REGISTRO DOI: 10.5281/zenodo.7478198
George Henrique Ferreira dos Santos¹
Lorena Silva Camelo²
Resumo: O ato de avaliar tem relação direta com a Ciência Estatística. Suas representações numéricas podem ser estudadas através da observação dos parâmetros das medidas estatísticas. Por isso, o presente trabalho teve como objetivo principal uma análise dos aspectos estatísticos através do Excel e da Linguagem e observando suas implicações no contexto educacional do município de Fortaleza-CE. Os dados coletados foram os resultados da aplicação das ADRs (ADR-1º aplicação e ADR-2º aplicação). Para tanto, foi feita a limpeza dos dados; organização e tabulação, depois se tirar as principais inferências para as considerações finais. Durante o trabalho houve estudos bibliográficos e testes práticos do software R e Excel para clusterização e organização dos dados educacionais colhidos no setor de Gestão e Escola do Distrito 2 da rede municipal objeto de pesquisa deste referido trabalho.
Palavras-chave: avaliação diagnóstica; análise estatística (Excel e Linguagem R); contexto educacional.
Abstract: The act of evaluating is directly related to Statistical Science. Its numerical representations can be studied through the observation of the parameters of the statistical measures. Therefore, the present work had as main objective an analysis of the statistical aspects through Excel and Language and observing its implications in the educational context of the city of Fortaleza-CE. The collected data were the results of the application of the ADRs (ADR-1st application and ADR-2nd application). For that, the data was cleaned; organization and tabulation, then drawn the main inferences for the final considerations. During the work there were bibliographical studies and practical tests of the R and Excel software for clustering and organization of the educational data collected in the Management and School sector of District 2 of the municipal network object of research of this work.
Keywords: diagnostic evaluation; statistical analysis (Excel and R language); educational context.
1 INTRODUÇÃO
Na avaliação, é comum a contagem de acertos em uma prova aplicada aos estudantes, em que tais valores são utilizados como a escala de medida para esse instrumento. Todavia, a contagem de acertos pouco representa a relação entre as respostas dadas aos itens a sua representação numérica e pedagógica. Quando isso acontece, diz-se que a avaliação utiliza a escala intervalar, em que cada instrumento acaba gerando resultados únicos e não comparáveis.
Dessa forma, realizar-se-á uma análise estatística dos dados coletados, resultados da Avaliação Diagnóstica de Rede durante o ano letivo de 2022, em seguida testar hipóteses sobre a natureza da realidade para o contexto educacional das escolas do município de Fortaleza-CE. Portanto, serão analisadas as principais medidas de tendência central e as principais medidas de variabilidade para que se descreva nas considerações finais deste trabalho se houve ou não evolução da aprendizagem dos alunos durante o ano letivo corrente.
Segundo Levin, Fox, Forde (2012, p.77):
Uma maneira útil de descrever um grupo como um todo é encontrar um único número que represente a média ou algo típico daquele conjunto de dados. Na pesquisa social, tal valor é conhecido como medida de tendência central, porque ela geralmente está localizada no meio ou no centro de uma distribuição em que a maioria dos dados tende a estar concentrado.
Em outras palavras, os autores quiseram dizer que a mensuração das medidas de tendência central descreve um quadro equilibrado dos escores extremos e que estas são utilizadas para representar um conjunto de dados como um todo, identificando as características apresentadas pelo conjunto.
No entanto, quando empregadas, individualmente, qualquer medida de tendência central produz um quadro incompleto com relação a um conjunto de dados e, por isso, pode tanto enganar ou distorcer quanto esclarecer. Por isso, neste estudo analítico, além das medidas de tendência central, também, serão analisadas as medidas de variabilidade (também conhecidas como espalhamento ou dispersão) objetivando o alcance de resultados mais razoáveis para a decisão de tomada: evolução ou não de aprendizagem dos estudantes da rede municipal no contexto da ADR.
Segundo Levin, Fox, Forde (2012, p.98):
Podemos ver que precisamos, além de uma medida de tendência central, de um índice como os escores estão distribuídos em torno do centro de distribuição. Essa medida é denominada de variabilidade, espalhamento ou dispersão.
Em outras palavras, as medidas de dispersão são usadas para determinar a variação em grupos de dados em relação à sua média; garantindo uma melhor colocação dos cálculos e; visando a chegar a um resultado desejado.
Por isso, a prática de avaliar na educação não deve ser restrita ao ato de aplicar provas e testes a fim de atribuir uma nota ao conhecimento do aluno, deve ser algo além disso. Por exemplo, a utilização de outros instrumentos avaliativos serve de apoio à gestão escolar e direciona um processo formativo de professores, cujos resultados podem mensurar e promover melhorias na qualidade do processo de ensino-aprendizagem. Para Luckesi (2005) a avaliação é um panorama da situação da aprendizagem e tais resultados servem para promover tomadas de decisões por parte da gestão escolar e dos professores com o mesmo objetivo, a melhoria da qualidade de ensino.
Uma das ferramentas avaliativas capaz de colher esses resultados é a avaliação diagnóstica que tem como função tomada de decisão, seja pela própria gestão escolar ou políticas públicas, sempre a favor do ensino-aprendizagem. Através dos resultados, o corpo docente pode analisar os conhecimentos e habilidades já adquiridos pelos alunos, antes de iniciar o processo de ensino. Haydt (2000, p.20) acrescenta que:
Não é apenas no início do período letivo que se realiza a avaliação diagnóstica. No início de cada unidade de ensino, é recomendável que o professor verifique quais as informações que seus alunos já têm sobre o assunto, e que habilidades apresentam para dominar o conteúdo. Isso facilita o desenvolvimento da unidade e ajuda a garantir a eficácia do processo ensino – aprendizagem.
Sabendo-se dessa necessidade de colher informações acerca dos conhecimentos e habilidades dos alunos com o fim de planejar ações para a melhoria do ensino-aprendizagem a Secretaria Municipal de Educação (SME) de Fortaleza-CE criou em 2009 o Sistema de Avaliação do Ensino Fundamental (SAEF); inicialmente limitada apenas para as turmas de 1º e 2º ano do ensino fundamental. A partir de 2015 passou a ser chamado de Avaliação Diagnóstica de Rede (ADR) utilizando três etapas de avaliação: inicial, intermediária e final. Atualmente abrange toda rede de ensino: ensino fundamental, anos iniciais e finais; ensino de jovens e adultos.
O SAEF permite, assim, a consolidação dos dados e geração de relatórios, que apresenta o percentual de acertos e erros por aluno; por turma; por escola e na rede de ensino. O que permite a todos os gestores, professores e profissionais lotados na Secretaria de Educação, planejar ações e promover melhorias para os próximos resultados.
Nessa perspectiva são a coleta dos dados educacionais e sua mineração que fornecem informações e fatores associados à aprendizagem do estudante. Também, quais desafios, tanto, a administração pública municipal, estadual e / ou federal irão enfrentar diante das políticas educacionais existentes e o que poderá ser melhorado. Por isso, se faz necessário aprofundar os conceitos estatísticos relacionados à avaliação da aprendizagem e sua potencialidade pedagógica.
Isto é, o uso da estatística mostra como os métodos estatísticos podem ser aplicados à pesquisa. Considerando a análise de variáveis categóricas e de variância para esse trabalho de pesquisa que têm caráter descritivo e testes de hipóteses, a partir do tratamento de dados da ADR através da Linguagem de Programação R.
A Linguagem R possibilita a realização de análise estatísticas (simples e complexas) apenas com a inserção de alguns comandos simples. O software R ajuda a reunir os dados e calcular números e, também, compreender os conceitos estatísticos. Por isso, é uma linguagem de computador bastante utilizada para auxiliar na tomada de decisão de uma pesquisa e apresentar os resultados de maneira compreensível.
Considerando todos os aspectos citados anteriormente, este artigo tem como objetivo realizar a análise entre os resultados da ADR; inicial, intermediário e final, considerando a disciplina de Matemática; as turmas do 9º ano do Ensino Fundamental do Distrito de Educação 2 de Fortaleza-CE e as aplicações realizadas no ano de 2022. Outro objetivo será comparar os que descritores que tiveram evolução quanto aos índices de acertos. E verificar se o planejamento das ações de intervenções da época promoveram melhorias nos resultados considerando que em cada resultado das ADRs a Secretaria Municipal de Educação promove ações para a melhoria destes índices.
Enfim, será realizada uma pesquisa bibliográfica e conceitual sobre a importância da estatística; utilização da tecnologia da informação (uso da linguagem R) e avaliação. Realização de coleta de dados e análise através do software R e a consolidação destes dados serão apresentados em tabelas e gráficos. Por fim, serão discutidos através dos resultados obtidos se houve ou não evolução de aprendizagem na proficiência destes estudantes no período considerado para a realização dos testes e hipóteses.
2 REFERENCIAL TEÓRICO
A estatística ajuda a dar sentido a qualquer tipo de informação e ocupa-se da análise e interpretação de dados quantificáveis. Por isso, pode ser útil para fins de generalização de resultados, com um alto grau de confiança, de amostras pequenas para populações maiores.
De acordo com Levin, Fox, Forde (2012, p.22), nesse contexto, uma definição para estatística é:
O conjunto de técnicas de tomada de decisões que ajudam os pesquisadores a fazer inferências a partir de amostras para populações e, por conseguinte, a testar hipóteses em relação à natureza da realidade social.
Ou seja, a aplicação de técnicas estatísticas oferece insumos técnicos para subsidiar as discussões em relação às adequações necessárias para o processo de ensino-aprendizagem, quando considerado o contexto educacional. Esse tratamento de dados contribui para o acesso à informação de qualidade e fortalecer a confiança da comunidade educacional na gestão; diálogo sobre as melhores ações e decisões a serem tomadas durante o processo.
Como este trabalho configura-se num artigo de análise dos aspectos estatísticos através da Linguagem R convém destacar que, esse software é flexível e robusto para a análise estatística. Traz consigo inúmeras vantagens aos pesquisadores, já que, trabalha com uma extensa relação de modelos estatísticos, entre eles: a modelagem linear e não-linear; a análise de séries temporais; os testes estatísticos clássicos; análise de agrupamento e classificação, entre outros.
Também,utilizando o R é possível apresentar gráficos dos resultados.
Segundo Alcoforado (2021, p.20):
O R é uma linguagem idealizada para realizar análise de dados através de um sistema para computação estatística e gráfica, permitindo explorar dados, produzir funções, computar linhas de comando ou utilizar pacotes disponíveis na rede CRAN (Comprehensive R Archive Network). Trata-se de sistema de licença livre, sem qualquer ônus e sua disseminação pela comunidade acadêmica permitiu que um grande número de pessoas contribuísse para sua evolução.
Ou seja, a Linguagem R, é uma ferramenta tecnológica de análise estatística gratuita com diversas ferramentas e funções. Possibilita a realização de análise estatísticas, compreendendo suas implicações e resultados. Procura deixar a ciência de dados rápida, fluente e divertida, quando transforma a imensa quantidade de dados brutos em insight gráficos convenientes para análise.
Desse modo, o presente trabalho desde as considerações introdutórias traz consigo uma fundamentação teórica sobre a importância da estatística para pesquisa; utilização das tecnologias digitais (software R), definição e implicações para a área de conhecimento estatístico e opiniões; pensamento de autores renomados com relação ao processo avaliativo.
3 METEDOLOGIA
O presente trabalho classifica-se segundo os critérios metodológicos como um artigo de natureza exploratória, descritiva, explicativa e bibliográfica. O mesmo visa proporcionar maior familiaridade com o problema, tornando-o explícito e / ou construindo hipóteses sobre ele. Descreve características de uma determinada população (amostra), utilizando-se de técnicas padronizadas de coleta de dados. Também, procura identificar os fatores que causam um determinado fenômeno, aprofundando o conhecimento em realidade. Por fim, foi concebida a partir de materiais já publicados.
A abordagem do artigo é classificada em quantitativa com clareza para a questão da pesquisa. Requer o uso de recursos e técnicas de estatística, utilizando-se da Linguagem R, procurando traduzir em números os conhecimentos gerados pelos pesquisadores. Entretanto, a coleta de dados representa a seleção de uma amostra que evidencia quais os critérios para a escolha da amostra, a qual servirá para a compreensão do objeto de estudo.
Este artigo analisa os dados colhidos no SAEF cujo endereço eletrônico é https://saef.sme.fortaleza.ce.gov.br/saef/login.jsf . São dados abertos à comunidade e foram colhidos escola por escola que continha turma de 9º ano do ensino fundamental do Distrito de Educação 2. Esses dados serão analisados com o software R no ambiente de trabalho Rstudio e foram colhidos do site em formato .xls.
O R é uma linguagem versátil que foi utilizada neste trabalho para auxílio na manipulação, análise e visualização de dados. Para a realização dessas análises preditivas, contou-se com os pacotes da Linguagem R cuja função foi o manuseio de modelos de regressão linear e não linear, clusterização e outros. Com poucas linhas de código foi realizada a análise exploratória dos dados. Também, com o uso deste software foi possível importar os dados obtidos no formato xls. para que pudessem ser explorados e analisados.
O pré-processamento de dados, por muitas vezes, é um processo mais demorado da metodologia, tem como objetivo extrair algumas características, limpeza e integração dos dados para tornar os dados adequados para o processamento.
Desse modo, de acordo com Alcoforado (2021):
O pré-processamento de dados é uma das etapas mais importantes de uma análise de dados. Essa etapa do processo fornece uma ampla visão sobre o comportamento e relações entre variáveis de uma base de dados. Tarefa fundamental tanto no início da exploração dos dados como, também, para a etapa de comunicação dos resultados de uma pesquisa.
O autor quer destacar que a limpeza e o tratamento dos dados, assim como a integração dos mesmos, evitam a obtenção de tabulações cruzadas das variáveis, entre outros problemas que podem ser encontrados ao utilizar dados abertos. E que essa análise descritiva dos dados se ocupa em obter informações preliminares como a contagem dos resultados observados em cada variável do conjunto de dados.
Portanto,inicialmente foi feita a condensação dos dados contidos nas planilhas em um único arquivo, pois como os dados foram coletados escola por escola, eles se encontravam em 14 arquivos separados que foram reunidos em um único arquivo.
Os atributos como “distrito de educação”, “escola” e “turma” foram retirados. Alunos que não continham informação de gabarito foram excluídos. Alunos que deixaram de marcar alguma alternativa ou marcaram mais de um item foram considerados como marcação de item errado. Os dados que serão aproveitados para a análise estatística são apenas os itens marcados e transformados em erros e acertos.
Nessa perspectiva, foram analisados e compilados inicialmente 1208 dados observáveis na ADR inicial. Esses mesmos dados foram comparados com os com os 1219 dados coletados na ADR final. A partir daí pode-se perceber a quantidade de acertos por descritor em cada aplicação; quais descritores avaliados nas duas provas tiveram ou não evolução no processo de aprendizagem do estudante observando-se os percentuais de acertos nas duas aplicações.
4 Resultados e Discussão
Essa etapa do trabalho consiste em analisar a coleta de dados, ADR Inicial e ADR final, considerando os resultados obtidos para os descritores avaliados em cada uma das diagnósticas em função do número de erros e acertos. Após a análise comparativa; ilustrar através de tabelas e gráficos, quais descritores tiveram evolução no processo de aprendizagem, quando diagnosticados nas duas provas. E aqueles descritores que os alunos tiveram mais ou menos dificuldade no processo de aprendizagem no intervalo entre as duas aplicações. Portanto, por configurar uma parte de análise e discussão sobre os dados coletados considera-se a parte mais importante do referido artigo.
Dessa forma, serão apresentadas nessa seção as linhas de códigos da Linguagem R para análise de dados e compreensão dos resultados das duas aplicações.
ADR1 – 1º APLICAÇÃO (1208 avaliados)
### Importação do arquivo
library(readxl)
adr1 <- read_excel(“C:/Users/Usuário/Desktop/adr1.xlsx”)
View(adr1)
> View(adr1)
> pacotes <- c(“readxl”, “knitr”, “kableExtra”, “tidyverse”, “plotly”,
+ “gt”, “descr”, “crosstable”, “gtools”, “writexl”, “flextable”,
+ “webshot2”, “freqdist”, “fdth”, “viridis”, “as_flaxtable”)
>
> if(sum(as.numeric(!pacotes %in% installed.packages())) != 0){
+ instalador <- pacotes[!pacotes %in% installed.packages()]
+ for(i in 1:length(instalador)) {
+ install.packages(instalador, dependencies = T)
+ break()}
+ sapply(pacotes, require, character = T)
+ } else {
+ sapply(pacotes, require, character = T)
+ }
### Conhecimento dos dados
## Visualização de parte das observações e suas especificações
glimpse(adr1)
> glimpse(adr1)
Rows: 22
Columns: 3
$ DESCRITORES <chr> “D25”, “D46”, “D07”, “D10”, “D50”, “D12”, “D17”, “D59”, “D18”, “D19”, “D65”, “D24”, “D69”, “D51”, “…
$ ACERTOS <dbl> 554, 501, 380, 429, 389, 791, 497, 658, 334, 265, 372, 246, 99, 393, 173, 405, 225, 562, 395, 231, …
$ ERROS <dbl> 654, 707, 828, 779, 819, 417, 711, 550, 874, 943, 836, 962, 1109, 815, 1035, 803, 983, 646, 813, 97…
## Resumo dos dados, incluindo estatísticas univariadas
summary(adr1)
> summary(adr1)
DESCRITORES ACERTOS ERROS
Length:22 Min. : 99.0 Min. : 417.0
Class :character 1st Qu.:258.0 1st Qu.: 728.0
Mode :character Median :384.5 Median : 823.5
Mean :382.6 Mean : 825.4
3rd Qu.:480.0 3rd Qu.: 950.0
Max. :791.0 Max. :1109.0
## Caso deseje salvar o objeto “adr1” para uso posterior sem a
## necessidade de importá-lo de um arquivo XLSX, é possível salvá-lo
## como objeto do R e importá-lo com a função “load()”.
save(adr1, file = “adr1.RData”)
> save(adr1, file = “adr1.RData”)
### Preparação dos dados
## Transformação de variáveis para a classe “factor”
adr1$DESCRITORES <- factor(adr1$DESCRITORES)
adr1$ACERTOS <- factor(adr1$ACERTOS)
adr1$ERROS <- factor(adr1$ERROS)
summary(adr1)
> save(adr1, file = “adr1.RData”)
> adr1$DESCRITORES <- factor(adr1$DESCRITORES)
>
> adr1$ACERTOS <- factor(adr1$ACERTOS)
>
> adr1$ERROS <- factor(adr1$ERROS)
>
> summary(adr1)
DESCRITORES ACERTOS ERROS
D07 : 1 99 : 1 417 : 1
D10 : 1 173 : 1 550 : 1 D11 : 1 225 : 1 646 : 1
D12 : 1 231 : 1 654 : 1
D13 : 1 246 : 1 707 : 1
D14 : 1 257 : 1 711 : 1
(Other):16 (Other):16 (Other):16
### Tabela adr1
## Uso da função “flextable()” do pacote “flextable”
# Estabelecimento de parâmetros gerais para a função “flextable()”
set_flextable_defaults(
font.family = “Arial”,
font.size = 10,
font.color = “black”,
decimal.mark = “,”,
big.mark = “.”,
digits = 2
)
# Configuração das bordas mais grossas
border1 <- fp_border_default(
color = “black”,
style = “solid”,
width = 3
)
> set_flextable_defaults(
+ font.family = “Arial”,
+ font.size = 10,
+ font.color = “black”,
+ decimal.mark = “,”,
+ big.mark = “.”,
+ digits = 2
+ )
> border1 <- fp_border_default(
+ color = “black”,
+ style = “solid”,
+ width = 3
+ )
## ADR – 1º APLICAÇÃO
tab1 <- adr1 %>%
select(DESCRITORES, ACERTOS, ERROS) %>%
filter(DESCRITORES == “DESCRITORES”) %>%
group_by(ACERTOS, ERROS) %>%
summarise(
DESCRITORES = unique(DESCRITORES),
ACERTOS = length(ACERTOS),
ERROS = length(ERROS)
) %>%
flextable() %>% set_header_labels(DESCRITORES = “DESCRITORES”,
ACERTOS = “ACERTOS”,
ERROS = “ERROS”) %>%
hline_top(j = c(1:2), border = border1, part = “header”) %>%
hline_bottom(j = c(1:2), border = border1, part = “body”) %>%
tab1
> tab1 <- adr1 %>%
+ select(DESCRITORES, ACERTOS, ERROS) %>%
+ filter(DESCRITORES == “DESCRITORES”) %>%
+ group_by(ACERTOS, ERROS) %>%
+ summarise(
+ DESCRITORES = unique(DESCRITORES),
+ ACERTOS = length(ACERTOS),
+ ERROS = length(ERROS)
+ ) %>%
+ flextable() %>%
+ set_header_labels(DESCRITORES = “DESCRITORES”,
+ ACERTOS = “ACERTOS”,
+ ERROS = “ERROS”) %>%
+ hline_top(j = c(1:2), border = border1, part = “header”) %>%
+
+ tab1
# Exportação como imagem PNG
tab1 %>%
save_as_image(“tab1.png”, webshot = “webshot2”)
> tab1 %>%
+ save_as_image(“tab1.png”, webshot = “webshot2”)
# Exportação como arquivo DOCX
tab1 %>%
save_as_docx(path = “tab1.docx”)
> tab1 %>%
+ save_as_docx(path = “tab1.docx”)
Sendo assim, após a limpeza dos dados realizados com utilização do software; organizou-se e analisou-se os dados, de forma clara e objetiva uma tabela para ADR1 – 1º Aplicação (1208 avaliados) considerando os principais dados estatísticos: valor mínimo; valor máximo; média; primeiro quartil; mediana (segundo quartil) e terceiro quartil, considerando o número de acertos e erros para os descritores aplicados nessa avaliação. Essa condensação de dados estatísticos possibilitou uma melhor visão e compreensão com relação aos resultados da aplicação desta avaliação.
Tabela 1: Dados estatísticos univariados da ADR1 – 1o Aplicação
ACERTOS ERROS VALOR MÍNIMO 99,0 417,00 VALOR MÁXIMO 791,0 1109,0 1º QUARTIL 258,0 728,0 MÉDIA 382,6 825,4 MEDIANA 384,5 823,5 3º QUARTIL 480,0 950,00
Nota-se pelos resultados estatísticos expostos na Tabela 1 que na primeira aplicação 2022 da ADR (ADR 1) a média de erros na avaliação foi bem superior que a média de acertos. Também, observa-se uma grande diferença entre o valor mínimo de acertos e erros. Porém, percebe-se que isso no contexto avaliativo da educação seja considerado normal para uma primeira avaliação de ano letivo cujo intuito é sondar os conhecimentos prévios e que merecem reforço de aprendizagem para esses estudantes.
ADR2 – 2º APLICAÇÃO (1219 avaliados)
O mesmo processo de análise, compilação, organização e sumarização de dados foi realizado da mesma forma para os resultados da ADR2 – 2º Aplicação, tendo como diferente os valores dos principais dados estatísticos: valor mínimo; valor máximo; média; primeiro quartil; mediana (segundo quartil) e terceiro quartil, considerando o número de acertos e erros para os descritores avaliados, porém desta vez considerando 1219 alunos pesquisados. Essa condensação de dados estatísticos possibilitou uma melhor visão e compreensão com relação aos resultados da aplicação desta avaliação.
Portanto, para observação da ADR2 será considerado apenas o resumo de dados, incluindo estatísticas univariadas, uma vez que as demais linhas de comando se repetem trocando apenas os objetos (adr1) por (adr2). ## Resumo dos dados, incluindo estatísticas univariadas
summary(adr1)
> summary(adr2)
DESCRITORES ACERTOS ERROS
Length:22 Min. : 196.0 Min. : 167.0
Class :character 1st Qu.: 389.5 1st Qu.: 524.2
Mode :character Median : 495.0 Median : 724.0
Mean : 555.1 Mean : 663.9
3rd Qu.: 694.8 3rd Qu.: 829.5
Max. :1052.0 Max. :1023.0
ACERTOS ERROS VALOR MÍNIMO 196,0 167,00 VALOR MÁXIMO 1052,0 1023,0 1º QUARTIL 389,5 524,2 MÉDIA 555,1 663,9 MEDIANA 495,0 724,0 3º QUARTIL 694,8 829,5
Tabela 2 : Dados estatísticos univariados da ADR2 – 2o Aplicação
Nota-se pelos resultados estatísticos expostos na Tabela 2 que na segunda aplicação 2022 da ADR (ADR 2) a média de erros na avaliação foi superior que a média de acertos. Também, observa-se uma diferença entre o valor mínimo e o valor máximo de acertos e erros, positiva para a aplicação da ADR2. Assim, como um crescimento de média de acertos quando comparada a tabela de resultados estatísticos da aplicação inicial (ADR1). Consequentemente, percebe-se uma evolução da aprendizagem na proficiência dos descritores avaliados e subentende-se que as escolas realizaram ações pedagógicas de reforço à aprendizagem.
Uma outra maneira de observar a evolução da aprendizagem dos estudantes é observando os gráficos de colunas que são comparativos quanto ao número de acertos e erros para cada descritor. Portanto, abaixo serão apresentados os gráficos da primeira aplicação (ADR1) e da segunda aplicação (ADR2) com as respectivas legendas representando os acertos e erros pelos estudantes obtidos.
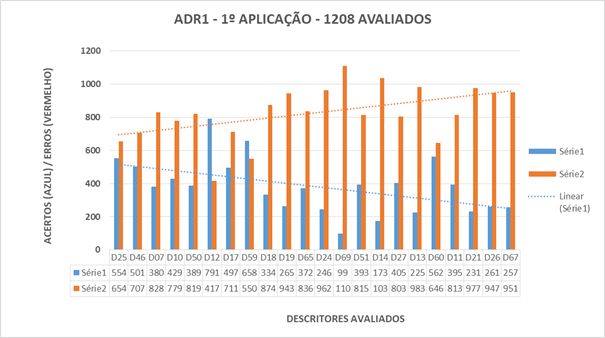
Gráfico 1 : Resultados da ADR1 – 1o Aplicação – Acertos e erros por descritor
Observando-se o Gráfico 1, é fácil perceber que na primeira aplicação houve mais erros do que acertos com relação à aprendizagem dos descritores avaliados. Avaliação inicial de conhecimento prévios para estabelecer um planejamento das metas de aprendizagem das escolas durante o ano letivo.
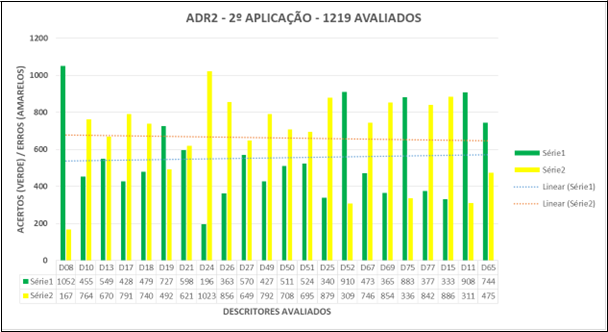
Gráfico 2 : Resultados da ADR2 – 2o Aplicação – Acertos e erros por descritor
O Gráfico 2 mostra uma queda no número de erros e um crescimento suave com relação a aplicação da segunda ADR (ADR2). Isso mostra a evolução na aprendizagem dos estudantes avaliados e que, supostamente, houve ações pedagógicas nas escolas do Distrito Educacional 2 para a melhoria dos resultados, muito embora ainda sejam superficiais.
5 CONSIDERAÇÕES FINAIS
A utilização da planilha do Excel e da Linguagem R são excelentes ferramentas tecnológicas para manipulação, visualização e modelagem de dados. Contribuem de modo positivo para a metodologia do trabalho científico através de seus métodos e técnicas para análise de dados, no caso deste trabalho, dados educacionais que são aplicados para as evidências de gestão pública seja municipal, estadual ou federal.
Por fim, a Estatística é uma Ciência que tem contribuído bastante para avaliação da aprendizagem na escola. São através de estudos e análises de dados; resultados de avaliações diagnósticas (ADR1 e ADR2), objetos de pesquisa deste trabalho, que os gestores da Secretaria, Distrito e Escolas reelaboram os conceitos e criam novas práticas para o reforço da aprendizagem e melhoria de proficiência dos descritores avaliados.
Enfim, o uso do Excel e da linguagem R, contribuíram de forma simples, flexível e eficaz para percepção da melhoria embora superficial dos descritores avaliados e que supostamente as escolas do Distrito Educacional 2 do município de Fortaleza-CE vem realizando ações para melhorar a aprendizagem de seus estudantes.
REFERÊNCIAS
ALCOFORADO, Luciane Ferreira. Utilizando a linguagem R- conceitos, manipulação, visualização, modelagem e elaboração de relatórios. Rio de Janeiro. Editora: Alta Books. 2021;
HAYDT, Regina Cazaux. Avaliação do processo ensino-aprendizagem. São Paulo: Ática, 2000;
FORDE, David R.; FOX, James Alan, LEVIN, Jack. Estatística para Ciências Humanas.Revisão técnica: Fernanda Bonafini. 11ª edição. São Paulo. Editora: Pearson Education doBrasil, 2012;
FREITAS, Ernani Cesar de Prodanov, Cleber Cristiano. Metodologia do Trabalho Científico: Métodos e Técnicas da Pesquisa e do Trabalho Acadêmico. 2º edição,Editora: Universidade FEEVALE, Novo Hamburgo, Rio Grande do Sul, Brasil, 2013;
JUNIOR, Odílio Hilário Moreira. Análise de Dados Educacionais: aplicando evidências em gestão pública. Organização: Open Knowledge Brasil, Fundação Lemann, Interdisciplinaridade e Evidências no Debate Educacional (IEDE). São Paulo, 2021;
LUCKESI, Cipriano Carlos. Avaliação da aprendizagem na escola: reelaborando conceitos e criando a prática. 2 ed. Salvador: Malabares Comunicações e Eventos, 2005.
¹Licenciado em Matemática pelo Instituto Federal de Educação, Ciência e Tecnologia do Ceará (IFCE). Especialista em Tecnologias Digitais para Educação Básica pela Universidade Estadual do Ceará (UECE).
²Licenciada em Matemática e especialista em educação matemática pela Universidade Federal do Ceará (UFC)