IMPUTATION OF MISSING DATA IN DATABASES: A PRODUCTION ANALYSIS USING BIBLIOMETRY
REGISTRO DOI:10.5281/zenodo.10427960
Leonardo Minelli1
Paulo Sérgio Sausen2
Airam Teresa Zago Romcy Sausen3
Resumo
Os dados são fundamentais para o conhecimento e tomada de decisões, seguindo o modelo DICS (Dados, Informação, Conhecimento e Sabedoria). A imputação de dados faltantes em bancos de dados é essencial para garantir a integridade dos dados. A pesquisa bibliométrica analisou a produção científica sobre esse tema na base de dados WoS entre janeiro de 2018 e janeiro de 2023. Foram encontradas 427 publicações sobre imputação de dados faltantes, com crescimento constante ao longo dos anos. As áreas de saúde, trânsito, educação, clima e energia são as mais exploradas. A China lidera com 23,9% das publicações, enquanto o Brasil representa 1,5%. A maioria das publicações são artigos científicos, focados em aprendizado de máquina, regressão e predição. As publicações mais citadas incluem trabalhos sobre imputação de dados em tráfego inteligente, análise integrativa de grandes dados biomédicos e aprendizado de máquina em metabolômica. Os autores mais cocitados propõem o pacote MICE em R para imputação de dados multivariados. O estudo conclui que a pesquisa cumpriu o objetivo de revisar a literatura internacional sobre imputação de dados faltantes em bancos de dados. Como limitações, sugere-se ampliar a busca para outras bases de dados, focando em técnicas específicas de imputação e direcionando as palavras-chave para a área de interesse.
Palavras-chave: Imputação de dados. Dados faltantes. Bibliometria.
1 INTRODUÇÃO
Os dados são a fonte de informação, conhecimento e sabedoria para máquinas e seres humanos. Segundo o modelo hierárquico DICS (Dados, Informação, Conhecimento e Sabedoria), os dados são a base para que se obtenha os passos seguintes no modelo (SHARMA, 2008). A sabedoria é conceituada como sendo o conhecimento aplicado, proporcionando a decisão de situações futuras. O conhecimento, por sua vez, é a informação colocada sob um contexto, já relacionando registros do passado. Os dados organizados de forma a ter algum significado são definidos como informação.
De acordo com Duarte (2023), uma quantidade massiva de dados são criados todos os dias, e essa quantia aumenta de forma exponencial proporcionando grandes acúmulos de dados. São caracterizados como dados criados aqueles que provém de novas fontes, copiados ou ainda consumidos. O estudo revelou que entre 2010 e 2020 cerca de 328 milhões de Gigabytes foram gerados diariamente no mundo, e que existe uma projeção que sejam gerados aproximadamente 181 Zettabytes somente no ano de 2025.
Além ter uma produção acelerada, os dados têm se mostrado importantes para as mais diversas finalidades, sendo alguns dos ramos em que são utilizados amplamente: processamento de linguagem natural, saúde, veículos autônomos etc. A Inteligência Artificial se mostra influente no que diz respeito à engenharia de software e à produção de software. Segundo Whang et al. (2023), mesmo os softwares mais aperfeiçoados, com os melhores algoritmos e recursos computacionais podem falhar em decorrência de dados ruins ou mal preparados.
A falta de dados em bancos de dados podem proporcionar vários problemas para a realização de tarefas que envolvem o uso de recursos computacionais e a tomada de decisão. Alguns exemplos de falhas que podemos mencionar, decorrentes de ocorrências de dados faltantes em bancos de dados, são: falhas de hardware ou software; falhas de rede; e falhas de relatórios (CHEN, HE & SUN, 2019).
Neste contexto, essa pesquisa tem como objetivo analisar a produção científica sobre a área de imputação de dados faltantes em bancos de dados, focando na base de dados Web of Science (WoS). Destarte, esse estudo está organizado em capítulos e subcapítulos do seguinte modo: introdução, onde são expostos os objetivos e justificativas da pesquisa; referencial teórico, apresentando os conceitos básicos da área estudada; métodos, consistindo da linha de desenvolvimento utilizada para o estudo; resultados, onde são apresentados os achados preliminares da pesquisa; e conclusão.
2 FUNDAMENTAÇÃO TEÓRICA
Para fins de esclarecimento do tema pesquisado, neste capítulo é apresentado o estado da arte da imputação de dados, tal como estudos envolvendo a teoria e a prática desse processo da ciência de dados.
2.1 Imputação de Dados
A imputação de dados é um processo essencial para lidar com valores ausentes em bancos de dados. Ocorre quando certos atributos ou informações estão ausentes ou incompletos, e é necessário preencher essas lacunas para garantir a integridade e a utilidade dos dados. Conforme Schafer (1997), a presença de valores ausentes pode comprometer a qualidade e a integridade dos dados, prejudicando as análises estatísticas e as inferências obtidas.
A imputação de dados apresenta desafios significativos devido à natureza complexa dos valores ausentes. A identificação correta do mecanismo de geração dos valores ausentes, a seleção apropriada de técnicas de imputação, a preservação da distribuição original dos dados e a avaliação da qualidade das imputações são questões críticas a serem consideradas (GRAHAM, 2012). A imputação de dados é especialmente relevante em bancos de dados utilizados para análise estatística, mineração de dados e aprendizado de máquina, onde a presença de valores ausentes pode afetar a precisão dos resultados e levar a conclusões equivocadas.
É importante mencionar que a escolha da técnica de imputação depende do tipo dos dados, da distribuição dos valores ausentes e do contexto específico do problema. Além disso, segundo os autores Little & Rubin (2019), é necessário considerar a qualidade dos dados imputados e realizar uma avaliação cuidadosa dos resultados obtidos.
Destarte, a imputação de dados desempenha um papel fundamental na garantia da integridade e da confiabilidade dos bancos de dados. Diversas abordagens e técnicas estão disponíveis para lidar com valores ausentes, e a escolha adequada depende do contexto e das características dos dados em questão. Nesse sentido, o presente trabalho se alicerça na busca da verificação da prevalência da imputação de dados faltantes em bancos de dados nas bases científicas.
2.2 Bibliometria
O presente trabalho é caracterizado de natureza descritiva, tendo como abordagem o método quantitativo e sua aplicação por análise bibliométrica. A pesquisa bibliométrica visa a demonstração das tendências dos periódicos e o perfil dos pesquisadores do tema em discussão. O foco desse tipo de pesquisa é ampliar os conhecimentos sobre os assuntos relacionados.
Os estudos de natureza descritiva são projetados e realizados com o objetivo de mensurar as características descritas de um evento ou atividade (HAIR et al. 2009). A abordagem quantitativa, acordo com Sampieri, Collado & Lucio (2006), envolve a medição do conhecimento, opiniões, hábitos e comportamentos, buscando quantificar dados e generalizar resultados da amostra. Além disso, essa abordagem também relata os eventos e fatos que fornecem informações específicas sobre a realidade, permitindo explicação e previsão. No contexto da análise bibliométrica, Chueke & Amatucci (2015) definiram esta como sendo a aplicação de métodos estatísticos e matemáticos para analisar obras literárias.
3 METODOLOGIA
Quanto à coleta de dados, foi utilizada a bases de dados WoS, com uma busca delimitada no período de janeiro de 2018 a janeiro de 2023 com o conjunto de palavras-chave “missing data imputation“. A análise dos dados incluiu a utilização de clusters de cocitações e palavras-chave, por meio de um mapa textual gerado pela ferramenta Biblioshiny, do pacote Bibliometrix presente no ambiente R Studio, além dos dados relevantes obtidos na base de dados.
Na Figura 1 são ilustradas as etapas, sequenciais e evolutivas da pesquisa para que o objetivo proposto fosse alcançado.
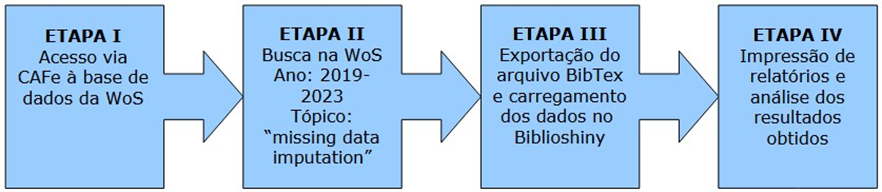
Figura 1. Evolução das etapas utilizadas para a análise bibliométrica do interesse da pesquisa.
Na primeira etapa foi efetuado o acesso à base de dados WoS utilizando as credenciais via Comunidade Acadêmica Federada (CAFe). A partir deste acesso, foi possível aceder às mais diversas informações que a base de dados fornece para buscas avançadas. A segunda etapa consistiu de limitar a busca nessa base para os últimos cinco anos, sendo de janeiro de 2019 até janeiro de 2023 e a partir do conjunto de palavras que compuseram a palavra-chave “missing data imputation”. Foi necessária tal medida pois, utilizando palavras-chave isoladas, a base de dados incluia em sua relação de publicações encontradas trabalhos que não eram do interesse desta pesquisa. Na terceira etapa foi exportado o arquivo que contém os metadados, em formato BibTex (em extensão .bib) e, carregado este arquivo na ferramenta Biblioshiny. A quarta e última etapa consistiu da impressão de relatórios (pela própria ferramenta), e análise dos resultados encontrados. A partir dessa sistemática, são apresentados os resultados a seguir.
4 RESULTADOS
Neste capítulo são apresentados os resultados da pesquisa, sendo inicialmente apresentadas as características das publicações sobre o tema de imputação de dados faltantes em bancos de dados. Posteriormente são apresentadas as citações, as cocitações e os termos frequentes destas publicações.
4.1 Características gerais das Publicações sobre Imputação de Dados
Nesse subcapítulo são apresentadas as características gerais das publicações que envolvem o tema desta pesquisa. Tais características são delimitadas nas publicações presentes na base de dados WoS, delimitando-se o período entre janeiro de 2019 e janeiro de 2023. Utilizando os filtros propostos, foram encontrados 427 publicações. A evolução das publicações pode ser visualizada na Figura 2.
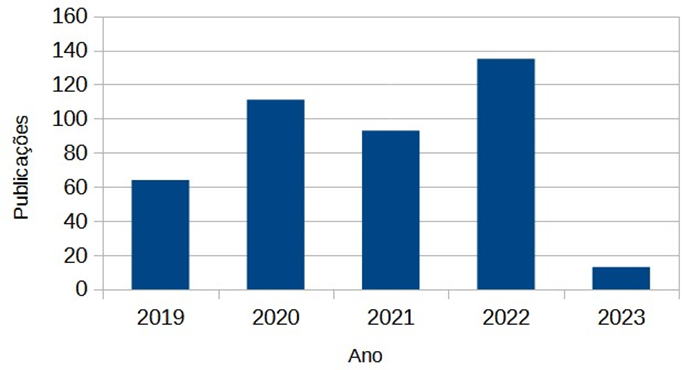
Figura 2. Evolução das publicações nos últimos cinco anos.
Podemos destacar que, a partir da evolução, existe uma crescente na quantidade de publicações que envolvam a temática da pesquisa. Com relação ao ano de 2023, cabe relatar que são as publicações que envolvam somente o primeiro mês do referido ano (i.e. janeiro). Além disto, publicações que já foram aprovadas mas ainda não indexadas podem não estar relacionadas nesta população de documentos.
No rol de documentos relacionados, a partir da nuvem de palavras e da relação de termos existentes nas publicações, percebemos a existência de grandes áreas que envolvam a imputação de dados faltantes em bancos de dados, sendo: saúde, educação, clima, trânsito, energia, entre outras. Parte dessa relação pode ser vista na Figura 3.

Figura 3. Nuvem de palavras e alguns dos termos mais comuns.
A partir das publicações encontradas, é apresentado na Figura 4 o quantitativo de publicações feitas por cada país. Nessa relação, foram apresentados os dez países com maior quantidade de publicações na temática da pesquisa.
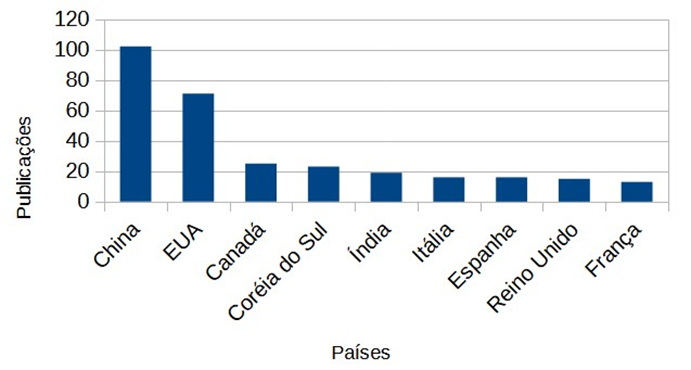
Figura 4. Quantidade de publicações por país.
Destaca-se que o Brasil encontra-se na 14ª posição, com sete artigos publicados e indexados na base de dados da WoS nesse intervalo de tempo, onde o autor principal é o autor correspondente da pesquisa (i.e. autor principal). Em termos percentuais de participação, a China detém aproximadamente 23,9% de ocupação do total de publicações feitas, enquanto que o Brasil representa aproximadamente 1,5%.
Como forma de verificação dos tipos de publicações, também foi possível efetuar a análise quantitativa deste tipo de dado. Na Figura 5 é representada essa informação.
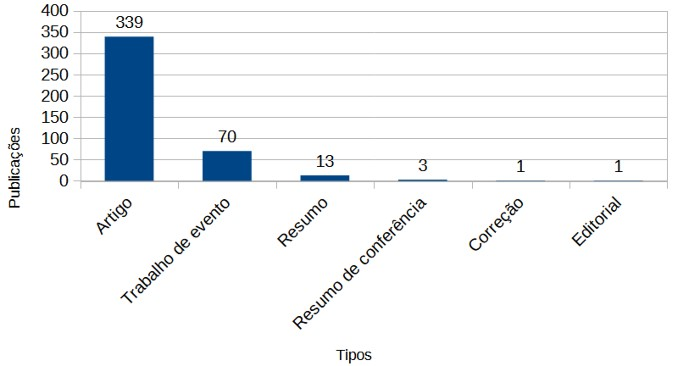
Figura 5. Quantidade de publicações por tipo.
É perceptível que a maior parte dos tipos de trabalhos publicados que envolvem o tema de imputação de dados faltantes em bancos de dados é de artigos científicos. Os trabalhos apresentados em eventos também possuem uma boa participação no que diz respeito à disseminação dos conhecimentos produzidos. Os artigos listados neste estudo são compostos por trabalhos publicados em periódicos, podendo também estarem no formato de early access, proceedings papers e/ou data papers.
4.2 Relatório de Citações, Cocitações e Termos Frequentes
Neste subcapítulo, apresentamos a análise das citações e na construção do mapaconceitual de cocitações. São descritas as fontes bibliográficas mais relevantes encontradas e, além disso, é exibido o mapa-conceitual, destacando as conexões entre os trabalhos acadêmicos citados. Foi buscado fornecer uma visão abrangente e fundamentada do fluxo do conhecimento no campo de estudo de imputação de dados faltantes em bancos de dados, tal como a rede de cooperação entre os autores desta área.
Na Tabela 1 são apresentadas as publicações com o maior número de citações globais, ou seja, citações feitas em qualquer publicação no mundo, e não somente no país de origem da publicação.
Tabela 1. As cinco publicações mais citadas.
A Bayesian tensor decomposition approach for
spatiotemporal traffic data imputation CHEN, X. 2019 126 Machine Learning and Integrative Analysis of Biomedical Big Data MIRZA, B. 2019 123 Machine Learning Applications for Mass Spectrometry-Based Metabolomics LIEBAL, U.W. 2020 94 Missing traffic data imputation and pattern discovery with a Bayesian augmented tensor factorization model Missing value imputation using a novel grey based CHEN, X. 2019 54 fuzzy c-means, mutual information based feature selection, and regression model SEFIDIAN, A.M. 2019 47
É possível perceber que o trabalho de Chen, He & Sun (2019) encontra-se como o mais citado, nos últimos cinco anos na base de dados WoS. Este trabalho explica que o problema de dados faltantes em bancos de dados é comum ao coletar informações de tráfego de sistemas de transporte inteligentes. Utilizando um conjunto de dados de velocidade de tráfego coletados em Guangzhou, China, eles avaliaram o desempenho do modelo proposto em prever dados faltantes, especialmente quando havia corrupção temporal dos dados.
Neste mesmo ano de 2019, o trabalho publicado por Mirza et al. (2019) também possui uma quantidade significativa de citações. Nessa publicação os autores discutem as abordagens mais avançadas de aprendizado de máquina para enfrentar os desafios computacionais dos dados “omics” (e.g. genoma, epigenoma, transcriptoma, proteoma e metaboloma), como o grande número de dimensões dos dados, a heterogeneidade entre as fontes, a presença de dados faltantes, o desequilíbrio entre as classes e os problemas de escalabilidade da análise integrativa.
O artigo de Liebal et al. (2020) discute o uso de aprendizado de máquina para análise de dados metabolômicos obtidos por espectrometria de massa (MS). A metabolômica é o estudo dos metabólitos presentes em um organismo em um determinado momento e é influenciada tanto por fatores ambientais quanto por regulação intracelular. O trabalho destaca que a qualidade dos dados é crucial para a qualidade da análise, e a escolha do modelo de aprendizado de máquina apropriado para os dados é um desafio importante.
Além da verificação de autores mais citados, ainda é possível relatar o mapa de cocitações, envolvendo trabalhos passados que contribuíram para o estudo científico das publicações encontradas nesta pesquisa. Essa ilustração está presente na Figura 6.
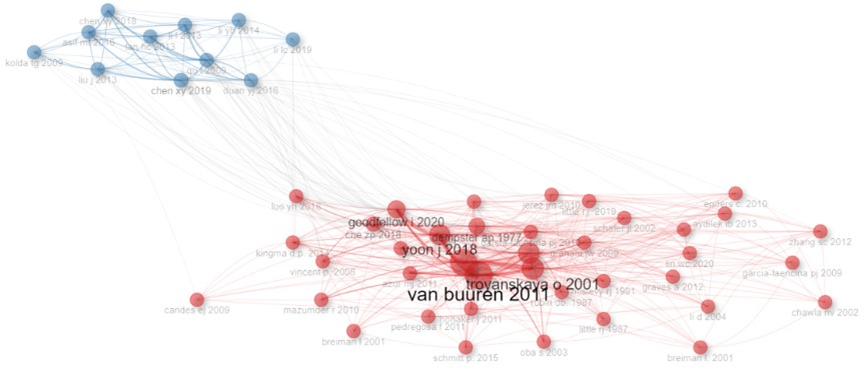
Figura 6. Mapa conceitual de cocitações.
No mapa conceitual de cocitações são ilustrados dois clusters. O cluster de cor vermelha, que envolve a majoritária cocitação do artigo de Van Buuren & GroothuisOudshoorn (2011), possui trabalhos publicados há mais tempo mas que ainda são uma importante referência na publicação de trabalhos recentes. Pode-se destacar que a participação dos primeiros oito trabalhos mais cocitados, na concepção e elaboração de pesquisas recentes, encontram-se agrupados neste cluster. Tais publicações são datadas em 1976, 1977, 2001, 2010, 2011, 2012, 2018 e 2020. No cluster de cor azul, são notadas referências mais recentes, sendo a mais antiga datada em 2009. A representação do quantitativo de citações das publicações mais cocitadas, apresentadas na Figura 6, é feita na Tabela 2.
Tabela 2. Os cinco trabalhos mais cocitados.
Referência Citações VAN BUUREN S, 2011, J STAT SOFTW, V45, P1 68 STEKHOVEN DJ, 2012, BIOINFORMATICS, V28, P112 62 RUBIN DB, 1976, BIOMETRIKA, V63, P581 50 TROYANSKAYA O, 2001, BIOINFORMATICS, V17, P520 49 YOON J, 2018, PR MACH LEARN RES, V80 45
No trabalho proposto por Van Buuren & Groothuis-Oudshoorn (2011) é descrito o pacote MICE (Multiple Imputation by Chained Equations) do ambiente R Studio, que é utilizado para imputar dados multivariados incompletos através de equações encadeadas. O artigo colabora tecnicamente com a prática do MICE 2.9 na resolução de problemas reais com dados incompletos, apresentando formas de auxiliar os usuários a imputar dados de forma eficiente e adequada.
Entre todos os 427 trabalhos relacionados na busca, foi efetuada a análise dos termos mais comuns utilizados nos títulos, palavras-chave, resumo e no texto. As palavras mais encontradas encontram-se ilustradas na Figura 7, no formato de mapa de calor, onde também são demonstradas as relações em rede destas palavras.

Figura 6. Mapa de calor de palavras e sua ocorrência.
É perceptível que palavras como “prediction”, “multiple imputation” e “regression” são algumas encontradas e que possuem forte relação de agrupamento e quantidade significativa de ocorrências. Como a proposta de imputação de dados faltantes em bancos de dados também é proveniente da utilização de recursos e processos computacionais, há também a presença dos termos “model” e “algorithm”, justificado pela utilização de softwares na solução de problemas deste tipo. Cabe destacar que na apresentação da Figura 3 estão palavras que são utilizadas em conjunto, ou seja, conceitos que possuem coocorrência nos trabalhos científicos.
5 CONCLUSÃO
Podemos destacar que o tema de imputação de dados faltantes em bancos de dados sofre algumas variações no que se refere ao quantitativo de publicações por ano. Tal variação é justificada pela ocorrência de novas tecnologias que surgem e a utilização de bancos de dados nestas, resultando em motivações para a pesquisa na área de imputação de dados faltantes (e.g. smart cities, healthcare, smart grids etc.).
As áreas envolvendo publicações com a temática de imputação de dados faltantes em bancos de dados mostram-se promissoras na área das ciências da saúde, do trânsito e infraestrutura, educação e ensino, meteorologia e previsão do tempo e engenharia elétrica, conforme as palavras-chave encontradas nas publicações. Cabe salientar que todas as áreas têm sua aplicação na imputação de dados faltantes em bancos de dados, porém essas se destacaram em termos quantitativos.
A maior parte das publicações referenciadas são originárias de países como China, Coréia do Sul, Estados Unidos e Canadá, embora exista a tendência de outras regiões terem uma boa participação nas publicações deste tema, como a região da Europa. Nesse sentido, percebe-se a concentração de pesquisas científicas em países desenvolvidos.
Os tipos de publicações que envolvem a imputação de dados faltantes em bancos de dados são: artigos, trabalhos de eventos, resumos, resumos de conferência, correção e editorial. Essa variação tem como maior participação a dos artigos, que envolvem desde trabalhos presentes em formato de early access, quanto proceedings e/ou data papers.
Os trabalhos citados nesta análise refletem a crescente importância da imputação de dados faltantes em diversas áreas de pesquisa. Destacam-se os problemas de dados faltantes em bancos de dados ao coletar informações de sistemas de transporte inteligentes, os desafios computacionais em dados “omics” e a importância da qualidade dos dados e a necessidade de escolher adequadamente o modelo para a análise.
O mapa conceitual de cocitações revela clusters de trabalhos relacionados, demonstrando a influência de publicações mais antigas, como o trabalho de Van Buuren & Groothuis-Oudshoorn (2011), que apresentaram o pacote MICE para imputação de dados multivariados incompletos. Essa contribuição técnica ainda se mostra relevante para resolver problemas reais com dados incompletos.
O mapa de calor, em que são relacionados as coocorrências, revela padrões de associação entre termos encontrados no estado da arte da imputação de dados faltantes em bancos de dados, relacionando-os com o panorama científico e as tendências dessa temática. A busca por termos que relacionam-se pode favorecer a pesquisa científica neste cenário.
Com base nas análises realizadas, pode-se afirmar que a pesquisa alcançou com sucesso o seu propósito de apresentar os resultados de uma revisão bibliométrica abrangendo a literatura internacional sobre imputação de dados faltantes em bancos de dados. O período de abrangência da pesquisa compreendeu de janeiro de 2018 a janeiro de 2023.
Como limitação do estudo, destaca-se a realização do mesmo somente na base de dados da WoS. Neste sentido, recomenda-se para pesquisas futuras utilizar outras bases de dados (em paralelo ou em simultâneo), além de direcionar as palavras-chave de busca de forma mais assertiva, além de vincular a temática de interesse na imputação de dados. Outrossim, direcionar a busca para as técnicas de imputação de dados pode ser interessante, refinando modelos e algoritmos atuais e mais utilizados nesta temática.
REFERÊNCIAS
CHEN, Xinyu; HE, Zhaocheng; SUN, Lijun. A Bayesian tensor decomposition approach for spatiotemporal traffic data imputation. Transportation research part C: emerging technologies, v. 98, p. 73-84, 2019.
CHUEKE, Gabriel Vouga; AMATUCCI, Marcos. O que é bibliometria? Uma introdução ao Fórum. Internext, v. 10, n. 2, p. 1-5, 2015.
DUARTE, F. Amount of data created daily (2023). Disponível em: http://explodingtopics.com/blog/data-generated-per-day. Acessado em: 26 de Abril de 2023.
GRAHAM, John W. Missing data: Analysis and design. Springer Science & Business Media, 2012.
HAIR, Joseph F., et al. Análise multivariada de dados. Bookman editora, 2009.
LIEBAL, Ulf W., et al. Machine learning applications for mass spectrometry-based metabolomics. Metabolites, v. 10, n. 6, p. 243, 2020.
LITTLE, Roderick JA; RUBIN, Donald B. Statistical analysis with missing data. John Wiley & Sons, 2019.
MIRZA, Bilal, et al. Machine learning and integrative analysis of biomedical big data. Genes, v. 10, n. 2, p. 87, 2019.
SAMPIERI, Roberto Hernández; COLLADO, Carlos Fernández; LUCIO, Pilar Baptista. Metodologia de pesquisa. In: Metodologia de pesquisa. 2006. p. xxiv, 583-xxiv, 583.
SCHAFER, Joseph L. Analysis of incomplete multivariate data. CRC press, 1997.
SHARMA, Nikhil. The origin of data information knowledge wisdom (DIKW) hierarchy. Preuzeto, v. 25, p. 2021, 2008.
VAN BUUREN, Stef; GROOTHUIS-OUDSHOORN, Karin. mice: Multivariate imputation by chained equations in R. Journal of statistical software, v. 45, p. 1-67, 2011. WHANG, Steven Euijong, et al. Data collection and quality challenges in deep learning: A data-centric ai perspective. The VLDB Journal, v. 32, n. 4, p. 791-813, 2023
Discente do Programa de Pós-Graduação em Modelagem Matemática e Computacional da Universidade Regional do Noroeste do Estado do Rio Grande do Sul (PPGMMC/UNIJUI). e-mail: leonardominelli@sou.unijui.edu.br1
Docente do Programa de Pós-Graduação em Modelagem Matemática e Computacional da UniversidadeRegional do Noroeste do Estado do Rio Grande do Sul (PPGMMC/UNIJUI). e-mail: sausen@unijui.edu.br2
Docente do Programa de Pós-Graduação em Modelagem Matemática e Computacional da UniversidadeRegional do Noroeste do Estado do Rio Grande do Sul (PPGMMC/UNIJUI). e-mail: airam@unijui.edu.br3