REGISTRO DOI: 10.5281/zenodo.8076527
João Vitor dos Santos Campos1
Ana Paula Abrantes e Castro Shiguemori2
ABSTRACT
Breast cancer is a disease caused by the disordered growth of abnormal breast cells, which multiply and form tumors. It is one of the most common cancers among women, and also has a high mortality rate in advanced disease cases. For the year 2019 alone, according to a Ministry of Health [2], around 59,700 new cases of this type of cancer were expected in Brazil. This paper aims to compare the performance of the techniques of Random Forest and Deep Learning in cancer prediction.
KEYWORDS: Breast Cancer, Random Forest, Deep Learning, Cancer Prediction, Performance Comparing.
1. INTRODUÇÃO
O câncer de mama é uma doença causada pelo crescimento desordenado de células anormais na mama, as quais se multiplicam e formam tumores. Ele é um dos tipos de câncer mais comuns entre as mulheres, contando também com uma alta taxa de mortalidade em casos de doença avançada. Somente para o ano de 2019, segundo estimativas do Ministério da Saúde [2], eram esperados cerca de 59.700 casos novos deste tipo de câncer no Brasil, com uma taxa de óbito de cerca de 13,68/100 mil mulheres.
Além da promoção de um estilo de vida mais saudável, uma das principais formas de impedir o desenvolvimento e a evolução desta doença é a realização periódica dos exames de mamografia, visto que a detecção do câncer em fases iniciais pode aumentar as possibilidades de cura e de estabelecimento de um tratamento menos agressivo. Neste contexto, ferramentas modernas de predição podem auxiliar na definição de um diagnóstico inicial e, consequentemente, na definição de um tratamento mais efetivo.
Levando em consideração estes aspectos, o presente trabalho busca comparar o desempenho das técnicas de classificação na predição dos casos de câncer de mama. Para isto, foram definidos dois algoritmos que aplicam, respectivamente, as técnicas Random Forest e Deep Learning na predição de casos de câncer utilizando como base de dados informações sobre tumores detectados em mulheres.
2. FERRAMENTAS E MÉTODOS
Devido a necessidade do diagnóstico eficiente de pacientes com câncer de mama, este trabalho propõe como método de obtenção de diagnóstico o uso dos algoritmos Deep Learning e Random Forest. Outrossim, a implementação dessas técnicas se deu através do ambiente Colab, no qual foram utilizadas as bibliotecas descritas no item 2.1 deste artigo.
2.1. Ferramentas
A seção a seguir apresenta as ferramentas utilizadas na implementação dos algoritmos de predição propostos.
2.1.1. Tensorflow
O Tensorflow1 é uma biblioteca de códigoaberto para computação numérica e aprendizado de máquina. De propriedade da Google, ele pode ser apresentado como um sistema para criação de redes neurais que são capazes de detectar e decifrar padrões e correlações, de forma similar ao raciocínio e ao aprendizado humanos. Seu maior benefício é a abstração, visto que coloca em foco a lógica geral da aplicação ao invés do desenvolvedor e detalhes básicos de implementação. Com apoio de diversas APIS, o Tensorflow se torna flexível para utilização em diversos cenários e aplicações.
2.1.2. Keras
O Keras2é uma API de alto nível para utilização em redes neurais complexas, amplamente utilizadas no ambiente Tensorflow. Ele possui uma grande vantagem: tem uma interface otimizada e simples , o que facilita a criação de um modelo de redes neurais profundas. Ademais, esta API conta com vasta documentação e, por estar baseada na linguagem Python, conta com facilidades de aprendizado e manipulação.
2.1.3. Pandas
Desenvolvida desde de 2008, a biblioteca com o código aberto nomeada Pandas3, oferece um ótimo suporte para estruturas de dados e ferramentas para análise dos mesmos. Por meio de estruturação de dados em estruturas unidimensionais e bidimensionais chamadas Data Frames e Series se dá o funcionamento do Pandas; permitindo assim pelas suas estruturas para a realização de comandos para a manipulação dos dados como conversão, transformação, agrupamento, etc. O objetivo do Pandas é tornar a linguagem Python mais atraente tanto para acadêmicos quanto para profissionais que atuam na área de análise de dados.
2.1.4. Sklearn
Com base em outras bibliotecas como Sympy, Pandas, NumPy e outras que complementam este conjunto, a Sklearn 4é uma biblioteca para ser utilizada com Python. A Sklearn apresenta eficiência para análise de dados e mineração. Ela traz um grande número de opções de algoritmos, como regressão e agrupamento, classificação e inclui até mesmo máquinas de vetor de suporte. As implantações dos seus algoritmos são em linguagens de nível inferior, garantindo uma boa performance de hardware.
2.2 Métodos
Para realização deste trabalho foi proposta uma abordagem em três etapas, sendo elas a coleta de dados (2.2.1), o estudo de técnicas c de inteligência computacional (2.2.2 e 2.2.3) e por fim a análise do desempenho das técnicas escolhidas (2.2.4)
2.2.1. Coleta de Dados
Para a realização desse trabalho foram utilizados dados disponibilizados pela plataforma Kaggle5. A plataforma de propriedade da Google caracteriza-se por ser uma comunidade online de cientistas de dados e aprendizes, na qual é possível que sejam encontrados uma grande quantidade de ótimo suporte para estruturas de dados e datasets6sobre os mais variados assuntos, além de competições, discussões e cursos naárea de ciência de dados.
O dataset utilizado no contexto desse projeto apresenta dados calculados a partir de imagens digitalizadas de massas mamárias. Os quais descrevem características dos núcleos celulares presentes nas imagens.
2.2.2. Deep Learning
O Deep Learning é um sub-ramo do “Machine Learning” que objetiva o aprendizado de máquina por meio da configuração de parâmetros, que são adaptados em um treinamento com várias camadas de processamento. Neste contexto, o Deep Learning utiliza algoritmos, estruturas de dados e, principalmente, Redes Neurais para treinar a máquina na interpretação e futura solução de problemas.
Diferentemente do Machine Learning, o Deep Learning busca trabalhar com um número menor de variáveis, o que aumenta a assertividade na busca por resultados esperados. Por isso, de forma ampla, o Deep Learning utiliza as chamadas redes neurais de arquitetura Feed-Forward, que se baseiam na retropropagação, para adaptar pesos e parâmetros capazes de solucionar o problema em questão. Por se basear em um número restrito de variáveis, a aplicação desta técnica depende, para a obtenção de um bom resultado, da seleção de um dataset [1] de qualidade. Desta forma, os dados devem ser íntegros, normalizados e suficientes para todas as etapas do treinamento da Rede Neural.
Em virtude das vantagens da utilização da técnica de Deep Learning, para a realização deste trabalho foi selecionada a aplicação de um algoritmo de Rede Neural Feed-Foward. Este algoritmo configura uma rede com a arquitetura de três camadas com 64, 32 e 1 neurônios respectivamente. A função de ativação selecionada é a Sigmóide e o algoritmo para adaptação dos pesos é o algoritmo Adam.
2.2.3. Random Forest
O algoritmo Random Forest é um método classificador composto por um conjunto de árvores de decisão. Cada árvore desse conjunto indica uma decisão sobre a classe a qual o objeto de entrada pertence, dessa forma, a classe com o maior número de indicações é tida como a saída do algoritmo.
Figura 1: Criação de uma árvore de decisão [5]
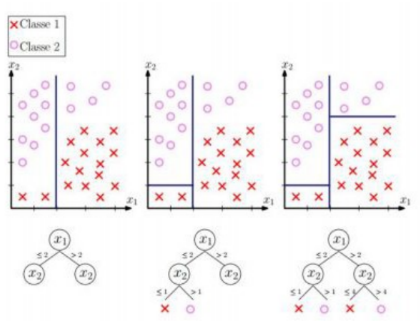
Na figura 1 é possível se observar que o método de utilização de árvores é em suma uma maneira de se separar superfícies de decisão, nesse caso, o número de dimensões é o mesmo do de parâmetros de entrada do classificador.
2.2.4. Análise de Desempenho
Com o fito de comparação do desempenho das técnica de Random Forest e Deep Learning foram escolhidas duas métricas, sendo elas a Curva ROC (Receiver Operating Characteristic)7 e o MAPE (Mean Absolute Percentage Error)8.
2.2.4.1. Curva ROC
A Curva ROC é um método gráfico para avaliação de processos de predição. Esta técnica é amplamente utilizada no campo da medicina devido a possibilidade de estudo da variação sensibilidade e especificidade para diferentes amostras.
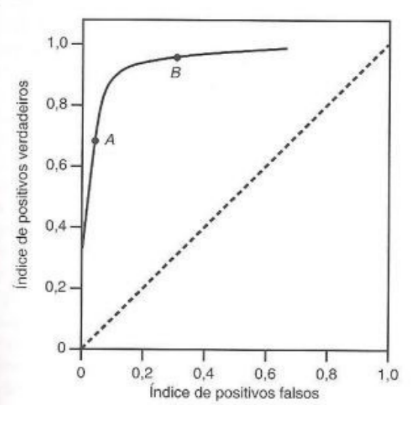
Essa técnica consiste em um gráfico de comparação entre verdadeiros e falsos positivos, como evidenciado na figura 2.
A linha diagonal pontilhada, presente na figura 2, corresponde a um teste entre positivo e negativo. Quanto mais otimizado e próximo do valor esperado, a curva se encontra mais próxima ao campo superior esquerdo do diagrama. Para este modelo, os valores positivos verdadeiros (corretos) se encontram próximos de 1, enquanto os valores falsos positivos são próximos de zero.
Neste contexto, a curva ROC é um bom modelo para análise de classificação, visto que é capaz de distinguir entre duas saídas. Estas, por sua vez, normalmente são representadas pelos valores binários (1 e 0).
Figura 2: Exemplificação de Curva ROC [10]
2.2.4.2. MAPE
O Erro Percentual Absoluto Médio (da sigla em inglês MAPE), é um método de medida da precisão de uma análise estatística. Esta precisão, no ramo do Machine Learning, é utilizada para medir a acurácia de um algoritmo na solução de um problema.
O MAPE é calculado pela seguinte fórmula:
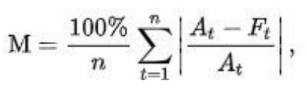
onde At é o valor obtido e Ft é o valor esperado. A diferença entre estes valores é dividida pelo valor obtido é um somatório é realizado para todos os conjuntos de saídas obtidas e esperado. Por fim, os valores sofrem um cálculo de porcentagem. Quanto maior a porcentagem final, maior é a acurácia do algoritmo.
3. RESULTADOS OBTIDOS
Nessa seção são descritos os resultados obtidos através da utilização das ferramentas e métodos descritos anteriormente. Para a obtenção dos resultados mostrados a seguir foram implementados, no ambiente Colab, os algoritmos de Deep Learning e Random Forest e, a partir dos resultados obtidos por essas implementações, foram geradas métricas de avaliação de desempenho.
3.1. Fase de implementação
Inicialmente foi implementada a técnica de Deep Learning. Diversas arquiteturas foram testadas para sua construção, no entanto este trabalho utilizou como objeto de análise aquela cuja assertividade fora maior – a acurácia obtida foi de 97,89%.
Posto isso, esta rede foi formada por três camadas, sendo uma a camada inicial, a outra uma camada escondida e a última a camada de saída, possuindo 32, 64 e 1 neurônios respectivamente.
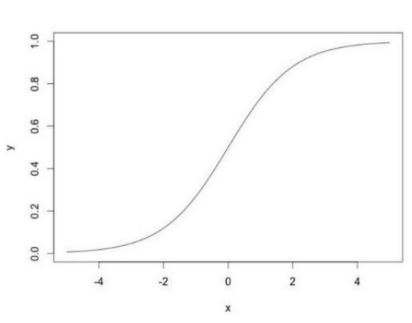
A função de ativação utilizada foi a Sigmóide, que tem como característica a não linearidade, variando de 0 a 1, tendo um formato de S (figura 3). Sua forma é dada pela expressão:
f (x) = 1 / (1 + e ^ -x).
Figura 3: Representação da função Sigmóide [11]
Em seguida, o algoritmo de Random Forest foi implementado. Assim como no caso anterior, diversas arquiteturas foram testadas até que se chegasse à arquitetura utilizada neste estudo. O modelo implementado utiliza uma floresta de 500 árvores, com sequência de critérios – método de medição de pureza dos nós – de entropia. A acurácia obtida por esse modelo foi de 96,49%.
3.2. Métricas de Análise de Desempenho
Para a avaliação do desempenho de ambos os algoritmos foram calculados a curva ROC e o MAPE de cada um. Ambas as métricas foram obtidas através da comparação entre a saída predita pelas técnicas e comparação com a saída esperada.
A curva ROC que mostrou melhor resultado foi a referente a Deep Learning (figura 4), visto a proximidade do valor um desenhado pela linha em amarelo. Este fato se justifica pelo alto valor de assertividade desse algoritmo – 97,89%. A mesma métrica quando referente ao Random Forest obteve uma distância maior do valor ideal (figura 5), fato justificado por sua menor assertividade – 96,49%.
Figura 4: Curva ROC do algoritmo de Deep Learning.
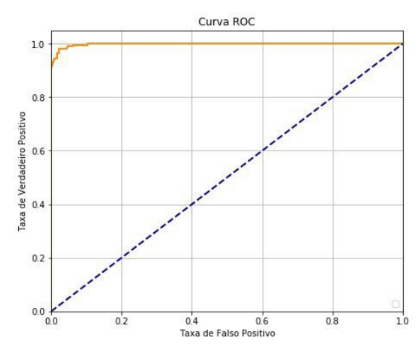
(Fonte: Os autores)
Figura 5: Curva ROC do algoritmo Random Forest.
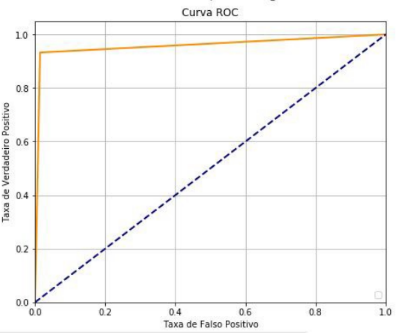
(Fonte: Os autores)
No entanto, quando olhar do estudo é voltado ao percentual de erro os resultados se invertem, mostrando que o algoritmo baseado na solução com árvores obteve menor percentual de erro durante a fase de treinamento (0.035 ou 3.5%) em comparação com a mesma fase da solução de Deep Learning (0.069 ou 6.9%).
CONCLUSÃO
Neste trabalho, as técnicas de Deep Learning e Random Forest foram comparadas segundo a assertividade na predição de casos de câncer de mama. Estes métodos obtiveram precisão similar, sendo que a Rede Neural contou com um desempenho 1,40% superior.
Os resultados obtidos neste trabalho podem ser utilizados na melhoria de ferramentas para a predição do câncer de mama, auxiliando no diagnóstico e consequentemente, tratamento de novos casos.
Em estudos futuros, os parâmetros e pesos da rede neural treinado podem ser aplicados a novos dados, verificando a capacidade de generalização alcançada pelo Deep Learning.
1https://www.tensorflow.org/
2https://keras.io/
3https://pandas.pydata.org/
4https://scikit-learn.org/stable/
5https://www.kaggle.com/
6Conjunto de dados
7Característica de Operação do Receptor
8Média Percentual Absoluta do Erro
REFERÊNCIAS
[1] BREAST Cancer Wisconsin (Diagnostic) Data Set: Predict whether the cancer is benign or malignant. [S. l.], 19 jul. 2016. Disponível em:https://www.kaggle.com/uciml/breast-cancer-wisconsin-data. Acesso em: 30 nov. 2019.
[2] A SITUAÇÃO do câncer de mama no Brasil: Síntese de dados dos sistemas de informação. Rio de Janeiro: Christiane Dieguez, 2019. Disponível em: https://www.inca.gov.br/sites/ufu.sti.inca.local/files/media/document/a_situacao_ca_mama_brasil_2019.pdf. Acesso em: 30 nov. 2019.
[3] RODRIGUES, Fabrício Alves; DO AMARAL, Laurence Rodrigues. Aplicação de Métodos Computacionais de Mineração de Dados na Classificação e Seleção de Oncogenes Medidos por Microarray. Revista brasileira de Cancerologia, [s. l.], 17 maio de 1912. Disponível em: https://rbc.inca.gov.br/site/arquivos/n_58/v02/pdf/14_artigo_aplicacao_metodos_computacionais_mineracao_dados_classificacao_selecao_oncogenes_medidos_microarray.pdf. Acesso em: 28 nov. 2019.
[4] FREITAS, Ana Gabriela da Silva; ResearchGate, [s. l.], 21 dez. 2017. FERREIRA, Pedro Marcio; DA SILVA, Disponível em: Robson Mariano. Redes Neurais na Classificação de Neoplasias Mamárias. CEREUS, [s. l.], 5 mar. 2019. Disponível em: http://ojs.unirg.edu.br/index.php/1/article/view/2685/780. Acesso em: 1 dez. 2019.
[5] LOPEZ, R. Z., Classificação automática de defeitos em máquinas rotativas. projeto final de graduação, Universidade Federal do Rio de Janeiro, Dezembro 2014.
[6] AGOSTINI, Cristiano; BAESSO, João Victor; PUERARI, Rosicler Felippi. ESTUDO DE RECONHECIMENTO FACIAL UTILIZANDO TENSORFLOW. SIEPE, [s. l.], 23 out. 2019. Disponível em: https://portalperiodicos.unoesc.edu.br/siepe/article/view/22861/13281. Acesso em: 1 dez. 2019.
[7] LOPES, Gesiel Rios; TOLEDO, Claudio; DELBEM, Alexandre C. B. Introdução à Análise Exploratória de Dados com Python. ResearchGate, [s. l.], 14 out. 2019. Disponível em: https://www.researchgate.net/profile/Gesiel_L opes/publication/336778766_Introducao_a_A nalise_Exploratoria_de_Dados_com_Python/l inks/5db225d2a6fdccc99d9426f2/Introducao a-Analise-Exploratoria-de-Dados-com-Python .pdf. Acesso em: 1 dez. 2019.
[8] FERNANDES, William Reis; DA SILVA, Rodrigo Cezario. Aprendizagem profunda de máquinas: conceitos, técnicas e bibliotecas. https://www.researchgate.net/profile/William _Fernandes4/publication/324844857_Aprendi zagem_profunda_de_maquinas_conceitos_tecnicas_e_bibliotecas/links/5ae77a8245851588 dd7f86fa/Aprendizagem-profunda-de-maquinas-conceitos-tecnicas-e-bibliotecas.pdf. Acesso em: 29 nov. 2019.
[9] RIBEIRO, Maxwell M.; GUIMARÃES, Samuel S. REDES NEURAIS UTILIZANDO TENSORFLOW E KERAS. Revista Eletrônica Científica de Ciência da Computação , [s. l.], 16 out. 2018. Disponível em: http://revistas.unifenas.br/index.php/RE3C/art icle/view/231/163. Acesso em: 1 dez. 2019.
[10] PRATI, R. C.; BATISTA, G. E. A. P. A.; MONARD, M. C. Curvas ROC para avaliação de classificadores. ICMC- USP, [s. l.], 15 fev. 2017. Disponível em: http://conteudo.icmc.usp.br/pessoas/gbatista/f iles/ieee_la2008.pdf. Acesso em: 1 dez. 2019.
[11] REDES NEURAIS – FUNÇÕES DE ATIVAÇÃO. Laboratório iMobilis Computação Móvel. Disponível em: http://www.decom.ufop.br/imobilis/redes-neurais-funcoes-de-ativacao. Acesso em: 3 dez. 2019.
[12] FUNÇÃO DE ATIVAÇÃO. Deep Learning Book. Disponível em: http://deeplearningbook.com.br/funcao-de-ati vacao/. Acesso em 3 dez. 2019
1Instituto Federal de Educação, Ciência e Tecnologia de São Paulo, Campus Jacareí
j.campos@aluno.ifsp.edu.br
2Instituto Federal de Educação, Ciência e Tecnologia de São Paulo, Campus Jacareí
anapaula.aes@ifsp.edu.br