ALGORITHMS FOR IDENTIFICATION AND ANALYSIS OF EYE POSITIONS IN THE USE OF COMMANDS FOR MOVEMENTS OF PARAPLEGIC AND TETRAPLEGIC PATIENTS
REGISTRO DOI: 10.69849/revistaft/ch10202512190624
Arnaldo Cubaski Junior1
Márcio Roberto Covacic2
Ruberlei Gaino3
Resumo
A Visão Computacional e a Inteligência Artificial trabalham juntas em inúmeras aplicações na ciência. Desta forma, utilizando estas duas áreas é possível obter informações de imagens e classificá-las em determinadas classes pré-especificadas, de forma a simplificar ou, até mesmo, minimizar a ação humana em uma determinada atribuição. Tendo isso em mente, este projeto visa a elaboração de um algoritmo confiável que detecte posições oculares simples expressas como ‘CIMA’, ‘BAIXO’, ‘ESQUERDA’, ‘DIREITA’ e ‘PADRÃO’, utilizando como base de processamento a retina e a íris do indivíduo e, consequentemente, seja capaz de identificar em qual direção tal pessoa está olhando. Sendo assim, o algoritmo desenvolvido, pode atuar facilitando a manipulação de certos equipamentos e dispositivos eletrônicos, utilizando os movimentos oculares como uma forma de controle. A exemplo disso, temos uma cadeira de rodas cujo controle de direção seja através de movimentos oculares, como também acionar comandos ao neuroestimulador para promover movimentos funcionais de membros. Desta maneira, evidenciando a capacidade de controle do algoritmo desenvolvido, foi realizado testes nos quais as posições oculares identificadas pelo algoritmo atuam variando a angulação de um servo motor.
Palavras-chave: Rastreamento Ocular Visual. Redes Neurais Convolucionais. Tecnologias Assistivas. Tetraplegia. Visão Computacional.
1 INTRODUÇÃO
1.1. Tecnologias Assistivas
Segundo dados obtidos pelo Instituto Brasileiro de Geografia e Estatística (IBGE) no ano de 2000, foram constatados cerca de 9.875.510 brasileiros com alguma deficiência motora, definidas dentre elas, a Paraplegia, a Tetraplegia e a Hemiplegia Permanente. Este valor, na época, contabilizava aproximadamente 6.55% da população brasileira naquele ano. No ano de 2010 foram constatados cerca de 13.265.599 brasileiros com algum tipo de deficiência motora. Nesta pesquisa realizada, não foi especificado qual a deficiência motora, apenas classificadas em “Não Consegue de Modo Algum”, “Grande Dificuldade” e “Alguma Dificuldade”. Este número expressava cerca de 6.95% da população brasileira naquele ano (INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, 2021a,b).
O aumento expressivo destes números evidencia a necessidade de uma maior preocupação com este grupo populacional, de forma a viabilizar a integração destes indivíduos na sociedade, diminuindo suas dificuldades enfrentadas. A partir deste princípio e devido às poucas pesquisas desenvolvidas a fim de oferecer melhor qualidade de vida para pessoas com deficiências motoras, o autor (GAINO, 2009) desenvolveu um sistema de controle em malha fechada para variação angular da articulação do joelho de pacientes paraplégicos utilizando estímulos elétricos no músculo quadríceps. Dados do IBGE mais recentes confirmam a tendência de aumento.
Em (GOMIDE, 2012), o autor desenvolve um ambiente virtual no formato de jogo visando a recuperação de pacientes com deficiências motoras nos membros superiores utilizando de técnicas de Visão Computacional. Além disso, em (SOUSA, 2019), a autora desenvolve um sistema capaz de extrair imagens dos olhos e boca do usuário, identificar as posições oculares dos olhos e movimento da boca, além de inclinações na cabeça e associar tais movimentos ao controle de uma cadeira de rodas. Ambos os projetos abordam tecnologias assistivas para pessoas com deficiências motoras, de forma a possibilitar uma melhor qualidade de vida para este grupo de pessoas.
O controle do movimento de uma cadeira de rodas com base nos movimentos dos olhos também é abordado em (THARWAT et al., 2022) e (XU et al., 2023). Em (XU et al., 2023), o controle se baseia em deep learning com redes neurais.
Uma discussão muito bem apresentada em (DAHMANI et al, 2020) coloca no estado da arte, os tipos de uso de rastreamento ocular visual, os tipos de redes neurais e a necessidade de reduzir custos. Os softwares comerciais ainda são muito caros para rastreamento ocular visual, tornando economicamente inviável a utilização no acionamento da cadeira de rodas para pessoas paraplégicas e tetraplégicas.
O nosso grupo tem experiência com outras opções de acionamento, que foram abordadas pelo nosso estudo em (INPI, 2022a), (INPI, 2002b) e (LEÔNCIO JUNIOR et al., 2025). Uma outra colaboração de desenvolvimento foi apresentada pela interação do Programa de Pós Graduação da Engenharia Elétrica da Universidade Estadual de Londrina com o curso de Engenharia Elétrica da Unicesumar, cujo projeto consiste no controle da cadeira de rodas pelo rastreamento ocular visual com uso de controle (SILVA; MAGAN; OLIVEIRA, 2021).
Neste artigo, foi apresentado uma possibilidade de reduzir os custos, com a utilização de softwares open source e microcontrolador acessíveis com a utilização da linguagem Python. As imagens a serem analisadas podem ser obtidas com a câmera de um telefone celular, reduzindo ainda mais o custo da tecnologia. Os comandos de posição ocular acionam um servo motor que tem como objetivo acionar os motores da cadeira de rodas.
O acionamento ocular a baixo custo (DAHMANI et al., 2020) mostra-se uma opção viável e incentivou os nossos estudos, culminando, neste artigo, na criação de um sistema com custos menores, utilizando softwares open source, biblioteca Python, Arduino e telefone celular.
Para o acionamento de uma cadeira de rodas, a eletrônica empregada, os sensores e os estágios de potência são apresentados em (GENTILHO JUNIOR, 2014) e (NUNES, 2015).
1.2. Visão Computacional
A Visão Computacional trata-se de uma técnica de análise que permite interpretar imagens do mundo real por meio de um software. Desta maneira, com a devida programação, é possível desenvolver algoritmos capazes de realizar ações que necessitam da habilidade cognitiva de interpretação de imagens pelos seres humanos, facilitando assim, atividades realizadas pelo homem. Trata-se de um tema interdisciplinar, no qual pode atuar em diversos campos, como na agricultura, no setor industrial, na biologia, na medicina, dentre outros.
Em (NEVES; NETO; GONZAGA, 2012), os autores apresentam 20 trabalhos sobre visão computacional e suas aplicações. Estes trabalhos foram selecionados no evento VII Workshop de Visão Computacional (WVC 2011), realizado na Universidade Federal do Paraná, em Curitiba, no ano de 2011. A partir deste livro, é possível perceber a ampla gama de aplicabilidades da Visão Computacional. São apresentados trabalhos na área da medicina, agricultura, processamento de imagens, sistemas automatizados de identificação, reconhecimento de padrões, dentre outros.
1.3. Inteligência Artificial
Segundo (PEREIRA, 2003), a Inteligência Artificial (IA) é uma disciplina científica que utiliza as capacidades de processamento computacional com a finalidade de desenvolver métodos genéricos para automatizar atividades perceptivas, cognitivas e manipulativas, utilizando de hardwares.
Ainda, em (NORVIG; RUSSEL, 2013), os autores apresentam definições para a Inteligência Artificial sob quatro categorias diferentes. Estas categorias são: “Pensando como um Humano”, “Pensando Racionalmente”, “Agindo como Seres Vivos” e “Agindo Racionalmente”. Segundo os autores estas quatro categorias são estratégias para se definir a IA. Desta forma, subentende-se que uma IA deve simular o raciocínio humano e desenvolver habilidades perceptivas e de tomadas de decisão, elevando ao máximo estas habilidades procurando sempre o melhor desempenho.
1.4. Redes Neurais Artificiais
De acordo com o autor (SPÖRL; CASTRO; LUCHIARI, 2011), as Redes Neurais Artificiais (RNA’s) são algoritmos computadorizados que possuem seu modelo matemático semelhante a estrutura neural de seres inteligentes, que tentam simular o funcionamento de um cérebro humano, ainda que de forma simplificada. Desta maneira, a partir de um aprendizado prévio, as Redes Neurais Artificiais conseguem desempenhar processos de estimação, com base neste aprendizado. O fato de serem capazes de “aprender” certo método de classificação e posteriormente reproduzi-la, possibilitou que as RNA’s sejam utilizadas nas mais diversas áreas, ofertando análises de imagens, diagnósticos médicos, identificação de pragas na agricultura, dentre outras.
De forma a compreender com mais facilidade os conceitos de uma RNA, é preciso previamente estudar o modelo real de um neurônio. Desta maneira, o autor (BIANCHINI, 2001) nos apresenta a representação de um neurônio real, bem como a identificação de cada uma de suas estruturas, mostrada na Figura 1. As dendrites são as estruturas responsáveis por receber os impulsos elétricos de outros neurônios. O corpo celular é responsável pelo processamento do sinal recebido. O axônio é a estrutura que permite a retransmissão do sinal recebido e processado. A conexão do axônio de um neurônio com a dendrite de outro, configurando uma troca de informações, é denominado de Sinapse.
Figura 1 – Modelo Neurônio Real
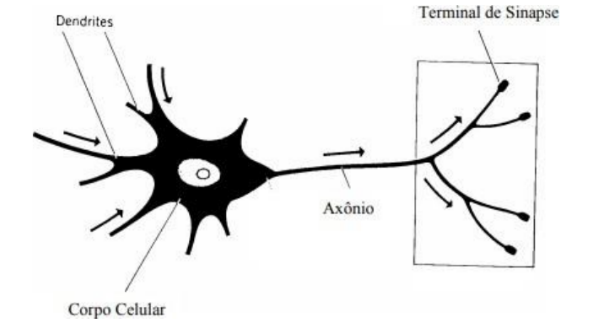
Fonte: (BIANCHINI, 2001).
O modelo de neurônio artificial também é apresentado pelo autor Bianchini (BIANCHINI, 2001) e é mostrado na Figura 2. Nesta representação, as sinapses representam os valores de entrada, que deverão ser multiplicadas a diferentes valores de pesos, configurando uma ponderação de sinal. Estes sinais serão somados através de um somador e posteriormente aplicado à uma função de ativação, realizando o processamento do sinal.
Figura 2 – Modelo Neurônio Artificial
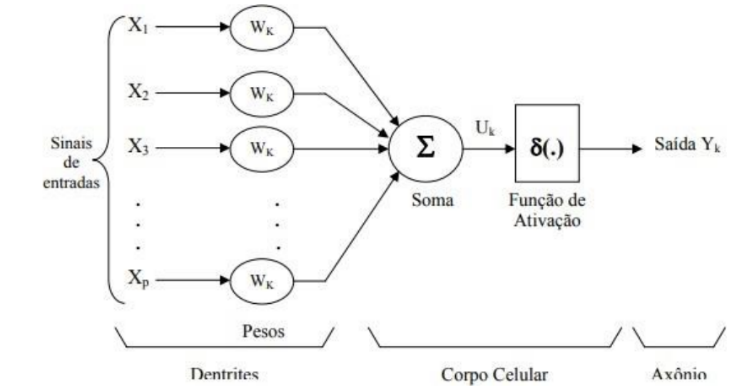
Fonte: (BIANCHINI, 2001).
Dependendo do tipo de Rede Neural e de sua finalidade, podem ser utilizados centenas e milhares de estruturas citadas acima, dispostas em diversas camadas.
1.5. Redes Neurais Convolucionais
As autoras (VARGAS; CARVALHO; VASCONCELOS, 2016) apresentam que uma Rede Neural Convolucional (CNN) é uma variação das redes neurais mais básicas, sendo principalmente usada para processamento de dados visuais. Uma CNN apresenta diversas camadas com diferentes funções. Majoritariamente, os dados de entrada são aplicados sobre uma camada de convolução. Esta camada é constituída de diversos neurônios como expressos na Figura 2. Cada neurônio aplica um filtro sobre uma partição específica da imagem.
Além disso, as autoras ainda explicam que neste tipo de Rede Neural, apenas um subconjunto de entradas é conectado a cada neurônio, de forma que cada neurônio realiza a análise de pequenas porções da imagem, os chamados campos perceptivos locais.
Outra estrutura importante deste tipo de Rede Neural é a camada de agrupamento (pooling) cuja principal função é reduzir a dimensão dos dados trabalhados garantindo agilidade no treinamento e criar a chamada variância espacial, que permite o reconhecimento de padrões em qualquer local da imagem.
A combinação destas camadas, juntamente com outras diversas que não foram abordadas neste texto, formam as chamadas Arquiteturas, que consistem, basicamente, no esqueleto da Rede Neural e apresentam todos os processos a serem realizados sob determinados dados de entrada.
Tendo em vista os pontos levantados, o escopo deste projeto visa o desenvolvimento de um algoritmo capaz de identificar a região dos olhos em uma face, tendo como dados de entrada um vídeo em tempo real. Com os olhos identificados, ocorre a extração desta região de interesse da imagem original, e por meio de uma Rede Neural Convolucional, é possível identificar a posição que o olho se encontra.
Este trabalho se justifica pelo uso de uma câmera de baixo custo, como uma câmera de celular, e um microcontrolador Arduino e um software open library para machines learning. Cria-se assim, um kit de fácil acesso que utiliza machine learning com redes neurais, usando equipamento de baixo custo.
2 METODOLOGIA
Para este projeto foram consideradas posições oculares simples, denotadas como PADRÃO, DIREITA, ESQUERDA, BAIXO e CIMA, caso o usuário esteja olhando para a frente, direita, esquerda, baixo e cima, respectivamente. Com o resultado proveniente da CNN é possível realizar a comunicação serial com um hardware, de forma a controlar um servo motor, através de posições oculares simples.
O desenvolvimento do algoritmo foi dividido em algumas partes de forma a facilitar o processo. Desta forma, temos a Construção do Banco de Dados, o Desenvolvimento da Rede Neural, a Obtenção da Região de Interesse e o Desenvolvimento do Código Final.
2.1. Construção do Banco de Dados
A eficiência de uma Rede Neural é um reflexo direto de seu banco de dados. Desta forma, para uma Rede Neural consistente é necessário também um banco de dados consistente, bem organizado e bem variado.
É possível encontrar diversos bancos de dados na internet sobre diversos tipos de conteúdo. Para este caso, foi necessário encontrar um banco de dados de olhos que atendessem as especificações deste projeto. Assim, foi necessário obter um dataset de imagens de olhos sob diferentes índices de luminosidade no qual houvessem diferentes posições oculares presentes.
O vídeo a ser analisado pelo algoritmo final será obtido através da câmera frontal de um celular Xiaomi Redmi Note 7, com especificações de 13MP, f/2.0, 1.12µm. Visando uma melhor eficiência da Rede Neural, de forma que os dados de treinamento sejam semelhantes aos da- dos trabalhados no resultado final, o banco de dados para treinamento da CNN foi desenvolvido pelo autor através de um algoritmo auxiliar.
De maneira a simular um método de controle a partir do algoritmo desenvolvido, foi utilizada a biblioteca Pyserial, de forma a realizar uma comunicação serial com microcontrolador Arduino UNO. Este microcontrolador foi utilizado devido a sua praticidade e facilidade na programação. Desta forma, para cada resultado obtido pela rede neural, é enviado um conjunto de bits diferentes pela comunicação serial, no qual o Arduino UNO ajusta a posição angular de um servo motor. A programação utilizada no Arduino realiza apenas a verificação do conjunto de bits recebidos pela comunicação serial e ajusta-os.
Foram gravados cerca de 7 vídeos, de aproximadamente 35 segundos cada, no qual o usuário filmava seu rosto e olhava para as 5 diferentes posições oculares trabalhadas, sob diferentes índices de luminosidades. Estas imagens obtidas foram utilizadas no treinamento e vali- dação da rede neural desenvolvida.
Para o desenvolvimento do algoritmo foram utilizadas bibliotecas específicas para o reconhecimento facial e ocular, manipulação dos dados e conceitos de visão computacional. Estas bibliotecas são, respectivamente, o Dlib-ml, Numpy e o OpenCV.
Utilizada pelas funções específicas de reconhecimento facial, a biblioteca Dlib-ml é uma biblioteca open source voltada para engenheiros e pesquisadores científicos que visa fornecer um ambiente igualmente rico para desenvolvimento de algoritmos de aprendizagem de máquina (KING, 2009). Para o reconhecimento facial, existem funções específicas capazes de identificar faces, além de predizer pontos de interesse localizados na face identificada.
NumPy é uma biblioteca open source fundamental para computação científica em Python. É uma biblioteca que fornece um objeto de matriz multidimensional, vários objetos derivados (como matrizes e matrizes mascaradas) e uma variedade de rotinas para operações rápidas em matrizes (NUMPY, 2021). Desta maneira, utilizando a biblioteca NumPy operações vetoriais são feitas com extrema rapidez e velocidade.
A biblioteca OpenCV trata-se de uma biblioteca open source utilizada para processamento de visão computacional. Um dos objetivos do OpenCV é proporcionar uma arquitetura de fácil implementação que ajude o usuário a desenvolver sofisticados algoritmos de visão computacional. Esta biblioteca contém mais de 500 funções que abrange diversas áreas em visão computacional, como inspeção de produtos em fábricas, imagens médicas, segurança, calibração de câmeras, dentre outras (BRADSKI; KAEHLER, 2008).
A cada 5 frames, o algoritmo realiza a análise da imagem. Isto evita que sejam analisadas imagens contendo informações muito parecidas. A cada frame analisado é identificado o rosto e seus pontos de interesse com a biblioteca Dlib-ml. Após isso, é realizada uma segmentação da imagem original de forma a conter todos os pontos de interesse ao redor dos olhos, abrangendo assim, toda a informação dos olhos dentro da segmentação. Esta segmentação, contendo a informação dos olhos, é sobreposta sobre um fundo branco e redimensionada de forma a possuir 30×30 pixels. É importante que esta imagem possua dimensão pequena para agilizar o processo de treinamento e predição da rede neural. Com a informação dos olhos extraída da imagem original, esta nova imagem é salva em um diretório específico.
Com as imagens salvas, elas são novamente analisadas, agora manualmente, e o usuário adiciona a posição ocular, observada na imagem, em seu nome. Desta forma, é possível, posteriormente, facilitar a criação dos labels do banco de dados para o treinamento da rede neural.
2.2. Desenvolvimento da Rede Neural
A arquitetura utilizada para o treinamento da Rede Neural utilizada foi baseada na CNN desenvolvida em (KINLI, 2018). A arquitetura original foi desenvolvida para o treinamento de uma rede neural de reconhecimento de emoções faciais, utilizando o banco de dados fer2013. Este banco de dados consiste em 35887 imagens de faces sob diferentes expressões. A partir de testes realizados com diversas arquiteturas diferentes, foi verificado um melhor resultado utilizando a arquitetura proposta em (KINLI, 2018).
Para o processamento dos dados de entrada, estruturação da arquitetura, treinamento da Rede Neural e dos testes realizados, foi desenvolvido um algoritmo em Python utilizando as bibliotecas OpenCV, NumPy e o Tensorflow.
O NumPy é uma biblioteca open-source fundamental para computação científica em Python. É uma biblioteca que fornece um objeto de matriz multidimensional, vários objetos derivados (como matrizes e matrizes mascaradas) e uma variedade de rotinas para operações rápidas em matrizes (NUMPY, 2021). Desta maneira, utilizando a biblioteca NumPy, as operações vetoriais são feitas com extrema rapidez e velocidade.
TensorFlow é uma biblioteca open source utilizada para computação numérica que utiliza gráficos de fluxos de dados para habilitar pesquisadores de aprendizagem de máquina a realizar mais computação intensiva de dados (ZACCONE; KARIM; MEN-SHAWY, 2017). O TensorFlow é um framework, ou seja, um conjunto de códigos que objetivam uma determinada aplicação. No contexto de Redes Neurais, esta biblioteca possui inúmeras funções para o desenvolvimento de CNNs que implementam arquiteturas, funções de ativações, algoritmos de otimização, funções de custo, dentre outras. Desta maneira, a estruturação, treinamento e teste de uma rede neural completa é severamente facilitada com o uso desta biblioteca.
O banco de dados de treinamento apresentado na seção anterior é processado de forma a atender as especificações necessárias. Para isso, todas as imagens são convertidas para tons de cinza, ou seja, a intensidade de cada pixel da imagem varia somente de 0 a 255, no qual 0 equivale ao preto de 255 ao branco. Estes valores são normalizados de forma a facilitar o treinamento da rede neural. Além disso, é definido um label para cada imagem, de acordo com a posição ocular especificada em seu nome. Desta forma, o treinamento da rede neural consegue associar a imagem a uma posição ocular.
Com as imagens do banco de dados já processadas, foi realizado uma divisão deste dataset, de forma aleatória, obtendo grupos de imagens para serem utilizados no treinamento, na validação e no teste da rede neural. Desta forma, o banco de dados de treinamento contou com 518 imagens, o de validação com 130 imagens e o de teste 162 imagens. A arquitetura consiste em 8 camadas convolucionais, responsáveis por gerar filtros que contém informações presentes na imagem de entrada. Para cada camada de convolução, é utilizado a função de ativação conhecida como ‘Relu’. Esta função de ativação serve para trazer uma não-linearidade para a CNN, sendo uma solução mais prática e eficiente do ponto de vista computacional, resultando em uma melhor convergência. Esta função zera os valores negativos na entrada do neurônio, sendo descrita como:

Além disso, nas camadas convolucionais é utilizado um padding com o parâmetro ‘same’. Isto garante que todos as extremidades da informação sejam analisadas pela CNN, incluindo colunas ou linhas de valor igual a 0 na informação, caso necessário.
A fim reduzir a informação das camadas anteriores, são utilizadas 4 camadas de Polling. Assim, é definida uma região de 2×2 pixels, que percorre toda a informação. Esta região é utilizada para resumir a informação contidas nos pixels em um único valor.
Com o objetivo de acelerar o processo de treinamento, são utilizadas 7 camadas de ‘Batch Normalization’. Estas camadas padronizam as entradas de cada camada de forma automática.
São utilizadas ainda, 7 camadas de Dropout. Estas camadas desativam alguns neurônios, aleatoriamente, durante o treinamento, de forma a obter diferentes valores de pesos e vieses. Assim, o Dropout garante que não serão realizados grandes ajustes de pesos e vieses, evitando assim, um over-fitting na Rede Neural.
A fim de organizar todos os dados em um único vetor, é utilizada uma camada de Flatten.
Por fim, são utilizadas 4 camadas densas, que possuem todos os neurônios conectados. Para as camadas densas, é utilizado a função de ativação ‘Softmax’. Esta função retorna a probabilidade da imagem analisada pela rede neural pertencer a cada um dos labels especificados. A classe que possuir maior probabilidade é a resposta estimada pela rede. Sua equação pode ser visualizada abaixo, no qual xi são valores pertencentes ao vetor resposta.

Vale ressaltar também que entre as camadas densas, são utilizadas mais camadas de ‘Dropout’, visando reduzir o overfitting do modelo.
Para o treinamento, a função de erro utilizada foi a ‘categorical crossentropy’. Este parâmetro é utilizado principalmente em casos onde há mais de uma classificação possível para a imagem trabalhada, e a rede neural precisa predizer qual classificação é a correta.
Como otimizador, foi utilizado o otimizador ‘Adam’. Este otimizador, serve para minimizar o erro encontrado, de forma eficiente, atualizando os valores dos pesos, sendo utilizado em aplicações envolvendo visão computacional.
A avaliação do modelo, ou seja, o parâmetro adotado para verificar se a rede neural apresenta bons resultados foi a Acurácia.
2.3. Desenvolvimento do Algoritmo Final
O último algoritmo desenvolvido trata-se da extração da região de interesse do vídeo de entrada, predição desta região de interesse a partir da rede neural treinada, exposição da posição ocular identificada e variação na posição de um servo motor com base no resultado obtido. As bibliotecas utilizadas são a OpenCV, Numpy, Dlib-ml, TensorFlow e a PySerial.
A biblioteca Pyserial realiza a conexão com as por- tas seriais, possibilitando a comunicação da programação Python com um microcontrolador ou hardware utilizado. Desta maneira, este algoritmo realiza a extração da região de interesse (olhos direito e esquerdo) de forma semelhante à desenvolvida para a criação do banco de dados de treinamento da Rede Neural. É utilizada a biblioteca Dlib-ml para identificar todos os pontos da face detectada no vídeo. Os pontos que contornam os olhos (36-41 para o olho direito e 42-47 para o esquerdo) são extraídos da imagem original e adicionados sobre um fundo branco de 30×30 pixels. No decorrer deste processo, são aplicados alguns filtros sobre a imagem de forma a suavizar contornos e reduzir ruídos indesejados presentes na imagem.
A função principal analisa frame a frame do vídeo recebido em tempo real. Em cada um dos frames é realizada a detecção de faces e, caso encontrada, são identificados os pontos de interesse facial. Posteriormente, são extraídos os olhos, como já explicado, e ambas as imagens (olho direito e esquerdo) são utilizadas como entradas na rede neural desenvolvida. Após a predição realizada pela rede neural, é retornado a probabilidade da imagem de entrada pertencer a cada um dos labels do treinamento (CIMA, DIREITA, ESQUERDA, PADRÃO). A classe que possuir maior probabilidade é exibida juntamente com o vídeo, indicando a posição ocular no qual o usuário está indicando. Considerando a câmera localizada na frente do usuário, a posição ocular BAIXO acaba por aproximar os landmarks obtidos pela biblioteca Dlib-ml, de forma que a imagem isolada dos olhos apresenta muita pouca informação, não sendo possível realizar a predição com a rede neural. Desta forma, para viabilizar a identificação da posição ocular ‘BAIXO’, foi utilizado um método semelhante ao apresentado no detector de piscadas, desenvolvido em (ROSEBROCK, 2017). Assim, foi realizado o cálculo da distância entre dois landmarks opostos verticalmente e horizontalmente. Após isso, é realizado uma operação de proporção, na qual, caso o valor resultante seja inferior a uma constante definida por meio de testes realizados, os olhos do usuário podem ser considerados semi-abertos e no contexto deste trabalho, pode ser considerada a posição ‘BAIXO’.
De maneira a simular um método de controle a partir do algoritmo desenvolvido, foi utilizada a biblioteca Pyserial, de forma a realizar uma comunicação serial com microcontrolador Arduino UNO. Este microcontrolador foi utilizado devido a sua praticidade e facilidade na programação. Desta forma, para cada resultado obtido pela rede neural, é enviado um conjunto de bits diferentes pela comunicação serial, no qual o Arduino UNO ajusta a posição angular de um servo motor. A programação utilizada no Arduino realiza apenas a verificação do conjunto de bits recebidos pela comunicação serial e ajusta a posição angular do servo motor.
3 RESULTADOS OBTIDOS
3.1. Construção do Banco de Dados
A partir do algoritmo de criação do dataset, utilizado para treinamento da rede neural, foi possível a partir de 7 vídeos feitos pelo autor, de 35 segundos aproximadamente, obter o seguinte número de imagens de cada classe, de acordo com a Tabela 1:
Tabela 1 – Banco de Dados de Treinamento

Fonte: O Autor.
Idealmente, é necessário que as classes contenham o mesmo número de imagens para, desta forma, evitar uma adaptação da rede às imagens em maior quantidade. Outro fato importante em salientar, é que o banco de dados foi construído em cima de vídeos gravados pelo próprio autor. Desta forma, esta rede neural não é recomendada para generalizações. Assim, no caso de outras pessoas tentarem realizar a predição das posições oculares, é previsível que os resultados sejam inferiores aos apresentados neste trabalho, uma vez que a rede neural não está adaptada a possíveis características fisiológicas presentes no usuário.
3.2. Desenvolvimento da Rede Neural
De acordo com a arquitetura utilizada, já apresentada neste trabalho, o treinamento foi realizado e obteve como resultados os gráficos expressos na Figura 3. De acordo com as métricas utilizadas, o treinamento obteve uma acurácia de 0.9745 e um erro de 0.1176, ambos valores satisfatórios para a aplicação. A predição realizada com o banco de dados de teste obteve uma acurácia de 0.9753 e um erro de 0.1020, sendo novamente, ambos considerados aceitáveis para a aplicação.
Figura 3 – Acurácia e Erro da Rede Neural
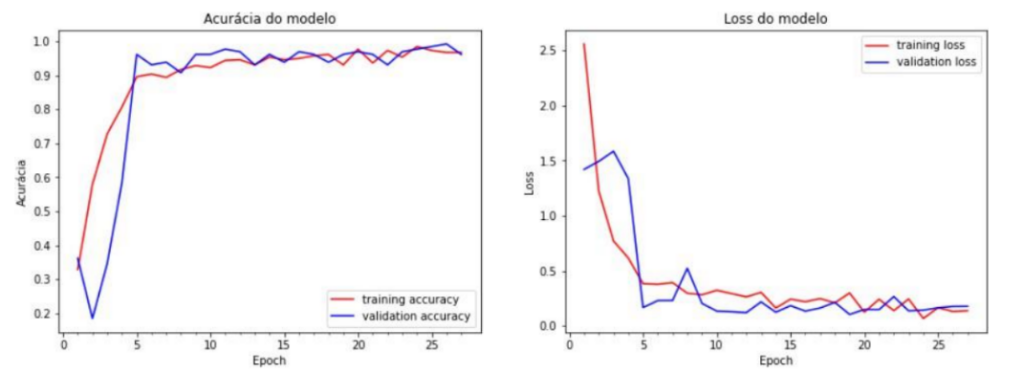
Fonte: O autor.
Para verificar a consistência da Rede Neural treinada, foram construídos outros 6 novos bancos de dados, sob diferentes níveis de luminosidades em diferentes períodos do dia. Estes bancos de dados foram pré-processados e especificados suas classes, como visto anteriormente. Após a predição realizada, foram observadas acurácias superiores a 97% em todos os bancos de dados utilizados, evidenciando a consistência da rede neural desenvolvida.
Através dos testes realizados, foi possível perceber que as maiores acurácias decorreram de ambientes com menor incidência de luz ou incidência de luz artificial. Isto se deve pelo fato de que, sob baixa luminosidade, a imagem em tons de cinza, sofre um maior contraste entre a pupila e íris com relação à esclera, facilitando na predição do modelo neural.
A discussão é o local do artigo que abriga os comentários sobre o significado dos resultados, a comparação com outros achados de pesquisas e a posição do autor sobre o assunto. Uma discussão sem estrutura coerente desagrada, daí a conveniência de organizar os temas em tópicos. Cada um dos tópicos informa sobre uma faceta da discussão e seu conjunto fornece os subsídios para se julgar a adequação dos argumentos, da conclusão e de todo o texto.
3.3. Desenvolvimento do Algoritmo Final
O algoritmo final foi desenvolvido para realizar a predição das posições oculares a partir de um vídeo sendo feito em tempo real, introduzindo, assim, uma nova forma de controle, de acordo com a Figura 4.
Figura 4 – Exemplo de imagens do dataset de Treinamento.

Fonte: O Autor.
A Figura 5 apresenta o diagrama de fluxo do funciona- mento do algoritmo final, de forma simplificada. As setas azuis representam o fluxo normal do algoritmo, enquanto as flechas coloridas expressam condicionais analisados pelo algoritmo. As setas vermelhas indicam uma condicional negativa e as verdes, positivas.
Observando a Figura 6 podemos visualizar alguns frames do vídeo analisado. Nestes frames é exibido a forma como o algoritmo retorna as predições realizadas, exibindo a posição detectada no canto superior esquerdo do vídeo analisado em tempo real.
Figura 5 – Diagrama de blocos do Algoritmo Final
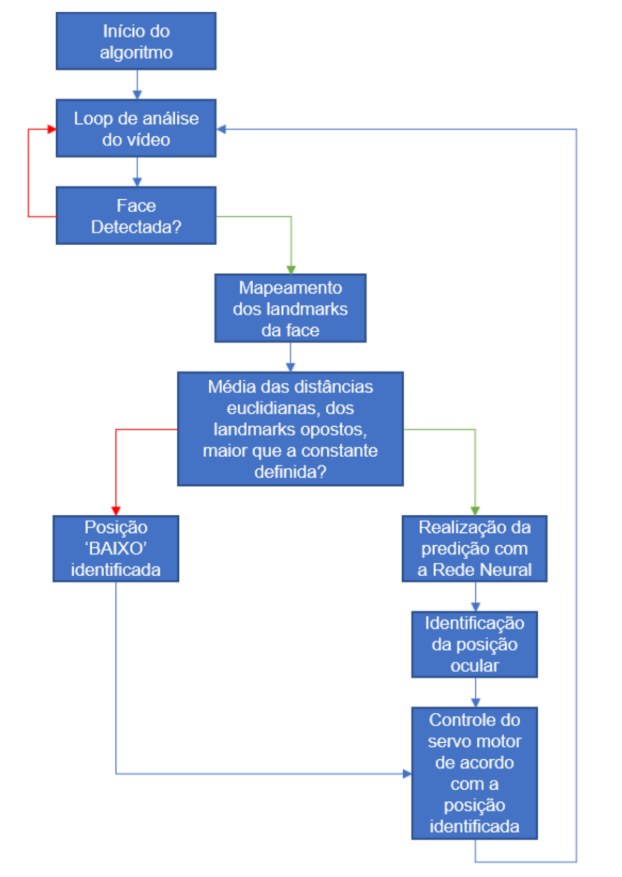
Fonte: O Autor.
Para evidenciar o sistema de controle desenvolvido, foi realizado a comunicação serial com um Arduino UNO que utiliza o protocolo UART com um baud rate de 9600bps. Este microcontrolador foi utilizado para alteração da posição angular de um servo motor a partir de uma programação simples. Desta maneira, foi estabelecido na programação do Arduino UNO, que a classe ‘PADRÃO’ equivale a 90º. No momento em que o usuário altera sua posição ocular para ‘DIREITA’, a rede neural realiza a predição desta posição e envia um conjunto de bits para o microcontrolador. Através da programação estabelecida no Arduino, o valor do ângulo é
reduzido, movimentando o eixo do servo para a direita. O mesmo acontece com a classe ‘ESQUERDA’, que neste caso aumenta o valor do ângulo, movimentando o eixo do servo para a esquerda.
Figura 6 – Exemplo de predição da Rede Neural com vídeo.

Fonte: O autor.
4 CONCLUSÕES
A alteração da posição angular do servo motor evidencia o êxito no sistema de controle desenvolvido. Neste caso, foram utilizadas apenas 3 posições oculares, ‘DIREITA’, ‘ESQUERDA’, ‘PADRÃO’, para o movimento do servo motor. É possível utilizar as demais posições oculares para outras finalidades, dependendo das especificações do projeto. Desta maneira, considerando o projeto apresentado em (GAINO, 2009), que visa o desenvolvimento de uma forma de controle visando pacientes Paraplégicos e Tetraplégicos através de modelos Fuzzy T-S, é possível associar as demais posições oculares no controle de velocidade, sendo possível desenvolver uma cadeira de rodas controlada unicamente pelas movimentações visuais, não dependendo da capacidade motora do usuário, ideal para casos de paraplegia e tetraplegia.
O fato de ter sido realizado a construção do banco de dados por meio de imagens de uma única pessoa através de seu celular evidencia a possível aplicação em uma cadeira de rodas autônoma para portadores de deficiências motoras, uma vez que, a rede neural se adapta unicamente a cada usuário e as características de qualidade de câmera de seu celular. A utilização do celular como câmera facilita na execução do projeto, além de baratear custos mas também, pode ser substituído por câmeras com maior qualidade gráfica em possíveis aprimoramentos técnicos do trabalho.
A partir disso, foi aferido que, a partir das posições oculares, uma pessoa é capaz de realizar movimentos através do servo motor, ainda que movimentos simples. Evidentemente que este trabalho necessita de inúmeros ajustes e aprimoramentos em seu desenvolvimento, caso o intuito seja utilizar este sistema no controle de equipamentos elétricos visando tecnologias assistivas, uma vez que a segurança do usuário é prioridade. O objetivo deste projeto é introduzir novos conceitos, evidenciando a possibilidade de novos sistemas de controle que, caso aprimorados e aperfeiçoados, possibilitarão a melhoria de qualidade de vida de uma grande parcela da população, especialmente grupos de pessoas com algum tipo de dificuldade motora, uma vez que necessidades físicas poderão ser supridas.
5 AGRADECIMENTOS
Os autores agradecem imensamente à Universidade Estadual de Londrina, pelo acesso a informação e possibilidade de realização deste trabalho, ao CNPq pelo apoio financeiro.
REFERÊNCIAS
BAMPI, Luciana Neves da Silva; GUILHEM, Dirce; LIMA, David Duarte. Qualidade de vida em pessoas com lesão medular traumática: um estudo com o WHOQOL-bref. Revista Brasileira de Epidemiologia, v. 11, n. 1, p. 67-77, 2008.
BIANCHINI, Ângelo. Arquitetura de Redes Neurais para Reconhecimento Facial Baseado em Neocognitron. São Carlos, 2001. 141 p. Monografia (Ciência da Computação) – Universidade Federal de São Carlos, São Carlos, 2001.
BRASIL. Cartilha do censo 2010: pessoas com deficiência. (Org.). OLIVEIRA, L.M.B. Brasília, DF: SDH-PR/SNDP, 2012.
BRADSKI, Gary; KAEHLER, Adrian. Learning OpenCV: Computer Vision with the OpenCV Library. Sebastopol: O’Reilly Media, f. 288, 2008. 575 p. IBGE. CENSO 2010. Disponível em: https://censo2010.ibge.gov.br/apps/mapa/. Acesso em: 01 de maio de 2020). 2010.
DAHMANI M, CHOWDHURY MEH, KHANDAKAR A, RAHMAN T, AL-JAYYOUSI K, HEFNY A, KIRANYAZ S. An Intelligent and Low-Cost Eye-Tracking System for Motorized Wheelchair Control. Sensors (Basel). 2020 Jul 15;20(14):3936. doi: 10.3390/s20143936. PMID: 32679779; PMCID: PMC7412002.
GAINO, Ruberlei. Controle de Movimentos de Pacientes Paraplégicos Utilizando Modelos Fuzzy T-S. Ilha Solteira, 2009. 178 p. Tese (FACULDADE DE ENGENHARIA ELETRICA CAMPUS ILHA SOLTEIRA) – Universidade Estadual Paulista “Julio de Mesquita Filho” – Unesp, Ilha Solteira, 2009.
GENTILHO JUNIOR, Edno. Instrumentação e Controle PID Embarcado para Cadeiras de Rodas Elétricas Acionada por Sopro e Sucção. Londrina f. 97, 2014. Dissertação (Mestrado em Engenharia Elétrica) – Universidade Estadual de Londrina, Londrina, 2014.
GOMIDE, Renato de Sousa. Ambiente Virtual para Reabilitação de Membros Superiores Utilizando visão Computacional. Goiânia, f. 89, 2012. Dissertação (Escola de Engenharia Elétrica e Computação) – Universidade Federal de Goiás, Goiânia, 2012.
INPI. Motorização de cadeiras de rodas por motores de indução trifásicos com controle vetorial e comando por joystick e sopro/sucção. Revista da Propriedade Industrial, 2669:632, 2022.
INPI. Cadeira de rodas movida por sopro e sucção. Revista da Propriedade Industrial, 2708:586, 2022.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, Tabela 3425 – População Residente por tipo de Deficiência, segundo a Situação do Domicílio, o Sexo e os Grupos de Idades. sistema IBGE de Recuperação Automática – SIDRA (2021a). Disponível em: https://sidra.ibge.gov.br/tabela/3425#resultado. Acesso em: 24 maio 2021.
INSTITUTO BRASILEIRO DE GEOGRAFIA E ESTATÍSTICA, Tabela 2111 – População Residente por tipo de Deficiência, segundo a Situação do Domicílio, o Sexo e os Grupos de Idades. sistema IBGE de Recuperação Automática – SIDRA (2021b). Disponível em: https://sidra.ibge.gov.br/tabela/2111#resultado. Acesso em: 24 maio 2021.
KING, Davis. Dlib-ml: A Machine Learning Toolkit. Jour- nal of Machine Learning Research, Baltimore, Maryland, USA, v. 10, p. 1755-1758, Setembro, 2009.
KINLI, Furkan. [Deep Learning Lab] Episode-3: fer2013. Disponível em: https://medium.com/birdortyedi_23820/deep-learning- lab-episode-3-fer2013-c38f2e052280. Acesso em: 19 jun. 2021.
LEÔNCIO JUNIOR, A. P.; PERIOTTO, A. J.; NUNES, W. R. B. M.; CAUN, R. P; COVACIC, M. R.; GAINO, R.. Voice String Throat Vibration Voice Recognition System for Electric Rotorcraft Navigation. Journal of Engineering Research, v.5, n. 2, p.1 – 11, 2025.
NEVES, Luiz; NETO, Hugo; GONZAGA, Adilson. Avanços em Visão Computacional. Curitiba, PR: Omnipax Editora, 2012. 406 p.
NORVIG, PETER; RUSSELL, STUART. INTELIGENCIA ARTIFICIAL: Tradução da Terceira Edição. GEN LTC, 2013. 1016 p.
NUMPY. Documentation: Whats NumPy?. Disponível em: https://numpy.org/. Acesso em: 22 mai. 2021.
NUNES, Willian Ricardo Bispo Murbak. Desenvolvimento de sistemas com motores trifásicos de indução de alto rendimento, IFOC e comando por joystick para cadeira de rodas. Londrina f. 248, 2015. Dissertação (Mestrado em Engenharia Elétrica) – Universidade Estadual de Londrina, Londrina, 2015.
PEREIRA, Luís. Inteligência Artificial: Mito e Ciência. Ciberscópio, Outubro 2003.
ROSEBROCK, Adrian. Eye blink detection with OpenCV, Python and Dlib. Pyimagesearch. Disponível em: https://www.pyimagesearch.com/2017/04/24/eye- blink-detection-opencv python-dlib/. Acesso em: 19 jun. 2021.
SILVA, M. D. L. da; MAGAN, M. V.; OLIVEIRA, I. H. N. Cadeira de Rodas Motorizada Controlada pela Íris. Revista Técnico-Científica do CREA-PR, Edição Especial Melhores TCCs, p. 1-19, Setembro, 2021.
SOUSA, Ingrid. Estudo e desenvolvimento de um sistema de reconhecimento de expressões faciais para controle de cadeira de rodas. Brasília, DF, 2019. 65 p. Trabalho de Conclusão de Curso (Engenharia Eletrônica) – Universidade de Brasília – Unb, Brasília, DF, 2019.
SPÖRL, Christiane; CASTRO, Emiliano; LUCHIARI, Aílton. Aplicação de Redes Neurais Artificiais na Con- strução de Modelos de Fragilidade Ambiental. Revista do Departamento de Geografia, São Paulo, v. 21, p. 113-135, 2011.
THARWAT, M.; SHALABI, G. SALEH, L.; BADAWOUD, N.; ALFALATI, R., “Eye Controlled Wheelchair,” 2022 5th International Conference on Computing and Informatics (ICCI), New Cairo, Cairo, Egypt, 2022, pp. 097-101.
VARGAS, Ana; CARVALHO, Aline; VASCONCELOS, Cristina. Um estudo sobre redes neurais convolucionais e sua aplicação em detecção de pedestres. In: PROCEED- INGS OF THE XXIX CONFERENCE ON GRAPHICS. 2016. Proceedings […]. 1-4 p.
ZACCONE, Giancarlo; KARIM, Md. Rezaul; MEN-SHAWY, Ahmed. Deep Learning with TensorFlow. Birm- ingham: Packt Publishing Ltd, f. 160, 2017. 320 p.
XU, J.; HUANG, Z.; LIU, L.; LI, X.; WEI, K. Eye-Gaze Controlled Wheelchair Based on Deep Learning. Sensors 2023, 23, 6239.
1Engenheiro Eletricista do Curso Superior de Engenharia Elétrica da Universidade Estadual de Londrina Campus Londrina e-mail: arnaldo.cubaski@gmail.com
2Docente do Curso Superior de Engenharia Elétrica da Universidade Estadual de Londrina Campus Londrina. Doutor em Engenharia Elétrica (FEIS/UNESP). e-mail: marciocovacic@uel.br
3Docente do Curso Superior de Engenharia Elétrica da Universidade Estadual de Londrina Campus Londrina. Doutor em Engenharia Elétrica (FEIS/UNESP). e-mail: rgaino@uel.br