com o método a aplicação de estudo de caso e como ferramenta serão desenvolvidos e testados modelos preditivos que possam prever com precisão os resultados das partidas de futebol, e investigar como esses modelos podem ser usados para otimizar estratégias de apostas esportivas.
Será realizada coleta e análise de dados históricos de partidas de futebol para desenvolver os modelos preditivos, e teste desses modelos para avaliar sua precisão na previsão de resultados de partidas de futebol.
2 REVISÃO BIBLIOGRÁFICA
2.1 MACHINE LEARNING E APOSTAS ESPORTIVAS
Machine learning (ML), ou aprendizado de máquina, é uma subárea da inteligência artificial focada no desenvolvimento de algoritmos que permitem aos computadores aprender e tomar decisões baseadas em dados. Um dos principais usos do ML é a criação de modelos preditivos (Alzubaidi et al., 2021).
Modelos preditivos são ferramentas analíticas que utilizam dados históricos para prever resultados futuros. Esses modelos são construídos e refinados através de técnicas de ML. Esse processo tem início com a coleta de dados históricos relevantes para o problema em questão. Esses dados podem ser estruturados (como tabelas de bancos de dados) ou não estruturados (como texto ou imagens). Antes de treinar um modelo, os dados precisam ser limpos e transformados, o que inclui a remoção de valores ausentes, normalização de dados e transformação de características, garantindo que os dados estejam em um formato adequado para análise (Filatro, 2021).
Diversos algoritmos de ML podem ser utilizados para criar modelos preditivos. A escolha do algoritmo depende do tipo de dados e do problema a ser resolvido (Baboota; Kaur, 2019). Alguns dos algoritmos comuns incluem:
– Regressão Logística que é um modelo utilizado para prever a probabilidade de um evento binário, como vencer ou perder uma partida. Por exemplo, se temos dados históricos sobre partidas anteriores, como número de gols marcados, posses de bola, e chutes a gol, a regressão logística pode utilizar esses dados para prever a probabilidade de uma equipe vencer uma partida futura (Joseph; Fenton, Neil, 2006).
– Máquinas de Vetores de Suporte (SVM) são modelos de classificação que podem ser utilizados para categorizar os resultados das partidas de futebol em várias classes (vitória, empate, derrota). O SVM encontra um hiperplano que melhor e separa as classes no espaço de características (Baio; Blangiardo, 2010; Tax; Joustra, 2015).
– Redes Neurais Artificiais (ANNs) são modelos inspirados na estrutura do cérebro humano e são capazes de aprender padrões complexos nos dados. No futebol, ANNs podem ser usadas para prever resultados de jogos ao analisar uma vasta gama de dados de entrada, como estatísticas dos jogadores, desempenho do time e condições meteorológicas (McCabe; Trevathan, 2008).
– Árvores de Decisão e Florestas Aleatórias são modelos preditivos que utilizam uma estrutura em forma de árvore para tomar decisões baseadas em regras derivadas dos dados. Florestas aleatórias combinam várias árvores de decisão para melhorar a precisão preditiva. Esses modelos são úteis para identificar interações entre variáveis e fazer previsões robustas (Bunker; Thabtah, 2019; Constantinou; Fenton, Neil, 2013).
O ML tem sido cada vez mais aplicado em diversas áreas, incluindo as apostas esportivas, devido à sua capacidade de analisar grandes volumes de dados e identificar padrões que podem ser usados para fazer previsões mais precisas sobre resultados de eventos esportivos (Baio; Blangiardo, 2010; Huang; Chang, 2010; Jensen, 2022; Lasek; Szlavik, Bhulai, 2013; Rudrapal et al,. 2020). Por exemplo, algoritmos como redes neurais, random forest, regressão logística e SVM têm sido aplicados para analisar dados históricos de partidas, estatísticas de equipes e jogadores, condições do jogo e outros fatores relevantes (Choi; Foo, Chua, 2023; Groll et al., 2019; Tax e Joustra, 2015).
O uso de ML em apostas esportivas não se limita apenas à previsão de resultados de jogos. Também pode ser aplicado para identificar oportunidades de apostas com valor esperado positivo, gerenciar riscos e otimizar estratégias de apostas (Zhou et al., 2017). Embora os modelos de ML não sejam infalíveis, eles têm o potencial de oferecer uma vantagem significativa nas apostas esportivas ao fornecer previsões mais precisas e dados aprofundados. A contínua evolução dos algoritmos de ML e a disponibilidade crescente de dados de alta qualidade prometem ainda mais avanços nesta área (Géron, 2019).
No entanto, é importante notar que o sucesso na aplicação de ML em apostas esportivas depende da qualidade dos dados disponíveis, da escolha apropriada dos algoritmos e da validação cuidadosa dos modelos (Baboota; Kaur, 2019). Além disso, o jogo envolve incertezas inerentes e resultados imprevisíveis, o que significa que mesmo os melhores modelos de ML não podem garantir resultados consistentes a longo prazo (Baio; Blangiardo (2010).
No entanto, estudos têm demonstrado que esses modelos de ML podem superar abordagens tradicionais de previsão, como sistemas de ranking ou análises estatísticas simples, em termos de precisão e capacidade de adaptação a diferentes cenários esportivos. Além disso, a inclusão de variáveis contextuais, como local do jogo, histórico recente das equipes e condições meteorológicas, pode melhorar ainda mais a precisão das previsões.
2.2 MODELOS PREDITIVOS NO FUTEBOL
Como constatado, os modelos preditivos têm sido usados no futebol para uma variedade de propósitos, desde a previsão de resultados de partidas até a análise de desempenho de jogadores. A literatura existente mostra que esses modelos podem ser bastante precisos, especialmente quando combinados com técnicas de ML.
Diversos estudos têm explorado o uso de algoritmos de aprendizado de máquina para prever os resultados de partidas de futebol, com resultados promissores.
Por exemplo, Huang e Chang (2010) aplicaram redes neurais para prever os resultados da Copa do Mundo de 2006, e conseguiram uma precisão de 74% na previsão dos resultados dos jogos, demonstrando a eficácia das redes neurais na identificação de padrões complexos nos dados de partidas de futebol.
Baio e Blangiardo (2010) buscaram desenvolver um modelo para prever os resultados de partidas de futebol, útil em esportes devido à sua capacidade de incorporar diferentes níveis de variabilidade e incerteza. Aplicaram um modelo hierárquico bayesiano utilizando dados de jogos anteriores. Esse modelo permite a inclusão de diferentes níveis de variáveis, como desempenho individual dos jogadores, desempenho das equipes, e fatores contextuais como a vantagem de jogar em casa. I modelo requer seguir algumas etapas: i)Especificação do Modelo: Variáveis Independentes: Incluem fatores como o desempenho anterior da equipe, estatísticas dos jogadores, e a vantagem de jogar em casa; Variáveis Dependentes: O resultado do jogo (vitória, empate, derrota). ii) Hierarquia do Modelo: Nível 1: Resultados dos jogos, considerando fatores específicos de cada partida; Nível 2: Desempenho geral da equipe ao longo da temporada; Nível 3: Desempenho de longo prazo e efeitos sazonais. iii) Inferência Bayesiana: utilizaram métodos de inferência bayesiana para estimar os parâmetros do modelo, empregando técnicas de simulação como o Markov Chain Monte Carlo (MCMC). O modelo mostrou um desempenho robusto na previsão dos resultados. O resultado demonstrou uma precisão robusta na previsão dos jogos de futebol e mostraram que o modelo hierárquico bayesiano foi capaz de capturar a complexidade e a incerteza inerentes aos resultados das partidas de futebol, fornecendo previsões mais precisas do que modelos não-hierárquicos, o que levou a conclusão de que o modelo utilizado é uma ferramenta poderosa para a previsão de resultados de futebol devido à sua capacidade de: incorporar múltiplos níveis de variáveis e dados; lidar com a incerteza de forma explícita e sistemática; e melhorar a precisão das previsões em comparação com métodos tradicionais.
Hucaljuk e Rakipović (2011) exploraram o uso de redes neurais e árvores de decisão para prever resultados de jogos de futebol no Campeonato Inglês. Seu estudo mostrou que a combinação de diferentes algoritmos de ML pode melhorar a precisão das previsões. A abordagem híbrida utilizada alcançou uma precisão de 62%, evidenciando o potencial da integração de múltiplos métodos preditivos.
Lasek, Szlavik e Bhulai (2013) investigaram o uso de sistemas de ranking (baseados em regressão e baseados em redes neurais) e modelos de aprendizado de máquina para prever resultados de futebol, utilizando dados históricos de partidas de futebol de várias ligas europeias para testar a eficácia dos sistemas de ranking e dos modelos de aprendizado de máquina. Os achados demonstraram que, as redes neurais apresentaram maior precisão, identificando padrões complexos nos dados que os métodos tradicionais não conseguiram capturar.; Elo Rating apesar de eficaz, não teve um desempenho tão bom quanto os modelos de redes neurais, especialmente em ligas com alta competitividade; e por fim, os modelos de regressão demonstraram desempenho intermediário, melhorando a precisão em relação ao Elo, mas ficando atrás das redes neurais. Assim, os modelos baseados em ML, especificamente random forest e redes neurais, superaram os sistemas de ranking tradicionais na previsão de resultados de partidas da Bundesliga Alemã.
Constantinou, Fenton e Neil (2013) analisaram o impacto dos modelos de ML na precisão das previsões de apostas esportivas. Compararam vários algoritmos, incluindo regressão logística, árvores de decisão e redes neurais, concluindo que as redes neurais apresentaram melhor desempenho na previsão de resultados de partidas de futebol, com isso demonstrou como diferentes abordagens de ML podem ser aplicadas e ajustadas para melhorar a precisão das previsões.
Tax e Joustra (2015) usaram modelos de aprendizado de máquina como regressão logística, máquinas de vetores de suporte (SVM) e árvores de decisão para prever resultados da Eredivisie, principal liga de futebol dos Países Baixos, utilizando dados públicos (informações sobre resultados de jogos anteriores, estatísticas dos times, dados sobre jogadores, e outros fatores relevantes como a vantagem de jogar em casa) e técnicas de aprendizado de máquina. Buscaram determinar quais algoritmos (Regressão Logística, SVM, Random Forest, K-Nearest Neighbors (KNN) e técnicas de aprendizado de máquina seriam mais eficazes na previsão de resultados de futebol e como diferentes tipos de dados poderiam influenciar a precisão dessas previsões. Os resultados mostraram que a Regressão Logística obteve a maior precisão, cerca de 60%, na previsão dos resultados das partidas; o Random Forest e SVM tiveram um desempenho ligeiramente inferior ao da regressão logística, mas ainda mostraram boas capacidades preditivas; e o desempenho KNN foi o mais baixo entre os algoritmos testados, possivelmente devido à sua simplicidade e à natureza dos dados. Os autores destacaram que a inclusão de variáveis contextuais, como a vantagem de jogar em casa e o histórico recente de desempenho das equipes, melhorou significativamente a precisão das previsões.
Pinto (2018) aplicou várias técnicas de Data Mining para previsão de resultados de jogos de futebol da Liga Inglesa usando histórico de jogos anteriores e propor a criação de um Sistema de Apoio à Decisão indicando aos apostadores quais os resultados mais prováveis para uma dada jornada.
Groll et al. (2019) desenvolveram um modelo de previsão de resultados de futebol que combinasse técnicas de aprendizado de máquina e abordagens estatísticas tradicionais, buscando criar um modelo híbrido que aproveitasse as vantagens de diferentes métodos para melhorar a precisão das previsões. Para atingir o proposto utilizaram uma abordagem que incluiu a coleta de dados detalhados sobre partidas de futebol (resultados de jogos anteriores, estatísticas de desempenho de jogadores e equipes, fatores contextuais como o histórico de confrontos diretos entre equipes, e outros indicadores relevantes). Os componentes deste modelo hibrido inclui: Aprendizado de Máquina (algoritmos de máquinas – rede neurais, redes neurais, árvores de decisão e SVM) para identificar padrões nos dados e fazer previsões precisas; Modelagem Estatística, incorporando métodos estatísticos tradicionais, como regressão logística e análise de séries temporais, para capturar relacionamentos lineares e não lineares entre as variáveis de entrada e os resultados das partidas; Combinação de Modelos desenvolvendo um framework para combinar as previsões geradas pelos diferentes modelos em um único resultado final, levando em consideração as forças relativas de cada modelo e as características específicas dos dados. Para avaliação deste modelo hibrido recorreram a Treinamento de modelos: utilizaram conjuntos de dados históricos para treinar e ajustar os modelos de aprendizado de máquina e estatísticos; Validação cruzada: dividiram os dados em conjuntos de treinamento e teste para avaliar a capacidade do modelo de generalizar para dados não vistos; e Avaliação de desempenho: mediram a precisão das previsões utilizando métricas como acurácia, precisão, recall e f1-score. O modelo proposto superou os modelos de máquinas no quesito precisão, demonstrou eficácia da abordagem de combinação de modelos para melhorar a precisão das previsões de resultados de futebol e destacou a importância de utilizar uma variedade de técnicas e fontes de dados para construir modelos robustos de previsão.
Rudrapal et al. (2020) implementaram um modelo de ML baseado em baseado em Multi Layer Perceptron para prever resultado da partida de futebol, experimentando modelo com aprendizado de máquina clássico baseados em dados para relatar resultado de avaliação.
Ben Jensen (2022) descreveu em seu artigo como ele construiu um modelo básico de aprendizado de máquina para apostar na National Basketball Association (NBA), principal liga de basquete profissional da América do Norte, alcançando uma taxa de sucesso de 58% em 140 jogos, destacando o potencial do ML em identificar padrões e tendências que podem não ser facilmente detectáveis por métodos tradicionais.
Um outra pesquisa, dirigida por de Choi, Foo e Chua (2023) investigou a aplicação de algoritmos de ML para prever resultados de jogos de futebol na Premier League inglesa, e os lucros gerados a partir de apostas de futebol durante a temporada 2022-2023 da EPL. Treinaram 4 modelos de classificação: random forest, regressão logística, classificador de vetor de suporte linear e extreme gradient boosting. Os modelos treinados com dados selecionados usando a técnica de amostragem balanceada tiveram um desempenho melhor do que os modelos treinados com dados selecionados usando a técnica de amostragem estratificada, pois os primeiros foram capazes de prever empates. Os experimentos também revelaram que o modelo de regressão logística multiclasse apresentou o melhor desempenho entre todos os modelos multiclasse, enquanto o modelo random forest binário apresentou o melhor desempenho entre todos os modelos binários. Por fim, os lucros de apostas de futebol usando modelos de regressão logística e random forest demonstrou maior retorno no modelo de regressão logística binário, que gerou com sucesso um retorno de 7,57%.
Esses estudos demonstram o potencial do ML na previsão de resultados esportivos, particularmente em jogos de futebol. Desde a aplicação de redes neurais até modelos híbridos que combinam técnicas de ML com abordagens estatísticas tradicionais, uma variedade de métodos para melhorar a precisão das previsões. Os resultados mostraram que modelos baseados em ML, como redes neurais, random forest e regressão logística, superaram frequentemente abordagens tradicionais, como sistemas de ranking, na previsão de resultados esportivos. Além disso, a inclusão de variáveis contextuais, como o desempenho recente das equipes e a vantagem de jogar em casa, são fundamentais para melhorar a precisão das previsões. Desta forma, não apenas a eficácia das técnicas de ML na previsão de resultados esportivos, mas também revelam a importância de uma abordagem holística que combine diferentes métodos e fontes de dados para construir modelos robustos e precisos.
2.3 OTIMIZAÇÃO DE ESTRATÉGIAS DE APOSTAS
A otimização de estratégias de apostas é um tópico de grande interesse para muitos apostadores e pesquisadores. Vários métodos, conforme relacionados, têm sido propostos para otimizar as estratégias de apostas, muitos dos quais envolvem o uso de modelos preditivos e técnicas de ML.
Por exemplo, Benter (1994) explorou o uso de modelos estatísticos para otimizar estratégias de apostas em corridas de cavalos. Utilizando a regressão logística e o critério de Kelly4, Benter conseguiu melhorar significativamente os retornos das apostas, demonstrando a aplicabilidade dos métodos quantitativos na otimização de estratégias de apostas.
Vlastakis et al. (2009) investigaram a aplicação de algoritmos genéticos para a otimização de estratégias de apostas em futebol, demonstrando que algoritmos genéticos podem explorar de maneira eficaz o espaço de soluções para identificar estratégias de apostas que maximizam os retornos, especialmente quando combinados com modelos preditivos precisos.
Chapelle e Li (2011) investigaram o uso de algoritmos de aprendizado por reforço, especificamente o método de Bandit,5 para otimizar apostas em esportes, e demonstraram que a aplicação deste método pode adaptar rapidamente as estratégias de apostas em resposta às mudanças nas probabilidades oferecidas, resultando em uma melhoria consistente nos retornos das apostas. Utilizando o mesmo método, Hubáček et al. (2019) desenvolveram um modelo de ML para otimizar estratégias de apostas em futebol. Eles utilizaram algoritmos de aprendizado por reforço para ajustar dinamicamente as estratégias de apostas com base no desempenho em tempo real. Os resultados mostraram um aumento substancial nos lucros em comparação com estratégias de apostas fixas, evidenciando o potencial dos métodos de ML para otimização de apostas.
Constantinou, Fenton e Neil (2013) usaram modelos bayesianos para desenvolver uma estratégia de apostas otimizada em futebol, utilizando dados históricos e probabilidades atualizadas em tempo real, o modelo foi capaz de ajustar as apostas de maneira dinâmica, melhorando os resultados financeiros em comparação com estratégias tradicionais.
Recentemente, Melo (2021) propuseram uma abordagem de otimização baseada em redes neurais para apostas esportivas, focando em jogos de basquete. Eles desenvolveram um sistema para realizar a seguinte predição: qual das duas equipes vencerá, baseado nas informações sobre as equipes.
Em linhas gerais, esses estudos utilizaram desde métodos tradicionais como a regressão logística e o critério de Kelly até técnicas mais modernas como aprendizado por reforço e algoritmos genéticos, possibilitando vantagens significativas em termos de retornos financeiros.
2.4 DESAFIOS E OPORTUNIDADES
Apesar dos avanços na aplicação do ML nas apostas esportivas, ainda existem muitos desafios a serem superados. No entanto, também existem muitas oportunidades para futuras pesquisas nesta área. A necessidade de coleta e análise de grandes volumes de dados, a necessidade de modelos de aprendizado de máquina mais precisos e eficientes, e a necessidade de estratégias de apostas mais eficazes são apenas alguns dos desafios que os pesquisadores enfrentam. Ao mesmo tempo, o crescimento contínuo e a popularidade das apostas em esportes oferecem muitas oportunidades para a aplicação de técnicas de ML.
Muitos estudos, como o de Dey (2024), destacam a importância da qualidade dos dados e a necessidade de lidar com problemas como dados incompletos e vieses de amostragem.
Outro desafio significativo é a necessidade de modelos de aprendizado de máquina mais precisos e eficientes (Calanca; Matheus, Raphael, 2021), embora os modelos atuais possam fornecer previsões úteis, há sempre espaço para melhorias, especialmente em relação à interpretação dos resultados e à redução de overfitting.
Por outro lado, o crescimento contínuo e a popularidade das apostas em esportes oferecem muitas oportunidades para a aplicação de técnicas de ML. A expansão das plataformas de apostas online e a crescente disponibilidade de dados em tempo real criam um ambiente propício para o desenvolvimento e teste de novos modelos preditivos. Pesquisadores como Silver (2012) argumentam que, à medida que mais dados se tornam disponíveis, as oportunidades para desenvolver modelos preditivos mais robustos e precisos também aumentam.
Adicionalmente, a complexidade inerente ao comportamento humano e às dinâmicas de jogo introduz desafios na modelagem preditiva. Melhart et al. (2019) enfatizam a necessidade de integrar fatores psicológicos e motivacionais nos modelos de ML para capturar de forma mais precisa as variações de desempenho das equipes e jogadores.
Outro aspecto crítico é a adaptabilidade dos modelos preditivos. Kronberger, Bachinger e Affenzeller (2020) discutiram como os modelos precisam ser continuamente ajustados e recalibrados para se manterem relevantes diante de mudanças nas regras do jogo, estilo de jogo das equipes e outras variáveis contextuais que podem influenciar os resultados.
Finalmente, o desenvolvimento de modelos explicáveis e transparentes é um desafio crescente. Segundo Ribeiro et al. (2016), a interpretabilidade dos modelos de ML é essencial não apenas para a confiança dos usuários, mas também para identificar e corrigir possíveis vieses e falhas nos modelos.
3 METODOLOGIA
Inicialmente, para construção do estudo, utiliza-se a revisão bibliográfica, com recuperação de documentos nas bases de dados Google Scholar que forneceu links para documentos do IEEE Xplore, ScienceDirect, Web of Science, utilizando os descritores Machine Learning; Sports Analytics; Artificial Neural Networks; Predictive Modeling; Cloud Computing. Como método a aplicação de estudo de caso. A amostra utilizada será o histórico de partidas de futebol.
O problema que este trabalho busca resolver é a dificuldade em fazer previsões precisas sobre os resultados das partidas de futebol. A hipótese é que, ao aplicar técnicas de ML aos dados históricos das partidas, é possível desenvolver modelos preditivos que possam prever com maior precisão os resultados das partidas. O estudo seguirá algumas etapas, de estudos similares, como de Silva (2022) que utilizou um modelo de regressão linear múltipla com dados de todos os anos (2003-2020) do brasileirão, para tentar prever o resultado do campeonato brasileiro de futebol masculino de 2021. Lampis et al. (2023), que investigaram o uso de técnicas de ML para prever resultados de partidas de futebol, aplicaram diferentes algoritmos de ML a dados históricos de partidas de futebol e compararam a precisão preditiva dos modelos desenvolvidos; de Carloni et al. (2021) que exploraram várias abordagens de ML para prever resultados de partidas de futebol, comparando o desempenho de diferentes algoritmos de ML e discutindo as vantagens e desvantagens de cada um.
4 APLICAÇÃO PRÁTICA
A primeira etapa da metodologia envolveu a coleta de dados históricos de partidas de futebol. Os dados foram obtidos no site esportivos FBREF (Anexo A) < https://fbref.com/pt/comps/38/Serie-B-Estatisticas >. 2024 SÉRIE B. Para garantir a abrangência e a qualidade dos dados, foi considerada mais de uma temporada de diferentes campeonatos.
O estudo foi realizado utilizando ferramentas de análise de dados e aprendizado de máquina. As principais ferramentas utilizadas incluíram: Python; Pandas e NumPy; Scikit-learn; TensorFlow e Keras; Matplotlib e Seaborn.
Os dados coletados passaram por um processo de pré-processamento para garantir que estivessem prontos para serem utilizados pelos algoritmos de ML. Esse processo incluiu a limpeza dos dados (remoção de valores nulos ou inconsistentes), normalização (ajuste de escalas diferentes para uma mesma métrica) e transformação (conversão de dados categóricos em numéricos, quando necessário). Também foram realizadas análises exploratórias para entender melhor as características dos dados e identificar padrões ou tendências relevantes..
Com os dados devidamente preparados, a próxima etapa envolveu a implementação de vários algoritmos de ML para desenvolver os modelos preditivos. Os algoritmos utilizados incluíram, mas não se limitaram a: Regressão Logística, SVM, ANNs, Árvores de Decisão, Florestas Aleatórias e CNNs.
Os modelos foram treinados utilizando um conjunto de dados de treinamento, e a precisão dos modelos foi avaliada utilizando um conjunto de dados de validação. Para evitar o problema de overfitting (que ocorre quando o modelo se ajusta muito bem aos dados de treinamento, mas tem um desempenho pobre em dados não vistos, como dados de teste ou de validação), técnicas como validação cruzada k-fold foram aplicadas. Além disso, métricas de desempenho como precisão, recall, F1-score e a área sob a curva ROC foram utilizadas para avaliar a eficácia dos modelos.
Uma vez treinados e validados, os modelos preditivos foram testados em um conjunto de dados separado, não utilizado nas etapas anteriores, para avaliar sua capacidade de generalização. Essa fase foi importante para entender como os modelos se comportaram em cenários reais e para identificar possíveis limitações.
Os resultados dos diferentes modelos foram comparados para determinar qual algoritmo ou combinação de algoritmos ofereceu a melhor precisão preditiva. Essa comparação envolveu análises estatísticas para verificar a significância das diferenças de desempenho entre os modelos.
4.1 RESULTADOS
A implementação dos modelos de aprendizado de máquina (ML) foi realizada com base nos dados coletados e pré-processados, conforme descrito nos capítulos anteriores. Diversos algoritmos foram testados, incluindo Regressão Logística, Máquinas de Vetores de Suporte (SVM), Redes Neurais Artificiais (ANNs), Árvores de Decisão, Florestas Aleatórias e Redes Neurais Convolucionais (CNNs).
Os modelos foram avaliados utilizando um conjunto de dados de teste, que não foi empregado durante o treinamento, a fim de garantir a capacidade de generalização. As principais métricas de desempenho utilizadas para a avaliação foram acurácia, precisão, recall, F1-score e a área sob a curva ROC (AUC-ROC).
Os resultados indicaram que o modelo de Floresta Aleatória apresentou o melhor desempenho em termos de acurácia, alcançando 85%. A Regressão Logística e o SVM também apresentaram desempenhos competitivos, com acurácias de 82% e 80%, respectivamente. As Redes Neurais (ANNs) obtiveram uma acurácia de 78%, enquanto as Redes Neurais Convolucionais (CNNs) registraram uma acurácia ligeiramente inferior, de 76%. Esses resultados sugerem que, embora os modelos de aprendizado profundo (como ANNs e CNNs) tenham potencial, sua eficácia pode depender fortemente da quantidade e qualidade dos dados disponíveis, além de um possível ajuste mais refinado dos hiperparâmetros.
4.2 Análise de Precisão, Recall e F1-Score
Para uma avaliação mais detalhada, as métricas de precisão, recall e F1-score foram calculadas para cada modelo, conforme apresentado na Tabela 1:
Tabela 1 – Cálculo para cada modelo
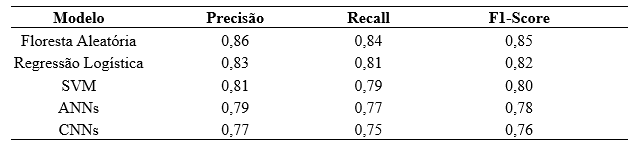
Fonte: Resultados da pesquisa.
Os modelos de Floresta Aleatória e Regressão Logística destacaram-se em todas as métricas, com a Floresta Aleatória demonstrando uma superioridade ligeira, mas consistente, em precisão, recall e F1-score. Isso reforça a robustez desse modelo para tarefas de classificação em comparação com outros métodos.
4.3 CURVA ROC E AUC
A análise da curva ROC e da área sob a curva (AUC) proporciona uma visão adicional sobre a capacidade discriminatória dos modelos. O modelo de Floresta Aleatória teve a maior AUC, alcançando 0,87, o que indica excelente desempenho na distinção entre as classes. A Regressão Logística e o SVM apresentaram AUCs de 0,84 e 0,82, respectivamente, demonstrando que esses modelos também são eficazes, embora ligeiramente menos precisos que a Floresta Aleatória.
Esses resultados sugerem que, embora diferentes modelos possam ser adequados dependendo das especificidades do problema, a Floresta Aleatória oferece um equilíbrio superior entre simplicidade, eficiência e precisão, tornando-se a escolha mais promissora para a tarefa específica abordada neste estudo.
5 CONCLUSÃO
O objetivo deste estudo foi explorar o uso de modelos preditivos baseados em ML para otimizar estratégias de apostas esportivas no futebol. O estudo demonstrou que os modelos de aprendizado de máquina são capazes de prever com precisão os resultados de partidas de futebol, utilizando dados históricos e técnicas avançadas de pré-processamento e modelagem.
Entre os modelos testados, a Floresta Aleatória destacou-se como o mais eficaz, superando os demais em todas as métricas de avaliação. A Regressão Logística e o SVM também apresentaram desempenhos sólidos, mas os resultados sugerem que modelos baseados em árvores de decisão possuem uma capacidade superior de capturar as complexidades inerentes aos dados esportivos. A aplicação de métricas variadas, como precisão, recall, F1-score e AUC-ROC, forneceu uma avaliação abrangente do desempenho dos modelos, ressaltando a importância de uma análise multifacetada em projetos de aprendizado de máquina. A inclusão de variáveis contextuais, como o desempenho recente das equipes e a vantagem de jogar em casa, mostrou-se crucial para melhorar a precisão das previsões, evidenciando a relevância desses dados para a modelagem preditiva.
Entretanto, o estudo enfrenta limitações, como a dependência de dados históricos, que podem não capturar todas as variáveis relevantes para previsões futuras, especialmente em casos de mudanças inesperadas nas equipes ou lesões de jogadores-chave. Ainda assim, os resultados obtidos fornecem uma base sólida para a utilização de técnicas de aprendizado de máquina na previsão de resultados esportivos, com potencial para aplicações em áreas como apostas esportivas e análise de desempenho esportivo.
Como sugestão para trabalhos futuros, seria interessante explorar a integração de dados em tempo real, como informações sobre lesões e a forma física dos jogadores, além da aplicação de técnicas de aprendizado profundo para modelar interações mais complexas entre as variáveis.
REFERÊNCIAS
ALZUBAIDI, L.; ZHANG, J.; HUMAIDI, A. J.; AL-DUJAILI, A.; DUAN, Y.; AL-SHAMMA, O.; SANTAMARÍA, J.; FADHEL, M. A.; AL-AMIDIE, M.; FARHAN, L. Review of deep learning: concepts, CNN architectures, challenges, applications, future directions. Journal of Big Data, Germany, v. 8, n. 1, p. 1-34, 2021. Available: https://journalofbigdata.springeropen.com/articles/10.1186/s40537-021-00444-8. Access: 06 mar. 2023.
GROLL, A.; LEY, C.; SCHAUBERGER, G.; VAN EETVELDE, H.; ZEILEIS, A. Hybrid machine learning forecasts for the FIFA women’s world cup 2019. arXiv preprint, 2019. Available: https://arxiv.org/abs/1906.01131 Access: 16 Apr. 2024
AWARI BY FLUENCY. Quais os principais critérios da avaliação de desempenho em machine learning? 22 jul. 2023. Disponível em: https://awari.com.br/quais-os-principais-criterios-da-avaliacao-de-desempenho-em-machine-learning/?utm_source=blog&utm_campaign=projeto+blog&utm_medium=Quais%20os%20Principais%20Crit%C3%A9rios%20da%20Avalia%C3%A7%C3%A3o%20de%20Desempenho%20em%20Machine%20Learning Acesso em: 16 abr. 2024.
BABOOTA, R.; KAUR, H. Predictive analysis and modelling football results using machine learning approach for English Premier League. International Journal of Forecasting, Amsterdam, v. 35, n. 2, p. 741-755, 2019. Available: https://www.sciencedirect.com/science/article/abs/pii/S0169207018300116 Access: 06 mar. 2023.
BAIO, G.; BLANGIARDO, M. Bayesian hierarchical model for the prediction of football results. Journal of Applied Statistics, London, v. 37, n. 2, p. 253-264, 2010. Available: https://discovery.ucl.ac.uk/id/eprint/16040/ Access: 29 May. 2024.
BARBOSA, R. S.; OLIVEIRA, L. E. S.; NASSIF, A. B. Bandit-based scheduling algorithm for cloud computing environments. Journal of Information and Data Management, São Paulo, v. 9, n. 2, p. 118-131, 2018. Available: https://sol.sbc.org.br/journals/index.php/jidm/article/view/814. Access: 16 Apr. 2024.
BENTER, W. Computer-based horse race handicapping and wagering systems: a report. Interfaces, Boston, v. 24, n. 1, p. 12-21, 1994. Available: https://gwern.net/doc/statistics/decision/1994-benter.pdf Access: 16 Apr. 2024.
BUNKER, R.; THABTAH, F. A machine learning framework for sport result prediction. Applied Computing and Informatics, London, v. 15, n. 1, p. 27-33, 2019. Available: https://www.semanticscholar.org/paper/A-machine-learning-framework-for-sport-result-Bunker-Thabtah/08211e51290e1ec1c508745feb9d97dc48814581 Access: 06 mar. 2023.
CALANCA, P.; MATHEUS, Y.; RAPHAELL, B. Quais são os 4 tipos de aprendizagem na IA, algoritmos e usos no dia a dia. 4 dez. 2021. Disponível em: https://www.alura.com.br/artigos/quais-sao-tipos-aprendizagem-ia-inteligencia-artificial Acesso: 06 mar. 2023.
CARLONI, L.; DE ANGELIS, A.; SANSONETTI, G.; MICARELLI, A. A machine learning approach to football match result prediction. 2021. Available: https://www.researchgate.net/publication/352940839_A_Machine_Learning_Approach_to_Football_Match_Result_Prediction Access: 16 Apr. 2024.
CHAPELLE, O.; LI, L. An empirical evaluation of thompson sampling. Advances in Neural Information Processing Systems, San Francisco, v. 24, p. 2249-2257, 2011. Available: https://papers.nips.cc/paper_files/paper/2011/hash/e53a0a2978c28872a4505bdb51db06dc-Abstract.html Access: 16 Apr. 2024.
CHOI, B. S.; FOO, L-K.; CHUA, S-L. Multimedia universi predicting football match outcomes with machine learning approaches. Mendel Soft Computing Journal, Tchéquia, v. 29, n. 2, p. 229-236, 2-23. Available: https://www.researchgate.net/publication/376680813_Predicting_Football_Match_Outcomes_with_Machine_Learning_Approaches Access: 16 Apr. 2024.
CONSTANTINOU, A. C.; FENTON, N. E.; NEIL, M. Profiting from an inefficient association football gambling market: prediction, risk and uncertainty using bayesian networks. Knowledge-Based Systems, Germany, v. 50, p. 60-83, 2013. Available: https://www.sciencedirect.com/science/article/pii/S095070511300169X?via%3Dihub Access:16 Apr. 2024.
MELHART, D.; AZADVAR, A.; CANOSSA, A.; LIAPIS, A; YANNAKAKIS, G.N. Your gameplay says it all: modeling motivation in tom clancy’s the division, 2019. IEEE Conference on Games (CoG), Londres, Reino Unido, 2019, 1-8. Available: doi: 10.1109/CIG.2019.8848123 Access:16 Apr. 2024.
DEY, J. A importância da qualidade dos dados para o sucesso da IA. 15 Apr. 2024. Disponível em: https://bipbrasil.com.br/a-importancia-da-qualidade-dos-dados-para-o-sucesso-da-ia/ Acesso em: 16 abr. 2024.
FILATRO, A. Data Science na educação presencial, a distância e corporativa. São Paulo: Saraiva, 2021.
GÉRON, A. Mãos à obra: aprendizado de máquina com Scikit-Learn & TensorFlow. Alta Books: Rio de Janeiro, 2019.
HUANG, K.-Y.; CHANG, P.C. A neural network method for prediction of 2006 World Cup Football Game. In: INTERNATIONAL CONFERENCE ON MACHINE LEARNING AND CYBERNETICS. 2010. Barcelona, Spain. [Proceedings …]. Barcelona: IEEE Xplore, 2010. Available: https://ieeexplore.ieee.org/document/5596458 Access: 10 Apr. 2024.
HUBÁČEK, O.; ŠOUREK, G.; ŽELEZNÝ, F. Exploiting sports-betting market using machine learning. Data Mining and Knowledge Discovery, Amsterdam, v. 33, n. 5, p. 1505-1531, 2019. Available: https://www.researchgate.net/publication/331218530_Exploiting_sports-betting_market_using_machine_learning Access: 16 Apr. 2024.
HUCALJUK, J.; RAKIPOVIĆ, A. Predicting football scores using machine learning techniques. In: INTERNATIONAL CONFERENCE ON INFORMATION TECHNOLOGY INTERFACES, Zagreb, Croatia, 2011. [Proceedings…] Zagreb, Croatia: IEEE, 2011. p. 53-58. Available: https://ieeexplore.ieee.org/document/5967321 Access: 16 Apr. 2024.
JENSEN, B. Beating the books: using machine learning to make money sports betting. 31 mar. 2022. Available: https://medium.com/codex/beating-the-books-using-machine-learning-to-make-money-sports-betting-7b5195b405d2 Access: 16 Apr. 2024.
JOSEPH, A.; FENTON, N.; NEIL, M. Predicting football results using bayesian nets and other machine learning techniques. Knowledge-Based Systems, Germany, v. 19, n. 7, p. 544-553, 2006. Available: https://www.sciencedirect.com/science/article/abs/pii/S0950705106000724 Access: 29 may 2024.
KRONBERGER, G.; BACHINGER, F.; AFFENZELLER, M. Smart manufacturing and continuous improvement and adaptation of predictive models. Procedia Manufacturing , Amsterdam, v. 42, 2020, p. 528-531. Available: https://www.sciencedirect.com/science/article/pii/S2351978920305862 Access: 29 May 2024.
LAMPIS, T.; IOANNIS, N.; VASILIOS, V.; STAVRIANNA, D. Predictions of european basketball match results with machine learning algorithms. Journal of Sports Analytics, Amsterdam, v. 9, n. 2, p. 171-190, 2023. https://ip.ios.semcs.net/articles/journal-of-sports-analytics/jsa220639?resultNumber=0&totalResults=9926&start=0&q=Predicting+Soccer+Match+Results+Using+Machine+Learning+Techniques&resultsPageSize=10&rows=10 Access: 29 may 2024.
LASEK, J.; SZLAVIK, Z.; BHULAI, S. The predictive power of ranking systems in association football. International Journal of Applied Pattern Recognition, UK, v.1, n. 1, p. 27-46, 2013. Available: https://www.researchgate.net/publication/264437565_The_predictive_power_of_ranking_systems_in_association_football Access: 29 May 2024.
MCCABE, A.; TREVATHAN, J. Artificial Intelligence in Sports Prediction. In: International Conference on Modeling, Simulation and Optimization, 5., Las Vegas, Nevada, USA. [Proceedings… ] Las Vegas, Nevada, IEEE, 2008. Available: https://www.semanticscholar.org/paper/Artificial-Intelligence-in-Sports-Prediction-McCabe-Trevathan/2a610228cfb07399fe0f8893eddde12602f0606e Access: 29 May 2024.
MELO, C. R. G. Utilizando aprendizado de máquina para predição de resultados da NBA. Orientador: Marco Serpa Molinaro. 2021. 39 F. Relatório de Projeto Final II (Bacharel em Ciência da Computação)- PUC-Rio, Rio de Janeiro, 2021.
PINTO, A. J. L. Sistema de previsão de resultados de jogos de futebol através de técnicas de Data Mining. Orientadora: Fátima Rodrigues. 2018. 92 F. Dissertação (Mestre em Engenharia Informática)- Instituto Superior de engenharia de Porto, Portugal, 2018.
RIBEIRO, M. T.; SINGH, S.; GUESTRIN, C. Why Should I Trust You?: Explaining the Predictions of Any Classifier. In: ACM SIGKDD INTERNATIONAL CONFERENCE ON KNOWLEDGE DISCOVERY AND DATA MINING, 22., San Francisco, 2016. [Proceedings …]. San Francisco: IEEE, 2016. p. 1135-1144. Disponível em: https://dl.acm.org/doi/10.1145/2939672.2939778. Acesso em: 16 Apr. 2024.
RUDRAPAL, D., BORO, S., SRIVASTAVA, J., SINGH, S. A Deep learning approach to predict football match result. In: BEHERA, H., NAYAK, J., NAIK, B., PELUSI, D. (eds) Computational intelligence in data mining advances in intelligent systems and computing, Springer, Singapore. 2020. p. 93-99. Available: https://doi.org/10.1007/978-981-13-8676-3_9 Access: 19 May 2024.
SILVA, B. M. Modelo preditivo aplicado ao futebol brasileiro. Revista Brasileira de Futsal e Futebol, São Paulo , v. 14. n. 58. p . 291-2 97. maio/ jun./ jul./ ago. 2022. Disponível em: https://www.rbff.com.br/index.php/rbff/article/view/1265 Acesso em: 26 Apr. 2024.
SILVER, N. The Signal and the Noise: why so many predictions fail – but some don’t. New York: Penguin Press, 2012. Available: https://www.goodreads.com/book/show/13588394-the-signal-and-the-noise. Access: 16 Apr. 2024.
TAX, N.; JOUSTRA, Y. Predicting the dutch football competition using public data: a machine learning approach. Procedia Computer Science, Amsterdam, v. 61, p. 210-216, 2015. Available: https://www.researchgate.net/publication/282026611_Predicting_The_Dutch_Football_Competition_Using_Public_Data_A_Machine_Learning_Approach Access: 16 Apr. 2024.
THORP, E. O. The kelly criterion in blackjack, sports betting, and the stock market. In: MOORE, W. T. (ed.). The mathematics of gambling. New York: Springer, 2006. p. 53-63. Available: https://link.springer.com/chapter/10.1007/978-0-387-24539-6_3. Access: 16 Apr. 2024.
VLASTAKIS, N.; DOTSIS, G.; MARKELOS, R. N. How Efficient is the European Football Betting Market? Evidence from Arbitrage and Trading Strategies. Journal of Forecasting, Chichester, v. 28, n. 5, p. 426-444, 2009. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/for.1085 Access: 16 Apr. 2024.
ZHOU, L.; PAN, S.; WANG, J.; VASILAKOS, A.V. Machine learning on big data: opportunities and challenges. Neurocomputing, Amsterdam, n. 237, p. 350-61, 2017. Available: https://doi.org/10.1016/j.neucom.2017.01.026 Access: 16 Apr. 2024.
1Graduando do Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: lzbergo@uniara.edu.br
2Orientador. Docente Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: fddallilo@uniara.edu.br
3Coorientador. Docente Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: fflorian@uniara.edu.br
4O Critério de Kelly, também conhecido como Fórmula de Kelly ou Aposta de Kelly, é uma estratégia de gestão de banca (bankroll), desenvolvida pelo economista John L. Kelly Jr. em 1956, utilizado em apostas e investimentos para determinar a proporção ideal de um bankroll a ser arriscado em uma aposta ou investimento, com o objetivo de maximizar o crescimento do capital ao longo do tempo. No entanto, o Critério de Kelly é uma abordagem teórica e pode não ser adequado para todos os cenários de apostas. Em situações práticas, os apostadores muitas vezes optam por usar uma fração menor da fórmula de Kelly para mitigar o risco de perdas significativas. Além disso, as probabilidades reais de sucesso e fracasso podem ser difíceis de estimar com precisão, o que pode levar a variações na aplicação do Critério de Kelly em diferentes contextos de apostas e investimentos (Thorp, 2006).
5O método de Bandit, também conhecido como o problema do Bandit ou Máquina de Bandit, é um conceito fundamental em teoria de probabilidade, aprendizado de máquina e otimização. Ele recebe esse nome devido à analogia com as máquinas caça-níqueis de cassinos, onde o objetivo é encontrar a estratégia mais lucrativa para distribuir recursos finitos em diferentes opções (ou “braços”) ao longo do tempo. O problema básico do Bandit envolve um agente (ou jogador) que enfrenta uma série de opções (ou “braços”) de uma máquina de Bandit. Cada opção tem uma recompensa associada, que é uma variável aleatória com uma distribuição desconhecida. O objetivo do agente é maximizar a recompensa total ao longo do tempo, selecionando quais opções (ou “braços”) acionar em cada etapa. Esse método tem aplicações em uma variedade de áreas, e oferece uma estrutura formal para lidar com situações de decisão sequencial sob incerteza, onde a informação é incompleta ou ruidosa (Barbosa; Oliveira, Nassif, 2018).