REST API INTEGRATION ANALYSIS IN DIFFERENT PROGRAMMING LANGUAGES
REGISTRO DOI: 10.69849/revistaft/ar10202412131438
Fernando Arruda de Miranda¹;
João Henrique Gião Borges²;
Fabiana Florian³.
Resumo: Este artigo científico tem o objetivo de analisar integrações de serviços API Rest, desenvolvidas em diferentes linguagens de programação, Java e Python. Os serviços executam a mesma rotina de tarefas, consultam uma API externa e armazenam as informações no mesmo banco de dados relacional, PostgreSQL. No final da execução das rotinas dos serviços, foi gerado um relatório do tempo levado para finalizar a tarefa, com esses resultados, somados aos esforços para o desenvolvimento das respectivas API, foi possível gerar uma comparação relativa de alguns aspectos como desempenho, complexidade, tempo de execução e facilidade de uso. A partir desta análise foi estabelecido dados para esclarecer qual linguagem tem a melhor atuação na implementação de API REST.
Palavras-chave: API. Java. Linguagem de programação. PostgreSQL. Python. REST.
Abstract: This scientific article aims to analyze the integration of Rest API services developed in different programming languages, Java and Python. The services perform the same routine tasks, consult an external API and store the information in the same relational database, PostgreSQL. At the end of the execution of the service routines, a report was generated on the time taken to complete the task. With these results, added to the efforts made to develop the respective APIs, it was possible to generate a relative comparison of some aspects such as performance, complexity, execution time and ease of use. From this analysis, data was generated to clarify which language has the best performance when implementing REST APIs.
Key-Words: API. Java. Programming Languages. Python. PostgreSQL. REST.
1 INTRODUÇÃO
Roy Fielding, cientista da computação que criou a arquitetura API REST, também conhecida como API RESTful, que nada mais é que uma interface de programação de aplicação (API ou API web) que segue as restrições de arquitetura REST (REST é a sigla em inglês para “Representational State Trasfer”, quem em português significa transferência de estado representacional), concedendo interações com serviços web RESTful. REST não é um protocolo ou padrão, mas sim um conjunto de restrições de arquitetura. Em resumo, uma API é um conjunto de definições de protocolos utilizados no desenvolvimento e integração de aplicações, um contrato entre provedor e usuário, estabelecendo o conteúdo exigido pelo consumidor (a chamada), e o conteúdo exigido pelo produtor (a resposta). Os desenvolvedores de API podem implementar a arquitetura REST de maneiras variadas.
O artigo demonstra os resultados de duas aplicações desenvolvidas em Java e Python, adotando essa arquitetura com uma rotina de consumo da API externa, ViaCep (https://viacep.com.br/), um WebService gratuito de alto desempenho para consulta de Código de Endereçamento Postal (CEP) do Brasil, a API externa fornece informações dos CEPs, como logradouro, complemento, bairro, localidade, UF (unidade federativa), DDD telefônico, código IBGE, código GIA (Guia de Informação e Apuração do ICMS) e código SIAFI (Sistema Integrado de Administração Financeira), houve a persistência das informações em um banco de dados local Postgres, cronometrando o desempenho das APIs.
Apesar de existir uma grande variedade de linguagens de programação, algumas podem ser mais adequadas para certos negócios ou empresas. Segundo Prechelt (2000), a literatura científica e de engenharia fornece muitas comparações de linguagens de programação de diferentes maneiras e com diferentes restrições.
A implementação do código-fonte para consumir uma API externa em diferentes linguagens de programação de modo que resulte nas respostas necessárias para suprir as necessidades da pesquisa demanda muito tempo. As documentações das tecnologias e frameworks muitas vezes não são bem desenvolvidas, tendo como opções recorrer aos fóruns on-line para sanar dúvidas que em contrapartida são bastante utilizadas. Os testes foram realizados na mesma máquina com as mesmas especificações de hardwares para não interferir na realidade da análise. A captura das informações será feita no tempo de execução da aplicação para dados mais fieis aos resultados.
A partir do desenvolvimento das aplicações, com as implementações API REST nas linguagens de programação JAVA com o framework Spring Boot e PYTHON com framework Flask. Foi feito o registro de tempo de execução, e análise estatística do código-fonte para identificar qual API executou os mesmos números de tarefas, consultando as informações e armazenando, de forma mais eficiente.
Dividindo os esforços em duas fases, a primeira no desenvolvimento, versionamento e executando as aplicações,na segunda foi feita a análise das aplicações em execução, resultando nos dados para uma resposta esclarecida dos dados obtidos.
2 REVISÃO BIBLIOGRÁFICA
Nesta seção foram apresentados brevemente o funcionamento da Arquitetura Rest, Linguagens de programação e banco de dados.
2.1 Rest
O Representational State Transfer (REST), que em português significa Transferência de Estado Representacional, é um estilo de arquitetura de software da World Wide Web (WWW) desenvolvido para servir aplicações em Web. O REST oferece um conjunto de linhas de orientação necessárias para se desenvolver um serviço coeso, escalável e com elevada performance. É independente da plataforma e da linguagem. Segundo a dissertação do Dr. Roy Fielding, este estilo de arquitetura baseia-se nos seguintes princípios básicos : Cliente Servidor, Stateless, Cacheble, Interface Uniformizada e Sistemas de Camadas.(MARQUES, 2018, p.23).
2.1.1 Cliente Servidor
Uma aplicação REST deve dividir suas arquitetura e responsabilidades entre dois ambientes distintos, o cliente e o servidor, garantindo independência e, por conseguinte, melhorando sua escalabilidade. O cliente concentra-se exclusivamente na interface, enquanto o servidor, que fornece o serviço, é encarregado de responder às solicitações do cliente por meio da execução dos pedidos recebidos. A interação entre clientes e servidor via protocolo HTTP é ilustrada na Figura 1.
Figura 1 – Modelo Cliente Servidor
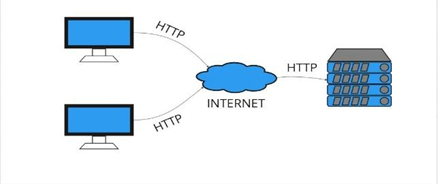
2.1.2 Stateless
O servidor não retém dados sobre o estado do cliente, pois essas informações residem no próprio cliente. Este último pode emitir múltiplos pedidos ao servidor, cada um executado de maneira independente e seguindo um padrão. Cada requisição ao servidor é estruturada de modo a fornecer somente as informações indispensáveis para o processamento eficiente e preciso por parte do servidor.
2.1.3 Cacheable
Para evitar processos desnecessários e otimizar significativamente o desempenho, quando um cliente solicita informações ao servidor, a resposta é temporariamente armazenada em cache. Dessa forma, se outros clientes solicitarem as mesmas informações, o servidor pode fornecer a resposta diretamente do cache, sem a necessidade de reprocessamento, resultando em melhorias de eficiência, escalabilidade e desempenho para o usuário. Entretanto, o uso excessivo do cache pode comprometer a confiabilidade dos dados, tornando-os desatualizados. Por isso, é importante implementar um cache de gateway (ou proxy reverso), que é um servidor de rede independente responsável por armazenar em cache as respostas do servidor, reduzindo o número de interações diretas e aumentando a eficácia do sistema.
2.1.4 Interface Uniformizada
A interação entre clientes e servidor segue princípios simples baseados em diretrizes específicas, as quais, quando claramente definidas, promovem uma comunicação mais consistente e padronizada. Seguem abaixo algumas diretrizes fundamentais baseadas no padrão arquitetônico estabelecido:
Cada recurso é identificado por meio de um URI (Uniform Resource Identifier) único e coeso. As URIs representam recursos, não ações. As ações são expressas por meio de verbos (ou métodos) HTTP. O formato no qual o recurso é fornecido ao cliente é selecionado conforme as necessidades do provedor de serviço, sendo os formatos mais comuns o JavaScript Object Notation (JSON) e o extensible Markup Language (XML). O formato da comunicação entre cliente e servidor é especificado no Content Type. O cliente recebe todas as informações necessárias na resposta para navegar e acessar todos os recursos da aplicação. Tanto nos pedidos quanto nas respostas, informações de meta dados são incluídas (por exemplo, código HTTP, Content-Type, Host, entre outras).
2.1.5 Sistemas em camadas
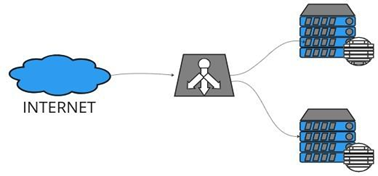
É crucial que a aplicação seja construída com camadas que possam ser facilmente ajustadas, adicionadas ou removidas. Cada camada desempenha funções específicas na comunicação ou processamento de informações entre o cliente e o servidor. Geralmente, o cliente não se comunica diretamente com o servidor da aplicação; em vez disso, ele passa por um middleware, como um balanceador de carga ou uma máquina intermediária. Esse middleware é responsável por direcionar os pedidos para o servidor, assegurando que cada camada execute suas funções designadas. Isso resulta em uma estrutura mais adaptável a mudanças, melhorando significativamente a performance, escalabilidade, simplicidade, flexibilidade, visibilidade, portabilidade, confiabilidade e segurança. A Figura 2 ilustra um diagrama de rede que emprega um balanceador de carga para distribuir a carga entre vários servidores.
Figura 2 – Modelo Cliente-Servidor com um load balancer.
2.2 Linguagem de Programação
“Os computadores são máquinas que processam dados, para isso, precisam ser instruídos. A linguagem que um computador eletrônico compreende, são sequências de “zeros” e “uns” (a linguagem binária).” (BORGES E GANIMI, 2018)
Como esta linguagem não é apropriada para os humanos, foi necessário o desenvolvimento das linguagens de programação. As linguagens de alto nível são aquelas que se aproximam mais da nossa linguagem e por consequência se distanciam mais da linguagem dos computadores. Elas possuem um nível de abstração que facilita o entendimento do programador, pois foi removido da sintaxe o que o programador não precisa entender, ou pra quem nunca vai mexer com linguagens de baixo nível que são as que mais se aproximam dos computadores. (BORGES E GANIMI, 2018)
De acordo com BORGES E GANAMI (2018), para o uso da linguagem de alto nível é necessário que a mesma seja traduzida para a linguagem de baixo nível do computador, que é realizada através do uso dos compiladores ou interpretadores. Por exemplo a linguagem Python.
2.2.1 Java
Java é uma linguagem de programação de alto nível, orientada a objetos, desenvolvida pela Sun Microsystems (agora parte da Oracle Corporation) na década de 1990. Desde então, tornou-se uma das linguagens mais populares e amplamente utilizadas em uma variedade de domínios, incluindo desenvolvimento de aplicativos web, desktop, móveis e corporativos. Java é uma linguagem poderosa e versátil que oferece portabilidade, segurança e eficiência. Seu vasto ecossistema de ferramentas, bibliotecas e frameworks a torna uma escolha popular para uma ampla gama de aplicações, desde aplicativos web até sistemas empresariais complexos.
2.2.2 Python
Python é uma linguagem de programação de alto nível, interpretada, dinâmica e multiparadigma. Criada por Guido van Rossum e lançada pela primeira vez em 1991, Python ganhou popularidade devido à sua sintaxe simples e legibilidade, além de sua vasta gama de aplicações em diversos domínios, incluindo desenvolvimento web, análise de dados, automação, inteligência artificial e muito mais.
Python é uma linguagem poderosa, flexível e fácil de aprender, que oferece uma ampla gama de recursos e funcionalidades. Sua sintaxe simples e legível, combinada com um ecossistema robusto de bibliotecas e frameworks, a torna uma escolha popular para desenvolvimento em uma variedade de domínios e aplicações.
2.3 Banco de dados
Um banco de dados constitui um conjunto organizado de informações ou dados, os quais são, em sua maioria, armazenados de forma eletrônica em sistemas computacionais. Esse banco de dados é usualmente gerido por um Sistema de Gerenciamento de Banco de Dados (SGBD). O conjunto formado pelos dados, pelo SGBD e pelos aplicativos associados é denominado sistema de banco de dados, frequentemente abreviado para banco de dados.
Nos modelos mais comuns de bancos de dados utilizados atualmente, os dados são estruturados em linhas e colunas dispostas em tabelas, o que facilita tanto o processamento quanto a consulta dessas informações de maneira eficiente. Esse formato possibilita o acesso, gerenciamento, modificação, atualização, controle e organização dos dados de maneira simplificada. A grande maioria dos bancos de dados faz uso da Linguagem de Consulta Estruturada (SQL) para a escrita e consulta das informações armazenadas.
2.3.1 Postgresql
O Postgresql é uma ferramenta que atua como sistema de gerenciamento de bancos de dados relacionados. Seu foco é permitir implementação da linguagem SQL em estruturas, garantindo um trabalho com os padrões desse tipo de ordenação dos dados.
Nos últimos anos, o uso desse sistema tem crescido consideravelmente, muito por conta de sua praticidade e pela sua alta compatibilidade com diferentes padrões de linguagem. Seu funcionamento é desenvolvido para ser, na prática, de grande suporte para que qualquer trabalho seja feito sem maiores dificuldades.
Um de seus pontos principais é sua adequação em padrões de conformidade, ajudando a construir bancos de dados otimizados. Neste trabalho, com suas qualidades principais, o PostgreSQL ajuda a armazenar informações de forma segura e, se necessário, restaurá-las sempre que houver solicitação de outras aplicações integradas.
3 DESENVOLVIMENTO
Nesta seção foram apresentadas a idealização da arquitetura do projeto, referente ao desenvolvimento das tecnologias necessárias para satisfazer a comparação das API ‘s. De acordo com a necessidade de construir aplicações similares, que resultou na comparação entre as tecnologias, foi desenvolvido duas APIs uma em Java com o framework Spring Boot e outra em Python com o framework Flask, ambas consultaram uma API externa ViaCep, e salvaram as informações consultadas em um mesmo banco de dados relacional Postgresql
3.1 Banco de Dados
A fim de armazenar as informações, resultantes da execução das funções da API, foi idealizada uma estrutura de dados para ser aplicada na arquitetura do banco de dados, para ser mantido uma massa de dados com as informações necessárias para a execução do projeto. Podemos ver o Diagrama de Entidades de Relacionamento do Banco de dados (Figura 14).
Figura 4 – Diagrama de Entidade de Relacionamento do Banco de Dados.
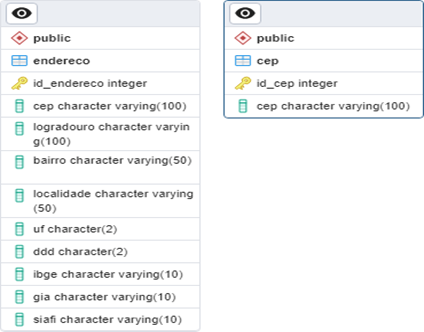
Como demonstrado na Figura 4, a tabela “cep” que possui as colunas id_cep e cep , foi responsável por conter os dados de ceps que as Api’s se responsabilizaram de consultar na Api externa ViaCep e salvar as respectivas informações na tabela “endereco” e suas coluna id_endereco, cep, logradouro, bairro, localidade, uf, ddd, ibge, gia, siafi, mantendo registros desses dados no nosso banco de dados local.
3.2 Api Java
Foi utilizado Java 17 com o Maven 3.9.2 e Spring Boot e suas dependências necessárias para execução do projeto Lombok e Feign Client. O projeto foi baseado em padrões de persistências, separando as Classes em Clients , Controllers, DTO’s, Entities, Repositories e Services.
Também há as classes de configurações padrões em Java, CrudApplication e ServeletInitializer, que são classes para a execução do projeto. Outros arquivos necessário pro funcionamento do projeto, o application.properties contém todas as informações necessárias para o funcionamento da aplicação, como por exemplo as configurações necessárias para autenticação no banco de dados e o pom.xml arquivo responsável por mapear as dependências para a construção e execução do projeto. A arquitetura de pacotes e classes podem ser observadas na Figura 5.
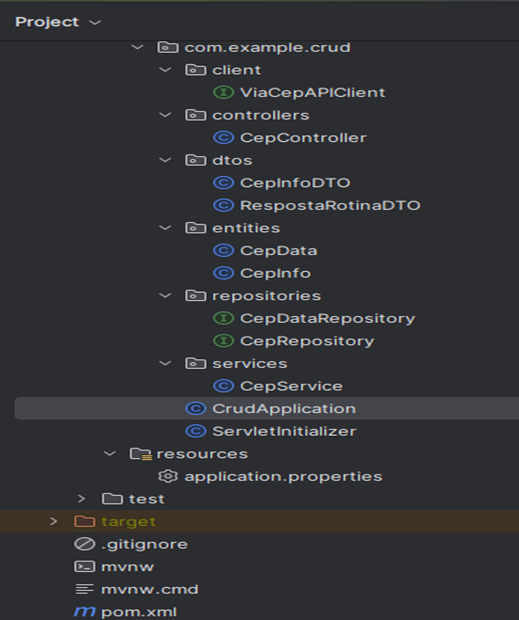
Autor, 2024
3.2.1 ViaCepClient
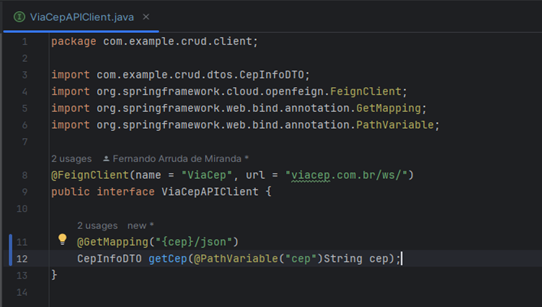
A classe do pacote client, ViacepApiClint, através do Feign Clint (Dependência do Spring Boot que faz com que o projeto consiga fazer requisições para outro API Rest) , tem mapeada a chamada para outro serviço externo, que forneceu para o sistemas os dados necessário para execução da rotina.
Veja na Figura 6 o mapeamento da url para a chamado do serviço através da anotação do Feign Cliente e logo depois, foi feito uma chamada do tipo GET que realizou a consulta do cep atráves da informação que o método ‘getCep’ recebe como parâmetro.
Figura 6 – Classe ViaCepClint.
3.2.2 Cep Controller
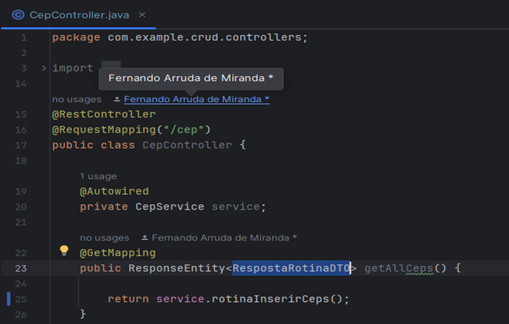
A classe do pacote Controllers, CepController, fica responsável por disponibilizar os endpoints da API. Onde contém toda a configuração necessária para o Postman requisitar o acesso a API, por isso há as anotações ‘RestController’ para indicar que a classe obviamente é um controller e também ‘RequestMapping ’ indicando que a url para acessar o método ‘getAllCeps’ é “/cep”. A classe contém o atributo service com uma anotação de ‘Autowired’ necessário para fazer a injeção da dependência do service, e o métodos ‘getAllCeps’ que também foi anotado com ‘GetMapping’, indicando que o método HTTPS para a chamada da rotina é do tipo GET, e seu retorno do tipo ResponseEntity, (Figura 7).
Figura 7 – Classe CepController.
3.2.3 Dtos
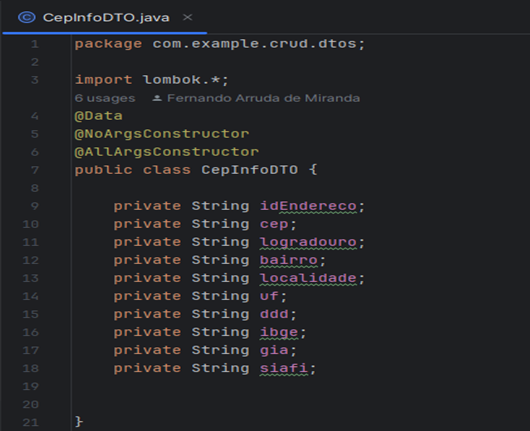
Há no projeto o pacote de dtos, do inglês Data Trasfer Objec (DTO), é um padrão de design usado em programação para transportar dados entre processos. Ele ajuda a encapsular dados, reduzindo a quantidade de chamadas necessárias e melhorando a eficiência na transferência. DTOs são geralmente usados em serviços de API e aplicações em camadas, permitindo uma troca de dados mais organizada e simplificada. No projeto foram implementadas duas classes de dto, a primeira representa as informações que a API externa retorna, nomeada como ‘CepInfoDTO’, veja na Figura 8.
Figura 8 – Classe CepInfoDTO.
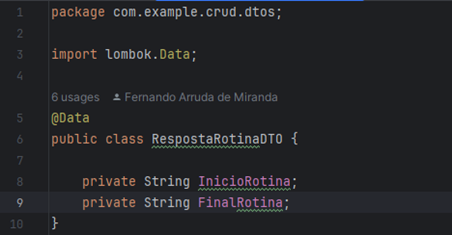
E a segunda representa o retorno como resposta para API, para ser descrito o tempo necessário para executar a rotina. Nomeada como ‘RespostaRotinaDTO’, neste vai conter duas informações, o horário de início da rotina e o horário final, resultando no tempo total que foi necessário para executar a rotina. Observe na Figura 9.
Figura 9 – Classe RespostaRotinaDTO.
3.2.4 Entities
São as classes que representam tabelas relacionadas ao nosso banco de dados, onde cada atributo da classe está ligado a uma coluna da tabela. Parametrizando as tabelas em códigos para transferir as informações atribuídas aos objetos com a finalidade de serem persistidas no banco de dados. Para isso é necessário mapear algumas informações da classe, como nome da tabela com a anotação ‘Table’ e o seu identificador primário com ‘Id’ , para que o banco de dados se responsabiliza por organizar o identificador único acrescenta na classe a anotação ‘GeneratedValue’. Observe as entidades do projeto representadas na Figura 10 e 11.
Figura 10 – Entidade CepInfo.

Figura 11 – Entidade CepData.
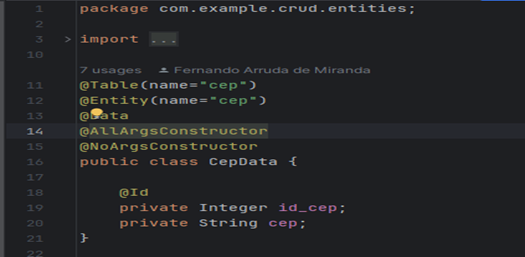
3.2.5 Repositories
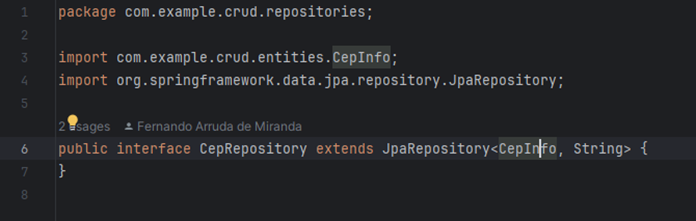
Os repositories são interfaces encarregadas de criar a conexão com o banco de dados e executar as instruções através de SQLs de forma muito simples, utilizando as classes entities mapeadas o Spring utiliza uma biblioteca JPA Data, que possui diversos métodos para facilitar a execução de consulta ao banco de dados. Apenas mapeando as tabelas de forma correta, os repositories já são capazes de executar as consultas padrões em SQL como um select, insert, update e delete de forma simplificada. Implementando um repositories para cada tabela do banco de dados os repositories podem ser observados nas Figuras 12 e 13.
Figura 12 – CepDataRepository.
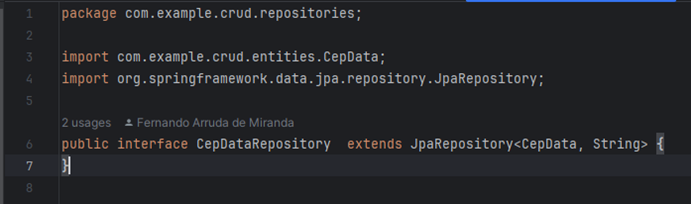
Figura 13 – CepRepository.
3.2.6 Services
Services são as classes encarregadas de fazer a comunicação e interação entre as demais camadas, nele fica contido toda a regra negocial do serviço, lógica e execução da rotina, encapsulando a lógica de negócios da aplicação, gerenciando as regras de como os dados são manipulados, processados e retornados. O service da aplicação é nomeado de ‘CepService’, ele se responsabilizará por injetar as dependências dos repositories e client, essa injeção é feita a partir da anotação ‘Autowired’ (Figura 14).
Autor, 2024.
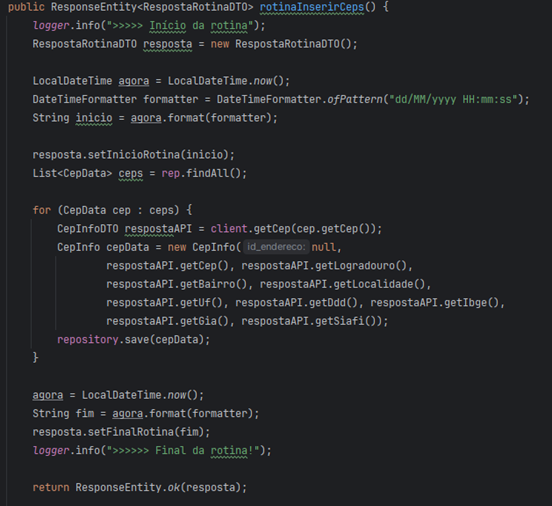
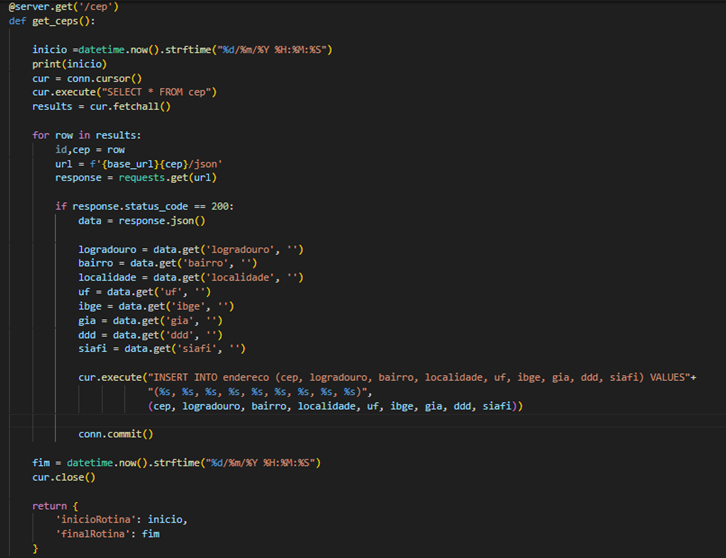
O Service vai possuir um método que executa a rotina, nomeado de ‘rotinaInserirCeps’, primeiro vai ser declarado uma data para registrar o horário de início da rotina e salva essa informação no atributo ‘inicioRotina’ do DTO ‘RespostaRotinaDTO’. Na sequência foi consultado na base de dados todos os CEPs presentes na tabela cep, utilizando o repositorie ‘CepDataRepositorie’ e armazenados em uma lista identificada como ‘ceps’. Através de um laço de repetição ‘for’ , o método percorre os ceps um a um, consultando o respectivo cep no client fazendo uma requisição para a API externa, armazena as informações no DTO ‘CepInfoDTO’, instância uma entidade do tipo ‘CepInfo’, transfere as informações do dto para a entidade, e através do repositorie salva a informação no banco de dados através do método ‘save’ passando a entidade como parâmetro. Terminado de percorrer todo o ‘for’, foi declarada outra data e registrado no atributo ‘finalRotina’ do ‘RespostaRotinaDTO’, e esse objeto foi a resposta do método para a chamada (Figura 15).
Figura 15 – Rotina de inserir ceps.
3.3 Api Python
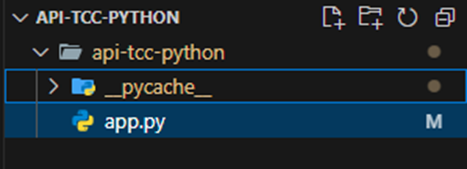
Utilizando Python na versão 3.12.3 e seu framework Flask na versão 3.0.3. Por ser uma linguagem interpretada, não precisou ser fortemente tipada como a API em Java, não foi necessário fazer compilação do código para ser executada e não foi necessário adotar padrões muito robustos como a Orientação a Objeto. Para configurar, foi necessário fazer o download da versão do python e utilizar o comando ‘pip’ para baixar as bibliotecas do projeto, como exemplo foi feita a instalação do Flask através do comando ‘pip install flask’. Um arquivo com a extensão ‘.py’ , foi o suficiente para a aplicação funcionar. O diretorio do projeto tem apenas o arquivo ‘app.py’ e uma pasta chamada ‘_pycache_’ que foi gerada automaticamente na execução do projeto para armazenar os arquivos compilados em bytecode, para melhorar a performance das execuções futuras. A figura 16 apresenta a organização das pastas.
Figura 16 – Arquitetura de pastas do projeto em Python.
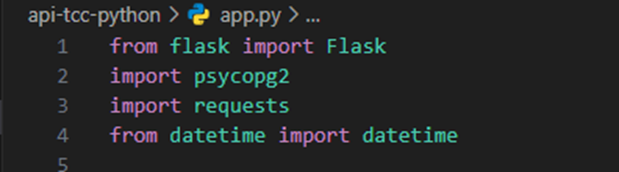
Para dar início a API em Python, na parte superior do arquivo, fica as dependências que foram utilizadas, atráves de um ‘import’ foi feita a implementação das bibliotecas, Flask é o framework que facilita as funções para nossa API, psycopg2 é a biblioteca responsável por ter as configurações necessária para fazer a implementação do banco de dados Postgres. A biblioteca ‘requests’ é importante para os métodos de comunicação Rest com API externas, e datetime é a biblioteca para gerenciamento de dados . A figura 17 apresenta essas importações.
Figura 17 – Importações para API Python.
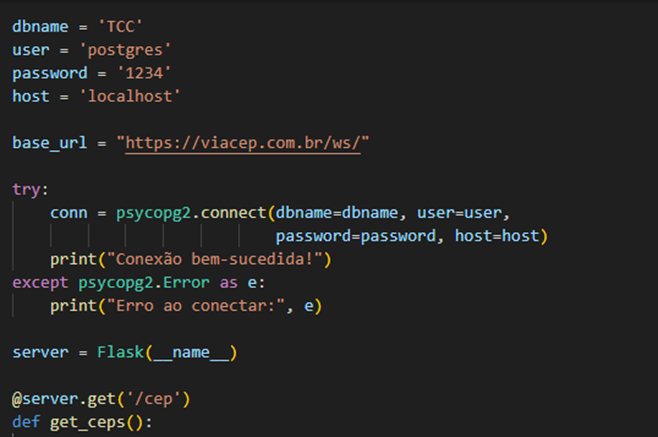
Em seguida foi parametrizadas informações para a conexão com o banco de dados, e a url da API externa, através de um ‘try catch‘ foi testado a conexão. Logo após é feita a instância do server em Flask, e no server foi mapeada a requisição HTTP GET para a rotina da API, também no ‘/cep’. A Figura 18 apresenta as configurações.
Figura 18 – Configurações iniciais da API.
A partir disso, há a origem do início da rotina. Com a variável datetime foi atribuída a variável início, a data referente ao início da execução da tarefa. Com a conexão estabelecida, foi feito uma consulta para trazer todos os ceps contidos na tabela cep e armazenados em uma lista chamada ‘results’, passamos a percorrer a lista com um ‘for’ e a cada item da interação usaremos a biblioteca ‘requests’ para fazer a requisição para a API externa, verifica através do if se o status_code é igual a 200, caso for usamos a resposta e convertemos para um json. Foi extraído do json as informações retornadas da API externa, e armazenado em variáveis locais, para executar uma inserção através de um sql nativo, passando as informações das variáveis. Finalizando a consulta com um ‘commit’ para salvar as alterações no banco de dados, e atribuindo uma data , para a variável fim, para ter registro do final da execução da tarefa,encerrando a conexão com o banco e respondendo a requisição com um json, contendo os atributos ‘inicioRotina’ e ‘finalRotina’ (Figura 19).
Figura 19 – Rotina de consulta de CEPs.
4 RESULTADOS
Nesta seção foram demonstrados os resultados obtidos através da execução das API ‘s.
4.1 Execução da Rotina da API em Java
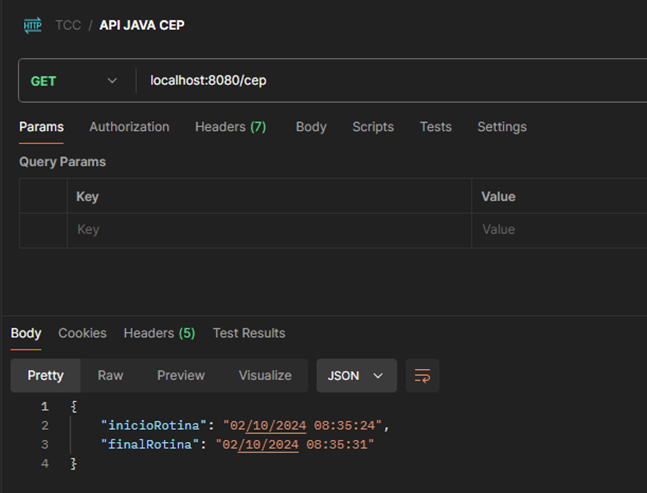
Através do postman, foi executado a requisição do tipo GET ‘/cep’ para a rotina, retornando o tempo de execução, no final da rotina os 50 registros de ceps contido no banco de dados, na tabela cep, será persistido na tabela ‘endereco’, foi registrado o tempo que a API em Java levou para executar essa rotina. A figura 20 apresenta o resultado obtido através do Postman.
Autor, 2024.
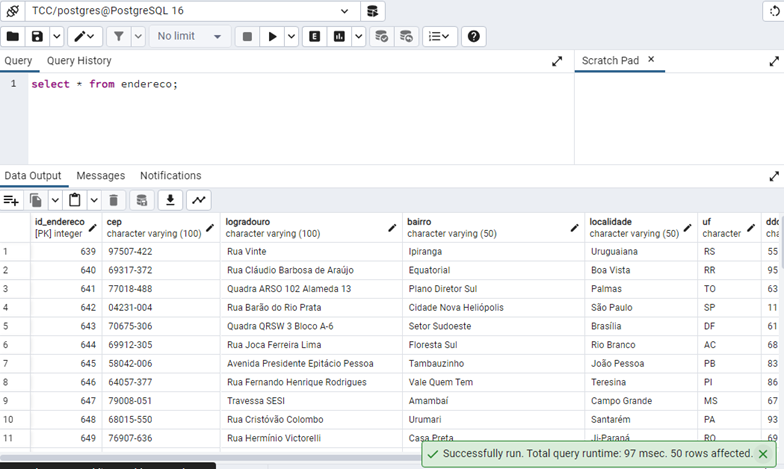
A rotina teve início às 08:35:24, finalizando às 08:25:31, logo a rotina em java levou 7 segundos para finalizar a tarefa. Foi obtido como resultado a tabela ‘endereco’, computando os 50 registros de informações dos respectivos CEP ‘s. (Figura 21).
Autor, 2024.
4.2 Execução da Rotina da Api em Python
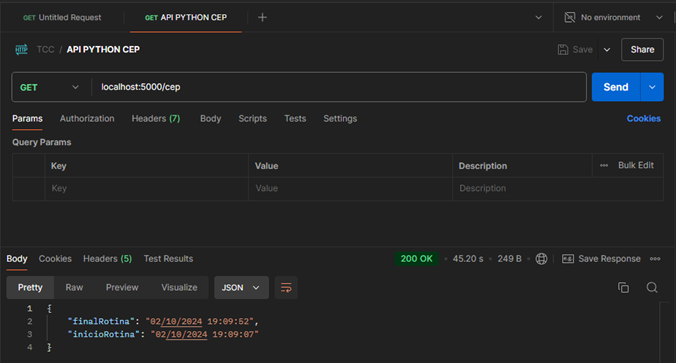
Através do postman, foi executado a requisição do tipo GET ‘/cep’ para a rotina, retornando o tempo de execução, no final da rotina os 50 registros de ceps contido no banco de dados será persistido na tabela ‘endereco’, e foi registrado o tempo que a API em Python levou para executar essa rotina.a Figura 22 apresenta o resultado obtido através do Postman.
Autor, 2024.
A rotina teve início às 19:09:07, finalizando às 19:09:52, logo a rotina em python levou 43 segundos para finalizar a tarefa.Na tabela ‘endereco’ foram armazenados 100 registros de informações da soma dos respectivos ceps consultados em ambas as APIs. (Figura 23).
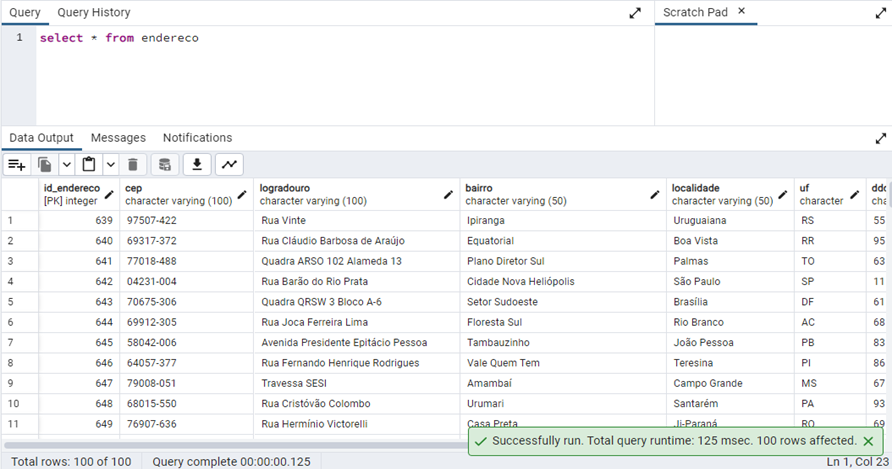
Autor, 2024.
4.3 Java X Python
Embora a comparação da execução das API em relação de tempo seja melhor em Java levando apenas 7 segundos para executar a rotina, Python fazendo a mesma rotina em 43 segundos, foi necessário acrescentar informações à análise. Para fazer a rotina em Java foi criado o código-fonte com 6 pacotes, 11 classes, 221 linhas de código e mais algumas configurações, como configurações de ambiente e variáveis, dependências e bibliotecas, compilador integrado, servidor embarcado , entre outras coisas, para o Python apenas 1 arquivo, 66 linhas de códigos, e alguns comandos de instalação de dependências e biblioteca.
Outro ponto a acrescentar é que Java é fortemente tipada, e orientada a objetos aumentando ainda mais a complexidade de compreensão e leitura dos códigos, enquanto Python é totalmente interpretada, não precisa de compilação para ser executada o que deixa a programação mais leve, e facilita na compreensão dos códigos, e não é necessário codificar muitas linhas de código. Em contrapartida Python necessidade de indentação para funcionar, e não é indicado com chaves ({ }) o que torna um pouca mais difícil a identificação de erros, caso haja um código-fonte muito extenso, enquanto o Java com suas repartições em camadas de classes, métodos e indicações visuais torne o código mais “bonito”, embora que muito enxuto.
Por último, Java requer uma ampla gama de conhecimento específico para conseguir desenvolver na linguagem, também sofre alterações que mudam a sintaxe das versões mais antigas para versões mais recentes, enquanto Python por ser mais simples não sofre tanto com essas alterações corriqueiras.
5 CONCLUSÃO.
A partir do objetivo proposto conclui-se que foi realizado com sucesso o processo de desenvolvimento de duas API ‘s, e foi descrito as comparações entre elas(Java e Python), a fim de apontar e mensurar características específicas de cada uma.
Foi possível demonstrar que embora Java seja mais rápido em tempo de execução para as tarefas, a complexidade da tecnologia precisa ser colocada na balança ao se pensar em tarefas simples, que por sua vez o tempo de execução não seja importante. Buscar conhecer qual a especialidade da linguagem também torna-se importante, tendo em vista que Python tem atuações melhores em outros ramos da tecnologia, como Big Data e gerenciamento de imagens e Inteligência Artificial.
REFERÊNCIAS BIBLIOGRÁFICAS
ALURA, 10 Linguagens de programação mais usadas pelas empresas. Disponível em: https://www.alura.com.br/empresas/artigos/linguagens-de-programacao-mais-usadas?gclid=CjwKCAjwu_mSBhAYEiwA5BBmf6XZdUm-qMt3- uWQYkYMdgL9bCLvdUCZKf0MJV7I9mJxmbHqyBbKkhoCXBEQAvD_BwE. Acesso em: 18 abr.2022.
BORGES, Thiago da Cunha; GANIMI, Zeus Olenchuck. Extração de Dados com Web Scraping para análise da variação de preço de Veículos Automotores. 2018. 53 p. Trabalho de conclusão de curso (Tecnólogo em Sistemas de Computação) – UNIVERSIDADE FEDERAL FLUMINENSE, Niterói, 2018. Disponível em: <https://app.uff.br/riuff/bitstream/1/8930/1/TCC_THIAGO_DA_CUNHA_BORGES E ZEUS_OLENC HUK_GANIMI.pdf>. Acesso em: 05 out. de 2024.
EXAME, Confira as 5 linguagens mais populares do mundo. Disponível em: https://exame.com/bussola/gosta-de-programacao-confira-as-5-linguagens-mais-populares-do-mundo/. Acesso em: 21 mai.2024.
MARQUES, Ana Isabel Alves. Desenvolvimento de API para aplicação Cloud, 2018. Projeto Mestrado em Engenharia da Informática, Instituto Politécnico de Leiria. Disponível em: https://iconline.ipleiria.pt/bitstream/10400.8/3263/1/2151668_Ana%20Marques_MEICM_Tese.pdf. Acessado em: 05 jun. 2024.
MIRANDA, Fernando. API REST EM JAVA. 2024. Disponível em: https://github.com/Fernando-AMiranda/api-tcc-java. Acesso em: 12 dez. 2024.
MIRANDA, Fernando. API REST EM PYTHON. 2024. Disponível em: https://github.com/Fernando-AMiranda/api-tcc-python. Acesso em: 12 dez. 2024.
ORACLE, O que é um Banco de Dados?, disponível em: https://www.oracle.com/br/database/what-is-database/. Acesso em : 27 nov. 2024.
PRECHELT, Lutz; An Empirical comparison of C, C++, Java, Perl, Python, Rexx, and Tcl for search/string-processing program. Disponível em: https://www.nsl.com/papers/phone/jccpprtTR.pdf, Acessado em: 10 dez. 2024.
RED HAT, API REST. Disponível em: https://www.redhat.com/pt-br/topics/api/what-is-a-rest-api. Acesso em: 18 abr.2022.
¹Fernando Arruda de Miranda, Graduando do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: fadmiranda@uniara.edu.br
²João Henrique Gião Borges, Orientador. Docente do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP.E-mail: jhgborges@uniara.edu.br
³Fabiana Florian, Co Orientadora. Docente do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP.E-mail: fflorian@uniara.edu.br