REGISTRO DOI: 10.5281/zenodo.10065477
Gerson Henrique Celestino Santos1
Resumo
A longevidade é um ponto importante a se pensar ao desenvolver um sistema. Com o passar do tempo se torna necessário fazer alterações em um software existente, e dependendo da implementação, essas mudanças têm um alto custo. Softwares que possuem um grande acoplamento em seus módulos são de difícil mudança, pois uma pequena alteração em uma parte do sistema pode gerar problemas em toda a sua extensão. Visando a construção de sistemas de fácil manutenção ao passar do tempo que foi desenvolvido este trabalho. São mostrados conceitos de engenharia e arquitetura de software para posteriormente apresentar a Arquitetura Limpa como uma opção para construir sistemas com uma boa manutenção. São apresentados dois sistemas web em React, um utilizando o Create React App, padrão de criação de um projeto em React, e outro utilizando a Arquitetura Limpa. No final são apresentadas as vantagens em utilizar a Arquitetura Limpa em grandes sistemas.
Palavras-chaves: Arquitetura Limpa, Engenharia de Software, React, Evolução de Software, Sistemas Web.
Introdução
A utilização de sistemas computacionais se torna cada vez mais presente e essencial na sociedade. Desde tarefas cotidianas, como pedir refeições pelo celular e fazer transações bancárias, até a realização esporádica de exames de imagem fazem uso de softwares. Para manter essa demanda crescente é necessário produzir e manter softwares dentro de custos adequados, visando o crescimento e a otimização do mesmo sem prejudicar o que já foi desenvolvido.
A engenharia de software é uma disciplina da engenharia que se preocupa com todos os aspectos da produção de software, tendo como principais atividades a especificação, o desenvolvimento, a validação e a evolução do software (SOMMERVILLE, 2010). Como o software é abstrato e não limitado a leis físicas, isso simplifica a engenharia de software. Do mesmo modo que essa simplificação fornece poder para que o desenvolvedor construa aplicações de maneira otimizada, a falta de restrição também pode tornar o software em algo complexo e difícil de manter.
Como as construções físicas são compostas de componentes menores como tijolo, concreto ou madeira, as construções de softwares são compostas por componentes de softwares que são feitos de outros componentes de softwares, e ambos os tipos de construções possuem uma arquitetura por trás com o objetivo de manter essa estrutura firme e segura. Um conceito da engenharia de software essencial para esse estudo é o de arquitetura de software. A arquitetura de software de um programa ou sistema computacional é a estrutura ou estruturas do sistema, que abrange os componentes de software, as propriedades externamente visíveis desses componentes e as relações entre eles (BASS; CLEMENTS; KAZMAN, 2012).
As mudanças que ocorrem durante o desenvolvimento de software são inevitáveis, e uma boa arquitetura tem como objetivo diminuir o tempo para executar essa mudança, que consequentemente diminui os custos financeiros e esforço. Uma arquitetura deve além de atender as demandas imediatas dos usuários, desenvolvedores e proprietários atender também essas expectativas ao longo do tempo (MARTIN, 2017).
Do mesmo modo que na arquitetura de construções existem diferentes estilos, como por exemplo o clássico, o romântico e o barroco, na arquitetura de software existem tipos arquiteturais como a Arquitetura Cliente-Servidor (Client-server Architecture), o Padr˜ao MVC (Model-view-controller pattern) e a Arquitetura Limpa (Clean Architecture).
Uma arquitetura não deve apenas atender as demandas dos usuários, desenvolvedores e proprietários em um determinado momento, mas também corresponder a essas expectativas ao longo do tempo. Robert MARTIN (2017) propôs a Arquitetura Limpa com o objetivo de promover a implementação de sistemas coesos, independentes de tecnologia e favorecendo a reusabilidade do código.
Como a Arquitetura Limpa é independente de tecnologia, ela pode ser aplicada em todos os contextos do desenvolvimento de software. Uma das aplicações é na área do desenvolvimento web, sendo utilizada para estruturar aplicações tanto a nível de front-end (parte que lida com a interface do usuário, ou seja, com o que o usuário vê e interage) quanto de back-end (parte que cuida do lado do servidor, onde busca as informações a serem apresentadas na tela). Neste trabalho será utilizada a biblioteca JavaScript React.
O React é uma biblioteca JavaScript de construção de interface de usuário, surgindo em 2011, no Facebook. Em 2012, passou a integrar também a área de tecnologia do Instagram e de várias outras ferramentas da empresa. Em 2013, tornaram o código do projeto open-source para a comunidade e desde então sua popularização só cresceu.
Uma das maneiras de iniciar um projeto React, de acordo com sua documentação oficial, é através do comando de terminal Create React App (CRA). O CRA é um boilerplate (na computação, boilerplate code são trechos de códigos que podem ser reutilizados diversas vezes sem precisar de alguma alteração, ou muito pouca) que gera o projeto com todas as pré configurações básicas prontas para executar a aplicação sem muito esforço.
Apesar da facilidade para inicializar um projeto React, você não pode fazer customizações adicionais fora do contexto da estrutura provida pelo boilerplate. A aplicação é inicializada engessada, não podendo alterar configurações do jest, webpack ou typescript e até mesmo o arquivo index da aplicação, pois tudo vem pré-configurado para a execução do sistema, tendo essas configurações ocultas para o desenvolvedor
Pensando na longevidade do software e nas mudanças tecnológicas, o arquiteto de software responsável pelo projeto deve estruturar a aplicação para que ela consiga ser facilmente adaptável independente da versão da tecnologia utilizada. Ao ser lançada uma nova versão da tecnologia a aplicação deve poder ser facilmente migrada. Caso seja a decisão do projeto de mudar a tecnologia, o ideal é apenas mudar o framework sem mudar as regras de negócio atreladas à aplicação.
Analisando uma aplicação front-end planejada para longo prazo e desenvolvida com React, e não apenas um Produto Mínimo Viável (MVP, de Minimum Viable Product), criar uma aplicação com o CRA não é a melhor solução. Como o constantemente lançamento de novas versões do Reactor e o avanço de outros frameworks javascript/typescript trazem outras possibilidades e melhorias, a aplicação terá que se adaptar às mudanças sem que seja necessário um trabalho custoso (tanto em tempo quanto em recurso operacional).
Engenharia de Software
Quando se fala em desenvolvimento de sistemas computacionais logo se pensa na criação de códigos que atendem a uma determinada finalidade. Entretanto, a engenharia de software vai muito além de apenas codificar, ela diz respeito à documentação associada e aos dados de configuração essenciais para o correto funcionamento do programa. Um software raramente é apenas um programa, e sim um conjunto de vários programas menores que através de arquivos de configuração fazem o sistema funcionar como um todo.
A engenharia de software é uma disciplina da engenharia focada em todos os aspectos da produção de software, desde a especificação do sistema até a sua manutenção ao os estar em produção (SOMMERVILLE, 2010). A engenharia tem como foco escolher um método mais adequado para uma situação específica, logo, na engenharia de software também é necessário um planejamento e faz-se uso de diferentes processos para cada tipo de sistema. Ela é uma abordagem sistemática, analisando questões práticas de custos, prazo, confiança, necessidade dos clientes e dos produtores do software. Existem diferentes processos de criação de software, mas todos devem ter quatro atividades em comum para a engenharia de software: especificação, projeto e implementação, validação e evolução.
Na especificação de software, também chamada de engenharia de requisitos, é feita a definição dos serviços necessários e das restrições na operação e no desenvolvimento do sistema. Este é um processo de extrema importância no desenvolvimento, pois uma escolha errada pode acarretar problemas futuros em todo o sistema.
O projeto e implementação é o processo onde são transformadas as especificações, previamente definidas, em um sistema executável. No projeto de software é realizada a descrição da estrutura a ser implementada, dos modelos e estruturas de dados do sistema, das interfaces entre os componentes e dos algoritmos usados. O projeto final não é concluído imediatamente, são acrescentados novos detalhes durante o seu desenvolvimento e feitas constantes revisões para correção de projetos anteriores.
O objetivo da validação de software é mostrar que o sistema se adequa às especificações definidas e satisfaz as necessidades do cliente. Essa validação pode ser feita através de testes de programa, em que o sistema é executado com dados de testes simulados, e por meio de inspeções e revisões em todas as etapas do processo de software.
Dentre os quatro processos, a evolução do software é o mais relevante para esse trabalho. Sempre houve uma separação entre os processos de desenvolvimento e evolução de software, pois as pessoas que pensam no desenvolvimento como uma atividade interessante e importante veem a manutenção de software como maçante e desinteressante (SOMMERVILLE, 2010). Entretanto, essa separação entre o desenvolvimento e a manutenção se torna cada vez mais irrelevante, dado que, em vez de serem dois processos separados, é um único processo em evolução. O sistema é alterado ao longo do tempo para acompanhar as mudanças de requisitos e necessidades do cliente.
Figura 1 – Evolução de um Software
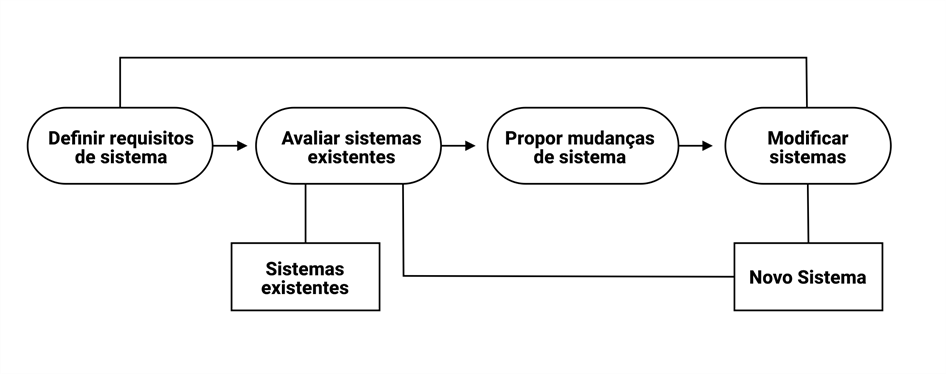
Fonte: adaptada de MARTIN (2017).
Todo sistema computacional está propenso à mudanças. Com o passar do tempo surgem novos requisitos e tecnologias que podem melhorar o funcionamento de um software e o custo dessas mudanças é alto, pois muitas vezes é necessário refazer uma grande parte do sistema. Monitorar a complexidade de fazer mudanças em um sistema de software em evolução e medir seu efeito na qualidade do software são essenciais para uma prática de engenharia de software madura (KOUROSH FAR et al., 2015).
Dito isso, percebe-se que é essencial que um sistema seja capaz de receber alterações ao longo do tempo de uma forma simples e com baixo custo. Uma das formas de ter um sistema pronto para receber alterações é a escolha de uma boa Arquitetura de Software.
Arquitetura Limpa
O conceito de Arquitetura Limpa foi definido por Robert C. Martin (MARTIN, 2017) no seu livro intitulado ”Arquitetura Limpa: O guia do artesão para estrutura e design de software”. Como visto no tópico 2.2, uma boa arquitetura deve suportar os casos de uso e operação do sistema, a manutenção, o desenvolvimento e a implantação do sistema. Os sistemas podem ser divididos em dois elementos principais: a política e os detalhes. A política são as regras e procedimentos de negócio e os detalhes são os itens necessários para a realização da política. (MARTIN, 2017) É a partir dessa divisão que a Arquitetura Limpa começa a se diferenciar dos outros padrões arquiteturais. Banco de dados, sistemas web, servidores, protocolos de comunicação são apenas alguns exemplos dos detalhes citados no livro. O arquiteto deve criar uma forma do sistema reconhecer a política como elemento principal do sistema, e os detalhes como elementos irrelevantes para a política. Ao deixar as opções abertas por um tempo maior, mais experimentos e testes poderão ser realizados, e, com isso, o desenvolvedor terá mais segurança para tomar decisões (MARTIN, 2017).
Na arquitetura limpa não é necessário escolher no início do desenvolvimento o banco de dados, o servidor web adotar um framework ou Transferência de Estado Representacional (REST), pois todos esses são detalhes que não interferem na política e consequentemente podem ser alterados ao longo do tempo.
Divisão de Responsabilidade
Existem diversas Arquiteturas de Software com detalhes que diferem entre si. Entretanto toda arquitetura tem o objetivo comum de dividir o software em camadas, tendo pelo menos uma camada para as regras de negócio e uma para as interfaces de usuário e sistema (MARTIN, 2017).
Na Arquitetura Limpa há uma divisão de camadas bem definida. A arquitetura possui independência de framework, ou seja, não depende de nenhuma biblioteca de software carregada de recursos, o que permite ao desenvolvedor utilizar um framework como ferramenta e não adaptar o sistemas para atender as especificações de um determinado framework. Outras características da Arquitetura Limpa são a testabilidade, a independência da UI, a independência do banco de dados e a independência de qualquer agente externo. A estabilidade faz com que as regras de negócio possam ser testadas sem a UI, sem o banco de dados e sem qualquer elemento externo. A independência da UI expõe que a UI pode ser substituída sem alterar o sistema, como por exemplo trocar de uma interface web por uma de console sem alterar as regras de negócio. A independência de banco de dados define que o banco pode ser substituído do Oracle para o CouchDB por exemplo, sem afetar o sistema, uma vez que as regras de negócio não são ligadas à base de dados. Por último é citada a independência de qualquer agente externo, pois as regras de negócio não devem saber nada sobre as interfaces do mundo externo.
Para ilustrar todos esses conceitos foi criado um diagrama apresentado na Figura 2.
Figura 2 – Diagrama de Camadas da Arquitetura Limpa
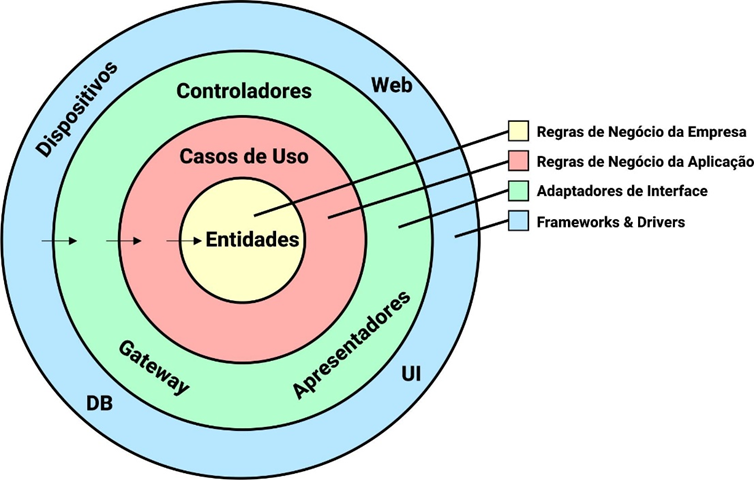
Fonte: adaptada de MARTIN (2017).
Cada círculo da Figura 2 representa uma área diferente do software, sendo na parte mais interna as políticas e na mais externa os mecanismos. A regra principal para a Arquitetura Limpa e a Regra da Dependência, que diz que as dependências de um código fonte devem sempre apontar apenas para dentro, ou seja, na direção das políticas de nível mais alto. Dito isto, podemos afirmar que os elementos de um círculo mais interno não podem ter nenhuma informação sobre os elementos de um círculo mais externo. As classes, funções, variáveis, formato de dados ou qualquer entidade declarada em um círculo externo não deve ser mencionada pelo código de um círculo interno.
O círculo mais interno é o de Entidades, nele estão reunidos os objetivos de negócios da aplicação, contendo as regras mais gerais e de nível mais alto. Uma entidade pode ser um conjunto de estrutura de dados e funções ou um objeto com métodos, contanto que essa entidade possa ser usada por diversas aplicações. Essa camada não deve ser alterada por mudanças nas camadas mais externas, ou seja, nenhuma mudança operacional em qualquer aplicação deve influenciar nesta camada.
A camada de casos de uso contém as regras de negócio específicas da aplicação, agrupando e implementando todos os casos de uso do sistema. Os casos de uso organizam o fluxo de dados, para e a partir das entidades, e orientam as entidades na aplicação das Regras Cruciais de Negócios para atingir os objetivos do caso de uso (MARTIN, 2017). Essa camada também não deve ser afetada pelas camadas mais externas e suas mudanças não devem afetar a camada de entidades. Entretanto, se os detalhes de um caso de uso mudarem, uma parte do código desta camada será afetada.
A camada de adaptadores de interface possui um conjunto de adaptadores que fazem a conversão dos dados para o formato mais conveniente para as camadas ao seu redor. Em outras palavras, ela pega os dados de uma base de dados, por exemplo, e converte para o formato mais conveniente para as camadas de entidades e casos de uso. O caminho inverso de conversão também pode ser feito, dos dados das camadas mais internas para as camadas mais externas. Os apresentadores, visualizações e controladores pertencem a esta camada.
A camada mais externa do diagrama geralmente é composta pelos frameworks, base de dados e frameworks web. Nessa camada é feito o código que estabelece a comunicação com a camada de adaptadores de interface. Todos os detalhes ficam nessa camada, Todos os detalhes ficam nessa camada, a web é um detalhe, base de dados é um detalhe, e todos esses elementos ficam na camada mais externa para não correr risco de causar interferências nas demais (MARTIN, 2017).
Mas se as camadas são tão independentes, como é feita a comunicação entre elas? Essa contradição é resolvida com o Princípio de Inversão de Dependência. Robert C. MARTIN (2017) expõe que pode-se organizar as interfaces e relacionamentos de herança para que as dependências do código fonte fiquem opostas ao fluxo do controle nos pontos certos. Se um caso de uso precisa se comunicar com o apresentador, essa chamada não pode ser direta, pois violaria a Regra da Dependência, então o caso de uso chama uma interface do círculo interno e o apresentador no círculo externo que faz a implementação. Essa técnica pode ser utilizada entre todas as camadas da arquitetura. Os dados que trafegam entre as camadas podem ser estruturas básicas ou objetos de transferência de dados simples, sendo esses dados apenas argumentos para chamadas de função. Não devem ser transmitidas entidades ou registros das bases de dados para não violar a Regra da Dependência.
Princípios de Padrão de Projeto
Os princípios S.O.L.I.D., um acrônimo com as iniciais dos princípios abordados a seguir, tem como finalidade organizar as funções e estruturas de dados de forma a facilitar o desenvolvimento de software. O objetivo desses princípios é criar códigos que tolerem mudanças, sejam fáceis de entender e que sejam a base de componentes que possam ser usados em diversos sistemas. A seguir serão definidos cada um desses princípios.
SRP: O Princípio da Responsabilidade Única
Esse princípio mostra que uma classe deve ser especializada em um único assunto e ter apenas uma responsabilidade. Em outras palavras, a classe deve ter uma única ação para executar. MARTIN (2017) reformula a descrição comumente usada, de que um módulo deve ter apenas uma razão para mudar, e disserta que o SRP deve ser descrito como um módulo deve ser responsável por apenas um ator. Esse ator é a representação de um usuário ou stakeholder que são a ”razão para mudar” da definição inicial. O termo módulo pode ser definido como o arquivo-fonte ou um conjunto coeso de funções e estrutura de dados.
A violação desse princípio pode fazer com que uma classe assuma responsabilidades que não são suas, aumentar o nível de acoplamento, gerar dificuldades na implementação de testes automatizados e tornar difícil o reaproveitamento do código.
OCP: O Princípio Aberto/Fechado
Esse princípio foi criado por Bertrand MEYER (1997) e afirma que um software deve ser aberto para extensão, mais fechado para modificação. Ou seja, quando novos recursos precisam ser adicionados no sistema ele deve ser estendido e não alterar o código fonte original.
Segundo MARTIN (2017), o OCP é uma das forças motrizes na arquitetura de sistemas. Para que seja possível cumprir com o objetivo de o sistema ser fácil sem que essa mudança cause um impacto grande é preciso dividir o sistemas em componentes. Esses componentes são organizados em uma hierarquia de dependências, de forma a proteger os componentes de alto nível das mudanças realizadas em componentes de níveis inferiores.
LSP: O Princípio de Substituição de Liskov
O Princípio da Substituição de Liskov foi definido por Barbara Liskov e disserta sobre usar como base a propriedade de substituição o que fala: se, para cada objeto o1 de tipo SE, houver um objeto o2 de tipo T, de modo que, para todos os programas PRÉ definidos em termos de T, o comportamento de P não seja modificado quando o1 for substituído por o2, então S é um subtipo de T.1 (MEYER, 1997).
Em outras palavras, o LSP diz que se S é um subtipo de T, então os objetos do tipo T em um programa podem ser substituídos pelos objetos de tipo S sem a necessidade de alterar as propriedades desse sistema.
O LSP se transformou em um princípio mais amplo de padrão de projeto, podendo ser aplicado em interfaces e implementações. Essas interfaces podem ter diversas formas, como por exemplo uma interface no estilo Java implementada por várias classes. A aplicação do LSP é importante, pois os usuários precisam de interfaces bem definidas e dessa capacidade de substituição de implementação das interfaces. Esse princípio deve ser aplicado à arquitetura, dado que uma violação na capacidade de substituição pode contaminar a arquitetura do sistema com uma grande quantidade de mecanismos extras (MARTIN, 2017). Alguns exemplos do que pode acontecer ao violar esse princípio: lançar uma exceção inesperada, sobrescrever ou implementar um método que não faz nada, e retornar valores de tipos diferentes da classe base.
ISP: O Princípio da Segregação de Interface
Esse princípio mostra que uma classe não deve ser forçada a implementar interfaces e métodos que não vai utilizar, ou seja, é melhor criar interfaces mais específicas do que ter uma grande interface genérica. Utilizando esse princípio na arquitetura pode-se afirmar que é prejudicial depender de módulos com muitos elementos desnecessários. Isso é válido tanto em níveis arquiteturais mais altos quanto mais baixos, como por exemplo as dependências de código fonte podem forçar de forma desnecessária a compilação e implantação.
DIP: O Princípio da Inversão de Dependências
Sobre o Princípio de Inversão de Dependências, MARTIN (2017) expõe que os sistemas mais flexíveis são aqueles nos quais as dependências de ćodigo-fonte se referem apenas a abstrações e não a itens concretos. Aplicando a Arquitetura Limpa os módulos de alto nível não devem depender de módulos de baixo nível, os dois devem depender da abstração. As abstrações não devem depender de detalhes e sim os detalhes que devem depender das abstrações.
Algumas classes, como por exemplo a classe String, são concretas, então não seria interessante forçá-las a ser abstratas. Entretanto, essas classes são muito estáveis de forma que as mudanças nelas são muito raras e controladas, logo não é necessário se preocupar com essas mudanças. Classes concretas são toleráveis pois sabe-se que elas não irão mudar.
Princípios dos Componentes
Componentes são as menores entidades que podem ser implementadas em um sistema, por exemplo, em Java são os arquivos jar (MARTIN, 2017). Esses componentes podem ser reunidos em um executável, em um único arquivo ou implementados de forma independente como plugins separados carregados dinamicamente, um exemplo o .exe. Utilizando qualquer uma das formas de implementação, desde que um componente tenha sido bem projetado, ele tem a capacidade de ser desenvolvido e implementado de forma independente.
Fazendo uma breve retrospectiva na história dos componentes, nota-se que na década de 1980 as bibliotecas eram carregadas nos programas por meio de ligadores, que nada mais eram do que segmentos compiláveis e recarregáveis. Entretanto, com o desenvolvimento tecnológico, o aumento da complexidade dos programas e o uso de linguagens de alto nível, o tempo de compilação desses módulos era muito elevado e estava prestes a se tornar inviável. Contudo, no fim da década de 1980 os discos começaram a diminuir e ficar mais rápidos, diminuindo bastante esse tempo de compilação. Nos meados dos anos 1990, o tempo gasto com ligação diminuiu bastante, em alguns casos passou de 1 hora para alguns segundos. Os computadores e dispositivos ficaram tão rápidos que se tornou possível fazer a ligação na hora do carregamento, podendo ligar arquivos ou bibliotecas compartilhadas em segundos e a partir daí executar o programa. Foi assim que surgiu a arquitetura e o plugin de componentes (MARTIN, 2017).
Coesão de Componentes
Decidir quais classes pertencem a quais componentes é uma decisão importante e que faz uso de princípios de engenharia de software. A seguir serão apresentados os três princípios da coesão de componentes (MARTIN, 2017).
REP: Princípio da Equivalência do Reúso/Release
Esse princípio fala que para se reutilizar componentes de software estes devem ser rastreados por um processo e recebam números de release. Sem esses números não seria possível garantir a compatibilidade dos componentes uns com os outros. Outra importância desse número é para que os desenvolvedores saibam quando serão lançados novos releases e quais mudanças eles contemplarão. Por isso, deve-se gerar notificações e produzir documentos para que o usuário tome a decisão de migrar para o novo ou continuar com o antigo.
Analisando esse princípio por intermédio da arquitetura de software pode-se concluir que os módulos e classes formados em um componente devem fazer parte de um grupo coeso, de forma que o componente não seja uma mistura de classes e modelos aleatórios, mas sim ter um tema ou propósito que todos os módulos compartilhem. MARTIN (2017) expressa que as classes e os módulos agrupados em um componente devem poder ter um release em conjunto, pois ao compartilhar a mesma versão, o mesmo rastreamento de release e estarem na mesma documentação facilita o entendimento tanto do autor quanto dos usuários.
CCP: Princípio do Fechamento Comum
O Princípio do Fechamento Comum discorre que deve-se reunir em componentes as classes que mudam pelas mesmas razões e nos mesmos momentos, e separar em diferentes componentes as classes que mudam em momentos distintos e por diferentes razões (MARTIN, 2017).
Esse princípio é uma reformulação do Princípio de Responsabilidade Única (SRP) visto no tópico 3.3.1 aplicando-o para componentes. Assim como SRP afirma que uma classe não deve ter muitos motivos para mudar, o CCP declara que um componente não deve ter muitos motivos para mudar.
Quando é necessário fazer uma mudança em um código, o ideal é que essas mudanças ocorram em apenas um componente, não em vários. Assim, é necessário implementar novamente apenas o componente modificado, sem alterar os demais. Por isso, o CCP alega que todas as classes que têm alta probabilidade de mudar pelas mesmas razões, sejam reunidas no mesmo lugar. Se duas ou mais classes são fortemente ligadas e sempre mudam juntas, elas devem pertencer ao mesmo componente, para assim, reduzir a quantidade de trabalho de reimplantar, revalidar e fazer release do software.
O CCP também se relaciona com mais um princípio do SOLID, o Princípio Aberto/Fechado (OCP), visto no tópico 3.1.2, sendo o termo ”fechado” usado em ambos com o mesmo sentido. O OCP afirma que as classes devem ser fechadas para modificações, mas abertas para extensões. Por não ser possível ter um fechamento completo, as classes são projetadas de modo que fiquem fechadas para a maioria dos tipos de mudanças esperados ou observados. O CCP desenvolve essa definição ao reunir em um mesmo componente as classes fechadas para os mesmos tipos de mudanças, de forma que ao ocorrer uma modificação nos requisitos ela tenha uma grande chance de se limitar a uma quantidade reduzida de componentes.
CRP: Princípio do Reúso Comum
Este princípio atesta que as classes e módulos que inclinam-se a ser reutilizados juntos pertencem a um mesmo componente (MARTIN, 2017). Devido ao fato das classe raramente serem utilizadas isoladamente é esperado que diversas classes que fazem parte da abstração reutilizável colaborem umas com as outras. Portanto, segundo o CRP, essas classes devem pertencer a um mesmo componente, tendo elas várias dependências entre si.
Acoplamento de Componentes
Sobre o acoplamento dos componentes também existem três princípios que abordam os relacionamentos entre os componentes.
O Princípio das Dependências Acíclicas
Um dos maiores erros de desenvolvedores com pouca experiência é ter várias pessoas trabalhando em um mesmo código. Por causa dessa falta de divisão de um sistema é muito comum que a medida em que um problema é resolvido por um desenvolvedor, outro problema surge na parte de responsabilidade de outra pessoa.
Para evitar que isso aconteça é preciso particionar o ambiente de desenvolvimento em componentes passíveis de release (MARTIN, 2017). Assim, cada componente se torna um ambiente de trabalho sob a responsabilidade de um desenvolvedor ou de uma equipe. Ao fazer este componente funcionar é gerada uma versão para ser usada pelas outras equipes, após isto, os desenvolvedores voltam a trabalhar em suas áreas privadas até ter uma outra versão. As demais equipes podem decidir se já começam a usar o novo release ou continuam com o antigo. Dessa forma, as mudanças de um componente não precisam ter efeito imediato nas outras equipes, sendo responsabilidade de cada uma decidir quando adaptar os seus componentes para o novo release.
O Princípio de Dependências Estáveis
O Princípio de Dependências Estáveis afirma que os projetos não podem ser completamente estáticos, que alguma volatilidade é necessária para manter o design. Ao utilizar o Princípio do Fechamento Comum são criados componentes sensíveis a algumas mudanças, mas não a outras. Alguns desses componentes são criados para serem voláteis, logo espera-se que eles mudem (MARTIN, 2017).
Ao utilizar o Princípio de Dependências Estáveis garante-se que um módulo difícil de mudar não dependa de um componente volátil, pois isso faria com que o componente volátil se tornasse difícil de alterar. A estabilidade de algo está relacionada com o trabalho necessário para fazer uma mudança. Aplicado a software, existem diversos fatores que tornam um componente difícil de mudar, como por exemplo o tamanho, a clareza e a complexidade. Uma maneira segura de fazer com que um componente seja difícil de mudar é fazer com que outros componentes dependam dele, já que isso requer muito trabalho para conciliar mudanças com todos os seus dependentes (MARTIN, 2017).
Contudo, nem todos os componentes devem ser estáveis, pois isso deixaria o sistema imutável. É necessário projetar a estrutura de componentes de forma a ter componentes estáveis e instáveis.
O Princípio de Abstrações Estáveis
Este princípio estabelece uma relação entre estabilidade e abstração. Ele afirma que um componente estável também deve ser abstrato para que a estabilidade não impeça a sua extensão, e que um componente instável deve ser concreto, posto que sua instabilidade faz com que o seu código concreto seja facilmente modificado. Por consequência, para um componente ser estável ele deve possuir interfaces e classes abstratas de modo que possa ser estendido (MARTIN, 2017).
Camadas e Limites
Um sistema pode ser definido por três componentes básicos, a UI, as regras de negócio do banco de dados, sendo que em sistemas maiores existem muito mais componentes. Para explicar o conceito de camadas e limites será utilizado o exemplo feito por MARTIN (2017) que descreve sobre o jogo da década de 1970 chamado Hunt the Wumpus.
As regras do jogo são irrelevantes para esse exemplo, pois o foco será na implementação em si. Considerando que é utilizada uma UI baseada em texto, faz-se necessário desacoplar as regras do jogo para que ele possa ter diferentes idiomas. As regras se comunicarão com a UI utilizando uma API, independente do idioma, e a UI que fará a tradução para o idioma solicitado. Dessa forma todos os componentes da UI poderão fazer uso das mesmas regras do jogo. Supondo que o estado do jogo é mantido em um armazenamento persistente, não é preciso que as regras do jogo conheçam os detalhes, logo será criada uma API para fazer a comunicação dessas regras com o componente de armazenamento de dados. As regras do jogo também não devem saber sobre os diferentes tipos de armazenamento de dados, logo as dependências devem ser direcionadas corretamente seguindo a Regra da Dependência, como visto na Figura 3.
Figura 3 – Estrutura Básica do Jogo

Fonte: MARTIN (2017)
Após essa breve descrição e baseando-se na seção 3.1, imagina-se que a arquitetura limpa seria facilmente aplicada nesse exemplo. Entretanto, não estão claros todos os limites arquiteturais. Nesse exemplo o idioma não é o único eixo de mudança da UI, pode ser variado também o mecanismo de comunicação, como por exemplo uma aplicação de chat, uma janela normal ou mensagens de texto. Existem inúmeras possibilidades de mudança, o que mostra que há um limite arquitetural definido por esses eixos de mudança. Portanto, faz-se necessária a criação de uma API para cruzar esse limite e isolar o idioma do mecanismo de comunicação.
Figura 4 – Estrutura do Jogo Reformulada
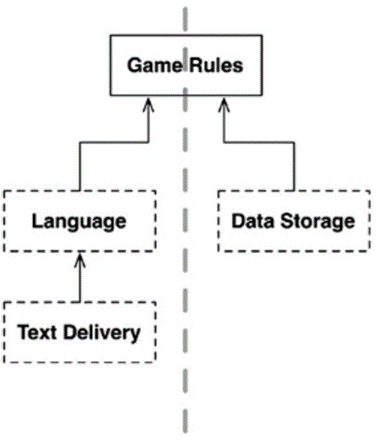
Fonte: MARTIN (2017)
No diagrama da Figura 4, os retângulos pontilhados são as APIs e o retângulo escrito ”Game Rules” são as regras do jogo. O componente das regras do jogo está posicionado no topo do diagrama, pois nele estão as políticas de mais alto nível. Essa organização divide o fluxo de dados, sendo o lado esquerdo para se comunicar com o usuário e o direito para persistência dos dados. À medida que os sistemas vão crescendo, a estrutura de componentes pode se dividir em diversos fluxos com diferentes hierarquias, o que deixa a arquitetura cada vez mais complexa.
Esse exemplo simples tem a finalidade de mostrar que existem limites arquiteturais em todos os lugares, e que cabe aos arquitetos de software reconhecer as necessidades. É preciso saber também que a implementação desses limites é algo caro, porém, ao mesmo tempo, se não implementados no início do desenvolvimento podem ter custos ainda maiores ao longo do tempo. MARTIN (2017), conclui esse assunto afirmando que o papel do arquiteto de software é avaliar os custos, determinar os limites arquiteturais e quais desses limites devem ser implementados por completo, quais devem ser implementados parcialmente e quais devem ser ignorados. Além disso, reforça que essas decisões não são tomadas uma única vez, que é necessário observar a evolução do sistema, analisar onde os limites podem ser necessários e o que pode acontecer caso não tenham limites bem definidos. Reforça-se a importância de comparar os custos de implementação desses limites com o custo de ignorá-los, buscando sempre implementar os limites certos no ponto ideal onde o custo de implementação seja menor do que o de ignorar.
Conclusão
A arquitetura do sistema Marvel Finder CRA apesar de ser mais difícil de ser testada por ter um grande acoplamento e ser mais difícil de escalar com qualidade de código, talvez seja a melhor opção para sistemas pequenos que não lidam com tantas requisições (de preferência páginas estáticas). De acordo com as análises referentes ao Create React App dos capítulos anteriores, isso ocorre devido sua fácil inicialização com as configurações de construção da aplicação prontas.
A Arquitetura Limpa ajuda a manter e evoluir a aplicação sem que seja necessário muito custo (seja de recurso físico ou tempo). Essa ajuda se dá pelo fato de suas camadas serem independentes e pelo uso constante dos padrões de projetos para proporcionar essa independência, com isso as alterações de uma parte determinada do sistema tendem a não interferir com o funcionamento do restante da aplicação.
Ao utilizar JavaScript ou TypeScript como linguagem de programação, as regras de negócio e estrutura da aplicação são escritas na linguagem pura, enquanto as interfaces tendem a usar algum framework para facilitar o desenvolvimento. No experimento foi utilizado React, se no futuro as decisões de projeto mudasse e fosse necessário migrar de React para Vue ou Angular, a divisão em camadas separando as interfaces das regras de negócio permitiria essa mudança sem muitas consequências negativas, uma vez que a camada de apresentação não contém regras de negócio.
Por fim, percebe-se que ambas arquiteturas têm seus pontos positivos e negativos, assim como propósitos. Nota-se a vantagem da arquitetura limpa no quesito evolução e manutenção da aplicação, porém é necessário uma equipe de desenvolvedores mais experientes e com conhecimento mais aprofundado em padrões de projetos para estruturar o sistema. Apesar das desvantagens da arquitetura do sistema com CRA, é uma opção interessante para fins de aprendizado ou se o software for pequeno e não escalável, uma vez que a arquitetura limpa exige mais tempo e recurso.
Referências
BANDARA, Vidudaya; PERERA, Indika. Identifying software architecture erosion through code comments. In: 2018 18th International Conference on Advances in ICT for Emerging Regions (ICTer). [S.l.: s.n.], 2018. p. 62–69.
BASS, Len; CLEMENTS, Paul; KAZMAN, Rick. Software Architecture in Practice. 3rd. ed. [S.l.]: Addison-Wesley Professional, 2012. ISBN 0321815734.
DRAGONI, Nicola et al. Microservices: yesterday, today, and tomorrow. In: . [S.l.: s.n.], 2017.
HAITZER, Thomas; NAVARRO, Elena; ZDUN, Uwe. Architecting for decision making about code evolution. In: Proceedings of the 2015 European Conference on Software Architecture Workshops. New York, NY, USA: Association for Computing Machinery, 2015. (ECSAW ’15). ISBN 9781450333931. Disponível em: ⟨https://doi.org/10.1145/2797433.2797487⟩.
JAILIA, Manisha et al. Behavior of mvc (model view controller) based web application developed in php and .net framework. In: 2016 International Conference on ICT in Business Industry Government (ICTBIG). [S.l.: s.n.], 2016. p. 1–5.
KOUROSHFAR, Ehsan et al. A study on the role of software architecture in the evolution and quality of software. In: Proceedings of the 12th Working Conference on Mining Software Repositories. [S.l.]: IEEE Press, 2015. (MSR ’15), p. 246–257. ISBN 9780769555942.
LE, Duc Minh et al. Relating architectural decay and sustainability of software systems. In: 2016 13th Working IEEE/IFIP Conference on Software Architecture (WICSA). [S.l.: s.n.], 2016. p. 178–181.
MARTIN, Robert C. Clean Architecture: A Craftsman’s Guide to Software Structure and Design. 1st. ed. USA: Prentice Hall Press, 2017. ISBN 0134494164.
MEYER, Bertrand. Object-Oriented Software Construction. 2. ed. Upper Saddle River, NJ: Prentice Hall, 1997. ISBN 978-0-13-629155-8.
SOMMERVILLE, Ian. Software Engineering. 9. ed. Harlow, England: Addison-Wesley, 2010. ISBN 978-0-13-703515-1.
TOOL, S. The Eisenhower Matrix: Task Management Through Notebook, Distinguish Between Urgent & Important Tasks, Make Real Progress In Your Life, Eisenhower Box, How To Be More Productive, Eliminate Time Wasting Activities, Radical Prioritization, Four Quadrant. [S.l.]: Independently Published, 2019. ISBN 9781693780424.
WHITING, Erik; ANDREWS, Sharon. Drift and erosion in software architecture: Summary and prevention strategies. In: Proceedings of the 2020 the 4th International Conference on Information System and Data Mining. New York, NY, USA: Association for Computing Machinery, 2020. (ICISDM 2020), p. 132–138. ISBN 9781450377652. Disponível em: ⟨https://doi.org/10.1145/3404663.3404665⟩.
WOODS, Eoin. Software architecture in a changing world. IEEE Software, v. 33, n. 6, p. 94–97, 2016.