DEVELOPMENT OF A CHATBOT FOR TASK MANAGEMENT
REGISTRO DOI: 10.69849/revistaft/ni10202412050711
Leonardo Ribeiro Marangão1;
Saulo Savio Leite Santos2;
André Luiz da Silva3
Resumo: Este trabalho tem como objetivo apresentar o desenvolvimento de um chatbot (ou assistente virtual) que visa colaborar com a gestão de tarefas de seus usuários. Aproveitando-se dos conceitos de redes neurais recorrentes e processamento de linguagem natural, foi dada ênfase à elaboração do código que dita todas as reações do assistente a partir da classificação da mensagem recebida. A pesquisa apresenta uma abordagem até então pouco explorada dentro do contexto de produtividade pessoal, trazendo a conversação como alternativa para a manipulação de compromissos e envios de alertas, com potencial para ser integrado a aplicativos de trocas de mensagens. A concepção da ferramenta foi possível devido a utilização da plataforma online Google Colaboratory, do framework TensorFlow e da linguagem de programação Python.
Palavras-chave: Assistentes Virtuais. Chatbot. Processamento de Linguagem Natural. Redes Neurais Recorrentes.
Abstract: This work aims to present the development of a chatbot (or virtual assistant) that aims to collaborate with the management of its users’ tasks. Taking advantage of the concepts of recurrent neural networks and natural language processing, emphasis was placed on developing the code that dictates all the assistant’s reactions based on the classification of the message received. The research presents an approach that has previously been little explored within the context of personal productivity, bringing conversation as an alternative for handling appointments and sending alerts, with the potential to be integrated into messaging applications. The design of the tool was possible due to the use of the Google Colaboratory online platform, the TensorFlow framework and the Python programming language.
Keywords: Chatbot. Natural Language Processing. Recurrent Neural Network. Virtual Assistant.
1 INTRODUÇÃO
São inúmeros os fatores que podem contribuir para uma baixa produtividade pessoal, razões que nem sempre são triviais de se resolver, tais como: sobrecarga, interrupções, ausência de rotina e problemas com o ambiente de trabalho. É natural que alguns afazeres sejam postergados ou até mesmo esquecidos. Procurando evitar retrabalho e estresse, uma ferramenta de fácil acesso e capaz de emitir alertas a qualquer momento, como um assistente virtual, pode ser útil.
Cruz, Alencar e Schmitz (2019) definem os assistentes virtuais como uma categoria de entidades inteligentes, sem corpo físico, que tem por objetivo auxiliar uma pessoa ou grupo de pessoas a resolver questões que as estão afligindo.
Ainda, Raj (2019) aponta que 70% dos consumidores interagem mais de uma vez ao mês com chatbots e aprovam a experiência, enquanto 27% desse mesmo grupo também se declaram adeptos ao uso de ferramentas baseadas em Inteligência Artificial. Logo, uma possível solução nessa situação não deve encontrar grande resistência daquele que enxerga sua gestão de tarefas como algo a ser melhorado.
Identificada a escassez de ferramentas voltadas para o controle de compromissos que utilizam os assistentes virtuais como abordagem, foi realizada uma pesquisa bibliográfica através do Google Acadêmico e desenvolvido um chatbot orientado por dados e preditivo, que são muitas vezes mencionados como assistentes virtuais ou assistentes digitais, os quais aproveitam o entendimento da linguagem natural para aprender (ORACLE, s.d.).
Seu funcionamento consiste em identificar datas, horários e eventos a partir de mensagens, realizando o envio de um lembrete no momento apropriado. Existe a expectativa de integração com aplicativos de trocas de mensagens, como WhatsApp e Telegram. Com esta pesquisa, espera-se estimar a eficácia dos chatbots dentro do contexto de produtividade pessoal, analisando sua capacidade de otimizar tarefas diárias e facilitar o acesso às informações.
A implementação do assistente é dividida nas fases: levantamento de requisitos, criação da base de dados, pré-processamento das informações, criação de um modelo e teste de uso. As principais ferramentas utilizadas durante o processo foram a linguagem de programação Python e o framework TensorFlow, com código desenvolvido no Google Colaboratory.
2 REVISÃO BIBLIOGRÁFICA
Esta seção apresenta uma introdução aos principais conceitos e ferramentas ligados à área de Inteligência Artificial (IA) que foram utilizados durante a pesquisa, a fim de contextualizar as escolhas tomadas para o desenvolvimento do assistente virtual.
2.1 LINGUAGEM DE PROGRAMAÇÃO PYTHON
Carvalho (2024) define Python como uma linguagem de programação de uso geral, sendo versátil e de fácil uso, visto que possui uma sintaxe simples e é multiparadigma, aplicável em soluções com automação de tarefas, testes de software e aprendizado de máquina, por exemplo.
Para o Instituto Federal do Pará (2018), é a linguagem na vanguarda de pesquisa da IA, onde é possível encontrar a maioria das estruturas de machine learning e deep learning.
É também utilizada em notebooks (arquivos de extensão .ipynb), que é um recurso que permite integrar o código fonte e seus resultados com textos e imagens. Este trabalho utiliza o Google Colaboratory, um serviço em nuvem e gratuito que lida com arquivos deste formato.
2.2 INTELIGÊNCIA ARTIFICIAL
Inteligência Artificial (IA) pode ser definida como a simulação de processos de inteligência humana por sistemas de computador, incluindo aprendizado, raciocínio e autocorreção (SALOMON, 2024). Com um conjunto de tecnologias adequado, habilita sistemas computacionais a executar uma série de funções avançadas, como ver, entender e traduzir idiomas falados e escritos, analisar dados, fazer recomendações, etc.
O modelo de Inteligência Artificial adotado para essa pesquisa é o de memória limitada, que é capaz de usar memória para se desenvolver com o passar do tempo, podendo ser complementada com novos dados por algum modelo de treinamento, garantindo decisões autônomas. Assistentes virtuais como Alexa e o sistema de recomendações da Netflix possuem esse tipo de IA como base.
2.2.1 NATURAL LANGUAGE PROCESSING (NLP)
Raj (2019) conceitua o Natural Language Processing, de modo geral, como uma área da Inteligência Artificial que permite que os computadores entendam a linguagem humana. Substancialmente, são algoritmos e modelos que capacitam sistemas computacionais a compreender e manipular texto e fala, visando sempre operar de maneira similar à dos seres humanos. Trazer o Processamento de Linguagem Natural (PLN) à uma aplicação torna-a capaz de automatizar processos de negócios, reduz custos e riscos de falhas operacionais, gera ganho em acessibilidade, etc.
Ainda, de acordo com a IBM (International Business Machines Corporation), podemos encontrar exemplos de PLN no nosso dia a dia em dispositivos como GPS operados por voz, assistentes digitais e software de ditado de fala para texto.
Atualmente, existe uma gama de módulos (arquivos que contém definições e instruções) em Python que lidam com Processamento de Linguagem Natural, como o NLTK (Natural Language Toolkit) e spaCy, outro fator que justifica a escolha da linguagem para o desenvolvimento da ferramenta.
Definindo uma rede neural para treinar um modelo de IA capaz de lidar com PLN, espera-se que a ferramenta consiga realizar predições, identificando as intenções por trás das mensagens que irá receber.
2.2.2 REDE NEURAL
Inspirada no funcionamento do cérebro humano, rede neural é um modelo adaptativo que os computadores usam para aprender com os erros e se aprimorar continuamente (AWS, s.d.), sendo capaz de fazer generalizações e inferências, reconhecimento de voz, mecanismos de recomendação, processamento de linguagem natural, etc. Para ter o retorno esperado, os dados percorrem neurônios artificiais que estão dispostos em três camadas da rede neural:
– Camada de entrada: primeiro contato dos dados do mundo externo com a rede.
– Camada oculta: onde ocorre a maior parte do processamento, extraindo características e padrões.
– Camada de saída: fornece o resultado final depois de interpretar todas as informações recebidas.
Durante o procedimento são levados em consideração dados como “peso” (valor numérico que indica a importância do resultado obtido pelo neurônio anterior para o atual) “viés” (valor fixo de cada nó/neurônio que é adicionado ao peso, tornando o cálculo mais ajustável) e “função de ativação” (para suportar mudanças nos pesos, potencializando a capacidade de generalização do modelo). O cálculo de todos os pesos e vieses formam o aprendizado da rede neural.
2.2.3 TENSORFLOW
Desenvolvido pelo Google nas linguagens de programação C++ e Python, o TensorFlow é uma biblioteca de código aberto e software livre. Ao mesmo tempo que tem um nível de complexidade alto, é flexível e poderoso, sendo uma das principais ferramentas para o desenvolvimento em Deep Learning e Inteligência Artificial. Tem como uma de suas principais aplicações a criação e treinamento de redes neurais.
O TensorFlow pode treinar e executar redes neurais profundas para diversas linhas de pesquisa, como por exemplo, reconhecimento de imagens, incorporação de palavras, modelos sequência a sequência para tradução automática. Ele é capaz de suportar previsões de produtos em escala, com os mesmos modelos usados para treinar. Ele pode ser executado utilizando diversas plataformas e arquiteturas, incluindo CPUs, GPUs e as até TPUs (FERREIRA, 2021, p. 25).
2.2.4 CHATBOT
No nível mais básico, um chatbot é um programa de computador que simula e processa conversas humanas (escritas ou faladas), permitindo que as pessoas interajam com dispositivos digitais como se estivessem se comunicando com uma pessoa real (ORACLE, s.d.). Utilizando PLN e de Machine Learning (algoritmos que organizam dados, reconhecem padrões e fazem com que computadores aprendam com esses modelos), podem fornecer respostas a todos os tipos de solicitações.
São divididos em “orientados a tarefas” ou “declarativo”, que é quando há uma finalidade única, gerando respostas automatizadas, por serem mais específicos e estruturados, são mais aplicáveis para funções de suporte e serviço; e “orientados por dados e preditivos” ou “conversacionais”, que são mais sofisticados e interativos, conseguindo se adequar com base no perfil do usuário.
3 DESENVOLVIMENTO
A fase do desenvolvimento consiste na definição das funções realizadas pelo chatbot, das ferramentas a serem utilizadas para a implementação de um modelo de classificação multiclasse e a criação de classes responsáveis por manipular o local de armazenamento dos dados e interações com o usuário.
3.1 LEVANTAMENTO DE REQUISITOS
Os requisitos de um sistema são as descrições dos serviços que o sistema deve prestar e as restrições a sua operação. Esses requisitos refletem as necessidades dos clientes de um sistema que atende a um determinado propósito, como controlar um dispositivo, fazer um pedido ou encontrar informações (SOMMERVILLE, 2018, p. 84).
Sendo classificados como funcionais e não funcionais, defini-los antes de iniciar a implementação de um software é importante por questões de entendimento, planejamento e controle de mudança, possibilitando adaptações durante o desenvolvimento da ferramenta. Requisitos funcionais são declarações dos serviços que o sistema deve oferecer, que respostas são dadas conforme os tipos de entradas e de como se comportar em determinadas situações. Devem ser escritos de modo que seu ator possa compreender sua funcionalidade. Em resumo, são focados nas ações do sistema (SOMMERVILLE, 2018).
Embora existam processos que garantem o funcionamento adequado do chatbot (gerenciamento dos alertas, envio de mensagens…), do ponto de vista da interação direta, por ser de uso exclusivamente pessoal, o usuário é o único ator envolvido no uso do assistente virtual, dado omitido no quadro 1.
Quadro 1 – Requisitos funcionais do chatbot.
| Identificação | Descrição | Prioridade |
| RF_1 | Registro do usuário O chatbot deve ser capaz de registrar o nome fornecido pelo usuário, para personalização de respostas futuras | Importante |
| RF_2 | Marcar lembrete Ao interpretar a mensagem recebida a partir do usuário, o chatbot precisa extrair as informações dela, criando um lembrete. | Essencial |
| RF_3 | Editar lembrete É permitido ao usuário alterar qualquer alerta que já tenha sido criado a qualquer momento. | Importante |
| RF_4 | Excluir lembrete Se não for mais útil, o usuário tem liberdade para excluir o lembrete que quiser. | Importante |
| RF_5 | Visualizar lembretes Possibilita que o usuário acesse o histórico de lembretes gravados. | Importante |
| RF_6 | Enviar alerta Com base na data e horário extraídos no momento do cadastro do lembrete, o chatbot deve enviar uma mensagem com o evento correspondente ao usuário. | Essencial |
| RF_7 | Feedback do usuário O assistente virtual deve fornecer o caminho para o envio de sugestões sempre que o usuário solicitar. | Desejável |
| RF_8 | Ajudar usuário A ferramenta precisa revisar sua funcionalidade quando requerido. | Desejável |
| RF_9 | Cancelar ação A interpretação do chatbot é imperfeita. Em caso de errar a intenção da mensagem do usuário, deve haver possibilidade de retroceder um passo. | Importante |
Sommerville (2018) define requisitos não funcionais como restrições oferecidas pelo sistema, sendo aplicáveis ao software como um todo, em vez de aos serviços de forma individual. Atrelados às questões de desempenho, disponibilidade e segurança, são mais críticos que os requisitos funcionais, já que seu descumprimento pode inviabilizar a utilização do sistema. O quadro 2 apresenta os requisitos não funcionais estimados para o projeto.
Quadro 2 – Requisitos não funcionais do chatbot.
| Identificação | Descrição |
| RNF_1 | A conversação com o assistente virtual deve ser intuitiva, sendo preparado para entradas de diferentes tipos de intenções. |
| RNF_2 | Será elaborado um manual, que apresentará o objetivo do chatbot e exemplos de uso. |
| RNF_3 | O chatbot será desenvolvido na linguagem de programação Python, com auxílio da plataforma Google Colaboratory. |
| RNF_4 | O assistente virtual deve estar em concordância com a Lei Geral de Proteção de Dados. |
3.2 ESCOLHA DAS TECNOLOGIAS
O desenvolvimento do assistente virtual envolve conceitos complexos, como redes neurais e processamento de linguagem natural. Para facilitar a curva de aprendizagem durante sua implementação, foi escolhida a linguagem de programação Python, que além de ter uma sintaxe simples, é muito utilizada para soluções que envolvem Inteligência Artificial, integrando grande parte dos frameworks (conjunto de códigos que visa a uma aplicação) voltados para essa área, incluindo o TensorFlow, do Google.
Como auxílio à implementação e manutenções futuras do chatbot, o assistente virtual foi escrito em notebook, arquivo composto pela combinação de blocos de código em Python com blocos de textos formatáveis, ou seja, com o formato .ipynb é possível fragmentar o código em pequenos pedaços e tecer comentários entre eles, além de poder separá-los em seções, facilitando o entendimento da abordagem adotada. A interface utilizada para manusear esse arquivo foi o Google Colaboratory, que oferece um poder de processamento alto o suficiente para lidar com a solução do chatbot.
Encarregado do desenvolvimento de toda a rede neural utilizada e criação de um modelo, o TensorFlow foi escrito em Python e é facilmente integrável com o Google Colaboratory que, inclusive, fornece exemplos iniciais em sua plataforma ensinando alguns conceitos de aprendizado de máquina, que é o foco do TensorFlow. Sua utilização favorece também a agregação de outras ferramentas amplamente utilizadas em soluções de Inteligência Artificial, como o Keras, além de permitir o uso de bases de dados já prontos, o que economiza tempo e esforço do desenvolvedor.
3.3 CRIAÇÃO DA BASE DE DADOS
A primeira etapa para a implementação de um modelo de Inteligência Artificial é a escolha da sua base de dados (dataset), nome dado ao conjunto de informações que é processado pela rede neural durante seu treinamento.
Foi definido que algoritmo do assistente virtual realize o treinamento de forma supervisionada. De acordo com Fontana (2020), algoritmos de aprendizado supervisionado são aqueles que relacionam uma saída com uma entrada baseados em rótulos, estes, sendo um valor numérico ou classe. Quando a saída (resposta) pode assumir apenas rótulos prédefinidos, esse modelo é chamado de algoritmo de classificação.
Para a base de dados foi feito manualmente, em um arquivo do tipo json (JavaScript Object Notation), a previsão de um total de 2000 possíveis entradas do usuário em forma de texto divididas em 9 rótulos, que representam as intenções que uma mensagem pode ter. A distribuição entre as classes é expressada na tabela 1.
Tabela 1 – divisão dos dados.
| Intenção (classe) | Quantidade de amostras |
| Ajuda | 100 |
| Pesquisa | 100 |
| Feedback | 100 |
| Cancelar | 100 |
| Saudação | 200 |
| Despedida | 200 |
| Alteração | 300 |
| Exclusão | 400 |
| Marcação | 500 |
Inicialmente, espera-se maior dificuldade na avaliação de entradas não previstas no dataset. Como a quantidade de dados não permite variabilidade alta entre as amostras, é natural que o modelo falhe ao generalizar (prever) para informações que não seguem o padrão dos dados do arquivo json. Todavia, a base de dados ser pequena viabiliza ajustes rápidos em casos, por exemplo, de similaridade entre duas ou mais classes, fator que causaria confusão durante o treinamento.
3.4 PREPARAÇÃO DOS DADOS
Visando a padronização e simplificação dos dados em sua forma bruta, é importante que eles sejam pré-processados.
A etapa de pré-processamento dos dados é uma etapa crucial na utilização de algoritmos de machine learning, por forma a garantir que os dados disponibilizados aos algoritmos são completos e consistentes, de forma a obter o melhor desempenho e os melhores resultados. (SILVA, 2021, p. 14).
O pré-processamento consiste em uma série de etapas preparatórias para a transformação das informações em sequências numéricas, que posteriormente vão ser a base de todo o treinamento. Para isso, foram usadas as técnicas de:
– Tokenização: ato de dividir entradas de texto em segmentos (palavras, subpalavras ou caracteres), chamados tokens. Facilita a extração de características por parte do modelo de IA, como semântica, contexto e relações entre as palavras.
– Remoção de stopwords: stopwords é o nome dado à um conjunto de palavras que aparecem com muita frequência numa base de dados, como “a”, “de”, “para”, etc. Por possuírem pouco conteúdo léxico e não serem cruciais para a interpretação da entrada, podem ser removidas (Raj, 2019).
– Lematização: análise vocabular e morfológica que procura reduzir palavra às suas raízes (por exemplo, “estudando” para “estudar”).
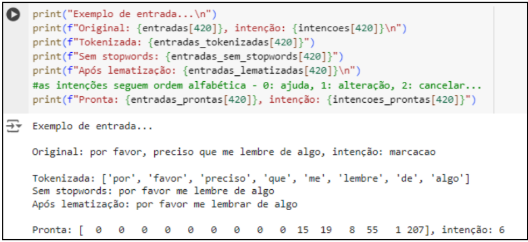
A partir do momento que o pré-processamento é finalizado, todas as entradas passam a ter mesmo tamanho, cada uma sendo representada por uma lista com seus respectivos tokens, que representam uma palavra. Por outro lado, as intenções são convertidas para um número inteiro, entre 0 e 8, totalizando as 9 classes previstas. É importante que ambos conjuntos tenham o mesmo tamanho (2000) e que as posições estejam sincronizadas: a mensagem na posição 50 do conjunto “entradas” deve possuir a classe descrita na posição 50 do conjunto “intenções”. O resultado de cada etapa é apresentado na figura 1.
Figura 1 – Visualização dos resultados de cada etapa do pré-processamento.
3.5 DIVISÃO DAS INFORMAÇÕES EM CONJUNTOS MENORES
Para encerrar a manipulação das informações vindas do dataset, é necessário dividi-las em três grupos, a fim de potencializar sua capacidade de generalização.
Generalização refere-se à capacidade de um modelo de IA aplicar o que foi aprendido em dados não vistos em treinamento. O algoritmo tem sua capacidade de generalizar comprometida no momento em que se adapta excessivamente aos dados de treinamento, fazendo conclusões precisas apenas dos dados que foram vistos, problema conhecido por overfitting (IBM, s.d.). Quando o modelo é excessivamente simples, ocorre o underfitting, que é a imprecisão alta tanto em dados de treino quanto em não previstos. Para avaliar seu desempenho e reconhecer esses potenciais problemas, a divisão dos dados em conjuntos menores é necessária.
– Conjunto de treinamento: usado para treinar o modelo, representa a maior parte do total.
– Conjunto de teste: comprova a capacidade de generalização do modelo. É omitido na fase de treinamento e possibilita a visualização de testes como precisão, Recall, F1 Score, etc.
– Conjunto de validação: auxilia em ajustes de hiperparâmetros, como o número de neurônios de uma camada ou monitoramento de sinais de overfitting. Convencionalmente também é usado como métrica para a interrupção prematura do treinamento, early stopping, à critérios definidos pelo programador.
Para o chatbot, o conjunto de teste representa 15% do total (300 amostras), o conjunto de validação 15 % do restante dos dados (15 % de 1700, 255 amostras) e o conjunto para treinamento, com 1445 amostras, cerca de 72% do total.
3.6 DEFINIÇÃO DA REDE NEURAL
Uma Rede Neural Recorrente (RNN) é um tipo de rede neural artificial com conexões ponderadas dentro de uma camada. A inclusão de loops em seus neurônios possibilita o armazenamento de informações conforme processa as entradas recebidas. RNNs mantém memória interna com feedback e, portanto, suportam o comportamento temporal (JONES, 2017).
VASCO (2020) classifica o feedback, dentro desse contexto, como um circuito, onde há o recebimento de informação de duas fontes, uma no momento atual do treinamento e outra num momento passado, que juntas são utilizadas para decidir como reagir a uma nova entrada de dados. A capacidade de resgatar resultados obtidos no passado (lidar com séries temporais) habilita o uso dessa rede neural para soluções que envolvem processamento de linguagem natural (PLN), tradução de idiomas, reconhecimento de fala e sistemas de legendas, por exemplo.
Os maiores problemas enfrentados por essa abordagem são o desaparecimento de gradientes e explosão de gradientes. Gradientes são valores que indicam o grau de mutabilidade que determinado parâmetro precisa ter para reduzir erros em suas conclusões, sendo fundamentais para a atualização dos pesos e vieses utilizados pelos neurônios durante os cálculos. Tais falhas ocorrem no momento que esses valores se tornam muito pequenos ou muito grandes, impossibilitando a aprendizagem do modelo, para quando o peso tende a 0, ou resultando um modelo instável, quando o gradiente é alto. A manifestação de falhas no gradiente ocorre devido à presença de dependências de longo prazo criadas pela Rede Neural Recorrente.
Uma alternativa capaz de remediar esse potencial obstáculo é a utilização de LSTMs (Long Short-Term Memory), que é uma arquitetura de RNN capaz de lidar com sequências textuais mais longas. Nas LSTMs, há um estado interno que aglomera um conjunto de subredes conectadas de forma recorrente, chamadas blocos de memória, que alocam as células de memória (SANTANA, 2017), sendo estas estruturas responsáveis pela manutenção, descarte e processamento dos dados advindos de valores de entrada no momento específico e saída da célula anterior.
Baseado na arquitetura LSTM, foi criada a rede neural recorrente do modelo que condicionará todas as tomadas de decisão do chatbot. Foi escolhido o tipo Sequential (recurso do módulo Keras), ele define que cada camada toma a saída da camada anterior como sua entrada, formando uma sequência linear de operações. Além disso, é necessária também a adição de uma camada do tipo Embedding, que garante a mesma dimensionalidade para todos os dados que vão percorrer as camadas seguintes. Com ela, foram definidos:
– Tamanho do vocabulário (input_dim): o número de palavras únicas que ocorrem na base de dados + 1, 1430 foi o número obtido com auxílio da função len( ) do Python em conjunto com a word_index( ), do Keras.
– Dimensionalidade das palavras (output_dim): define o tamanho do vetor que representa cada palavra. Neste caso, cada palavra do vocabulário será representada por 128 números.
– Dimensionalidade das entradas (input_length): é preciso repassar para o modelo o comprimento das entradas, antes padronizadas para o tamanho 20. Uma entrada com 15 palavras terá um preenchimento de 5 números 0 nas últimas posições do conjunto que a representa, enquanto uma entrada de tamanho 25 terá as últimas 5 palavras desconsideradas.
Para a camada LSTM foram determinados 27 neurônios, enquanto a do tipo Dense, de saída, com 9 neurônios (coincidindo com a quantidade de classes definidas inicialmente). A função de ativação softmax, responsável por converter um conjunto de valores em uma distribuição de probabilidade, é indicada para redes de classificação multiclasse e, por isso, foi adotada. A definição da rede neural resultante pode ser vista na figura 2.

3.7 TREINAMENTO DO MODELO
O treinamento de um modelo é o primeiro contato da rede neural com as informações da base de dados já tratadas. Para que essa etapa seja iniciada, é necessário convertê-lo para a linguagem de máquina, para isso foi usada a função compile( ), passando como parâmetro o otimizador Adam, que adapta a taxa de aprendizado para cada parâmetro individualmente e corrige os vieses. O treinamento foi realizado com a função fit( ). Ambas funções são do módulo Keras, que atua em conjunto com o TensorFlow.
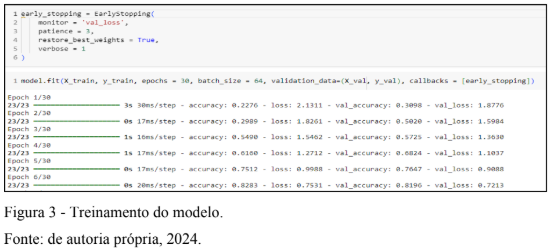
É preciso passar informações para a função fit( ): os conjuntos de dados contendo as mensagens (X_train); o conjunto de dados contendo os rótulos (y_train); o número de épocas (epoch) igual a 30 – que representa a quantidade de varreduras feitas nos conjuntos; o tamanho dos pacotes (batch_size) igual a 64 – definindo a quantidade de dados que entrará por vez na rede neural, resultando em 23 pacotes de 64 dados cada (23 x 64 = 1472, o número mais próximo de 1445, que é o tamanho do conjunto de treinamento); os conjuntos de validação, similares aos de treinamento (X_val e y_val) e, por fim, o callbacks, que especifica um critério de parada do treinamento. Neste caso, foi usado o early_stopping, que monitora o valor de val_loss e tem uma paciência de 3 épocas. Por conta desse parâmetro, o treinamento foi encerrado após a época 24, devido a ausência de melhora no parâmetro monitorado por 3 épocas consecutivas. Parte do treinamento foi ilustrado na figura 3.
3.7.1 RESULTADOS DO TREINAMENTO
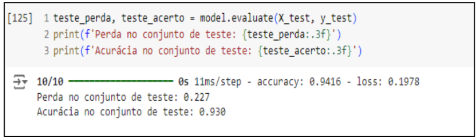
A acurácia, conforme visto na figura 4, foi de 93% no conjunto de teste, enquanto a perda atingiu 0.227, que não é um valor tão baixo, porém, considerando o tamanho pequeno da base de dados, está dentro do previsto.
Fonte: de autoria própria, 2024.
A precisão (razão entre o número de verdadeiros positivos e o número total de previsões positivas feitas – independentemente de estarem ou não corretas), o Recall (razão entre o número de verdadeiros positivos e o número total de casos positivos) e o F1-score (média harmônica entre as duas métricas anteriores) ficaram também próximos de 93%, o que, a princípio, indicam uma boa performance do modelo ao generalizar, classificando os dados corretamente. Os resultados estão apresentados na figura 5.
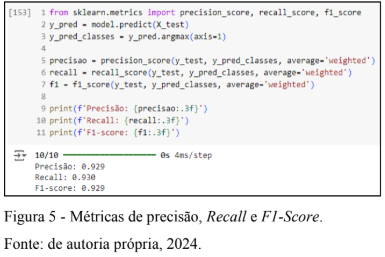
Por mais positivo que os testes possam parecer, é preciso levar em consideração o desbalanceamento das classes: enquanto há rótulos representados por 100 amostras, outros possuem 300 a 500 exemplos, o que é uma diferença significativa e pode interferir negativamente nas métricas vistas.
3.7.2 MÉTODO GERADO
Para testar a eficiência do modelo de maneira mais confiável, foi implementado um método “reconhecer_intencao”, que espera receber uma mensagem para retornar sua respectiva classe. Ele é visto em etapas na figura 6.
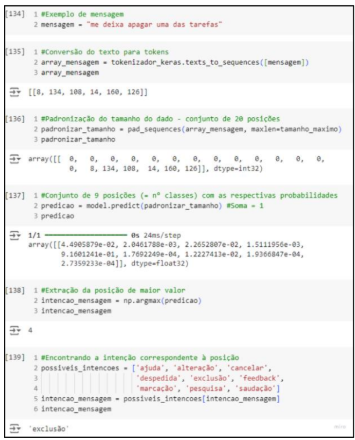
Fonte: de autoria própria, 2024.
Foram testadas um total de 20 entradas para cada intenção. 10 delas foram previstas no dataset e 10 são novas, inexistentes nos conjuntos de dados. A partir dessa experimentação, é possível estimar o desempenho da ferramenta quando já estiver em contato com o usuário.
A figura 7 apresenta um exemplo dos testes feitos para uma das classes, tendo o resultado dos contadores que mostram o percentual de acerto com dados já obtidos, com novas ocorrências e geral, quando se considera todas as classes.
Em relação ao desempenho do modelo, para mensagens contidas na base de dados, errou 1 de 90. Para mensagens novas, acertou 83% das ocasiões. Considerando os dois conjuntos, previu corretamente 164 de 180 entradas. O rótulo “cancelar” faz parte do projeto para que o usuário possa desistir de uma determinada ação e que consiga também lidar com as más predições que ocasionalmente vão ser feitas. Portanto, um acerto geral de 91% não é alarmante.
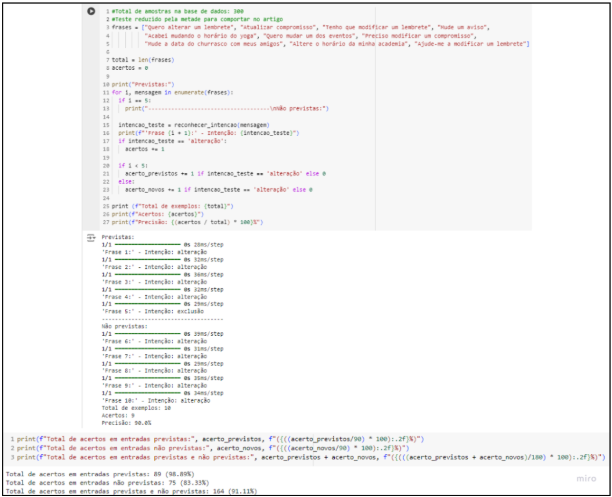
Fonte: de autoria própria, 2024.
3.8 CLASSES
Todas as informações relativas aos lembretes (evento, data, hora, data do aviso e hora do aviso) vão ser salvos num arquivo .csv (Comma-Separated Values) de forma local, de modo que apenas o usuário terá acesso aos dados. Uma vez apagados, não há alternativa para resgatá-los. Para a manipulação – marcações, pesquisas, alterações e exclusões, foi criada uma classe (paradigma de orientação a objetos) chamada ‘CSV’. Ela também lida com a geração de identificadores únicos, para que seja possível diferenciar eventos de mesma descrição. Seu principal método é o “manipular_arquivo”, que faz a chamada de outros métodos presentes na classe. Ele é requisitado para cada manipulação completa durante a interação com o usuário.
Seu funcionamento é idealizado na figura 8.
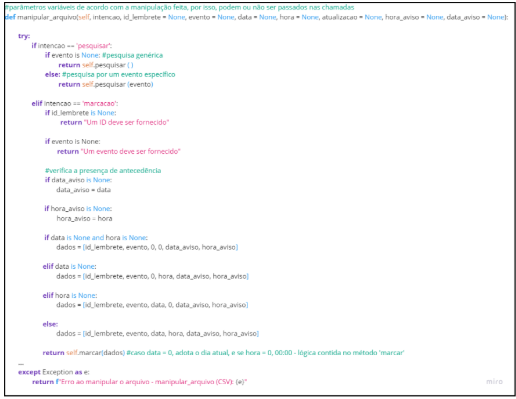
Fonte: de autoria própria, 2024.
Por outro lado, a classe ‘Chatbot’ atua como validador de dados (barrando, por exemplo, eventos marcados para um momento que já passou) e identificando as classes contidas nas mensagens que recebe, tirando proveito do método “reconhecer_intencao”, desenvolvido a partir do modelo de IA.
Ao reconhecer a intenção “marcação”, “pesquisa”, “alteração” ou “exclusão”, inicia-se um diálogo a fim acessar o arquivo CSV. A cada nova entrada do usuário, enquanto a conversa sobre a manipulação em questão existir, são feitas verificações, de modo que para qualquer mensagem de classificação igual a “cancelar” faça com que a interação se encerre de forma antecipada, com o arquivo dos dados permanecendo imutável. Caso contrário, tendo em vista a conclusão da manipulação, seus métodos encerram fazendo a chamada de “manipular_arquivo”, da classe CSV, passando todos os dados obtidos como argumentos.
As classes “saudação” e “despedida” são apenas formalidades. Adaptando-se conforme o horário, o assistente virtual retribui com uma mensagem.
Seguindo o levantamento de requisitos, a intenção “ajuda” resulta em uma série de mensagens introdutórias sobre o funcionamento da ferramenta, encerrando com o compartilhamento de um manual. Enquanto o rótulo “feedback” direciona o usuário para um formulário, fornecendo espaço para compartilhar sua experiência.
Na figura 9, está o método principal main ( ), que interage com as classes “CSV” e “Chatbot”, visto que é nele que os objetos são instanciados.

O envio do alerta acontece devido à Thread, técnica que permite a execução de trechos de código de forma paralela. Ao mesmo tempo que o programa aguarda uma mensagem do usuário, é feita a chamada de um método “enviar_alerta” com frequência de 60 segundos. Nele, é feita a comparação dos valores de data e hora do evento (salvos num conjunto “avisos”) com a data e hora atual. No momento que coincidirem, faz o envio da mensagem.
Sua lógica pode ser conferida na figura 10.

4 RESULTADOS
Foram criadas duas páginas, uma para o envio da avaliação e outra referente ao manual. Elas podem ser acessadas através dos links disponibilizados pelo assistente, durante a interação. A figura 11 exibe o início de ambas as páginas.
Fonte: de autoria própria, 2024.
Abaixo, o assistente já está em funcionamento, interagindo com o usuário e enviando um aviso por conta própria. “Alteração” repete os passos de “marcação”, enquanto “saudação”, “despedida” e “feedback”, assim como “ajuda”, apenas retornam mensagens. Por conta da similaridade, não estão presentes na figura 12.
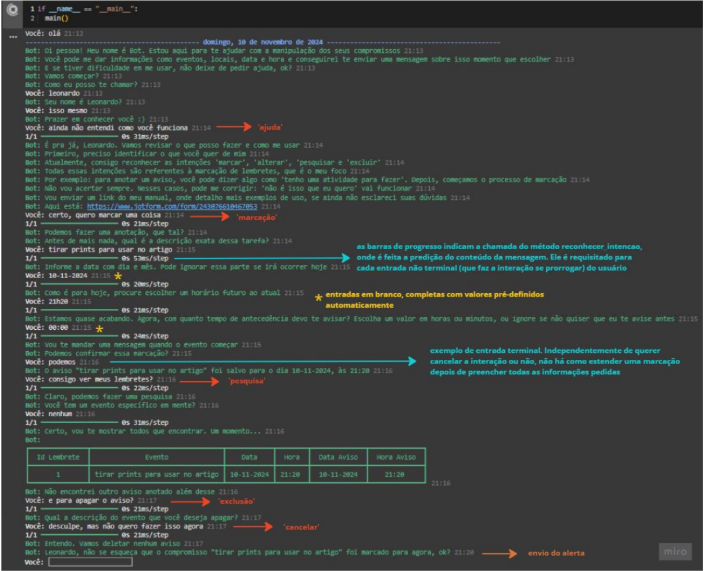
Fonte: de autoria própria, 2024.
5 CONCLUSÃO
O chatbot desenvolvido com Processamento de Linguagem Natural apresentou-se como uma abordagem válida para colaborar com a gestão de tarefas dos usuários, sendo a base de um assistente mais robusto que, futuramente, pode ser integrado ao WhatsApp ou Telegram.
Antecedente à experimentação da ferramenta em outras plataformas, é importante enriquecer sua base de dados em quantidade e variabilidade, além de balancear as amostras, possibilitando o reconhecimento das classes de forma mais assertiva. Além disso, a criação de um modelo de IA auxiliar capaz de extrair entidades personalizadas (variáveis como nomes, datas e horários) do texto reduziria a quantidade de mensagens requeridas para completar as ações, fazendo com que as interações sejam mais diretas.
REFERÊNCIAS BIBLIOGRÁFICAS
AWS. O que é uma rede neural? Disponível em: https://aws.amazon.com/pt/what–is/neuralnetwork/. Acesso em: 01 jun. 2024.
CARVALHO, C. O que é Python? – um guia completo para iniciar nessa linguagem de programação. Disponível em: https://www.alura.com.br/artigos/python. Acesso em: 02 jun. 2024.
CRUZ, L. T.; ALENCAR, A. J.; SCHMITZ, E. A. Assistentes Virtuais Inteligentes e Chatbots: Um guia prático e teórico sobre como criar experiências e recordações encantadoras para os clientes da sua empresa. 1. ed. Rio de Janeiro: Brasport, 2019.
FERREIRA, M. H. S. Reconhecimento facial para detecção de emoções utilizando redes neurais convolucionais com tensorflow. Trabalho de Conclusão de Curso (Bacharel em Engenharia de Computação) – Pontifícia Universidade Católica de Goiás, 2021. Disponível em: https://repositorio.pucgoias.edu.br/jspui/handle/123456789/3704. Acesso em: 02 jun. 2024.
FONTANA, E. Introdução aos Algoritmos de Aprendizagem Supervisionada. S. I. Universidade Federal do Paraná, 2020. Disponível em: https://fontana.paginas.ufsc.br/files/2018/03/apostila_ML_pt2.pdf. Acesso em: 22 set. 2024.
IBM. O que é processamento de linguagem natural (PLN)? Disponível em: https://www.ibm.com/br-pt/topics/natural-language-processing. Acesso em: 16 abr. 2024.
IBM. O que é overfitting? Disponível em: https://www.ibm.com/br–pt/topics/overfitting. Acesso em 20 abr. 2024.
Instituto Federal do Pará. Conheça as 5 melhores linguagens de programação para inteligência artificial. Disponível em: https://ctead.ifpa.edu.br/noticias/448-conheca-as-5. Acesso em: 02 jun. 2024.
JONES, M. T. Um mergulho profundo nas redes neurais recorrentes. Disponível em https://imasters.com.br/data/um–mergulho–profundo–nas–redes–neurais–recorrentes. Acesso em 24 set. 2024.
ORACLE. O que é um chatbot? Disponível em: www.oracle.com/br/chatbots/what–is–achatbot/. Acesso em: 15 abr. 2024.
RAJ, Sumit. Construindo Chatbots com Python: Usando Natural Language Processing e Machine Learning. 1. ed. São Paulo: Novatec, 2019.
SALOMON, Augusto. Inteligência Artificial: Construindo o Amanhã. 1. ed. São Paulo: Publicação Independente, 2024.
SANTANA, L. M. Q. Aplicação de redes neurais recorrentes no reconhecimento automático da fala em ambientes com ruídos. Dissertação (Mestrado em Ciência da Computação) – Universidade Federal de Sergipe, 2017. p. 30. Disponível em: https://ri.ufs.br/bitstream/riufs/10760/2/LUCIANA_MAIARA_QUEIROZ_SANTANA.pdf. Acesso em 4 nov. de 2024.
SILVA, D. Pré-processamento de Dados e Comparação entre Algoritmos de Machine Learning para a Análise Preditiva de Falhas em Linhas de Produção para o Controlo de Qualidade. Dissertação (Mestrado em Engenharia Informática – Sistemas de Informação e Conhecimento) – Instituto Superior de Engenharia do Porto, 2021. Disponível em: http://hdl.handle.net/10400.22/18266. Acesso em 21 set. de 2024.
SOMMERVILLE, Ian. Engenharia de Software. 10. ed. São Paulo: Pearson Education do Brasil, 2018.
VASCO, L. P. Um Estudo de Redes Neurais Recorrentes no Contexto de Previsões no Mercado Financeiro. Trabalho de Conclusão de Curso (Graduação em Engenharia de Computação) – Universidade Federal de São Carlos, 2020. p. 24. Disponível em: https://repositorio.ufscar.br/bitstream/handle/ufscar/13730/Trabalho_de_Conclusao_de_Curso _Lucas_Vasco.pdf?sequence=2&isAllowed=y. Acesso em 4 nov. de 2024
1Graduando do Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: lrmarangao@uniara.edu.br
2Orientador. Docente Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA.
Araraquara-SP. E-mail: sslsantos@uniara.edu.br
3Coorientador. Docente Curso de Engenharia de Computação da Universidade de Araraquara- UNIARA.
Araraquara-SP. E-mail: alsilva@uniara.edu.br