ANALYSIS OF DETECTORS FOR AI-GENERATED TEXTS: APPROACHES BASED ON NLP AND MACHINE LEARNING
REGISTRO DOI: 10.69849/revistaft/fa10202505261458
Fani Tamires de Souza Batista2
Renildo Viana Azevedo3
RESUMO
O artigo tem como objetivo verificar a qualidade de detectores de textos gerados por IA utilizando técnicas de Processamento de Linguagem Natural (PLN) e Machine Learning (ML). Foram testadas quatro ferramentas: Justdone, Undetectable AI, Monica e Isgen.ai, com textos humanos e do ChatGPT. Os resultados encontrados mostraram uma variação na precisão das ferramentas testadas. Os testes indicaram que o Isgen.ai foi o mais confiável e o Justdone o menos eficaz. Além da acurácia, analisou-se a profundidade na análise dos resultados. Nesse ponto, a Isgen.ai apresentou mais detalhes na análise dos textos submetidos. A pesquisa indica que há desafios na identificação correta dos textos, porque erros podem impactar a integridade acadêmica e favorecer a desinformação. Mesmo que existam avanços, os detectores precisam de melhorias para garantir a certeza nos resultados e evitar falsos positivos ou negativos. O estudo destaca a importância de que métodos robustos sejam criados para lidar com a crescente sofisticação das IAs na geração de textos.
Palavras-chaves: Inteligência Artificial, identificação de texto, ferramentas de IA, geração de texto
1 INTRODUÇÃO
Nos últimos anos, a Inteligência Artificial (IA) vem se popularizando em diferentes setores. E o seu desenvolvimento voltado para os sistemas que prometem realizar tarefas que se assemelham às habilidades humanas em compreender e resolver problemas, tem se aprimorado cada vez mais (Diaz-Guio, et al. 2023). Atualmente, as ferramentas possuem propriedades que integram técnicas avançadas para realizar diferentes tarefas e assim, dar suporte nas mais distintas áreas do conhecimento, inclusive no contexto da produção de textos, tendo em vista que as IAs são capazes de aprender, reconhecer padrões e compreender a linguagem natural (Figueiredo, et al. 2025).
Nesse contexto, o uso de IA para gerar textos vem sendo adotado frequentemente. Os modelos de linguagem baseados em Inteligência Artificial, como o GPT, COPILOT e GEMINI, geram textos automáticos para diferentes contextos, o que tem gerado um impacto significativo em áreas como educação, ciência e comunicação. Em um estudo realizado por Lucchi (2024) é abordado que o desenvolvimento de ferramentas que ajudam a identificar os textos gerados por IA tem chamado atenção devido a crescente preocupação com confiabilidade passada pelas ferramentas em detectar a autoria do texto, mas sobretudo no uso de IA para a propagação de fraudes acadêmicas e a desinformação. Tal preocupação é questionada por Moraes (2024), no que se refere a forma que essas ferramentas podem influenciar decisões, causando um grande impacto a depender do que está sendo tratado.
Adentrando ao contexto das ferramentas de detecção de textos gerados por IA, nota-se que há poucos estudos em literatura que fazem uma análise profunda sobre o tema. As menções relacionadas às técnicas de Processamento de Linguagem Natural e Machine Learning são diretamente voltadas para os processos que englobam o funcionamento dos Grandes Modelos de Linguagem (GML), como Chat GPT.
Criado pela OpenAI em 2015, o Chat GPT é baseado no modelo de Machine Learning GPT (Generative Pré-trained Transformer), que aprende continuamente padrões de linguagens com base nos dados e textos presentes na web, sendo capaz de gerar textos, conduzir conversas com os usuários, responder perguntas e resolver cálculos (Haque; Brito; Frade, 2024).
Chaka (2023), faz uma abordagem voltada para as ferramentas que fazem uso de técnicas de Processamento de Linguagem Natural (PLN) e Machine Learning e que identificam os padrões linguísticos para diferenciar textos escritos por humanos de textos gerados artificialmente. Porém, em um curto espaço de tempo, o número de ferramentas que são desenvolvidas para realizar essa tarefa tem crescido absurdamente, e em muitas dessas ferramentas, o desempenho apresenta desafios significativos, o que abala a confiança dos usuários.
Com isso, é essencial realizar uma análise das principais ferramentas que se propõem a identificar textos gerados por IAs, para demonstrar o nível de precisão e eficácia de cada uma. Dessa maneira, esse estudo se justifica pela necessidade de entender o funcionamento e a eficácia das plataformas de detecção, na utilização de critérios previamente definidos, que exploram a performance das ferramentas para fornecer uma percepção e inovação em âmbito acadêmico.
Nesse sentido, uma questão se coloca: qual o nível de eficácia dos principais detectores de textos gerados por inteligências artificiais? Em resposta a esse questionamento, a pesquisa possui como objetivo primordial analisar a capacidade e a eficácia das ferramentas baseadas em PLN e Machine Learning para identificar textos gerados por IA garantindo resultados confiáveis e aplicáveis com diferentes textos. Sendo possível também, descrever os principais fundamentos do PLN; explicar as principais técnicas de análise de sintaxe, semântica e frequência de palavras; selecionar os critérios para avaliar a capacidade e eficácia de cada ferramenta; e verificar o desempenho das ferramentas com base nos critérios de avaliação.
O estudo será conduzido de maneira teórica e prática, a partir de uma revisão de literatura que aborda sobre as técnicas de PLN e Machine Learning para classificar textos, e na prática a análise das ferramentas de detectores de IA. Para isso, o artigo está organizado nas seguintes seções: revisão de literatura para abordar os conceitos fundamentais e as técnicas de PLN e ML utilizadas em ferramentas de detecção, bem como os trabalhos relacionados ao tema; a metodologia da pesquisa; os resultados da análise dos resultados dos testes com as plataformas avaliadas.
2 FUNDAMENTAÇÃO TEÓRICA
Conceitos fundamentais: Processamento de Linguagem Natural e Aprendizado de Máquina
O Processamento de Linguagem Natural (PLN), do termo em inglês Natural Language Processing (NLP) é uma área dentro da Ciência da Computação que está relacionada à Inteligência Artificial. Essa área possui como intuito, pesquisar e demonstrar métodos e procedimentos de processamento computacional da linguagem humana (Caseli, Nunes, 2024).
Nos estudos de Barbosa et al (2017, p. 337) o PLN é definido como “uma forma de descobrir quem fez o quê, a quem, quando, onde, como e porquê”, tendo em vista que os autores afirmam que o propósito do PLN na computação é a extração de representações e significados íntegros de textos escritos em linguagem humana, ou seja, em linguagem natural usada na comunicação diária.
As duas visões apresentadas concordam que o PLN é responsável por processar a linguagem humana de forma que ela seja “compreendida” pelo computador, e para que haja essa aproximação é necessário um processamento dos termos da linguagem humana em diferentes níveis. Nos estudos de Diáz-Guio (2023), são descritos previamente a ocorrência do processamento, onde há a extração de dados de uma entrada, análise da semântica, sintáticas e do contexto, gerando ao usuário um retorno similar ao de um humano com uma baixa taxa de erro. Em GML, por exemplo, Dwivedi, et al (2023) trazem o foco do processamento de linguagem natural para a utilização de bilhões de parâmetros acertados e aperfeiçoados por meio de um vasto agrupamento de dados de textos, que originaram a capacidade de aprendizado contextual.
Nesse sentido, o campo da Inteligência Artificial incorpora o Aprendizado de Máquina. Campos, Farina e Florian (2022), definem Machine Learning como um processo sucessivo de máquina. Em concordância com essa definição, Damasceno e Vasconcelos (2018) indicam que após o fornecimento de dados de entrada, a máquina começa a aprender com os dados e busca elaborar saídas que melhor atendam o problema. Em uma outra abordagem, Chen e Decary (2020) definem que Machine Learning está associado a uma estrutura que treina um modelo preditivo ao reconhecer padrões de entradas, e utiliza-o para fazer previsões úteis partindo de dados novos.
Em relação aos seus conceitos fundamentais, a tokenização é uma abordagem essencial. Palmer (2010), define a tokenização como pontos onde uma palavra termina e se inicia a outra, em outros termos, ela também é conhecida como quebra de sequência de caracteres ou segmentação de palavras. O autor ainda explica que na linguagem computacional, as palavras que são identificadas são chamadas de tokens, e complementa que ao tratar de caracteres como vírgulas, pontos e ponto e vírgula, entre outros, há sinais de ambiguidades em linguagens delimitadas por espaço.
A partir disso, três conceitos são integrados nas ferramentas de detecção, são eles: análise léxica, sintática e semântica. Barbosa, et al (2017), explicam que após a tokenização, o processo seguinte é a análise léxica, ou análise a nível de palavra, dessa forma há dois tratamentos para uma palavra, no primeiro ela é pensada como uma sequência de caracteres, como o verbo “entregar”, na segunda ela é vista como um objeto mais abstrato para um conjunto de sequências de caracteres, onde “entregar” é o objeto ou lemma do conjunto “entrega, entregando, entregador…”. Na análise sintática, é onde ocorre a extração do significado de uma frase, e para representar a análise sintática são utilizadas gramaticais e árvores sintáticas. Por fim, na análise semântica ocorre a recuperação e extração de informação, mineração de dados, sumarização de textos e tradução para linguagem de máquina, dessa forma seu objetivo final é entender o enunciado de frases e textos.
Técnicas de PNL utilizadas nas ferramentas de detecção
Dentre as técnicas de PLN utilizadas estão a extração de recursos linguísticos, e nesses contextos, se destacam a análise de n-gramas (bigramas, trigramas) e a vetorização de palavras (WordVec, GloVe, embeddings contextuais como BERT). As técnicas de análise de N-gram, desempenham um papel fundamental na captura de contexto local, aprimorando a linguagem, a extraindo recursos, lidando com palavras fora do vocabulário, mitigando escassez, tirando ambiguidades no significado de palavras e dando suporte a inúmeras tarefa e aplicações de PLN (Kalbhor; Goyal; Sankhla, 2024). A técnica se faz fundamental no processamento de texto que envolve a quebra de um pedaço de texto em uma sequência contínua de N palavras ou caracteres.
Em relação aos métodos de vetorização de palavras, Ali, et al (2024) apontam que eles possuem um papel na análise, classificação e detecção de dados textuais. O processo de vetorização envolve a conversão de textos em formatos numéricos, permitindo que algoritmos de aprendizado de máquina processem e analisem as informações de forma eficiente e estruturada. Na tabela abaixo (tabela 1) estão os métodos de vetorização e o seu papel na detecção dos dados textuais.
| Método de Vetorização | Aplicabilidade |
| Vetorização de Contagem | É um método direto que converte uma coleção de documentos de texto em uma matriz de contagens de tokens. Nessa abordagem, cada palavra única na base de dados corresponde a um recurso na matriz de recursos. O valor de cada posição na matriz indica a quantidade de vezes que uma palavra em particular aparece em determinado documento. Tal método é simples e efetivo para inúmeras tarefas de classificação de texto, entretanto ignora totalmente o contexto e ordem das palavras, tendo uma perda de semântica. |
| Termo-Frequência Inversa do Documento | A vetorização TF-IDE possui algumas limitações da Vetorização de contagem. Além de considerar a frequência de palavras em um documento, também avalia a importância de cada palavra em toda base de dados. Resultando valores que refletem o quão relevante uma palavra é em um documento em particular relativo pela frequência em outros documentos. Esse método é útil para identificar características distintas em um texto e ajudar na redução de palavras comuns que não contribuem para compreensão do conteúdo do documento. |
| Vetorização em Hash | É uma técnica mais avançada que emprega uma função de hashing para converter palavras em uma representação de vetor de tamanho fixo. Diferentemente dos outros métodos apresentados, que dependem do vocabulário na base de dedos, a vetorização em hash usa funções de hash para mapear palavras diretamente no espaço de recurso. Tal método possui é bastante vantajoso quando se trata de lidar com grandes bases de dados, uma vez que evita a necessidade de armazenar o vocabulário inteiro na memória. Entretanto, uma desvantagem notável é a ocorrência de colisão, ou seja, diferentes palavras mapeadas para um mesmo recurso, potencializando a perda de informação. |
Outra técnica relevante é a análise de sentimento e polaridade. Em um estudo feito por Alsaedi, et al. (2024), são abordadas as formas de identificação de emoções nos textos e como isso pode diferenciar conteúdos humanos e gerados por IA. Para os autores, a análise de sentimentos é uma técnica que consiste em analisar dados textuais para identificar sentimentos subjacentes ou opiniões, o que se torna significativamente poderoso com a integração de tecnologias de aprendizado de máquina. A identificação de emoções em textos de review de ecommerce possibilita focar em aspectos específicos, para extrair de opiniões informações impactam na elaboração de design, performance e serviços ao consumidor.
Técnicas de Aprendizagem de Máquina utilizadas nas ferramentas de detecção
Ao observar as técnicas de ML nas ferramentas de detecção, podem ser destacados dois pontos principais: os algoritmos de classificação supervisionada e modelos baseados em deep learning. Nesse sentido, a utilização de Redes Neurais Artificiais (ANN) são utilizadas em tarefas de classificação textual. A pesquisa de AL-Wesabi, et al (2023), discute sobre as ANN em um contexto de análise de sentimentos e processamento de linguagem natural. ANN são destacadas por sua capacidade de classificar sentimentos ao aprender automaticamente características relevantes de grandes conjuntos de dados, melhorando a precisão na identificação de polaridades em textos.
O conceito de Support Vector Machines (SVM) é um meio pelo qual é possível se obter eficiência em separar textos humanos e gerados por IA. Para Alnasser e Almuhaideb (2024), trata-se de um método que busca encontrar um hiperplano que separa diferentes classes em um espaço de características, podendo alcançar altos desempenhos, mesmo em comparação com modelos mais atuais.
Em relação aos modelos baseados em deep learning, destacam-se as Redes Neurais Recorrentes (RNN) e Long Short-Term Memory (LSTM) para análise sequencial. As RNN são do tipo de classe de redes neurais projetadas para processar sequências de dados, permitindo que informações anteriores influenciem as saídas atuais. Uma variante de RNN são as Long Short-Term Memory (LSTM), projetadas para lidar com o problema do desvanecimento do gradiente, permitindo que a rede retenha informações por longos períodos (Alnasser; Almuhaideb, 2024).
Por fim, para a modelagem contextual, Latina, et al (2024) discutem sobre os transformadores, que são uma arquitetura de rede neural que processa linguagem natural. Nessa arquitetura os modelos aprendem relações contextuais entre palavras, sem depender de sequências lineares. Os autores discutem o uso do Bidirectional Encoder Representations Terms (BERT), um modelo pré-treinado, que utiliza essa arquitetura para gerar incorporações contextuais, considerando o contexto de uma palavra em ambas as direções, direita e esquerda. Isso permite que o BERT capture nuances semânticas e relações complexas entre palavras, tornando altamente eficaz em tarefas de compreensão de linguagem.
Trabalhos relacionados ao tema
A pesquisa de trabalhos relacionados identificou poucas contribuições para a reflexão sobre o tema. Moraes (2024), desenvolveu uma pesquisa para detectar textos gerados pelo Chat GPT, analisando as capacidades, limitações e aplicações práticas. No estudo o autor concluiu a partir das ferramentas analisadas, que há necessidade de aprimoramento das ferramentas de detecção que estão disponíveis na web.
O trabalho de Xu e Sheng (2024) aborda a identificação de códigos gerados por Inteligência Artificial em tarefas de programação, utilizando a perplexidade de modelos de linguagem de grande porte. A metodologia proposta envolve a perturbação direcionada de áreas do código com maior perplexidade e o uso de um modelo CodeBERT. O estudo mostra que o método proposto supera os detectores de texto atuais, dentre eles GPT2-Detector, DetectGPT, RoBERTa-QA, GPTZero e The Writer AI Detector. Este trabalho se destaca por abordar uma problemática emergente na educação de novos programadores, onde estudantes podem usar modelos de linguagem para gerar códigos em suas atividades.
Outro estudo que aborda essa linha de pesquisa, foi desenvolvido por Hua e Yao (2024). Nele, os autores demonstram que as ferramentas de detecção falham constantemente ao identificar textos que foram parafraseados, comprometendo a eficácia. Tal demanda salienta a necessidade de desenvolver técnicas mais robustas para assim poder lidar com modificações sutis no texto feito por inteligência artificial. Ainda nessa pesquisa, são citadas as Máquinas de Vetores de Suporte (SVM), um tipo tradicional de algoritmo usado em aprendizado de máquina. O trabalho supramencionado demonstrou que esse modelo obteve 100% de acurácia em identificar textos gerados por seres humanos.
Por fim, Kar, et al (2024), realizam uma análise abrangente das ferramentas de detecção de textos gerados por IA destacando a eficácia e as limitações de diferentes métodos disponibilizados no mercado. Os autores constatam que, embora em algumas ferramentas apresentam alta precisão na detecção de conteúdo gerado por modelos como Chat GPT, a variabilidade nos resultados sugere a carência de melhorias contínuas para acompanhar o aprimoramento da capacidade de geração dos modelos. Os resultados enfatizam que na medida que as ferramentas de IA que geram texto se tornam cada vez mais sofisticadas, as metodologias empregadas em detecção também precisam evoluir, integrando abordagens qualitativas e quantitativas para garantir a integridade acadêmica e confiabilidade nos resultados dos detectores.
3 METODOLOGIA
A pesquisa possui natureza aplicada, visto que visa a produção de conhecimentos para aplicação prática, buscando respostas para problemas específicos. No que se refere a sua abordagem, é qualitativa, método esse que conforme citam Gerhardt e Silveira (2009), é utilizado para esclarecer o porquê das coisas, expressando o que convém ser feito, sem quantificar valores. Por fim, em relação aos seus objetivos, o estudo é caracterizado como exploratório descritivo, em que ao mesmo tempo que familiariza o pesquisador com o problema, descreve os fenômenos de uma realidade (Gil, 2007).
Para a seleção das ferramentas, objetos da análise, foi realizada uma busca nos browsers Google e Opera GX com os termos “Identificador de IA” e “Detector de IA” respectivamente, pois são navegadores desktop populares no Brasil (Figueiredo, 2024). E com base na ordem dos resultados listados, as quatro ferramentas selecionadas foram: Justdone detector de IA, Undetectable AI, Monica e Isgen.ai. Vale ressaltar que, com base nos trabalhos relacionados que analisaram detectores de IA, nesse estudo foram priorizadas as ferramentas ainda não testadas e analisadas. Na listagem dos resultados ao identificar uma ferramenta já testada, a preferência foi para a próxima da busca.
Para a realização dos testes com as ferramentas, foram construídos cenários simulados de textos narrativos, dissertativos e expositivos. A escolha de tipos textuais distintos é fundamental para se verificar a capacidade das ferramentas em lidar com a diversidade dos textos. No que concerne os tipos textuais, Rauta e Silva (2024) explicam que os textos narrativos, são aqueles que relatam o acontecimento de fatos ou ações; os textos dissertativos se referem a exposição de ideias, teorias, opiniões ou ponto de vista de forma a convencer o interlocutor, e os textos expositivos possuem o intuito de abordar informações, dados sobre um objeto ou fato.
O critério de seleção dos textos de autoria humana foi a publicação do texto antes da criação da Inteligência Artificial (quadro 1), ou seja, não havendo a possibilidade do uso de IA. E a IA utilizada no estudo para gerar os textos artificialmente (quadro 2) foi o Chat GPT, que foi selecionado devido a sua popularidade no mercado e ao número de trabalhos que analisam o seu impacto. Nos quadros abaixo estão expostos os textos que foram utilizados na pesquisa a fim de uma análise comparativa.
Quadro 1: Textos escritos por humanos em diferentes tipos textuais.
| Tipo textual | Obra e autoria | Texto utilizado |
| Narrativo | Os Lusíadas de Luís de Camões (1572) | “Mas um velho, d’aspeito venerando, que ficava nas praias, entre a gente, postos em nós os olhos, meneando três vezes a cabeça, descontente, a voz pesada um pouco levantando, que nós no mar ouvimos claramente, c’um saber só de experiências feito, tais palavras tirou do experto peito:” |
| Dissertativo | Redação nota 1000 no Exame Nacional do Ensino Médio (2001) | “Em prol da sobrevivência, há milhares de anos, a caça e a pesca eram praticadas pelo homem. Hoje, em nome do neoliberalismo, na atual conjuntura de perda dos sentimentos holísticos, desmatamos e poluímos a natureza na incessante busca do lucro, em detrimento do bem-estar da humanidade. Todavia, o homem parece ter esquecido que a natureza não é apenas mais um instrumento de alcance do desenvolvimento, mas a garantia de que é possível alcançá-lo.” |
| Expositivo | Entrevista com Clarice Lispector (1977) | “Clarice, a partir de qual momento você efetivamente decidiu assumir a carreira de escritora? Por que? Eu nunca assumi, eu não sou uma profissional, eu só escrevo quando eu quero. Eu sou amadora e faço questão de continuar sendo amadora. Profissional é aquele que tem uma obrigação consigo mesmo de escrever. Ou então com o outro, em relação ao outro. Agora eu faço questão de não ser uma profissional para manter minha liberdade.” |
Da mesma forma, foi solicitado ao Chat GPT, que escrevesse textos de caráter narrativo, dissertativo e expositivo, e a resposta resultou nos dados abaixo.
Quadro 2: Textos criados pelo Chat GPT com base nos tipos textuais solicitados.
| Tipo textual | Comando e Data | Texto utilizado |
| Narrativo | “Escreva um texto contendo dez linhas no gênero narrativo” Texto gerado em 28 de dezembro de 2024. | “No final de uma tarde de primavera, o sol lançava seus últimos raios dourados sobre a pequena cidade costeira. As ruas tranquilas eram pontilhadas por sombras alongadas das árvores, e o ar estava impregnado com o perfume das flores recém-abertas. Nas proximidades do cais, onde barcos de pesca descansavam suavemente na água calma, um jovem pescador chamado Pedro reparava suas redes. Enquanto trabalhava, recordava-se das histórias que seu avô costumava contar sobre grandes pescarias do passado. No entanto, sabia que o mar também tinha seus mistérios e caprichos, e isso o mantinha humilde diante da imensidão azul.” |
| Dissertativo | “Escreva um texto contendo dez linhas no gênero dissertativo” Texto gerado em 29 de dezembro de 2024. | “A educação é um dos pilares fundamentais para o progresso de qualquer sociedade. Mais do que um direito humano básico, ela desempenha um papel central na formação de cidadãos conscientes, no combate às desigualdades sociais e no fomento ao desenvolvimento econômico. Assim, discutir a importância da educação é essencial para compreender como ela impacta diretamente a construção de um futuro mais justo e igualitário.” |
| Expositivo | “Escreva um texto contendo dez linhas no gênero expositivo” Texto gerado em 29 de dezembro de 2024 | “A alimentação saudável é fundamental para manter o bom funcionamento do corpo e prevenir diversas doenças. Esse hábito consiste em consuamir alimentos variados, como frutas, verduras, cereais integrais, proteínas magras e gorduras saudáveis, garantindo o equilíbrio de nutrientes necessários para o organismo. Uma dieta equilibrada ajuda a fortalecer o sistema imunológico, melhorar o desempenho físico e mental e controlar o peso corporal. Além disso, reduz o risco de problemas como diabetes, hipertensão e doenças cardiovasculares. É importante evitar alimentos ultra processados, ricos em açúcares, gorduras saturadas e sódio, que podem causar prejuízos à saúde a longo prazo.” |
Por fim, os critérios de avaliação selecionados foram: i) Precisão (capacidade da ferramenta de classificar corretamente os textos); ii) Explorabilidade dos resultados (avalia se a ferramenta fornece justificativas claras para as suas classificações). Os critérios foram elaborados conforme o estudo dos trabalhos relacionados e contribuem para responder ao questionamento principal do estudo que busca saber a eficácia das ferramentas de detecção de IA.
4 RESULTADOS E DISCUSSÕES
I. Precisão das ferramentas de detecção de IA testadas
a) Justdone detector de IA
A primeira ferramenta, Justodone, adota o slogan “Mantenha a autenticidade da sua escrita identificando conteúdo gerado por IA” e promete verificar conteúdo de IA com maior banco de dados de fontes, detectar paráfrases usando um algoritmo próprio, rapidez na execução e criar um relatório detalhado. A ferramenta também possui outras funcionalidades como verificador de plágio e humanizador de textos por IA. Na primeira execução dos testes, foram testados os textos escritos por humanos e na segunda execução, foram testados os textos escritos por IA, nos dois casos usou-se os tipos narrativos, dissertativos e expositivos, conforme mostra um dos testes abaixo (figura 1).
Figura 1: Texto narrativo escrito por humano
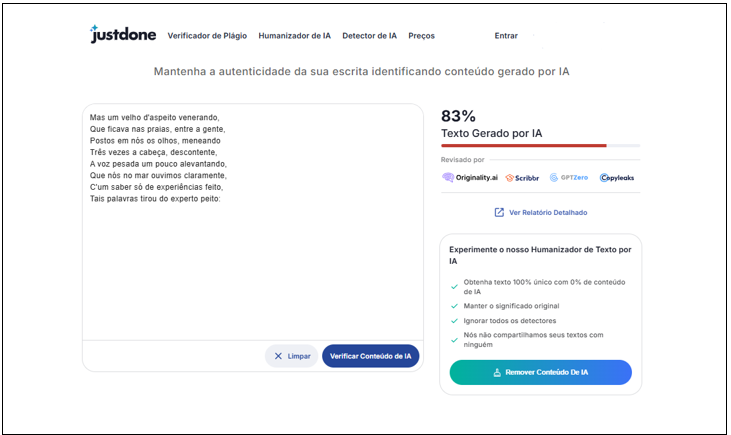
A ferramenta Justdone identificou erroneamente todos os textos testados, porém nota-se que a plataforma é mais precisa quando os textos inseridos são em inglês. Em um estudo de Caswell, et al (2020), são discutidos os desafios enfrentados na identificação de idiomas em grandes textos, que se deve a desequilíbrios de classes e similaridade entre os idiomas. Corroborando essa afirmação, Weber-Wulff, et al (2023), avaliam que as ferramentas disponíveis não são 100% precisas e confiáveis, e destaca as técnicas como tradução automática e ofuscação de conteúdo como prejudiciais no desempenho dessas ferramentas.
b) Undetectable AI
O Undetectable AI utiliza algoritmos avançados e técnicas de parafraseamento, que garantem um resultado confiável aos usuários. Além disso, a plataforma também oferece a funcionalidade de humanizar textos gerados por IA, e possui uma limitação de 10 mil caracteres por vez. Em relação ao idioma, seu foco principal é o inglês, porém há suporte secundário para detecção multilíngue (inclusive no português brasileiro) tanto na detecção de IA, quanto na humanização. No exemplo abaixo (figura 2), vemos como foi a performance da ferramenta nos textos pré selecionados.
Figura 2: Texto dissertativo escrito por humanos
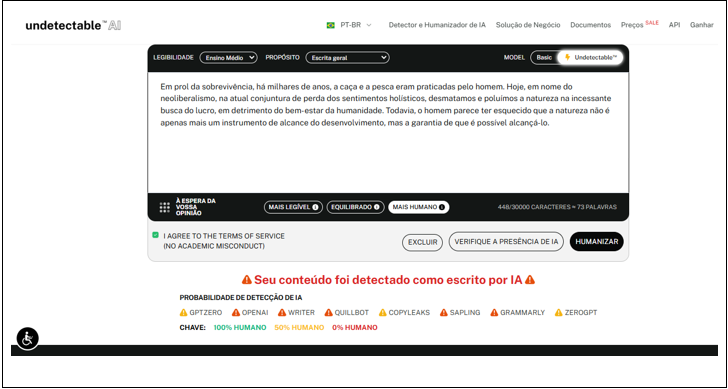
A ferramenta performou muito bem em todos os textos que foram gerados pelo Chat GPT, identificando que os textos narrativos, dissertativos e expositivos foram escritos por uma IA. Porém ao analisar os textos escritos por humanos, ele identificou erroneamente os textos dissertativos e expositivos, como podemos observar no exemplo da figura 2. O texto dissertativo foi escrito por um humano, porém a IA não foi capaz de identificá-lo corretamente.
Resultados similares foram encontrados nos estudos de Moraes (2024), onde alguns detectores obtiveram um desempenho insatisfatório. Contudo, na pesquisa em questão ficou evidenciado as falhas na identificação de textos gerados por IA indicando a necessidade de refinamento nas suas análises. Nas discussões de Weber-Wulff et al (2023), são apontadas questões relacionadas aos desafios na detecção de conteúdos gerados por IA. Dentre eles está a confiabilidade das ferramentas disponíveis, chamando a atenção para os possíveis erros que a ferramenta pode cometer ao identificar um texto incorretamente.
c) Monica
A ferramenta Monica oferece diferentes serviços em sua plataforma, além de detectar textos gerados por IA, a ferramenta gera imagens e vídeos utilizando inteligência artificial, cria mapas mentais, traduz textos, humaniza textos, verifica erros gramaticais, entre outras coisas. No que se refere ao detector de IA, a ferramenta afirma ser capaz de detectar conteúdo gerado por mais de oito dos modelos de IA mais avançados, com uma precisão de detecção de 98%. Na imagem abaixo (figura 3), está o exemplo de um dos resultados dos testes realizados na plataforma.
Figura 3: Texto narrativo escrito por inteligência artificial
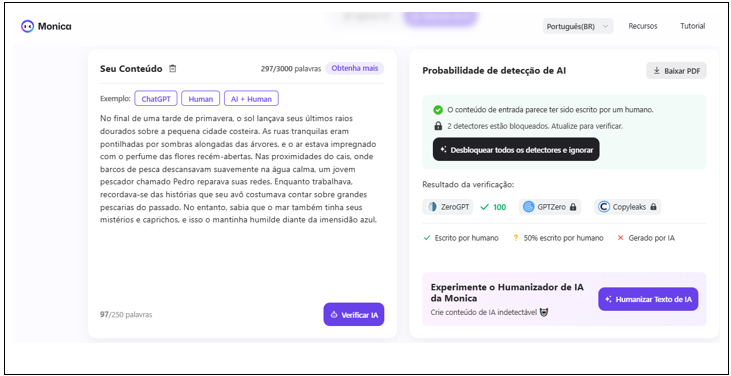
A ferramenta Monica identificou corretamente todos os textos escritos por humanos (narrativo, dissertativo e expositivo), porém nos textos gerados por IA, houve falha no texto narrativo, visto que foi identificado erroneamente que o texto foi escrito por humano. Mindner, Schlippe e Schaaff (2023), exploram esse problema ao investigar que a classificação é mais difícil de ser feita quando uma IA é instruída a criar um texto de maneira que um ser humano não reconheceria como sendo gerado por IA. No presente estudo isso não ocorreu, mas ainda assim os resultados foram similares.
d) Isgen AI
A ferramenta Isgen,ai afirma que o detector de IA possui referência na detecção de IA, treinada para identificar uma gama de modelos de código aberto e de IA fechado. Possui detecção multilíngue, gera relatórios e garante 96,4% de precisão com uma proporção de falso positivo de quase 0%. Todos os textos foram testados na plataforma, e abaixo está um exemplo dos resultados encontrados (figura 4).
Figura 4: Texto expositivo escrito por ia
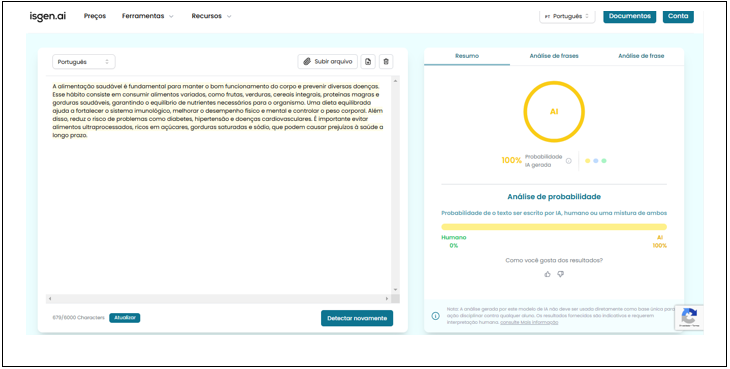
Dentre as ferramentas analisadas, a Isgen AI foi a que melhor performou nos testes. Os textos escritos por IA e os textos escritos por humanos foram classificados corretamente com a precisão correta em cada um dos testes.
Neste estudo, se verifica que as ferramentas analisadas não obtiveram todas elas sucesso quanto aos testes realizados. Em Moraes (2024), vemos algo similar quando o autor, ao analisar diferentes ferramentas, consegue resultados bons e precisos com uma ferramenta e com outras não. Dessa forma, fica evidente que a confiabilidade de um detector deve ser testada para que ela seja utilizada em uma análise mais concreta.
II Explorabilidade dos Resultados
A realização dos testes retornou resultados de cada texto testado nas plataformas. No quadro abaixo (quadro 3), são apresentadas as ferramentas apontando ao usuário as justificativas da classificação (escrito por humano ou escrito por IA) dado ao texto inserido. Nesse sentido, foram avaliados dois fatores: a justificativa da classificação (sim ou não) e o detalhamento do resultado (indicação das partes dos textos escritos por IA). Em relação ao segundo item, foi verificado em qual versão a ferramenta oferecia esse detalhamento (gratuita ou paga).
Quadro 3: Justificativa aos resultados dos testes com as ferramentas.
| Ferramenta de detecção | Oferece Justificativa? | Detalhamento dos Resultados |
| JustDone | Sim | Alta (Apenas versão paga) |
| Undetectable AI | Sim | Baixa (Versão gratuita) |
| Monica | Sim | Média (Versão gratuita) |
| Isgen AI | Sim | Alta (Versão gratuita) |
Com base nas análises, a plataforma que demonstrou melhor desempenho em relação a explorabilidade dos resultados oferecidos foi a Isgen AI. Na figura abaixo (figura 5), nota-se que a plataforma além de oferecer uma análise de probabilidade indicando se o texto foi escrito por IA, também disponibiliza, na versão gratuita, uma análise por frase que indica ao usuário qual frase foi detectada como gerada por IA.
Figura 5: Detalhamento aos resultados apresentados pelas ferramentas.
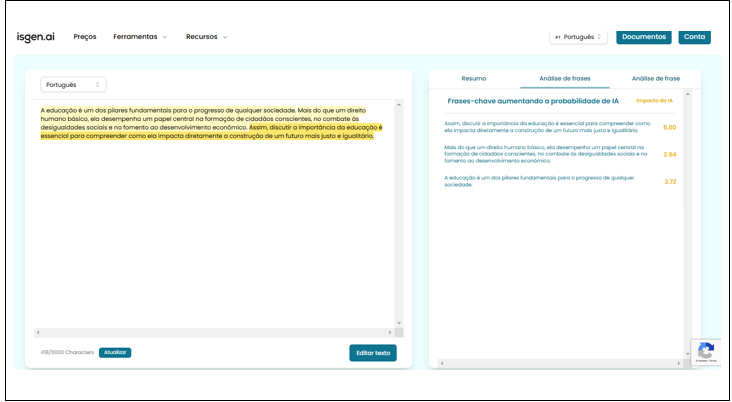
Explorar o resultado fornecido por uma IA é essencial para o aumento da confiabilidade e credibilidade da plataforma e fornecer o detalhamento a um resultado mostra transparência no processo de análise. Numa análise feita por Carvalho et al (2021), é destacado que há riscos e benefícios no uso de IA. Portanto, entender a interpretabilidade dos modelos de IA é essencial para garantir a tomada de decisões confiáveis e éticas, ou seja, o usuário deve compreender as razões por trás das decisões tomadas pelo sistema.
CONSIDERAÇÕES FINAIS
Dessa forma, os resultados da análise das ferramentas de identificação de textos gerados por IA revelaram uma similaridade com os resultados encontrados na literatura. A variação da eficácia de cada ferramenta destaca a necessidade de melhorias contínuas para que haja cem por cento de confiança. Os resultados demonstraram que, das quatro ferramentas testadas, apenas uma possui a capacidade de identificar inteligência artificial em textos corretamente.
Os resultados imprecisos, podem favorecer a propagação de informações falsas, confundindo o usuário na identificação de conteúdo não confiáveis. No contexto acadêmico, os resultados falsos acerca da autoria de um texto, pode impactar em carreiras e reputações, visto que algumas ferramentas de detecção identificam textos escritos por humanos como sendo gerados por IA. Logo, o investimento na melhoria das ferramentas de detecção seria o cenário ideal para aumentar a confiabilidade nos resultados, garantindo a integridade do conteúdo propagado.
REFERÊNCIAS
ALI, A. A.; et al. Proactive Detection of Malicious Webpages Using Hybrid Natural Language Processing and Ensemble Learning Techniques. Journal of Information and Organizational Sciences, v. 48, n. 2, p. 295-309, 18 dez. 2024.
ALNASSER, S.; ALMUHAIDEB, S. Listening to Patients: Advanced Arabic Aspect-Based Sentiment Analysis Using Transformer Models Towards Better Healthcare. Big Data and Cognitive Computing, v. 8, n. 11, p. 156, 14 nov. 2024.
ALSAEDI, T. et al. Sentiment Mining in E-Commerce: The Transformer-based Deep Learning Model. International Journal of Electrical and Computer Engineering Systems, v. 15, n. 8, p. 641–650, 16 set. 2024.
AL-WESABI, F. N. et al. Low-Resource Language Processing Using Improved Deep Learning with Hunter–Prey Optimization Algorithm. Mathematics, v. 11, n. 21, p. 4493, 30 out. 2023.
BARBOSA, J. et al. Introdução ao processamento de linguagem natural usando python. III Escola Regional de Informatica do Piauí, v. 1, p. 336-360, 2017.
CAMÕES, L. V. Os Lusíadas. 2012. Disponível em: https://ebooksbrasil.org/eLibris/Ivsiadas.html Acesso em: 5 de janeiro de 2025.
CAMPOS, W. P.; FARINA, R. M.; FLORIAN, F. Inteligência Artificial: Machine Learning na Gestão Empresarial. RECIMA21-Revista Científica Multidisciplinar-ISSN 2675-6218, v. 3, n. 6, p. e361617-e361617, 2022.
CARVALHO, André CARLOS Ponce de Leon et al. Inteligência Artificial: riscos, benefícios e uso responsável. Estudos Avançados, v. 35, p. 21-36, 2021.
CASELI, H. M.; NUNES, M. G. V. Processamento de Linguagem Natural: Conceitos, Técnicas e Aplicações em Português. 2. ed. São Carlos: BPLN, 2024. 796p.
CASWELL, Isaac et al. Language ID in the wild: Unexpected challenges on the path to a thousand-language web text corpus. arXiv preprint arXiv:2010.14571, 2020.
CHAKA, C. Detecting AI content in responses generated by ChatGPT, YouChat, and Chatsonic: The case of five AI content detection tools. Journal of Applied Learning and Teaching, v. 6, n. 2, 2023.
CHEN, M.; DECARY, M. Artificial intelligence in healthcare: An essential guide for health leaders. Healthcare Management Fórum, v. 33, n. 1, p. 10–18, jan. 2020.
DAMACENO, S. S.; VASCONCELOS, R. O. Inteligência Artificial: uma breve abordagem sobre seu conceito real e o conhecimento popular. Caderno De Graduação -Ciências Exatas E Tecnológicas -UNIT -SERGIPE, v. 5, n. 1, 2018.
DÍAZ-GUIO, D. A.; et al. Artificial intelligence, applications and challenges in simulation-based education. Colombian Journal of Anesthesiology, v. 52, n. 1, p. 1-6, set. 2023.
DWIVEDI, Y. K. et al. Opinion Paper: “So what if ChatGPTwrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. International Journal of Information Management, v. 71, p. 102642, ago. 2023.
FIGUEIREDO, A. L. Quais os navegadores mais usados do Brasil? 2024. Disponível em: https://olhardigital.com.br/2024/02/19/internet-e-redes-sociais/quais-os-navegadores-mais-usados-do-brasil Acesso em: 01 de janeiro 2025.
FIGUEIREDO, F. J. G. et al. Impacto da IA na produtividade científica: uma revisão sistematizada. Revista Foco, v. 18, n. 1, p. e7398-e7398, 2025.
GERHARDT, T. E.; SILVEIRA, Denise Tolfo. Métodos de pesquisa. Plageder, 2009.
GIL, A. C. Como elaborar projetos de pesquisa. 4. ed. São Paulo: Atlas, 2007. 192 p.
HAQUE, R. R.; BRITO, I. M.; FRADE, S. Copilot e ChatGPT: Como utilizar ferramentas de IA na análise de dados. In M. Prada (Coord.). Caderno de laboratório: Guia prático para investigadores/as, Lapso-Laboratório de Psicologia, v. 1, p. 96-106, 2024.
HUA, H.; YAO, C. Investigating generative AI models and detection techniques: impacts of tokenization and dataset size on identification of AI-generated text. Frontiers in Artificial Intelligence, v. 7, p. 1469197, 2024.
KALBHOR, S.; GOYAL, D.; SANKHLA, K. Taming Misinformation: Fake Review Detection on Social Media platform using Hybrid Ensemble Technique. International Journal of Electrical and Electronics Research, v. 12, n. Special issue, p. 27-33, 28 mar. 2024.
KAR, S. K.; et al. How sensitive are the free AI-detector tools in detecting AI-generated texts? A comparison of popular AI-detector tools. Indian Journal of Psychological Medicine, p. 02537176241247934, 2024.
LATINA, J. V. et al. Utilization of NLP Techniques in Plagiarism Detection System through Semantic Analysis using Word2Vec and BERT. Anais… In: 2024 International Conference on Expert Clouds and Applications (ICOECA). Bengaluru, India: IEEE, 18 abr. 2024.
LISPECTOR, C. A última entrevista. [Entrevista concedida ao repórter Júlio Lerner]. Jornal Opção, São Paulo, 1977.
LUCCHI, N. ChatGPT: a case study on copyright challenges for generative artificial intelligence systems. European Journal of Risk Regulation, v. 15, n. 3, p. 602-624, 2024.
MINDNER, L.; SCHLIPPE, T.; SCHAAFF, K. Classification of human-and ai-generated texts: Investigating features for chatgpt. Anais… In: International conference on artificial intelligence in education technology. Singapore: Springer Nature Singapore, 2023. p. 152-170.
MORAES, F. S. Detecção de textos gerados pelo ChatGPT: capacidades, limitações e aplicações práticas. Revista de Ciências do Estado, Belo Horizonte, v. 9, n. 2, p. 1–21, 2024.
NEVES, M. Redação nota 1000 no enem 2001. 2012. Disponível em: https://pt.slideshare.net/slideshow/redao-nota-1000-no-enem-2001/13699582 Acesso em: 01 de janeiro de 2025.
PALMER, D. Text Preprocessing. In: Indurkhya N.; Damerau, F. (Ed.) Handbook of Natural Language Processing – Second Edition. CRC Press. p. 9-30, 2010.
RAUTA, C. R. V. S.; SILVA, K. F. Gêneros e tipos textuais. Revista de Educação a Distância do IFSC, v. 1, n. 2, p. 57-67, 2024.
WEBER-WULFF, Debora et al. Testing of detection tools for AI-generated text. International Journal for Educational Integrity, v. 19, n. 1, p. 26, 2023.
XU, Z.; SHENG, V. S. Detecting AI-Generated Code Assignments Using Perplexity of Large Language Models. Proceedings of the AAAI Conference on Artificial Intelligence, v. 38, n. 21, 23155–23162. 24 mar. 2024.
1 Este artigo é resultado do projeto de pesquisa e desenvolvimento ARANOUÁ financiado pela Samsung Eletrônica da Amazônia Ltda nos termos da Lei Federal no 8.387/1991, de acordo com o art. 21 do Decreto no 10.521/2020. Agradecemos, também, ao Instituto Federal do Amazonas (IFAM) pelo suporte institucional e incentivo acadêmico para a realização deste trabalho.
2Acadêmica do curso de Tecnologia em Análise de Desenvolvimento de Sistemas (TADS) do campus Manaus Centro do Instituto Federal de Educação, Ciência e Tecnologia do Amazonas (Ifam) e bolsista do projeto ARANOUÁ.
3É professor o curso de Tecnologia em Análise de Desenvolvimento de Sistemas (TADS) do campus Manaus Centro do Instituto Federal de Educação, Ciência e Tecnologia do Amazonas (Ifam) e professor tutor no Projeto ARANOUÁ.