USING PREDICTION MODELS TO IMPROVE HIGH TURNOVER INVENTORY PLANNING – A STUDY IN A COMPANY IN THE BEVERAGE SECTOR
REGISTRO DOI: 10.69849/revistaft/ni10202411240801
Gabriel Martine Brandão1;
Felipe Diniz Dallilo2;
Fabiana Florian3
Resumo
Este projeto desenvolve um modelo de predição para o planejamento de estoque de produtos de alta rotatividade, especificamente chopp, em uma empresa do setor de bebidas. Utilizando técnicas de redes neurais e séries temporais, o objetivo é minimizar desperdícios e garantir a disponibilidade de produtos, considerando a validade curta do chopp e a necessidade de pedidos antecipados. A pesquisa envolveu a coleta de dados de vendas de anos anteriores, tratamento dos dados, e o desenvolvimento de uma interface amigável para o usuário. O modelo foi treinado com algoritmos de machine learning, para prever as vendas semanais. Os resultados mostram que o modelo é eficaz em prever padrões de vendas, permitindo ajustes e integrações futuras, como a inclusão de dados climáticos e demográficos. Este trabalho oferece uma base sólida para a otimização do gerenciamento de estoque e a formulação de estratégias comerciais mais eficientes.
Palavras-chave: Machine Learning, Análise de dados, Redes neurais
Abstract
This project develops a prediction model for inventory planning of high-turnover products, specifically draft beer, in a company in the beverage sector. Using neural network and time series techniques, the aim is to minimize waste and guarantee product availability, taking into account the short shelf life of draft beer and the need for advance orders. The research involved collecting sales data from previous years, processing the data and developing a user-friendly interface. The model was trained with machine learning algorithms to predict weekly sales. The results show that the model is effective at predicting sales patterns, allowing for adjustments and future integrations, such as the inclusion of climate and demographic data. This work provides a solid basis for optimizing inventory management and formulating more efficient commercial strategies.
Keywords: Machine Learning, Data analysis, Neural networks
1 INTRODUÇÃO
Modelos de predição são funções matemáticas que podem prever o futuro com eficiência usando dados matemáticos, estatísticos que podem ser otimizadas através de redes neurais.
Segundo EJFGV (2023), eles são uma maneira de buscar padrões através de uma grande quantidade de dados para identificar padrões e tendências, calculando resultados e soluções que reforcem a segurança e otimizem o sistema de dados. E, a partir dos resultados obtidos por essas análises, a empresa consegue tomar decisões baseadas nessas futuras probabilidades.
As Redes Neurais Artificiais (RNA) são baseadas em uma visão abstrata do próprio cérebro humano. Tentando replicar características desejáveis dele que não estão presentes em máquinas de Von Neumann, como processamento de informação contextual inerente, habilidade de aprendizado, habilidade de generalização e adaptabilidade.
O uso de redes neurais e séries temporais para modelos de predições tem como objetivo aumentar a porcentagem de acerto de previsões e diminuir a dificuldade de fazê-las. A modelagem de séries temporais com deep learning (redes neurais) é uma área em constante evolução. (Filho, 2023)
O software pode ajudar em um ambiente empresarial num melhor planejamento do estoque e evitar desperdícios no caso de produtos com um curto prazo de validade.
Este trabalho tem o objetivo de desenvolver um modelo de predição de planejamento de estoque de produtos de alta rotação baseado em dados de venda de anos anteriores no setor de dep. de bebidas localizada no interior do estado de São Paulo. Que funcionará através de um aplicativo de fácil acesso e entendimento para o usuário, baseado no uso de redes neurais e séries temporais para realizar as predições.
No depósito de bebidas da empresa há um grande volume de chopp. Como o produto não é pasteurizado, ele possui um curto prazo de validade, aproximadamente 10 dias. No entanto, os pedidos devem ser feitos com pelo menos duas semanas de antecedência. Isso cria um problema em que o mau planejamento do estoque pode resultar em desperdício do produto ou na falta dele em determinados dias, ambos causando problemas para a empresa.
A hipótese dessa pesquisa é que se espera que com o uso do modelo de predição, reduzam erros e o estoque sempre tenha uma quantidade adequada de produtos. Evitando assim qualquer tipo de problemas, para a empresa.
A predição de série temporal consiste em desenvolver modelos que se adequam aos seus dados históricos e usá-los para predizer as observações futuras (BROWNLEE, 2020). Segundo Hyndman e Athanasopoulos (2013) construção do modelo depende também de um devido conhecimento na área a se tratar e do problema a resolver, uma coleta de informações com base suficiente, realização de análise exploratória dos dados previamente, treinamento do modelo e avaliação de desempenho.
Foram realizadas pesquisas bibliográficas, qualitativas, documentais, assim como, uma pesquisa em uma época no setor de bebidas.
Os dados foram disponibilizados através de planilhas da base de dados das lojas estudadas. A inserção das planilhas e o resultado funcionará através de uma interface criada usando tkinter, um pacote próprio para desenvolvimento de interfaces Python. Depois serão analisados e modulados usando a biblioteca de código aberto, pandas. Após o tratamento dos dados passará pelo algoritmo criado em Python 3.12, assim mostrando os possíveis resultados na tela.
2 REVISÃO BIBLIOGRÁFICA
Nesta seção, serão abordados alguns conceitos fundamentais para o entendimento da tecnologia de tipos de redes neurais para séries temporais como redes neurais recorrentes e convolucionais, além de aprofundar em ideais do sistema e as ferramentas que foram utilizadas ao longo do trabalho.
2.1 TIPOS DE REDES NEURAIS PARA SÉRIES TEMPORAIS
Uma Rede Neural Recorrente (RNN) é um modelo de aprendizado profundo treinado para processar e converter uma entrada de dados sequencial em uma saída de dados sequencial específica. Dados sequenciais são dados, como palavras, frases ou dados de séries temporais, em que componentes sequenciais se inter-relacionam com base em regras complexas de semântica e sintaxe. Uma RNN é um sistema de software que consiste em muitos componentes interconectados que imitam a forma como os humanos realizam conversões sequenciais de dados, como a tradução de texto de um idioma para outro. (AMAZON, 2024)
Redes Neurais Convolucionais (CNN) são redes neurais pensadas para processar dados com alguma estrutura espacial. Os exemplos mais famosos estão na área de visão computacional, onde as imagens são representadas como matrizes e as redes neurais convolucionais são usadas para extrair características relevantes para prever um alvo. As convoluções são como filtros que são aplicados sobre os dados. A diferença entre aplicar uma rede convolucional ou um filtro pré-definido é que a rede aprende os filtros mais relevantes para os dados apresentados. (Filho, 2023)
2.2 IDEALIZAÇÃO DO NOVO SISTEMA
O novo sistema idealizado, tem como base modelos de previsões através de séries temporais. Essas séries temporais serão de baseadas em previsões quantitativas.
Previsão quantitativa pode ser aplicada quando duas condições são satisfeitas:
– Informações numéricas sobre o passado estão disponíveis;
– É razoável assumir que alguns aspectos dos padrões passados continuarão no futuro.
Existe uma ampla gama de métodos de previsão quantitativa, frequentemente desenvolvidos dentro de disciplinas específicas para propósitos específicos. Cada método possui suas próprias propriedades, precisões e custos que devem ser considerados ao escolher um método específico. (Hyndman, R. J.; Athanasopoulos, G., 2013)
Com base em dados obtidos por relatórios de vendas de anos anteriores das lojas. O sistema deve analisá-los e fornecer uma previsão para realizar o pedido da loja. Inicialmente essa previsão vai ser analisada para ver se está dentro dos conformes, caso não esteja, será realizada uma nova consulta com a entrada de possíveis novas variáveis não existentes antes.
2.3 FERRAMENTAS UTILIZADAS
Algumas das principais ferramentas utilizadas para o desenvolvimento deste trabalho foram: Python 3, NumPy, Pandas, TensorFlow, Tkinter.
A escolha da linguagem de programação principal foi Python 3, pois ela é uma linguagem de código aberto com sintaxe clara, vasta quantidade de bibliotecas especializadas e frameworks para trabalhar com modelos de inteligência artificial, além de possuir uma comunidade ativa que oferece suporte constante e documentação total.
O Pandas é uma biblioteca do Python que fornece estruturas de dados rápidas, flexíveis e expressivas, concebidas para tornar o trabalho com dados “relacionais” ou “rotulados” fácil e intuitivo. O seu objetivo é ser o bloco de construção fundamental de alto nível para fazer análises de dados práticas e reais em Python. Além de ser uma ferramenta de análise/manipulação de dados de código aberto. Já está no bom caminho para atingir este objetivo. (NumFocus, 2024)
TensorFlow, segundo Google (2015), é uma biblioteca de código aberto para aprendizado de máquina aplicável a uma ampla variedade de tarefas. É um sistema para criação e treinamento de redes neurais para detectar e decifrar padrões e correlações, análogo à forma como humanos aprendem e raciocinam.
NumPy é uma biblioteca Python de código aberto que é amplamente utilizada em ciência e engenharia. A biblioteca NumPy contém estruturas de dados de matrizes multidimensionais, como a matriz homogénea, N-dimensional e uma grande biblioteca de funções que operam eficientemente nestas estruturas de dados. (NumPy, 2024)
O Scikit-learn é uma biblioteca de aprendizagem automática de código aberto que suporta a aprendizagem supervisionada e não supervisionada. Também fornece várias ferramentas para ajuste de modelos, pré-processamento de dados, seleção de modelos, avaliação de modelos e muitos outros utilitários. (Scikit-learn developers, 2024)
A interface foi desenvolvida o Tkinter, pois é a interface padrão do Python e faz parte do kit de ferramentas Tcl/Tk GUI. Tcl/Tk não é uma biblioteca única, mas consiste em alguns módulos distintos, cada um com sua própria funcionalidade e sua própria documentação oficial.
2.4 RESULTADOS ESPERADOS
O sistema deve ser capaz de prever numa faixa de valores a quantidade que deverá ser pedida a cada semana e isso será acompanhado pelos dados reais para adicionar mais dados de resultados para melhorar sua precisão.
Quando obtemos uma previsão, estamos estimando o meio da faixa de valores possíveis que a variável aleatória poderia assumir. Frequentemente, uma previsão é acompanhada por um intervalo de previsão que fornece uma faixa de valores que a variável aleatória poderia assumir com uma probabilidade relativamente alta. (Hyndman, R. J.; Athanasopoulos, G., 2013)
O sistema também contará com a recepção de dados de uma API de clima que ajudará a melhorar os resultados, com condições climáticas que tem alta influência nas vendas e é um dado incerto, pois segundo Hyndman e Athanasopoulos (2013) uma organização precisa desenvolver um sistema de previsão que envolve várias abordagens para prever eventos incertos.
3 DESENVOLVIMENTO
Para iniciar o desenvolvimento do modelo de predição foram captados os dados das lojas localizadas no interior do estado de São Paulo, e foi realizado uma entrevista com o dono dos estabelecimentos para analisar como são feitas e o que é considerado quando ele realiza pedidos para o fornecedor.
3.1 CONTEXTO E PROCESSO ATUAL
Uma franquia de depósito de bebidas especializada em chopp, realiza pedidos com ao menos quinze dias de antecedência, porém o produto em si tem uma validade de aproximadamente dez dias. Então o acúmulo de produtos na loja pode causar grande prejuízo a empresa que tem que descartar os produtos vencidos e a falta deles gera insatisfação do consumidor.
Atualmente, o responsável pela previsão é o próprio dono do estabelecimento, que leva em conta experiência no mercado e dados de vendas de suas lojas anteriormente, sem uso de nenhum tipo de sistema para isso. No caso da ausência dele, previsões normalmente tendem a ser mais errôneas, e como isso deve ser feito em mais de uma loja fica difícil somente para uma pessoa realizar o trabalho.
3.2 TRATAMENTO DOS DADOS
Os dados brutos que foram disponibilizados eram de todas as vendas realizadas, primeiramente foram retiradas colunas que poderia haver dados sobre clientes, para a segurança e porque eles não têm relevância para a pesquisa. Após a seleção, os produtos com maior rotação foram escolhidos para os testes iniciais do projeto, por serem considerados os mais relevantes. Focar em produtos muito procurados ajuda a desenvolver modelos preditivos mais fortes, já que essas categorias têm dados abundantes e variações mais evidentes com o passar do tempo. Essa decisão é fundamental, uma vez que séries temporais precisam de uma quantidade significativa de dados antigos para identificar padrões importantes. A figura 1 abaixo representa como os dados foram disponibilizados para a pesquisa.
Figura 1 – Exemplo dos dados a serem analisados
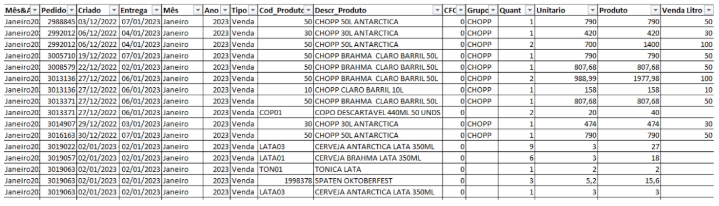
Uma parte fundamental do processo de desenvolvimento foi a manipulação dos dados de vendas para transformá-los em totais semanais. De acordo com Nascimento a limpeza e gestão dos dados para se trabalhar com eles de maneira mais efetiva tem uma import6ancia crucial nos resultados alcançados. A importância da frequência semanal está em sua coincidência com o momento habitual em que a empresa solicita reposições de estoque.
Adicionalmente, foram levados em conta fatores externos, como feriados e datas festivas, já que tais ocasiões influenciam diretamente as decisões de compra dos clientes. Essa mudança é essencial para criar uma série temporal robusta, que consiste em observações organizadas em ordem cronológica para permitir a análise de padrões e tendências ao longo do tempo, conforme descrito por Morrentin.
3.2 DESENVOLVIMENTO DA INTERFACE
Durante o desenvolvimento da interface, foi feito uma simples tela para inserir um arquivo compatível que seriam os formatos XLSX (.xlsx) e XLS (.xls). Como mostra a figura 2 abaixo. Essas extensões foram escolhidas pois são compatíveis com a base de dados que a própria loja tem sobre os pedidos. E a validação acontece para evitar envio de outras extensões que podem vir a causar erros do sistema.
Figura 2 – Validação de formatos do arquivo
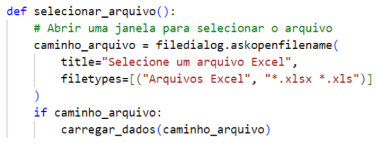
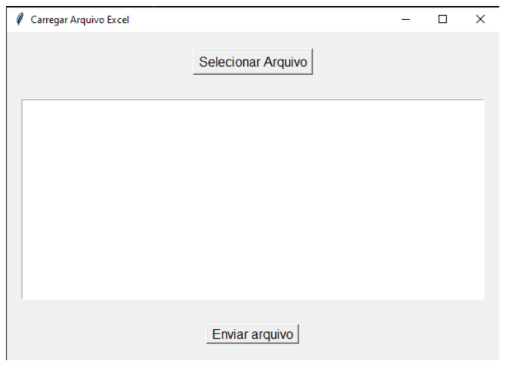
Os componentes dessa tela é o botão para selecionar o arquivo citado acima, um visualizador que fornece uma prévia do arquivo assim que ele for selecionado para fazer a conferência de que o arquivo escolhido é o correto a se inserir. Além de um botão de enviar o arquivo. Segue na figura 3 abaixo a visualização da tela.
Figura 3 – Tela inicial para enviar arquivos
3.3 DESENVOLVIMENTO DO MODELO DE PREDIÇÃO
A previsão ocorre através do uso de algoritmos de machine learning designados para séries temporais. Dentre as técnicas mais populares, inclui-se a utilização de modelos ARIMA (AutoRegressive Integrated Moving Average), os quais são eficazes em identificar correlações entre as variáveis ao longo do tempo, ou redes neurais de memória de longo curto prazo (LSTM), que possuem a habilidade de lidar com relações temporais extensas. Estas estratégias são desenvolvidas com base nos registros de vendas passados e adaptadas à medida que novos dados são incluídos no sistema, com o objetivo de aprimorar constantemente as previsões.
A elaboração do modelo inicia com a etapa de pré-processamento dos dados. A etapa inicial consistiu em converter a coluna Entrega em dados relevantes para o modelo. Com o objetivo de alcançar esse resultado, a data foi transformada em características importantes, como o dia da semana e a semana do ano, possibilitando assim que o modelo identificasse tendências temporais nos dados. Depois disso, a coluna Descr_Produto, que inclui informações sobre os produtos, foi transformada em variáveis binárias através do OneHotEncoder, que é uma ferramenta do Scikit-learn capaz de codificar caraterísticas categóricas como uma matriz numérica de um ponto. Essa codificação ajuda o modelo a compreender de forma mais eficaz as diferentes categorias de produtos, o que simplifica a aprendizagem dos padrões relacionados a cada uma delas. A transformações desses dados estão representados na figura 4 abaixo.
Figura 4 – Preparação dos dados recebidos
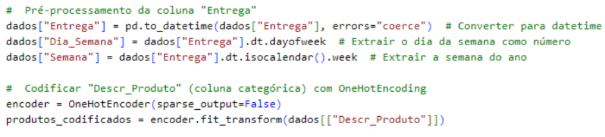
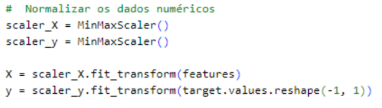
Depois da etapa de pré-processamento, os dados foram normalizados. O MinMaxScaler, que também é uma ferramenta do Scikit-learn, foi empregado para normalizar as entradas e saídas do modelo, alterando o valor de todas as variáveis para ficarem dentro da faixa de 0 a 1, como retratado na figura 5 abaixo. Normalizar é crucial para aprimorar o desempenho do modelo, possibilitando uma aprendizagem mais eficiente e estável, principalmente em redes neurais.
Figura 5 – Normalização dos dados
Com todos os dados preparados, o próximo passo foi desenvolver o modelo de rede neural. O padrão foi formado por três camadas compactas. A camada de entrada, composta por 128 neurônios, tem a função de analisar os dados iniciais do conjunto. Foi incluída uma camada intermediária de 64 neurônios para auxiliar no aprendizado de padrões mais complexos, enquanto a camada de saída, com 1 neurônio, foi configurada para gerar a previsão do valor desejado. A construção do modelo foi retratada na figura 6 abaixo. A estrutura básica da rede é adequada para este tipo de trabalho de prever valores contínuos.
Figura 6 – Construção do modelo

O treinamento do modelo foi realizado por 50 épocas, empregando um conjunto de dados de treinamento e outro de validação. Monitorar o desempenho do modelo durante o treinamento é essencial, pois a validação ajuda a prevenir o sobreajuste e assegura a capacidade de generalização para novos dados. Enquanto era treinado, o modelo fez ajustes em seus parâmetros para reduzir a perda, utilizando as informações disponíveis.
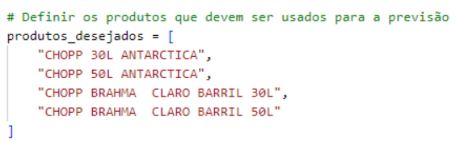
Com o modelo treinado foi feito um filtro para os produtos desejados que no caso é o chopp que deve ser feito a contagem da venda por litro. Os produtos desejados estão apresentados na figura 7 abaixo.
Figura 6 – Produtos desejados
Por fim, o desempenho do modelo foi verificado por meio de sua métrica de erro absoluta, que é uma medida de avaliação calculada a partir da média dos erros absolutos entre os valores reais e os valores previstos. Com base na avaliação realizada, o modelo conseguiu fazer previsões para o conjunto de teste. Estas previsões apontam os valores estimados para as variáveis-alvo e podem ser utilizadas para realizar previsões em novos dados em cenários da vida real. Então os resultados obtidos serão salvos num arquivo Excel para facilitar a visualização das informações.
4 RESULTADOS
Neste capítulo serão mostrados os resultados da execução do modelo de predição. Com a execução do programa é inserido o arquivo com venda de anos anteriores como mostra a figura 7 abaixo.
Figura 7 – Execução do programa
E assim que o arquivo é enviado ele passa pelo processo descrito anteriormente, passando pelo treinamento e gerando um arquivo Excel contendo os valores das predições. A figura 8 abaixo demonstra as últimas épocas do treinamento e a confirmação que o arquivo foi gerado com sucesso.
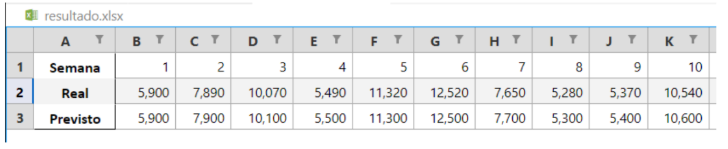
Figura 9 – Tabela de resultados

O arquivo de resultados é separado em 3 colunas, a primeira é a coluna Semana que simplesmente representa o número da semana no ano. A segunda coluna é a Real que foi preenchida com os valores reais de Venda Litro para os produtos que correspondem aos critérios selecionados. Esses valores representam o total de litros vendidos em cada semana para os produtos de interesse, que foram filtrados com base nas descrições dos produtos. E a terceira coluna é a coluna de Previsto que foi preenchida com as previsões geradas pelo modelo de rede neural treinado. O modelo foi alimentado com dados históricos das semanas de anos anteriores, levando em consideração características como a data de entrega e o tipo de produto. O modelo então gerou previsões para a quantidade total para a venda da semana com base nos padrões aprendidos durante o treinamento. Na figura 9 abaixo está um exemplo da tabela gerada até a semana 10, porém seus dados foram transpostos para facilitar a visualização no formato do trabalho.
Figura 9 – Tabela de resultados
5 CONCLUSÃO
Os resultados alcançados mostraram que o modelo é eficaz em prever padrões de vendas semanais utilizando informações passadas. A execução possibilita a verificação de diferenças entre os valores efetivos e estimados, oferecendo uma fundação robusta para modificações posteriores. Além do mais, é possível ajustar a estrutura criada para incorporar elementos adicionais, como sazonalidade e promoções, de forma a melhorar a precisão das previsões.
Como trabalho futuro, é aconselhável considerar a utilização de dados suplementares, como dados demográficos ou informações de mercado, para aprimorar ainda mais a capacidade de previsão do modelo. Em resumo, o modelo criado oferece uma abordagem sólida para examinar vendas e pode ser incorporado à tomada de decisões, ajudando a administrar estoques e definir estratégias comerciais.
REFERÊNCIAS BIBLIOGRÁFICAS
BROWNLEE, J. Introduction to Time Series Forecasting with Python: How to Prepare Data and Develop Models to Predict the Future. v1.9 ed. 2020.
HYNDMAN, R. J.; ATHANASOPOULOS, G. Forecasting: Principles and Practice v3, Austrália: OTexts, 2021. Disponível em: < https://otexts.com/fpp3/ > Acesso em: 20 abr.2024
EJFGV, Modelo de predição: o que é e para que serve?, 2023. Disponível em: < https://ejfgv.com/modelo-de-predicao/ >. Acesso em: 30 mai.2024
MORRENTIN, P. A.; TOLOI, C. M. C. Análise de séries temporais –Modelos multivariados e não lineares. São Paulo, Editora Blucher, 1981
FILHO, M Como Prever Séries Temporais Com Redes Neurais em Python, 2023 Disponível em: <https://mariofilho.com/como-prever-series-temporais-com-redes-neurais-em-python/ > Acesso em: 30 mai.2024
NUMFOCUS INC. Pandas Documentation. 2024. Disponível em< https://pandas.pydata.org/docs/getting_started/overview.html >. Acesso em: 31 out. 2024.
AMAZON. O que é RNN (Rede neural recorrente)? Disponível em: < https://aws.amazon.com/pt/what-is/recurrent-neural-network/ >. Acesso em: 01 nov. 2024.
GOOGLE. TensorFlow: Open source machine learning. YouTube, 09 nov. 2015. Disponível em: < https://www.youtube.com/watch?v=oZikw5k_2FM >. Acesso em: 03 nov. 2024.
NUMPY. NumPy: the absolute basics for beginners. Disponível em: <https://numpy.org/doc/stable/user/absolute_beginners.html >. Acesso em: 01 nov. 2024.
NASCIMENTO, L.; MORAES, R; MODA, V. – Impacto do tratamento de dados para o machine learning, 04 dez. 2023. Disponível em: < https://ric.cps.sp.gov.br/handle/123456789/15925 >. Acesso em: 15 nov. 2024.
SCIKIT-LEARN DEVELOPERS. Getting Started Disponível em: < https://scikit-learn.org/stable/getting_started.html >. Acesso em: 16 nov. 2024.
1Graduando do Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. Araraquara-SP. E-mail: gabriel.brandao@uniara.edu.br
2Orientador. Docente Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. AraraquaraSP. E-mail: fddallilo@uniara.edu.br
3Coorientador. Docente Curso de Sistemas de Informação da Universidade de Araraquara- UNIARA. AraraquaraSP. E-mail: fflorian@uniara.edu.br