REGISTRO DOI: 10.69849/revistaft/fa10202511300854
Carlos Vinicios Nogueira Costa
Hilson Barbosa da Silva
RESUMO
A economia digital brasileira tem registrado expansão acelerada, impulsionada por plataformas de e-commerce, fintechs e serviços digitais que dependem de aprendizado de máquina (machine learning) para operar em escala. Este trabalho investiga as vantagens competitivas proporcionadas pelo MLOps (Machine Learning Operations) nesse contexto, analisando como práticas de automação, monitoramento contínuo e retreinamento adaptativo transformam modelos preditivos em ativos estratégicos sustentáveis. A fundamentação teórica aborda conceitos de MLOps, monitoramento de concept drift, design de sistemas de ML e aplicações reais em instituições financeiras brasileiras (Itaú, Nubank, PicPay), plataformas de e-commerce (Mercado Livre, Magalu, Shopee) e serviços de delivery (iFood). Para demonstrar os benefícios operacionais e financeiros do MLOps, desenvolveu-se um experimento utilizando a base pública IEEE-CIS Fraud Detection, comparando quatro estratégias de manutenção de modelos: Train-Once (estático), retreinamentos periódicos (Q30 e Q3M) e retreinamento adaptativo por drift. Os resultados mostram que a estratégia Drift alcançou lucro de US$ 559.720 (ROI 2,18×) no cenário base, superando em 143% o modelo estático (US$ 229.823). No cenário com custo real de fraude ativado, apenas a combinação Drift + Recall Guard manteve operação lucrativa (lucro de US$ 1,30 milhão, ROI 2,36×), enquanto todas as demais estratégias apresentaram prejuízo superior a US$ 1,6 milhão. Análises de retenção de clientes revelaram que o impacto de falsos positivos pode reduzir o lucro em até 33% no cenário pessimista (58% de retenção pósbloqueio indevido). Conclui-se que MLOps constitui diferencial competitivo crítico em ambientes de alta volatilidade e custo elevado de erros, permitindo que organizações adaptem seus sistemas de ML continuamente, minimizem perdas financeiras e mantenham vantagem sobre concorrentes que dependem de modelos estáticos.
Palavras-chave: MLOps, Detecção de Fraude, Machine Learning Operations
ABSTRACT
The Brazilian digital economy has experienced accelerated growth, driven by ecommerce platforms, fintechs, and digital services that rely on machine learning to operate at scale. This work investigates the competitive advantages provided by MLOps (Machine Learning Operations) in this context, analyzing how automation practices, continuous monitoring, and adaptive retraining transform predictive models into sustainable strategic assets. The theoretical foundation addresses MLOps concepts, concept drift monitoring, ML system design, and real applications in Brazilian financial institutions (Itaú, Nubank, PicPay), e-commerce platforms (Mercado Livre, Magalu, Shopee), and delivery services (iFood). To demonstrate the operational and financial benefits of MLOps, an experiment was developed using the public IEEE-CIS Fraud Detection dataset, comparing four model maintenance strategies: Train-Once (static), periodic retraining (Q30 and Q3M), and drift-based adaptive retraining. Results show that the Drift strategy achieved a profit of US$ 559,720 (ROI 2.18×) in the baseline scenario, exceeding the static model (US$ 229,823) by 143%. In the scenario with actual fraud cost enabled, only the Drift + Recall Guard combination maintained profitable operation (profit of US$ 1.30 million, ROI 2.36×), while all other strategies presented losses exceeding US$ 1.6 million. Customer retention analyses revealed that the impact of false positives can reduce profit by up to 33% in the pessimistic scenario (58% retention post-incorrect blocking). It is concluded that MLOps constitutes a critical competitive differential in high-volatility environments with elevated error costs, enabling organizations to continuously adapt their ML systems, minimize financial losses, and maintain advantage over competitors relying on static models.
Keywords: MLOps, Fraud Detection, Machine Learning Operations
1. INTRODUÇÃO
A economia digital brasileira tem registrado crescimento acelerado nos últimos anos, impulsionada por inovações em comércio eletrônico, serviços financeiros digitais e outras plataformas online. Segundo The Paypers [1], o Brasil figura como o maior mercado de e-commerce da América Latina, tendo movimentado cerca de US$ 276,9 bilhões em 2023, com projeção de alcançar aproximadamente US$ 500 bilhões em 2026. Em consonância com esse diagnóstico, Consumidor Moderno [2] mostra que o ecossistema do Mercado Livre, sozinho, movimentou R$ 381 bilhões em 2024 — valor equivalente a aproximadamente 3,2% do PIB nacional — a partir de 5,8 milhões de micro e pequenas empresas usuárias da plataforma. Esse contexto evidencia como a expansão da economia digital cria oportunidades para o uso intensivo de inteligência artificial e aprendizado de máquina em personalização, logística, prevenção à fraude e modelos de negócio baseados em dados.
O uso de machine learning é fundamental para a proteção do comércio eletrônico brasileiro. De acordo com a Signifyd [3], sua plataforma antifraude emprega modelos de aprendizado de máquina e análise massiva de dados para identificar padrões suspeitos em tempo real e tomar decisões de aprovação ou recusa com garantia financeira, protegendo a receita dos lojistas. Em linha com essa abordagem, Serasa Experian e ClearSale [4] descrevem uma solução conjunta de antifraude para vendas online que integra modelos estatísticos, inteligência de mercado e revisão especializada para equilibrar segurança e aprovação de bons clientes. Complementarmente, a ClearSale [5] apresenta o portfólio “Preventative Intel”, composto por camadas de decisão automatizada e análise humana, que se valem de dados históricos e técnicas de IA para reduzir fraudes sem comprometer a experiência do consumidor legítimo. Em conjunto, esses exemplos ilustram como o ML se tornou peça central nas estratégias modernas de gestão de risco no e-commerce.
Nesse contexto, o MLOps (Machine Learning Operations) surge como fator estratégico para empresas que desejam escalar o uso de modelos de ML com segurança. IBM [6] define MLOps como o conjunto de práticas que une engenharia de software, ciência de dados e operações, criando pipelines automatizados para desenvolvimento, teste, implantação e monitoramento de modelos em produção. Em sintonia com essa definição, Dataforest [7] ressalta que o MLOps reduz o tempo de colocação de soluções de IA em produção, padroniza fluxos de trabalho e melhora o aproveitamento de recursos em nuvem. Dessa forma, o MLOps deixa de ser apenas um suporte tecnológico e passa a representar capacidade organizacional crítica para transformar experimentos de ML em resultados de negócio recorrentes.
Este trabalho de conclusão de curso analisa as vantagens competitivas do MLOps na economia digital brasileira, com ênfase em setores-chave. No comércio eletrônico, discutem-se exemplos de gigantes como Amazon, Mercado Livre, Shopee e Magalu, destacando como a IA embutida nas operações de pesquisa, recomendação de produtos e logística tem sido potencializada pela adoção de MLOps[8][9]. Nas fintechs brasileiras (por exemplo, Nubank e PicPay), examina-se como a IA aplicada em análise de risco, detecção de fraudes e personalização de serviços financeiros tem requerido pipelines de MLOps para acelerar lançamentos e aumentar a retenção de clientes[10][11]. Além desses, abordam-se outras áreas digitais relevantes — como aplicativos de delivery (por exemplo, iFood) e saúde digital — em que o aprendizado de máquina, suportado por MLOps, impulsiona ganhos de eficiência e qualidade.
Por fim, dedica-se atenção especial ao uso de MLOps na detecção de fraudes, ilustrando o caso de um projeto baseado na competição IEEE-CIS Fraud Detection (Kaggle). Nesse contexto, contrastam-se duas estratégias de manutenção de modelos: a abordagem estática “train-once” versus a abordagem adaptativa “drift-based”. Discutese como sistemas MLOps com monitoramento de modelo e detecção de deriva (concept drift) permitem recalibrar algoritmos de fraude à medida que o comportamento dos fraudadores evolui[12][13], em contraste com modelos treinados uma única vez (train-once), que tendem a ficar obsoletos diante de novas realidades. Assim, esta introdução contextualiza o papel transformador do MLOps no ambiente digital brasileiro e apresenta os temas desenvolvidos na fundamentação teórica subsequente.
2. FUNDAMENTAÇÃO TEÓRICA
2.1 Conceitos Fundamentais e Monitoramento em MLOps
MLOps (Machine Learning Operations) representa disciplina emergente que aplica princípios de DevOps ao ciclo de vida de sistemas baseados em machine learning. Kreuzberger, Kühl e Hirschl (2022)[14] definem MLOps como um conjunto de práticas, conceitos e cultura de desenvolvimento voltado a automatizar e operacionalizar produtos de ML, trazendo-os rapidamente à produção de forma confiável por meio de automação, colaboração e monitoramento contínuo. A disciplina surge em resposta a desafios específicos de operacionalizar ML em escala, transcendendo práticas tradicionais de engenharia de software.
Sculley et al. (2015)[15], em artigo seminal apresentado na NeurIPS (Conference on Neural Information Processing Systems), identificam fontes de technical debt específicas de sistemas de ML que justificam a adoção de práticas MLOps. Os autores documentam fenômenos críticos como entanglement (mudanças em um atributo afetam o comportamento global do modelo), hidden feedback loops (predições do modelo influenciam dados futuros de treinamento), undeclared consumers (serviços downstream dependendo de outputs do modelo sem contratos explícitos) e dependências de dados instáveis. Esses anti-patterns geram custos de manutenção exponenciais se não forem gerenciados proativamente por meio de arquiteturas e processos apropriados[15].
O ciclo de vida MLOps tipicamente compreende: (1) desenvolvimento iterativo de modelos com versionamento de código, dados e configurações; (2) validação automatizada por meio de pipelines de CI/CD (Continuous Integration/Continuous Deployment); (3) deployment automatizado em ambientes de produção com estratégias de rollout progressivo; (4) monitoramento contínuo de performance, qualidade de dados e saúde de infraestrutura; (5) retreinamento e atualização de modelos com base em triggers automáticos ou manuais. Feature stores centralizam features reutilizáveis entre times, model registries versionam e rastreiam artefatos de modelo em produção, e frameworks de serving padronizam a exposição de predições via APIs com garantias de latência e disponibilidade[6][14].
A evolução do machine learning em escala industrial exigiu práticas robustas de operação e governança. IBM [6] argumenta que, à medida que modelos passam a influenciar diretamente a experiência do cliente e os resultados financeiros, torna-se essencial incorporá-los a esteiras de integração e entrega contínuas (CI/CD) e a boas práticas de desenvolvimento. Dataforest [7], por sua vez, destaca que arquiteturas de MLOps organizam o ciclo de vida dos modelos como uma espécie de “linha de montagem”, em que etapas como ingestão de dados, treinamento, validação, implantação e monitoramento são automatizadas e auditáveis. Em conjunto, essas visões indicam que o MLOps preenche lacunas entre equipes de ciência de dados, engenharia e TI, diminuindo silos organizacionais e favorecendo um processo contínuo de melhoria de modelos em produção.
O monitoramento de concept drift constitui componente crítico de sistemas MLOps, especialmente em domínios como detecção de fraudes, em que o comportamento anômalo evolui continuamente. Materiais técnicos da EvidentlyAI, baseados em experimentos que comparam cinco testes estatísticos para detecção de data drift em grandes bases de dados, organizam os métodos em torno de duas abordagens principais: comparar distribuições de dados em janelas temporais sucessivas e monitorar métricas de desempenho do modelo em produção[16]. Técnicas estatísticas amplamente adotadas incluem Population Stability Index (PSI), Kolmogorov–Smirnov test (KS test), Kullback–Leibler divergence e Jensen–Shannon divergence para quantificar drift em distribuições de features e scores de modelos, permitindo detecção proativa de degradação de performance[16]. Essas abordagens dialogam com estudos mais amplos sobre concept drift em fluxos de dados contínuos, incluindo análises comparativas em bases de dados financeiras[17].
2.2 Design de Sistemas de ML e Vantagens Competitivas do MLOps
Huyen (2022)[18], em obra abrangente sobre design de sistemas de machine learning, enfatiza a importância crítica de considerar requisitos não funcionais desde a concepção arquitetural. Latência (tempo para retornar predições), throughput (volume de predições por unidade de tempo), escalabilidade (capacidade de crescer com a demanda), disponibilidade (uptime de serviços) e custos computacionais constituem constraints arquiteturais que moldam decisões técnicas fundamentais. A autora discute trade-offs entre freshness de modelos (frequência de retreinamento para incorporar dados recentes) e custos operacionais, ilustrando a tensão constante entre performance preditiva e viabilidade econômica de manutenção contínua[18]. Esse balanço é especialmente crítico em mecanismos de identificação de atividades fraudulentas, nos quais tanto a acurácia quanto a latência de decisão impactam diretamente nos resultados do negócio.
A adoção de MLOps traz vantagens competitivas expressivas. Em primeiro lugar, MLOps acelera o time-to-market de soluções analíticas, pois permite implantar modelos em produção muito mais rapidamente do que processos manuais tradicionais[6][7]. A IBM ressalta que, ao otimizar o ciclo de desenvolvimento do ML, as empresas conseguem garantir superioridade frente à concorrência por meio da celeridade na implementação de modelos [6]. Estima-se que organizações de ponta em IA apresentem margens de lucro superiores em até cinco pontos percentuais em comparação com concorrentes menos avançados, justamente pelo fôlego operacional em gerenciar IA em escala[7]. Ou seja, a vantagem não advém apenas de algoritmos sofisticados, mas da capacidade operacional de colocar esses algoritmos em produção de forma confiável e rápida.
Em segundo lugar, MLOps melhora eficiência e produtividade. Ao automatizar tarefas repetitivas — limpeza de dados, retreinamento de modelos, testes e implantação —, MLOps libera cientistas de dados e engenheiros para foco em inovação e refino de algoritmos[6][19]. Essa automação reduz erros humanos e custos de manutenção, elevando a escala dos projetos de ML. Além disso, a prática contínua de monitoramento de modelos permite detectar e corrigir rapidamente problemas de desempenho, como desvios de dados (data drift) e mudanças de contexto (concept drift)[12][16]. Segundo artigo da FinTech Weekly, “plataformas modernas de MLOps integram detecção de drift, retraining automático e governança em fluxos de trabalho unificados”, reforçando a centralidade do MLOps em setores altamente dinâmicos, como o financeiro[20].
Em terceiro lugar, MLOps favorece governança e escalabilidade. Com pipelines bem definidos e versionamento de dados e modelos, as empresas mantêm consistência e auditabilidade — aspecto crítico em indústrias reguladas, como fintechs e saúde, nas quais é preciso justificar decisões automatizadas[6][14]. Além disso, um ambiente MLOps robusto torna mais fácil ampliar o portfólio de modelos: depois de validada a infraestrutura, novos casos de uso podem ser desenvolvidos reutilizando componentes já estabelecidos[7][19]. Em suma, a organização e a governança proporcionadas pelo MLOps transformam esforços de IA em ativos estratégicos duráveis.
Os textos especializados reforçam esse ponto de vista. Um blog corporativo da Thoughtworks destaca que empresas que inovam com ML/LLM ganham “vantagem competitiva significativa”, mas frequentemente enfrentem dificuldades em levar soluções além do protótipo. Nesse contexto, MLOps ajuda a “simplificar e acelerar o desenvolvimento, implantação e operações de ML, minimizando trabalho manual” e garantindo ciclos rápidos de inovação[21]. Outros autores enfatizam que, no atual mercado digital, “inteligência artificial não é mais algo isolado em pesquisas”; modelos de ML tornam-se parte intrínseca de produtos e serviços, e seu domínio requer processos padronizados de operação[7]. Essa convergência de visão indica que a competitividade hoje depende tanto da sofisticação dos modelos de IA quanto da capacidade de operacionalizá-los via MLOps[6][14].
2.3 Aplicações de MLOps na Economia Digital Brasileira
Instituições financeiras e fintechs.
O Itaú Unibanco, maior banco da América Latina, com mais de 65 milhões de clientes e dezenas de petabytes de dados sob gestão, é um exemplo de adoção avançada de MLOps em contexto financeiro. Nogare e Silveira [22] descrevem o desenvolvimento, pelo banco, de uma plataforma proprietária de MLOps responsável por orquestrar todo o ciclo de vida dos modelos, desde o treinamento e validação até a implantação e o monitoramento em produção. Essa plataforma padroniza pipelines, controla versões de dados e artefatos de modelo e automatiza etapas de deploy, permitindo que equipes de ciência de dados e engenharia coloquem novos modelos em produção com maior rapidez, segurança e rastreabilidade [22].
Atualmente, o Itaú opera cerca de 1.300 modelos de IA, dos quais 50 são preventivos e aproximadamente metade é dedicada à análise de comportamento de clientes e possíveis fraudadores[23]. Em três meses, as inteligências artificiais do banco processaram mais de 1,4 bilhão de transações, o que resultou em uma redução de cerca de 30% nos valores contestados por fraudes ou golpes, preservando mais de R$ 45 milhões e beneficiando diretamente mais de 7 mil clientes[24][25]. No domínio transacional, os modelos comportamentais observam ações do usuário no site e no aplicativo (como movimentos do mouse, padrão de digitação, geolocalização, uso de Wi-Fi e nível de bateria do dispositivo) para diferenciar comportamentos legítimos de padrões típicos de robôs ou dispositivos dominados por criminosos[23]. Combinada a uma estratégia de AI First e security by design, essa abordagem ajudou o banco a reduzir em mais de 50% o total de casos de golpes e fraudes e em 98% os incidentes de alto impacto desde 2018[23].
As fintechs brasileiras são outro segmento em que MLOps tem ganhado destaque. Startups como Nubank e PicPay utilizam machine learning desde seus primeiros produtos e hoje dependem de práticas maduras de MLOps para manter competitividade[10][11]. Por exemplo, o Nubank usa algoritmos de IA para avaliar risco de crédito, definir limites e aprovar pedidos de cartão em segundos, realizando análises de risco e prevenção à fraude em tempo real[10]. Pesquisas setoriais, como a Fintech Deep Dive da PwC, reforçam que a combinação entre IA, dados e nuvem é um dos principais motores de crescimento das fintechs brasileiras[26].
O PicPay, em seu blog institucional, destaca que seus algoritmos “atualizam-se constantemente com base em novos padrões de fraude identificados no mercado”, o que permite antecipar táticas criminosas e garantir segurança das transações[11]. Essa cultura de inovação orientada por dados é reforçada por comunicados oficiais aos consumidores — como o aviso geral aos clientes com contas ativas no PicPay —, que enfatizam o uso de tecnologia avançada na proteção contra golpes e fraudes[27]. Em conjunto, esses elementos contribuem para que o sistema financeiro nacional se destaque internacionalmente em regulação e excelência digital.
Plataformas globais e serviços digitais
No contexto internacional, a Uber desenvolveu sua plataforma Michelangelo como sistema centralizado de ML servindo milhares de modelos em produção para casos de uso variados, incluindo previsão de demanda, estimativas de tempo de chegada (ETAs), precificação dinâmica e detecção de fraudes[28]. A arquitetura implementa um feature store centralizado para reutilização de features entre múltiplos times de dados, suporte a treinamento distribuído e infraestrutura de serving com suporte tanto a predições online (baixa latência para decisões em tempo real) quanto a batch processing (alto throughput para análises em massa)[28]. A evolução da plataforma, passando de ML preditivo para dados tabulares a modelos de deep learning e, mais recentemente, IA generativa, ilustra a maturação progressiva de capacidades MLOps em resposta a demandas organizacionais crescentes[28].
Outras áreas digitais também aproveitam o MLOps. No segmento de delivery, por exemplo, o iFood criou em 2020 uma “Academia de IA” para treinar equipes e expandir o uso de ML em escala[29]. Relatos de executivos indicam que a infraestrutura baseada em AWS (com SageMaker) “permite treinar diversos modelos em máquinas do tamanho que necessitamos e colocar estes modelos em produção de forma simples”[29]. Entre as primeiras aplicações estava um simulador de rotas que estima prazos de entrega; após validação, novos parâmetros passaram automaticamente a alimentar o modelo de previsão logística, acelerando em anos a melhoria do sistema[29]. O iFood também personaliza recomendações de restaurantes e pratos, sugerindo opções de acordo com o gosto do usuário graças a modelos servidos em escala pela infraestrutura de MLOps[29].
No âmbito da saúde digital, grupos como a Dasa (rede de diagnóstico) têm criado centenas de modelos de IA que melhoram o desempenho de equipamentos e reduzem prazos de laudos, encurtando o tempo de emissão de exames de 24 horas para apenas 2 horas em alguns casos[30]. Esses modelos incluem algoritmos de apoio à decisão clínica, priorização de exames críticos e otimização de agendas. Embora casos específicos variem, a regra comum é que, sem MLOps, essas organizações teriam dificuldade em atualizar, monitorar e escalonar seus modelos conforme exigências de operação e regulação[30].
Panorama das Atividades Fraudulentas no Brasil e soluções especializadas
No contexto brasileiro, as perdas com fraude representam um desafio macroeconômico relevante. Segundo Dock Technology [31], as atividades fraudulentas podem corresponder a algo entre 0,35% e 0,4% do PIB, resultando em prejuízos superiores a R$ 10 bilhões em 2024. Esses números reforçam a importância de sistemas automáticos de detecção de fraude baseados em machine learning: modelos analisam, em tempo quase real, variáveis como local da transação, horário, dispositivo, valor e frequência de uso, comparando-as ao perfil histórico de cada usuário para identificar padrões atípicos [31]. Ao serem integradas a pipelines de MLOps, essas soluções podem ser atualizadas com frequência e ajustadas à evolução dos golpes, reduzindo a janela de exposição ao risco.
A Datarisk, fundada em 2017, é pioneira no Brasil na oferta de soluções focadas no conceito de MLOps (Machine Learning Operations)[32]. A empresa desenvolveu uma plataforma de MLOps que automatiza etapas de treinamento, criação de APIs e monitoramento de modelos, permitindo reduzir ciclos que tradicionalmente levariam meses para uma questão de horas[32]. Reportagem do Monitor Mercantil destaca que, apenas no primeiro semestre de 2024, essa plataforma já havia sido utilizada em um volume superior a 10 milhões de consultas, evidenciando a viabilidade prática de MLOps em escala no contexto brasileiro[33].
De acordo com a Valuates Reports, projeta-se que o mercado global de MLOps salte de US$ 186,4 milhões, valor registrado em 2023, para US$ 3.652,7 milhões até 2030, apresentando uma taxa de crescimento anual composta de 44,6%[34]. Esse avanço é fortemente impulsionado por instituições financeiras, que adotam essas tecnologias para otimizar o processamento de grandes volumes de dados, aprimorar a detecção de fraudes e criar experiências personalizadas para seus clientes[34].
No Brasil, esse movimento é acompanhado pela maturidade das soluções locais, que já competem com as principais plataformas globais ao mesmo tempo em que incorporam conhecimento sobre as especificidades regulatórias e de mercado nacionais[32]. Uma análise da Deloitte projeta que, até 2025, inteligência artificial e machine learning possam gerar cerca de US$ 4,4 trilhões em valor comercial, com expectativa de que o mercado de MLOps alcance aproximadamente US$ 4 bilhões[35]. Esses números reforçam o MLOps como componente crítico para capturar o valor econômico da IA de forma sustentável.
E-commerce e varejo digital
O e-commerce brasileiro é um dos principais cenários de aplicação intensiva de ML e, por consequência, de MLOps. E-Commerce Brasil [8] aponta que plataformas de marketplace utilizam algoritmos de recomendação, motores de busca inteligentes e modelos de previsão de demanda para adaptar vitrines, ofertas e estoques ao comportamento dos consumidores. Em alinhamento com essa análise, Product Gurus [9] discute como o Mercado Livre combina modelos preditivos para personalização, precificação dinâmica e otimização logística, tratando a IA como elemento central da estratégia digital. Nesses casos, o MLOps é o mecanismo que permite manter em produção dezenas ou centenas de modelos de forma confiável, garantindo monitoramento, atualização contínua e aderência às metas de negócio [8][9].
Nesse contexto, o MLOps suporta a rápida iteração dessas aplicações. O Magazine Luiza, por exemplo, investe em plataformas de MLOps (baseadas em Kubeflow e MLflow) para padronizar pipelines de treinamento e implantação de modelos no grupo[36]. O Luizalabs, laboratório de tecnologia da companhia, desenvolveu a plataforma Compass para democratizar IA internamente, permitindo que equipes de data science explorem, treinem e exponham modelos de ML de forma escalável na nuvem[36]. Isso reforça sua estratégia digital de atuar como ecossistema de serviços, e não apenas como varejista tradicional[36].
Dados recentes mostram a dimensão do impacto dessas iniciativas. O ecossistema do Mercado Livre movimentou R$ 381 bilhões em 2024 (3,2% do PIB) e já gera 111 mil empregos diretos no Brasil[2][9]. Para suportar esse volume, tanto Mercado Livre quanto outros marketplaces investem em infraestrutura de dados escalável e pipelines de ML avançados, tratando IA como área transversal que conecta crescimento e rentabilidade[9]. Modelos preditivos são aplicados em previsão de demanda, roteirização logística e personalização, o que permitiu ao Mercado Livre entregar cerca de 50% das compras no mesmo dia em grandes regiões (74% em até 48 horas)[9]. Em paralelo, a Amazon Web Services destaca que MLOps reduz tempo de lançamento no mercado e aumenta produtividade, ao combinar “menor tempo de introdução no mercado, produtividade aprimorada, implantação eficiente de modelos e constante retroalimentação de dados”[19].
Esses benefícios são amplificados em plataformas como a Shopee, que no Brasil concentra milhões de lojistas. Nesse contexto, soluções como as do Predize oferecem automação de atendimento baseada em IA: por meio da assistente “Mia”, a plataforma automatiza o atendimento 24/7, mesmo fora do horário comercial, garantindo o cumprimento de SLA (Service Level Agreement)[37]. A ferramenta consegue identificar tickets com risco de cancelamento e alertar o time de SAC para dar atenção redobrada, além de antecipar conversas automaticamente para garantir o contexto do atendimento, fazendo a separação entre pré e pós-venda[37]. Esse tipo de operacionalização de IA em escala é viabilizada por pipelines de MLOps que garantem que os modelos estejam sempre calibrados e servindo em produção[19][37].
2.4 MLOps na Detecção de Fraudes: Train-Once vs. Drift-Based
A detecção de fraudes é um caso de uso crítico em que as vantagens do MLOps ficam especialmente evidentes. Fraudes financeiras e digitais estão em constante evolução, de modo que modelos de ML precisam se adaptar a novas estratégias dos atacantes. A literatura em MLOps enfatiza que ML não é um sistema “treine uma vez, use para sempre”, mas sim um sistema que exige alinhamento contínuo com realidades que mudam[13][15]. Em fraude bancária, é comum o fenômeno de concept drift, em que o modelo treinado em padrões passados deixa de capturar comportamentos emergentes de fraude[12][16]. O KDNuggets ilustra essa dinâmica ao apontar que fraudadores entendem como o sistema funciona e mudam seu comportamento ao longo do tempo; portanto, um modelo de ML treinado em dados históricos não prediz com precisão as mudanças graduais nesse comportamento[12]. Para lidar com isso, a estratégia MLOps típica inclui monitoramento de performance em produção e disparo de retraining quando se detecta desvio significativo[12][20].
No caso da competição IEEE-CIS Fraud Detection (Kaggle), constatou-se que havia covariate shift entre o conjunto de treino e o de teste. Em um tutorial da competição, observa-se que “a distribuição dos dados muda do conjunto de treino para o teste, fenômeno chamado de covariate shift”[38]. Em outras palavras, os dados de transações futuras têm características diferentes das anteriores. Com um modelo trainonce, esse deslocamento implicaria queda de desempenho. Em contrapartida, uma abordagem drift-based (baseada em detecção de deriva) retreinaria periodicamente o modelo conforme chegam novos dados de transações, mantendo-o alinhado às tendências atuais[12][16]. Ferramentas modernas de MLOps facilitam exatamente esse tipo de fluxo: por exemplo, a AWS disponibiliza recursos em SageMaker para cálculo de baseline e checagem de drift em pipelines automatizados[39], enquanto frameworks dedicados permitem incluir rotinas automáticas de avaliação e rollback[39].
Na prática, a vantagem do MLOps em fraud detection é demonstrada por casos reais de mercado. Empresas financeiras têm recriado infraestruturas de dados em streaming para processar transações em tempo real, extrair características (feature stores) e servir modelos continuamente[31][40]. O blog da Techahead descreve a implementação do sistema “Sherlock” da fintech Revolut, em que o MLOps permitiu estruturar dados baseados em padrões de comportamento, dimensionar a solução para milhões de usuários em tempo real, garantir resiliência e monitorar continuamente o desempenho do modelo[40]. Graças a isso, a Revolut conseguiu reduzir drasticamente falsos positivos sem perder a taxa de detecção, protegendo milhões de transações de forma automática[40]. Em resumo, o pipeline de MLOps — que engloba ingestão de dados em tempo real, engenharia de atributos, treinamento automatizado e rollout gradual de modelos — tem se tornado padrão em sistemas de prevenção à fraude[20] [40].
Portanto, no confronto direto entre train-once e drift-based, os resultados teóricos e empíricos apontam vantagem clara para a segunda abordagem. Modelos estáticos são suscetíveis à deriva de conceito (concept drift), especialmente em ambientes hostis e mutáveis como o de fraudes financeiras[12][16]. Em contrapartida, pipelines MLOps permitem reorganizar rapidamente o ciclo de vida de ML: detectar mudanças nos dados, acionar retreinamentos e manter o modelo relevante ao longo do tempo. Como afirma a FinTech Weekly, plataformas integradas de MLOps “automatizam o retraining e a governança” justamente para reagir a tais mudanças[20]. Assim, em projetos como o da competição IEEE-CIS Fraud Detection, adotar MLOps significa implementar mecanismos de monitoramento de drift e reimplantação de modelos, garantindo que a solução contra fraudes acompanhe a evolução dos atacantes — condição essencial para diferenciação competitiva em setores de risco elevado[12][20].
2.5 Síntese da Fundamentação Teórica
A síntese da literatura acadêmica, documentação de plataformas internacionais e casos práticos brasileiros indica que o MLOps é hoje uma capacidade estratégica para empresas da economia digital. No e-commerce (Mercado Livre, Shopee, Magalu), em fintechs (Nubank, PicPay, Itaú), em serviços de delivery (iFood) e em saúde digital (Dasa e outras), a adoção de MLOps — entendida como automação de pipelines de ML, com monitoramento contínuo e governança robusta — reduz custos operacionais, acelera inovações e melhora a adaptabilidade dos sistemas inteligentes[8][22][29].
Em particular, no domínio da detecção de fraudes — em que as perdas anuais superam R$ 10 bilhões no Brasil — MLOps transforma o machine learning em uma solução dinâmica, superando as limitações de abordagens estáticas (train-once) e mantendo a eficácia dos modelos frente às mudanças constantes do mercado[31][40]. Plataformas corporativas como a do Itaú, que opera centenas de modelos de IA em produção apoiados por uma arquitetura de MLOps madura, ilustram como essa abordagem permite escalar casos de uso de forma controlada[22][24]. Já soluções especializadas de provedores como Datarisk, Dock e Signifyd mostram que é possível aplicar os mesmos princípios em ofertas de mercado voltadas para detecção de fraudes em diferentes segmentos de clientes, fornecendo “MLOps como serviço” para empresas de portes variados[3][31][32].
Esses fatores combinados mostram que o MLOps gera vantagens competitivas concretas na economia digital brasileira. No varejo online, iniciativas como as do Mercado Livre, descritas por Consumidor Moderno [2] e Product Gurus [9], evidenciam o impacto de modelos de recomendação e de otimização logística sobre a receita e a experiência do cliente. No setor financeiro, casos como o do Itaú Unibanco, analisados por Nogare e Silveira [22] e por Tele.Síntese [25], ilustram como arquiteturas de MLOps e IA fortalecem a prevenção a fraudes e a gestão de risco em larga escala. Em consonância com essas evidências empíricas, a literatura internacional reforça que MLOps é componente central para levar modelos de aprendizado de máquina à produção de forma confiável e sustentável [6][14][18]. A convergência entre resultados práticos e fundamentos teóricos indica que MLOps se consolidou como fator-chave de competitividade e inovação, ao integrar engenharia de software, ML e governança de dados em um ciclo de vida único.
3. METODOLOGIA
3.1 Visão geral do experimento
Esta pesquisa utiliza a base pública IEEE-CIS Fraud Detection [41], que reúne transações de um grande emissor internacional de cartões de crédito. Trabalhos anteriores mostram que sistemas de detecção de fraude em cartão de crédito operam tipicamente em cenários de forte desbalanceamento de classes, deriva de conceito e atraso na rotulagem [47][50]. A hipótese central deste trabalho é que uma política de MLOps com monitoramento contínuo de deriva de dados e retreino condicionado (DriftBased) é financeiramente superior a estratégias estáticas (Train-Once) ou a retreinos puramente agendados (Q30 e Q3M com intervalo de 60 dias).
O período de produção simulado cobre os dias 60 a 180 da série temporal do dataset. O modelo principal é treinado até o dia 59 e validado no intervalo de dias 60– 89, reproduzindo um cenário em que o modelo vai para produção somente após uma validação temporalmente coerente. A partir do dia 60 são avaliadas quatro políticas de operação do modelo: Train-Once, Q30, Q3M (60 dias) e Drift-Based; no cenário com custo real de fraude adiciona-se ainda a política Drift + Recall Guard.
3.2 Engenharia de atributos
A etapa de feature engineering começa com o script build_features_hourly.py, que produz o arquivo data/warehouse/curated/features_hourly.parquet com agregações numéricas por hora derivadas das tabelas train_transaction e train_identity. Em vez de usar diretamente identificadores sensíveis (como IP ou e-mail), o pipeline trabalha com estatísticas agregadas construídas a partir de colunas já anonimizadas do IEEE-CIS.
Para enriquecer o histórico por entidade e, opcionalmente, adicionar embeddings de grafo, executa-se em seguida scripts/build_graph_embeddings.py, que lê f e a t u r e s _ h o u r l y. p a r q u e t e g r a v a d a t a / w a r e h o u s e / c u r a t e d / features_hourly_graph.parquet. Esse segundo Parquet inclui contagens históricas de transações e fraudes por nó do grafo (graph_tx_count, graph_fraud_count, graph_fraud_rate) e pode receber colunas graph_emb_* se o Node2Vec estiver habilitado, sem expor identificadores crus.
As principais famílias de atributos são:
• agregações horárias de valor de transação (TransactionAmt_mean, TransactionAmt_std, mínimo, máximo e contagens);
• estatísticas derivadas das colunas C1, C5, D1, D15, V258 e id_02 (médias, desvios e contagens por janela);
• contagens históricas por entidade construídas a partir de grafos de relacionamento: graph_tx_count, graph_fraud_count e graph_fraud_rate (e, opcionalmente, embeddings graph_emb_*).
Com esse fluxo em duas etapas, o núcleo do modelo enxerga cerca de trinta atributos agregados na versão base e passa a mais de 30 colunas quando as contagens de grafo são adicionadas em features_hourly_graph.parquet. Embeddings graph_emb_* podem expandir ainda mais esse núcleo quando habilitados, mas a lógica principal do experimento permanece centrada nesse conjunto de atributos derivados e agregados.
3.3 Modelo principal e Recall Guard
O modelo principal é um ensemble do tipo stacking formado por dois classificadores de gradiente de decisão (LightGBM [42] e HistGradientBoosting, via scikit-learn [43]) e uma regressão logística como meta-estimator. O treinamento considera pesos financeiros proporcionais ao valor da transação e ao multiplicador de chargeback definido em configs/policy.yaml, de forma que o modelo aprenda diretamente o trade-off entre bloquear fraudes e evitar falsos positivos.
Na validação (dias 60–89) o stacking atinge ROC AUC em torno de 0,76, PR AUC de 0,32 e Brier Score de aproximadamente 0,049, com cutoff ótimo de lucro próximo de 0,97. O uso combinado de ROC AUC, PR AUC e Brier Score segue recomendações da literatura para avaliação de classificadores probabilísticos em conjuntos desbalanceados [48][49][50]. Os componentes individuais (LightGBM e HistGradientBoosting) apresentam desempenho ligeiramente superior em termos de ROC AUC, mas o ensemble é mantido como modelo operacional por combinar as vantagens de ambos.
Para os cenários com custo real de fraude (fn_cost_multiplier = 1.0), o modelo principal é complementado por um Recall Guard treinado separadamente. Esse guardião é um LightGBM auxiliar calibrado para operar com threshold em torno de 0,29 e recall alvo de 95 % em relação ao rótulo de fraude. Ele não substitui o modelo principal, mas funciona como camada adicional de checagem para transações de alto valor: sempre que o guard prevê fraude com alta confiança em uma transação que o modelo principal aprovaria, a decisão é forçada para “bloquear”. Assim, a política Drift + Guard reduz drasticamente o número de falsos negativos em tickets críticos sem alterar o restante do fluxo de decisão.
3.4 Políticas de retreino avaliadas
Foram simuladas as seguintes políticas de manutenção de modelo:
• Train-Once — o modelo treinado até o dia 59 é congelado e usado sem retreinos entre os dias 60 e 180;
• Q30 — retreinos agendados a cada 30 dias. No horizonte analisado isso resulta em quatro novos treinamentos, com janelas que se iniciam nos dias 90, 120, 150 e 180;
• Q3M (60 dias) — retreinos agendados a cada 60 dias. No horizonte de produção considerado (dias 60–180), isso resulta em um único novo treinamento programado no dia 120, cuja promoção para produção é decidida com base no ganho financeiro em relação ao modelo vigente;
• Drift-Based — retreinos condicionados a sinais de deriva nas distribuições de entrada e nos scores do modelo;
• Drift + Recall Guard — política usada apenas no cenário com custo real de fraude. Aqui o fluxo de Drift-Based é mantido, mas as decisões finais passam ainda pelo guardião de recall descrito na Seção 3.3.
3.5 Detecção de deriva e gatilhos de retreino
Na estratégia Drift-Based o retreino não é disparado por datas fixas nem por métricas de desempenho com rótulo (como AUC diário ou variação de recall). O motor de simulação implementa apenas checagens baseadas em distribuição dos atributos e dos scores, em linha com a literatura de concept drift [47] e com práticas recomendadas de MLOps [15][51]. Os thresholds são definidos em monitoring/thresholds.yaml.
Os gatilhos considerados combinam:
• Population Stability Index (PSI): são avaliados tanto o PSI máximo quanto a mediana entre as features numéricas. Valores acima de limites moderados ou severos configurados indicam mudança significativa na distribuição das variáveis de entrada;
• Kolmogorov–Smirnov (KS): é monitorada a diferença máxima entre as distribuições de scores do período de produção e da janela de referência. Um KS acima do cutoff definido sugere alteração relevante no comportamento do modelo;
• Variação percentual da entropia dos scores: o simulador acompanha a entropia dos scores de fraude ao longo do tempo. Picos de entropia além do limite percentual configurado sinalizam perda de separação entre classes.
Sempre que uma combinação destas métricas ultrapassa os limiares configurados por um determinado número de horas ou dias consecutivos, o motor marca um evento de deriva e agenda um novo treinamento usando os dados mais recentes. Uma vez concluído o retreino e aprovado o candidato, o modelo corrente da estratégia Drift-Based é substituído pelo novo artefato, e as métricas passam a monitorar o comportamento desse modelo atualizado.
3.6 Métricas financeiras
Além das métricas clássicas de classificação (ROC AUC, PR AUC, Brier Score [48][49]), a comparação entre estratégias é baseada em indicadores financeiros acumulados ao longo dos dias 60–180:
• Perda evitada — valor total das transações fraudulentas que foram corretamente bloqueadas;
• Custo de falso positivo (FP) — valor associado às transações legítimas bloqueadas; incorpora fatores de retenção no Capítulo 5;
• Custo de falso negativo (FN) — apenas no cenário com custo real de fraude, corresponde ao valor das transações fraudulentas aprovadas;
• Custo de computação — custo aproximado de monitoramento contínuo do modelo;
• Custo de retreino — custo incremental associado a cada novo treino disparado;
• Lucro líquido — perda evitada menos custo de FP, custo de FN (quando aplicável) e custos de computação/retreino;
• ROI — razão entre lucro líquido e somatório dos custos.
Essas métricas são materializadas nos arquivos kpis_dia.csv e strategy_summary.csv do repositório [46] e servem de base para os comparativos apresentados nos capítulos seguintes.
O cálculo de lucro varia de acordo com a política financeira configurada em cada cenário:
• no cenário legado 559k vs 229k, utiliza-se chargeback_fee_pct = 1,0 e não há custo direto de FN (fn_cost_multiplier = 0), de modo que o cutoff ótimo por lucro considera apenas a perda evitada ponderada pelo custo de falsos positivos e pelo multiplicador de chargeback. O repositório está versionado atualmente com chargeback_fee_pct = 0,0 (cenário Fee 0); para recomputar o cenário legado é necessário ajustar configs/policy.yaml para 1,0 antes do treino e das simulações;
• no cenário Fee 0 + Guard, o multiplicador de chargeback é zerado (chargeback_fee_pct = 0,0) e passa-se a considerar explicitamente o custo das fraudes aprovadas por meio de fn_cost_multiplier = 1,0, de forma que cada FN custa aproximadamente o valor da transação fraudulenta.
Sempre que este texto mencionar “cutoff ótimo por lucro”, o cálculo deve ser interpretado à luz da política de custos específica de cada cenário.
4 ARQUTETURA MLOPS E IMPLEMENTAÇÃO
4.1 Organização do repositório
A implementação do experimento foi organizada como um projeto de MLOps completo, com separação clara entre código reutilizável, pipelines de orquestração e scripts de automação. O código-fonte está disponibilizado em repositório público do autor [46]. De forma resumida, a estrutura principal é:
• src/fraud_mlops/ — núcleo de código de negócio: ◦ features/ — atualmente contém o módulo hourly.py, responsável por construir as features horárias agregadas;
• models/ — rotinas de treinamento, busca de cutoffs de lucro e serialização do ensemble stacking;
• simulator/ — motor de simulação financeira e de políticas de retreino;
• pipelines/ — comandos de alto nível (via Typer) para ingestão, construção de features, treinamento, simulação e monitoramento;
• simulator/ (diretório na raiz) — camada de CLI que encadeia o motor de simulação e os exports para dashboards;
• monitoring/ — parâmetros e scripts usados pelo Evidently [45] e pelos gatilhos de deriva;
• data/ — árvore de dados com subpastas regeneráveis (warehouse/, results/) e artefatos consolidados (exports/, reports/, models/);
• docs/ — documentação técnica e material específico do TCC (métricas, runbooks, figuras);
• .dvc/ — diretório de configuração do Data Version Control (DVC), inicializado com cache local em .dvc/site-cache e, na versão atual, sem remote configurado. Esse diretório armazena os metadados de versionamento dos principais artefatos de dados do projeto.
4.2 Pipeline de dados e treinamento
O fluxo padrão para reproduzir o cenário considerado no TCC é o seguinte:
- Geração de features horárias — executar o comando make features_hourly START_DAY=0 END_DAY=180, que roda features/hourly.py para toda a janela temporal e grava data/warehouse/ curated/features_hourly.parquet.
- Enriquecimento de grafos — executar python scripts/build_graph_embeddings.py, que lê o Parquet base e grava data/warehouse/curated/ features_hourly_graph.parquet com contagens por entidade (e, opcionalmente, embeddings graph_emb_*).
- Treinamento do ensemble stacking — executar o comando python pipelines/train.py –features-path data/warehouse/curated/ features_hourly_graph.parquet –train-end-day 59 –valid-start-day 60 –valid-endday 89 –model-type stacking –model-name model_day89_stacking_graph, salvando o artefato e as métricas correspondentes.
- Simulação das estratégias — executar python simulator/run_simulation.py –strategy {train_once,q30,q3m,drift} -features-pathata/warehouse/curated/features_hourly_graph.parquet –modelpath data/models/model_day89_stacking_graph.joblib –start-day 60 –end-day180 –thresholds-path monitoring/thresholds.yaml, aplicando fn_cost_multiplier = 0 para o cenário legado ou fn_cost_multiplier = 1 e –recall-guard-path data/models/recall_guard.joblib para o cenário Fee 0 + Guard. O script scripts/run_full_scenario.py encapsula essa sequência.
- Exportação de KPIs — executar python simulator/export_for_looker.py –input-dir data/results/simulations –out data/exports, consolidando os Parquets em CSVs (kpis_hora.csv, kpis_dia.csv, strategy_summary.csv, retention_summary.csv) usados nas análises e dashboards.
- Rastreabilidade de experimentos — o histórico de execuções de treino e simulação é armazenado via MLflow [44], permitindo inspecionar métricas, parâmetros e artefatos de cada run.
Complementarmente, o repositório utiliza o DVC para versionar dados e modelos. Estão sob controle de DVC, com cache local em .dvc/site-cache, os diretórios data/exports/ (incluindo os arquivos de KPIs, resumos de estratégias e o snapshot scenario_559_vs_229/), data/models/ (modelo model_day89_stacking_graph com seu arquivo de métricas e o artefato recall_guard) e data/results/ (scores de monitoramento e saídas de simulação para os cenários 559k vs 229k em simulations/ e o pacote consolidado das simulações Fee 0 + Guard em simulations_fee0_all/). Ainda não há remote configurado, de modo que o versionamento é mantido localmente.
Para o cenário com custo real de fraude (chargeback_fee_pct = 0 e fn_cost_multiplier = 1), um script adicional é utilizado para simular a política Drift + Recall Guard e salvar os resultados em um diretório específico, posteriormente agregado em data/exports/strategy_summary.csv.
4.3 Monitoramento de deriva e Evidently
O monitoramento em produção é baseado em duas camadas:
• monitoramento estatístico — o script pipelines/monitor_hourly.py utiliza o Evidently [45] para comparar uma janela de referência (scores_baseline) com a janela corrente (scores), gerando relatórios HTML e JSON com PSI, KS e métricas de estabilidade de distribuição de scores;
• gatilhos operacionais de retreino — o arquivo monitoring/thresholds.yaml define limiares para as métricas de distribuição que, quando ultrapassados de forma persistente, disparam um retreino no motor de simulação. Esses thresholds incluem: PSI mediano e máximo por feature; KS dos scores; variação percentual da entropia dos scores; e parâmetros de persistência (por exemplo, número mínimo de horas consecutivas em estado “moderate” ou “severe”).
Na implementação atual, os gatilhos de retreino não utilizam métricas de performance dependentes de rótulo, como AUC diário, queda de recall ou F1 em janelas deslizantes. Todo o mecanismo de detecção de deriva é construído com base em medidas de mudança de distribuição (PSI, KS e entropia), de modo a refletir um cenário realista em que os rótulos completos de fraude chegam com atraso [47][50].
4.4 Simulador financeiro e promoção de modelos
O módulo src/fraud_mlops/simulator/engine.py é responsável por simular o fluxo financeiro para cada estratégia. Em cada dia simulado, o motor aplica os thresholds segmentados do modelo (por faixa de valor de transação), registra fraudes bloqueadas, falsos positivos, falsos negativos e custos de computação, e decide se é necessário retreinar.
Quando ocorre um retreino na estratégia Drift-Based, o candidato treinado é avaliado financeiramente e, se aprovado, substitui o modelo corrente da estratégia. Isso significa que o Drift-Based não mantém sempre o modelo inicial em produção: ao longo da janela de dias 60–180, quatro modelos sucessivos são promovidos (por exemplo, versões associadas aos dias 73, 76, 78 e 119), sempre que os gatilhos de deriva são atendidos e o retreino apresenta ganho financeiro em relação ao modelo anterior.
A sequência de artefatos de modelo utilizados na estratégia Drift-Based, bem como seus gatilhos de treino em produção e janelas de treino/validação, pode ser sumarizada em uma tabela específica. Nela também é incluído o artefato recall_guard.joblib, treinado offline com foco em alto recall e aplicado apenas na política Drift + Recall Guard descrita no Capítulo 3.
[Tabela 4.1 – Artefatos de modelo, gatilhos de treino e janelas de treino/validação na estratégia Drift-Based e no Recall Guard.]
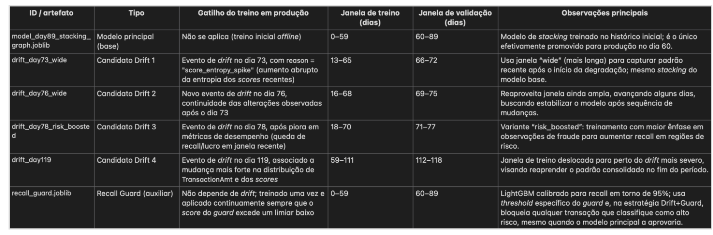
Os metadados dessas promoções (datas, lucro incremental, número de fraudes bloqueadas e falsos positivos sob o candidato) são persistidos em arquivos *_meta.json por estratégia e também consolidados em data/exports/strategy_events.csv, permitindo auditar quando e por que cada modelo foi substituído.
4.5 Testes, validação e limitações
Do ponto de vista de engenharia de software, o repositório não possui uma suíte formal de testes unitários baseada em frameworks como pytest ou unittest. O arquivo test.py existente funciona apenas como um script de smoke test que lê um Parquet e imprime algumas estatísticas, sem asserts automatizados nem integração com o pipeline de CI.
A garantia de qualidade é feita principalmente por meio de:
· reprodutibilidade dos experimentos (scripts e Makefile que recriam todo o cenário a partir dos dados brutos);
· validações manuais em notebooks e na interface do MLflow [44], comparando métricas de treino, validação e simulação;
· inspeção dos relatórios do Evidently [45] para checar consistência de distribuições ao longo do tempo.
Trabalhos como Sculley et al. [15] e Breck et al. [51] ressaltam a importância de testes sistemáticos, monitoramento e boas práticas de engenharia para reduzir o “débito técnico” em sistemas de aprendizado de máquina. No contexto deste projeto, a maturidade de engenharia está concentrada na automação de pipelines, no versionamento de artefatos por meio do DVC e na rastreabilidade via MLflow, mas ainda não há uma bateria sistemática de testes unitários ou de integração, o que é apontado como limitação e oportunidade de evolução.
5 RESULTADOS
5.1 Cenário legado — 559 k vs 229 k
O primeiro conjunto de resultados considera a política financeira original usada no storytelling do TCC, em que o custo direto de fraude aprovada (FN) é desativado (fn_cost_multiplier = 0) e admite-se um multiplicador de chargeback (chargeback_fee_pct = 1,0). Nesse arranjo, o custo de falso negativo não aparece explicitamente nos relatórios; o foco é comparar quanto cada estratégia consegue evitar em perda com fraude, dado o mesmo modelo base.
Na janela de produção dos dias 60–180, o resumo financeiro por estratégia é:
· Train-Once: perda evitada de aproximadamente US$ 584 mil, custo de falsos positivos de ~US$ 355 mil e lucro líquido em torno de US$ 230 mil;
· Q3M (60 dias): perda evitada de ~US$ 831 mil, custo de FP de ~US$ 309 mil e lucro de ~US$ 522 mil;
· Q30 (30 dias): perda evitada de ~US$ 868 mil, custo de FP de ~US$ 432 mil e lucro de ~US$ 436 mil;
· Drift-Based: perda evitada de ~US$ 816 mil, custo de FP de ~US$ 256 mil e lucro de ~US$ 560 mil.
[Tabela 5.1 – Resultados financeiros por estratégia no cenário legado (559 k vs 229 k).]

Apesar de Q30 maximizar a perda evitada bruta, a estratégia Drift-Based alcança o melhor equilíbrio entre bloqueio de fraudes e redução de falsos positivos, resultando no maior lucro acumulado e em um ROI médio em torno de 2,18×. A diferença de lucro entre Drift-Based e Train-Once supera US$ 329 mil no período, sustentando a tese de que monitorar deriva e retreinar sob demanda gera vantagem competitiva mesmo quando o custo direto de FN não é explicitamente contabilizado.
Nesse cenário, o Drift-Based executa quatro retreinos nos dias 73, 76, 78 e 119. A cada evento de retreino o modelo candidato é comparado ao modelo em produção e, quando o ganho financeiro é positivo, um novo artefato é promovido. Assim, os resultados reportados para a estratégia Drift-Based correspondem à sequência de quatro modelos efetivamente colocados em produção, e não a uma única versão estática do modelo treinado até o dia 59.
5.2 Cenário Fee 0 — custo real de fraude e Drift + Recall Guard
No segundo cenário, denominado Fee 0, o multiplicador de chargeback é zerado (chargeback_fee_pct = 0) e passa-se a contabilizar explicitamente o custo de fraudes aprovadas (FN), configurando fn_cost_multiplier = 1,0. Isso equivale a assumir que cada fraude que passa pelo modelo gera perda igual ao ticket fraudado, enquanto falsos positivos continuam representando perda de venda legítima.
Os resultados agregados mostram que, sob essa política mais realista, todas as estratégias estáticas se tornam fortemente deficitárias:
· Train-Once registra lucro acumulado negativo na ordem de −US$ 1,77 milhão;
· Q3M (60 dias) e Q30 também ficam no vermelho, com lucros entre −US$ 1,70 milhão e −US$ 1,60 milhão;
· em todas essas estratégias, o custo de FN domina o P&L, somando aproximadamente US$ 5,4 milhões em fraudes aprovadas.
[Tabela 5.2 – Resultados financeiros por estratégia no cenário Fee 0 (custo real de fraude).]

Para mitigar esse efeito, é introduzida a política Drift + Recall Guard. Nessa configuração, os fluxos de monitoramento e retreino do Drift-Based são mantidos, mas as decisões em tickets de maior valor são revisadas pelo guardião descrito na Seção 3.3. O guard força o bloqueio de transações em que o modelo principal estaria inclinado a aprovar, mas o LightGBM auxiliar identifica risco elevado, garantindo recall de, no mínimo, 95 % em fraudes de alto impacto.
O repositório preserva os resultados dessa estratégia em forma de exports agregados (data/exports/strategy_summary.csv, docs/tcc/fn_cost_fee0.csv) e em um pacote consolidado de simulações Fee 0 com guard (data/results/simulations_fee0_all/, versionado via DVC). A partir desses artefatos, observa-se que:
· Drift + Guard evita cerca de US$ 2,0 milhões em perda com fraude;
· o custo de falsos positivos fica em torno de US$ 553 mil;
· o custo de FN cai drasticamente para aproximadamente US$ 123 mil, com menos de 800 fraudes aprovadas em toda a janela;
· o lucro líquido acumulado da estratégia atinge cerca de US$ 1,30 milhão, com ROI médio de 2,36×.
Na prática, isso significa que, quando o custo real da fraude é levado em conta, apenas a combinação de monitoramento de deriva com recall guard consegue manter o experimento no azul. As estratégias estáticas, mesmo com retreinos agendados, não conseguem compensar o volume de fraudes aprovadas e permanecem financeiramente inviáveis. Essa sensibilidade ao custo de FN é coerente com formulações mais realistas de sistemas de detecção de fraude em cartão de crédito [50].
5.3 Análise de retenção de clientes
Um aspecto crítico na mensuração do custo de falsos positivos é a taxa de retorno dos clientes legítimos que tiveram sua compra bloqueada por engano. A literatura e relatórios de mercado indicam que uma fração desses clientes não retorna após um bloqueio indevido, o que implica perda permanentemente maior do que o valor de uma única transação.
Para capturar esse efeito, foi calculado um conjunto de cenários de retenção em que o custo de falso positivo é ampliado pela fração de clientes que não voltam a comprar. O arquivo data/exports/retention_summary.csv traz os resultados para três hipóteses principais:
· 100 % de retenção — cenário otimista em que todos os clientes bloqueados retornam;
· 85 % de retenção — cenário intermediário, alinhado a contextos com forte estratégia de fidelização;
· 58 % de retenção — cenário pessimista, em que cerca de 42 % dos clientes que sofreram um bloqueio indevido não retornam.
[Tabela 5.3 – Lucro e ROI por estratégia sob diferentes hipóteses de retenção.]

A análise de retenção é aplicada a todas as estratégias consideradas neste trabalho, incluindo a política Drift + Recall Guard. Tanto data/exports/ retention_summary.csv quanto data/exports_tcc/retention_summary.csv apresentam linhas específicas para a estratégia drift_guard em cada uma das três taxas de retenção, com os respectivos lucros e ROIs recalculados. Isso permite comparar diretamente o impacto da política de MLOps mais avançada em cenários em que uma parcela dos clientes legítimos não retorna após um bloqueio indevido.
5.4 Reprodutibilidade e limitações
O repositório preserva integralmente os Parquets horários e diários, além dos metadados de simulação, para as estratégias Train-Once, Q30, Q3M (60 dias) e DriftBased nos cenários analisados. Isso torna reprodutíveis os números do cenário legado (559 k vs 229 k) e permite auditar passo a passo cada evento de retreino, evolução de lucro, volume de fraudes bloqueadas e falsos positivos.
Esses artefatos — em particular os diretórios data/models/, data/results/ e data/ exports/ — estão versionados via DVC, o que facilita recuperar estados anteriores do experimento e reconectar modelos, simulações e KPIs mesmo após modificações no código. Como o cache é local e não há remote configurado, o versionamento é mantido no próprio repositório de trabalho.
Para a política Drift + Recall Guard, o repositório mantém exports agregados (em data/exports/strategy_summary.csv e docs/tcc/fn_cost_fee0.csv) e um pacote consolidado em data/results/simulations_fee0_all/, também rastreado via DVC. Ainda que esse pacote não siga exatamente a mesma estrutura de diretórios que as estratégias base, ele preserva os resultados necessários para reconstruir os indicadores financeiros e comparar a política Drift + Guard com as demais.
Essa caracterização dos limites de reprodutibilidade é importante para manter a transparência científica do trabalho e sinaliza claramente quais resultados podem ser revisados linha a linha (estratégias base) e quais dependem de artefatos consolidados (Drift + Guard).
6 DISCUSSÃO E CONCLUSÕES
6.1 Síntese dos achados
Os resultados obtidos nos dois cenários avaliados reforçam a tese central do trabalho: políticas de MLOps que combinam monitoramento contínuo de deriva com retreinos condicionados geram vantagem financeira relevante em relação a estratégias estáticas ou a retreinos puramente agendados [15][47][51].
No cenário legado, em que o custo direto de fraudes aprovadas não é contabilizado, a estratégia Drift-Based gera um lucro adicional de aproximadamente US$ 330 mil em comparação com o baseline Train-Once, mesmo com apenas quatro retreinos ao longo de 121 dias de produção. Esse ganho decorre principalmente de duas frentes: (i) capacidade de adaptar o modelo às mudanças de distribuição capturadas por PSI, KS e entropia de scores (concept drift [47]); e (ii) redução significativa de falsos positivos em relação às políticas de retreino agendado.
Quando o custo real de fraude é introduzido (cenário Fee 0), o papel do MLOps torna-se ainda mais evidente. As três estratégias estáticas — Train-Once, Q3M (60 dias) e Q30 — passam a operar consistentemente no prejuízo, com perdas de mais de US$ 1,6 milhão em todos os casos. O custo agregado de falsos negativos domina o P&L e torna o negócio inviável, em linha com o que se observa em estudos de sistemas reais de detecção de fraude [50].
A combinação de Drift-Based com Recall Guard, por sua vez, consegue reverter esse quadro: reduz o custo de falsos negativos em mais de uma ordem de grandeza, aumenta a perda evitada para cerca de US$ 2,0 milhões e entrega lucro líquido acima de US$ 1,3 milhão, com ROI positivo mesmo considerando custos de compute e de retreino. Em outras palavras, o guard mostra-se uma peça-chave para transformar um cenário teoricamente promissor, mas deficitário, em uma política operacionalmente sustentável.
6.2 Implicações para empresas brasileiras de economia digital
Embora o experimento tenha sido conduzido sobre uma base internacional anonimizada [41], os padrões observados são altamente relevantes para empresas brasileiras de e-commerce, fintechs e plataformas de delivery:
· Dependência do custo de fraude — muitos times ainda avaliam modelos apenas por AUC ou pela quantidade de fraudes bloqueadas. Os resultados mostram que, sem contabilizar o custo direto de fraudes aprovadas, pode-se chegar a conclusões excessivamente otimistas sobre o valor de uma estratégia;
· Importância de monitorar deriva — em ambientes com forte mudança de comportamento (promoções, sazonalidade, novos meios de pagamento), políticas Train-Once tendem a degradar rapidamente. O Drift-Based com thresholds bem calibrados oferece uma camada de defesa para detectar quando o modelo deixou de representar a realidade [47];
· Valor de guardiões de recall — em contextos regulados (instituições financeiras, arranjos de pagamento), tolerar um alto volume de falsos negativos pode ser tão crítico quanto gerar muitos falsos positivos. Guardiões leves, treinados com foco em recall, são uma solução prática para reduzir falsos negativos em segmentos de maior risco sem reescrever todo o pipeline.
Para a realidade brasileira, onde há forte pressão regulatória e margens apertadas, a combinação de monitoramento, retreino condicional e guardiões especializados pode ser a diferença entre um programa de prevenção a fraudes que agrega valor ao negócio e um que apenas transfere o problema de um lugar para outro.
6.3 Limitações
Além das limitações clássicas de trabalhos baseados em datasets públicos (como anonimização e ausência de custos específicos do contexto local), este projeto apresenta algumas restrições específicas:
- Ausência de suíte formal de testes — o repositório não conta com testes unitários estruturados. Isso aumenta o risco de regressões silenciosas à medida que novas funcionalidades são adicionadas [15][51];
- Simplificações na política financeira — embora tenha havido esforço para aproximar os custos de compute da realidade de serviços gerenciados em nuvem e para considerar retenção de clientes após falsos positivos, outras dimensões importantes ficaram de fora (por exemplo, custos operacionais de análise manual, impacto de chargebacks em reputação perante bandeiras, entre outros);
- Foco em um único modelo base — todas as simulações partem do ensemble stacking treinado até o dia 59, baseado em LightGBM [42] e scikitlearn [43]. Não foram exploradas alternativas como modelos especializados por segmento, ensembles heterogêneos em produção ou estratégias de champion– challenger.
Esses pontos não invalidam as conclusões do estudo, mas delimitam claramente o espaço em que elas são válidas e indicam cuidados para qualquer tentativa de replicar o experimento em ambiente de produção.
6.4 Trabalhos futuros
A partir das evidências reunidas, há vários caminhos naturais para evolução do projeto:
- Introduzir uma suíte de testes MLOps — construir testes unitários para os módulos de features, treinamento e simulador, além de testes de regressão para o pipeline completo, reduziria riscos de alteração inadvertida de métricas financeiras [51];
- Explorar múltiplos modelos em produção — estender o simulador para comparar políticas de champion–challenger, modelos especializados por canal ou por faixa de ticket, e ensembles dinâmicos;
- Aprofundar a modelagem de custos — incorporar custos operacionais, efeitos de reputação, diferentes perfis de chargeback e taxas de desconto financeiro tornaria o P&L ainda mais próximo da realidade de instituições brasileiras;
- Aplicar a outras fontes de dados — replicar o framework em bases reais de e-commerce nacional, arranjos de pagamento ou plataformas de delivery, respeitando as restrições de sigilo bancário e de dados pessoais.
Em síntese, o trabalho demonstra que a adoção de práticas de MLOps — especialmente monitoramento de deriva, retreino condicionado e guardiões de recall — não é apenas um “luxo tecnológico”, mas um componente central de estratégias de prevenção a fraudes financeiramente sustentáveis. Mesmo com as limitações apontadas, os resultados sugerem que organizações que investem em ciclos de vida de modelos mais maduros tendem a capturar vantagens competitivas significativas na economia digital brasileira.
7. REFERÊNCIAS
[1] THE PAYPERS. Brazil: 2024 analysis of payments and ecommerce trends. 2024. Disponível em: https://thepaypers.com/payments/expert-views/brazil-2024-analysis-ofpayments-and-ecommerce-trends. Acesso em: 16 nov. 2025.
[2] CONSUMIDOR MODERNO. Como o Mercado Livre está se tornando um dos principais destinos de compra dos brasileiros. [S.l.], 2025. Disponível em: https:// consumidormoderno.com.br/mercado-livre-tecnologia-logistica-brasil/. Acesso em: 16 nov. 2025.
[3] SIGNIFYD. Machine learning e análise de dados no combate às fraudes. [S.l.], 2024. Disponível em: https://br.signifyd.com/blog/machine-learning-e-analise-de-dados-nocombate-as-fraudes/. Acesso em: 16 nov. 2025.
[4] SERASA EXPERIAN; CLEARSALE. Machine learning na detecção de fraudes: como a tecnologia protege seu negócio. [S.l.], 2025. Disponível em: https:// www.serasaexperian.com.br/conteudos/machine-learning-na-deteccao-de-fraudescomo-tecnologia-protege-seu-negocio/. Acesso em: 16 nov. 2025.
[5] CLEARSALE. ClearSale unveils retail fraud prevention tools in new product portfolio. Business Wire, Miami, 14 ago. 2024. Disponível em: https:// www.businesswire.com/news/home/20240814502761/en/ClearSale-Unveils-RetailFraud-Prevention-Tools-in-New-Product-Portfolio. Acesso em: 16 nov. 2025.
[6] IBM. O que é MLOps? [S.l.], 2024. Disponível em: https://www.ibm.com/br-pt/think/topics /mlops. Acesso em: 16 nov. 2025.
[7] DATAFOREST. AI with MLOps: the end of silos, the start of growth. [S.l.], 2025. Disponível em: https://dataforest.ai/blog/ai-and-mlops. Acesso em: 16 nov. 2025.
[8] E-COMMERCE BRASIL. Como a IA está revolucionando as compras no ecommerce. [S.l.], 2025. Disponível em: https://www.ecommercebrasil.com.br/artigos/ como-a-ia-esta-revolucionando-as-compras-no-e-commerce. Acesso em: 16 nov. 2025.
[9] PRODUCT GURUS. Parte 3: como o Mercado Livre usa a IA para escalar e aumentar ROI. [S.l.], 2025. Disponível em: https://www.productgurus.com.br/p/parte-como-o-mercado-livre-usa. Acesso em: 16 nov. 2025.
[10] NUBANK. Data and AI culture: how Nu’s philosophy became a competitive advantage. Building Nubank, [s.l.], [s.d.]. Disponível em: https://building.nubank.com/ data-and-ai-culture-how-nus-philosophy-became-a-competitive-advantage/. Acesso em: 16 nov. 2025.
[11] PICPAY. Como o PicPay usa inteligência artificial para facilitar a sua vida. [S.l.], [s.d.]. Disponível em: https://blog.picpay.com/como-o-picpay-usa-inteligencia-artificial/. Acesso em: 16 nov. 2025.
[12] KDNUGGETS. Managing model drift in production with MLOps. 2023. Disponível em: https://www.kdnuggets.com/2023/05/managing-model-drift-productionmlops.html. Acesso em: 16 nov. 2025.
[13] SYMUFOLK. How to detect and handle data drift in ML. [S.l.], [s.d.]. Disponível em: https://symufolk.com/detect-and-handle-data-drift-in-ml/. Acesso em: 16 nov. 2025.
[14] KREUZBERGER, Dominik; KÜHL, Niklas; HIRSCHL, Sebastian. Machine learning operations (MLOps): overview, definition, and architecture. arXiv preprint, 2022. (arXiv:2205.02302). Disponível em: https://arxiv.org/abs/2205.02302. Acesso em: 16 nov. 2025.
[15] SCULLEY, D. et al. Hidden technical debt in machine learning systems. In: ADVANCES IN NEURAL INFORMATION PROCESSING SYSTEMS – NIPS 2015, 28., 2015. Proceedings […]. [S.l.: s.n.], 2015. Disponível em: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf. Acesso em: 16 nov. 2025.
[16] EVIDENTLY AI. Which test is the best? We compared 5 methods to detect data drift on large datasets. Evidently Blog, 20 jun. 2022. Disponível em: https:// www.evidentlyai.com/blog/data-drift-detection-large-datasets. Acesso em: 16 nov. 2025.
[17] UNIVERSIDADE FEDERAL DO PARANÁ. Streaming and concept drift: a comparative study. Curitiba: UFPR, [s.d.]. Disponível em: https://acervodigital.ufpr.br/ xmlui/handle/1884/93465. Acesso em: 16 nov. 2025.
[18] HUYEN, Chip. Designing Machine Learning Systems: An Iterative Process for Production-Ready Applications. Sebastopol: O’Reilly Media, 2022.
[19] AMAZON WEB SERVICES. O que é MLOps? Explicação sobre operações de machine learning. [S.l.], [s.d.]. Disponível em: https://aws.amazon.com/pt/what-is/ mlops/. Acesso em: 16 nov. 2025.
[20] FINTECH WEEKLY. How to manage AI model drift in fintech applications. [S.l.: s.n.], [s.d.]. Disponível em: https://www.fintechweekly.com/magazine/articles/ai-modeldrift-management-fintech-applications. Acesso em: 16 nov. 2025.
[21] THOUGHTWORKS. MLOps and LLMOps. Thoughtworks Brazil, [s.l.], [s.d.]. Disponível em: https://www.thoughtworks.com/en-br/what-we-do/ai/mlops. Acesso em: 16 nov. 2025.
[22] NOGARE, Diego; SILVEIRA, Ismar Frango. Experimentation, deployment and monitoring Machine Learning models: approaches for applying MLOps. arXiv preprint, arXiv:2408.11112, 2024. Disponível em: https://arxiv.org/abs/2408.11112. Acesso em: 16 nov. 2025.
[23] MEDEIROS, Henrique. Itaú usa inteligência artificial para combater fraudes e golpes. Mobile Time, [s.l.], 14 abr. 2025. Disponível em: https://www.mobiletime.com.br/ noticias/14/04/2025/itau-ia-comportamento/. Acesso em: 16 nov. 2025.
[24] ITAÚ UNIBANCO. Protegendo os clientes do Itaú e promovendo uma sociedade mais justa e segura através de dados e IA. AWS Brasil Blog, [s.l.], [s.d.]. Disponível em: https://aws.amazon.com/pt/blogs/aws-brasil/protegendo-os-clientes-doitau-e-promovendo-uma-sociedade-mais-justa-e-segura-atraves-de-dados-e-ia/. Acesso em: 16 nov. 2025.
[25] TELE.SÍNTESE. Itaú reforça segurança com IA e machine learning para a Black Friday. Tele.Síntese, [s.l.], 21 nov. 2023. Disponível em: https:// telesintese.com.br/itau-reforca-seguranca-com-ia-e-machine-learning-para-a-blackfriday/. Acesso em: 16 nov. 2025.
[26] PRICEWATERHOUSECOOPERS. Pesquisa Fintech Deep Dive 2024. São Paulo, 2024. Disponível em: https://www.pwc.com.br/pt/estudos/setores-atividade/financeiro/ 2024/pesquisa-fintech-de-deep-dive-2024.html. Acesso em: 16 nov. 2025.
[27] PICPAY. Aviso geral aos clientes com contas ativas no PicPay. Correio do Estado, [s.l.], [s.d.]. Disponível em: https://correiodoestado.com.br/mix/aviso-geral-aosclientes-com-contas-ativas-no-picpay/. Acesso em: 16 nov. 2025.
[28] UBER. From predictive to generative: how Michelangelo evolved. Uber Blog, 2024. Disponível em: https://www.uber.com/blog/from-predictive-to-generative-ai/. Acesso em: 16 nov. 2025.
[29] AMAZON WEB SERVICES. Caso de sucesso: inteligência artificial no iFood. AWS Case Studies, [s.l.], [s.d.]. Disponível em: https://aws.amazon.com/pt/solutions/ case-studies/ifoodai/. Acesso em: 16 nov. 2025.
[30] SAÚDE DIGITAL BRASIL. Saúde digital impulsiona a inovação e digitalização do setor de medicina diagnóstica. [S.l.: s.n.], [s.d.]. Disponível em: https:// saudedigitalbrasil.com.br/en_us/saude-digital-impulsiona-a-inovacao-e-digitalizacao-dosetor-de-medicina-diagnostica/. Acesso em: 16 nov. 2025.
[31] DOCK TECHNOLOGY. Machine learning na detecção de fraude. [S.l.: s.n.], [s.d.]. Disponível em: https://dock.tech/fluid/blog/fraud-prevention/machine-learning-nadeteccao-de-fraude/. Acesso em: 16 nov. 2025.
[32] DATARISK. MLOps: o combustível para startups acelerarem projetos de IA. Startups, [s.l.], 27 set. 2024. Disponível em: https://startups.com.br/coluna/mlops-ocombustivel-para-startups-acelerarem-projetos-de-ia/. Acesso em: 16 nov. 2025.
[33] MONITOR MERCANTIL. Alta do mercado de MLOps passa pela redução no prazo de criação de modelos preditivos. Monitor Mercantil, Rio de Janeiro, 9 out. 2024. Disponível em: https://monitormercantil.com.br/alta-do-mercado-de-mlops-passapela-reducao-no-prazo-de-criacao-de-modelos-preditivos/. Acesso em: 16 nov. 2025.
[34] VALUATES REPORTS. Cloud Machine Learning Operations (MLOps) market size to grow USD 3652.7 million by 2030 at a CAGR of 44.6%. PR Newswire, 9 set. 2024. Disponível em: https://www.prnewswire.com/news-releases/cloud-machinelearning-operations-mlops-market-size-to-grow-usd-3652-7-million-by-2030-at-a-cagrof-44-6–valuates-reports-302242292.html. Acesso em: 16 nov. 2025.
[35] DELOITTE. Desbloqueando o poder da inteligência artificial. Deloitte Insights, 5 set. 2023. Disponível em: https://www.deloitte.com/br/pt/our-thinking/mundo-corporativo/ deloitte-insights/desbloqueando-o-poder-da-inteligencia-artificial.html. Acesso em: 16 nov. 2025.
[36] PRADO, Kelvin Salton do. MLOps: democratizando o uso de Inteligência Artificial no Magalu. Medium – Luizalabs, [S.l.], 2020. Disponível em: https://medium.com/ luizalabs/mlops-democratizando-o-uso-de-intelig%C3%AAncia-artificial-nomagalu-8173a0a3ddbc. Acesso em: 16 nov. 2025.
[37] PREDIZE. Inteligência artificial no atendimento ao cliente da Shopee. [S.l.: s.n.], 2024. Disponível em: https://predize.com/blog/inteligencia-artificial-no-atendimento-aocliente-shopee/. Acesso em: 16 nov. 2025.
[38] MISHRA, Priyank. A realistic approach to Kaggle’s IEEE-CIS Fraud Detection Challenge. Medium, [S.l.], 2021. Disponível em: https://medium.com/ @mr.priyankmishra/a-realistic-approach-to-ieee-cis-fraud-detection-25faea54137. Acesso em: 16 nov. 2025.
[39] AMAZON WEB SERVICES. amazon-sagemaker-drift-detection. GitHub, [s.d.]. Disponível em: https://github.com/aws-samples/amazon-sagemaker-drift-detection. Acesso em: 16 nov. 2025.
[40] TECHAHEAD. Real-time fraud detection at scale: leveraging MLOps for financial services. [S.l.: s.n.], 2025. Disponível em: https://www.techaheadcorp.com/blog/mlopsfor-real-time-fraud-detection-for-financial-services/. Acesso em: 16 nov. 2025.
[41] IEEE COMPUTATIONAL INTELLIGENCE SOCIETY. IEEE-CIS Fraud Detection. Kaggle, 2019. Competição pública de detecção de fraudes em transações de cartão de crédito. Disponível em: https://www.kaggle.com/competitions/ieee-fraud-detection. Acesso em: 20 nov. 2025.
[42] KE, G. et al. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In: Advances in Neural Information Processing Systems 30 (NIPS 2017). [S. l.: s. n.], 2017. p. 3146–3154. Disponível em: https://papers.nips.cc/paper/6907-lightgbm-a-highlyefficient-gradient-boosting-decision-tree. Acesso em: 20 nov. 2025.
[43] PEDREGOSA, F. et al. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, v. 12, p. 2825–2830, 2011. Disponível em: https://jmlr.org/ papers/v12/pedregosa11a.html. Acesso em: 20 nov. 2025.
[44] ZAHARIA, M. et al. Accelerating the Machine Learning Lifecycle with MLflow. IEEE Data Engineering Bulletin, v. 41, n. 4, p. 39–45, dez. 2018. Disponível em: https:// people.eecs.berkeley.edu/~matei/papers/2018/ieee_mlflow.pdf. Acesso em: 20 nov. 2025.
[45] EVIDENTLY AI. Evidently: open-source ML monitoring and observability framework. [S. l.: s. n.], 2021. Projeto e documentação disponíveis em: https:// www.evidentlyai.com/. Acesso em: 20 nov. 2025.
[46] CARLOS COSTA. Repositório do projeto de TCC em MLOps para detecção de fraudes. GitHub, 2025. Disponível em: https://github.com/viniciiooss/tcc. Acesso em: 20 nov. 2025.
[47] GAMA, J. et al. A Survey on Concept Drift Adaptation. ACM Computing Surveys, v. 46, n. 4, p. 1–37, mar. 2014. DOI: 10.1145/2523813. Disponível em: https:// dl.acm.org/doi/10.1145/2523813. Acesso em: 20 nov. 2025.
[48] BRIER, G. W. Verification of Forecasts Expressed in Terms of Probability. Monthly Weather Review, v. 78, n. 1, p. 1–3, jan. 1950. Disponível em: https:// j o u r n a l s . a m e t s o c . o r g / v i e w / j o u r n a l s / m w r e /78/1/1520-0493_1950_078_0001_vofeit_2_0_co_2.xml. Acesso em: 20 nov. 2025.
[49] DAVIS, J.; GOADRICH, M. The Relationship Between Precision-Recall and ROC Curves. In: Proceedings of the 23rd International Conference on Machine Learning (ICML 2006). Pittsburgh, PA, USA: ACM Press, 2006. p. 233–240. Disponível em: https://minds.wisconsin.edu/handle/1793/60482. Acesso em: 20 nov. 2025.
[50] DAL POZZOLO, A. et al. Credit Card Fraud Detection: A Realistic Modeling and a Novel Learning Strategy. IEEE Transactions on Neural Networks and Learning Systems, v. 29, n. 8, p. 3784–3797, ago. 2018. DOI: 10.1109/TNNLS.2017.2736643. Disponível em: https://ieeexplore.ieee.org /document/8038008. Acesso em: 20 nov. 2025.
[51] BRECK, E. et al. The ML Test Score: A Rubric for ML Production Readiness and Technical Debt Reduction. In: 2017 IEEE International Conference on Big Data (Big Data). Boston, MA, USA: IEEE, 2017. p. 1123–1132. DOI: 10.1109/ BigData.2017.8258038. Disponível em: https://ieeexplore.ieee.org/document/8258038. Acesso em: 20 nov. 2025