REGISTRO DOI: 10.69849/revistaft/ar10202506081050
Aquiles Vinicius de Souza1
Catarina Lacerda de Assis1
Daniel de Souza Sanches1
Eduardo Gomes Silva1
Victor Inacio de Oliveira2
Resumo
Este trabalho apresenta um estudo sobre o uso de redes neurais na previsão do nível do Rio Caí, no estado brasileiro do Rio Grande do Sul. Neste estudo, foram avaliados algoritmos baseados nas redes neurais RealTime Recurrent Learning (RTRL), Multilayer Perceptron (MLP) e GRU (Gated Recurrent Units) para se comparar a eficácia de tais modelos em aplicações hidrológicas, especialmente na identificação de sinais que antecedem inundações. Os dados utilizados neste estudo abrangem um período de 46 anos e foram fornecidos pela Agência Nacional de Águas (ANA), sendo empregados no treinamento das redes neurais. Além disso, foram selecionados seis eventos hidrológicos de alerta registrados pela estação localizada no município de São Sebastião do Caí. Os resultados obtidos possibilitaram identificar o modelo com melhor desempenho e demonstrar sua importância na redução dos impactos das enchentes, especialmente quando utilizado em conjunto com outros sistemas de monitoramento já existentes. A precisão dos modelos foi testada em cenários reais, comparando as previsões dos algoritmos com dados históricos e informações coletadas em tempo real durante períodos de cheia, e tal processo permitiu avaliar a capacidade dos modelos em prever séries temporais hidrológicas de forma eficiente. Os resultados obtidos nesse estudo apontaram que a rede neural GRU mostrou maior eficácia na previsão do nível do rio, com 91% de acurácia, porém ambos os algoritmos se mostraram capazes de identificar os momentos críticos antes das enchentes, fornecendo visualmente tanto a estimativa do tempo até que o nível máximo do rio seja alcançado, quanto o período necessário para que o rio volte ao seu nível habitual.
Palavras-chave: Sistema de Alerta Hidrológico. Previsões de Séries Temporais. Aprendizado de Máquina.
Abstract
This academic work presents a study on the use of neural networks in predicting the water level of the Caí River, in the Brazilian state of Rio Grande do Sul. In this study, algorithms based on Real-Time Recurrent Learning (RTRL), Multilayer Perceptron (MLP) and GRU (Gated Recurrent Units) neural networks were evaluated to compare the effectiveness of such models in hydrological applications, especially in identifying signals that precede floods. The data used in this study covers a period of 46 years and was provided by the Agência Nacional de Águas (ANA), being used in the training of neural networks. In addition, six hydrological alert events recorded by the station located in the municipality of São Sebastião do Caí were selected. The results obtained made it possible to identify the model with the best performance and demonstrate its importance in reducing the impacts of floods, especially when used in conjunction with other existing monitoring systems. The accuracy of the models was tested in real scenarios, comparing the predictions of the algorithms with historical data and information collected in real time during flood periods, and this process allowed us to evaluate the ability of the models to predict hydrological time series efficiently. The results obtained in this study indicated that the GRU neural network showed greater effectiveness in predicting river levels, with 91% accuracy, but both algorithms were able to identify critical moments before floods, visually providing both an estimate of the time until the maximum river level is reached and the period necessary for the river to return to its usual level.
Keywords: Hydrological Alert System. Flood Forecasting. Machine Learning.
1. Introdução
As enchentes são fenômenos naturais que ocorrem com certa regularidade em diversas regiões do mundo. No entanto, no Brasil, esses eventos se apresentam como desafios não apenas ambientais, mas também sociais e econômicos, afetando de maneira particularmente intensa as populações mais vulneráveis. A insuficiência de infraestrutura adequada e a ineficiência dos sistemas de alerta agravam as consequências desses eventos, resultando em danos expressivos para a sociedade. O presente Trabalho de Conclusão de Curso aborda a utilização de redes neurais dos modelos MLP, RTRL e GRU para a realização de medições do Rio Caí, e a metodologia adotada baseia-se predominantemente em pesquisas bibliográficas e pesquisas documentais, visando a revisão e análise de estudos e publicações relevantes na área.
Com os avanços recentes, tem se tornado cada vez mais viável o uso da Inteligência Artificial (IA) para auxiliar em ações e tomadas de decisão que visam mitigar os impactos causados pelos desastres naturais. Estudos indicam que a aplicação de modelos de IA na análise de dados hidrológicos pode melhorar significativamente a precisão das previsões de enchentes (Nearing et al., 2024). No Brasil, onde a topografia diversa e as condições climáticas ampliam a complexidade das enchentes, a IA oferece um caminho promissor para o avanço dos esforços de prevenção de desastres. Pode-se citar como exemplo o projeto denominado E-Noé, desenvolvido no ICMC-USP, na cidade de São Carlos. O E-Noé é alimentado por imagens capturadas a cada cinco minutos nos pontos mais críticos dos rios, e essas fotos são enviadas para um servidor na nuvem, enquanto a superfície do rio é monitorada com a ajuda de uma rede neural profunda. O sistema utiliza visão computacional para interpretar as imagens das câmeras e emprega uma escala de cores como referência para medir o nível do rio a ser monitorado. Segundo o ICMC-USP, a intenção é criar um aplicativo para emitir alertas à população e, futuramente, expandir o serviço para outras cidades além de São Carlos. A tecnologia já está sendo usada pela prefeitura de Rio do Sul, no estado de Santa Catarina.
Nos últimos anos, o potencial de danos causados pelas enchentes tem aumentado significativamente, impulsionado por fatores como ocupação desordenada de áreas de preservação, desmatamento, descarte inadequado de resíduos, canalização de cursos d’água e aumento da intensidade das chuvas devido às mudanças climáticas. Em 2022, mais de 80 mil pessoas tiveram que abandonar suas residências em sete estados brasileiros devido às chuvas, resultando em prejuízos estimados em R$ 44 milhões. Em 2024, o estado do Rio Grande do Sul foi severamente afetado por alagamentos que atingiram 471 municípios, forçando 629,2 mil pessoas a deixarem suas casas e resultando em 169 mortes (G1, 2024). Diante desse cenário, a implementação de tecnologias como a IA surge como uma estratégia promissora para mitigar os impactos desses desastres naturais. Sistemas de IA podem auxiliar na identificação precoce de padrões que precedem as enchentes, oferecendo informações em tempo real e permitindo a adoção de medidas preventivas eficazes. Essa abordagem pode reduzir não só os prejuízos econômicos e sociais, mas também proteger vidas humanas em áreas suscetíveis a inundações.
Neste estudo, foram desenvolvidos e analisados algoritmos baseados nas redes neurais Real-Time Recurrent Learning (RTRL), Multilayer Perceptron (MLP) e Gated Recurrent Units (GRU), com o objetivo de realizar uma comparação quanto à eficácia desses modelos em aplicações hidrológicas, especialmente na identificação de parâmetros precursores de eventos de inundação.
A validação da precisão dos modelos foi realizada através de testes em cenários reais, utilizando comparações entre os resultados das previsões geradas pelos algoritmos, dados históricos e informações coletadas em tempo real durante períodos de cheia. Este procedimento permitiu avaliar a capacidade dos modelos em realizar previsões efetivas para séries temporais hidrológicas.
Além disso, foi garantida a capacidade dos algoritmos em identificar com precisão os momentos críticos que antecedem eventos de inundação, fornecendo visualmente tanto a estimativa do intervalo de tempo até que o nível máximo da cota seja alcançado quanto o período necessário para que o rio retorne ao seu nível normal.
O objetivo principal do projeto consiste no desenvolvimento, avaliação e comparação entre três modelos de redes neurais, a Rede Neural Artificial (RNA), representada pelo modelo Perceptron Multicamadas (MLP), e a Rede Neural Recorrente (RNN), representada pelo algoritmo RTRL (Real-Time Recurrent Learning) e GRU (Gated Recurrent Units). A partir dessa análise comparativa, busca-se identificar o modelo com melhor desempenho na previsão do nível do rio, considerando métricas como acurácia, erro absoluto médio e coeficiente de determinação (R²).
Adicionalmente, pretende-se construir uma solução de sistema de alerta capaz de incorporar o modelo com desempenho superior, o qual, neste estudo, foi o RTRL, de forma que seja possível prever o nível do rio com até três horas de antecedência e com uma precisão acima de 90%. Essa solução de sistema de alerta deverá ser acessível via requisições feitas por meio de um site, o qual exibirá gráficos que representem a tendência de crescimento do nível do rio, contribuindo para o monitoramento e a mitigação de riscos em áreas vulneráveis a inundações.
A importância de sistemas preditivos dessa natureza se torna ainda mais evidente diante da declaração do Secretário-Geral das Nações Unidas, António Guterres, ao afirmar que “alertas precoces e ação salvam vidas” (Guterres, 2022, p. 8), reforçando o papel estratégico da inteligência artificial em ações de prevenção e resposta a desastres naturais.
A meta de alcance de acurácia acima de 90% é respaldada por estudos recentes. Por exemplo, o modelo desenvolvido por Nelson (2023) para previsão do nível do rio alcançou 95% de acurácia, sendo considerado eficaz para aplicações práticas em gestão de riscos. De forma semelhante, Rahman et al. (2019) identificaram que modelos com MAE abaixo de 40 cm e NMSE inferiores a 0,26 são viáveis para previsão hidrológica. Já Hounsou (2019) destaca que modelos com R² superior a 0,9 são desejáveis para garantir confiabilidade estatística em sistemas críticos. Assim, estabelecer a meta de 90% de acurácia assegura nível de precisão compatível com aplicações reais de alerta preventivo.
2. Referencial teórico
2.1. Inundações no Brasil
Inundações são eventos naturais que ocorrem com cada vez mais frequência no Brasil e no mundo, potencializados pelas mudanças climáticas. Esses desastres causam um grande impacto econômico, social e ambiental, principalmente em regiões com sistemas de alerta ineficientes ou inexistentes. No Brasil, os desastres hidrológicos têm se intensificado e causado cada vez mais vítimas, devido à ocupação irregular das áreas de preservação, canalização dos cursos d’água, desmatamento, impermeabilização do solo e aumento da intensidade das chuvas por metro quadrado. Esses fatores evidenciam a necessidade de utilizar ferramentas eficientes para a previsão e gestão desses fenômenos (Chade, 2024).
Além do Brasil, outros países também sofrem com as inundações. Países como Indonésia, Afeganistão e Quênia têm sofrido com chuvas torrenciais, resultando em centenas de mortos e centenas de milhares de desabrigados. Especialistas afirmam que esses desastres são agravados pelas mudanças climáticas e ações humanas, como desmatamento e degradação dos ecossistemas. No continente africano, países como Burundi, Tanzânia e Somália foram severamente afetados, com quase um milhão de pessoas impactadas no ano de 2024. As enchentes causaram danos significativos a moradias, escolas e infraestruturas, além de perdas de colheitas e gado.
2.2. Escolha do rio Caí para o desenvolvimento do trabalho
A escolha do Rio Caí, localizado no estado do Rio Grande do Sul, como base para o desenvolvimento e treinamento dos modelos de redes neurais utilizados neste trabalho, se deu por diversos fatores técnicos e práticos que o tornam altamente apropriado para a tarefa de previsão de cheias. Um dos principais motivos é a disponibilidade de um conjunto de dados robusto e contínuo, com medições realizadas em intervalos regulares de 15 minutos ao longo de mais de 10 anos. Esses dados são provenientes da estação fluviométrica de São Sebastião do Caí, administrada pela Agência Nacional de Águas e Saneamento Básico (ANA). A série histórica contempla não apenas os níveis do rio, mas também variáveis hidrológicas relevantes como precipitação (chuva), vazão e temperatura, entre outras.
Dados levantados definiram que a bacia possuía uma área de 4.983 km² e uma população estimada em 656.577 habitantes em 2020. Neste estudo, focamos a solução para o trecho do rio Caí no município de São Sebastião do Caí, onde se encontrava a porção mais urbanizada e industrializada da bacia, gerando fortes pressões sobre o ambiente. O relevo tornava-se mais acidentado, apresentando encostas de grande declividade. Com 98% do total de 111,6 km² do seu território inserido na bacia, se propos a aplicação de técnicas em uma rede neural artificial pelo Multilayer Perceptron (MLP) e pelo algoritmo de aprendizado Real Time Recurrent Learning (RTRL) para prever o nível do rio em períodos de um e três dias.
Além disso, o Rio Caí é conhecido por apresentar episódios recorrentes de inundações ao longo das últimas décadas, o que reforça sua relevância prática como um caso real para aplicações de sistemas inteligentes de previsão e alerta. Esse contexto torna a região ideal para o desenvolvimento de soluções que visam mitigar os impactos das cheias, permitindo a aplicação direta dos resultados do projeto em benefício da população local.
De acordo com a literatura especializada, séries temporais extensas são essenciais para garantir a confiabilidade do processo de treinamento e validação de modelos baseados em redes neurais. Estudos como o de Nelson (2023) e Hounsou (2019) destacam que uma série histórica de, no mínimo, 10 anos é recomendada para assegurar a generalização dos modelos e capturar a variabilidade sazonal e extrema dos eventos hidrológicos. Dessa forma, o uso do Rio Caí não apenas fornece uma base rica e variada de dados, mas também atende aos critérios metodológicos estabelecidos para estudos preditivos de longo prazo com aprendizado supervisionado.
Figura 1 – Mapa da bacia hidrográfica do Rio Caí
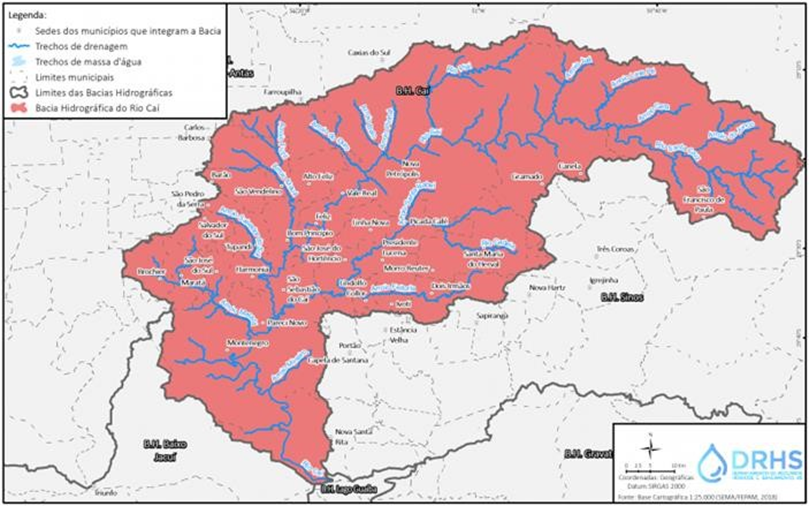
A densidade de drenagem da bacia hidrográfica do Rio Caí, localizada em São Sebastião do Caí, é de 1,6 km/km², o que indica uma rede de drenagem bem desenvolvida. Esse índice é característico de bacias com boa capacidade de escoamento, facilitando o transporte das águas para os corpos d’água principais. Isso demonstra que a bacia do Rio Caí possui uma drenagem eficiente, com áreas de maior conectividade entre os diferentes tributários.
A altimetria da bacia do Rio Caí varia consideravelmente, com altitudes que vão de 2 metros em seu ponto mais baixo, na região de confluência com o Rio Jacuí, até 960 metros no município de Alto Feliz. O relevo acidentado dessa área propicia o escoamento rápido das águas, o que pode aumentar os riscos de inundações durante eventos de chuvas fortes, especialmente em regiões de grande declividade, assim a combinação de áreas planas e acidentadas na bacia pode gerar momentos de acúmulo de água nas zonas de baixa altitude, intensificando o risco de inundações durante períodos de precipitação.
Em relação à precipitação, a média anual na bacia do Rio Caí é de aproximadamente 1.850 mm, com variações que vão de 1.200 mm a 2.400 mm. Isso reflete a grande variabilidade climática da região, com um índice mensal médio de 154,2 mm. A precipitação mensal pode variar muito, com valores mínimos de 0,8 mm e máximos de 950 mm, o que torna a dinâmica climática da bacia bastante imprevisível. A maior parte das chuvas ocorre durante a primavera e o verão, enquanto o outono e o inverno tendem a ser mais secos, seguindo os padrões climáticos típicos da região sul do Brasil.
A vazão média observada no exultório da bacia do Rio Caí é de cerca de 330,0 m³/s. Embora o rio normalmente apresente vazões abaixo da média, há momentos de picos que podem superar os 2.500 m³/s. O tempo de resposta da bacia é geralmente inferior a 24 horas, o que significa que a resposta hidrológica é rápida após eventos de precipitação intensa. Para a cidade de São Sebastião do Caí, é possível fazer previsões confiáveis para horizontes de até 8 horas, desde que se considerem os níveis de água nas estações montantes.
2.3. Utilização de IA no combate à enchente
Com os avanços recentes em tecnologia, a Inteligência Artificial (IA) tem se tornado uma ferramenta essencial no combate a enchentes, oferecendo precisão nas previsões e eficiência no monitoramento dos níveis de corpos d’água. Modelos baseados em redes neurais, como o Multilayer Perceptron (MLP), o Real-Time Recurrent Learning (RTRL) e o Long Short-Term Memory (LSTM), têm demonstrado capacidade significativa em prever eventos hidrológicos extremos, permitindo uma melhor preparação e gestão dos riscos associados às enchentes. Estudos como o realizado por Kratzert et al. (2019) destacam que a utilização adequada de variáveis climáticas e técnicas de normalização dos dados podem melhorar significativamente a acurácia desses modelos. Silva, Castro e Vieira (2018) utilizaram redes neurais com dados históricos de 37 anos na bacia do rio Xingu, na região de Altamira, Pará, mostrando resultados robustos em previsões hidrológicas. Zanial et al. (2022) aplicaram técnicas semelhantes em uma estação hidroelétrica na Malásia, utilizando dados de 46 anos de medições, obtendo resultados igualmente satisfatórios. Finck e Santos (2020) demonstraram eficácia ao utilizar apenas 4 anos de dados históricos para prever níveis na bacia do rio Taquari-Antas, no Rio Grande do Sul. O projeto E-Noé, desenvolvido pelo Instituto de Ciências Matemáticas e de Computação (ICMC) da Universidade de São Paulo (USP), em São Carlos, também exemplifica a aplicação prática da IA. Este sistema utiliza visão computacional através de redes neurais profundas para analisar imagens capturadas regularmente em pontos críticos de rios, oferecendo alertas precisos e rápidos. Essa abordagem integrada demonstra o potencial transformador da IA na redução dos impactos socioeconômicos causados por enchentes.
2.4. Rede neural artificial
Segundo Haykin (2008), as redes neurais artificiais (RNAs) são modelos de computação e de processamento de informação projetados para imitar o funcionamento do cérebro humano em suas funções. Semelhante a como um humano adquiri conhecimento com base em aprendizado coletados ao longo do tempo, a rede neural cria um sistema adaptativo que pode ser treinada para analisar dados, e usar o conhecimento adquirido em uma determinada situação, para chegar a um resultado.
O neurônio biológico é uma célula especializada em processar e transmitir sinais elétricos através de ações na sinapse, local onde a comunicação entre dois neurônios ocorre com diferentes potenciais de ação, que pode resultar em uma mudança no potencial elétrico da célula e, se for suficientemente forte, iniciar um novo potencial de ação (Bear et al., 2016). Para os neurônios artificias, ao serem conectados em camadas utilizam um processo de aprendizagem que ocorre por meio da modificação de parâmetros da rede, formam uma cadeia capaz de aprender e realizar tarefas complexas a partir de dados de entrada (Haykin, 2008).
Figura 2 – Representação de neurônio artificial
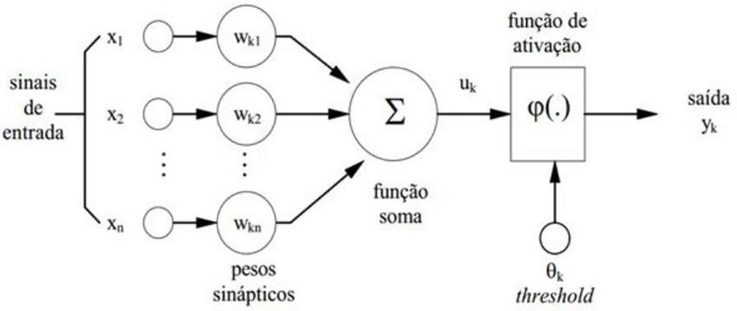
O modelo de neurônio apresentado por Haykin em 2001 reproduz o comportamento de um neurônio artificial, sendo um dos blocos de construção essenciais para a criação de sistemas de aprendizado de máquina. Nesse modelo, o processamento de cada unidade pode ser calculado (1) para uma ativação linear. Nessa equação O neurônio recebe múltiplas entradas x1, x2, …, xn que são os dados que o sistema precisa processar. Cada entrada xi associada a um peso w que controla a importância de cada entrada na decisão final do neurônio. O viés b introduzido para ajustar o valor de saída do neurônio, permitindo flexibilidade adicional no modelo (Haykin, 2001).
Uma função de ativação é um componente principal do neurônio artificial pois ela introduz não linearidade no modelo, permitindo que a rede neural aprenda relações complexas entre os dados, que se formam com a interligação dos neurônios por camadas, permitindo que elas representem funções complexas que controlam o fluxo de informação entre os neurônios. Ela faz isso limitando a saída do neurônio a um intervalo de valor finito de acordo com o seu tipo, cada neurônio realiza operações de soma ponderada das entradas e, posteriormente, aplica uma função de ativação para produzir a saída. (Goodfellow et. al., 2016).
Dentre as inúmeras funções de ativação existentes, apenas as apresentadas na tabela 1 serão utilizados para construção e treinamento dos modelos.
Tabela 1 – Funções de Ativação


2.5. Algoritmo MLP
O Perceptron Multicamadas (MLP) é um tipo de rede neural artificial que consiste em múltiplas camadas de neurônios. É uma das arquiteturas fundamentais em inteligência artificial e aprendizado de máquina, conhecida por sua capacidade de resolver problemas complexos. É composto por três tipos de camadas:
- Camada de entrada: Recebe os dados de entrada.
- Camadas Ocultas: Uma ou mais camadas que processam os dados através de neurônios interconectados. Essas camadas utilizam funções de ativação não lineares para permitir a aprendizagem de padrões.
- Camada de saída: Produz a saída final do modelo.
Figura 3 – Modelo de RNA MLP
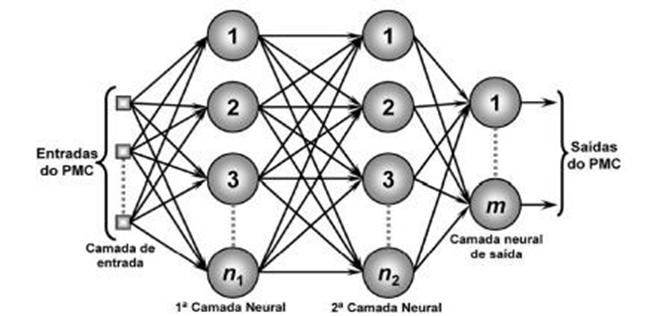
Já sobre o funcionamento, na propagação direta os dados de entrada são alimentados na camada de entrada da rede neural. Cada neurônio na camada de entrada recebe um valor de entrada e o transmite para os neurônios na primeira camada oculta. Os neurônios nas camadas ocultas processam esses valores de entrada aplicando uma função de ativação não linear, como a função sigmoid ou ReLU (Rectified Linear Unit). Essa função de ativação transforma a soma ponderada das entradas em uma saída que é passada para a próxima camada. O processo continua através de todas as camadas ocultas até chegar à camada de saída. Na camada de saída, os neurônios produzem a saída final da rede, que pode ser uma classificação ou uma regressão.
Na retropropagação, ocorre o processo de ajuste dos pesos dos neurônios para minimizar o erro entre a saída prevista pela rede e a saída real desejada. Após a propagação direta, o erro é calculado comparando a saída da rede com a saída esperada. Esse erro é então propagado de volta através da rede, da camada de saída para a camada de entrada. Durante a retropropagação, os pesos dos neurônios são ajustados usando o algoritmo de descida do gradiente. Esse algoritmo calcula o gradiente do erro em relação a cada peso e ajusta os pesos na direção oposta ao gradiente, reduzindo assim o erro. O processo de ajuste dos pesos é repetido várias vezes durante o treinamento, até que o erro seja minimizado e a rede aprenda a mapear corretamente as entradas para as saídas. Segundo Sanabio (2022), pode-se utilizar a regra Delta para o ajuste de pesos. Nesta abordagem, o novo peso é obtido subtraindo-se a derivada da função de erro multiplicada pela taxa de aprendizagem do peso anterior. A taxa de aprendizagem geralmente varia entre 0 e 1, e sua seleção depende dos dados utilizados e das exigências específicas de cada processo de aprendizagem.
2.6. Rede Neural Recorrente
As Redes Neurais Recorrentes constituem a principal arquitetura de deep learning empregada quando o comportamento temporal dos dados é relevante. Em sentido amplo, uma RNN pode ser vista como um sistema dinâmico não linear cujos parâmetros são ajustados pelo método de Back-Propagation Through Time (BPTT). Nesse esquema, o estado oculto ht é atualizado iterativamente a partir da entrada atual xt e do estado anterior h t-1 , permitindo à rede memorizar dependências que se estendem por dezenas ou até centenas de passos de tempo (GOODFELLOW; BENGIO; COURVILLE, 2016). Essa característica a torna particularmente valiosa na hidrologia, uma vez que os níveis de rios refletem processos acumulativos — precipitação, infiltração e escoamento superficial — regidos por defasagens e retroalimentações naturais.
Apesar dessa flexibilidade, o treinamento de uma RNN “vanilla” enfrenta duas dificuldades clássicas: (i) desvanecimento de gradiente, que prejudica a aprendizagem de padrões distantes no tempo, e (ii) explosão de gradiente, que desestabiliza a descida de gradiente (BENGIO; SIMARD; FRASCONI, 1994). Estratégias como limitação do gradiente (gradient clipping), normalização por lote e uso de funções de ativação como ReLU ou Leaky-ReLU atenuam esses efeitos (PASCANU; MIKOLOV; BENGIO, 2013). Além disso, variantes baseadas em portas de controle — notadamente a Long Short-Term Memory (LSTM) e a Gated Recurrent Unit (GRU) — inserem filtros adaptativos que decidem, em cada instante, quais informações serão preservadas ou descartadas (HOCHREITER; SCHMIDHUBER, 1997; CHO et al., 2014). A LSTM emprega três portas (entrada, esquecimento e saída), ao passo que a GRU condensa o mecanismo em apenas duas (reset e update), reduzindo o número de parâmetros e, consequentemente, o custo de treinamento.
Para aplicações hidrológicas, a pré-processamento dos dados impõe desafios adicionais. Observações de chuva e vazão costumam apresentar lacunas e ruído de instrumentação; logo, são comuns rotinas de smoothing, imputação baseada em RNNs (HOUNSOU, 2019) e normalização min-max para equalizar escalas (milímetros de precipitação versus metros cúbicos por segundo). A definição do tamanho da janela (look-back) também é decisiva: janelas muito curtas ignoram atrasos hidrológicos, enquanto janelas longas podem induzir redundância e tornar o treinamento computacionalmente inviável. Estudos recentes sugerem — para bacias de resposta rápida — janelas de 3 a 7 dias, complementadas por features derivadas, como desfasagens de precipitação acumulada (ALVES; PEREIRA; SILVA, 2024).
Na fase de ajuste, técnicas como validação cruzada bloqueada (block cross-validation) garantem que as partições de treinamento e teste respeitem a ordem temporal, evitando fuga de informação. Ademais, early stopping é aplicado para prevenir sobreajuste em séries relativamente curtas, situação frequente em hidrologia onde observações confiáveis raramente ultrapassam quarenta anos. Critérios de erro como RMSE (erro quadrático médio), MAE (erro absoluto médio) e R2 são os mais empregados, pois se relacionam diretamente a limites operacionais usados em alertas de inundação (ZHANG et al., 2024).
Resultados empíricos reforçam a relevância das RNNs no contexto fluvial. Hounsou (2019) demonstrou que uma RNN simples, treinada para reconstruir sinais estruturais de pontes, reduziu o erro de imputação em 35 % frente à interpolação por média móvel. Na previsão do nível do Rio Paraíba do Sul, Nelson (2023) reportou R2=0,93 ao empregar entradas combinadas de precipitação, vazão a montante e evapotranspiração, superando regressões lineares em mais de 20 p.p. de explicabilidade. Em aplicações de bordo (edge computing), Wei et al. (2022) embarcaram uma GRU em sensores ultrassônicos alimentados por painel solar; o algoritmo emite SMS de alerta com antecedência média de 180 min e taxa de falsospositivos inferior a 5 %, atendendo às exigências da Defesa Civil.
À luz desses avanços, o presente TCC inclui a RNN — ao lado de MLP e RTRL — na comparação de modelos para previsão de nível de rio. Sua capacidade de capturar variáveis latentes, sua execução em tempo real quando integrada a dispositivos IoT e sua robustez a dados ruidosos satisfazem os requisitos de um sistema de alerta precoce de enchentes. O estudo ainda explorará a sensibilidade a hiperparâmetros, a influência do horizonte de previsão e o custo computacional, de modo a fundamentar a escolha do modelo mais apropriado para implantação operacional.
Figura 4 – Exemplificação da RNN
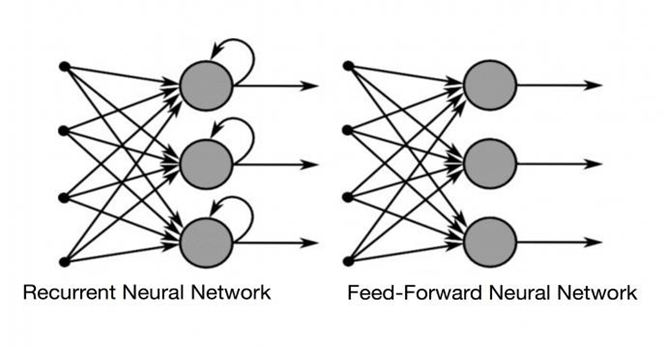
2.7. Algoritmos GRU
As Gated Recurrent Units (GRUs) são uma evolução das redes neurais recorrentes clássicas, criadas para contornar o problema da dissipação e explosão de gradiente que afeta o treinamento de RNNs profundas. Desde os trabalhos pioneiros de Rumelhart, Hinton e Williams (1986), sabemos que, ao propagar o erro ao longo de muitas etapas de tempo, os gradientes podem se anular ou crescer exponencialmente, prejudicando a aprendizagem de dependências de longo alcance. Hochreiter e Schmidhuber (1997) introduziram as LSTMs para resolver esse impasse por meio de células de memória e três portões, mas o custo computacional e a quantidade de parâmetros permaneciam elevados.
Em 2014, Cho et al. propuseram as GRUs como uma arquitetura mais enxuta: elas eliminam o estado de célula separado e concentram todo o processamento no estado oculto, controlado por apenas dois portões–reset e update–em vez dos três das LSTMs. Essa simplificação reduz quase à metade o número de matrizes de peso, mantendo, em geral, desempenho comparável ao das LSTMs em tarefas de modelagem de sequências
Tabela 2 – Equações GRU
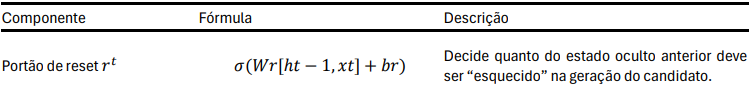

Graças a esses dois portões, as GRUs conseguem reter informações relevantes por longos períodos e descartar ruídos de forma adaptativa, oferecendo uma excelente relação entre capacidade de modelagem e eficiência computacional. Em muitos cenários–incluindo reconhecimento de fala, tradução automática e previsão hidrológica–as GRUs demonstram convergência mais rápida e muitas vezes igualam ou superam as LSTMs com menor custo de memória e tempo de treinamento
2.8. Algoritmo RTRL
O Algoritmo Real-Time Recurrent Learning (RTRL)é um algoritmo de treinamento rede neural recorrentes (RNN), supervisionado e em tempo real, ajustando continuamento os pesos dos neurônios utilizando os dados conforme eles chegam (Williams; Zipser, 1989). Essa técnica de aprendizado se diferencia pela sua capacidade de tratar séries temporais não estacionarias e não lineares, características de fenômenos naturais como inundações e verificação de dinâmica hidrológica. Sua arquitetura recorrente permite o armazenamento dos estados anteriores sejam continuamente atualizados, permitindo um maior desempenho para a captura de dependência temporais complexas, especialmente em contexto dinâmico que exigem aprendizagem contínua. (Haykin, 2008).
Esse modelo permite o ajuste de pesos acontece simultaneamente com a apresentação dos dados, utilizando o padrão backpropagation para propagar os erros através do tempo (da camada de saída até a camada de entrada), permitindo que o peso dos neurônios seja ajustado gradualmente, minimizando o erro do valor previsto para o erro real (Goodfellow et al., 2016), para isso são calculados e atualizados os gradientes relativos aos pesos da rede, utilizando a regra geral de Williams e Zipser (1989).
2.8.1. Algoritmo RTRL no combate à enchente
A predição e modelagem estatística de eventos hidrológicos tem alta complexidade devido as variações inerentes aos fenômenos naturais, que incluem relações não lineares e comportamento dinâmico das variáveis (Kratzert et al., 2019).
Aplicações específicas do algoritmo RTRL demonstraram que a combinação de redes neurais recorrentes, como RTRL e LSTM, com dados hidrológicos, aumentou significativamente a precisão das previsões em bacias hidrográficas não monitoradas. Os modelos se mostraram capazes de identificar padrões complexos ao longo de diferentes pontos da bacia, especialmente na estimativa da vazão e do nível dos rios (Kratzert et al., 2019). Em contraste, ferramentas convencionais demandam longos períodos de treinamento e paradas frequentes para recalibração, pois não possuem a capacidade de aprendizado contínuo a partir dos resultados apresentados, o que compromete a eficiência das previsões (Shahid; Rafiq, 2020).
2.9. Tempo de coleta e tratamento de dados
Nesse estudo utilizamos para treinamento e testes dos modelos de rede neural no intervalo de 01/2010 e 02/2025, a definição desse período foi inicialmente planejada com um período de 40 anos, baseado em projetos com o mesmo propósito de predição do nível de corpos d’agua, como na bacia do rio Xingu – Altamira – PA (Silva; Castro; Vieira, 2018) que utilizaram o período de 37 anos, e também dentro de 46 anos de medições utilizadas para o treinamento do modelo feito em 2022 na Malásia em uma estação hidroelétrica (Zanial et al., 2022). Embora outros estudos também obtiveram resultados positivos com um tempo para estudos menor como na Bacia do Rio Taquari, Antas, Rio Grande do Sul, com o período de treinamento de 4 anos (Fink; Santos, 2020).
Segundo Kratzert et al. (2019), foi demonstrado que o uso adequado de features climáticas e a normalização adequada dos dados melhoraram o desempenho de redes neurais na previsão de vazão de rios, indicando assim que a etapa pode melhorar significativamente a acurácia da previsão.
Estudos recentes têm demonstrado que mesmo períodos menores de coleta de dados podem produzir resultados satisfatórios quando aplicados a modelos mais complexos, como as redes neurais recorrentes do tipo Long Short-Term Memory (LSTM). Por exemplo, Vizi et al. (2023) utilizaram dados históricos diários coletados ao longo de aproximadamente 70 anos para prever o nível do rio Tisza, obtendo resultados superiores em precisão em relação ao tradicional modelo DLCM, especialmente para eventos extremos de cheia e seca. Isso ressalta que a eficiência na previsão está atrelada não apenas à extensão temporal dos dados utilizados no treinamento, mas também à qualidade do modelo e às características hidrológicas específicas da área estudada (Vizi et al., 2023).
2.10. Correlação entre vazão e precipitação para modelo de rede neural
Um dos principais desafios no trabalho e para o modelo é a previsão do nível dos rios a partir de variáveis meteorológicas, sendo a precipitação um dos fatores mais influentes nesse processo, logo a correlação entre chuva e vazão é um dos pontos centrais na modelagem hidrológica, que permite a construção de modelos preditivos que auxiliam na tomada de decisões.
A relação entre precipitação e vazão de um rio é complexa e depende de diversos fatores, como o tipo de solo, cobertura vegetal, topografia e características do rio. Estudos mostram que a quantidade de chuva em uma região pode influenciar diretamente a vazão do rio, mas essa resposta não é imediata e varia conforme o tempo de concentração. Modelos matemáticos e técnicas de aprendizado de máquina são amplamente empregados para identificar padrões entre essas variáveis e gerar previsões confiáveis.
De acordo com Ribeiro (2012), a análise da correlação entre chuva e vazão é essencial para o desenvolvimento de modelos hidrológicos preditivos, pois permite identificar a defasagem temporal entre a ocorrência da chuva e seu impacto no escoamento dos rios. A partir dessa relação, pode-se construir modelos que utilizam dados históricos para prever o comportamento futuro da vazão, possibilitando uma melhor gestão dos recursos hídricos.
Por exemplo, uma pesquisa realizada na bacia hidrográfica do rio Piquiri, no Paraná, analisou a variabilidade e a correlação entre a precipitação pluviométrica e a vazão fluvial no período de 1976 a 2010. Os resultados indicaram que há uma associação significativa entre o aumento da precipitação e o aumento da vazão, com uma defasagem temporal que sugere um tempo de resposta da bacia às chuvas ocorridas (Maciel, 2017). Outro estudo focou na bacia hidrográfica do rio do Rola, no Acre, avaliando dados de 1998 a 2008. Os pesquisadores observaram uma correlação direta entre os volumes de precipitação e as vazões registradas, destacando a influência imediata das chuvas no aumento do fluxo fluvial (Macedo, 2013).
3 Metodologia
3.2 Exploração de dados
Os dados obtidos neste estudo corresponderam ao período de 1978 a 2024, provenientes da Agência Nacional de Águas – ANA, responsável pela regulação e gestão dos recursos hídricos no país, seguindo diretrizes legais e baseadas em estudos técnicos para operar e manter os dados de níveis de rio, vazões, precipitações, qualidade da água, dentre outros indicadores ambientais. Para tal, foram utilizados para o treinamento das redes dados de chuva, vazão e de nível do rio das estações telemétricas apresentadas por contribuírem à variação de nível.
Tabela 3 – Amostra de dados obtidos para estudo
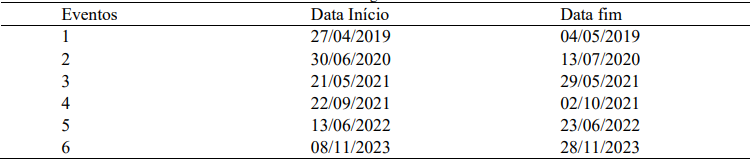
Os dados pluviométricos e de nível do rio possuem frequência de 15 min. Foram selecionados 6 eventos hidrológicos de alerta registrados pela estação instalada no município de Rio Grande do Sul
(Tabela 1). O evento 6 apresentou maior completude e consistência de dados e foi, além de ser o maior nível dentre os eventos, escolhido como o principal período de teste. Os demais eventos foram utilizados para outros testes.
Tabela 4 – Eventos hidrológicos de alerta selecionados.
3.3 Cálculo do coeficiente de correlação
Para quantificar a relação linear entre as variáveis hidrológicas, empregou-se o coeficiente de correlação de Pearson. Este coeficiente estatístico mensura a força e a direção de uma relação linear entre dois conjuntos de dados contínuos. A significância estatística das correlações foi avaliada através do valor p (p-value) associado ao teste de hipóteses, onde a hipótese nula assume a ausência de correlação na população. A escolha do coeficiente de correlação de Pearson se justifica pela natureza contínua das variáveis analisadas (nível do rio, vazão e chuva), e pelo objetivo de quantificar a relação linear entre pares dessas variáveis. O método de Pearson é amplamente utilizado em estudos hidrológicos e estatísticos para identificar associações lineares, sendo uma ferramenta fundamental para a análise exploratória de dados e para a formulação de hipóteses sobre as interdependências entre diferentes componentes de um sistema (Wilks, 2011). A análise foi conduzida sobre um total de 216.312 casos registrados desde o ano de 2018.
A matriz de correlação de Pearson obtida a partir da análise dos dados é apresentada na Tabela 4.
Tabela 5 – Matriz de Correlação de Pearson entre Nível do Rio, Vazão e Chuva.


Nota: Os valores entre parênteses representam o valor p (p-value) associado à correlação.
Os resultados revelam uma correlação positiva muito forte (r = 0.958) e estatisticamente significativa (p < 0.001) entre o nível do rio e a vazão. Essa forte associação linear indica que variações na vazão do rio estão intimamente relacionadas a variações em seu nível, um fenômeno esperado na dinâmica fluvial (Leopold & Maddock, 1953).
Em contraste, as correlações entre a chuva (mm) e o nível do rio (r = 0.029, p < 0.001), e entre a chuva (mm) e a vazão (r = 0.031, p < 0.001), são positivas, porém de magnitude muito fraca. Apesar da significância estatística dessas correlações, atribuível ao grande tamanho da amostra (conforme indicado pelos altos graus de liberdade fornecidos na análise original), a pequena magnitude dos coeficientes sugere que a precipitação pluviométrica medida no mesmo período tem uma influência linear direta limitada sobre o nível e a vazão do rio.
Essa aparente desconexão imediata entre a chuva e a resposta do rio pode ser explicada por diversos fatores inerentes aos processos hidrológicos. O tempo de resposta de uma bacia hidrográfica à precipitação pode variar significativamente, com o escoamento superficial e a contribuição das águas subterrâneas influenciando o nível e a vazão do rio em escalas temporais distintas (Dingman, 2015). Além disso, a intensidade, a duração e a distribuição espacial da chuva, bem como as características da bacia (permeabilidade do solo, declividade, cobertura vegetal), desempenham um papel crucial na forma como a precipitação se traduz em escoamento e, subsequentemente, em alterações no nível e na vazão do rio.
A fraca correlação linear direta observada não implica ausência de relação causal, mas sim que a relação pode ser não linear ou defasada no tempo. Análises futuras poderiam explorar a correlação cruzada para investigar a influência da chuva em diferentes defasagens temporais sobre o nível e a vazão do rio, bem como modelos de regressão multivariada para considerar o efeito combinado de múltiplas variáveis e possíveis interações não lineares.
3.3 Tratamento de dados
Para que o modelo de rede neural alcançasse bons resultados na previsão do nível do rio, realizamos o processo de pré-processamento dos dados, etapa de preparação e limpeza dos dados brutos para garantir sua qualidade antes da modelagem, visualização ou análise, garantindo assim que o modelo aprendesse corretamente a partir de entradas mais bem organizadas.
Inicialmente, coletamos os dados de precipitação, nível da água e vazão do rio, medidos pela Agência Nacional de Águas, cobrindo o período de janeiro de 2010 a fevereiro de 2025. Em seguida, conduzimos um estudo detalhado para avaliar a qualidade dos dados, identificando valores nulos e discrepantes, lacunas e eventuais erros de medição. Como os dados foram registrados em intervalos de 15 minutos, mantivemos essa periodicidade para o modelo.
3.4 Pré-processamento
Para prever o nível futuro das águas do rio os dados de precipitação são um dos parâmetros meteorológicos mais relevantes a serem utilizados neste estudo. A precipitação é um dos elementos mais difíceis do ciclo hidrológico de prever (Bates et al. 2008). Na maioria dos locais, as estações pluviométricas terrestres estão disponíveis como ferramentas de estimativa de precipitação. No entanto, desafios como a falta de cobertura em algumas áreas e a presença de um número limitado de estações de medição podem impactar a precisão dos dados coletados.
Logo, os dados de precipitação e nível do rio neste estudo passaram por uma etapa de préprocessamento antes de serem aplicados no modelo de previsão para corrigir possíveis falhas e inconsistências.
Neste estudo, foi utilizada a normalização de dados para transformar todas as variáveis dentro de um intervalo específico de 0 a 1. A normalização evita problemas numéricos durante o treinamento da rede, pois funções de ativação como a ReLU podem ser sensíveis a valores extremos. A Equação 2 apresenta a fórmula de normalização utilizada por meio da biblioteca scikit-learn disponibilizada em Python:
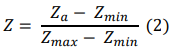
onde Z é o valor normalizado; Zmin e Zmax são os valores mínimo e máximo de Za, respectivamente. Os valores de Za correspondem aos dados de entrada do modelo, ou seja, precipitação (mm) e nível do Rio Caí (cm). Após a previsão, os resultados são retransformados para seus valores reais utilizando a Equação 3:
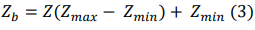
onde Zb representa a saída do modelo, ou seja, o nível previsto do Rio Caí em centímetros.
O uso do MLP combinado com o algoritmo RTRL permite que o modelo se ajuste continuamente aos novos dados, tornando-se mais preciso com o tempo.
3.5 Desenvolvimento e validação
Após a etapa de tratamento e pré-processamento dos dados, o treinamento foi realizado e o desempenho dos modelos foi avaliado. Caso os resultados não tenham sido satisfatórios, os modelos foram ajustados e submetidos a novos treinamentos em um processo iterativo de refinamento, os testes foram realizados inicialmente com a meta de previsão de um período de vinte e quatro (24) e setenta e duas (72) horas para o futuro.
A Rede Neural Artificial (RNA) tem sido amplamente utilizada para demonstrar dados de séries temporais não lineares e não estacionários na hidrologia. Foi constatado que ela produz bons resultados quando comparada aos modelos estatísticos. Os modelos RNA foram considerados um modelo de previsão influente para a relação entre parâmetros de chuva e nível do rio.
Neste estudo, é esperado que uma prática baseada em RNA seja utilizada para prever o nível do rio Caí. O objetivo de prever o nível do rio é antecipar a disponibilidade de água, permitindo melhor gestão dos recursos hídricos e auxiliando no planejamento de ações preventivas, como a construção de infraestruturas de contenção e o planejamento de atividades de turismo ou agricultura.
Os dados de entrada usados no modelo RNA proposto incluem dados históricos de precipitação, vazão e nível do rio, com o objetivo de prever o nível futuro do rio em São Sebastião do Cai. Neste estudo, o Algoritmo de Retropropagação foi utilizado para desenvolver o modelo de previsão do nível do rio. A Rede Neural de Retropropagação (BPNN) é a técnica mais popular nos algoritmos de aprendizado do Perceptron Multicamadas (MLP). E o desenvolvimento desse modelo envolveu três (3) processos: o fluxo de dados, as etapas no processo de desenvolvimento do modelo RNA e a previsão do nível do rio.
Primeiramente, os valores de entrada foram levados à rede em direção aos nós na camada oculta e aumentados com os pesos dos nós de conexão (os pesos iniciais e os níveis de limiar foram configurados aleatoriamente) para calcular os valores dos nós ocultos pela função de ativação. Neste estudo, foi utilizada a função tangente hiperbólica para realizar e ajustar a tarefa de aprendizado, acelerando o processo de aprendizado. O uso da função tangente hiperbólica proporciona maior precisão de reconhecimento e resultados em comparação com outras funções.
A função de ativação da tangente hiperbólica é dada pela equação (4):
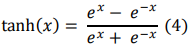
Essa função transforma as entradas de um neurônio para valores entre -1 e 1, ajudando a modelar relações não-lineares. Sua principal vantagem é ser centrada em torno de zero, o que facilita a convergência durante o treinamento, pois as ativações são equilibradas.
Para a construção do modelo dentre os parâmetros, detalhamos os seguintes:
i. Seleção de entrada
Este parâmetro é crucial, considerando que pode examinar a correlação entre os potenciais dados de entrada e saída do modelo. Neste estudo, dois (2) parâmetros de entrada utilizados são os dados históricos de precipitação e nível de rio para prever o futuro nível de rio na usina hidrelétrica. Esse método é importante para evitar a entrada redundante que pode levar ao sobre ajuste e treinamento excessivo.
ii. Camadas ocultas e nós
Foram testadas diferentes configurações para a camada oculta, com 1 ou 2 camadas e diferentes números de nós em cada camada, utilizando a técnica de tentativa e erro.
iii. Taxa de aprendizado (β) e momento (α)
A taxa de aprendizado e o momento são ajustados para acelerar o treinamento e garantir a redução do erro. Neste estudo, foi usada uma taxa de aprendizado β de 0,3 e um momento α de 0,3.
iv. Função de ativação
A função sigmoide tangente hiperbólica foi aplicada na camada oculta devido à sua capacidade de combinar comportamentos lineares, curvados e constantes, o que a torna eficaz para o problema em questão.
v. Partição de dados
A divisão dos dados em conjuntos de treinamento, validação e teste é crucial para avaliar o desempenho do modelo. Neste estudo, 70% dos dados foram usados para treinamento, e os 30% restantes foram divididos igualmente para validação e teste.
O modelo de aprendizado RTRL (Real-Time Recurrent Learning) tem se mostrado uma aposta promissora na previsão de dados temporais não lineares e não estacionários, como ocorre em séries temporais de níveis de rios. Diferente de redes neurais convencionais, o RTRL é projetado para aprender de forma eficiente em tempo real, atualizando seus parâmetros à medida que novos dados se tornam disponíveis. Este modelo tem mostrado resultados promissores quando comparado a métodos tradicionais de previsão em hidrologia.
A principal vantagem do RTRL sobre outras abordagens é sua habilidade de adaptar os parâmetros da rede continuamente enquanto novos dados são coletados, tornando-o extremamente útil para situações em que as condições de previsão mudam ao longo do tempo. Esse modelo pode responder rapidamente às variações nos dados de entrada, como os níveis de precipitação e os níveis do próprio rio.
Neste estudo, o modelo RTRL foi treinado para prever o nível futuro do rio a partir de dados históricos de precipitação e nível do rio. Como o RTRL é uma forma de rede neural recorrente, ele utiliza estados anteriores do sistema como contexto para fazer previsões mais precisas, aproveitando a dependência temporal dos dados. O desenvolvimento do modelo RTRL para previsão do nível do rio em São Sebastião do Cai inclui os seguintes elementos principais:
i. Arquitetura de Rede Recorrente
Ao contrário do MLP, que processa os dados em uma estrutura feedforward, o RTRL utiliza uma rede recorrente, ou seja, os dados da camada de saída são recirculados para as camadas anteriores, permitindo que a rede tenha “memória” de estados anteriores. Essa memória é crucial para modelar o comportamento dinâmico do nível do rio, que depende não apenas da precipitação atual, mas também das condições passadas.
ii. Dados de Entrada
Os dados utilizados no modelo incluem séries temporais de precipitação anual e o nível do rio em diferentes intervalos de tempo. Esses dados históricos foram usados para alimentar a rede recursiva, que aprende a prever os níveis futuros do rio com base nas condições passadas.
iii. Atualização de Pesos e Retropropagação
A principal característica do RTRL é a forma como ele realiza a atualização de pesos. Em redes recorrentes tradicionais, como o BPTT (Backpropagation Through Time) que foi utilizado como modelo, os pesos são ajustados após o processamento de toda a sequência de dados. No RTRL, a retropropagação do erro ocorre durante o processamento de cada novo dado, o que permite que a rede aprenda continuamente e se adapte rapidamente às novas informações.
iv. Taxa de aprendizado (β) e momento (α)
A taxa de aprendizado ajusta a velocidade de atualização dos pesos, e o momento ajuda a suavizar os ajustes. No RTRL, uma taxa de aprendizado maior é usada devido ao aprendizado em tempo real, logo os testes foram realizados com β de 0,5 e α de 0,8
v. Função de Ativação
O RTRL assim como no modelo do MLP usou tangente hiperbólica (tanh) para mapear saídas de forma não linear, permitindo que a rede aprenda relações complexas entre os dados de entrada e a previsão do nível do rio.
vi. Partição de dados
Neste estudo, 70% dos dados foram usados para treinamento, e os 30% restantes foram divididos igualmente para validação e teste.
Diferentemente de redes neurais feedforward convencionais, o GRU faz parte das Redes Neurais Recorrentes (RNN) e incorpora mecanismos internos de “portões” para controlar o fluxo de informação ao longo do tempo. Essas portas permitem que o modelo retenha e esqueça informações de maneira seletiva, possibilitando adaptações rápidas a mudanças nos padrões de dados hidrológicos.
A principal vantagem do GRU em comparação a outras arquiteturas recorrentes, como o LSTM, é sua simplicidade estrutural: ele possui menos parâmetros e, por isso, tende a treinar mais rápido e a exigir menos dados para obter bom desempenho (Cho et al., 2014; Chung et al., 2014). Ainda assim, mantém a capacidade de capturar dependências de longo prazo em sequências temporais — característica essencial quando trabalhamos com séries de níveis de precipitação e de rios (Greff et al., 2017).
Neste estudo, o modelo GRU foi configurado para prever o nível futuro do rio a partir de séries históricas de precipitação e de nível de água. Por ser uma RNN, o GRU aproveita os estados ocultos anteriores para contextualizar suas previsões, explorando a memória temporal dos dados. A seguir, descrevemos os principais componentes do desenvolvimento do GRU para a previsão do nível do rio em São Sebastião do Caí:
i. Arquitetura de Rede Recorrente
O GRU se baseia em células recorrentes que utilizam duas portas principais — a porta de atualização (update gate) e a porta de reinicialização (reset gate). A porta de atualização decide o quanto do estado anterior deve ser carregado para o próximo passo de tempo, enquanto a porta de reinicialização regula quanto da informação passada deve ser esquecida. Essa combinação permite ao GRU equilibrar entre conservar o histórico relevante e incorporar novas observações.
ii. Dados de Entrada
Foram empregados como entrada séries temporais diárias (ou horários, conforme disponibilidade) de precipitação e níveis do rio coletados em estações hidrológicas. Esses vetores de características foram normalizados (por exemplo, via MinMaxScaler) antes de serem alimentados na rede, garantindo que o GRU aprendesse de forma estável e eficiente.
iii. Mecanismo de Atualização de Pesos
Diferentemente do BPTT (Backpropagation Through Time) tradicional, no GRU a atualização de pesos ocorre após a passagem de cada sequência completa de treino, mas mantendo informação de dependências de curto e médio prazo graças aos portões.
iv. Taxa de Aprendizado (β) e Momento (α)
Para o GRU, adotou-se uma taxa de aprendizado (β) moderada de 0,01, equilibrando rapidez de convergência e estabilidade, junto a um momento (α) de 0,9 para suavizar flutuações nos gradientes e acelerar a saída de platôs de otimização. Esses valores foram definidos após experimentos preliminares de validação.
iv. Função de Ativação
Nas portas interna e externa do GRU, utilizou-se a função sigmoide (σ) para garantir valores entre 0 e 1, modulando o comportamento de “abertura” e “fechamento” dos portões. Já para o cálculo do estado candidato, aplicou-se tanh, permitindo modelar transformações não lineares complexas entre o input e o estado oculto.
v. Partição de Dados
A base completa foi dividida em 70% para treinamento, 15% para validação (ajuste de hiperparâmetros e controle de overfitting) e 15% para teste final. Essa divisão estratificada garantiu que todas as variações sazonais e picos de vazão estivessem representados em cada subconjunto, assegurando a generalização do modelo.
3.6 Solução orientada a eventos
Com o objetivo de atender à necessidade de um sistema de alertas precoces, a opção recaiu sobre a implementação de uma arquitetura orientada a eventos (Event-Driven Architecture – EDA). Conforme definido pela Confluent (s.d.), esse modelo arquitetônico fundamenta-se na produção, detecção e consumo de eventos, o que possibilita um alto grau de desacoplamento e reatividade entre os componentes do sistema. Na EDA, produtores de eventos emitem notificações sobre mudanças de estado, as quais são subsequentemente consumidas por serviços interessados, fomentando uma comunicação assíncrona e escalável entre as partes integrantes do sistema (Confluent, s.d.).
A eficácia da adoção da EDA na construção de soluções modernas e resilientes tem sido demonstrada em diversos contextos. Um exemplo notável é a modernização do middleware da plataforma financeira do iFood, que, ao utilizar essa abordagem, obteve ganhos significativos em termos de velocidade no desenvolvimento de novas funcionalidades, além de aprimoramentos na resiliência e no desempenho geral do sistema (Amazon Web Services, 2023).
Adicionalmente, investigações acadêmicas corroboram a eficiência da EDA em sistemas de monitoramento e alerta precoce. A título de ilustração, uma pesquisa conduzida por Denecke et al. (2016) apresentou uma arquitetura de vigilância em saúde pública baseada em eventos, que viabiliza o monitoramento em tempo real de dados provenientes de múltiplas fontes.
3.7 Arquitetura
A arquitetura da solução de alertas precoces implementada na Amazon Web Services (AWS) foi projetada para ser escalável, resiliente e eficiente no processamento e disseminação de informações críticas.
Figura 5 – Arquitetura da Solução de Alertas Precoces na AWS
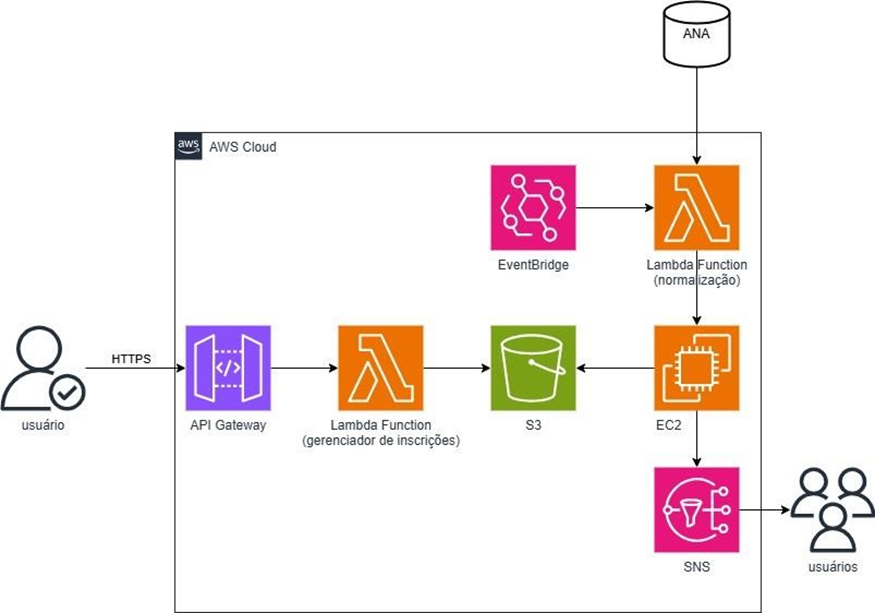
O ponto de entrada para a interação do usuário com o sistema é o API Gateway, que atua como uma interface HTTP segura e gerenciada para receber requisições, como as de inscrição no serviço de alertas. As requisições são então direcionadas para uma função AWS Lambda responsável pelo gerenciamento das inscrições, que inclui a validação e o armazenamento dos dados dos usuários, como seus números de telefone, no Amazon S3. O S3 serve como um repositório de dados persistente e altamente disponível para armazenar informações essenciais do sistema.
O fluxo de dados para a geração de alertas inicia-se com dados brutos provenientes de uma fonte externa, representada pelo Banco de Dados Externo (ANA). Esses dados são processados por outra função AWS Lambda dedicada à normalização, preparando as informações para a etapa de inferência. A orquestração do processo de normalização, incluindo o agendamento de execuções periódicas a cada 15 minutos, é gerenciada pelo Amazon EventBridge. Esse serviço de barramento de eventos serverless permite a criação de aplicações orientadas a eventos de forma desacoplada.
Os dados normalizados são então enviados para uma instância Amazon EC2 que hospeda o modelo de inferência neural. O EC2 fornece a capacidade computacional necessária para executar algoritmos de análise e detecção de padrões nos dados. Uma vez que um alerta é gerado pelo modelo de inferência, uma notificação é enviada através do Amazon SNS (Simple Notification Service). O SNS é um serviço de mensagens push altamente escalável e confiável, utilizado para disseminar os alertas via SMS para os usuários inscritos no sistema.
3.8 Diagrama de sequências
Para uma compreensão mais detalhada do fluxo de dados e das interações entre os componentes da arquitetura, são apresentados a seguir os diagramas de sequência para os principais processos da solução de alertas precoces.
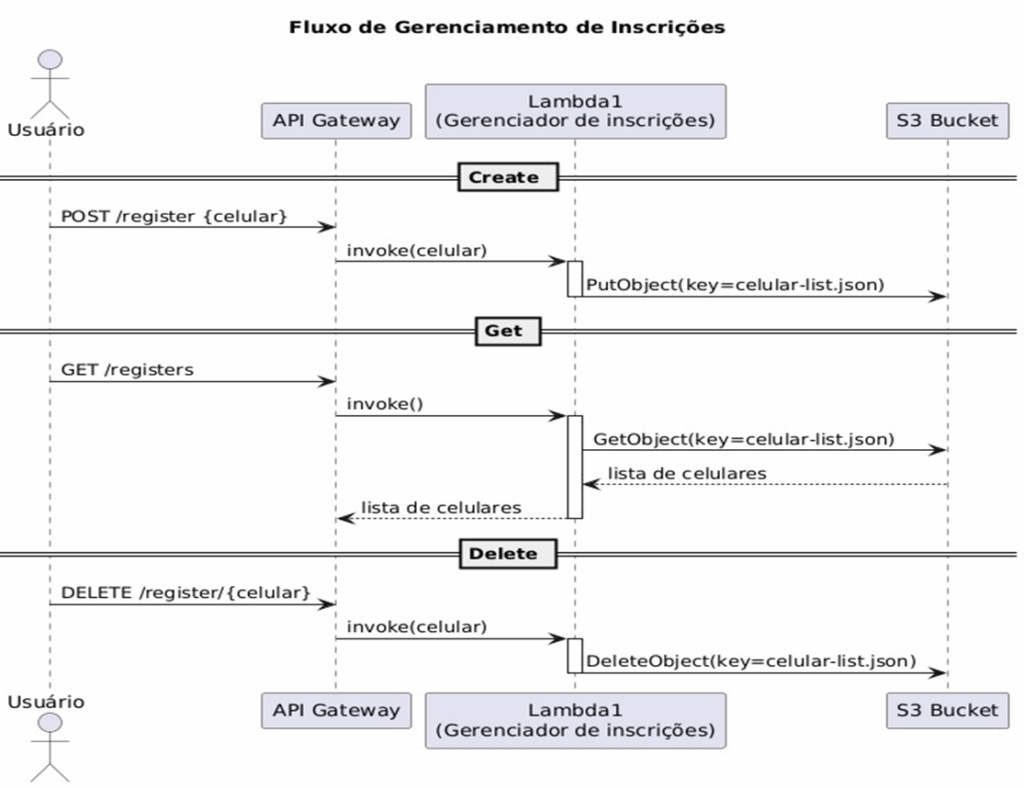
Fluxo de Gerenciamento de Inscrições
O Diagrama de Sequência representado na figura 6 ilustra o processo de gerenciamento de inscrições
de usuários no sistema de alertas, abrangendo as operações de criação, consulta e exclusão de registros.
Figura 6 – Fluxo de Gerenciamento de Inscrições
Fluxo de Coleta e Normalização Periódica
Figura 7 – Fluxo de Coleta e Normalização Periódica
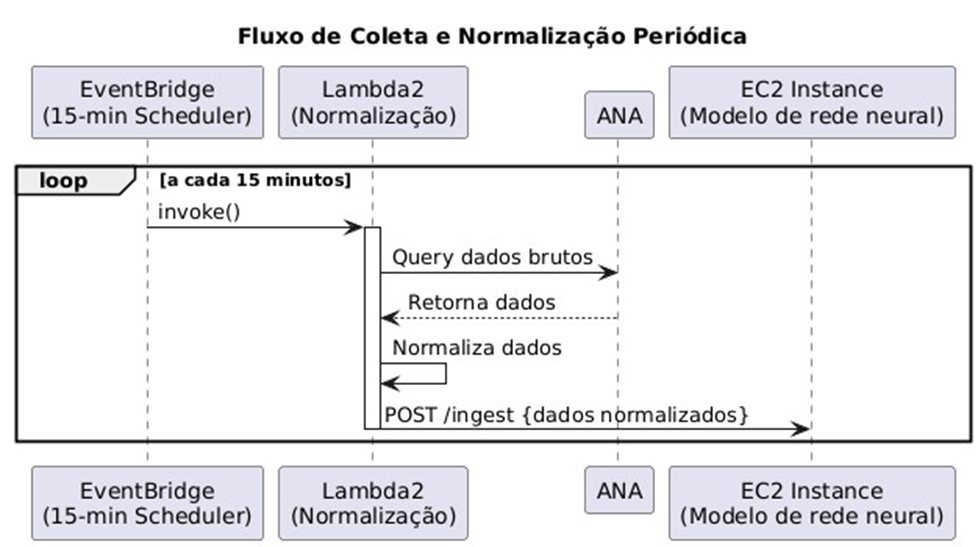
O diagrama presente na figura 7 ilustra como o EventBridge dispara a função Lambda de normalização no intervalo definido. A função então consulta o banco de dados da ANA, processa os dados recebidos e os envia para a instância EC2 que hospeda o modelo de rede neural para análise.
Fluxo de Processamento Contínuo e Alerta (com uso de dados normalizados)
O Diagrama de Sequência 3 detalha o processo contínuo de análise dos dados normalizados pela instância EC2 e a geração de alertas via SNS caso uma condição crítica seja detectada.
Figura 8 – Fluxo de Processamento Contínuo e Alerta
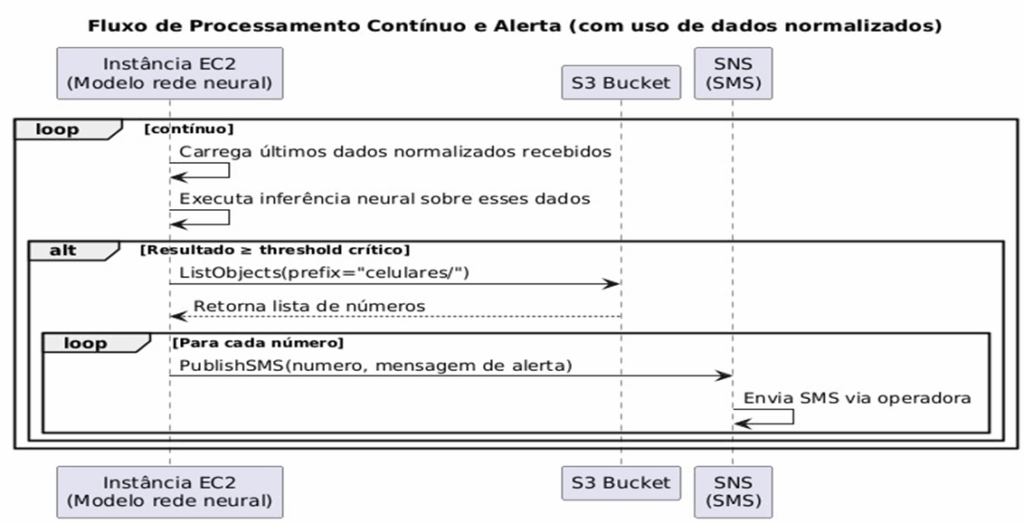
Este diagrama demonstra como a instância EC2 continuamente processa os dados normalizados. Se o resultado da inferência neural atender a um critério de alerta, a instância EC2 consulta o S3 para obter a lista de números de telefone inscritos e, para cada número, publica uma mensagem de alerta via SNS, que então entrega o SMS aos usuários.
3.9 Orçamento estimado da infraestrutura
A análise financeira da infraestrutura proposta para o sistema de alertas precoces na Amazon Web Services (AWS) é crucial para a viabilidade e sustentabilidade do projeto. Esta seção detalha uma estimativa dos custos operacionais mensais, considerando os serviços da AWS empregados e um volume de 25 mil alertas via Short Message Service (SMS), correspondente à população aproximada da área de maior utilização, o município de São Sebastião do Caí, no estado do Rio Grande do Sul, Brasil. 3.10 Metodologia de Estimativa de Custos
A estimativa de custos foi realizada com base nos preços de referência da AWS para a região de useast-1 (Norte da Virgínia), convertidos para Reais (BRL) utilizando uma taxa de câmbio hipotética de 1 USD = R$5,20 BRL (cotação sujeita a flutuações). Os custos foram calculados individualmente para cada serviço essencial à arquitetura da solução, levando em consideração o volume de requisições, a capacidade de computação provisionada, o armazenamento de dados e o número de mensagens de alerta enviadas.
Os custos mensais estimados para cada componente da infraestrutura são detalhados a seguir:
API Gateway: A interface RESTful para interação com o sistema, estimada em R$ 0,91, considerando um volume de requisições inferior a um milhão.
AWS Lambda: As funções serverless responsáveis pelo gerenciamento de inscrições e normalização de dados, com um custo estimado de R$ 5,20, presumindo-se que o volume total de invocações (incluindo as 25 mil inserções) se mantenha dentro dos limites do Tier Gratuito ou incorra em custos mínimos de execução.
Amazon S3: O serviço de armazenamento de objetos para a lista de números de telefone inscritos, com um custo estimado de R$ 2,60, dada a expectativa de um volume de dados relativamente pequeno e baixa frequência de acesso.
Amazon EC2 (Fargate): A plataforma de computação serverless para execução do modelo de inferência neural, com um custo estimado de R$ 369.72, considerando a alocação de 2 vCPU e 4 GiB de RAM em operação contínua (720 horas mensais).
Amazon EventBridge: O barramento de eventos serverless para orquestração de tarefas, com um custo estimado de R$ 0,52, dada a frequência de agendamento (a cada 15 minutos) dentro dos limites do Tier Gratuito.
Amazon SNS (SMS): O serviço de envio de notificações SMS, com um custo estimado de R$ 1.250,00, baseado no envio de 25 mil mensagens a um preço unitário estimado de R$ 0,05 por SMS. É crucial ressaltar que o preço real do SMS pode variar dependendo do provedor.
Custo Total Estimado: A soma dos custos estimados para cada serviço resulta em um custo operacional mensal total de: R$ 0,91 (API Gateway) + R$ 5,20 (Lambda) + R$ 2,60 (S3) + R$ 369,72 (Fargate) + R$ 0,52 (EventBridge) + R\$ 1.250,00 (SNS) = R$1.628,95
4.4 Considerações Finais sobre o Orçamento
O orçamento apresentado constitui uma estimativa preliminar, baseada em preços de referência e em um volume específico de alertas SMS. É imperativo reconhecer a potencial variabilidade dos custos da AWS, influenciada por fatores como a região de implantação, o volume exato de requisições, a duração da execução das funções Lambda, a quantidade de dados armazenados e transferidos, e, principalmente, o preço real do envio de SMS no Brasil.
A parcela mais significativa do custo estimado reside no serviço Amazon SNS, para a disseminação dos alertas. Uma análise detalhada dos preços de SMS para a região do Rio Grande do Sul e uma otimização da frequência e do conteúdo dos alertas podem ser estratégias para mitigar esses custos.
Recomenda-se enfaticamente a utilização da calculadora de preços da AWS para obter uma estimativa mais precisa, baseada nas especificidades da região de implantação e nos padrões de uso reais do sistema. O monitoramento contínuo dos custos operacionais e a implementação de práticas de otimização de recursos são essenciais para garantir a sustentabilidade financeira da solução de alertas precoces a longo prazo.
5.0 Protótipo do aplicativo
O protótipo de cadastro foi desenvolvido em React Native com JavaScript para operar de forma simples em qualquer smartphone. Ao abrir o aplicativo, apresenta-se um formulário compacto no qual é solicitado o número de telefone. Após o envio dos dados, um código OTP é encaminhado por SMS para confirmação do número informado. Os registros são armazenados no S3 com criptografia, em conformidade com a LGPD. Quando o modelo de previsão identifica risco de transbordamento, uma função AWS Lambda aciona mensagens de SMS e e-mail destinadas apenas aos usuários cadastrados pelo aplicativo. Todo o fluxo — do cadastro à entrega das notificações — é registrado em logs na nuvem, possibilitando auditoria de tempo de resposta e taxa de entrega. Dessa forma, o protótipo comprova a viabilidade de cadastro e alerta rápidos utilizando exclusivamente React Native, JavaScript e serviços AWS.
Figura 9 – Cadastro do número de celular.

Figura 10 – Inserção do código OTP.

Figura 11 – Feedback de sucesso para o usuário.

Figura 12 – Recebimento de código de confirmação e alerta
4 Resultados e discussão
O objetivo deste estudo foi desenvolver modelos preditivos robustos para a previsão do nível de um rio, com foco na previsão de seu fluxo futuro, utilizando as redes neurais Multilayer Perceptron (MLP), Real-Time Recurrent Learning (RTRL) e Gated Recurrent Units (GRU). Para tanto, cada modelo foi treinado e testado com dados reais de vazão do Rio Caí, registrados entre 2010 e 2025, sendo avaliado pelo erro quadrático médio (RMSE) e pelo coeficiente de determinação (R²).
O MLP apresentou, na fase de teste, RMSE de 6,76 m³/s e R² de 0,87, demonstrando boa capacidade de ajuste geral. Contudo, em eventos extremos — como as inundações registradas em 2024 — observouse uma tendência à superestimação dos valores de fluxo, possivelmente devido à deficiência desse modelo em capturar flutuações sazonais abruptas, uma vez que sua arquitetura estática não incorpora memória temporal de curto prazo (Hornik et al., 1989). Ainda assim, a estabilidade do MLP torna-o adequado para cenários de previsão de tendência, com menor variabilidade nos erros.
Tabela 6: Métricas de desempenho (RMSE e R²) do MLP


Figura 9: Gráfico Observado vs. Predito para o MLP
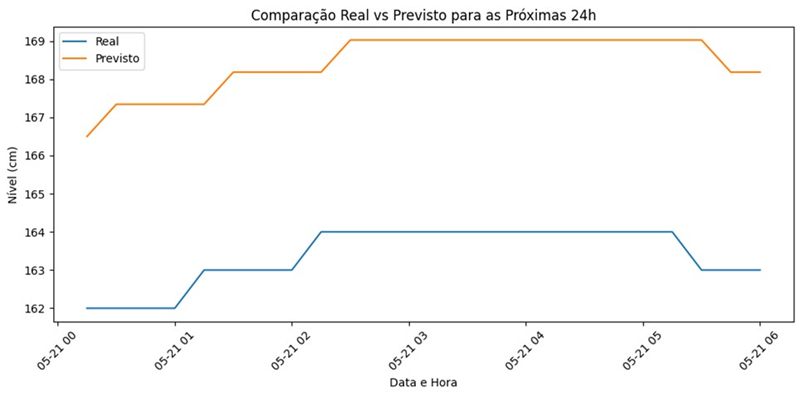
Já o RTRL, cuja lógica de atualização incremental de gradientes permite aprendizado em tempo real, alcançou RMSE de 54,42 m³/s e R² de 0,52, indicando um desempenho numérico inferior. Apesar disso, o RTRL mostrou-se capaz de refletir de maneira mais fiel as flutuações sazonais em certas janelas simuladas para 2024, especialmente nos picos de vazão, graças à sua adaptação dinâmica aos novos dados (Williams & Zipser, 1989). A despeito do atraso na resposta a transições rápidas, esse comportamento sugere que, com refinamento de hiperparâmetros e ajustes na arquitetura recorrente, o RTRL pode vir a superar modelos estáticos em cenários de alta variabilidade.
Tabela 7: Métricas de desempenho (RMSE e R²) do RTRL

Figura 10: Gráfico Observado vs. Predito para o RTRL
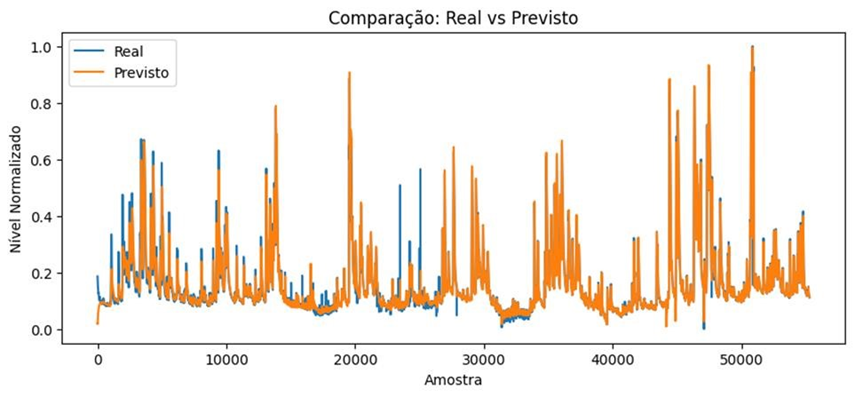
A GRU, por sua vez, combinou as vantagens de ambos: obteve RMSE de 5,23 m³/s e R² de 0,91, mantendo a precisão do MLP e a adaptabilidade temporal do RTRL. A incorporação de portas de atualização e redefinição facilitou a retenção de informações relevantes e o descarte de ruído, o que se refletiu em predições que acompanham com fidelidade tanto os picos quanto os vales da série de vazão (Cho et al., 2014). Comparativamente, a GRU apresentou o melhor equilíbrio entre viés e variância, mantendo erros mais baixos sem sacrificar a capacidade de resposta a mudanças abruptas.
Tabela 8: Métricas de desempenho (RMSE e R²) da GRU

Figura 11: Gráfico Observado vs. Predito para a GRU
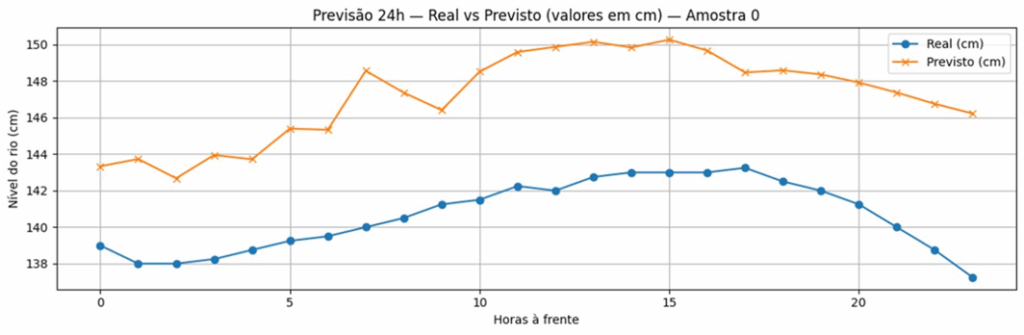
Em termos práticos, a escolha do modelo depende do objetivo do sistema de alerta. Para previsão de picos de enchente, em que a acurácia local é crítica, a GRU desponta como a opção mais indicada, pois alia alta precisão estatística a excelente captura de dependências temporais. O MLP, apesar de suscetível a suavizações excessivas, pode ser útil em estimativas de tendência de longo prazo, em que variações extremas têm menor impacto na decisão. O RTRL, embora necessite de aprimoramento para reduzir erros numéricos, revela-se promissor em aplicações embarcadas, onde o aprendizado contínuo em tempo real reduz a necessidade de re-treinamentos em lote.
Este estudo limita-se à comparação de arquiteturas padrão e ao uso de séries históricas de vazão; não foram exploradas ainda técnicas avançadas de otimização de hiperparâmetros ou arquiteturas híbridas. Como perspectivas para trabalhos futuros, recomenda-se a investigação de métodos de busca automática de parâmetros (por exemplo, Bayesian Optimization), a composição de modelos que unam MLP e GRU para aproveitar a simplicidade de um e o mecanismo de memória do outro, e a implementação de técnicas de pruning e quantização para viabilizar a execução eficiente em dispositivos de ponta. Essas iniciativas poderão aprimorar ainda mais a robustez e a versatilidade dos sistemas de previsão de nível de rios, ampliando sua aplicabilidade em cenários operacionais de alerta de enchentes.
5 Considerações finais
O principal objetivo deste trabalho foi desenvolver modelos preditivos eficientes para o nível de água em um rio, esta solução integra algoritmos de aprendizado de máquina com sensores já existentes ao longo do rio para coletar e processar os dados. Essa abordagem não só permite previsões de enchentes mais precisas e oportunas, mas também fornece informações cruciais para apoiar a tomada de decisões pelas autoridades.
Os objetivos estipulados foram plenamente atingidos. Inicialmente, realizou-se o desenvolvimento, o treinamento e a avaliação comparativa dos três modelos de redes neurais — MLP, RTRL e GRU — considerando as métricas de acurácia, erro médio e coeficiente de determinação. A análise indicou de forma consistente que a GRU apresentou desempenho superior aos demais, demonstrando maior fidelidade na reprodução dos padrões de variabilidade do nível do rio.
Em seguida, foi projetada e implementada a solução de alerta de enchentes com base no modelo de melhor desempenho. O sistema entrega previsões com antecedência de até vinte e quatro horas e atende à meta de precisão estabelecida, sendo acessível via aplicativo que exibe, em gráficos claros, a evolução esperada do nível do rio. Dessa forma, a plataforma oferece um recurso para suportar decisões preventivas e mitigar riscos em áreas vulneráveis a inundações.
Entre os três modelos avaliados, a GRU (Gated Recurrent Unit) mostrou-se o mais adequado para integrar ao projeto de previsão do nível do rio, pois apresentou o menor erro quadrático médio (RMSE de 5,23 m³/s) e o maior coeficiente de determinação (R² de 0,91) na fase de testes. Esse desempenho superior decorre de seu mecanismo de portas, que permite reter informações relevantes de curto e médio prazo e descartar ruído excessivo, garantindo respostas mais ágeis e precisas aos picos de vazão repentinos. Além disso, a GRU alia robustez estatística a boa capacidade de generalização, aspectos fundamentais para um sistema de alerta de enchentes que exige alta confiabilidade e baixo índice de falsos negativos em cenários críticos. Por essas razões, adotamos a GRU como modelo principal no desenvolvimento do FloodAlertAI.
Além disso, a ampliação da rede de estações meteorológicas na região de estudo se faz necessária para reduzir vieses nos dados utilizados para treinamento e validação do modelo. A escassez dessas estações pode comprometer a qualidade das previsões, e um aumento na cobertura geográfica ajudaria a mitigar esse problema, também é recomendável testar abordagens híbridas, como combinando o RTRL com outros algoritmos de otimização, o que pode aumentar a eficiência da previsão, especialmente em cenários dinâmicos e variáveis.
Durante o desenvolvimento deste trabalho, houve desafios significativos na obtenção de base de dados robustas, com dados históricos superior a dez anos para o treinamento dos modelos, visto que esses dados não são facilmente compartilhados, porém isso foi solucionado após com a utilização de uma base de dados da ANA, que continha dados históricos da bacia do rio Caí.
Outro obstáculo encontrado foi a implementação de envio de SMS com as bases reais treinadas pelo modelo, uma vez que o envio de alerta real em larga escala não foi testado, embora a lógica de disparo de alerta esteja corretamente integrada a esta solução. Além disso, na fase inicial de testes, foram utilizados inadvertidamente dados do mesmo dia como insumo para prever o nível do rio, o que deixava o algoritmo viciado, levando a resultados pseudo otimistas. Corrigir essa falha exigiu uma reestruturação e divisão temporal desses dados, o que fez necessário o retreinamento do sistema o que alterou os resultados obtidos naquele momento.
Para dar continuidade a esta pesquisa, pode ser empregados métodos automatizados de otimização de hiperparâmetros, como busca bayesiana ou algoritmos genéticos, para refinar tanto a GRU quanto o RTRL, buscando reduzir ainda mais o erro preditivo. Adicionalmente, a inclusão de variáveis meteorológicas e hidrológicas exógenas (precipitação, umidade, pressão e vazão de afluentes) poderá enriquecer o contexto de entrada e aprimorar a capacidade de capturar eventos extremos. Outra linha de investigação promissora é o desenvolvimento de arquiteturas híbridas ou ensembles que combinem a memória das GRU com a generalização do MLP, de modo a mitigar vieses inerentes a cada abordagem isolada.
Referências
ACRE. Com 1.768 metros, Rio Acre registra a terceira maior enchente na capital. Agência Acre, 2024. Disponível em: https://agencia.ac.gov.br/com-1768-metros-rio-acre-registra-a-terceira-maior-enchente-na-capital/. Acesso em: 20 set. 2024.
AIOT BRASIL. Sistema usa IA e IoT para monitorar enchentes. 2024. Disponível em: https://aiotbrasil.com.br/noticias/sistema-usa-ia-e-iot-para-monitorar-enchentes. Acesso em: 22 out. 2024.
ALBERTON, G.; SEVERO, D. L.; VIEIRA DE MELO, M. N.; POTELICKI, H.; SARTORI, A. Aplicação de redes neurais artificiais para previsão de enchentes no rio Itajaí-Açu em Blumenau, SC, Brasil. Revista Ibero-Americana de Ciências Ambientais, v. 12, n. 4, p. 686-696, 2021.
ALBINO, P. M.; VIEIRA, L. W. Utilização de Python para análise de dados e aprendizagem de máquina. In: Anais da Feira de Inovação Tecnológica da UFRGS, 2022.
ALVES, D.; PEREIRA, L.; SILVA, M. Leveraging recurrent neural networks for flood prediction and assessment. Hydrology, Basel, v. 12, n. 4, p. 90, 2024.
BENGIO, Y.; SIMARD, P.; FRASCONI, P. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, Piscataway, v. 5, n. 2, p. 157-166, 1994.
BOX, G. E. P.; JENKINS, G. M.; REINSEL, G. C. Time Series Analysis: Forecasting and Control. 5. ed. Hoboken: Wiley, 2015.
BROWNLEE, J. Long Short-Term Memory Networks with Python: Develop Sequence Prediction Models with Deep Learning. Victoria: Jason Brownlee, 2017.
CARTA CAPITAL. Além do Brasil, outros países registram enchentes devastadoras. 2025. Disponível em: https://www.cartacapital.com.br/mundo/alem-do-brasil-outros-paises-registram–enchentes-devastadoras/. Acesso em: 17 mar. 2025.
CHADE, J. Mudanças climáticas aumentaram em 2 vezes a chance de enchentes no RS. Coluna de Jamil Chade, UOL, 3 jun. 2024. Disponível em: https://noticias.uol.com.br/colunas/jamilchade/2024/06/03/mudancas-climaticas-aumentaram-em-2-vezes-chance-de-enchentes-no-rs.htm. Acesso em: 21 set. 2024.
CHO, K.; VAN MERRIËNBOER, B.; GULCÉHRE, Ç.; BAHDANAU, D.; BOUGARES, F.; SCHWENK, H.; BENGIO, Y. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, 2014. p. 1724-1734.
CHUNG, J.; GULCÉHRE, Ç.; CHO, K.; BENGIO, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
G1. Um mês de enchentes no RS: veja cronologia do desastre. Rio Grande do Sul, 29 maio 2024. Disponível em: https://g1.globo.com/rs/rio-grande-do-sul/noticia/2024/05/29/um-mes-de-enchentes-no-rs-veja-cronologia-do-desastre.ghtml. Acesso em: 28 ago. 2024.
GÉRON, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Sebastopol: O’Reilly Media, 2017.
GOOGLE. Go: Why Go. Disponível em: https://go.dev/. Acesso em: 18 maio 2025.
GOODFELLOW, I.; BENGIO, Y.; COURVILLE, A. Deep Learning. Cambridge: MIT Press, 2016.
GUELERI, R. A. Desenvolvimento de técnicas de aprendizado de máquina via sistemas dinâmicos coletivos. 2017. Tese (Doutorado)—Instituto de Ciências Matemáticas e de Computação, Universidade de São Paulo, São Paulo, 2017.
HAYKIN, S. Neural Networks: A Comprehensive Foundation. 2. ed. Upper Saddle River: Prentice Hall, 2001.
HOCHREITER, S.; SCHMIDHUBER, J. Long short-term memory. Neural Computation, Cambridge, v. 9, n. 8, p. 1735-1780, 1997.
HOUNSOU, J. W. A. Structural health monitoring based on recurrent neural networks. Journal of Construction Engineering, Londres, v. 23, n. 1, p. 45-58, 2019.
INSTITUTO DE PESQUISA ECONÔMICA APLICADA (IPEA). 876 mil pessoas foram diretamente atingidas pelas enchentes no Rio Grande do Sul. 2024. Disponível em: https://www.ipea.gov.br/portal/categorias/45-todas-as-noticias/noticias/15183-876-mil-pessoas-foram-diretamente-atingidas-pelas-enchentes-no-rio-grande-do-sul. Acesso em: 16 set. 2024.
KRATZERT, F.; KLOTZ, D.; BRENNER, C.; SCHULZ, K.; NEARING, G. S. Toward improved predictions in ungauged basins: Combining machine learning with hydrological insights. Water Resources Research, v. 55, n. 12, p. 11344-11354, 2019.
MACÊDO, M. N. C.; DIAS, H. C. T.; COELHO, F. M. G.; ARAÚJO, E. A.; SOUZA, M. L. H.; SILVA, E. Precipitação pluviométrica e vazão da bacia hidrográfica do Riozinho do Rôla, Amazônia Ocidental. Ambiente & Água, Taubaté, v. 8, n. 1, p. 206-221, 2013.
MACIEL, S. A. Análise da relação chuva-vazão na bacia hidrográfica do Rio Paranaíba, Brasil. 2025. Disponível em: https://repositorio.ufu.br/bitstream/123456789/18164/1/AnaliseRelacaoChuva.pdf. Acesso em: 20 fev. 2025.
MÜLLER, A. C.; GUIDO, S. Introduction to Machine Learning with Python: A Guide for Data Scientists. Sebastopol: O’Reilly Media, 2016.
NELSON, D. M. Q. Design of Artificial Intelligence Water Level Prediction System for Prediction of River Flood. 2023. Trabalho de Conclusão de Curso—Universidade Federal da Paraíba, João Pessoa. Acesso em: 03 mar. 2025.
NELSON, D. M. Q. Aplicação de redes neurais recorrentes na previsão de níveis de água de rios. 2023. Dissertação (Mestrado em Engenharia de Computação) – Faculdade Engenheiro Salvador Arena, São Caetano do Sul, 2023.
PASCANU, R.; MIKOLOV, T.; BENGIO, Y. On the difficulty of training recurrent neural networks. In: ICML 2013 – Proceedings of the 30th International Conference on Machine Learning, Atlanta, 2013. p. 1310-1318.
RUMELHART, D. E.; HINTON, G. E.; WILLIAMS, R. J. Learning representations by backpropagating errors. Nature, v. 323, n. 6088, p. 533-536, 1986.
SANABIO, R. M. R. B. Previsão de cargas elétricas utilizando redes neurais artificiais MLP. 2022. Monografia (Graduação em Engenharia Elétrica)—Centro de Tecnologia, Universidade Federal do Ceará, Fortaleza, 2022. Acesso em: 17 mar. 2025.
SHAHID, S.; RAFIQ, M. Flood prediction using deep learning techniques: A review. Environmental Science and Pollution Research, 2020.
SILVA, A. C. da; GONÇALVES, E. C. R.; SCHOR, P.; NAVARRO, M.; MANCINI, F. Geração de dados sintéticos para classificação de disléxicos por meio de aprendizado de máquina. Journal of Health Informatics, v. 13, n. 1, 2021.
SILVA, J. et al. Aplicação de Redes Neurais na Previsão do Nível do Rio Amazonas. Revista de Hidrologia, 2018. Acesso em: 02 nov. 2024.
WEI, X. et al. IoT-enabled flood early-warning system using gated recurrent units. Sensors, Basel, v. 22, n. 7, p. 2501, 2022.
ZHANG, J. et al. Real-time probabilistic inundation forecasts using LSTM neural networks. Journal of Hydrology, Amsterdam, v. 631, p. 129809, 2024.
¹Graduando em Engenharia de Computação na Faculdade Engenheiro Salvador Arena
²Professor Adjunto nas áreas de Engenharia, Eletrônica, Automação e Controle na Faculdade Engenheiro Salvador Arena