REGISTRO DOI: 10.5281/zenodo.8044715
Renato de Brito Sancheza,b*, João Carlos Lopes Fernandesa, Silvia Regina Matos da Silva Boschia, Marcia Aparecida Silva Bissacoa, Alessandro Pereira da Silvaa, Terigi Augusto Scardovellia and Silvia Cristina Martinia
ABSTRACT
This work proposes a digital cloud system through computer vision and a VGG Net with pre-trained models MPII and COCO Caffe validated with dataset for human pose, a health aid tool to identify key points and body segments in images and in gait. Data obtained by digital camera up to 1080p and 30…60fps, positioned parallel to the ground, height 0.6…2.4m, ≥1.5m away from the procedure area, capturing in the sagittal and frontal planes, processing digitally. Better data visualization showing an error of ≤5%, identification of key points ≤1s, keeping the history, different from manual systems with longer and limited time.
Keywords: cloud virtual environments; digital image processing; computer vision; human pose; key points
1. INTRODUCTION
In Brazil, the “2010 Census Booklet for People with Disabilities” [1] by the Brazilian Institute of Geography and Statistics (IBGE), launched by the Human Rights Secretariat of the Presidency of the Republic in 2012, says that about 45,606,048 Brazilians, 23.9 % of the total population, have some type of disability, of which the visual represents 18.6% of the population, with the greatest impact, followed by the motor that reaches 7% of the population. Motor or physical disability is a complete or partial limitation of the functioning of parts of the human body, easily identified in the lower and upper limbs and classified according to neurological or muscular origin, which requires from the health area several treatment methods characterized by the degree of severity of the disorder, the great challenge for physiotherapy being the solution to problems of functional mobility, with rehabilitation being a time-consuming procedure that performs several repetitive functions, however daily several new techniques appear in the rehabilitation process [2]. The human body is a single complex structure formed by different structures subject to being affected by different types and degrees of injuries [3], where individual treatments have a high operational cost that has been replaced by collective sessions with groups of patients, however, biomechanics depends on experimental results, where the acquisition of values is a concern of the applied methodologies [4], which can be obtained with techniques such as kinematics, electromyography, dynamometry and anthropometry [5], considering the complexity to obtain biomechanical parameters that allow defining anthropometric models that will be used by kinematics [6], in which two images are sufficient for one model, one in the sagittal plane and one in the frontal plane [7]. This work presents a digital system that allows to identify the key points through the human pose through a convolutional neural network.
2. METHODS
The digital system was developed with the resources shown in software and hardware implementation, in which it was applied for tests with volunteers at the Polyclinic of the University of Mogi das Cruzes (UMC), the sample will consist of 40 volunteers aged 18 to 59 years, and all volunteer participants will preliminarily fill out the documents for consent and authorization of their participation as the Free and Informed Consent Form (ICF) and the Term of Use of Voice Image and Sound. The test protocol was submitted to the Ethics Committee of the University of Mogi das Cruzes (UMC) and approved according under number CAAE 22125419.4.0000.5497.
The digital system with the digital camera in 1080p and 60fps used parallel to the ground, with height adjustment (0.6 to 2.4m), 1.5m from the analysis field (3x3m to 3x10m), performs the measurement of the patient standing or walking through the demarcated area, used for measurement, rehabilitation or walking procedures, through computer vision with machine learning identifying and recreating key points and body segments from pre-trained models that will be analyzed with a CNN without the need for markers on the skin in conforming as shown in Figure 1.
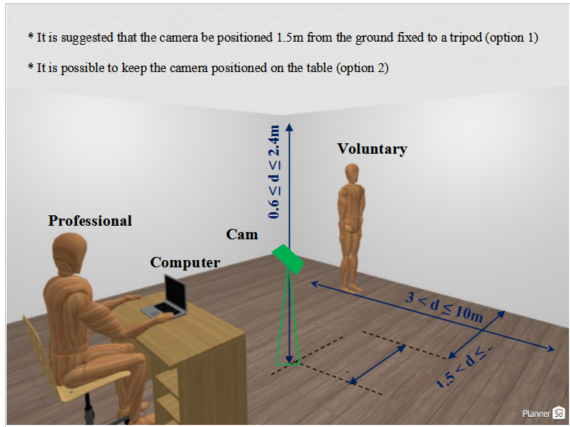
Figure 1. Proposition of the structure for data collection.
To enable the application and of the developed digital system, two bases of pre-trained models were used, the MPII Human Pose Dataset which produces 15 key points in the human body [8] and the COCO keypoint dataset trained at Caffe deep learning framework, known as COCO CAFFE, which produces 18 points. An important feature of these models is that they were trained with Convolutional Neural Networks (CNN), which favors the application, as it allows to recognize patterns [9], the machine learning being defined by the variation of the parameters associated with the variables and by its architecture and structure allow multi-layer training [10].
CNN are generally the most efficient for image and object recognition applications, allowing to apply in the recognition and classification of images of the human body [11], where VGGNet for human can recognition has advantages for having a deeper structure and small nuclei with an improved recognition rate in relation to other neural networks, including VGGNet was the CCN used in the MPII and COCO CAFFE models, extracting the confidence and affinity maps for key points [12].
In biomechanics, anthropometric measurements are standardized and referenced by anatomical points that allow better positioning of measuring instruments during anthropometric assessment [13], where the measurements were obtained in the anatomical position of the human being, that is, the position of the body alive, standing upright, with arms across the body and palms facing forward. In this way, the digital system with VGGNet makes the prediction of the two-dimensional Confidence Maps of the key points defined by the MPII and COCO CAFFE models [14] forming a data set for the estimation of the human pose with one or more people in the same frame allowing, in addition to jointly predicting the Affinity Fields to associate body points and segments.
Considering only the skeletal joints and systematically abstaining from specific joints, the authors obtained as a result for the COCO model the mean values of 83.7% for the AlphaPose and 77.6% for the OpenPose, while for the MPII model they obtained 82.2% for AlphaPose.
2.1 SOFTWARE AND HARDWARE IMPLEMENTATION
The digital system considers an external webcam connected to the computer or notebook, allowing mobility and better positioning of the camera, for a better definition of digital images and video capture considers the minimum resolution of 1280×720 (ideal Full HD in 1920×1080) for better sharpness and minimum 30fps to avoid sudden movement and greater smoothness of movement. Tested the system with Logitech, model C922 HD Pro, with glass lens, recording in full HD 1080p and 30fps, 78º field of view.
The source code was developed in Python 3.6 with the OpenCV 4.2.1, Matplot and NumPy libraries, operating with Google Cloud architecture using Google Drive and in the Google Collaboratory environment that allows the creation of virtual machines based on Jupiter Notebook, stored in ‘.ipynb’ format and making available via Google servers processing with NVIDIA® Tesla® K80 GPU acceleration and 13.7 gigabytes of available RAM to run in real time.
As input, the model receives a color image with dimensions of width and height that reproduces the two-dimensional output with the location of key points for everyone analysed by the digital system, in which detection comes from three distinct stages, Figure 2, where:
- initially the maps containing the characteristics of the input image are created in the first 10 layers of VGGNet;
- according to the two-stage CNN is applied and the first branch performs the prediction of a set of two-dimensional confidence maps containing the location of the points that identify the body parts, while a second branch is used to predict the set of vector fields that demonstrate the affinity between the detected parties and create weights for the confidence of the results;
- third, an intervention is applied between the trust and affinity maps so that the points are connected.
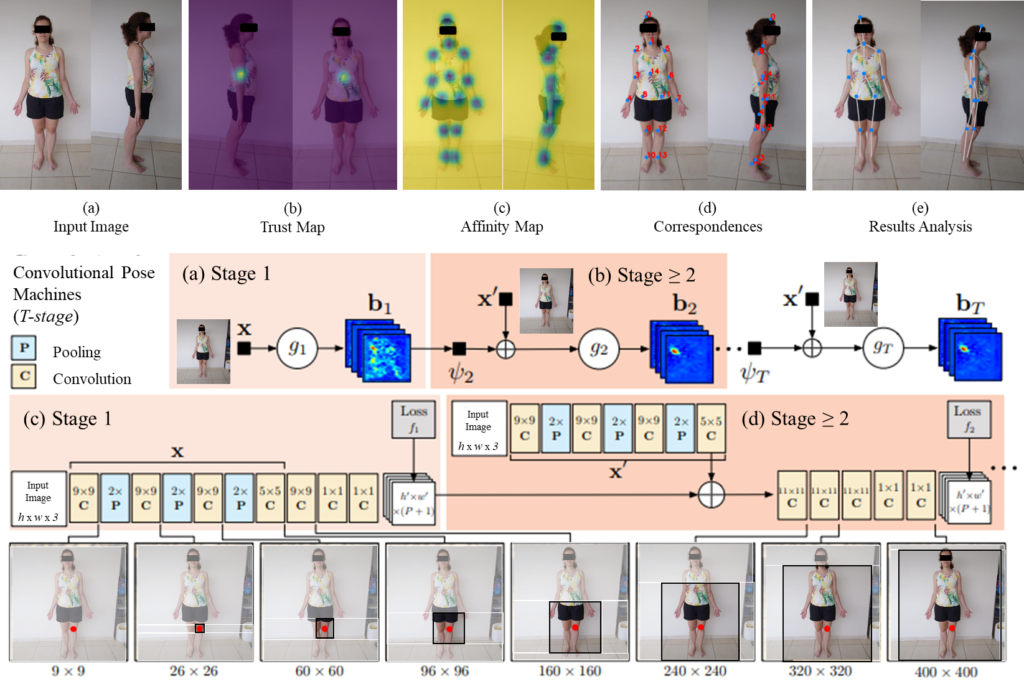
Figure 2. VGG Net proposition in the recognition of the Human Pose.
2.2 DIGITAL SYSTEM STRUCTURE
The system was structured with the pre-trained models MPII and COCO Caffe, which apply a CNN VGG Net and which are integrated through the OpenCV computer vision library, in which, as presented, the neural network allows operationalizing the human pose estimation through the identification of key points. The CNN overview, Figure 3, allows the models to predict the location of key points, which are previously validated.
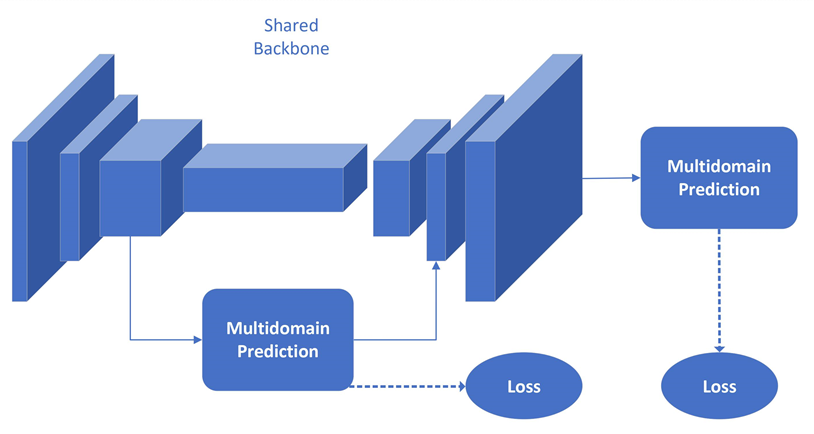
Figure 3. Prediction network overview.
The importance of pre-trained models is highlighted, as they were built through a CNN, that is, in the concept of Deep Learning, therefore the proposition of using both models, Figure 4.
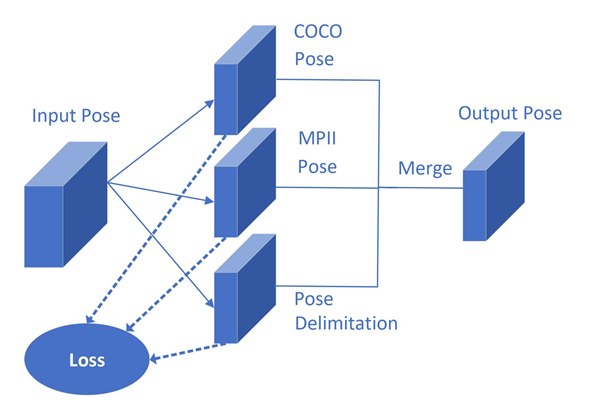
Figure 4. Multidomain prediction proposition scheme.
This way, it allows the system to combine the human pose and key points datasets so that the points and connections for the body segments are defined, established by the operation flow, Figure 5.
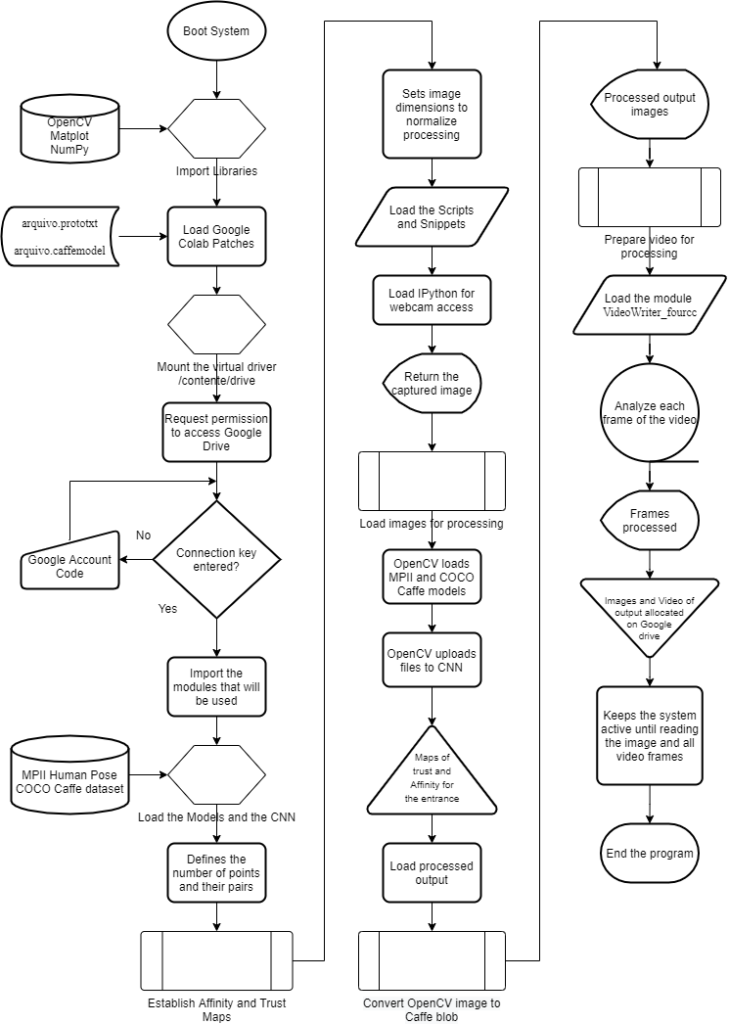
Figure 5. System operation flowchart.
3. RESULTS
The digital system was hosted on the main author’s Google Drive and accessed via laptop with i3, i5 and i7 processors at minimally 3.6GHz without GPU or TPU. Therefore, an important feature is that it does not need a specific computer, as in the Google Colab environment the processing is carried out through Google’s servers, with the option of being accelerated through TPU and GPU in the cloud with ‘NVIDIA’ hardware -SMI 450.66, Driver Version: 418.67 and CUDA Versions: 10.1′, also providing ‘Your runtime has 13.7 gigabytes of available RAM’.
3.1 FIRST APPLICATION STAGE – IDENTIFICATION OF VOLUNTEERS
The test with the system was carried out with 40 volunteers between 18 and 59 years old, regardless of the sound type and with their anonymous identity, who were submitted to the capture of images and videos that were processed by the digital system. As an open and random call, it is composed of 40% of women and 60% of men classified according to the IBGE’s age group, being 2 of 20…24, 33 of 25…44 and 5 of 45…59.
Another parameter for classifying the volunteers considered the body mass index adopted by the OMS to verify the participating somotypes, having as data 18 as healthy (18.50…24.99), 9 as Overweight (25.00…29 .99), 11 as Obesity Grade I (30.00…34.99), 1 as Obesity Grade II (severe) (35.00…39.99) and 1 as Obesity Grade III (morbid) ( ≥ 40.00).
Both parameters showed no difference or error that prevented the processing of images and frames or detection of key points, allowing the points identified by the digital system to be compared by analyzing the Trust and Affinity Maps, according to the COCO Caffe and MPII models, plotted in a ma digital copy of the image and video with the representation of points and body segments.
3.2 SECOND APPLICATION STEP – CAMERA CAPTURE AND IMAGE ANALYSIS
Digital cameras were positioned to prepare the image and video capture environment, considering the distances presented above to obtain a wide field of view and body movements in order to allow viewing the sagittal and frontal planes. The connection took place via USB cable to avoid lag with the video and with screen adjustment to widescreen, which allowed capturing the entire length of the volunteer. After capturing the images and videos, they were played back with streaming and buffering while the algorithm processed the results through the GPUs available on Google Cloud.
The field of vision was left without frontal obstruction, and for tests there was an environment with a difference in brightness and with an object behind the volunteer, allowing the system to process the results also in a condition of visual interference, in this case with obstructions or interferences, the algorithm estimated the movement and the position of the key points, although it was found that the best results occur with a uniform background.
Once the connection with Google Drive is established, the digital system loads the pre-trained models, establishes the recording paths of the processed outputs and performs the routines for reading the images and videos, attributing point 14 of COCO Caffe with a neutral point in the analysis for being in the chest, being impartial for the upper and lower limbs. All volunteers had four images collected, two in the sagittal plane (left and right turned) and two in the frontal plane (front and back), in order to extract the trust and affinity maps, expressing on the copy of the image the key points and body segments detected.
The results for the processed images were grouped for visualization in a 5×4 matrix for each of the 40 volunteers, as follows: Line 1 = Image with identification of the reference point in the Affinity Map; Line 2 = Image with Confidence Map of key points; Line 3 = Image with identification of key points by COCO Caffe dataset; Line 4 = Image with representation of body segments; Line 5 = Numerical identification of point pairs for each keypoint. As examples of volunteers 1 and 28 in Figure 6 that presents the processed results.

Figure 6. Exposure of results after digital image processing by the algorithm, considering volunteers 1 and 28 in the example.
The affinity map allowed the identification of the human skeleton and extracting the data exposed for each key point, among the different possible points in the same region, the one that will have greater accuracy in being the real indicated key point, with the output being plotted through the analysis of the trust map according to the code snippet below.
ponto = 12
mapa_confianca = saida[0, ponto, :, :]
mapa_confianca = cv2.resize(mapa_confianca, (imagem_largura, imagem_altura))
plt.figure(figsize = [14, 10])
plt.imshow(cv2.cvtColor(imagem, cv2.COLOR_BGR2RGB))
plt.imshow(mapa_confianca, alpha = 0.6)
plt.colorbar()
plt.axis(“off”)
The processed output allows to obtain the pairs of points of the Cartesian coordinates of the image that associated by the Affinity Map extracted from the MPII and COCO Caffe dataset, through CNN return the points (0) Head, (1) Neck, (2) Right shoulder , (3) Right elbow, (4) Right wrist, (5) Left shoulder, (6) Left elbow, (7) Left wrist, (8) Right hip, (9) Right knee, (10) Right ankle, ( 11) Left Hip, (12) Left Knee, (13) Left Ankle, (14) Chest and (15) Bottom. Thus it is possible with the distance equation, Equation 1, to obtain the size of a segment between neighboring key points, knowing that da,b is the distance between two points and xb,yb the coordinates of the endpoint and xa,ya of the point initial.
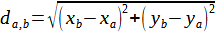
As a result, the value corresponding to the value with the dimensions of the image is obtained, then it is necessary to apply an adjustment to express the real value that considers the environment and individuals captured by the digital camera.
Equation 1 can be described with the code:
# Importar a biblioteca matemática para a função de raiz
quadrada
from math import sqrt
# Equação para cálculo da distância entre pontos
distAB = sqrt((xA-xB)**2) + ((yA-yB)**2)
# Exibe distância calculada
print(distAB)
The presence of obstructions resulted in regions not visible to the computer vision system and in this case the algorithm in the digital processing estimated the movement and position of the key points, a situation that for human vision makes this prediction difficult, that is, regardless of the reason, it is important that the volunteer is always visible to obtain maximum efficiency and results.
In detail with one of the volunteers, for an analysis of the lower limbs, both in the frontal and sagittal planes, Figure 7, the images were obtained with a focus on the right knee, extracting the visualization of the Confidence Map, which exposes the region that represents the point chosen in relation to the other points. This definition is important for the algorithm to refine its precision considering a point closer to the limb or body segment under analysis.
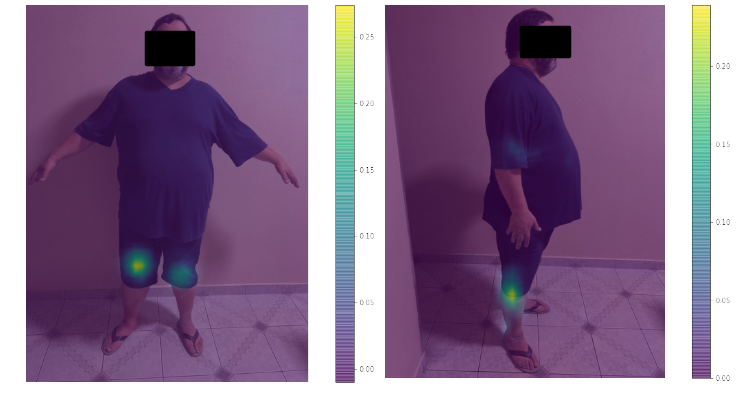
Figure 7. Images obtained in the sagittal and coronal planes using the Confidence Map focusing on the right knee.
From the Confidence Map produced by CNN from the MPII and COCO Caffe dataset, the algorithm extracted the Affinity Map that established the relationship between each point and its correspondence. This step is essential, as the definition within the algorithm with the correspondence extractions allows pointing out the correct connections, for example, between the direct ankle and the right knee, thus providing the body segments for the skeleton’s virtualization as shown in Figure 8.
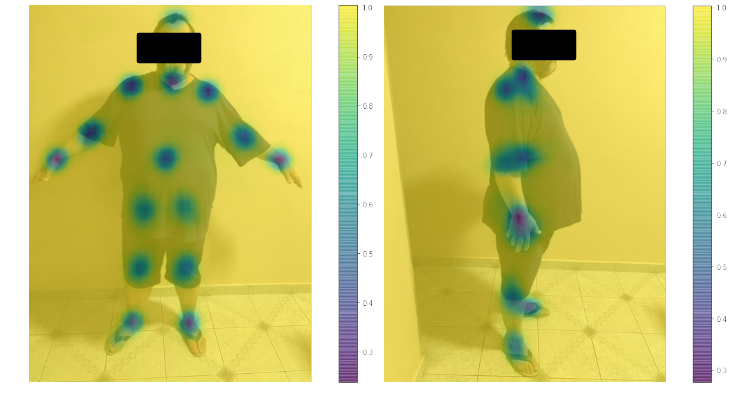
Figure 8. Images with extracted with the Affinity Map with the representation of the key points in the volunteer.
All 40 volunteers had frontal and sagittal plane images and gait videos with extractions. As a result of the identification of key points, the system establishes an output in which it identifies the pairs of Cartesian coordinates, Figure 9, which can be used to generate the spatial position of the points and allow predicting segmental or motion measurements.
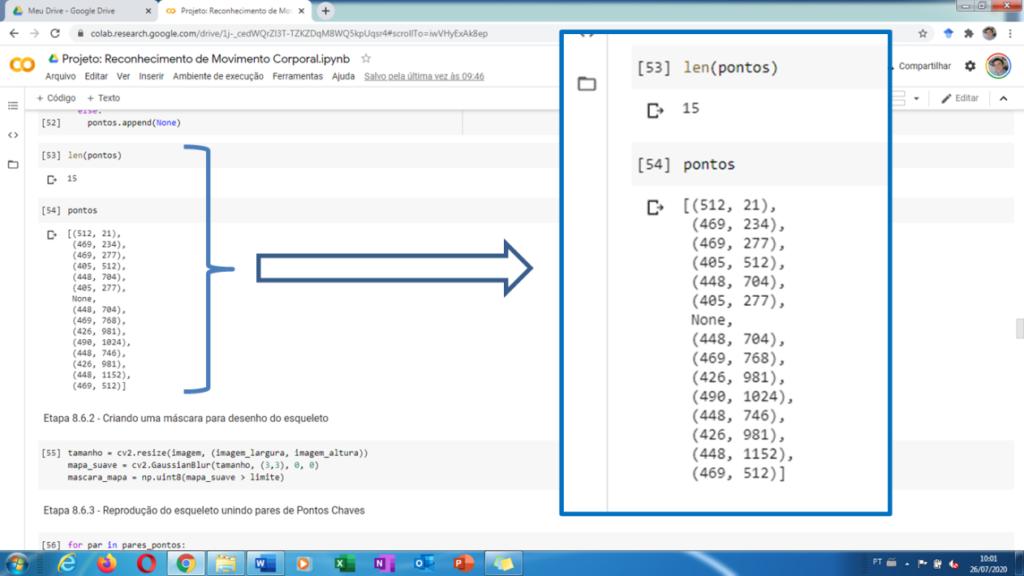
Figure 9. Output of Cartesian pairs that locate key points in the digitally processed image.
The key points identified by the Trust and Affinity Maps through extraction with pre-trained models through the association of the MPII and COCO Caffe dataset, were previously validated as presented in the Introduction and Methods chapters, which even present better efficiency and greater number of identified points compared to other models. It is also worth mentioning that these models were trained with a neural network type CNN VGG Net, the same used for this work and that they have a considerable base of images and activities used for the training.
Considering that in the sagittal plane there is naturally an obstruction in the visualization of the side of the body that is contrary to the visualization of both computer and professional vision, in this case the digital system developed provides by CNN and the parameters extracted from the trained models, the position of the key points not visible to the camera and to the professional conducting the rehabilitation session, Figure 10, thus allowing the prediction of body segments.
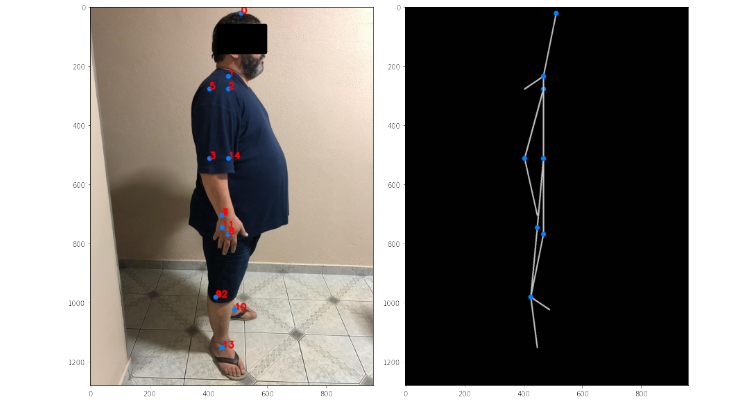
Figure 10. Presentation of key points and virtualization of body segments with partial obstruction in the sagittal plane.
For digital processing, all input images were resized to at least 360 x 480 pixels, allowing processing speed to work without losing image quality and precision in identifying key points expressions in the copy image and numbered from 0 to 14.
When operating the system with images in the frontal plane, there is no obstruction, so all points were identified and the body segments expressed directly, but as shown in Figure 34, when there is an obstruction in the case of the left elbow, it is not possible to identify the point 6, in this case the algorithm identifies it as “none” instead of exposing a numerical value, this point being predicted by estimation from adjacent points 7 and 5, respectively of the wrist and shoulder, which are uncovered, thus in the processed image the segment is virtualized connecting the dots.
3.3 THIRD STAGE OF APPLICATION – ANALYSIS OF GAIT VIDEOS
After the tests with the captured images, the test was carried out with the gait videos of each of the 40 volunteers, with four frames with the respective digital markings being extracted for one step. The definition for all tests regarding the assignment of point 14 as the focal point was maintained, as this remains neutral for any member,
It is important to note that in digital processing with video, in addition to the condition of defining key points and extracting trust and affinity maps, the algorithm maintains the dynamic analysis, that is, for each video input frame it considers it as an image This way I extract the matches and the analysis of results throughout the entire video playback, creating a copy with the results.
For all volunteers, video analysis was performed in which the algorithm generated the results for all frames of images, however, to expose the results, frames referring to one step were selected. It is noteworthy that for all image frames they allowed the representation of key points and body segments on the digitized copy of the original video.
For each of the 40 volunteers, a total of four frames were extracted from the processed video, which were arranged in 5×4 matrices with images, totaling 20 elements, knowing that in each figure five volunteers are represented as Figure 11, with the processed images of the four tables for the stride, being: Line 1 for volunteers 1, 6, 11, 16, 21, 26, 31 and 36; Line 2 for volunteers 2, 7, 12, 17, 22, 27, 32 and 37; Line 3 for volunteers 3, 8, 13, 18, 23, 28, 33 and 38; Line 4 for volunteers 4, 9, 14, 19, 24, 29, 34 and 39; and Line 5 for volunteers 5, 10, 15, 20, 25, 30, 35 and 40.
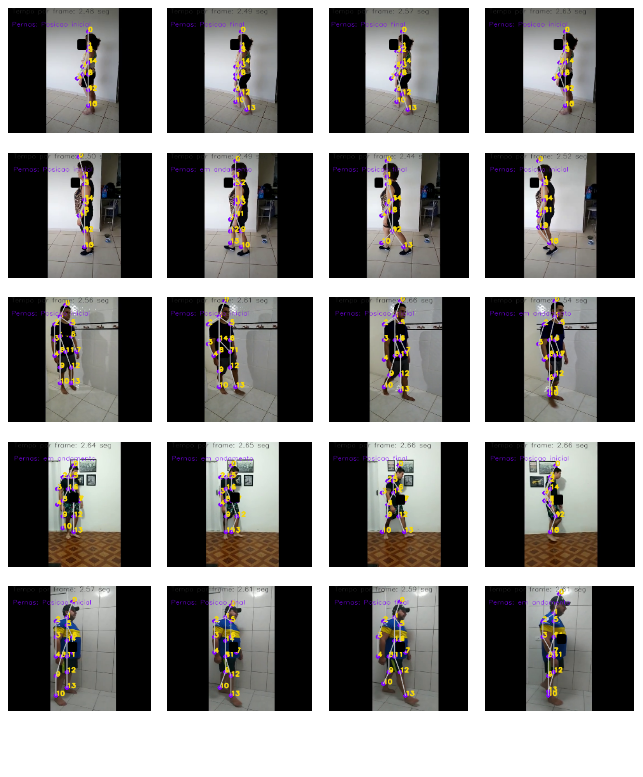
Figure 11. Exposure of results after digital video processing by the algorithm, considering volunteers 1 and 5 in the example.
The tests performed demonstrate in the analyzes of the 40 volunteers that it was possible to define the key points and dynamically maintain the representation of the body segments found, as well as it was possible to demonstrate verification points for movement, as possible by the Cartesian coordinates obtained from the identified points and defined, establish the information, in this case about the opening of legs or step, as shown in Figure 12, which shows the result of a step.

Figure 12. One-step example of definitions of key points and body segments during gait.
4. CONCLUSION AND DISCUSSION
Performing the routines of the developed digital system, one can obtain as a result, in one of the analyses, the body key points referenced to the 15 points assigned by the pre-trained models, being both for capturing images of the child and the adult, which through the code snippet below it is possible to normalize your identification, including this snippet defines the affinities based on the real and physical structure of the human body.
pares_pontos = [[0,1],[1,2],[2,3],[3,4],[1,5],[5,6],[6,7],[1,14],[14,8],[8,9],[9,10],[14,11],[11,12],[12,13]]
After the extractions by the MPII and COCO Caffe dataset, the pairs of points being identified, it is possible for the processed image to identify each x and y coordinate of each point, in which an identification value of x in ‘0’ and y in ‘1’ is assigned.
for par in pares_pontos:
#print(par)
parteA = par[0]
parteB = par[1]
Therefore, it is possible, through a subroutine, to proceed with the creation of a mask with points and lines to point out the visualization and interconnection of each key point.
if pontos[parteA] and pontos[parteB]:
cv2.line(imagem, pontos[parteA], pontos[parteB], cor_linha, 3)
cv2.circle(imagem, pontos[parteA], 8, cor_ponto, thickness = -1, lineType = cv2.LINE_AA)
cv2.line(mascara_mapa, pontos[parteA], pontos[parteB], cor_linha, 3)
cv2.circle(mascara_mapa, pontos[parteA], 8, cor_ponto, thickness = -1, lineType = cv2.LINE_AA)
The reconstruction of the body segments occurs by joining the identified points and if they are physically related, which allows extracting the virtualization of the body segments.
It is important to note that in the 40 volunteers the algorithm recognized the 15 key points and established the trust and affinity maps for each point, but during the digital processing, depending on the environment in which the volunteer was inserted, he was subject to what we call noise in the image by objects and materials that are inserted in the visual field, but that do not make up the human body.
These adverse scenarios allowed tests that under adverse conditions for the algorithm and analyse its ability to identify key points and subsequent reconstruction of body segments, in which it is noted for the global sample with 40 volunteers that there are only eight with deviations, that is, , represent 5% error between identification and reconstruction, knowing that 100% of the points were identified, but 5% are indicated in the reconstruction of body segments. From the error presented, segmenting between the frontal plane image group and the sagittal plane image group, there are 80 images in each group. while in the sagittal plane there is only one image with a displaced dot, which represents the rate of 1.25% of the group of 80 extractions, however it is highlighted that a factor that makes it difficult is the resolution of the images in which they are below 320 pixels and 96dpi resulted in an error, where the images that were recorded from these values allowed a more efficient analysis, so it is recommended that the capture be minimally at 480p and 96dpi.
In the third stage of testing, the videos of the 40 volunteers were analysed, which through the algorithm, without distinguishing the somotype, it was possible to obtain impartial analysis, considering as a fundamental point that the environment is clean, that is, only one wall, without drawings and with objects that can be foreseen, such as the case of apparatus and instruments used in the movement.
In an environment with a lot of objects and visual interference, the algorithm initially had deviations in the reading of the complete video, because when processing it, it generated small confusions with the objects and/or shadows in the data extraction, as noted in the analyses for the volunteers 13, 39 and 40, however with a small adjustment in the programming it is possible to correct such deviations.
For gait analysis with the algorithm, it is important that the capture be performed in widescreen format, as it allows the analysis of the frame and the insertion of the necessary inscriptions for the identification of each frame. Because the environment has greater dynamics, unlike static images, the analyzed videos had a satisfactory return, as the worst one-step index was obtained 75% in a full analysis of all frames, given that 10 of the videos showed some deviation, but in these same videos in other steps it is possible to notice that the algorithm corrects the reading.
In this scenario, it is a fact that 100% of the videos allowed at least one step analysis, so that 160 frames could be analysed, but considering that there are 240 steps and of those between 10 and 20 with deviations, the error rate is found in the range from 4.16 to 8.33%.
These errors are seen in the videos where for one or more frames the algorithm was not able to completely reconstruct the segments in the digital processing, although the confidence and affinity maps were generated, in which case occurred in the analysis of volunteers 9, 16, 17, 24, 31, 36 and 38.
The algorithm demonstrates relatively maintain accuracy in exposing some deviations in body posture. In general, most people have some posture, either because of the incorrect use of shoes, or because of the ergonomic posture of everyday life at work or in household activities, even because of orthopedic or muscle trauma that does not permanently affect the movement.
As an example, it is possible to notice from Volunteer 2, Figure 13, that points 9 and 12, which represent the knees, were displayed in the frontal plane, in which, analysing the set of images, a deviation between them can be seen, which in fact occurs in the reality and that can be seen by the points presented virtually.
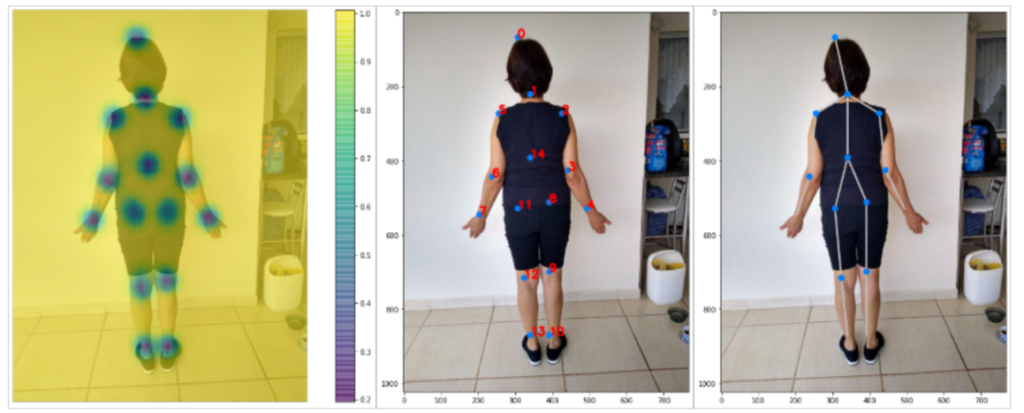
Figure 13. Visualization of the deviation between points 9 and 12 representing the knees of volunteer 2.
The algorithm allows the reading, in less than a second, of the original image and allows the extraction of processing results for the trust and affinity maps, as well as the reconstruction of body segments and key points independent of the physical characteristics of each person and even if the environment presents elements that are visual noise in the images.
It is important to emphasize that the garments had a minimal impact on the identification of points and reconstruction of the segments, as the algorithm through artificial intelligence allowed working with the silhouette of the human body, a factor that managed to correct even the ambient lighting condition.
Currently, Computer Vision systems with Deep Learning had a great insertion in the areas of safety and health, mainly because initially face, object and even medical image recognition were based on Classifiers, more commonly on Cascade, which results in large capacities However, they have a large field of research for the use of Neural Networks to optimize image processing, thus allowing not only recognition, but also the identification of patterns in images based on deep learning models.
In this research, the computer vision system for identification of body pose was discussed and applied, the proposed digital system opens a discussion on the current applications in which techniques with kinemetry are available in the commercial market that are more common for sports training and physiotherapy, however with the use of passive markers positioned on the individual’s body, while on the other hand there is the application of sensors or devices for Virtual Reality, which allow a dynamic interaction of the individual, but still depend on a physical interaction in the body.
The digital system has shown to tend to a coherent application to identify the key points, reproduce the virtualized body segments and, in videos or images, keep the record file both as a mask in the original frame and in reproduction with a black background, exposing only the points and segments.
From these models, it is possible to archive and analyse the frames extracted from the analysis, as well as it is possible to predict by the algorithm the position of points not seen because they are outside the visual field of the camera or the professional, as well as it is possible to extract the pairs of points that allow further analysis of sizes and distances.
One of the advantages is regardless of the type and model of camera used to capture videos and images, operating both with file upload and capture, allowing a low-cost application as it does not depend on a specific model, computers with high processing capacity or a specific environment for the application, therefore, the popularization of the application becomes viable.
As a future proposal, it is possible to explore the trained models and refine machine learning to improve identification, as well as to develop and insert routines that allow extracting direct data, as well as angular and kinematic parameters.
ACKNOWLEDGEMENTS
Special thanks to the researchers and the team of the Laboratório de Ambientes Virtuais e Tecnologia Assistiva (LAVITA) of the Núcleo de Pesquisa Tecnológica (NPT) of the Universidade de Mogi das Cruzes (UMC), Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP) (Grant #2017/14016-7) and Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) by fee scholarship.
REFERENCES
- CENSO, Cartilha do. Pessoas com deficiência. Luiza Maria Borges Oliveira/Secretaria de Direitos Humanos da Presidência da República (SDH/PR)/Secretaria Nacional de Promoção dos Direitos da Pessoa om Deficiência (SNPD)/Coordenação-Geral do Sistema de Informações sobre a Pessoa com Deficiência, 2010.
- Borgneth L. 2004. Considerações sobre o processo de reabilitação. Acta fisiátrica, v. 11, n. 2, p. 55-59.
- Guimarães LS, Cruz MC. 2003. Exercícios terapêuticos: a cinesioterapia como importante recurso da fisioterapia. Lato & Sensu, v. 4, n. 1, p. 3-5.
- Amadio AC, Duarte M. 1996. Fundamentos biomecânicos para a análise do movimento humano.
- Baumann, W. 1995. Métodos de medição e campos de aplicação da biomecânica: estado da arte e perspectivas. In: VI Congresso Brasileiro de Biomecânica. Brasília.
- Melo SIL, Santos SG. 2000. Antropometria em biomecânica: características, princípios e modelos antropométricos. Revista Brasileira de Cineantropometria e Desempenho Humano.
- Rebelo FS. 2002. Sistema Digita–Aquisição de Dados Antropométricos Baseada em Técnicas Fotogramétricas para Aplicações em Ergonomia. Manual Técnico. Lisboa, Portugal.
- Andriluka M, Pishchulin L, Gehler P, Schiele B. 2014. 2d human pose estimation: New benchmark and state of the art analysis. In: Proceedings of the IEEE Conference on computer Vision and Pattern Recognition. p. 3686-3693.
- Nilsen MA. 2015. Neural networks and deep learning. San Francisco, CA, USA: Determination press.
- Breda VM. 2018. Reconhecimento de gestos em vídeos utilizando modelos ocultos de Markov e redes neurais convolucionais aplicado a libras.
- Sanchez BS, Luzcena B, Rodrigues CMR, Fernandes JCL, Bondioli ACV, Mundin HAC, Sousa VS, Silva LHBO. 2019. Artificial Intelligence to Detect Alzheimer’s in Magnetic Resonances. In: XXVI Brazilian Congress on Biomedical Engineering. Springer, Singapore. p. 59-63.
- Carey K, Abruzzo B, Lowrence C, Sturzinger E, Arnold R, Korpela C. 2020. Comparison of skeleton models and classification accuracy for posture-based threat assessment using deep-learning. In: Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications II. International Society for Optics and Photonics. p. 1141321.
- Brendler CF, Teixeira FG. 2013. Diretrizes para auxiliar na aplicação da Antropometria no desenvolvimento de Projetos de Produtos Personalizados. Estudos em Design, v. 21, n. 2.
- Cao Z, Simon T, Wei S, Sheikh Y. 2017. Realtime multi-person 2d pose estimation using part affinity fields. In: Proceedings of the IEEE conference on computer vision and pattern recognition. p. 7291-7299.
a Núcleo de Pesquisas Tecnológicas – NPT, Laboratório de Ambientes Virtuais e Tecnologia Assistiva – LAVITA, Universidade de Mogi das Cruzes – UMC, Mogi das Cruzes, Brazil; bNúcleo de Engenharia, Universidade Santo Amaro – UNISA, São Paulo, Brazil
Provide full correspondence details here including e-mail for the *corresponding author
*renatobritosanchez@gmail.com