COMPARISON OF THE EFFICACY OF CONVOLUTIONAL NEURAL NETWORKS IN IMAGE CLASSIFICATION TASKS
REGISTRO DOI: 10.69849/revistaft/ra10202410311524
Leonardo Wellington Dal Rovere Lourenço1
João Henrique Gião Borges2
Fabiana Florian3
Resumo: Este artigo tem o objetivo de comparar a eficácia das arquiteturas de redes neurais convolucionais (CNNs) VGG16, ResNet50 e InceptionV3 em tarefas de classificação de imagens utilizando o conjunto de dados CIFAR-10. Foi realizada pesquisa bibliográfica e para comparar foi realizado técnicas de ajuste fino e congelamento de camadas para adaptar as redes pré-treinadas ao conjunto de dados. Os resultados indicaram que a VGG16 apresentou um equilíbrio entre precisão de treinamento e validação, sendo a mais eficaz para o CIFAR-10, enquanto o InceptionV3, apesar de sua alta precisão no treinamento, mostrou sinais de sobreajuste. O ResNet50 teve o pior desempenho, sugerindo que sua arquitetura não é adequada para este conjunto de dados. Conclui-se que a escolha da arquitetura é fundamental considerar o equilíbrio entre eficiência computacional e capacidade de generalização.
Palavras-chave: CNN. CIFAR-10. InceptionV3. ResNet50. VGG16.
Abstract: This article aims to compare the effectiveness of the convolutional neural network (CNN) architectures VGG16, ResNet50, and InceptionV3 in image classification tasks using the CIFAR-10 dataset. A literature review was conducted, and fine-tuning and layer freezing techniques were applied to adapt the pre-trained networks to the dataset. The results indicated that VGG16 presented a balance between training and validation accuracy, proving to be the most effective for CIFAR-10, while InceptionV3, despite its high training accuracy, showed signs of overfitting. ResNet50 had the worst performance, suggesting that its architecture is not suitable for this dataset. It is concluded that choosing the right architecture is essential to balance computational efficiency and generalization capacity.
Keywords: CNN. CIFAR-10. InceptionV3. ResNet50. VGG16.
1 INTRODUÇÃO
É notável que o uso da Inteligência Artificial (IA) está cada vez mais presente no dia a dia das pessoas, influenciando diversas áreas, auxiliando o aprendizado, automatizando processos e facilitando a tomada de decisões. No campo da visão computacional, que é fundamental para a IA, o surgimento das Redes Neurais Convolucionais (CNNs, do inglês Convolutional Neural Networks) representou um grande avanço. Essas redes utilizam convoluções, que são operações matemáticas e funcionam como mecanismos que ajudam a detectar padrões importantes em imagens, como bordas e formas, permitindo que o sistema entenda melhor o conteúdo visual.
É natural que seres humanos reconheçam objetos em imagens, uma vez que o cérebro processa informações visuais e as associa com memórias armazenadas (KANDEL et al., 2014; MILNER et al., 2014). Graças aos avanços das CNNs, a precisão da capacidade computacional na classificação de imagens melhorou significativamente.
As redes neurais convolucionais (CNNs) são desenvolvidas a partir de conhecimentos sobre o processamento de imagens visuais no cérebro humano. Diferentes das redes feedforward, onde os dados percorrem a rede em uma única direção, da entrada até a saída, as CNNs se destacam por não apenas vetorizarem as imagens, mas por se comportarem como neurônios no sistema nervoso central. Essas redes convolucionais têm a capacidade de captar dados pertinentes usando filtros de forma localizada, como bordas, texturas e formas, o que as torna extremamente eficientes para tarefas de classificação de imagens. (SCHMIDHUBER, 2015).
O objetivo deste artigo é comparar a eficácia de arquiteturas de redes neurais convolucionais (CNNs), ResNet50, InceptionV3 e VGG16 em tarefas de classificação de imagens utilizando as dez categorias presentes no conjunto de dados CIFAR-10. Foram escolhidas as arquiteturas ResNet50, InceptionV3 e VGG16 por serem amplamente reconhecidas pela sua eficiência em vários contextos de visão computacional, permitindo assim uma análise aprofundada para determinar qual delas é a mais adequada para lidar com os desafios do CIFAR-10.
A escolha do CIFAR-10 é importante porque ele é amplamente usado como referência em pesquisas de visão computacional. Composto por 60.000 imagens coloridas de 32×32 pixels, divididas em 10 classes desafiadoras, é um conjunto de dados que apresenta imagens de baixa resolução e classes que se parecem bastante, o que representa um verdadeiro teste para algoritmos de classificação. Os resultados deste estudo podem ajudar pesquisadores e desenvolvedores a escolher a melhor arquitetura de rede neural para classificar imagens de baixa resolução, o que é útil em dispositivos móveis e sistemas embarcados, por exemplo.
A avaliação e comparação da eficácia das redes em vários cenários de classificação de imagens é necessária devido ao avanço rápido das CNNs e à variedade de arquiteturas propostas.
Krizhevsky, Sutskever e Hinton (2012), demonstraram como CNNs profundas podem superar métodos convencionais em termos de precisão de classificação em conjuntos de dados difíceis, como o ImageNet. Desde então, no entanto, muitas outras arquiteturas surgiram, cada uma com suas próprias características e vantagens, tornando a análise comparativa essencial para guiar a escolha e o desenvolvimento de modelos mais eficazes.
Simonyan e Zisserman (2015), autores da VGGNet, e He et al. (2016), responsáveis pela ResNet, enfatizaram a necessidade de investigar a complexidade e a profundidade das redes neurais para evitar problemas como o sobreajuste e o desvanecimento do gradiente. Esses problemas mostram quão importante é fazer avaliações da precisão das CNNs, bem como de sua eficiência e robustez em diferentes situações.
Embora as Redes Neurais Convolucionais tenham evoluído e se tornado eficientes na classificação de imagens, ainda não se tem a arquitetura “perfeita” para determinado problema. Existem várias arquiteturas, cada uma com suas vantagens e desvantagens, no entanto, os resultados nem sempre são conclusivos ou generalizáveis para diferentes cenários.
A eficácia e a precisão das CNNs variam de acordo com a arquitetura utilizada, isso permite que os padrões de desempenho sejam encontrados para ajudar na seleção da rede mais adequada para cada tarefa específica. A hipótese é que embora algumas arquiteturas se comportem melhor em contextos gerais, outras podem ser melhores em situações específicas.
Para realizar essa comparação, utilizou-se de um conjunto de dados de classificação de imagens CIFAR-10 e a ferramenta Google Colab. O Google Colab oferece uma plataforma online gratuita e acessível para o desenvolvimento e execução de projetos de inteligência artificial, fornecendo ambientes de execução com GPUs, essenciais para treinar modelos de CNNs de forma eficiente. Foi implementada as CNNs em Python, que oferece diversas bibliotecas e frameworks especializados em inteligência artificial.
Foi utilizado métodos de ajuste fino (fine-tuning) e congelamento de camadas, estratégias comuns em Transfer Learning, para analisar como essas técnicas afetam o desempenho das diferentes arquiteturas de CNNs.
Por fim, para encontrar padrões de eficiência e escolher a arquitetura mais adequada para vários cenários de classificação de imagens, as redes foram avaliadas usando a métrica de desempenho acurácia, que se refere à proporção de previsões corretas feitas pelo modelo em relação ao total de amostras avaliadas.
2 REVISÃO BIBLIOGRÁFICA
Esta seção apresenta os conceitos básicos e outros estudos relacionados ao tema proposto. A revisão da literatura subdividiu-se nos itens: (2.1) Inteligência Artificial (IA), (2.2) Visão Computacional, (2.3) Histórico e Fundamentos das Redes Neurais Convolucionais (CNNs), (2.4) VGGNet, (2.4.1) Inception (GoogleNet), (2.4.2) ResNet, (2.5) Fine-Tuning, (2.6) CIFAR-10, (2.7) Google Colab, (2.8) Python e Bibliotecas e (2.8.1) TensorFlow.
2.1 Inteligência Artificial (IA)
Segundo Norvig e Russell (2013), a Inteligência Artificial (IA) é o estudo de agentes que recebem percepções do ambiente e executam ações. Cada agente implementa uma função que mapeia sequências de percepções em ações, e abordaram diferentes maneiras de representar essas funções.
Aprendizagem de máquina, visão computacional e processamento de linguagem natural são alguns dos vários subcampos da inteligência artificial (IA). O uso de redes neurais profundas, particularmente as CNNs para visão computacional, tem feito um grande avanço nesses campos.
2.2 Visão Computacional
Graças à inteligência artificial, a visão computacional capacita os computadores a perceber e compreender o ambiente visual, representando um avanço significativo na forma como interpretam o mundo ao seu redor. Segundo Szeliski (2010), “a visão computacional visa automatizar tarefas que o sistema visual humano pode realizar”.
Nos últimos anos, com o avanço das técnicas de aprendizado profundo, a visão computacional evoluiu rapidamente, permitindo a criação de sistemas que não apenas identificam objetos em imagens, mas também tarefas complexas como segmentação, detecção de objetos e reconhecimento facial.
2.3 Histórico e Fundamentos das Redes Neurais Convolucionais (CNNs)
A jornada das Redes Neurais Convolucionais (CNNs) teve início na década de 1990 com a LeNet, desenvolvida por Yann LeCun e sua equipe, que focava no reconhecimento de dígitos manuscritos (LECUN et al., 1998). Um salto significativo veio em 2012 com a AlexNet, criada por Krizhevsky, Sutskever e Hinton (2012), que conquistou o desafio ImageNet e comprovou a superioridade das CNNs profundas sobre métodos tradicionais. A partir daí, novas arquiteturas surgiram, como VGGNet (SIMONYAN; ZISSERMAN, 2015), Inception (SZEGEDY et al., 2015) e ResNet (HE et al., 2016), impulsionando ainda mais a precisão e a eficiência das CNNs.
Arquiteturas como DenseNet (HUANG et al., 2017) e EfficientNet (TAN; LE, 2019) introduziram novas abordagens para o design de redes neurais, priorizando a eficiência computacional e a facilidade de treinamento, sem sacrificar a precisão.
As Redes Neurais Convolucionais (CNNs) se baseiam no funcionamento do córtex visual humano, reproduzindo sua capacidade de processar e entender informações visuais.
As CNNs utilizam camadas convolucionais para extrair características locais das imagens, o que as torna altamente eficazes para tarefas de classificação de imagens (GOODFELLOW; BENGIO; COURVILLE, 2016). Essas camadas são responsáveis por aplicar filtros que capturam padrões específicos nas imagens, como bordas e texturas, que são essenciais para a identificação de objetos.
Uma Rede Neural Convolucional (ConvNet / Convolutional Neural Network / CNN) é um algoritmo de Aprendizado Profundo que pode captar uma imagem de entrada, atribuir importância (pesos e vieses que podem ser aprendidos) a vários aspectos / objetos da imagem e ser capaz de diferenciar um do outro (DEEP LEARNING BOOK, 2022).
2.4 VGGNet
A VGGNet, criada por Simonyan e Zisserman em 2015, era mais simples que a AlexNet, usando apenas filtros 3×3 em suas camadas convolucionais. “Com suas 16 a 19 camadas, a VGGNet ficou muito mais precisa para classificar imagens” (SIMONYAN; ZISSERMAN, 2015). A VGG16 é conhecida pela sua simplicidade e profundidade, mas tem um problema: precisa de mais recursos computacionais para funcionar e usa mais memória.
2.4.2 Inception (GoogLeNet)
A Inception, ou GoogLeNet, foi uma grande inovação porque usava “módulos Inception” que combinavam convoluções de diferentes tamanhos. “A Inception precisava de menos parâmetros, mas classificava imagens com a mesma precisão, ou até melhor” (SZEGEDY et al., 2015). Isso a tornava mais eficiente que as arquiteturas anteriores.
A primeira versão do Inception, usou uma combinação de diferentes filtros para analisar imagens, que foi aprimorada na InceptionV2, usando técnicas que aceleraram o treinamento e melhoraram o desempenho. Na InceptionV3, filtros especiais e técnicas avançadas foram utilizados para tornar o modelo mais rápido e preciso.
2.4.3 ResNet
Desenvolvida por He et al., (2016), resolveu um problema chamado “desvanecimento do gradiente” que acontecia em redes muito profundas. O “desvanecimento” acontece quando os gradientes, que são valores que servem para ajustar e melhorar o desempenho durante o treinamento de rede neural, ficavam muito pequenos, tornando difícil o ajuste dos pesos e prejudicando o treinamento. “Com as redes residuais, a ResNet pôde ter mais de 100 camadas e ainda ser muito precisa para classificar imagens” (HE et al., 2016). O “50” refere-se ao número de camadas de rede.
Isso a tornou uma das arquiteturas mais importantes da área de visão computacional.
2.5 Fine-Tuning
De acordo com Goodfellow, Bengio e Courville (2016), o fine-tuning consiste em ajustar modelos previamente treinados em grande conjunto de dados (ImageNet) para que eles se adaptem melhor a novas tarefas, permitindo que as redes se ajustem às especificidades do novo conjunto de dados e melhorem a precisão na tarefa e classificação.
Modelos como VGGNet, Inception e ResNet são treinados inicialmente em conjuntos e dados grandes, como o ImageNet, eles adquirem a capacidade de distinguir características comuns das imagens. No entanto, para que o modelo possa se especializar nas novas classes de imagem, as camadas finais do modelo devem ser ajustadas ao adaptá-los para os conjuntos de dados menores e mais precisos, como o CIFAR-10.
A precisão do modelo na nova tarefa é significativamente melhorada por esse processo de ajuste, que aproveita o conhecimento adquirido durante o treinamento inicial, mas adapta-o ao novo ambiente.
2.6 CIFAR-10
O CIFAR-10 (Canadian Institute For Advanced Research) é um conjunto de dados de imagens que são usados para treinar algoritmos de aprendizado de máquina e visão computacional. Consiste em 60.000 imagens coloridas de 32×32 pixels, divididas em 10 classes: Avião; Carro; Pássaro; Gato; Cervo; Cachorro; Sapo; Cavalo; Navio e Caminhão.
O conjunto de dados é dividido em 50.000 imagens de treinamento e 10.000 imagens de teste. As imagens de treinamento são divididas ainda em cinco lotes de 10.000 imagens cada. (KRIZHEVSKY; NAIR; HINTON, 2009). Ele é um dos conjuntos de dados mais amplamente utilizados para pesquisa em aprendizado de máquina.
2.7 Google Colab
O Colab é um serviço do Jupyter Notebook hospedado, que é uma aplicação web que permite criar e compartilhar documentos interativos com código executável, visualizações e texto descritivo, que não requer configuração para uso e oferece acesso sem custo financeiro a recursos de computação, incluindo Graphics Processing Unit (GPUs) e Tensor Processing Unit (TPUs), que basicamente são aceleradores de hardware. Ele é adequado principalmente para aprendizado de máquina, ciência de dados e educação. (GOOGLE, 2020).
Geralmente utilizando a linguagem de programação Python, o Google Colaboratory, ou Colab, permite a execução e criação de códigos sem a necessidade de instalação de softwares adicionais. Ele oferece acesso gratuito a unidades de processamento, como GPUs, o que facilita o uso em tarefas que exigem computação intensiva, como o treinamento de modelos de aprendizado de máquina.
Além disso, o Colab facilita a integração com o Google Drive, permitindo que os usuários salvem e compartilhem seus notebooks na nuvem. Uma das vantagens do Colab é que permite que vários usuários trabalhem juntos em um mesmo notebook.
O ambiente já vem pré-configurado com bibliotecas Python populares, eliminando a necessidade de instalar e configurar pacotes adicionais. Mas a execução do código é limitada a um tempo máximo de uso constante, e as máquinas virtuais usadas são temporárias.
2.8 Python e Bibliotecas
A aplicação foi desenvolvida em Python, uma linguagem popular, principalmente por possuir uma gama de bibliotecas essenciais para uso de aprendizado de máquina e redes neurais.
Guido van Rossum criou a linguagem no Instituto Nacional de Pesquisa para Matemática e Ciência da Computação na Holanda (CWI) em 1990. Ele inicialmente se concentrava em usuários como físicos e engenheiros. O Python derivava do ABC, outra linguagem existente na época. (BORGES, 2014).
O objetivo era de desenvolver uma linguagem de programação compreensível. Ao longo dos anos, o Python ganhou respeito e popularidade graças à sua facilidade de uso e natureza prática.
Segundo Menezes (2010), a linguagem de programação Python é fascinante devido à sua simplicidade e clareza. Embora seja simples, também é uma linguagem poderosa que pode ser usada para gerenciar sistemas e desenvolver projetos de grande porte. É uma linguagem objetiva e fácil de entender, pois vai direto ao ponto, além de ser software livre, ou seja, gratuito para uso.
Uma de suas grandes vantagens, é sua tipagem dinâmica, ou seja, não é necessário declarar o tipo da variável quando a cria. Por exemplo, x = 5 para um inteiro ou x = “olá” para string, e o Python ajusta o tipo da variável automaticamente.
Devido a rápida expansão da comunidade Python, uma ampla gama de bibliotecas e frameworks foram criadas para uma variedade de tarefas, contribuindo para o avanço do aprendizado de máquina.
2.8.1 TensorFlow
É uma biblioteca de código aberto criada pelo Google, mais especificamente pela equipe Google Brain em 2015, é amplamente utilizada em aplicações de machine learning (aprendizado de máquina). Ele permite a criação e treinamento de modelos complexos, como redes neurais, para identificação de padrões em grandes conjuntos de dados.
O TensorFlow facilita a criação de modelos de Machine Learning (ML) que podem ser executados em qualquer ambiente, oferecendo diversos níveis de abstração que se adapta às necessidades do projeto. Possibilita um caminho direto para a produção, tanto em servidores quanto em dispositivo de borda ou a web, permitindo treinar e implantar modelos de maneira simplificada, independentemente da linguagem ou da plataforma utilizada. (TENSORFLOW, 2024).
Ele não afeta o desempenho ou a velocidade do treinamento de modelos complexos. Com recursos como Application Programming Interface (APIs) de função Keras e APIs de camadas de modelo, permite a criação de topologias complexas e oferece controle e flexibilidade. A prototipagem e a depuração são facilitadas pelo uso rápido do TensorFlow. (TENSORFLOW, 2024).
A API Keras é uma interface sofisticada que permite construir e treinar redes neurais de forma simples e fácil de entender. Os comandos simples que ela fornece facilitam a criação de modelos de aprendizado de máquina. Integrada ao TensorFlow, facilita a definição, compilação e treinamento de redes neurais de maneira mais simples e fácil.
3 DESENVOLVIMENTO
Para comparar a eficácia das redes neurais, foi utilizado a base de dados pública, CIFAR-10, que contém milhares de imagens de algumas categorias, com a ferramenta Google Colab.
A comparação das redes neurais foi iniciada com a importação das bibliotecas, módulos e funções necessárias.
Primeiramente é feita a importação da biblioteca TensorFlow, uma biblioteca de código aberto desenvolvida pela Google para machine learning, que permite construir e treinar os modelos de redes neurais convolucionais (CNNs). A importação do conjunto de dados CIFAR-10 é feita em seguida, utilizando classes e funções específicas do Keras, uma API de alto nível para construir e treinar modelos em TensorFlow.
Os três modelos pré-treinados de CNNs são importados (VGG16, ResNet50 e InceptionV3).
Duas camadas essenciais foram importadas: a Dense, que conecta totalmente os neurônios para a classificação final, e a GlobalAveragePooling2D, que reduz as dimensões da imagem para um vetor ao calcular a média global dos mapas de ativação, ajudando a evitar o ajuste excessivo e a reduzir o número de parâmetros.
Assim como a importação da classe Model, que define modelos de rede neural no Keras e a to_categorical que transforma números de classe em um formato binário, onde cada classe é representada por um vetor que indica se a classe está presente ou não. Isso é útil para tarefas de classificação onde precisamos representar cada rótulo de forma clara e separada.
Conforme a Figura 1.
Figura 1 – Importação das bibliotecas necessárias
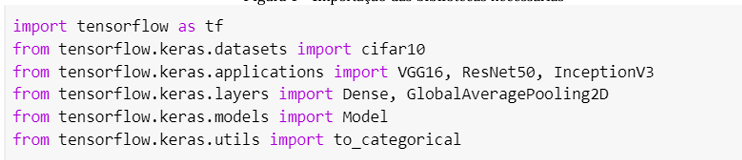
Fonte: Própria, 2024.
Após as importações, a função cifar10.load_data(), carrega o conjunto de dados CIFAR-10 e divide-o em conjuntos de treinamento e teste. O train_images e o test_images são as imagens de treinamento e teste, respectivamente, enquanto train_labels e test_labels são os rótulos correspondentes. Conforme a Figura 2.
Figura 2 – Dados CIFAR-10 sendo carregados

Fonte: Própria, 2024.
Na sequência as imagens são normalizadas dividindo por 255, escala os valores dos pixels de 0-255 para 0-1. Isso ajuda a uniformizar os dados e melhora a eficiência do treinamento do modelo. É uma prática comum em aprendizado de máquina para melhorar o desempenho dos algoritmos. Conforme a Figura 3.
Figura 3 – Normalização das Imagens

Fonte: Própria, 2024.
Com as imagens normalizadas, a função to_categorical converte rótulos de classe inteiros em vetores binários de uma só coluna (one-hot encoding). O train_labels e test_labels são transformados em vetores de 10 elementos, onde a posição do valor 1 indica a classe correta para cada rótulo, e 0 para as demais classes. Foi utilizado o número 10, pois é o número de classes contidas no CIFAR-10. Conforme a Figura 4.
Figura 4 – Conversão de Rótulos

Fonte: Própria, 2024.
As imagens foram ajustadas, foi definido a função create_model que recebe um modelo base pré-treinado (VGG16, ResNet50 ou InceptionV3) como entrada e retorna um novo modelo adaptado. Conforme a Figura 5.
Figura 5 – Função para Criar modelo

Fonte: Própria, 2024.
Para evitar ajustes excessivos, foi utilizado o GlobalAveragePooling2D que reduz as dimensões espaciais da imagem.
O x = Dense (512, activation=’relu’)(x) adiciona uma camada ao modelo com 512 neurônios, onde cada neurônio combina as entradas da camada anterior e usa a função ReLU para ativar apenas as entradas positivas, ajudando o modelo a aprender padrões complexos. Depois, predictions = Dense(10, activation=’softmax’)(x) adiciona a camada final com 10 neurônios, um para cada classe do CIFAR-10. A função Softmax transforma as saídas dessa camada em probabilidades, indicando a chance de cada entrada pertencer a uma das 10 classes, com a soma total das probabilidades igual a 1. Conforme a Figura 6.
Figura 6 – Funções contidas no Modelo

Fonte: Própria, 2024.
As camadas do modelo estão ajustadas, o modelo final foi criado, conectando a entrada do modelo pré-treinado com a camada de saída. Criando um novo modelo que usa a estrutura do modelo base para extrair características das imagens e depois passa essas características pelas novas camadas que adicionamos para gerar previsões.
O método model.compile() prepara o modelo para ser treinado, então o otimizador Adam ajusta os pesos do modelo para minimizar os erros, ajudando-o a aprender de forma eficiente. A função de perda categorical cross entropy calcula o quão incorretas são as previsões em comparação com as respostas corretas, ajudando a guiar o modelo para melhorar. A métrica accuracy mede a porcentagem de previsões corretas feitas pelo modelo, mostrando como ele está se saindo. Juntas, essas configurações garantem que o modelo aprenda e avalie seu desempenho de maneira eficaz. Conforme a Figura 7.
Figura 7 – Função para criar e compilar o modelo completa

Fonte: Própria, 2024.
Foi criado e compilado três modelos diferentes usando as arquiteturas VGG16, ResNet50 e InceptionV3. Estes modelos foram carregados com pesos pré-treinados da ImageNet, mas sem as camadas finais (include_top=False), pois estamos adicionando nossas próprias camadas de saída. Conforme a Figura 8.
Figura 8 – Três modelos criados e compilados

Fonte: Própria, 2024.
Foi utilizado modelos pré-treinados, pois a necessidade de processamento seria consideravelmente elevada para treinar os modelos a partir do zero com o CIFAR-10.
Após a execução, foi identificado um erro no modelo InceptionV3, que requer um tamanho mínimo de entrada de 75×75 pixels, mas o CIFAR-10 contém imagens de 32×32 pixels. Foi realizado um ajuste no código com a importação da função resize, disponível no TensorFlow, para redimensionar as imagens. Conforme as Figuras 9 e 10.
Figura 9 – Importação da Resize

Fonte: Própria, 2024.
Figura 10 – Ajuste no modelo InceptionV3

Fonte: Própria, 2024.
Após o ajuste, foi implementado o congelamento das camadas, para manter o conhecimento que esses modelos pré-treinados já têm. Isso foi feito devido à falta de recursos computacionais robustos, então foi aproveitado o conhecimento que o modelo adquiriu quando foi treinado em um grande conjunto de dados.
Esses modelos foram adaptados ao teste, ajustando às especificidades e melhorando a precisão na tarefa e classificação. Conforme a Figura 11.
Figura 11 – Congelando as camadas base
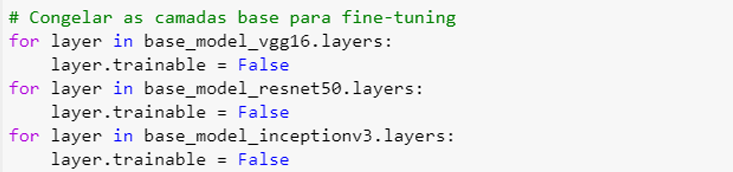
Fonte: Própria, 2024.
O base_model_vgg16.layers obtém todas as camadas do modelo, enquanto o loop for layer itera sobre cada camada e o layer.trainabe como false, é para manter ele congelado. O mesmo processo foi repetido pros demais modelos.
O próximo passo foi o treinamento e a avaliação de cada um dos modelos, utilizando o conjunto de dados CIFAR-10. Esta etapa foi crucial para verificar a eficácia de cada arquitetura e sua capacidade de generalização para novos dados. Conforme a Figura 12.
Figura 12 – Treinamento dos Modelos

Fonte: Própria, 2024.
O treinamento dos modelos foi realizado usando o método fit(), que ajusta os parâmetros do modelo para minimizar a função de perda definida. Cada modelo foi treinado por 10 épocas, ou seja, ajustando seus parâmetros com bases nos erros cometidos na iteração anterior, melhorando sua capacidade de prever corretamente os resultados.
Em history as informações sobre o processo de treinamento do modelo foram armazenadas e o processo se repetiu para o VGG16 e ResNet50, enquanto o InceptionV3 que requer imagens redimensionadas é treinado da mesma forma, porém com as imagens ajustadas para o tamanho adequado.
Foi garantido o treinamento apropriado para os modelos.
O passo seguinte foi avaliar seu desempenho em um conjunto de teste independente para verificar a eficácia na classificação de novas imagens. A avaliação foi realizada com o método evaluate(). Conforme a Figura 13.
Figura 13 – Avaliação dos Modelos

Fonte: Própria, 2024.
O modelo VGG16 foi avaliado usando as imagens de teste normalizados. A função retorna a perda (test_loss_vgg16) que informa sobre a magnitude do erro, e a precisão (test_acc_vgg16) que fornece uma métrica intuitiva de acurácia no conjunto de teste. O processo se repetiu para os demais modelos.
Foi possível entender a eficácia do modelo na comparação entre diferentes modelos.
4 RESULTADOS
Foram avaliadas três arquiteturas de redes neurais convolucionais para classificação de imagens do conjunto de dados CIFAR-10: VGG16, ResNet50 e InceptionV3. Cada modelo foi treinado e avaliado de acordo com sua capacidade de generalização e precisão em um conjunto de teste.
1.VGG16
O modelo VGG16 foi treinado por 10 épocas e demonstrou uma melhora constante em sua precisão ao longo do treinamento. A precisão no conjunto de treinamento começou em 48.26% e aumentou para 73.49% até a última época e sua perda começou em 1.4726 e caiu para 0.7499. No conjunto de validação, a precisão variou de 56.26% a 62.15%, e sua perda começou em 1.2295 e subiu para 1.1433. Indicando uma boa capacidade de generalização.
Conforme ilustrado no gráfico das Figuras 14 e 15.
Figura 14 – Acurácia do Modelo VGG16
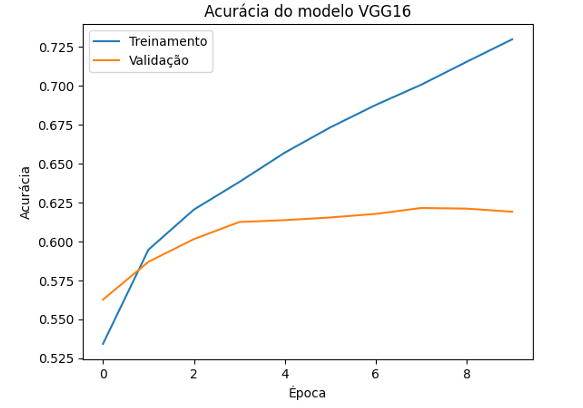
Fonte: Própria, 2024.
O eixo y, mostra a acurácia do modelo em porcentagem e o eixo y, o número da época de treinamento. A acurácia de treinamento aumenta consistentemente, indicando que o modelo está aprendendo bem a partir de dados.
A acurácia de validação mostra um aumento gradual, com flutuações, sugerindo que o modelo está se ajustando bem à validação.
Figura 15 – Perda do Modelo VGG16
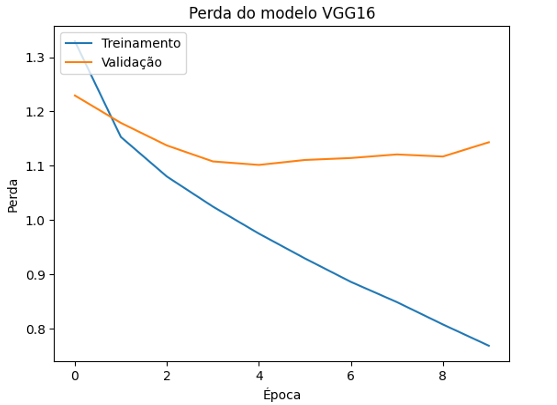
Fonte: Própria, 2024.
O eixo y mostra a perda do modelo, e o eixo x mostra a época de treinamento. A perda de treinamento diminui consistentemente, indicando que o modelo está ajustando os pesos corretamente para minimizar a perda de dados de treinamento.
Já a validação também diminui inicialmente, mas depois começa a aumentar, esse aumento pode indicar que o modelo está começando a sobreajustar (overfitting) aos dados de treinamento e não generaliza tão bem para os dados de validação.
A VGG16 apresentou um desempenho consistente tanto em treinamento quanto em validação, sugerindo uma boa capacidade de generalização e um ajuste eficaz durante o treinamento. Porém, mostrou sinais de overfitting, indicando que o modelo aprendeu muitos detalhes do treinamento e pode não generalizar tão bem para dados de validação.
2.ResNet50
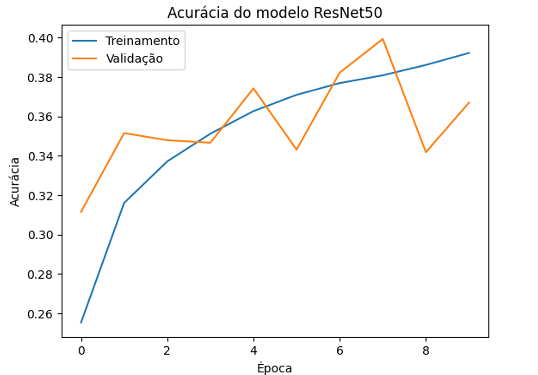
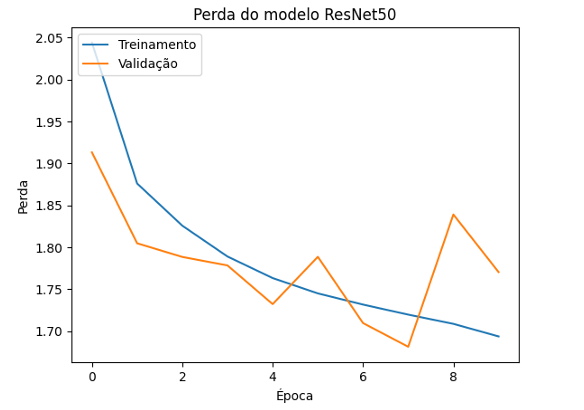
O modelo ResNet50, que utiliza blocos residuais para amenizar o problema de degradação em redes profundas, apresentou uma precisão inicial de 21.53%, com uma melhoria gradual durante o treinamento e sua perda começou em 2.1994 e caiu para 1.7011. Enquanto sua acurácia de validação começou em 31,15%, aumentou para 36.70%, e sua perda de validação começou em 1.9131 e foi para 1.7704. No entanto, o modelo atingiu uma precisão de treinamento final de apenas 38.62%, com uma precisão de validação que variou de 31.15% a 39.93%. Conforme ilustra os gráficos das figuras 16 e 17.
Figura 16 – Acurácia do Modelo ResNet50
Fonte: Própria, 2024.
O eixo y mostra a acurácia do modelo em porcentagem e o eixo x mostra o número de época de treinamento. A acurácia de treinamento começa em 21.53% e aumenta lentamente até 38.62%, indicando que o modelo está aprendendo, mas de maneira bem lenta, sugerindo que pode estar tendo dificuldades para aprender padrões eficazes nos dados de treinamento.
Já a acurácia de validação começa em 31.15% e sobe lentamente para 36.70%, com um padrão de melhoria ainda mais gradual e irregular, indicando que o modelo não está generalizando bem para dados de validação e que a diferença entre acurácia de treinamento e validação é pequena, o modelo não está aprendendo os padrões.
Figura 17 – Perda do Modelo ResNet50
Fonte: Própria, 2024.
O eixo y mostra a perda do modelo e o eixo x mostra o número da época de treinamento. A perda de treinamento começa em 2.1994 e diminui gradualmente para 1.7011, indicando que o modelo está ajustando seus parâmetros para reduzir o erro nos dados de treinamento, mas a taxa de redução é menor comparado a outros modelos, sugerindo que ele está lutando para aprender de maneira eficaz.
Já a perda de validação, começa em 1.9131 e diminui lentamente para 1.7704, embora haja diminuição na perda, ela é modesta e a perda permanece alta, indicando que o modelo tem dificuldades para generalizar para dados de validação. Isso também sugere que a capacidade em aprender padrões gerais a partir dos dados é limitada.
O ResNet50 demonstrou um desempenho inferior e dificuldades notáveis tanto no treinamento quanto na validação. Esse desempenho pode indicar que o modelo está subajustado para o conjunto de dados CIFAR-10 ou que ajustes adicionais na arquitetura ou treinamento são necessários.
3.InceptionV3
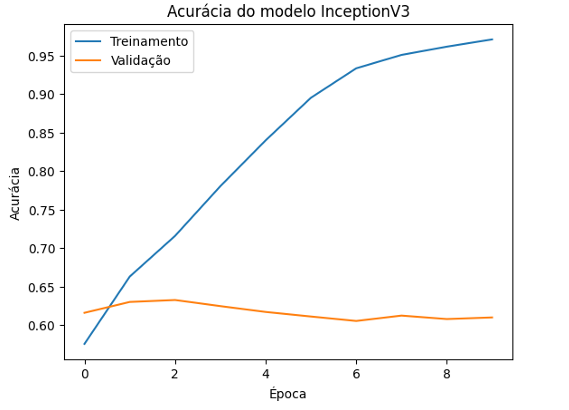
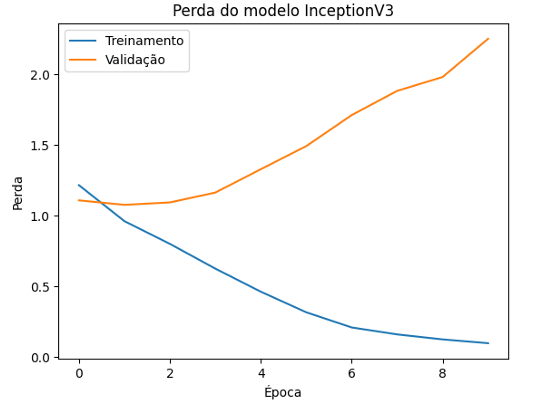
O modelo InceptionV3, conhecido por sua arquitetura inovadora com múltiplos tipos de filtros e blocos de Inception, iniciou com uma precisão de 52.71% e melhorou significativamente, alcançando uma precisão de treinamento final de 97.84%, sua perda começou em 1.3694 e diminuiu para 0.0771. Enquanto sua validação começou em 61.59% e subiu lentamente para 60.99%, sua perda começa em 1.1083 e aumenta para 2.2524.
Conforme ilustra os gráficos das figuras 18 e 19.
Figura 18 – Acurácia do modelo InceptionV3
Fonte: Própria, 2024.
O eixo y mostra a acurácia do modelo em porcentagem e o eixo x mostra o número de época de treinamento. A acurácia de treinamento começa em 52.71% e aumenta rapidamente para 97.84%, indicando que o modelo está aprendendo muito bem os dados de treinamento, apresentando uma melhoria significativa ao longo das épocas.
Enquanto a acurácia de validação, começa em 61.59% e o sobe lentamente para 60.99%, apresentando um aumento inicial, mas depois estabilizando e até diminuindo ligeiramente. Sugerindo que, embora o modelo esteja se ajustando bem aos dados de treinamento, sua capacidade de generalização para novos dados é limitada.
Figura 19 – Perda do modelo InceptionV3
Fonte: Própria, 2024.
O eixo y mostra a perda do modelo e o eixo x mostra o número de época de treinamento. A perda de treinamento começa em 1.3694 e diminui rapidamente para 0.0771, indicando que o modelo está ajustando seus parâmetros de forma eficaz para diminuir os erros nos dados de treinamento.
Enquanto a perda de validação começa em 1.1083 e aumenta para 2.2524, sugerindo que o modelo está se adaptando demais aos dados e pode começar a perder a capacidade de generalizar.
O InceptionV3 demonstrou uma performance excepcional em dados de treinamento, mas enfrentou problemas em termos de generalização, com um aumento de perda de validação ao longo das épocas.
Comparando os três modelos, o VGG16 demonstrou um bom equilíbrio entre precisão de treinamento e validação, com um desempenho consistente e uma precisão de teste de 61.67%. É uma escolha sólida para o CIFAR-10, com uma boa capacidade de generalização.
Já o ResNet50, teve o desempenho mais baixo entre os modelos avaliados, com uma precisão final de validação de apenas 36.70% e uma precisão de teste de 36.53%. Isso indicou que o conjunto de dados CIFAR-10 não é a mais indicada a essa arquitetura ou que ele necessitaria de uma quantidade bem maior de ajustes, processos de treinamentos e dados, o que consequentemente exigirá mais tempo e capacidade computacional maior.
Enquanto o InceptionV3, apesar de ter alcançado uma alta precisão de treinamento (97.84%), a precisão de validação e teste foi semelhante à do VGG16, com 60.99% e 60.72%, respectivamente. Isso sugere que embora o modelo aprenda muito bem o treinamento, ele sofre um pouco com o sobreajuste de dados.
Essa comparação é ilustrada conforme a figura 20.
Figura 20 – Acurácia dos três modelos
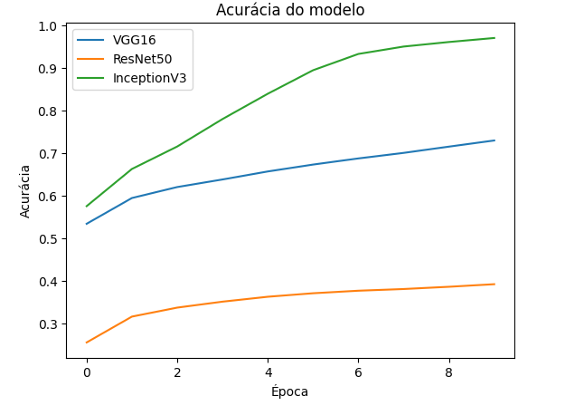
Fonte: Própria, 2024.
5 CONCLUSÃO
A partir do objetivo proposto conclui-se que o modelo VGG16 equilibrou melhor a precisão e a capacidade de generalização entre os modelos avaliados, tornando-se uma opção confiável para o conjunto de dados CIFAR-10. Embora tenha demonstrado alta precisão durante o treinamento, o InceptionV3 mostrou sinais de sobreajuste, indicando que precisa de ajustes adicionais para melhorar sua capacidade de generalização.
Por outro lado, o ResNet50 apresentou desempenho inferior. Isso pode ser atribuído à sua arquitetura complexa, que exige ajustes mais precisos para o CIFAR-10.
Essas descobertas reforçam a hipótese de que várias arquiteturas de CNN têm características que as tornam mais ou menos adequadas para situações específicas. A VGG16 demonstrou ser eficaz devido à sua simplicidade e profundidade, mas com um alto custo de recursos computacionais.
O InceptionV3, conhecido por sua eficiência, mostrou-se promissor; no entanto, para evitar o sobreajuste, são necessárias melhorias. Ao mesmo tempo, o ResNet50, que resolve o problema de desvanecimento do gradiente em redes profundas, teve problemas para se ajustar ao conjunto de dados usado. Indicando que as arquiteturas residuais podem não ser a melhor opção para tarefas com imagens de baixa resolução.
As principais implicações deste estudo estão na escolha de arquiteturas CNN que equilibrem eficiência e generalização, sendo o VGG16 e o InceptionV3 opções promissoras, inclusive para sistemas com restrições computacionais. Por outro lado, o ResNet50 se mostrou mais adequado para cenários que envolvem maior capacidade de processamento de dados de maior complexidade.
O uso de técnicas de regularização e ajustes mais refinados nas camadas das redes Inception e ResNet, comparação com conjuntos de dados mais desafiadores e a investigação de outras arquiteturas emergentes, como a EfficientNet, que priorizam a eficiência computacional, são sugestões para pesquisas futuras.
REFERÊNCIAS BIBLIOGRÁFICAS
BISHOP, C. Pattern Recognition and Machine Learning. Springer New York. 2016. p. 23680.
BORGES, E. L. Python para Desenvolvedores: Aborda Python 3.3. Novatec. 2014. p.15
DATA SCIENCE ACADEMY. Deep Learning Book. [S.I]: DAS, 2012. Disponível em: https://www.deeplearningbook.com.br/introducao-as-redes-neuraisconvolucionais/#:~:text=Definição,de%20diferenciar%20um%20do%20outro. Acesso em: 29 mai. 2024.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. The Mit Press. 2016.
GOOGLE. Google Colaboratory. 2020. Disponível em: https://colab.google/. Acesso em: 05 set. 2024.
HE, K.; ZHANG, X.; REN, S.; SUN, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. 770778p.
HUANG, G.; LIU, Z.; VAN DER MAATEN, L.; WEINBERGER, K. Q. Densely connected convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. pp. 4700-4708. Disponível em: https://openaccess.thecvf.com/content_cvpr_2017/html/Huang_Densely_Connected_Convolu tional_CVPR_2017_paper.html. Acesso em: 04 set 2024.
KANDEL, Eric R.; JESSELL, Thomas M.; SCHWARTZ, James H.; SIEGELBAUM, Steven A.; HUDSPETH, A. J. Princípios de Neurociências. 5. ed. AMGH, 2014.
KRIZHEVSKY, A.; SUTSKEVER, I.; HINTON, G. E. ImageNet Classification with Deep Convolutional Neural Networks. In: Advances in neural information processing systems (NeurIPS), 2012. Disponível em: https://papers.nips.cc/paper/4824-imagenet-classificationwith-deep-convolutional-neural-networks.pdf. Acesso em: 29 maio 2024.
KRIZHEVSKY, A.; SUTSKEVER, I.; HINTON, G. E. Classification with deep convolutional neural networks. In Advances in neural information processing systems. ImageNet. 2012. 1097-1105p.
KRIZHEVSKY, A.; NAIR, V.; HINTON, G. CIFAR-10. Canadian Institute For Advanced Research-CIFAR. 2009. Disponível em: https://www.cs.toronto.edu/~kriz/cifar.html. Acesso em: 03 jun. 2024.
KRIZHEVSKY, A.; NAIR, V.; HINTON, G. Learning Multiple Layers of Features from Tiny Images. 2009. Disponível em: https://www.cs.toronto.edu/~kriz/learning-features-2009TR.pdf. Acesso em: 03 jun. 2024.
LECUN, Y.; BOTTOU, L.; BENGIO, Y.; HAFFNER, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE. v. 86, n. 11, p. 2278-2324, 1998.
MENEZES, C. N. N. Introdução a programação com Python: Algoritmos e lógica de programação para iniciantes. Novatec. 2010. p.21.
NORVIG, P.; RUSSELL, S. Inteligência Artificial 3 ed. Elsevier 2013.
SCHMIDHUBER, J. Deep Learning in Neural Networks: An Overview. Neural Networks, v. 61, p. 85-117, 2015. DOI: 10.1016/j.neunet.2014.09.003.
SIMONYAN, K.; ZISSERMAN, A. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations (ICLR). 2015.
SZEGEDY, C.; LIU, W.; JIA, Y.; SERMANET, P.; REED, S.; ANGUELOV, D.;
RABINOVICH, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2015. 1-9p.
SZELISKI, R. Computer Vision: Algorithms and Applications. 11. ed. Springer. 2010. Disponível em: https://www.amazon.com/Computer-Vision-Algorithms-ApplicationsScience/dp/1848829345. Acesso em: 02 jun. 2024.
TAN, M.; LE, Q. V. EfficientNet: Rethinking model scaling for convolutional neural networks. Proceedings of the 36th International Conference on Machine Learning (ICML). 2019. 6105-6114. DOI: 10.48550/arXiv.1905.11946. Disponível em: https://arxiv.org/abs/190 5.11946. Acesso em: 04 set. 2024.
TENSORFLOW. Documentação oficial TensorFlow: Aprendizado de máquina de alta escalabilidade em sistemas heterogêneos distribuídos. 2015. Disponível em: https://www.tensorflow.org/about/bib?hl=pt-br#aprendizado-dem%C3%A1quina_de_alta_escalabilidade_em_sistemas_heterog%C3%AAneos_distribu%C3 %ADdos. Acesso em: 05 set. 2024.
TENSORFLOW. About TensorFlow. Disponível em: https://www.tensorflow.org/about?hl=pt-br. Acesso em: 05 set. 2024.
1 Graduando do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. Email: leonardo.lourenco@uniara.edu.br
2 Orientador. Docente Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-
SP. E-mail: jhgborges@uniara.edu.br
3 Coorientador. Docente Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA.
Araraquara-SP. E-mail: fflorian@uniara.edu.br