STUDIES OF ATTRIBUTE SELECTION IN FORECAST MODELS: A BEHAVIORAL ANALYSIS
REGISTRO DOI: 10.5281/zenodo.10073596
Augusto Santos Bettin¹
Felipe Moreira da Silva¹
Gabriel Marinelli Rodrigues Davenia Piro¹
Lucas dos Santos Oliveira¹
Alan Ferreira¹
Josemar dos Santos²
RESUMO
No âmbito da modelagem preditiva, especialmente em áreas como saúde, economia e marketing, a estimativa precisa da probabilidade de eventos ou comportamentos específicos é crucial. Os modelos de propensão, também conhecidos como modelos de pontuação, desempenham um papel fundamental nesse contexto, auxiliando na previsão da ocorrência de tais eventos ou comportamentos para indivíduos ou entidades. Central para o desenvolvimento de um modelo de propensão robusto está a seleção de features pertinentes. A seleção de features envolve identificar atributos que possuam um poder preditivo significativo, reduzindo a complexidade do modelo e aprimorando a interpretabilidade. Essa tarefa é crucial, pois visa criar um subconjunto ótimo de features que encapsulem da melhor forma possível a relação entre variáveis independentes e a variável alvo. Com uma infinidade de métodos de seleção de features disponíveis, avaliar sua eficácia e aplicabilidade em contextos distintos torna-se imperativo. Esta pesquisa busca realizar uma análise comparativa de diversas técnicas de seleção de features dentro do contexto de um modelo de propensão. O objetivo final é determinar o método de seleção de features mais adequado que esteja alinhado com as nuances do conjunto de dados utilizado.
Palavras-chave: Modelos Preditivos. Seleção de Recursos. Modelos de propensão.
ABSTRACT
In the realm of predictive modeling, particularly in fields like healthcare, economics, and marketing, the accurate estimation of the likelihood of specific events or behaviors is crucial. Propensity models, also known as scoring models, are instrumental in this regard, aiding in predicting the occurrence of such events or behaviors for individuals or entities. Central to the development of a robust propensity model is the selection of pertinent features. Feature selection involves identifying attributes that wield significant predictive power, streamlining model complexity, and enhancing interpretability. This task is pivotal as it aims to create an optimal subset of features that best encapsulate the relationship between independent variables and the target variable. With a plethora of feature selection methods available, assessing their efficacy and applicability in distinct contexts becomes imperative. This research endeavors to undertake a comparative analysis of varied feature selection techniques within a propensity model framework. The ultimate objective is to ascertain the most suitable feature selection method that aligns with the nuances of the utilized dataset.
Keywords: Preditive Models. Feature Selection. Propension Models.
1. INTRODUÇÃO
No contexto de estudos relacionados à intenção de compra de um produto, é relevante abordar o conceito de intenção de compra, que se refere à predisposição dos consumidores em adquirir um determinado item ou serviço dentro de um período específico. O termo em questão, frequentemente usado no campo de marketing e negócios, é utilizado para descrever a vontade expressa pelos potenciais compradores em realizar uma transação comercial.
Assim como o churn rate, que mede a saída de clientes de uma empresa, a intenção de compra é uma métrica relevante para avaliar a eficácia das estratégias de marketing e o potencial de crescimento de uma organização no mercado (Brown 2018). Portanto, compreender a intenção de compra dos consumidores e implementar ações para aumentá-la é essencial para o sucesso sustentável das empresas no cenário competitivo atual.
Nesse contexto, foi possível recuperar um conjunto de dados que de uma seguradora que tem como objetivo saber se os clientes que possuíam seu Seguro Saúde no ano passado ainda também terão interesse em adquirir o Seguro Automóvel que a seguradora fornece.
CAPTURA, PRÉ PROCESSAMENTO E ANÁLISE EXPLORATÓRIA
A captura de dados desempenha um papel fundamental na pesquisa científica, permitindo a coleta de informações relevantes para análises posteriores. Conforme definido por Chen e Zhang (2014), a captura de dados é o processo de coleta, organização e armazenamento de informações de fontes diversas.
Após a captura de dados, outra etapa fundamental é o pré-processamento. Como apontado por Fayyad et al. (1996), o pré-processamento refere-se à limpeza e transformação dos dados brutos em um formato adequado para análise. Isso inclui tratamento de valores ausentes, detecção e tratamento de outliers, normalização e redução de dimensionalidade, quando necessário. Um pré-processamento eficaz é essencial para garantir a validade e a qualidade dos resultados da análise.
A análise exploratória de dados (AED) é uma abordagem crucial após o pré-processamento. Conforme proposto por Tukey (1977), a AED envolve a exploração visual e estatística dos dados para revelar padrões, tendências e insights iniciais. Essa fase auxilia na formulação de hipóteses e na identificação de áreas de interesse para análises mais aprofundadas.
No contexto, a análise desempenha um papel fundamental na compreensão dos dados coletados e na identificação de tendências que podem ser relevantes para a pesquisa. Além disso, pode ajudar a definir a estratégia analítica apropriada para responder às perguntas de pesquisa.
MACHINE LEANING E ALGORITMO DE ARVORE
Machine Learning (Aprendizado de Máquina) é uma disciplina da inteligência artificial que revolucionou a maneira como enfrentamos problemas complexos de previsão e classificação. Esse campo se concentra no desenvolvimento de algoritmos e modelos que permitem que sistemas aprendam a partir de dados, em vez de serem programados de maneira explícita. Essa abordagem torna o Machine Learning uma ferramenta poderosa para diversas aplicações, desde o reconhecimento de padrões até a tomada de decisões automatizada (Mitchell, 1997). A Figura 1 nos mostra como machine learning é usado de uma maneira sucinta
Figura 1 – Esquema do aprendizado supervisionado
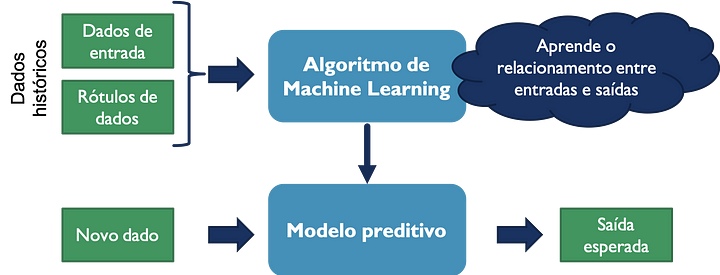
Fonte: Tatiana Escovedo & Adriano S. Koshiyama (2020)
O Machine Learning abrange uma variedade de técnicas, desde aprendizado supervisionado até não supervisionado e aprendizado por reforço. Essas abordagens permitem que os sistemas aprendam com dados históricos e gerem previsões ou tomem decisões com base nessas experiências (Bishop, 2006). Na figura 2 é mostrado um possível esquema de árvore de decisão.
Figura 2 – Esquema de Árvore de Decisão
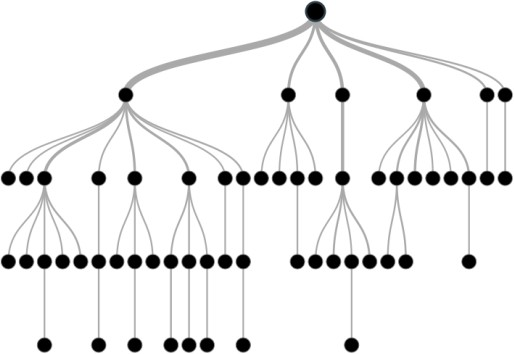
Fonte: Analytics Vidhya (2016)
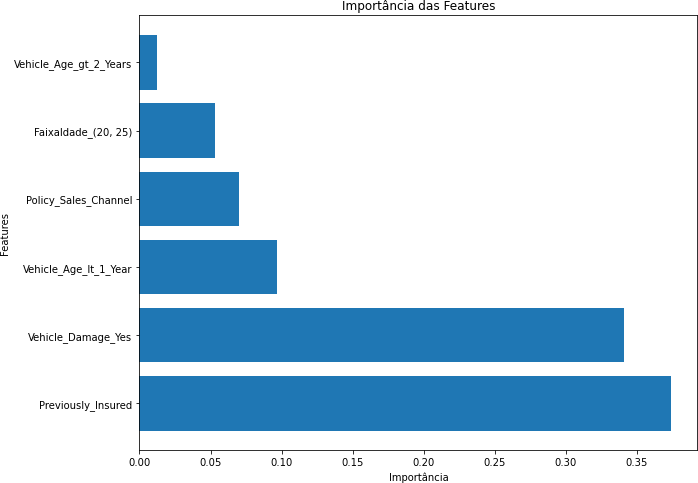
Os algoritmos de árvore são amplamente utilizados devido à sua capacidade de modelar relacionamentos complexos entre variáveis de entrada e variáveis de saída (Quinlan, 1986). Eles são particularmente úteis em tarefas de classificação, onde o objetivo é atribuir uma classe ou categoria a um conjunto de dados com base em características específicas. Uma das implementações mais notáveis de algoritmos de árvore é o Random Forest, que se destaca por sua eficiência e precisão (Breiman, 2001).
ALGORITMOS DE ÁRVORE
Os algoritmos de árvore são uma categoria de algoritmos de Machine Learning que se baseiam na estrutura de uma árvore de decisão. Eles funcionam dividindo os dados em conjuntos menores com base em características específicas, seguindo um processo hierárquico até que uma decisão seja alcançada. Alguns dos algoritmos de árvore mais conhecidos incluem:
- Árvores de Decisão (Decision Trees): As árvores de decisão são estruturas hierárquicas que dividem os dados com base em regras de decisão, permitindo a classificação ou previsão de saídas com base nas características de entrada.
- Árvores de Regressão (Regression Trees): Semelhantes às árvores de decisão, as árvores de regressão são usadas para prever valores numéricos, em oposição à classificação. Elas são particularmente eficazes em problemas de regressão.
- Árvores de Classificação (Classification Trees): As árvores de classificação são usadas para dividir os dados em categorias ou classes. Elas são amplamente aplicadas em tarefas de classificação, como diagnóstico médico e detecção de fraudes.
RANDOM FOREST
O Random Forest é uma das implementações mais proeminentes dos algoritmos de árvore. Ele se destaca por sua capacidade de combinar várias árvores de decisão para obter previsões mais robustas e precisas. O Random Forest segue um processo de treinamento e previsão da seguinte forma:
- Treinamento: Um conjunto de dados de treinamento é dividido em subconjuntos aleatórios, e várias árvores de decisão são construídas usando esses subconjuntos. Essa diversidade introduz a aleatoriedade e ajuda a evitar o overfitting.
- Previsão: Para fazer uma previsão, cada árvore na floresta recebe os dados de entrada e gera uma previsão. O Random Forest combina as previsões de todas as árvores, frequentemente usando votação por maioria, para determinar a previsão final.
Essa abordagem de combinação das previsões de várias árvores torna o Random Forest altamente resistente a ruído e eficaz em uma ampla gama de tarefas, tornando-o uma escolha popular em Machine Learning.
FEATURE SELECTION
FEATURE SELECTION (SELEÇÃO DE CARACTERÍSTICAS)
A seleção de características desempenha um papel fundamental no campo de Machine Learning. Esse processo envolve a escolha das variáveis de entrada mais relevantes ou informativas para um determinado problema, enquanto descarta as que contribuem menos para a tarefa em questão. A seleção apropriada de características pode melhorar significativamente o desempenho do modelo, reduzir a complexidade e economizar recursos computacionais (Guyon & Elisseeff, 2003).
IMPORTÂNCIA DA SELEÇÃO DE CARACTERÍSTICAS
A escolha das características certas é crucial em Machine Learning. Dados de entrada frequentemente incluem muitas características, algumas das quais podem ser irrelevantes, redundantes ou até prejudiciais ao desempenho do modelo. A seleção de características resolve esse problema, melhorando a precisão do modelo e simplificando a interpretação dos resultados.
TÉCNICAS DE SELEÇÃO DE CARACTERÍSTICAS
Existem várias técnicas para selecionar características, e a escolha da técnica apropriada depende do problema em questão. Algumas das técnicas comuns de seleção de características incluem:
- Seleção Univariable: Essa abordagem avalia cada característica independentemente de outras e seleciona as melhores com base em métricas como a correlação, a análise de variância ou testes estatísticos (Kohavi & John, 1997).
- Eliminação Recursiva de Características: Nessa técnica, o modelo é treinado em todas as características e, em seguida, as características menos importantes são removidas iterativamente, com base em alguma métrica de importância, até que um número desejado de características seja alcançado (Guyon et al., 2002).
- Seleção de Características baseada em Importância: Alguns algoritmos, como o Random Forest, fornecem pontuações de importância para cada característica. Essas pontuações podem ser usadas para selecionar as características mais relevantes (Breiman, 2001).
BENEFÍCIOS DA SELEÇÃO DE CARACTERÍSTICAS
- A seleção de características oferece uma série de benefícios, incluindo:
- Melhoria do desempenho do modelo.
- Redução da complexidade do modelo.
- Menor risco de overfitting.
- Redução de requisitos computacionais.
- Interpretação mais clara do modelo.
Figura 3 – Benefícios da Seleção de Características
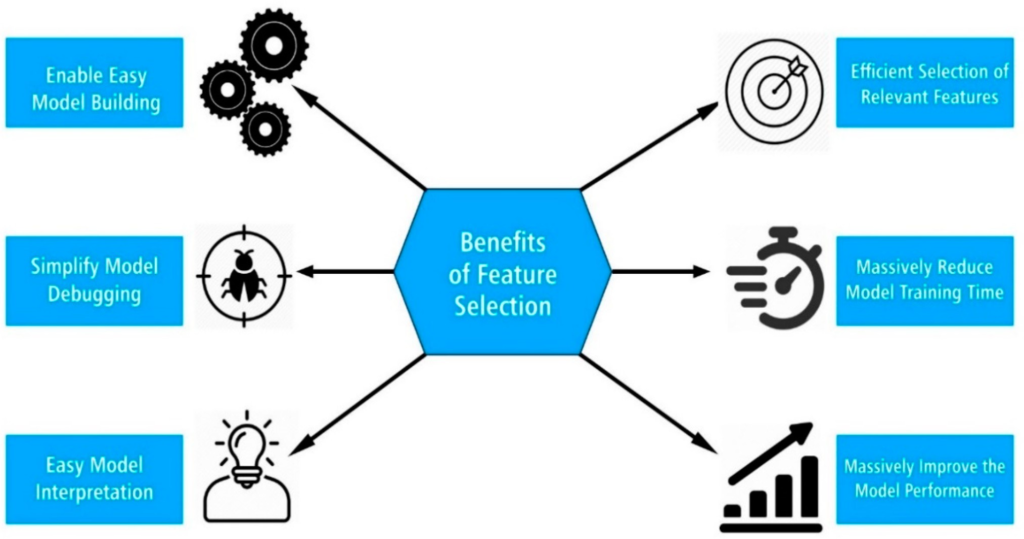
Fonte: Ebrima Jaw & Xueming Wang (2021)
A seleção de características é uma etapa crucial no pré-processamento de dados em projetos de Machine Learning, e a escolha da técnica certa pode ter um impacto significativo nos resultados. No próximo capítulo, aprofundaremos nas técnicas específicas de seleção de características e suas aplicações em problemas do mundo real.
CORRELAÇÃO DE PEARSON
Usada para quantificar a correlação linear entre duas variáveis continuas X e Y. A saída varia de [-1,+1], onde -1 significa correlação negativa perfeita (quando X cresce, Y diminui) e +1 significa correlação positiva perfeita (quando X cresce, Y cresce). O coeficiente de correlação de Pearson P(X,Y) é mostrada na equação 1.
Equação 1 – Equação da Correlação de Pearson
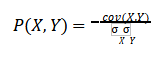
ELIMINAÇÃO RECURSIVA DE CARACTERÍSTICAS (RFE)
A Eliminação Recursiva de Características (RFE) é uma técnica que se concentra em treinar o modelo repetidamente, removendo características menos importantes em cada iteração. Isso é geralmente aplicado em algoritmos de Machine Learning que têm a capacidade de fornecer uma medida de importância das características.
Aplicação: A RFE é usada durante a seleção de características para identificar e eliminar características menos importantes, com base nas pontuações de importância do modelo.
SELEÇÃO DE CARACTERÍSTICAS BASEADA NA RANDOM FOREST
A Random Forest é uma técnica de Machine Learning que fornece pontuações de importância para cada característica. Essas pontuações podem ser usadas na seleção de características para identificar as mais relevantes.
Aplicação: A seleção de características baseada na Random Forest é valiosa durante a seleção de características, aproveitando as pontuações de importância das características geradas pela Random Forest.
ANÁLISE DE CORRELAÇÃO
Outro tópico importante a se avaliar é a correlação entre as variáveis independentes e a variável dependente e compreender as relações existentes. A análise de correlação é uma ferramenta fundamental na investigação estatística, permitindo identificar se é como as variáveis estão associadas. Os resultados dessa análise serão apresentados na tabela 1:
Tabela 1 – Analise de Correlação
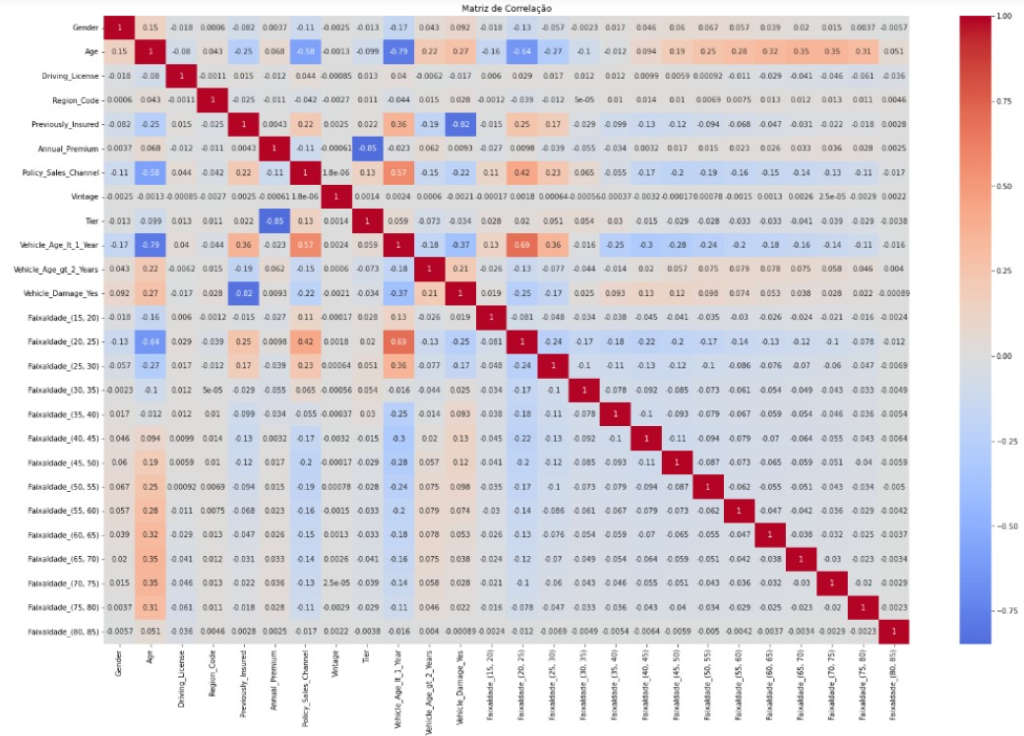
Fonte: Autoria própria
METRICAS DE AVALIAÇÃO DO MODELO PREDITIVO
ACURÁCIA
A acurácia é uma métrica simples e amplamente utilizada que mede a proporção de previsões corretas feitas pelo modelo em relação ao número total de previsões. Na equação 2 está representada a seguir como a acurácia é calculada:
Equação 2 – Calculo da Acurácia

A acurácia é uma métrica importante, mas não deve ser a única considerada, uma vez que pode ser enganosa em casos de desequilíbrio de classes (Han et al., 2011).
F1-SCORE
O F1-Score é uma métrica que combina a precisão e o recall em um único valor. Ele é particularmente útil em situações em que o desequilíbrio de classes é um problema, pois leva em consideração tanto os verdadeiros positivos quanto os falsos negativos e falsos positivos (Powers, 2011). Na equação 2 demonstra como o indicador é calculado:
Equação 3 – Calculo F1-Score
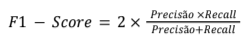
RECALL
O Recall, também conhecido como sensibilidade ou taxa de verdadeiros positivos, mede a capacidade do modelo em identificar todos os exemplos positivos da classe de interesse. A equação 4 ilustra o procedimento de cálculo do Recall:
Equação 4 – Cálculo do Recall

PRECISÃO
A Precisão mede a capacidade do modelo em fazer previsões positivas
corretas em relação ao total de previsões positivas. A fórmula para calcular a precisão do modelo é descrita na equação 5 apresentada a seguir:
Equação 5 – Cálculo da Precisão

AUC-ROC
A Área sob a Curva da Característica de Operação do Receptor (AUC-ROC) é uma métrica que avalia a capacidade do modelo em distinguir entre as classes. Quanto maior a AUC-ROC, melhor o modelo é em separar as classes (Fawcett, 2006), no Gráfico 1 podemos ver uma curva de ROC.
Gráfico 1 – Curva ROC
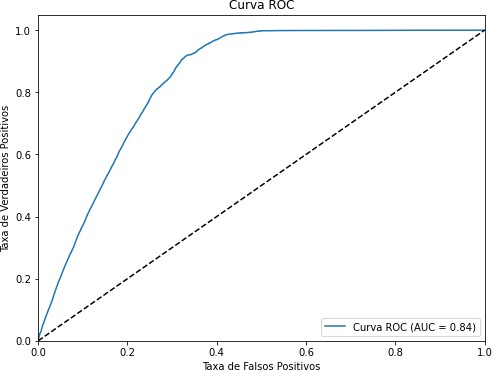
Fonte: Autoria Própria
MATRIZDECONFUSÃO
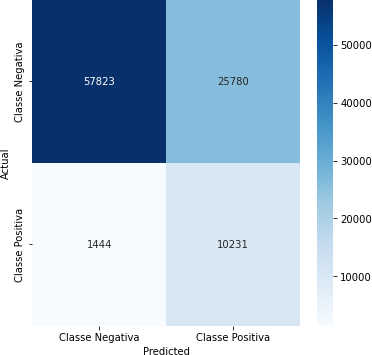
A matriz de confusão é uma tabela que resume o desempenho do modelo, mostrando o número de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos.
Tabela 2 – Matriz de Confusão
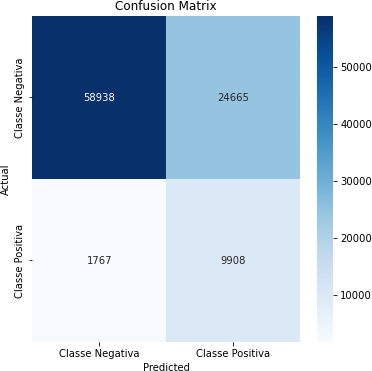
Fonte: Autoria Própria
KS(KOLMOGOROV-SMIRNOV)
O índice KS é uma métrica frequentemente utilizada em problemas de classificação, especialmente em avaliações de risco de crédito. Ele mede a capacidade do modelo em separar as distribuições de probabilidade das classes positivas e negativas (Hand, 2009).
METODOLOGIA
A base de dados obtida do Kaggle é composta por 12 colunas, que correspondem às características ou features desse conjunto. Adicionalmente, os dados estão organizados em dois arquivos, sendo um de treinamento com 381.109 linhas e outro de teste com 127.037 linhas, totalizando 508.146 linhas no conjunto completo. Cada uma dessas linhas representa um cliente individual. Para uma compreensão mais detalhada das informações contidas nesse conjunto de dados, as 12 variáveis são detalhadamente apresentadas na Tabela 1.
Tabela 3 – Glossário dados do Kaggle
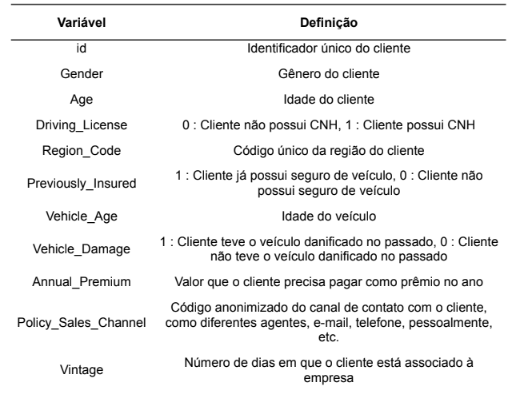

Fonte: Anmol Kumar (2020)
MÉTRICAS (KS, SCORE GERAL, LIFT E ANÁLISE INICIAL DE FEATURES
A fim de obter mais contexto sobre as variáveis, foi realizada uma análise exploratória detalhada dos dados coletados. Essa análise teve como objetivo principal compreender as relações entre as variáveis independentes (features) e a variável dependente (variável resposta). Na tabela 1 será apresentado uma análise de como cada variável se relaciona com a variável dependente e possíveis conclusões que é possível serem realizadas no momento.
Tabela 4 – Analise de Features
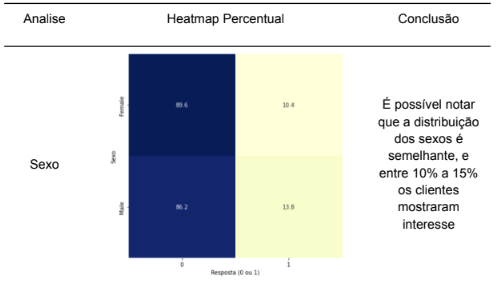
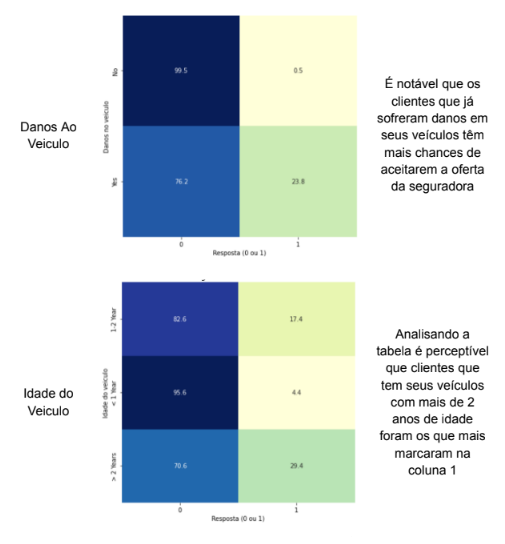
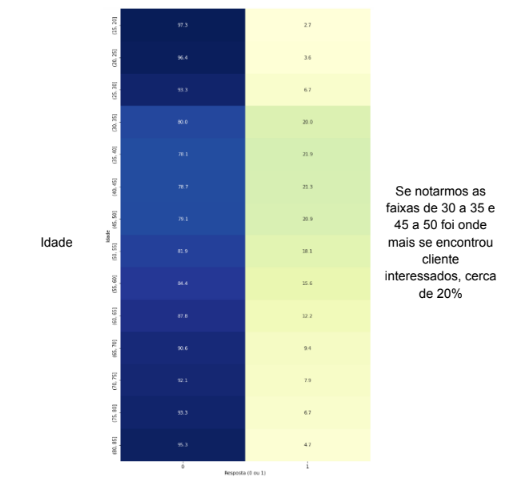
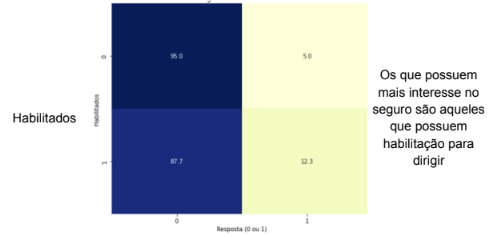
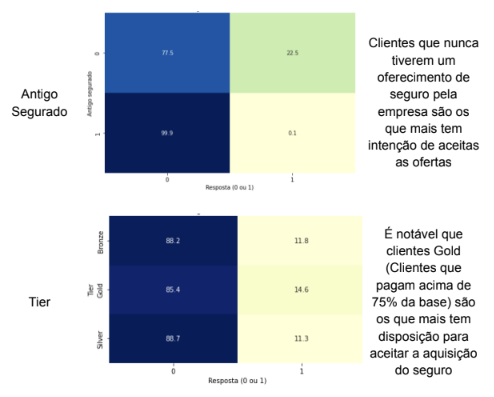
Fonte: Autoria Própria
PRÉ-PROCESSAMENTO
Neste subcapítulo, discutiremos o pré-processamento de dados, uma etapa essencial realizada antes de aplicar as técnicas de Machine Learning ao conjunto de dados. O pré-processamento desempenha um papel fundamental na preparação dos dados, abordando questões como limpeza, transformação e formatação. Essas ações são vitais para garantir que os dados estejam em um estado adequado e pronto para alimentar o modelo de aprendizado de máquina. Além disso, o pré-processamento pode envolver a eliminação de ruído, tratamento de valores ausentes, redução de dimensionalidade e seleção de características, contribuindo para a qualidade do modelo final e sua capacidade de generalização. Portanto, sua importância se estende além da mera formatação dos dados, impactando diretamente o desempenho e a eficácia do processo de aprendizado de máquina.
VARIÁVEIS CATEGÓRICAS
Para abordar as variáveis categóricas presentes no conjunto de dados, foram executadas as seguintes transformações:
- Variável “Tier”: A variável categórica “Tier” foi transformada em uma variável numérica, na qual os níveis Gold, Silver e Bronze foram mapeados para os valores 0, 1 e 2, respectivamente. Essa transformação permite que o modelo trabalhe com esses dados em formato numérico, mantendo a ordem relativa das categorias. Vale ressaltar que a variável “Tier” foi criada com base nos quartis da variável “Annual_Premium”.
- Variável “Gender”: A variável categórica “Gender” foi transformada em uma variável binária, onde “Female” foi mapeado para 0 e “Male” foi mapeado para
- Isso permite que o modelo trate o gênero como uma variável binária.
- Outras Variáveis Categóricas: Para as demais variáveis categóricas, aplicamos a técnica de one-hot encoding usando a função get_dummies. Isso cria variáveis binárias para cada categoria, tornando-as adequadas para serem usadas em modelos de Machine Learning.
Importante ressaltar que foi criada a variável “Faixa Idade” a partir da variável “Age” onde foi classificado os clientes em faixas de idade de 5 em 5 anos.
VARIÁVEIS NUMÉRICAS
- Variável“Vintage”: A variável numérica “Vintage” foi padronizada utilizando o StandardScaler. A padronização envolveu a subtração da média e a divisão pelo desvio padrão, o que resultou em uma distribuição com média zero e desvio padrão igual a um. Isso é útil quando as variáveis numéricas possuem escalas diferentes e podem afetar negativamente alguns algoritmos de Machine Learning.
- Variável“Annual_Premium”: A variável numérica “Annual_Premium” foi escalonada usando o MinMaxScaler. Essa técnica dimensiona os valores para o intervalo entre 0 e 1, o que ajuda a reduzir o impacto de valores discrepantes e coloca todas as variáveis numéricas em uma escala comparável.
RESULTADOS E DISCUSSÕES OU ANÁLISE DOS DADOS
Após analisarmos como cada variável se relaciona com a variável resposta foi realizada uma série de experimentos para avaliar o desempenho do modelo Random Forest e as três vertentes de seleção de características. Cada vertente adotou um método diferente de seleção de características, e os cortes foram determinados com base em critérios específicos.
EXPERIMENTO COM RANDOM FOREST
Inicialmente, aplicamos o algoritmo Random Forest ao conjunto de dados, considerando todas as características disponíveis. Este foi nosso ponto de partida para avaliar o desempenho do modelo. No gráfico 2 veremos os resultados das métricas avaliadas além da importância das features e a matriz de confusão:
Gráfico 2 – Importância das Features
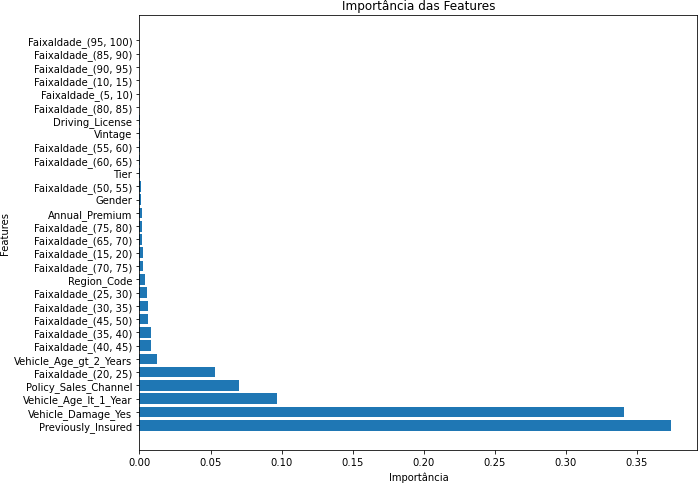
Fonte: Autoria Própria
Tabela 5 – Matriz de Confusão
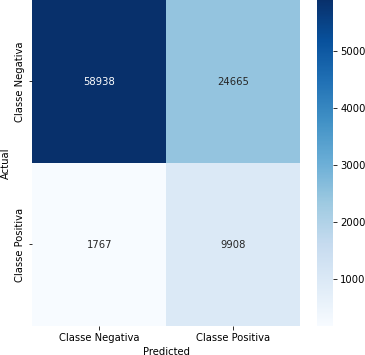
Fonte: Autoria Própria
Tabela 6 – Métricas
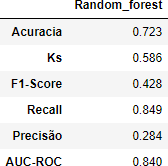
Fonte: Autoria Própria
SELEÇÃO DE CARACTERÍSTICAS PELA RANDOM FOREST
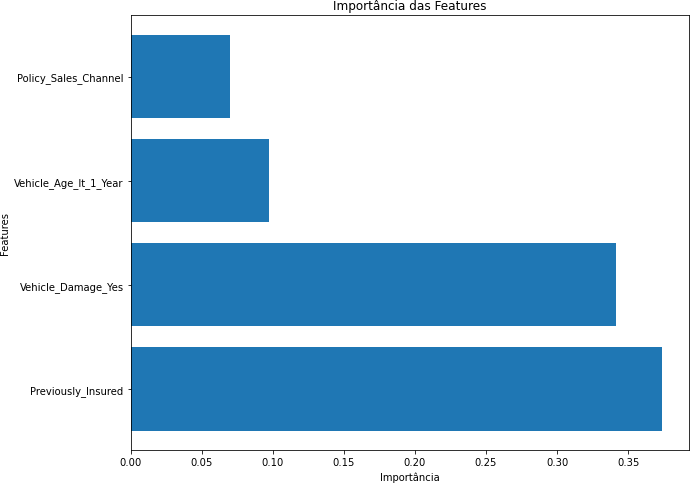
Na primeira vertente, utilizamos o próprio método da Random Forest para identificar as características mais importantes. As características foram classificadas com base em sua importância para o modelo. Em seguida, definimos cortes de 85%, 90% e 95% das características mais importantes e avaliamos o desempenho do modelo após a seleção. A seguir segue como o resultado das métricas avaliadas além da importância das features e a matriz de confusão:
Gráfico 3 – Importância das Features (Corte de 95%)
Fonte: Autoria Própria
Tabela 7 – Matriz de Confusão (Corte de 95%)
Fonte: Autoria Própria
Gráfico 4 – Importância das Features (Corte de 90%)
Fonte: Autoria Própria
Tabela 8 – Matriz de Confusão (Corte de 90%)
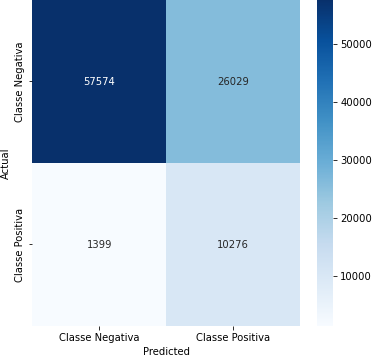
Fonte: Autoria Própria
Gráfico 5 – Importâncias das Features (Corte de 85%)
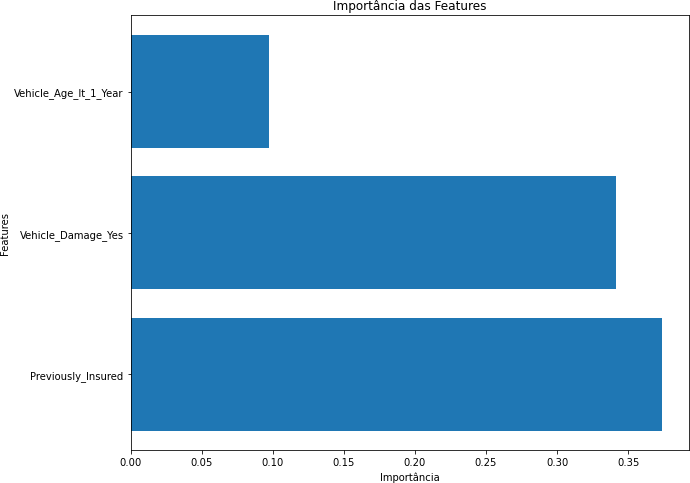
Fonte: Autoria Própria
Tabela 9 – Matriz de Confusão (Corte de 85%)
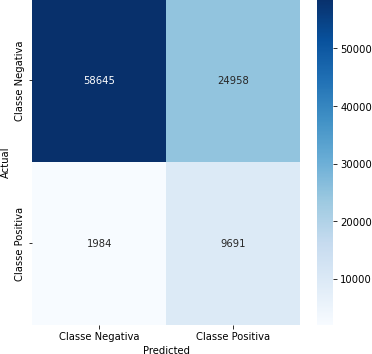
Fonte: Autoria Própria
Tabela 10 – Métricas
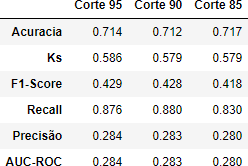
Fonte: Autoria Própria
SELEÇÃO DE CARACTERÍSTICAS POR CORRELAÇÃO DE PEARSON
Na segunda vertente, exploramos a correlação de Pearson entre as características e a variável de resposta. Definimos cortes com base no valor de correlação, considerando correlações acima de 0,05, 0,10 e 0,20 como critérios para a seleção de características. Em seguida, avaliamos o desempenho do modelo após a seleção. No gráfico 6 veremos os resultados das métricas avaliadas além da importância das features e a matriz de confusão:
Gráfico 6 – Importâncias das Features (Correlação Acima de 0,05)
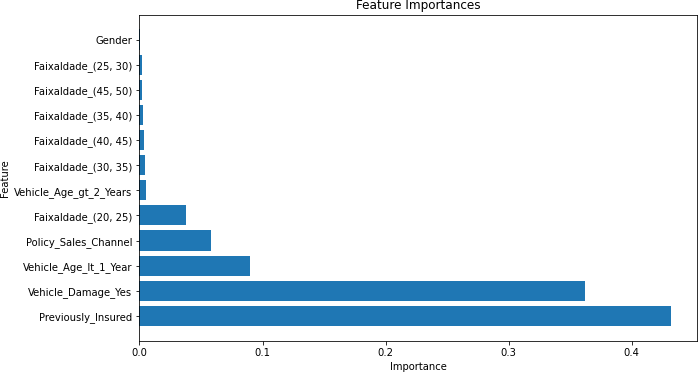
Fonte: Autoria Própria
Tabela 11 – Matriz de Confusão (Correlação Acima de 0,05)
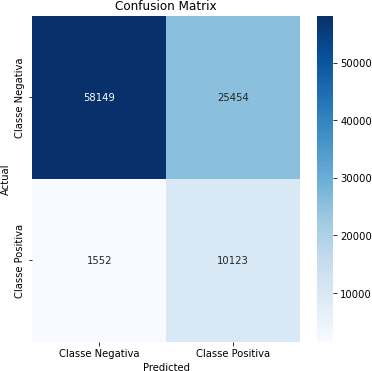
Fonte: Autoria Própria
Gráfico 7 – Importâncias das Features (Correlação Acima de 0,10)
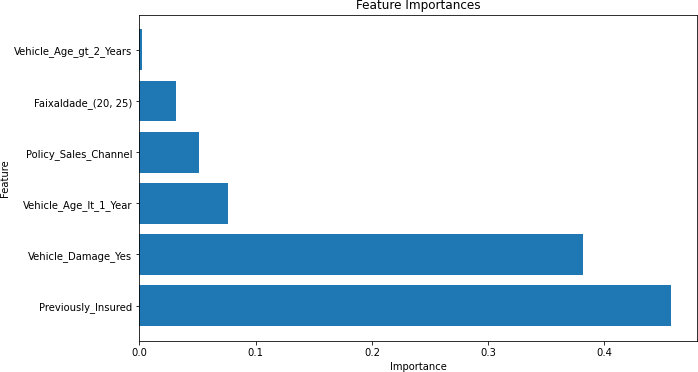
Fonte: Autoria Própria
Tabela 12 – Matriz de Confusão (Correlação Acima de 0,10)
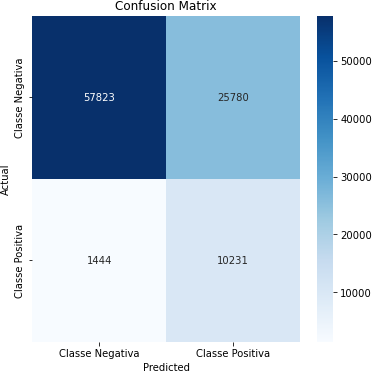
Fonte: Autoria Própria
Gráfico 8 – Importâncias das Features (Correlação Acima de 0,20)
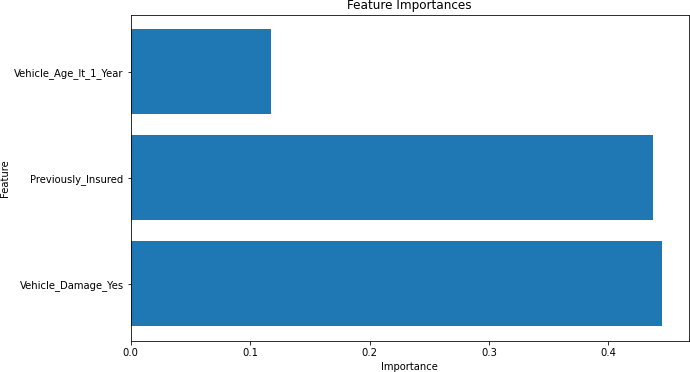
Fonte: Autoria Própria
Tabela 13 – Matriz de Confusão (Correlação Acima de 0,20)
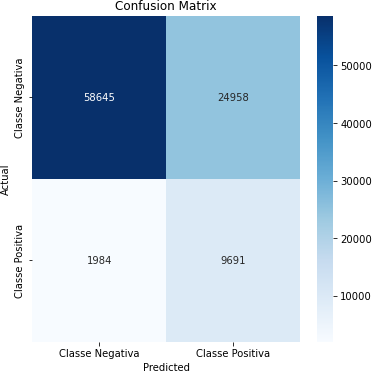
Fonte: Autoria Própria
Tabela 14 – Métricas
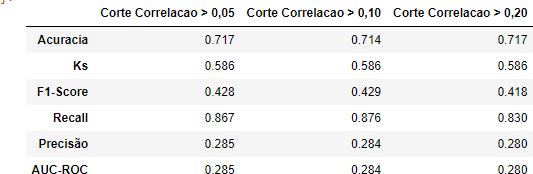
Fonte: Autoria Própria
SELEÇÃO DE CARACTERÍSTICAS COM RECURSIVE FEATURE ELIMINATION (RFE)
Na terceira vertente, utilizamos o método Recursive Feature Elimination (RFE) para selecionar características com base em sua contribuição para o modelo. Definimos cortes de 70%, 80% e 90% das características a serem mantidas e avaliamos o desempenho do modelo após a seleção. No gráfico 9 veremos como os resultados das métricas avaliadas além da importância das features e a matriz de confusão:
Gráfico 9 – Importâncias das Features (Corte de 70%)
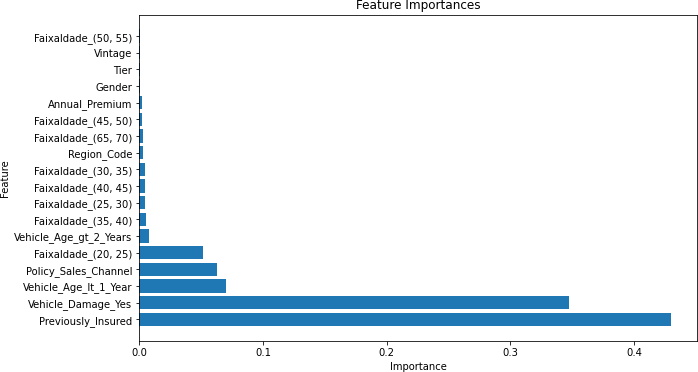
Fonte: Autoria Própria
Tabela 15 – Matriz de Confusão (Corte de 70%)
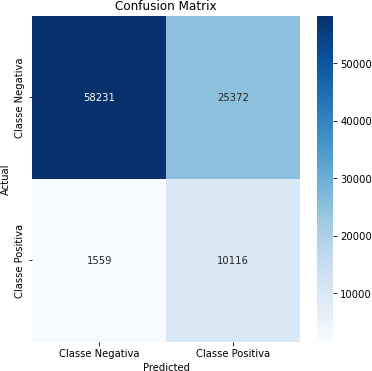
Fonte: Autoria Própria
Gráfico 10 – Importâncias das Features (Corte de 80%)
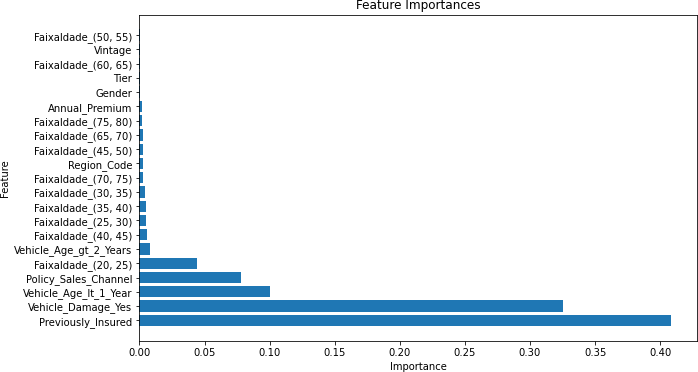
Fonte: Autoria Própria
Tabela 16 – Matriz de Confusão (Corte de 80%)
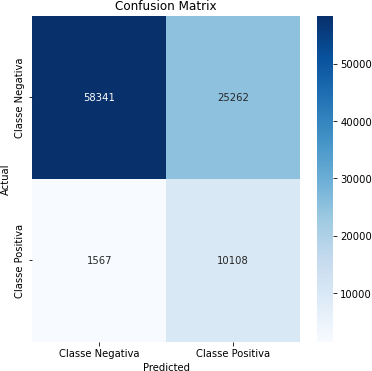
Fonte: Autoria Própria
Gráfico 11 – Importâncias das Features (Corte de 90%)
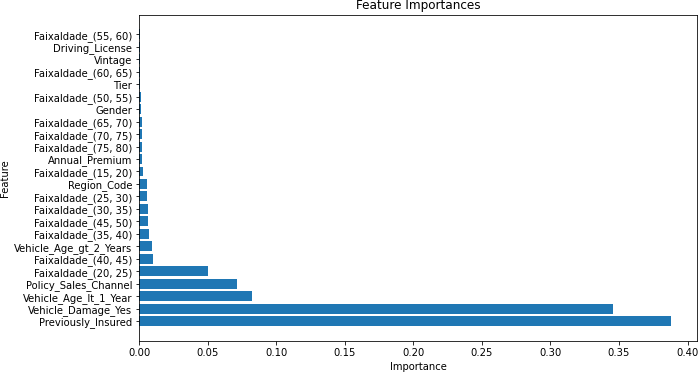
Fonte: Autoria Própria
Tabela 17 – Matriz de Confusão (Corte de 90%)
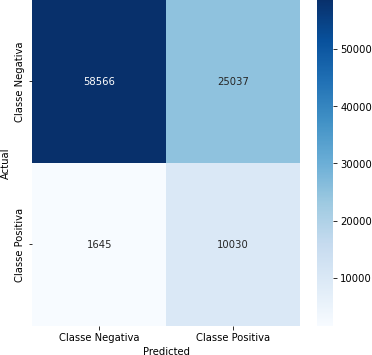
Fonte: Autoria Própria
Tabela 18 – Métricas
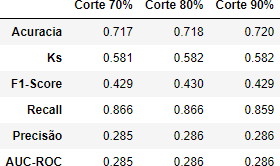
Fonte: Autoria Própria
CONCLUSÃO/CONSIDERAÇÕES FINAIS
O principal objetivo deste estudo foi avaliar e comparar as métricas de desempenho de diferentes métodos de seleção de características (feature selection) em um modelo preditivo em um caso de uso específico, utilizando uma base de dados de uma seguradora que visava determinar o interesse de seus clientes em um seguro automóvel. Os métodos investigados incluíram a seleção embutida de características com Random Forest, a correlação de Pearson e o método Recursive Feature Elimination (RFE).
Dos métodos de seleção de características analisados, o método RFE se destacou como o mais eficaz em nosso contexto. Especificamente, quando utilizamos 90% das características, observamos um desempenho superior em relação às métricas de avaliação.
As descobertas deste estudo têm implicações significativas para a indústria de seguros e a modelagem preditiva. A seleção de características desempenha um papel crucial na construção de modelos preditivos precisos, econômicos e interpretáveis. A escolha do método apropriado pode influenciar diretamente o sucesso de um modelo, bem como a capacidade da seguradora de identificar clientes interessados em seus produtos.
X.1 LIMITAÇÕES E RECOMENDAÇÕES FUTURAS
É importante reconhecer que este estudo apresenta algumas limitações. Primeiramente, os resultados podem ser específicos para a base de dados e o problema abordados neste estudo. Além disso, outras métricas de desempenho, além da acurácia, podem ser relevantes para avaliar o desempenho do modelo.
Para pesquisas futuras, recomenda-se a consideração de outras bases de dados e problemas de negócios, bem como a exploração de métodos de seleção de características alternativos. Além disso, a análise de custo-benefício associada à escolha do método de seleção de características pode ser um tópico de pesquisa promissor.
REFERÊNCIAS
BISHOP, C. M. Pattern Recognition and Machine Learning. [s.l.] Springer, 2006. BREIMAN, L. Random Forests. Machine Learning, v. 45, n. 1, p. 5–32, 2001.
FAYYAD, U.; PIATETSKY-SHAPIRO, G.; SMYTH, P. From Data Miningto Know ledge Discovery in Data bases. AI Magazine, v. 17, n. 3, p. 37–54, 15 mar. 1996.
FAWCETT, T. An introduction to ROC analysis. Pattern Recognition Letters,v. 27, n. 8, p. 861–874, jun. 2006.
GUALBERTO, A. Machine_Learning: Feature Selection. GitHub, 2017. Disponível em: https://github.com/arnaldog12/Machine_Learning/blob/master/Feature%20Selection.i pynb. Acesso em: 29 out.2023.
GUYON, I.; DE, A. An Introduction to Variable and Feature Selection André Elisseeff. Journal of Machine Learning Research, v. 3, p. 1157–1182, 2003.
GUYON, I. et al. Gene Selection for Cancer Classification Using Support VectorMachines. Machine Learning, v. 46, n. 1/3, p. 389–422, 2002.
HAND, D. J. Measuring classifier performance: a coherent alternative to the are a under the ROCcurve.Machine Learning, v. 77, n. 1, p. 103–123, 16 jun. 2009.
HAN, J.; PEI, J.; TONG, H. Data Mining.[s.l.] Morgan Kaufmann, 2022.
JAW, E.; WANG, X. Feature Selection and Ensemble-Based Intrusion DetectionSystem: An Efficient and Comprehensive Approach. Symmetry, v. 13, n. 10, p. 1764, 22 set. 2021.
KOHAVI, R.; JOHN, G. H. Wrappers for feature subset selection. Artificial Intelligence, v. 97, n. 1-2, p. 273–324, dez. 1997.
LIN, J.; DYER, C. Data-intensive text processing with Map Reduce. San Rafael: Morgan & Claypool, 2010.
MITCHELL, T. M. Machinelearning. New York: Mcgraw Hill, 1997.
POWERS, D.; AILAB. Evaluation: from precision, recall and f-measure to ROC,informedness, markedness & correlation. v. 2, n. 1, p. 37–63, 2011.
TUKEY, J. W. Exploratorydataanalysis. Reading, Mass.: Addison-Wesley Pub. Co, 1977.
1 Discentes do Curso Superior de Engenharia da Computação da Universidade São Judas Tadeu Campus Vila Leopoldina
2 Docente do Curso Superior de Engenharia Elétrica Josemar dos Santos Mr. Controle