COMPARISON OF MACHINE LEARNING MODELS FOR CARDIOVASCULAR DISEASE DIAGNOSIS: A STUDY ON STROKE, CARDIAC ARRHYTHMIA, AND CORONARY ARTERY DISEASE
REGISTRO DOI: 10.5281/zenodo.10116749
Barbara Nery
Jose Vargas
Rhuan Amaral
Thiago Ramos
Renata Marci
Pedro Alves
Resumo: O presente estudo visa investigar e comparar o desempenho de cinco modelos de aprendizado de máquina – Decision Tree (Árvore de decisão), Random Forest, Support Vector Machine (SVM), Regressão Logística e KNN (K-Nearest Neighbors) – na tarefa de diagnóstico de três doenças cardiovasculares críticas: Acidente Vascular Cerebral (AVC), Arritmia Cardíaca e Doença Arterial Coronariana (DAC). Para viabilizar tal comparação, é necessário utilizar um conjunto de dados abrangente contendo informações clínicas de pacientes, incluindo fatores de risco, histórico médico e resultados de exames. Os modelos foram treinados e avaliados em métricas de desempenho como acurácia, sensibilidade, especificidade e F1-score. Através deste trabalho, destaca-se a relatividade na busca pelo melhor modelo que, a depender do contexto da aplicação, difere, em termos de métricas de desempenho.
Palavras-chave: SVM; KNN; Regressão; Dataset; Machine Learning; Cardiovascular.
Abstract: The present study aims to investigate and compare the performance of five machine learning models – Decision Tree, Random Forest, Support Vector Machine (SVM), Logistic Regression and K-Nearest Neighbours (KNN) – in the diagnostic task of three critical cardiovascular diseases: Stroke, Cardiac Arrhythmia and Coronary Artery Disease (CAD). To enable such comparison, it is necessary to use a comprehensive dataset containing clinical information from patients, including risk factors, medical history and test results. The models were trained and evaluated on performance metrics such as accuracy, sensitivity, specificity and F1 score. Throughout this work, relativity is highlighted in the search for the best model which, depending on the application context, differs in terms of performance metrics.
Keywords: SVM; KNN; Regression; Data set; Machine Learning; Cardiovascular.
1. Introdução
Estima-se que 17,9 milhões de pessoas morreram de doenças cardiovasculares em 2019, representando 32% de todas as mortes globais (WHO, 2021). Essas doenças englobam uma variedade de condições críticas, incluindo arritmia cardíaca, acidente vascular cerebral (AVC) e doença arterial coronariana (DAC). Com o aumento da prevalência dessas doenças e sua gravidade, tornou-se imperativo desenvolver abordagens mais eficazes para o diagnóstico precoce e preciso.
OBERMEYER e EMANUEL (2016) afirmam que a medicina contemporânea tem testemunhado avanços substanciais na aplicação de técnicas de machine learning para a predição e diagnóstico de doenças, incluindo doenças cardiovasculares (DCVs). Nesse contexto, a escolha do modelo de machine learning adequado desempenha um papel crucial na rapidez e confiabilidade do diagnóstico. Neste estudo foi proposta uma análise da performance de cinco modelos de machine learning amplamente utilizados: Regressão logística, K-Nearest Neighbors (KNN), Árvore de decisão, Support Vector Machine (SVM) e Random Forest (RF), em relação a predição de três DCVs específicas: arritmia cardíaca, AVC e DAC.
A relevância desse estudo reside na necessidade de fornecer orientações claras aos profissionais de saúde e pesquisadores sobre quais modelos de machine learning podem ser mais apropriados para cada tipo de DCV. Essa diferenciação é essencial, pois as DCVs variam em termos de complexidade clínica, fatores de risco e padrões de manifestação. Um modelo que se destaque na predição de uma doença pode não ser igualmente eficaz em outra. Este estudo baseia-se na premissa de que a escolha do modelo de machine learning correto pode melhorar significativamente a rapidez e a precisão do diagnóstico de DCVs, levando a intervenções médicas mais oportunas e eficazes. As métricas de desempenho, como a área sob a curva Receiver Operating Characteristic (ROC) – ou Característica de Operação do Receptor -, precisão, recall e F1-score, serão avaliadas e comparadas para determinar qual modelo se destaca em relação a cada DCV específica.
O restante deste artigo está organizado da seguinte forma: na seção 2, será realizada uma revisão de literatura sobre o uso de Machine Learning em DCVs; na seção 3, é detalhada a metodologia utilizada na coleta de dados e construção dos modelos; na seção 4, apresentaremos os resultados e as análise das métricas de desempenho; na seção 5, são discutidas as implicações dos resultados obtidos; e, por fim, na seção 6, o estudo é concluído com insights sobre a aplicabilidade prática desses modelos na predição de DCVs e direções futuras na pesquisa.
1.1. Justificativa
As doenças cardiovasculares retratam uma das principais causas da mortalidade global (WHO, 2021), enfatizando a importância da busca por estratégias de diagnóstico rápidos e precisos. Com o constante crescimento de disponibilidade de registros eletrônicos médicos de pacientes e os avanços contínuos da tecnologia é possível verificar a ampla aplicação de modelos preditivos. A capacidade de prever essas doenças de forma eficaz é crucial para intervenções médicas precoces e tratamento adequado. Dessa forma, a aplicação de técnicas de machine learning para a previsão de doenças cardiovasculares oferece uma abordagem promissora, mas é essencial determinar qual modelo de machine learning é o mais apropriado para cada tipo de doença cardiovascular.
Com isto, será realizado a comparação dos parâmetros de performance, sendo eles: F1-score, acurácia, precisão e recall referentes aos modelos preditivos de doenças cardiovasculares. Portanto, a utilização dos modelos se revela uma ferramenta promissora para enfrentar este desafio, devido à sua capacidade de analisar extensos conjuntos de dados médicos e identificar padrões complexos.
1.2. Objetivos
O objetivo principal deste estudo é comparar a performance de cinco modelos de machine learning na predição de três doenças cardiovasculares distintas: arritmia cardíaca, AVC e DAC. os modelos selecionados para avaliação são: Regressão Logística, K-Nearest
Neighbors (KNN), Árvore de decisão, Support Vector Machine (SVM) e Random Forest (RF). Essa pesquisa visa comparar os diferentes modelos e apresentar a melhor performance para cada uma das doenças cardiovasculares, levando em consideração diferentes métricas de desempenho.
2. Revisão bibliográfica
A predição de doenças cardiovasculares por meio de algoritmos de aprendizado de máquina tem sido alvo de extensa pesquisa nos últimos anos. Nesta seção, serão revisados estudos anteriores que abordam a aplicação de diversos modelos de machine learning na previsão de três doenças cardiovasculares específicas: arritmia cardíaca, AVC e DAC. O objetivo central dessas pesquisas tem sido a avaliação do desempenho dos modelos e a identificação daqueles mais apropriados para cada tipo de doenças, reconhecendo a importância crítica de um diagnóstico rápido e confiável.
2.1.Previsão da Arritmia Cardíaca
Na busca por métodos eficazes de previsão da arritmia cardíaca, estudos anteriores têm explorado uma variedade de algoritmos de machine learning. Por exemplo, KURT (2005) comparou cinco algoritmos de classificação, incluindo Regressão Logística, Árvore de Decisão, Rede Neural Artificial, Função de Viés Radial e Mapas de Características Auto-organizáveis. Os resultados indicaram que a Rede Neural Artificial obteve o melhor desempenho.
Além disso, pesquisadores como DEHKORDI e SAJEDI (2022) empregaram algoritmos de classificação, como Árvore J48, Naive Bayes, KNN e uma abordagem ensemble denominada “Skating”. Embora o algoritmo “Skating” tenha alcançado uma precisão de 73,31%, outros estudos, como o de NORDIN et. al. (2015), obtiveram maior precisão, chegando a 98,13% com o Random Forest (RF).
2.2.Previsão de Acidente Vascular Cerebral (AVC)
A previsão de AVC tem sido alvo de intensas investigações. ARCHANA et. al. (2023) alcançaram uma precisão de 87% com o algoritmo KNN. Em contraste, ALIM et al. (2020) utilizaram Regressão Logística (LR), Naive Bayes (NB), Support Vector Machine (SVM), Random Forest (RF) e Gradient Boosting (GB) para prever a doença, destacando o RF com uma precisão de 86,42%.
Outros estudos, como o de SONI et al. (2011), aplicaram uma combinação de Árvore de Decisão e Algoritmo Genético, alcançando 99,2% de precisão. MANSOOR et al. (2017) analisaram o desempenho de algoritmos de classificação, como o LR e RF, com a LR apresentando uma precisão superior (89%) em comparação com o RF (88%).
2.3.Previsão de Doença Arterial Coronariana
A DAC também foi objeto de várias pesquisas. LATHA e JEEVA (2017) empregaram uma técnica de classificação em conjunto, obtendo uma precisão de 85,45%. MOHAN et al. (2019) introduziram um modelo de predição de DAC utilizando técnicas de aprendizagem de máquina híbrido, alcançando uma precisão de 88,7%. TARAWNEH e EMBARAK (2019) propuseram uma abordagem híbrida com uma precisão de 89,2%.
Além disso, estudos como o de NASSIF (2019), destacam a importância da seleção de características, ao aplicar a seleção de características em conjunto com algoritmos de classificação para melhorar o desempenho.
Dessa forma, os trabalhos revisitados anteriormente, têm demonstrado a eficácia de uma variedade de algoritmos de machine learning na predição de doenças cardiovasculares. No entanto, a escolha do algoritmo mais apropriado pode depender do tipo específico de doenças e das características do conjunto de dados.
2.4.Considerações gerais
Embora os trabalhos revisados tenham fornecido resultados promissores em suas respectivas áreas de foco, é importante notar que a precisão varia entre os estudos. Os diferentes estudos vistos anteriormente, utilizaram – em alguns casos – bases de dados diferentes e empregaram métodos diferentes para realizar a classificação dos conjuntos de dados.
Neste estudo, o objetivo é ampliar essa compreensão, comparando o desempenho de cinco modelos de aprendizado de máquina – Regressão Logística, K-Nearest Neighbors (KNN), Árvore de Decisão, Support Vector Machine (SVM) e Random Forest – na previsão de arritmia cardíaca, AVC e DAC. Sendo assim, essa análise comparativa contribui para a identificação dos modelos mais adequados para cada doença cardiovascular, melhorando assim a rapidez e confiabilidade dos diagnósticos.
3. Metodologia
Nesta seção, será descrito, em detalhes, a metodologia adotada para comparar a performance de cinco modelos de aprendizado de máquina na predição de três doenças cardiovasculares: Arritmia Cardíaca, AVC e DAC. O objetivo deste estudo é determinar qual modelo é mais apropriado para cada uma dessas doenças, considerando a importância crítica da precisão do diagnóstico em doenças cardiovasculares.
3.1.Conjunto de dados
Para conduzir esta análise comparativa, foram utilizados três conjuntos de dados diferentes, cada um deles correspondendo a uma das doenças cardiovasculares em estudo:
MIT-BIH Arrhythmia Disease: Este conjunto de dados abrange a arritmia cardíaca e é uma referência padrão para estudos nessa área. Ele contém informações detalhadas sobre a atividade elétrica do coração, sendo compostos por séries temporais de eletrocardiograma (ECGs) de pacientes. A arritmia cardíaca é uma condição caracterizada por batimentos cardíacos irregulares.
Cleveland Heart Disease: Este conjunto de dados é específico para o Acidente Vascular Cerebral (AVC) e foi obtido do repositório UCI Machine Learning. Contém uma variedade de atributos médicos e é usado para prever a presença de AVC em pacientes.
Framingham Massachusetts CHD: Este conjunto de dados abrange casos de doença arterial coronariana (DAC). Foi coletado como parte do Framingham Heart Study e inclui informações sobre fatores de risco cardiovascular e a ocorrência de eventos cardiovasculares, como AVC e DAC.
3.2.Pré-processamento de dados
O pré-processamento de dados foi uma etapa fundamental para garantir a qualidade dos dados de entradas para a utilização posterior, nos modelos de Machine Learning. As etapas incluíram:
– Tratamento de valores ausentes: Foram identificados e tratados os valores ausentes nos conjuntos de dados por meio de técnicas como imputação média para dados numéricos e preenchimento de moda para dados categóricos.
– Codificação de variáveis categóricas: Foi utilizada a técnica de codificação One-Hot Encoding para converter variáveis categóricas em representações numéricas, permitindo que os modelos de machine learning as utilizassem.
– Seleção de características: Foi realizada uma análise de seleção de características para identificar features mais relevantes em cada conjunto de dados. Com isso, foi possível reduzir a dimensionalidade e melhorar a eficiência dos modelos.
– Remoção de outliers: Foram detectados e tratados os outliers nos dados a fim de evitar que eles influenciassem negativamente o desempenho dos modelos.
– Divisão em Treinamento e Teste: Os conjuntos de dados foram divididos em conjuntos de treinamento e teste, na proporção 80/20, com o objetivo de avaliar o desempenho dos modelos em dados não vistos.
3.3.Pipeline de Machine Learning
Para a demonstração do fluxo de desenvolvimento dos modelos, foi utilizado o pipeline de Machine Learning proposto por POORTER et al. (2021) para cada conjunto de dados e cada doença cardiovascular, seguindo as melhores práticas. O pipeline incluiu as etapas demonstradas na figura 1.
Figura 1: Fluxograma com as etapas de desenvolvimento dos modelos e análise de dados.
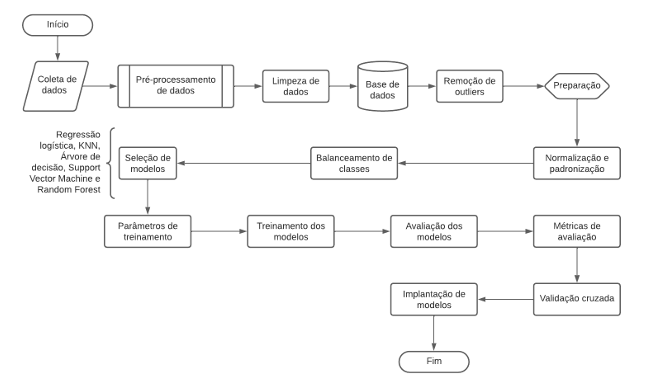
Fonte: Adaptado de POORTER et. al. (2021).
– Normalização e padronização: Os dados foram normalizados e padronizados, quando apropriado, para garantir que todas as características tivessem a mesma escala.
– Balanceamento de classes: Dado que as classes de diagnóstico podem ser desequilibradas, foram aplicadas técnicas de balanceamento como oversampling e undersampling, para evitar viés nos modelos.
– Treinamento de modelos: Foram utilizados cinco modelos de machine learning diferentes: Regressão logística, K-Nearest Neighbors (KNN), Árvore de decisão, Support Vector Machine (SVM) e Random Forest. Cada modelo foi treinado separadamente para cada conjunto de dados e doenças.
3.4. Métricas de avaliação
A avaliação do desempenho dos modelos foi baseado no estudo sobre avaliação de métricas de desempenho proposta por VUJOVIC (2021), que inclui:
– Acurácia: Mede a taxa de acertos em relação ao número total de amostras.
– Precisão: Calcula a proporção de verdadeiros positivos em relação ao total de positivos previstos.
– Revocação (recall): Calcula a proporção de verdadeiros positivos em relação ao total de positivos reais.
– F1-score: Uma métrica que combina a precisão e a revocação, fornecendo uma medida única de desempenho.
3.5. Otimização de hiperparâmetros
Para otimizar o desempenho dos modelos, foi realizada a otimização dos hiperparâmetros utilizando a biblioteca Optuna. Com isso, foi possível ajustar os parâmetros dos modelos de forma eficiente, garantindo que fossem bem ajustados aos dados.
4. Resultados e discussão
Nesta seção, foram apresentados os resultados da comparação de métricas de desempenho entre cinco modelos de aprendizado de máquina: Regressão Logística, K-Nearest Neighbors (KNN), Árvore de decisão, Support Vector Machine (SVM) e Random Forest. Esses modelos foram aplicados à tarefa de previsão de três doenças cardiovasculares distintas: arritmia cardíaca, acidente vascular cerebral (AVC) e doença arterial coronariana (DAC). A análise visa identificar qual modelo é mais apropriado para cada uma dessas condições de saúde críticas, considerando a importância da rapidez e confiabilidade no diagnóstico precoce.
Desempenho geral dos modelos
Antes de mergulhar nas métricas específicas para cada doença, é relevante avaliar o desempenho geral dos modelos em todas as condições cardiovasculares. Para isso, foi utilizada a Área Sob a Curva ROC (AUC-ROC) como métrica de referência. As figuras 2, 3 e 4 apresentam as curvas ROC para cada modelo em relação às três doenças estudadas.
Figura 2: ROC Curve para os 5 modelos aplicado a predição de Arritmia Cardíaca.
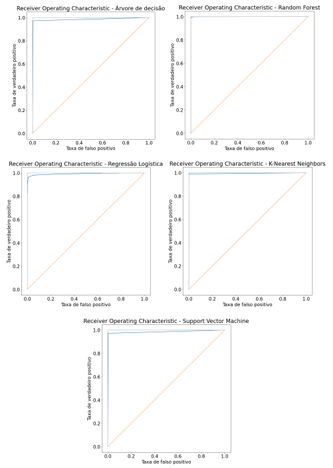
Figura 3: ROC Curve para os 5 modelos aplicado a predição de Acidente Vascular Cerebral.
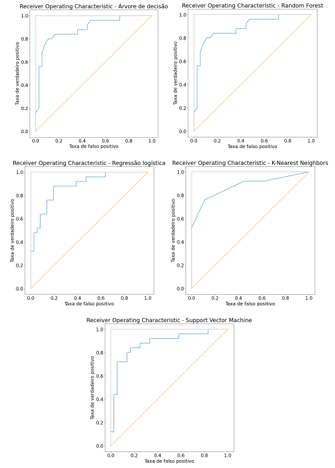
Figura 4: ROC Curve para os 5 modelos aplicado a predição de Doença Arterial Coronariana.
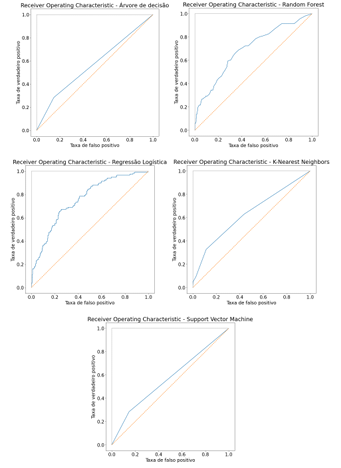
Observa-se que todos os modelos apresentam curvas ROC com AUC-ROC significativamente acima de 0,5. De acordo com SILVA (2019) para modelos com AUC-ROC igual a 0,5 – i.e., que se constituem na linha diagonal que vai do ponto (0,0) ao ponto (1,1) -, lhes é conferido o desempenho de um classificador aleatório (random guessing). Para os casos acima, no entanto, é importante destacar que as curvas variam em inclinação e formato, sugerindo diferenças na capacidade de discriminação entre os modelos.
Métricas específicas para cada doença
A fim de aprofundar a análise, foram calculadas métricas específicas para cada doença cardiovascular. Essas métricas incluem: acurácia, precisão, F1-scores e para cada modelo em relação a cada condição de saúde. Os resultados estão resumidos nas Tabelas 1, 2 e 3 para arritmia cardíaca, AVC e DAC, respectivamente.
Tabela 1: Métricas de desempenho dos modelos para previsão de arritmia cardíaca
Métrica Regressão Logística KNN Árvore de decisão SVM Random Forest Acurácia 95% 95% 93% 95% 95% Precisão 94% 95% 93% 95% 95% Recall 94% 95% 93% 95% 95% F1-Score 95% 95% 93% 95% 95%
Fonte: Elaborado pelos autores.
Tabela 2: Métricas de desempenho dos modelos para previsão de Acidente Vascular Cerebral
Métrica Regressão Logística KNN Árvore de decisão SVM Random Forest Acurácia 85% 88% 70% 86% 78% Precisão 85% 88% 71% 87% 79% Recall 85% 89% 71% 87% 78% F1-Score 85% 89% 70% 87% 78%
Fonte: Elaborado pelos autores.
Tabela 3: Métricas de desempenho dos modelos para previsão de Doença Arterial Coronariana
Métrica Regressão Logística KNN Árvore de decisão SVM Random Forest Acurácia 84% 82% 75% 84% 84% Precisão 75% 59% 54% 75% 71% Recall 53% 53% 55% 50% 53% F1-Score 53% 53% 55% 47% 52%
Fonte: Elaborado pelos autores.
Discussão
As métricas de desempenho apontam uma variação no desempenho geral dos modelos. Tal fato está intrinsecamente relacionado à doença analisada. Para a previsão de arritmia cardíaca, o modelo SVM apresentou o melhor desempenho, com a mais alta acurácia (95,62%) e F1-score (95%). Para a previsão de AVC, o modelo KNN apresentou o melhor desempenho, com a mais alta acurácia (88%) e F1-score (89%). Para os os casos de predição de AVC e arritmia, é possível constatar que os outros modelos também mostraram bom desempenho, com valores de acurácia e F1-score, próximos aos modelos com melhor performance. Já para o caso de DAC, é possível verificar que há 3 modelos mais performáticos, com a mesma acurácia (84%), sendo eles: regressão logística, SVM e random forest.
De qualquer forma, é importante observar que a escolha do modelo apropriado depende da priorização de diferentes métricas, como acurácia, precisão ou recall, com base nas necessidades clínicas específicas. Além disso, considerações práticas, como a interpretabilidade do modelo, também devem ser levados em consideração.
Os resultados indicam que os modelos de aprendizado de máquina têm o potencial de auxiliar no diagnóstico precoce e confiável de doenças cardiovasculares. No entanto, é essencial realizar mais pesquisas e validações clínicas antes da implementação prática desses modelos em ambientes clínicos reais. A utilização de dados mais granulares e registros clínicos detalhados pode aprimorar ainda mais a capacidade de previsão desses modelos.
5. Conclusão
Com a utilização de diferentes bases de dados e modelos, mesmo ao empregar metodologias semelhantes, é possível constatar que os modelos com melhor performance variam conforme a doença analisada. Para o caso de previsão de arritmia cardíaca, o modelo SVM teve uma performance geral superior aos outros modelos. Porém, as métricas indicam uma diferença relativamente baixa entre a performance geral dos modelos, para a previsão de arritmia cardíaca. Vale salientar, que de todos os conjuntos de dados utilizados, o “MIT-BIH Arrhythmia Disease” possuía a maior quantidade de registros: cerca de 16.000. Em termos de proporcionalidade, isso significa dizer que os conjuntos de dados “Cleveland Heart Disease” e “Framingham Massachusetts CHD” correspondem, respectivamente, a 1,89% e 26,5% da quantidade de registros da base de dados utilizada para a análise de arritmia. Dessa forma, o emprego de diferentes contextos e metodologias na aplicação de modelos de predição e tratamento de dados – como visto no pipeline de machine learning proposto por POORTER (2021) – para doenças cardiovasculares, reflete na variação de performance desses modelos. Isto posto, a seleção do modelo deve levar em consideração as características dos dados e as métricas de desempenho relevantes para determinado contexto, além dos outliers existentes que podem inviabilizar os modelos. A aplicação de técnicas de machine learning na predição de doenças cardiovasculares é promissora e pode desempenhar um papel crucial na medicina preventiva e diagnóstico precoce.
6. Referências bibliográficas
ALIM, Muhammad A. et. al. Robust Heart Disease Prediction: A novel Approach based on Significant Feature Ensemble learning Model. 3rd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET). 2023.
CARDIOVASCULAR diseases (CVDs). World Health Organization, 2021. Disponível em:<https://www.who.int/en/news-room/fact-sheets/detail/cardiovascular-diseases-(cvds)>.Acesso em 02 de jul. de 2023.
KURT, Arda. A comparative Study of five algorithms for processing Ultrasonic Arc Maps. Bilkent University. 2005
LATHA, C. Beulah Christalin; JEEVA, S. Carolin. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Elsevier, Science Direct. 2019 MANSOOR, Hend. et al. Risk prediction model for in-hospital mortality in women with STelevation myocardial infarction: A machine learning approach. Elsevier, Science Direct. 2017.
MOHAN, S. et al. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access, vol. 7. 2019.
NASSIF, Ali Bou. et al. Clustering Enabled Classification using Ensemble Feature Selection for Intrusion Detection. International Conference on Computing, Networking and Communications (ICNC). 2019
NEZHAD, Sana N.; ZAHEDI, Mohammad H.; Detecting diseases in medical prescriptions using data mining methods. Sharif University of Technology. 2022
NORDIN, Jan.; SAMARRAIE, Mohammed M. Texture classification using random forests and support vector machines. Journal of Theoretical and Applied Information Technology. Universiti Kebangsaan Malaysia
OBERMEYER, Z., & EMANUEL, E. J. Predicting the Future – Big Data, Machine Learning, and Clinical Medicine. New England Journal of Medicine, 375(13), 1216-1219. DOI: 10.1056/NEJMp1606181. 2016
SONI, Sunita et al. Predictive Data Mining for Medical Diagnosis: An Overview of Heart Disease Prediction. International Journal of Computer Applications. 2011
TARAWNEH, M.; EMBARAK, O. Hybrid Approach for Heart Disease Prediction Using Data Mining Techniques. Nutzwertanalysen in Marketing Und Vertrieb. 2019
VUJOVIC, Zeljko D. Classification Model Evaluation Metrics. International Journal of Advanced Computer Science and Applications. 2021.