REGISTRO DOI: 10.5281/zenodo.7308878
William Raulinavixius
Rodrigo J A Salgado
Katelin Ribeiro
Brendha Sales Bazoni
Vinicius Costa
Carlos Noriega
Orientador: Dr. Carlos Noriega
Abstract: In this article, we use IoT (Internet of Things) to demonstrate and describe all the steps and processes of a device that automates the verification of the use of PPE (Personal Protective Equipment) by the employee. The device is structured in three stages: The physical part, which consists of the microcontroller and its algorithm. The local server, which will receive the information sent by the microcontroller and communicate with the online server, sending the processed response to the microcontroller. The cloud server, AutoML Vision, which will identify the elements present in the image and return the response tags according to training.
Keywords: IoT, Automation, Microcontroller, AutoML Vision
1. Introdução
No cenário apresentado nos últimos anos, a pandemia trouxe a conscientização de que prevenção e proteção são elementos fundamentais de segurança. Por tanto, é indispensável que o país tenha uma política estratégica para o setor de Equipamentos de Proteção Individual. (RSDATA,2021)
De acordo com o relatório emitido pela Associação Nacional da Indústria de Material de Segurança e Proteção ao Trabalho (ANIMASEG, 2021), onde são apontados os indicadores do mercado brasileiro de equipamentos de proteção individual, no ano de 2019 a curva de crescimento indica um aumento de 20% em reais e 10% em dólares, com um volume do mercado de aproximadamente R$ 10,3 bilhões e US$ 2,6 bilhões.
O EPI é todo dispositivo ou produto de uso individual pelo trabalhador destinado à proteção contra os riscos no ambiente de trabalho. A norma regulamentadora (NR6) que rege a execução do trabalho com uso de Equipamentos de Proteção Individual (EPI), sem estar condicionada a setores ou atividades econômicas específicas.
Os tipos de EPI’s utilizados podem variar dependendo do tipo de atividade ou de riscos que poderão ameaçar a segurança, a saúde do trabalhador e da parte do corpo que se pretende proteger. As mais comuns entre as funções são: protetores auriculares, máscaras, óculos, capacetes, luvas e botas. (Uanderson, 2017).
De acordo com a ANIMASEG, foi realizado um levantamento que aponta os indicadores de acidentes com relação ao ano de 2019, no qual o Brasil ocupa a 18° posição no ranking internacional de acidentes do trabalho com 1.374 a cada 100.000 trabalhadores, segundo dados da OIT (Organização Internacional do Trabalho). O mesmo levantamento disponibiliza dados sobre os acidentes de trabalho, por situação do registro e motivo (ANIMASEG, 2021), onde as principais causas estão alinhadas com a negligência na utilização do EPI’s.
Por outro lado, a indústria 4.0 denominada como a quarta revolução industrial se caracteriza por seus nove pilares e um deles é a computação em nuvem, que disponibiliza serviços em formato online, dentre esses serviços temos: Aprendizado de máquina, inteligência artificial e outras soluções tecnológicas. (SCHWAB, 2017)
A proposta do presente trabalho, mediante utilização de um dos pilares da indústria 4.0, a computação em nuvem e seus serviços disponibilizados e por meio de abordagens estratégicas, consiste em implementar uma solução tecnológica que através da aprendizagem de máquina permita avaliar a utilização do equipamento de proteção individual.
1.1 Justificativa
Levando em consideração o cenário sobre o uso de EPI e a falta de reconhecimento e/ou validação que estão diretamente relacionados, esse projeto justifica-se devido ao alto número de acidentes registrados no ano de 2021 no Brasil, totalizando 46,9 mil acidentes de trabalho. Contudo, estima-se que esse número seja ainda maior se somados à quantidade de subnotificações, de acordo com os dados divulgados pela plataforma SmartLab.
Os problemas relacionados ao alto número de acidentes decorrentes da falta ou uso incorreto do EPI, vão desde lesões mais comuns como corte, laceração, ferida contusa ou punctura (21%), seguidos de fratura (17%) e contusão/esmagamento (15%) até às partes do corpo mais atingidas, que foram dedos (24%), pés (8%), mãos (7%) e joelhos (5%). (SMARTLAB, 2022).
Dessa forma, é possível notar que esse projeto sobre reconhecimento e validação do uso de EPI por Câmera e AutoML Vision API pode impactar direta ou indiretamente as empresas e trabalhadores, trazendo segurança, prevenção de acidentes, maior produtividade, conscientização, adequação às exigências legais, fortalecimento da imagem da empresa no mercado.
1.2 Objetivo Geral
O objetivo principal do presente projeto consiste em implementar uma solução tecnológica baseada na aprendizagem de máquina e disponibilizada como serviço de computação em nuvem com o intuito de avaliar a utilização ou não de equipamentos de proteção individual, tentando colaborar com a prevenção de acidentes no ambiente de trabalho.
1.3 Objetivo Específicos
- Treinar um modelo de reconhecimento de imagem, a partir de conceitos de aprendizagem de máquina inserindo fotografias em um banco de dados.
- Estabelecer uma comunicação entre o microcontrolador ESP32-CAM, servidor local e AutoML Vision API (Google cloud platform).
- Implementar mediante os algoritmos disponibilizados em computação em nuvem uma solução que permita identificar a utilização de ao menos dois EPI ‘s no membro superior do ser humano.
2. Materiais e Métodos
2.1 Sistemas de Controle Moderno
Um sistema de controle é a interconexão de componentes formando uma configuração de sistemas que produzirá uma resposta desejada do sistema.
A base para a análise de um sistema são os princípios fornecidos pela teoria de sistemas lineares, a qual supõe uma relação de causa e efeito para os componentes de um sistema. Além disso, um componente ou processo a ser controlado pode ser representado por um bloco. A relação de entrada e saída representa a relação de causa e efeito do processo, o qual por sua vez representa o processamento do sinal de entrada para fornecer um sinal de saída variável, frequentemente com uma amplificação de potência. Um sistema de controle em malha aberta usa um controlador e um atuador para obter a resposta desejada e não possui realimentação. (RICHARD C. DORF, 2009)
O projeto proposto consiste em um sistema de controle em malha aberta que utiliza um dispositivo de atuação para controlar o processo diretamente sem usar realimentação, conforme diagrama de blocos na figura 1.
Figura 1 – Diagrama de blocos de um sistema de controle em malha aberta

O primeiro bloco é composto por uma câmera de 2 Megapixels acoplada a um microcontrolador ESP32-CAM que realiza a captura da imagem.
Figura 2 – Microcontrola dor ESP32-CAM

Fonte: Adaptado do site randomnerdtutorials.com
No segundo bloco, a imagem é enviada para a API AutoML Vision, onde criamos um banco de imagens e treinamos um modelo para classificação de imagens.
Figura 3 – Representação do segundo bloco

No terceiro bloco, vinculamos ao microcontrolador uma sirene e dois LED’s (Verde e Vermelho) com a finalidade de sinalizar ao colaborador a ausência ou presença do EPI.
Figura 4 – Representação do terceiro bloco

Fonte: Adaptado do site randomnerdtutorials.com
Abordaremos neste projeto os principais conceitos que juntos nos proporcionaram criar esta solução, sendo eles elementos da indústria 4.0.
2.2 Indústria 4.0
A Indústria 4.0 também chamada de Quarta Revolução Industrial, engloba um amplo sistema de tecnologias avançadas como inteligência artificial, robótica, internet das coisas e computação em nuvem que estão mudando as formas de produção e os modelos de negócios no Brasil e no mundo. (SCHWAB, 2017)
Os pilares que compõem a indústria 4.0 são: Realidade aumentada, internet das coisas, cyber segurança, computação em nuvem, manufatura aditiva, big data, robôs autônomos, integração de sistemas e simulações. Podemos visualizar suas aplicações em dispositivos como impressoras 3D, biometrias, reconhecimento facial, gestão de dados em uma empresa, linhas de produção sem o auxílio de mão de obra manual, computação gráfica aplicada a jogos ou simuladores, na medicina seu uso é aplicado em cirurgias de precisão ou acompanhamento médico e no agronegócio para o monitoramento de plantio ou gado. (SCHWAB, 2017)
2.3 Internet das coisas
A Internet das Coisas (internet of things, IoT) é um dos pilares da Indústria 4.0 ao permitir que os objetos corporativos se conectem entre si e com os usuários. Isso tem permitido que as empresas usem esse tipo de conectividade para realizar serviços de manutenção preditiva em seus serviços.
A computação em nuvem permite a conexão de dispositivos e serviços, como Google Maps, Netflix, Spotify e Youtube. Este projeto une a computação em nuvem com o dispositivo IoT, desse modo é possível utilizar serviços online como a Application Programming Interface (API) para realizar predições de imagem.
2.4 Sistemas embarcados
Sistemas embarcados são dispositivos com capacidade de processamento de dados e que estão inseridos em um determinado dispositivo ou produto, em nosso cotidiano utilizamos muitos equipamentos que possuem internamente um microcontrolador, como eletroeletrônicos e eletrodomésticos. O timer de um aparelho micro-ondas, o controle remoto de um aparelho televisor ou ar-condicionado, um relógio digital, o controlador de voo de um drone, uma impressora 3D e outros dispositivos podem ser construídos fazendo uso de microcontroladores.
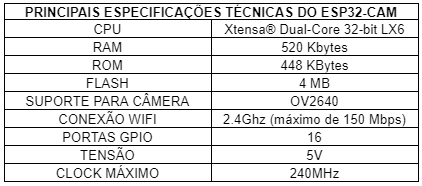
Neste projeto estamos utilizando um ESP-CAM que é um microcontrolador e é responsável por gerenciar os dados da API e realizar a captura de imagem por meio de uma câmera de 2 megapixel acoplada a ele, abaixo podemos ver suas especificações técnicas.
Figura 1 – Diagrama de pinagem do ESP32-CAM

Tabela 1 – Especificações técnicas do ESP32-CAM
2.5 Aprendizado de Máquinas (Machine Learning)
O princípio do reconhecimento por imagem advém da estrutura neural presente no córtex visual dos mamíferos, conhecida como Rede Neural Convolucional (Convolutional Neural Network – CNN) é uma classe de rede neural utilizada para processamento e análise de imagens. (Marcos Tanaka, 2018)
Sua estrutura pode ser observada através de camadas de clusters de neurônios conforme a figura de exemplo a seguir:
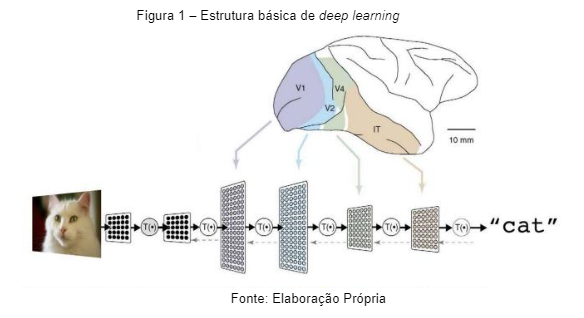
Quando vemos algo, clusters são ativados hierarquicamente, e cada um detecta um conjunto de atributos sobre o que foi visto. Nesse caso, para formular a imagem de um gato, nosso cérebro reúne em etapas diferentes aspectos do felino como o pêlo, os olhos, o formato da orelha, desse modo avançando na estrutura a cada camada e ao final obtendo resposta de que a imagem corresponde a imagem de um gato. (Marcos Tanaka, 2018)
A arquitetura da CNN simula clusters de neurônios para detectar atributos daquilo que foi visto, organizados hierarquicamente e de forma abstrata o suficiente para generalizar independentemente de tamanho, posição ou rotação. (Marcos Tanaka, 2018)
O input da CNN é uma imagem, representada como uma matriz. Cada elemento da matriz contém o valor de seu respectivo pixel, que pode variar de 0 a 255. Para imagens coloridas em RGB, temos uma matriz “em três dimensões”, onde cada dimensão é uma das camadas de cor (red, green e blue). Assim, uma imagem colorida de 255px por 255px é representada por três matrizes de 255 por 255 (255x255x3). (Marcos Tanaka, 2018)
Figura 2 – Representação de entradas para o cálculo convolucional

Fonte: www.imasters.com.br
Figura 3 – Representação das camadas estabelecidas hierarquicamente.

Fonte: Elaboração Própria
2.5 AutoML Vision
Um classificador personalizado é um tipo de modelo de aprendizagem de máquina que pode ser implantado quando seu caso de uso requer que você aplique rótulos predefinidos para classificar um conjunto de dados de imagens que deseja investigar. Como por exemplo, modelos de veículos específicos, tipos de flores ou arquiteturas de casas.
No Google Cloud (suíte de computação em nuvem oferecida pelo Google), o AutoML Vision nos permite fazer justamente isso. Vamos detectar a utilização correta de EPIs em um ser humano, para isso criamos um banco de dados e o alimentamos com centenas de fotos dos EPI’s que desejamos identificar em diferentes ângulos. Treinamos um modelo com base no banco de imagens que criamos, verificamos a precisão e resultados obtidos.
2.6 Elementos e Etapas do Processo
Figura 1– Fluxograma de representação dos elementos do processo

Fonte: Elaboração Própria
O sistema é composto pelos elementos descritos na imagem, que por sua vez são:
- A câmera, elemento que faz parte do micro controlador;
- O Microcontrolador utilizado é o ESP32-CAM, que possui a câmera como um periférico e também comunicação WIFI, o que nos permite a comunicação com os servidores;
- O Servidor local, que receberá os dados de todos os micros controladores conectados à mesma rede;
- O Servidor em nuvem (Google Cloud), que contém o AutoML Vision API;
- Sinalização visual e sonora que irão representar a resposta de todo o processo. Neste projeto de demonstração, são utilizados LEDs e um Buzzer;
Figura 2 – Fluxograma de representação das etapas do processo

Fonte: Elaboração Própria
As etapas do processo são compostas por todas as transições entre os elementos, sendo elas:
- Envio da imagem capturada pela câmera para o micro controlador;
- Envio da imagem em buffer para a API local;
- A imagem é enviada para o Google Cloud, onde é realizada a comparação com o modelo treinado, validando a presença dos EPIs.
- O Google Cloud retorna um ou mais rótulos com seus devidos percentuais de confiabilidade, como resposta da análise;
- A API local retorna para o microcontrolador um valor que irá representar uma resposta do processo;
- O microcontrolador aciona o buzzer em um padrão sonoro representando negatividade (1 beep longo) ou positividade (2 beeps curtos) e o Led vermelho em caso negativo ou Verde em caso positivo;
2.7 Treinamento do modelo
Etapas para criação do modelo
a) Criação de conta no google Cloud Platform, ativação da API e criação de um banco para upload das imagens;
b) Abastecimento do banco de imagens com fotografias rotuladas de acordo com os EPI’s para treinar o modelo de predição;
c) Implementação do modelo treinado para realizar previsões online.
Após criação de conta no google cloud platform e ativação da API AutoML Vision, criamos um conjunto de dados para treinamento do modelo. Onde queremos classificar vários rótulos em uma imagem.
Após criação de conta no google cloud platform e ativação da API AutoML Vision, criamos um conjunto de dados para treinamento do modelo. Onde queremos classificar vários rótulos em uma imagem.
Figura 1 – Seleção do tipo de modelo utilizado no modelo

Fonte: GOOGLE CLOUD PLATFORM (2022)
Após criação de conta no google cloud platform e ativação da API AutoML Vision, precisamos abastecer um banco de imagens para treinamento do modelo de predição personalizada.
Definimos rótulos para os grupos de imagens de modo a separar os tipos de EPI’s que desejamos reconhecer no modelo. Cada grupo possui fotos em diferentes ângulos conforme exemplo:
Figura 2 – Representação do grupo de imagens para indicação do uso de capacete.

Fonte: Elaboração Própria
A tabela abaixo contabiliza a quantidade de imagens para cada rótulo e respectivamente sua descrição.
Tabela 1 – Tabela de rótulos e especificação
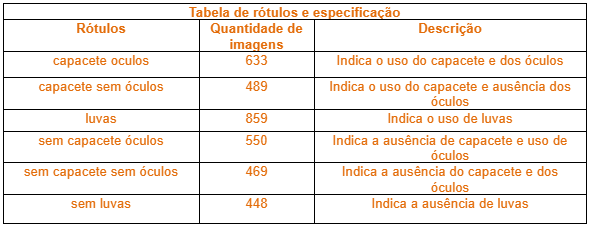
Por serem EPI ‘s com uso próximo entre si como o capacete e os óculos, decidimos criar rótulos bem definidos referente ao estado de utilização de cada, pois o resultado que a API nos fornecerá será o rótulo criado.
Separamos os grupos de imagens em pastas no formato ZIP e importamos para dentro do banco de imagens no Google Cloud Platform.
Figura 3 – Imagens importadas para o banco de dados

Fonte: Adaptado GOOGLE CLOUD PLATFORM (2022)
Na etapa seguinte, iniciamos o treinamento auto aprendizagem do modelo que durou em torno de seis horas.
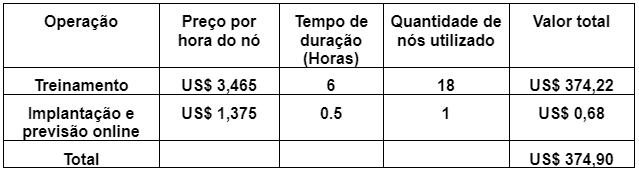
O custo do treinamento e implementação do modelo é baseado na quantidade de horas de uso do nó. Conforme tabela a seguir.
Figura 4 – Custos de Dados de Imagem

Fonte: cloud.google.com Tabela 2 – Tabela de custos do modelo treinado
Ao final do treinamento, podemos verificar as métricas de avaliação do modelo.
Uma métrica útil para a acurácia do modelo é a área sob a curva de recall e precisão. Ele mede o desempenho do modelo em todos os limites de pontuação. No AutoML Vision, essa métrica é chamada de Precisão média. Quanto mais próximo de 1 essa pontuação for, melhor será o desempenho do seu modelo no conjunto de testes. Um modelo que adivinha aleatoriamente cada rótulo teria uma precisão média em torno de 0,5.
Figura 5 – Exemplo de um resultado de recall e precisão

A precisão e o recall nos ajudam a entender o desempenho do modelo na captura de informações e o quanto ele está deixando de fora. A precisão indica quantos exemplos de teste realmente precisam ser categorizados com um rótulo, dentre todos os que receberam um rótulo. De todos os exemplos de teste que deveriam ter recebido um determinado rótulo, o recall indica quantos realmente foram rotulados.
Figura 6 – Exemplo de um resultado percentual

Podemos comparar o desempenho do modelo em cada rótulo usando uma matriz de confusão conforme imagem de exemplo abaixo. Em um modelo ideal, todos os valores na diagonal serão altos e todos os demais serão baixos. Isso mostra que as categorias desejadas estão sendo identificadas corretamente. Se outros valores forem altos, será um indício de como o modelo está classificando erroneamente as imagens de teste.
Figura 7 – Exemplo de matriz de confusão para reconhecer arquitetura de casas

2.8 Descrição do algoritmo no ESP32-CAM e servidor local
O algoritmo por parte do microcontrolador persiste em iniciar a câmera e suas funções específicas de captura de imagem, realizar a conexão com a rede através do WIFI (com auxílio de seu próprio módulo) e estabelecer comunicação com o servidor local. Então, é mantido em execução a leitura por parte da câmera, de acordo com os gatilhos estabelecidos, que durante os testes realizados, foi de uma foto a cada quinze segundos, sendo a mesma enviada para o servidor local e aguardando a resposta. Então a partir dos parâmetros recebidos, uma ação é tomada, emitindo um sinal negativo ou positivo, de acordo com a análise da imagem.
Já o servidor local possui uma função mais estática e simples. Se trata de uma API RESTful, com dois simples comandos, um GET que serve para verificar (por parte do microcontrolador) se o servidor está online e um POST onde é recebida a imagem a ser analisada. Após o recebimento, é realizado um POST agora no servidor em nuvem, que irá realizar os procedimentos de detecção dos equipamentos de proteção. Logo em seguida, com a resposta do AutoML Vision API, um rótulo é recebido e convertido em um valor de 0 (zero) a 3 (três) conforme tabela abaixo e enviado como resposta para o microcontrolador. Durante os testes realizados, os valores equivalentes eram: 0 (zero) para a presença de óculos e capacete, 1 (um) para óculos sem capacete, 2 (dois) para sem capacete e óculos e por fim, 3 (três) sem capacete e sem óculos.
Tabela 1 – Tabela de comunicação entre o servidor local e o micro controlador
Fonte: Elaboração própria
3. Resultados e Discussões
Figura 1 – Resultados obtidos referente ao modelo treinado no AutoML Vision

Notamos que a precisão do modelo treinado indica quantos exemplos de teste realmente foram categorizados com um rótulo, desse modo indicando que parte das imagens do banco de dados utilizados para teste se enquadram em 100% dentre todos os que receberam um rótulo. Assim ao enviar uma imagem para verificação as chances de obter uma resposta que coincide com o esperado são respectivamente altas.
De todos os exemplos de teste que deveriam ter recebido um determinado rótulo, o recall indica quantos realmente foram rotulados, de acordo com o gráfico 100% das imagens foram úteis para o treinamento. Caso algumas das imagens usadas para teste não estivessem alinhadas com as demais imagens do banco, esse percentual seria menor resultando em uma confiabilidade inferior à desejada.
Figura 2 – Resultados de percentual obtidos a partir do modelo treinado

Figura 3 – Matriz de confusão obtida no modelo treinado

Notamos na imagem que os valores indicados na diagonal é equivalente a um modelo ideal. Isso mostra que as categorias desejadas estão sendo identificadas corretamente. Se em outras combinações da matriz tivéssemos valores altos, seria um indício de que o modelo estaria classificado erroneamente.
A tabela a seguir representa os testes realizados, com as imagens que foram enviadas para o servidor em nuvem.
Figura 4 – Tabela de comunicação entre o servidor local e o micro controlador
Fonte: Elaboração própria

De acordo com a tabela a seguir, podemos verificar o sinal enviado pelo servidor local de acordo com a etiqueta recebida pelo servidor em nuvem.
A partir da resposta recebida do servidor local, o microcontrolador emite um sinal. Neste exemplo, onde estamos verificando o uso de capacete e óculos, ao receber um sinal “0”, o microcontrolador irá acionar o LED verde e emite dois beeps curtos, simbolizando um sinal positivo. Qualquer outro valor diferente de “0” irá resultar no acionamento do LED vermelho e um beep longo, simbolizando um sinal negativo.
Tabela 1 – Resultado obtidos a partir da tabela de testes na fig.4
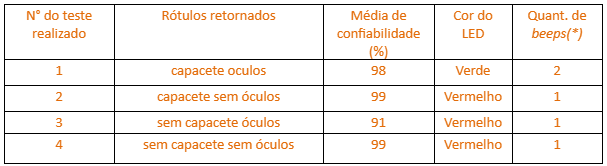
Fonte: Elaboração própria
Referente ao teste de número 1(um) em que a imagem enviada mostra que o colaborador possui a devida proteção, o resultado informa que a cor do led é verde acompanhado de 2(dois) sinais sonoros emitidos pelo buzzer indicando a utilização correta da proteção.
Nas demais imagens de teste notamos a ausência do EPI ‘s por parte do colaborador e as respostas obtidas de acordo com os teste 2(dois), 3(três) e 4(quatro) é contrária ao primeiro teste resultando no led de cor vermelha acompanhado de um estendido beep.
A partir dos testes realizados é possível constatar que a eficácia do protótipo é real, viabilizando o objetivo principal do projeto. Desse modo, comprovando que ao melhorar a quantidade e qualidade das imagens no abastecimento do banco de dados referente a diferentes tipos de EPI ‘s, podemos melhorar a prevenção de acidentes.
4. Considerações finais
De acordo com os resultados obtidos referentes aos gráficos de recall e precisão, conseguimos demonstrar que o AutoML vision é capaz de identificar os EPIs de forma precisa uma vez que as imagens foram devidamente rotuladas e inseridas no banco de imagens para treinamento.
De acordo com os dados recebidos pelo micro controlador, verificamos na tabela de resposta do servidor em cloud, a confiabilidade dos rótulos apresentados. Pode-se notar que o padrão de confiabilidade é sempre maior que 90%, resultando no acionamento dos Led´s e do buzzer de forma precisa.
Nossa demonstração foi realizada de forma simples, com o disparo realizado através de um botão e a sinalização da resposta através de um sinal sonoro e visual. Porém, existem muitas possibilidades envolvidas em torno de todo o processo. Pois, a partir do momento que utilizamos um servidor local, podemos armazenar não somente a imagem e a resposta do servidor em nuvem, mas também a identificação do colaborador, a data, horário e local onde foi realizada a verificação, possibilitando a visualização e controle em consultas posteriores. Ou uma simples alteração do gatilho, com um sensor de presença ou disparo por tempo. Ressaltando também, que em uma mesma planta e conectados ao mesmo servidor local, pode existir mais de um dispositivo, uma vez que cada um possui um IP único na rede, eles podem ser identificados e cadastrados com a sua localização (entrada da cabine primária, entrada do galpão, torno).
Para concluir, a partir dessa representação da ideia principal validamos que é possível criar um modelo único capaz de identificar todos os EPI’s utilizados por parte do colaborador, isso demandaria mais tempo, recurso financeiro e contribuiria com a prevenção de acidentes de trabalho.
5. Referências Bibliográficas
Livros
OLIVEIRA, U.R.O. Textos selecionados: Legislação de segurança do trabalho. Saraiva, 2017.
DORF, R.C.D; BISHOP, R.H.B. Sistemas de Controle Modernos. LTC, 2009.
SCHWAB, K.S. A Quarta Revolução Industrial. Edipro, 2017
Periódico
Indicadores do Mercado Brasileiro de Equipamentos de Proteção Individual. São Paulo: Associação Nacional da Indústria de Material de Segurança e Proteção ao Trabalho. 2021.
Mercado de EPI’s tem aumento de 20%. Rio Grande do Sul: RSData Software de Saúde e Segurança do Trabalho. 2020.
Internet
TANAKA, M.T. Classificação de imagens com Deep learning e Tensorflow. Disponível em:<https://imasters.com.br/back-end/classificacao-de-imagens-com-deep-learning-e-tensorflow> Acesso em: 20 junho 2018.
SMARTLAB. Citação de referências e documentos eletrônicos. Disponível em:<https://smartlabbr.org > Acesso em: 15 outubro 2022.
FILIAÇÃO