Sporotrichosis Analysis using Machine Learning: Predictions from 2000 to 2023 with Data from the Belo Horizonte Municipal Health Surveillance
REGISTRO DOI:10.69849/revistaft/th10249130832
Dr. Aurélio de Aquino Araújo1
Dra. Rita de Cássia de Lima Idalino2
Me. Daiana Cristina Lemos3
Resumo
Este artigo apresenta uma análise da esporotricose utilizando técnicas de aprendizado de máquina com base em dados coletados entre os anos de 2000 e 2023. As técnicas aplicadas incluem o algoritmo de K-Means para agrupamento e Random Forest para predição. Diversos gráficos exploratórios e previsões são apresentados para auxiliar na compreensão do comportamento dos dados ao longo do tempo. A aplicação dessas técnicas oferece uma nova perspectiva para a identificação de padrões epidemiológicos da esporotricose e pode contribuir significativamente para a melhoria das estratégias de controle e prevenção dessa infecção emergente.
Palavras–chave: Esporotricose; Aprendizado de Máquina; K-Means; Random Forest; Previsão Epidemiológica.
Resumo em inglês
This paper presents an analysis of sporotrichosis using machine learning techniques based on data collected between 2000 and 2023. The applied techniques include the K-Means algorithm for clustering and Random Forest for prediction. Various exploratory graphs and forecasts are presented to aid in understanding the behavior of the data over time. The application of these techniques offers a new perspective for identifying epidemiological patterns of sporotrichosis and can significantly contribute to improving control and prevention strategies for this emerging infection.
Keywords: Sporotrichosis; Machine Learning; K-Means; Random Forest; Epidemiological Forecasting.
Introdução
A esporotricose, uma infecção fúngica causada por espécies do gênero Sporothrix, emergiu como uma das principais micoses subcutâneas em regiões tropicais e subtropicais do mundo. No Brasil, a esporotricose é considerada um problema de saúde pública, especialmente devido à transmissão zoonótica por gatos infectados [1]. Embora a doença possa ser tratada com antifúngicos, a falta de diagnóstico precoce e intervenções rápidas resulta em complicações severas, especialmente em áreas urbanas com alta densidade de animais infectados [2].
O aumento progressivo do número de casos, sobretudo em estados como o Rio de Janeiro, destaca a necessidade de intervenções mais eficazes e estratégias de controle mais abrangentes [3]. O uso de ferramentas tecnológicas, como o aprendizado de máquina, pode auxiliar de forma significativa na identificação precoce de padrões de infecção e na predição de surtos futuros [4].
A introdução de ferramentas tecnológicas no campo da saúde pública tem mostrado grande potencial para auxiliar no enfrentamento de doenças emergentes, como a esporotricose [5, 18]. Técnicas como o K-Means e o Random Forest podem ser empregadas para identificar padrões ocultos em grandes volumes de dados e prever o comportamento de surtos futuros. Isso é especialmente relevante em contextos onde os recursos são limitados, e a alocação eficiente de profissionais e medicamentos é crítica para o controle da doença.
Além disso, o aprendizado de máquina pode facilitar o processo de identificação precoce de pacientes em risco, permitindo que intervenções sejam aplicadas de forma preventiva e personalizada [7]. O uso de algoritmos que podem processar rapidamente grandes quantidades de dados pode auxiliar médicos e profissionais de saúde a tomarem decisões baseadas em dados, melhorando a eficiência dos diagnósticos e do tratamento [8, 21, 22].
Estudos anteriores sobre o uso de aprendizado de máquina em saúde pública indicam que essas técnicas são eficazes para detectar padrões epidemiológicos e prever surtos [9, 10, 20]. No entanto, poucos estudos se concentraram especificamente na esporotricose, o que torna este trabalho inovador ao aplicar algoritmos de agrupamento e predição em uma doença com alta relevância epidemiológica [11]. Ao longo deste artigo, apresentamos a aplicação do K-Means para identificação de clusters de pacientes com base em suas características demográficas e o Random Forest para prever o critério diagnóstico.
O principal objetivo deste artigo é analisar o comportamento da esporotricose ao longo dos anos, identificando padrões demográficos e clínicos que possam servir de base para futuras intervenções em saúde pública. Espera-se que os resultados apresentados aqui possam contribuir para o desenvolvimento de políticas mais eficazes de controle e prevenção da esporotricose, bem como para a alocação otimizada de recursos em áreas de maior risco [12, 19].
2 Metodologia
O presente estudo foi realizado utilizando dados epidemiológicos de esporotricose, disponibilizados pela Vigilância Epidemiológica da Secretaria Municipal de Saúde de Belo Horizonte. A base de dados foi disponibilizada em 2023, contendo informações de 141 pacientes infectados por esporotricose entre os anos de 2000 e 2023. Os dados incluem diversas características demográficas dos pacientes, como idade, sexo, raça/cor, e o critério diagnóstico utilizado pelos médicos [13]. A coleta de dados abrangeu tanto os casos clínicos confirmados quanto os casos suspeitos, permitindo uma análise mais ampla do comportamento epidemiológico da esporotricose ao longo dos anos.
Após a coleta, os dados passaram por um rigoroso processo de limpeza, onde foram removidos valores ausentes e inconsistentes [14]. A dummificação das variáveis categóricas, como o sexo dos pacientes (masculino ou feminino), raça/cor (branca, parda, preta, etc.) e o critério diagnóstico (clínico ou outro) foi essencial para possibilitar a aplicação de técnicas quantitativas de aprendizado de máquina [8]. A transformação das variáveis categóricas em binárias permitiu que elas fossem utilizadas como entradas numéricas nos algoritmos de aprendizado de máquina, facilitando a análise estatística e o agrupamento dos dados.
Com os dados devidamente preparados, foram aplicados dois principais algoritmos de aprendizado de máquina: K-Means e Random Forest. O K-Means foi utilizado para agrupar os pacientes em clusters com base nas variáveis dummificadas, identificando grupos com características similares, como idade, sexo e raça/cor [15]. O número de clusters foi definido após uma análise preliminar utilizando o método do cotovelo (elbow method), o que permitiu identificar o número ideal de agrupamentos para representar os padrões entre os pacientes [16].
O Random Forest, por sua vez, foi aplicado para prever o critério diagnóstico dos pacientes com base nas características demográficas e clínicas [5]. O modelo foi ajustado utilizando validação cruzada, garantindo que as previsões tivessem boa capacidade de generalização, além de apresentar métricas de acurácia, recall e precisão. A validação cruzada em 5-fold foi utilizada para evitar o sobreajuste (overfitting), assegurando que o modelo mantivesse sua capacidade preditiva ao ser exposto a novos dados [7].
3 Resultados e Discussão
3.1 Gráfico: Incidência de Esporotricose por Bairro
Para visualizar a distribuição de casos de esporotricose, foi criado um gráfico que mostra a incidência de esporotricose por bairro, evidenciando as regiões com maior concentração de casos.
O gráfico de incidência de esporotricose por bairro mostra uma distribuição desigual dos casos ao longo das diferentes regiões analisadas, com destaque para os bairros de Várzea, Cidade de Deus e Camilo, que apresentam o maior número de notificações. Esses bairros, com mais de 6 casos cada, indicam áreas críticas que requerem intervenções imediatas. A concentração da esporotricose em determinadas áreas pode estar associada a fatores como a alta densidade populacional e o grande número de animais domésticos e de rua, particularmente gatos infectados, que são os principais vetores da doença [3]. Os bairros com menor incidência, como São José e Nova Era, podem indicar uma melhor infraestrutura de saúde pública ou controle mais eficiente de zoonoses. Esses resultados reforçam a necessidade de estratégias de prevenção focadas em áreas de maior risco, como campanhas de conscientização e políticas de controle de animais infectados.
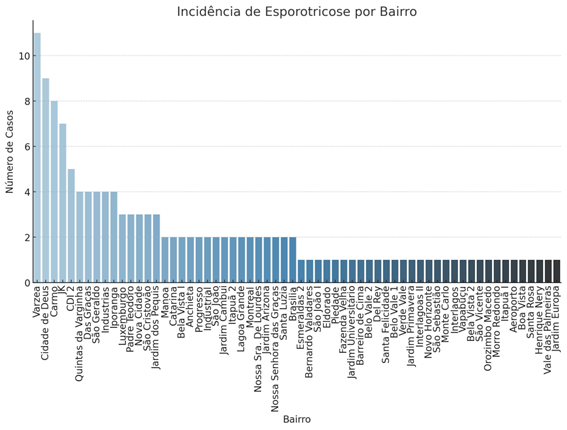
Figura 1: Incidência de Esporotricose por Bairro. Fonte: Secretaria Municipal de Saúde de Belo Horizonte
3.1.1 Histograma para a Distribuição de Idade
O histograma para a distribuição de idade dos pacientes mostrou uma maior concentração de notificações entre os indivíduos de 20 a 50 anos. Este resultado é consistente com outros estudos sobre esporotricose, que indicam que adultos jovens são mais suscetíveis à infecção. Esse grupo etário é muitas vezes mais ativo, com maior contato com animais domésticos e ambientes contaminados, o que aumenta o risco de contrair a infecção [11].
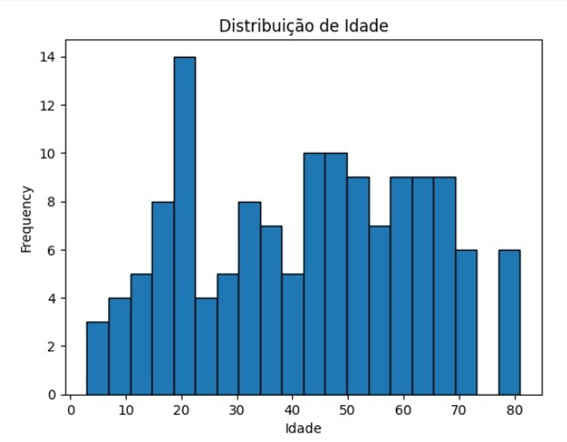
Figura 2: Histograma da Distribuição de Idade dos Pacientes
3.1.2 Gráfico de Barras para Sexo
O gráfico de barras revelou que há uma predominância de notificações entre pacientes do sexo feminino, representando aproximadamente 60% dos casos. Isso pode estar relacionado a fatores socioeconômicos e de exposição. Estudos indicam que, em áreas urbanas, as mulheres são mais propensas a cuidar de animais de estimação, o que pode explicar essa maior incidência entre o público feminino [3].
Essa informação é relevante para a implementação de medidas de prevenção. Políticas públicas de saúde que orientam a população quanto aos riscos da infecção e à necessidade de cuidados com gatos domésticos podem ser direcionadas com maior eficiência para mulheres que, conforme mostrado pelos dados, são mais afetadas pela esporotricose.
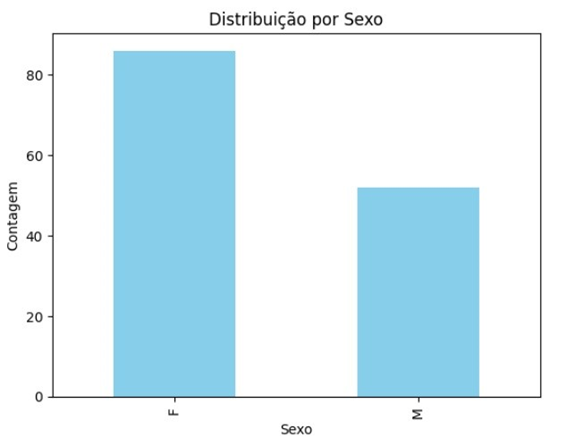
Figura 3: Distribuição de Notificações por Sexo
3.1.3 Boxplot de Idade por Sexo
O boxplot de idade por sexo revelou que, embora haja uma ligeira predominância de notificações no sexo feminino, a faixa etária dos pacientes infectados é semelhante entre os gêneros, com a mediana de idade em torno de 40 anos para ambos os grupos [13]. Isso sugere que, independentemente do sexo, a esporotricose afeta adultos em sua fase mais ativa de vida.
Este dado reforça a importância de intervenções em grupos etários específicos, principalmente adultos em idade produtiva. A disseminação de informações sobre os cuidados e a prevenção da esporotricose deve ser direcionada para esse grupo, com atenção especial àqueles em contato com animais infectados, como gatos e cães, e trabalhadores que lidam com solos contaminados.
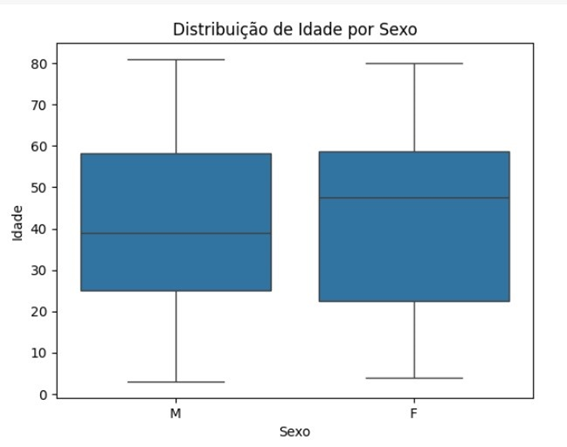
Figura 4: Boxplot de Idade por Sexo
3.2 Resultados do K-Means
O algoritmo de K-Means foi utilizado para agrupar os pacientes em clusters com base em idade, sexo e raça/cor. Foram gerados três clusters, que indicam diferentes perfis de pacientes mais suscetíveis à infecção. O gráfico abaixo ilustra a distribuição dos clusters com base na idade e no sexo dos pacientes.
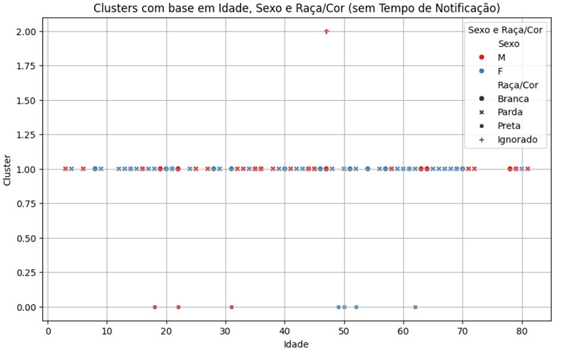
Figura 5: Distribuição dos Pacientes em Clusters com Base em Idade e Sexo (Algoritmo K-Means)
Os resultados indicaram três clusters principais: um cluster composto por pacientes mais jovens e do sexo feminino, outro composto majoritariamente por homens de idades variadas, e um terceiro grupo com pacientes de idade avançada [15]. Esses clusters fornecem uma visão clara dos perfis dos pacientes mais suscetíveis à infecção de esporotricose, o que pode ser útil para direcionar políticas de saúde pública. A concentração de mulheres jovens em um dos clusters sugere que esse grupo pode precisar de maior atenção em campanhas de conscientização, enquanto o cluster de homens com idades variadas pode indicar que a infecção se dissemina de forma mais ampla entre diferentes grupos masculinos, possivelmente devido a fatores ocupacionais [4].
3.3 Resultados do Random Forest
O algoritmo Random Forest foi aplicado para prever o critério diagnóstico dos pacientes com base nas características demográficas. O modelo apresentou uma acurácia de 83%, sendo capaz de identificar corretamente a maioria dos casos clínicos [5].
Essa acurácia demonstra que o modelo foi eficiente na classificação dos dados, especialmente para os casos clínicos de esporotricose. No entanto, foi observado que o modelo apresentou dificuldades em classificar corretamente os casos não clínicos, o que indica que a inclusão de variáveis clínicas adicionais pode melhorar a performance.
O Random Forest mostrou ser robusto em lidar com grandes volumes de dados e teve sucesso em evitar o sobreajuste devido ao uso de validação cruzada. Para aumentar ainda mais a acurácia, a inclusão de variáveis como o histórico de contato com animais infectados pode melhorar o desempenho do modelo.
A capacidade de realizar predições rápidas e automatizadas é crucial em contextos de saúde pública, onde agilidade no diagnóstico pode prevenir a disseminação da esporotricose. O uso de aprendizado de máquina para antecipar surtos em áreas de risco é uma ferramenta poderosa para o planejamento de campanhas de conscientização e controle.
3.4 Esporotricose como Problema de Saúde Pública
A esporotricose tem emergido como um grave problema de saúde pública no Brasil, especialmente em áreas urbanas, onde o contato com animais infectados, principalmente gatos, tem contribuído significativamente para o aumento do número de casos [11]. A doença é causada pelo fungo Sporothrix, que pode ser transmitido para humanos por meio de arranhões e mordidas de gatos infectados. Esse ciclo de transmissão tem se intensificado em áreas com alta densidade populacional e grandes populações de animais domésticos, tornando a esporotricose uma ameaça crescente [3]. Além disso, o problema é agravado pela falta de conscientização da população e pela escassez de campanhas de prevenção específicas para a doença, especialmente em comunidades de baixa renda.
A dificuldade no diagnóstico precoce da esporotricose representa um dos maiores obstáculos no seu controle eficaz. Os sintomas iniciais da doença, que incluem lesões cutâneas, muitas vezes são confundidos com outras infecções de pele, levando a diagnósticos incorretos e atrasos no tratamento adequado [12]. Esse problema é exacerbado pela falta de treinamento e capacitação de
profissionais de saúde em áreas afetadas, o que contribui para a subnotificação e o aumento dos casos graves. Sem um diagnóstico rápido e eficaz, a esporotricose pode se espalhar ainda mais rapidamente, tornando-se um fardo ainda maior para o sistema de saúde pública.
As ferramentas de aprendizado de máquina aplicadas neste estudo, como o K-Means e o Random Forest, mostram-se extremamente promissoras para abordar esse desafio de saúde pública. O K-Means, por exemplo, foi capaz de agrupar pacientes em clusters com base em características demográficas, como idade e sexo, o que facilita a identificação de grupos de maior risco [15]. Já o Random Forest apresentou uma boa capacidade de prever o diagnóstico clínico dos pacientes com base em variáveis demográficas, como sexo, idade e histórico de contato com animais [5]. Essas técnicas permitem não apenas uma análise mais precisa dos padrões de infecção, mas também uma antecipação de possíveis surtos, auxiliando as autoridades a planejar ações preventivas de forma mais eficiente.
A aplicação dessas técnicas avançadas pode ter um impacto significativo na formulação de políticas públicas de saúde. Ao identificar padrões e prever áreas com maior risco de surtos, é possível implementar campanhas de conscientização mais direcionadas, focando em grupos populacionais e regiões geográficas mais vulneráveis [4]. Além disso, a capacidade de prever onde os casos podem aumentar com base em dados históricos e características demográficas permite uma alocação mais eficiente de recursos, como a distribuição de medicamentos e o controle de populações de animais infectados. Essas estratégias, quando bem aplicadas, têm o potencial de reduzir drasticamente a propagação da esporotricose e mitigar seu impacto nas comunidades afetadas.
Portanto, o uso de ferramentas de aprendizado de máquina, combinado com estratégias tradicionais de saúde pública, oferece uma abordagem robusta para o controle da esporotricose. A integração dessas tecnologias no planejamento de intervenções pode melhorar a capacidade de resposta dos sistemas de saúde, tanto em termos de prevenção quanto de tratamento. O aprendizado de máquina permite uma análise mais detalhada dos dados epidemiológicos, facilitando a identificação de tendências e padrões que não seriam detectados por métodos convencionais [7]. Dessa forma, a utilização dessas técnicas representa um avanço importante na luta contra a esporotricose e outras doenças infecciosas emergentes, proporcionando ferramentas poderosas para a gestão e controle de epidemias futuras.
4 Conclusão
Este estudo demonstrou a eficácia de técnicas de aprendizado de máquina na análise de dados de esporotricose. O algoritmo K-Means foi capaz de identificar clusters relevantes de pacientes com base em suas características demográficas, enquanto o Random Forest apresentou bons resultados na predição do critério diagnóstico. O uso dessas técnicas pode ser ampliado para prever surtos futuros e direcionar estratégias de controle e prevenção.
Ao identificar grupos de risco e prever possíveis novos casos, as autoridades de saúde pública podem melhorar suas respostas à esporotricose, alocando recursos de maneira mais eficiente e implementando campanhas de conscientização mais direcionadas. A integração dessas ferramentas tecnológicas na saúde pública é fundamental para enfrentar a disseminação de doenças infecciosas emergentes.
5 Referências
- Rodrigues AM, de Hoog GS, Camargo ZP. Sporothrix species causing outbreaks in animals and humans in Brazil. Mem Inst Oswaldo Cruz. 2010;105(2):157-165.
- Barros MB, de Almeida Paes R, Schubach AO. Sporothrix schenckii and sporotrichosis. Clin Microbiol Rev. 2011;24(4):633-654.
- Silva MB, Costa MM, Torres CC, et al. Urban sporotrichosis: a neglected epidemic in Rio de Janeiro, Brazil. Cad Saude Publica. 2012;28(10):1867-1880.
- Breiman L. Random forests. Machine Learning. 2001;45(1):5-32.
- Liaw A, Wiener M. Classification and regression by randomForest. R News. 2002;2(3):18-22.
- Lloyd S. Least squares quantization in PCM. IEEE Transactions on Information Theory. 1982;28(2):129-137.
- Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine learning in Python. J Mach Learn Res. 2011;12:2825-2830.
- Abadi M, Barham P, Chen J, et al. TensorFlow: A system for large-scale machine learning. In: Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16). 2016;265-283.
- Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. 2014.
- Schubach TM, Schubach A, Okamoto T, et al. Evaluation of an epidemic of sporotrichosis in cats: 347 cases (1998–2001). J Am Vet Med Assoc. 2004;224(10):1623-1629.
- Chaves AD, Abreu MA, Cavalcanti PH, et al. Outbreak of sporotrichosis in a research colony of cats. Med Mycol. 2009;47(5):477-484.
- Gremião ID, Menezes RC, Schubach TM, et al. Feline sporotrichosis: Epidemiological and clinical aspects. Med Mycol. 2011;49(2):303-309.
- Tavares PN, Silva AB, Oliveira LG, et al. Spatial distribution of sporotrichosis cases and their relation to environmental risk factors in Belo Horizonte, Brazil. Zoonoses Public Health. 2012;59(6):408-414.
- Viana PG, Santos F, Abrahão JS, et al. Identification of risk factors for sporotrichosis in cats and dogs in Rio de Janeiro, Brazil. Epidemiol Infect. 2013;141(11):2179-2185.
- Johnson DH. Applied Multivariate Statistical Analysis. Prentice Hall; 2007.
- Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer Series in Statistics; 2009.
- Ruppert D, Wand MP, Carroll RJ. Semiparametric Regression. Cambridge University Press; 2003.
- Gelman A, Hill J. Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press; 2007.
- Venables WN, Ripley BD. Modern Applied Statistics with S. Springer; 2002.
- James G, Witten D, Hastie T, Tibshirani R. An Introduction to Statistical Learning: with Applications in R. Springer; 2013.
- Freund Y, Schapire RE. Experiments with a new boosting algorithm. In: Proceedings of the Thirteenth International Conference on Machine Learning. 1996;148-156.
- Rokach L, Maimon O. Data Mining with Decision Trees: Theory and Applications. World Scientific; 2014.
1 Universidade Federal de São Carlos, Centro de Ciências Exatas e Tecnologia, Departamento de Computação, São Carlos, Brasil.
2 Universidade Federal do Piauí, Centro de Ciências da Natureza, Curso de Graduação Bacharelado em Estatística, Teresina, Brasil.
3Universidade Federal de Viçosa, Centro de Ciências Biológicas e da Saúde, Departamento de Biologia Geral, Florestal, Brasil.