DATABASE MANAGEMENT: IMPACTS OF IN-MEMORY TECHNOLOGY ON ORGANIZATIONAL DATA MANAGEMENT
REGISTRO DOI: 10.69849/revistaft/fa10202412092308
Priscila Magda Carvalho dos Santos1,
Orientadora: Adriana dos Anjos Duarte Cascaes2
RESUMO
O ambiente organizacional contemporâneo enfrenta constantes mudanças tecnológicas, resultando em um volume crescente de informações que precisam ser gerenciadas e compartilhadas de forma ágil e eficiente. Nesse contexto, a informação se torna estratégica apenas quando é gerenciada adequadamente, transformando-se em conhecimento útil para otimizar processos, melhorar a tomada de decisões e manter a competitividade das empresas. Entretanto, a informação só se torna estratégica e se transforma em conhecimento quando é gerenciada de forma eficaz. Para atender a essa necessidade, os Sistemas de Gerenciamento de Dados (SGD) têm desempenhado um papel essencial, fornecendo mecanismos eficientes para gerenciar grandes volumes de dados e simplificar as tarefas de armazenamento, manutenção e recuperação de informações. Esta pesquisa, embasada em contribuições teóricas da Ciência da Informação e no uso de ferramentas tecnológicas, tem como objetivo analisar e otimizar o processo de controle de contratos de subempreiteiros e locação de equipamentos em uma empresa de construção pesada. O estudo propõe uma análise comparativa de desempenho entre bancos de dados relacionais armazenados em disco e aqueles que utilizam tecnologia inmemory. Para isso, foi desenvolvido um sistema capaz de carregar dados nos bancos de dados selecionados, além de realizar consultas que permitissem avaliar o desempenho em operações de leitura e escrita. A abordagem visa demonstrar como a escolha do modelo de armazenamento pode impactar significativamente a eficiência dos sistemas de gerenciamento de dados e, consequentemente, a capacidade das organizações de lidar com os desafios impostos pelo crescimento exponencial das informações.
Palavras-Chave: Sistema de Gerenciamento de Banco de Dados. Controle de contratos. Modelagem conceitual. Modelo Entidade Relacionamento.
ABSTRACT
It is known that nowadays, with large amounts of information, organizations have felt the need to manage and share this information quickly and efficiently. However, information is only strategic and becomes knowledge when it is managed effectively. By providing effective mechanisms for managing large groups of information, the so-called Data Management Systems fulfill the function of making the task of maintaining and retrieving large amounts of data easier. This research, based on theoretical contributions from Information Science and on frameworks of Information Technology tools, aims to analyze and optimize the process of controlling subcontractor contracts and equipment rental of a heavy construction company. This work aims to conduct a comparative study, based on general aspects of performance, between relational databases on disk and in memory. To this end, a system was used to load data into the chosen databases, as well as queries were performed to analyze the performance of read and write operations in the chosen databases.
Keywords: Database Management System. Contract control. Conceptual modeling. Entity Relationship Model.
1. INTRODUÇÃO
De acordo com (GROBELNIK, 2012), explica que nos dias atuais a Tecnologia da Informação e a sua inserção nos mais variados setores tem promovido uma revolução na forma como as pessoas consomem e produzem dados. Os dados produzidos são provenientes das mais diversas fontes de dados (redes sociais, banco de dados, intranet, smartphones) e possuem diferentes formatos, podendo ser estruturados ou não estruturados.
Para Gartner (2014), o termo Big Data, tem como objetivo caracterizar o aumento expressivo no volume de informações. Apesar de não existir uma definição clara, vários autores têm contribuído para seu entendimento. Pois afirma que o termo é utilizado para descrever extensos volumes de dados que possuem diferentes formatos e que são manipulados em alta velocidade. Enfatiza que o termo Big Data representa grandes volumes de dados que excedem a capacidade de processamento dos sistemas convencionais de banco de dados. Esses extensos volumes de dados, alta velocidade, e dados de diferentes fontes e formatos exigem novas formas de processamento.
O autor HASHEM et al., 2016 menciona a parte que para uma empresa SAS®1 o termo Big Data descreve o imenso volume de dados estruturados e não estruturados que impactam nos negócios e no dia a dia de uma organização. Contudo, não somente em casos envolvendo o mundo dos negócios o Big Data está inserido. Essa definição vem de grande volume de dados e a evolução da Internet das Coisas (IoT, do inglês Internet of Things) passam a desempenhar um papel cada vez mais relevante na viabilidade de diversas iniciativas voltadas, por exemplo, para cidades e ambientes inteligentes. Isto se torna possível a partir da integração de sensores sem fio em ambiente reais utilizando redes de serviços. A combinação do IoT e Big Data representa desafios, mas também oportunidades na oferta de serviços que agreguem valor às organizações e aos usuários. Os desafios se concentram principalmente sobre problemas relacionados a negócios e tecnologias referentes a um ambiente inteligente
A justificativa para esta pesquisa baseia-se no crescimento acelerado da geração de dados, conforme apontado por (GROBELNIK, 2012), o aumento crescente dos dados se deve aos avanços nas tecnologias da informação e comunicação, no que tange a capacidade de processamento, armazenamento e transmissão de informações apresentam novos desafios a serem enfrentados.
Pois o principal cenário, a área de Big Data vem se consolidando como a base para o desenvolvimento de novas tecnologias capazes de manipular grandes conjuntos de dados visando promover subsídios para a tomada de decisão. A área de Big Data tem atraído a atenção da academia, indústria e governos ao redor do mundo
O autor Hashem et al. (2016) explicou que poder computacional dos processadores ter crescido nas últimas décadas, conforme a perspectiva da lei de Moore, o desempenho dos sistemas de armazenamento não foi capaz de acompanhar tal evolução. Onde a principal base nessa discrepância e nos pontos principais do conceito de Big Data, acredita-se que as aplicações que lidam com esta perspectiva necessitam de uma infraestrutura capaz de ser escalável e paralela. Para ter um bom entendimento que o modelo de programação para o processamento de grandes conjuntos de dados com algoritmos paralelos pode ser usado para análise de dados e para obtenção de valor sobre os dados armazenados.
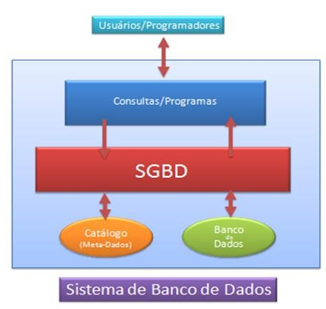
Em suma (PLATTNER, ZEIER, 2011),definem que a busca de informações em meio a grandes quantidades de dados é difícil de ser realizada nos Sistemas de Gerenciamento de Banco de Dados Sistema de Gerenciamento de Banco de Dados (SGBD) atuais devido às entradas e saídas de dados no disco rígido dos servidores e à demora no acesso entre o dispositivo de armazenamento e o servidor de aplicação. Onde o principal objetivo e facilitar a busca de informações considerando extensos volumes de dados surge a tecnologia in-memory, permitindo carregar e executar todos os dados na memória, reduzindo o tempo de recuperação por determinada informação. De maneira geral, o investimento nesta tecnologia vem se tornando viável com a queda do custo das memórias de computador e passa a ser uma alternativa capaz de lidar adequadamente com o crescente volume dos dados.
2. REFERENCIAL TEÓRICO
2.1 Introdução à Banco de Dados
De acordo com (WADE; CHAMBERLIN, 2012), explica que ao fazer o uso de um cartão de crédito ou gerar uma transação online de qualquer tipo, como uma compra em um webshop ou até mesmo o simples fato de acessar determinado site, ocorre o registro de dados relevantes que podem ser analisados para diversas finalidades.
GRAD; BERGIN, 2009destacou que como qualquer tecnologia, com o passar dos anos ela foi evoluindo e hoje existem diversos modelos em uso.
Exemplos como:
Relacional: o modelo de banco de dados relacional é uma coleção de múltiplos conjuntos de dados organizados em tabelas (linhas/colunas), possuindo uma relação bem definida entre as mesmas.
Em memória: segundo o autor (MOLKA; CASALE, 2015) ressalva a parte que o modelo de banco de dados em memória é um sistema de gerenciamento de banco de dados que, ao contrário dos modelos convencionais que utilizam a memória secundária do sistema, estes utilizam a memória principal para armazenar os dados. Sendo assim, esse tipo de modelo é usado principalmente em aplicações onde o tempo de resposta é um fator crucial.
Orientado a Documentos: No modelo de banco de dados orientado a documento, as informações são armazenadas no formato chave-valor em arquivos JSON, ou similares.
Orientado a Objetos: (KIM, 1990) menciona que este modelo é um sistema de gerenciamento de banco de dados que suporta a modelagem e criação de dados como objetos. Estes podem ser referenciados de maneira similar ao que acontece com objetos usados na programação orientada a objetos.
Essa parte destaca a relevância das tecnologias de bancos de dados relacionais e bancos de dados em memória, que são o foco principal deste trabalho.
2.2 Banco de Dados Relacional
Segundo Wade e Chamberlin (2012),explica que a história do surgimento dos Sistemas de Gerenciamento de Banco de Dados Relacionais Sistema de Gerenciamento de Banco de Dados (SGBD) onde pode ser considera a parte que uma das mais bem-sucedidas e com impacto mais direto na vida das pessoas. E isso só aconteceu graças ao trabalho de Edgar Frank Codd no começo dos anos 70, quando passou a fazer parte do Laboratório de Pesquisas da IBM® em San José.
Para (DARWEN, 2012) ressalva que este modelo fornecia alguns programas utilitários de uso geral, escritos na linguagem própria do TBS, para manutenção e geração de relatórios. O utilitário de manutenção permitia por parte dos usuários a adição, alteração e exclusão de registros de arquivos. Pois haverá uma geração de relatórios, como o nome já diz, permitia a geração de relatório a partir de determinado arquivo com a opção de escolha de registros a serem apresentados, e cálculos a serem feitos como totais e subtotais e outros itens.
Os autores WADE; CHAMBERLIN, 2012 destacam que no início dos anos 1970, enquanto Codd trabalhava no laboratório de pesquisas da IBM® em San Jose, ele escreveu um artigo que propunha um novo foco para o modo como a informação era armazenada em computadores chamado de “A Relational Model of Data for Large Shared Databanks”, o qual foi batizado de “Modelo de Dados Relacional”, por ter sido baseado na teoria matemática das relações, onde alguns profissionais descrevem as chamadas “Formas Normais”, que teriam como objetivo eliminar a redundância e evitar inconsistência no conteúdo armazenado no banco de dados.
Desse modo (CHAMBERLIN, 2012) enfatizou que através da implementação dessa ideia, acabou tornando-se possível um aumento de produtividade dos programadores, pois ao abstrair algumas estruturas físicas de dados, como índices de conteúdo, a criação de ponteiros e outras estruturas necessários, para que no futuro venha ter um obtenção de um melhor desempenho, o programador passava então a necessitar de um modelo de dados composto de valores em tabelas.
2.3 Transações em banco de dados
De acordo com (SUMATHI; ESAKKIRAJAN, 2007), explica que o gerenciamento de dados tem um papel crítico em qualquer organização. Através da utilização de um Sistema de Gerenciamento de Banco de Dados (SGBD) é possível obter um ambiente propício para o armazenamento e recuperação de dados de uma maneira eficiente e econômica
Conforme descreve (SILBERSCHATZ et al., 2006), ressalva que vai de extrema necessidade um Sistema de Gerenciamento de Banco de Dados (SGBD) garanta a execução de maneira adequada de determinada transação, ou seja, ela deve ser efetuada de maneira completa ou caso aconteça algum problema, nenhuma parte dela deve ser aceita
- Normalização
HEUSER, 2009, destaca que a normalização é o processo de reorganização de dados que tem como objetivo a eliminação de redundâncias que possam existir e, fazer com que os dados que tenham relação sejam armazenados em conjunto. Esse processo é realizado através das chamadas formas normais, que podem ser divididas em diversos casos, sendo a primeira, segunda e terceira formas normais as principais.
- Primeira Forma Normal (1FN):
Para que se atinja esta forma normal deve-se garantir que todos os domínios básicos contenham somente valores atômicos (não pode haver grupos repetidos), tão pouco deve existir tabelas aninhadas. O processo objetiva criar uma nova relação interligada por uma chave primária (campo único e responsável por identificar a tabela) e estrangeira (referência a uma chave primária de outra tabela). Desta forma, as tabela1 são o resultado da aplicação da 1FN, na tabela não normalizada. Como pode ser observado na tabela de relacionamento entre Projeto e Empregado (Tabela 3) esta possui uma ligação com a tabela de projetos
Figura1: Resultado da aplicação da 1FN
| CodProj | Tipo | ‘Descrição |
| LSC001 | Novo desenv | Sistema de Estoque |
Fonte: HEUSER, 2009
- Segunda Forma Normal (2FN):
Além da tabela se encontrar na primeira forma, é preciso garantir que não existam dependências parciais, ou seja, cada coluna não chave depender de parte da chave primária. Caso existam valores repetidos para vários registros, os mesmos devem ser transferidos para uma nova tabela, sendo vinculados por uma chave estrangeira.
- Terceira Forma Normal (3FN)
O autor Hauser (2009), explica que o processo de transformação de 2FN para 3FN indica que todas as colunas dependentes indiretamente da chave primária da tabela devam ser movidas para uma nova tabela ou removidas.
2.4 Banco de Dados em Memória
O autor Wang et al. (2015) explicou que a capacidade das memórias RAM (Random Access Memory) vem aumentando consideravelmente enquanto que o preço vem decaindo. Tal fato possibilita armazenar completamente bancos de dados cada vez maiores na memória principal do sistema. Desta forma, o conceito de banco de dados em memória se torna cada vez mais real e uma tendência. Afirmações similares podem ser encontradas no início da década de 90 através do trabalho de Molina.
Como salienta Wang, Zhong e Kun (2015), observou a parte onde as principias característica que diferencia os bancos em memória dos convencionais é a falta de operações de “Entrada e Saída” (E/S), objetivando a eliminação desse possível gargalo. Pois, em um sistema baseado em disco onde a informação é acessada através de um leitor que é movimentado por um braço mecânico, não é possível garantir o desempenho necessário para operações mais complexas. Os profissionais explicam que, ao armazenar informações diretamente na memória principal e eliminar as operações de entrada e saída (E/S), a velocidade de leitura e escrita é consideravelmente aprimorada.
Figura2: “Entrada e Saída” (E/S)
Fonte: Wang, Zhong e Kun (2015)
Com base nessa lista é possível criar uma divisão entre os bancos e seus diferentes focos:
- Foco comercial
Como destaca (ORACLE, 2016),onde explica que Times Ten: é um sistema de banco de dados em memória, proprietário da Oracle®, baseado no modelo relacional. Suas principais características são: suporte as propriedades Atomicidade, Consistência, Isolamento e Durabilidade (ACID) e um tempo de resposta quase instantâneo necessário para aplicações em tempo real, como aplicações de telecomunicações
- Foco em sistemas embarcados
SQLite: é um sistema em memória que tem como foco, dispositivos que contam com poucos recursos de espaço e memória, como por exemplo, smartphones. Foi desenvolvido por Dwayne Richard Hipp e tem como principais características ser um projeto open source (código aberto) e a não necessidade de um servidor fora do aparelho que o utiliza Berkeley DB: é um sistema baseado no conceito de chave-valor, desenvolvido pela Oracle®. Uma das características é a possibilidade de uso de uma Application Programming Interface (API) baseado no conceito chave-valor ao invés da linguagem SQL para o armazenamento de dados
- Foco em novas tecnologias
Como destaca (MONGODB, 2016), onde explica que um sistema baseado no conceito de (NoSQL), desenvolvido pela empresa de publicidade DoubleClick®. O modelo utilizado é o de orientação a documentos. É um projeto open source e utiliza a linguagem própria para realizar as operações de manutenção e consulta de dados ao invés da SQL VOLTDB, 2016 define a parte onde um sistema baseado no conceito de NewSQL, desenvolvido por Mike Stonebraker com suporte as propriedades ACID. VoltDB é um projeto open source e tem o foco voltado a aplicações que necessitam de um baixo tempo de resposta entre transações, como por exemplo, aplicações financeiras e de telecomunicações
3. METODOLOGIA
O tipo de pesquisa realizada neste estudo foi uma revisão literária, na qual foram consultados livros, dissertações e artigos científicos selecionados por meio de busca nas seguintes bases de dados: Google Acadêmico, Google Livros, além de artigos acadêmicos e livros especializados. A pesquisa abrangeu trabalhos publicados nos últimos cinco anos. As palavras-chave utilizadas na busca incluíram: banco de dados, banco de dados relacional, SGBD, MySQL e modelo relacional.
4. CONCLUSÃO
A conclusão deste estudo evidencia que o objetivo principal foi realizar uma análise comparativa entre as abordagens de Banco de Dados Relacional Tradicional (em disco) e o modelo Relacional em Memória, com foco no desempenho em relação à população e consulta de dados.
A pesquisa foi conduzida utilizando a base de dados do serviço de recomendação de filmes MovieLens®, que contém informações extraídas da Base de Dados de Filmes na Internet (IMDb). Para simular um cenário real, foi realizada uma avaliação de desempenho, permitindo a comparação entre os dois modelos de banco de dados.
Os resultados indicaram que, alguns modelos de conceito de armazenamento em disco apresentou um desempenho similar em comparação ao modelo baseado em memória quando a carga de dados contida no banco não tinha um tamanho expressivo. No entanto, essa similaridade deve-se ao método empregado para popular o banco de dados em memória, no qual os dados foram carregados a partir das estruturas já existentes em disco. Esse processo limitou a velocidade de população do banco em memória, uma vez que foi influenciado pela velocidade de leitura do disco.
De modo geral, pode-se concluir que o modelo orientado a memória apresenta desempenho similar ao modelo tradicional quando a carga de dados é pequena. Entretanto, à medida que aumenta a quantidade de entradas na base, o banco em memória começa a se distanciar da modelo tradicional, devido às limitações do disco e, por conseguir manter os dados no mesmo local (memória) onde são realizadas todas as operações, tanto de escrita quanto de leitura. Este fator diminui consideravelmente o tempo de busca de dados para execução de consultas.
Portanto, é importante destacar que existem diversas possibilidades de expansão para a análise apresentada neste trabalho. Uma direção interessante seria comparar as abordagens tradicionais e em memória com novas tecnologias, como o NewSQL, que combina alta disponibilidade e escalabilidade com requisitos transacionais e consistência dos dados. Essa comparação poderia abrir novas perspectivas para a evolução das tecnologias de bancos de dados.
REFERÊNCIAS
AQUINO, Amanda CV et al. Uma análise comparativa de sistemas de gerenciamento de bancos de dados NoSQL multimodelo. 2019.
CARVALHO, Herbson de et al. Um modelo de dados voltado ao serviço de inteligência policial. 2017.
COSTA, Felipe de Souza da et al. Uma Ferramenta para Extração de Esquemas de Bancos de Dados NoSQL Orientados a Documentos. 2017.
DA MOTTA GASPAR, João Alberto; RUSCHEL, Regina Coeli. A evolução do significado atribuído ao acrônimo BIM: Uma perspectiva no tempo. In: SIGraDi 2017, XXI Congreso de la Sociedad Iberoamericana de Gráfica Digital. 2017. p. 8.
HEUSER, Carlos Alberto. Projeto de banco de dados: Volume 4 da Série Livros didáticos informática UFRGS. Bookman Editora, 2009.
LOPES, Jeiel Miguel et al. Um estudo comparativo entre bancos de dados considerando as abordagens relacional e orientada ao grafo. 2014.
MAIA, Ana Cecília Lima; STEIN, Peolla Paula; AZEVEDO FILHO, Mário Angelo Nunes de. Escolha modal em campus universitário: revisão sistemática da literatura em bancos de dados internacionais.
OLIVEIRA NETO, José Dutra; RICCIO, Edson Luiz. Desenvolvimento de um instrumento para mensurar a satisfação do usuário de sistemas de informações. Revista de Administração, São Paulo, v. 38, n. 3, p. 230-241, 2003.
PALETTA, Francisco Carlos; DIAS, Daniel. Gestão electrônica de documentos e conteúdo. Prisma. com, n. 25, p. 126-152, 2014.
PINTO, Guilherme Lucon et al. Um estudo comparativo entre banco de dados relacional em disco e em memória. 2017.
SILVA NETO, Arlindo Rodrigues da. GoldBI: uma solução de Business Intelligence como serviço. 2016. Dissertação de Mestrado. Brasil.
SOUZA, Beatriz Soares de. Aplicação da teoria dos grafos na análise de similaridade e complexidade de consultas em bancos de dados relacionais. 2024. Dissertação de Mestrado. Universidade Federal do Rio Grande do Norte
TANAKA, Luis Carlos; CAMARGO, Felipe Melo; GOTARDO, Reginaldo Aparecido. Sistema gerenciador de banco de dados: Sistema de Gerenciamento de Banco de Dados (SGBD) exist xml. Revista Eletronica de sistemas de informaçao e Gestao Tecnologica, v. 2, n. 1, 2012.
WEBER, Érico Rosiski. Aplicação móvel e Web service para monitoramento e armazenamento dos dados de produção de energia eólica de um pequeno gerador. 2022.
1Estudante da Instituição – FUCAPI,
2Esp. – FUCAPI